本系列從零開始闡述如何編寫Python網絡爬蟲,以及網絡爬蟲中容易遇到的問題,比如具有反爬,加密的網站,還有爬蟲拿不到數據,以及登錄驗證等問題,會伴隨大量網站的爬蟲實戰來進行。
我們編寫網絡爬蟲最主要的目的是爬取想要的數據還有通過爬蟲去自動完成我們想在網站中做的一些事情。
從今天開始我會從基礎開始講解如何通過網絡爬蟲去完成你想要做的事。
先來看一段簡單的代碼。
import requests #導入requests包
url = 'https://www.cnblogs.com/LexMoon/'
strhtml = requests.get(url) #get方式獲取網頁數據
print(strhtml.text)
首先是import requests來導入網絡請求相關的包,然后定義一個字符串url也就是目標網頁,之后我們就要用導入的requests包來請求這個網頁的內容。
這里用了requests.get(url),這個get並不是拿取的那個get,而是一種關於網絡請求的方法。
網絡請求的方法有很多,最常見的有get,post,其它如put,delete你幾乎不會見到。
requests.get(url)就是向url這個網頁發送get請求(request),然后會返回一個結果,也就是這次請求的響應信息。
響應信息中分為響應頭和響應內容。
響應頭就是你這次訪問是不是成功了,返回給你的是什么類型的數據,還有很多一些。
響應內容中就是你獲得的網頁源碼了。
好了,這樣你就算是入門Python爬蟲了,但是還是有很多問題。
1. get和post請求有什么區別?
2. 為什么有些網頁我爬取到了,里面卻沒有我想要的數據?
3. 為什么有些網站我爬下來的內容和我真實看到的網站內容不一樣?
get和post請求有什么區別?
get和post的區別主要在於參數的位置,比如說有一個需要登錄用戶的網站,當我們點擊登錄之后,賬號密碼應該放在哪里。
get請求最直觀的體現就是請求的參數就放在了URL中。
比如說你百度Python這個關鍵字,就可以發現它的URL如下:
https://www.baidu.com/s?wd=Python&rsv_spt=1
這里面的dw=Python就是參數之一了,get請求的參數用?開始,用&分隔。
如果我們需要輸入密碼的網站用了get請求,我們的個人信息不是很容易暴露嗎,所以就需要post請求了。
在post請求中,參數會放在請求體內。
比如說下面是我登錄W3C網站時的請求,可以看到Request Method是post方式。
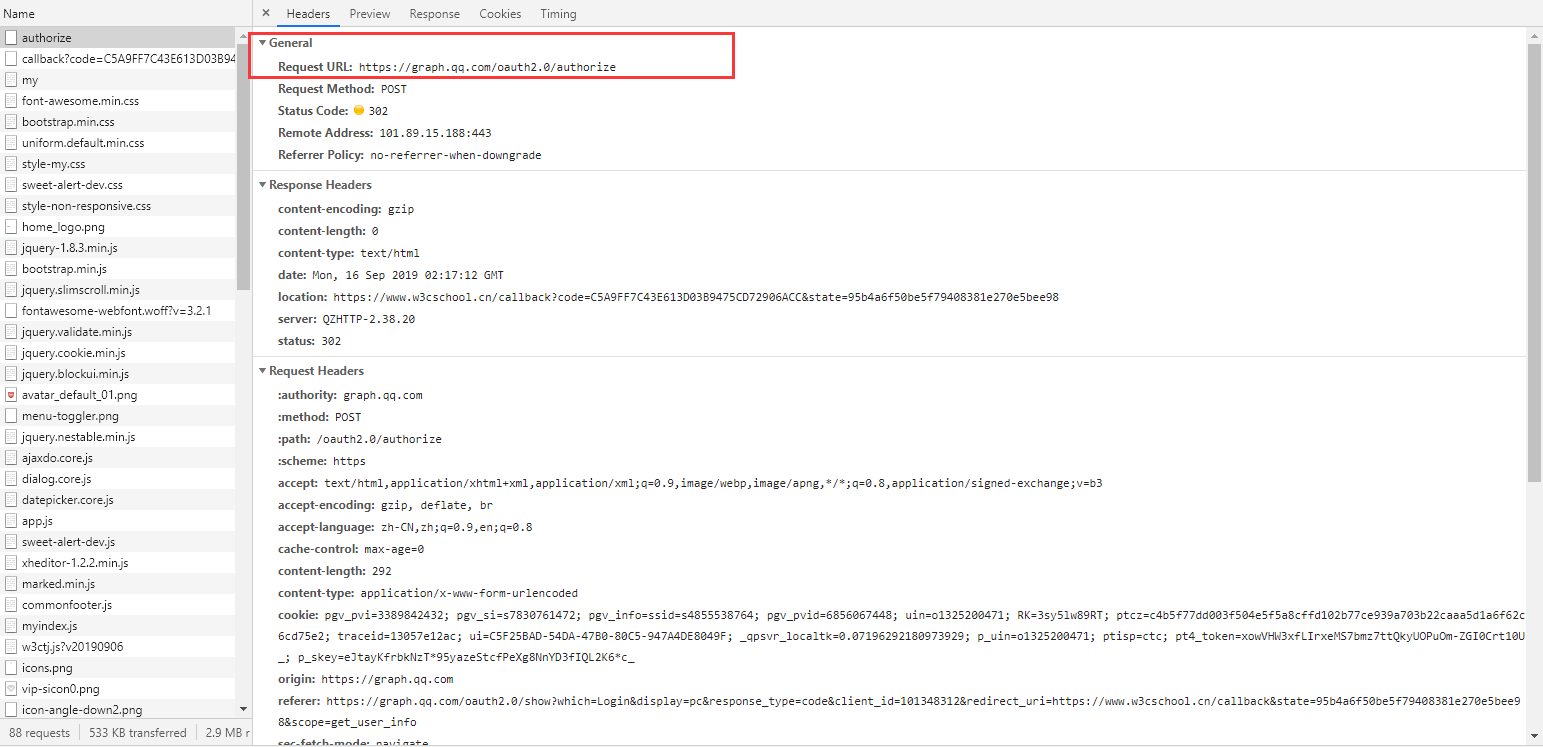
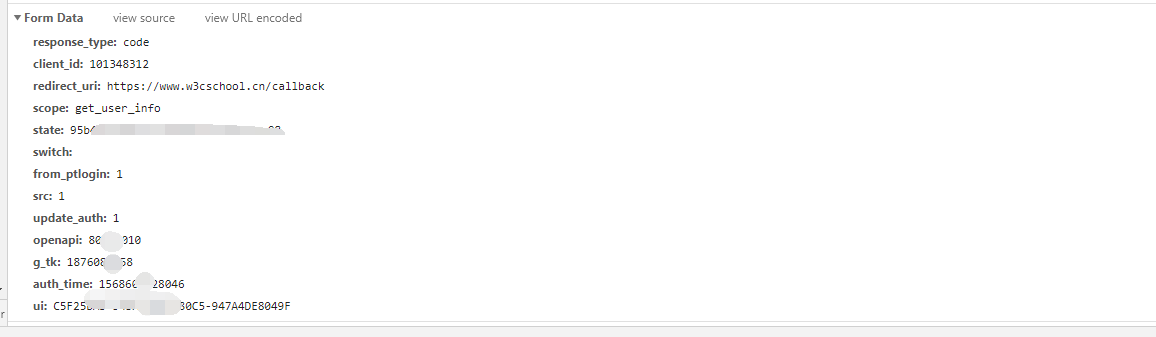
在請求的下面還有我們發送的登錄信息,里面就是加密過后的賬號密碼,發送給對方服務器來檢驗的。
為什么有些網頁我爬取到了,里面卻沒有我想要的數據?
我們的爬蟲有時候可能爬下來一個網站,在查看里面數據的時候會發現,爬下來的是目標網頁,但是里面我們想要的數據卻沒有。
這個問題大多數發生在目標數據是那些列表型的網頁,比如說前幾天班上一個同學問了我一個問題,他在爬攜程的航班信息時,爬下來的網頁除了獲得不了航班的信息,其他地方都可以拿到。
網頁地址:https://flights.ctrip.com/itinerary/oneway/cgq-bjs?date=2019-09-14
如下圖:
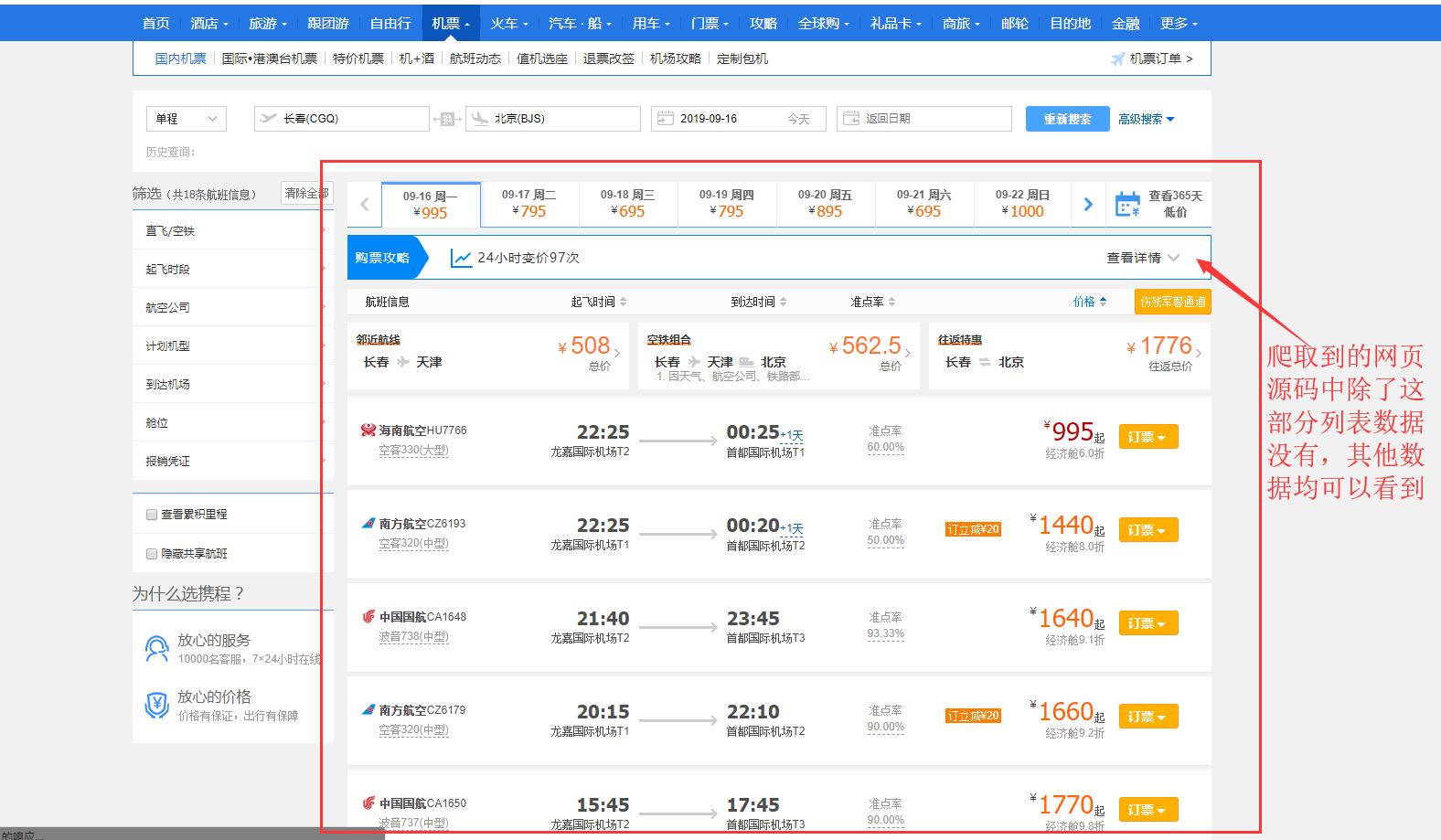
這是一個很常見的問題,因為他requests.get的時候,是去get的上面我放的那個URL地址,但是這個網頁雖然是這個地址,但是他里面的數據卻不是這個地址。
聽起來很像很難,但是從攜程這個網站的設計人的角度來說,加載的這部分航班列表信息可能很龐大,如果你是直接放在這個網頁里面,我們用戶打開這個網頁可能需要很久,以至於認為網頁掛了然后關閉,所以設計者在這個URL請求中只放了主體框架,讓用戶很快進入網頁中,而主要的航班數據則是之后再加載,這樣用戶就不會因為等待很長時間而退出了。
說到底怎么做是為了用戶體驗,那么我們應該怎么解決這個問題呢?
如果你學過前端,你應該知道Ajax異步請求,不知道也沒事,畢竟我們這里不是在說前端技術。
我們只需要知道我們最開始請求的https://flights.ctrip.com/itinerary/oneway/cgq-bjs?date=2019-09-14這個網頁中有一段js腳本,在這個網頁請求到之后會去執行,而這段腳本的目的就是去請求我們要爬的航班信息。
這時候我們可以打開瀏覽器的控制台,推薦使用谷歌或者火狐瀏覽器,按F進入坦克,不,按F12進入瀏覽器控制台,然后點擊NetWork。
在這里我們就可以看到這個網頁中發生的所有網絡請求和響應了。
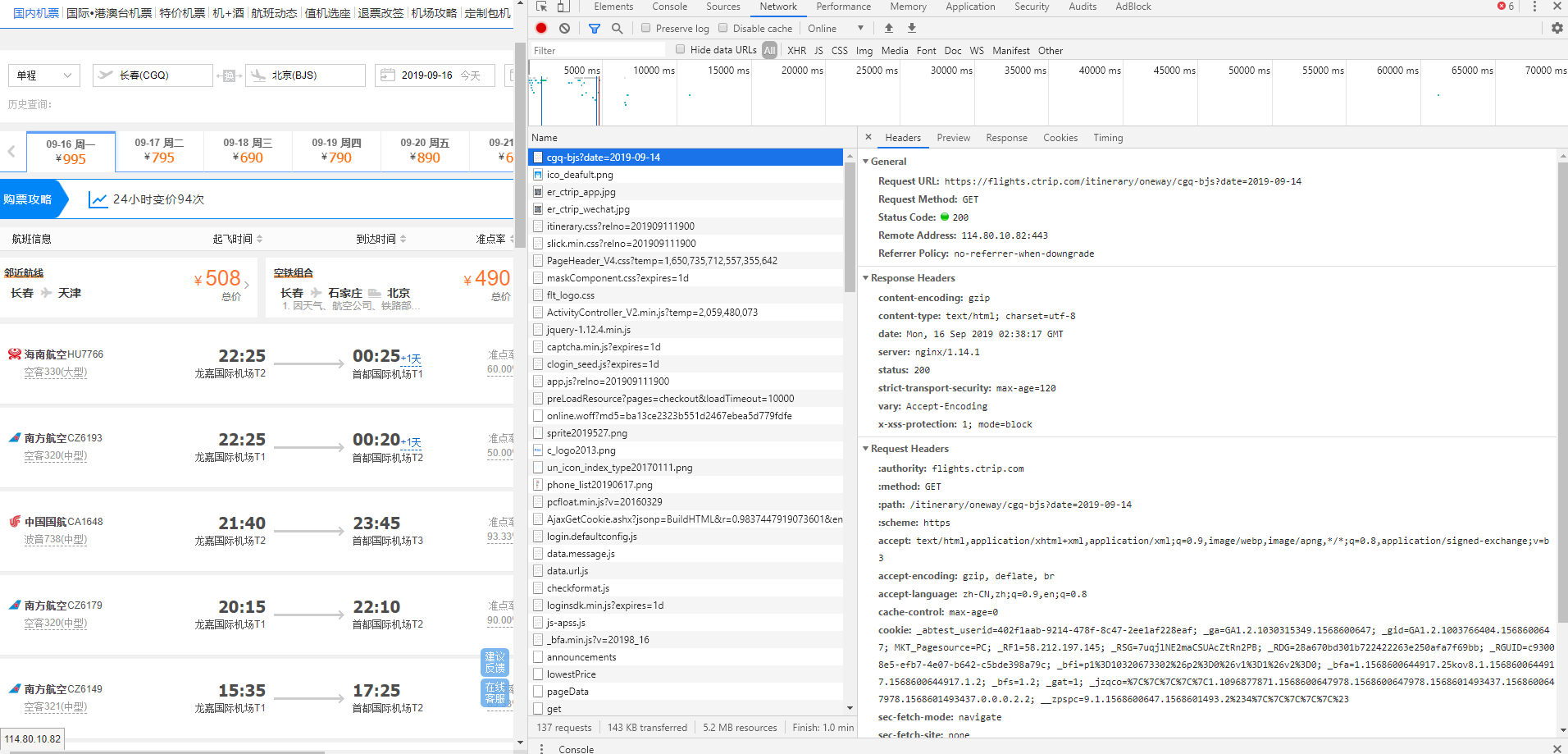
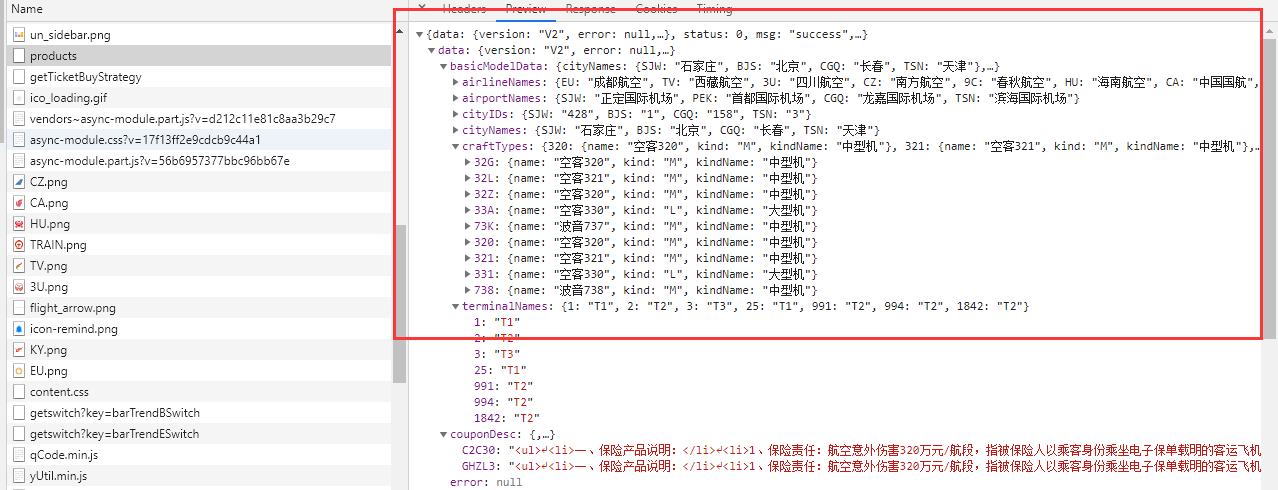
在這里面我們可以找到請求航班信息的其實是https://flights.ctrip.com/itinerary/api/12808/products這個URL。
為什么有些網站我爬下來的內容和我真實看到的網站內容不一樣?
最后一個問題就是為什么有些網站我爬下來的內容和我真實看到的網站內容不一樣?
這個的主要原因是,你的爬蟲沒有登錄。
就像我們平常瀏覽網頁,有些信息需要登錄才能訪問,爬蟲也是如此。
這就涉及到了一個很重要的概念,我們的平常觀看網頁是基於Http請求的,而Http是一種無狀態的請求。
什么是無狀態? 你可以理解為它不認人,也就是說你的請求到了對方服務器那里,對方服務器是不知道你到底是誰。
既然如此,我們登錄之后為什么還可以長時間繼續訪問這個網頁呢?
這是因為Http雖然是無狀態的,但是對方服務器卻給我們安排了身份證,也就是cookie。
在我們第一次進入這個網頁時,如果之前沒有訪問過,服務器就會給我們一個cookie,之后我們在這個網頁上的任何請求操作,都要把cookie放進去。這樣服務器就可以根據cookie來辨識我們是誰了。
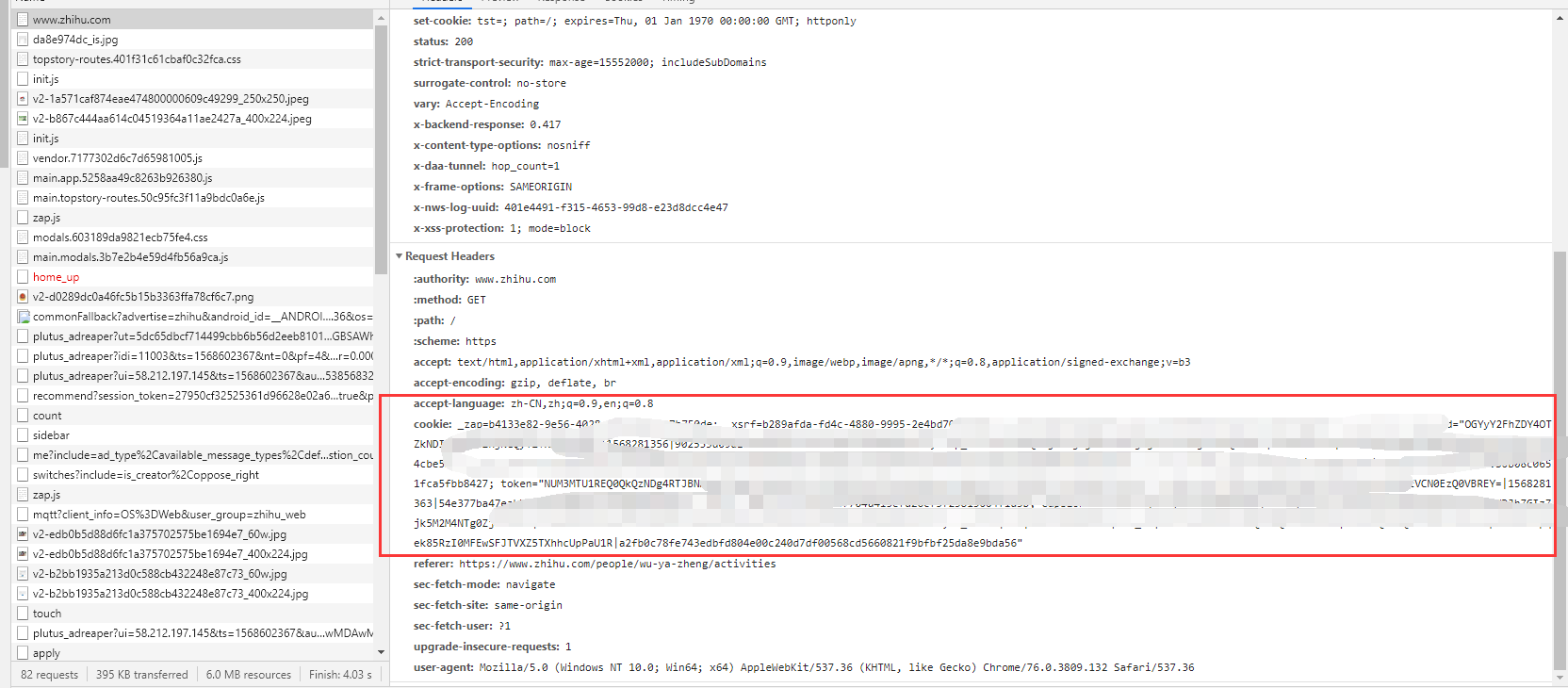
比如知乎里面就可以找到相關的cookie。
對於這類網站,我們直接從瀏覽器中拿到已有的cookie放進代碼中使用,requests.get(url,cookies="aidnwinfawinf"),也可以讓爬蟲去模擬登錄這個網站來拿到cookie。