結合CNN的可以參考:http://fcst.ceaj.org/CN/article/downloadArticleFile.do?attachType=PDF&id=1497
除了行為,其他還結合了時序的異常檢測的:https://conference.hitb.org/hitbsecconf2018ams/materials/D1T2%20-%20Eugene%20Neyolov%20-%20Applying%20Machine%20Learning%20to%20User%20Behavior%20Anomaly%20Analysis.pdf 里面提到了。也本質上就是LSTM做回歸。
deeplog除了檢測序列是否異常外,還檢測命令參數是否正常,也就是用LSTM去預測取值,看MSE是否很大。https://github.com/charles-typ/DeepLog-instroduction 這里有更加詳細的說明。
--------------------------------------
DeepLog:基於深度學習的日志異常檢測
簡介
本文介紹一個基於深度學習的日志異常檢測系統——DeepLog,來自安全領域頂會CCS2017。
系統日志記錄了系統的各個時段的狀態和重要事件,是性能監控和異常檢測的重要數據來源,而異常檢測是構建安全可靠系統的關鍵一步。現有基於日志的異常檢測方法主要分為三種,分別是使用PCA做異常檢測、分析不同日志類別相關性做異常檢測以及使用工作流模型做異常檢測。雖然這些異常檢測方法能夠有效地應用在特定的領域,但是它們不是一個通用的在線異常檢測方法。因此,通過系統日志做自動化地異常檢測是非常有必要的。
挑戰
系統日志的應用比較復雜,存在如下挑戰:
•非結構化日志,它們的格式和語義在不同系統之間有很大差異,一些現有的方法使用基於規則的方法來解決這個問題,但是規則的設計依賴於領域知識,例如工業界常用的正則表達式。 更重要的是,基於規則的方法對於通用異常檢測來說並不適用,因為我們幾乎不可能預先知道不同類型日志中的關注點是什么。
•時效性。為了用戶能夠及時的發現系統出現的異常,異常檢測必須要及時,日志數據以數據流的形式輸入,意味着需要對整個日志數據做分析的方法不適用。
•異常類型多。系統和應用程序可能會產生多種類型的異常。我們希望異常檢測系統不僅針對於特定的異常類型,還能檢測未知的異常。同時,日志消息中也包含了豐富的信息,比如log key、參數值、時間戳等。大多數現有的異常檢測方法僅僅分析了日志消息的特定部分(比如log key),這限制了它們能檢測到的異常類型。
DeepLog設計思想
針對上述挑戰,論文作者提出了一種基於深度學習的日志異常檢測系統——DeepLog。DeepLog通過以下三步異常檢測來綜合判斷系統異常,其框架如下圖所示。
1.執行路徑異常檢測。將異常檢測問題轉換成一個log key的多分類問題,使用LSTM對日志的log key序列建模, 自動從正常的日志數據中學習正常的模式並且由此來判斷系統異常。同時,LSTM可以增量式地調整模型參數,以便適應隨着時間推移而出現的新日志文件。
2.參數和性能異常檢測。f有時候系統雖然是按照正常操作步驟執行的,但是記錄的日志中的參數是不正常的,比如延遲比正常要大,這種情況也屬於異常。
3.工作流異常檢測。雖然工作流模型在異常檢測的有效性上不如LSTM模型,但是工作流模型可以可視化地幫助運維工程師在發現異常后找出異常的原因。
1、執行路徑異常檢測
大多數系統日志都是由系統按照一定的格式輸出的非結構化的文本,log key來表示一類日志(例如k1: Took * seconds to deallocate network),現有很多方法可以提取日志的log key。一般的,日志會按照一定的順序輸出,分步記錄了系統的狀態,即文中的執行路徑。DeepLog將執行路徑異常檢測的問題轉換為log key的多分類問題,使用下圖所示的LSTM網絡對log key序列建模。假設日志共有n個log key,DeepLog的輸入為一個時間窗口內的log key序列,輸出為所有的log key在該log key序列之后出現的概率的向量。也就是說,如果新來的一條日志對應的log key不是接下來出現概率較大的log key,則視為異常。
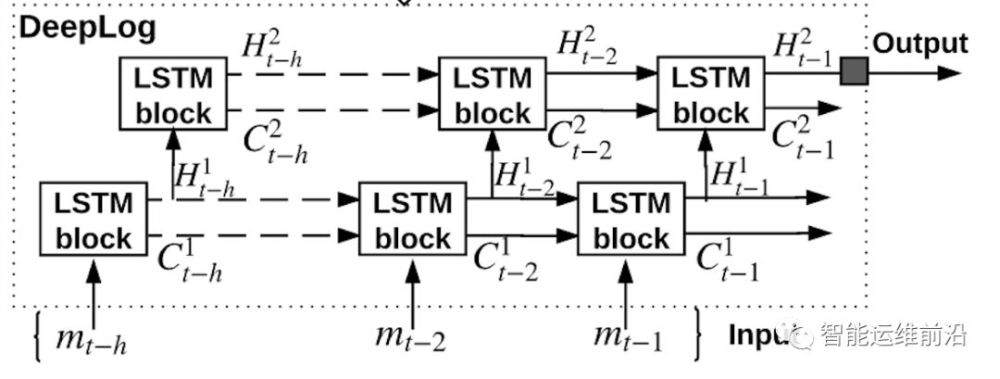
例如一段時間內logkey序列為,DeepLog讀取日志的窗口h為3,則DeepLog的輸入序列和輸出logkey分別為,和{ k3,k4,k5–> k6}。
在實際應用中,一個給定的log key序列之后可能會出現多種日志,而且這些日志可能都是正常的。例如系統在嘗試連接到主機時,“Waiting for * ” 和 “Connected to * ”這兩種日志都屬於正常的日志。所以DeepLog在這一步的異常檢測時,按照下一個log key出現的概率排序,將前幾個log key都視為正常。
2、參數和性能異常檢測
有些系統異常發生時,它的日志不會偏離正常的執行路徑,但是它日志內的參數會與正常情況下的參數有較大差異。DeepLog將每一個log key對應的參數保存下來,作為異常檢測的數據源。與執行路徑異常檢測的方法類似,參數和性能異常檢測也會使用LSTM網絡建模。它的輸入為某個log key對應日志中近期歷史的參數值向量,輸出為下一個參數值的預測值。在實際應用中,如果預測值和觀測值之間的誤差在高斯分布的高置信區間內,則輸入的日志參數被認為是正常,否則認為是異常事件。
3、工作流異常檢測
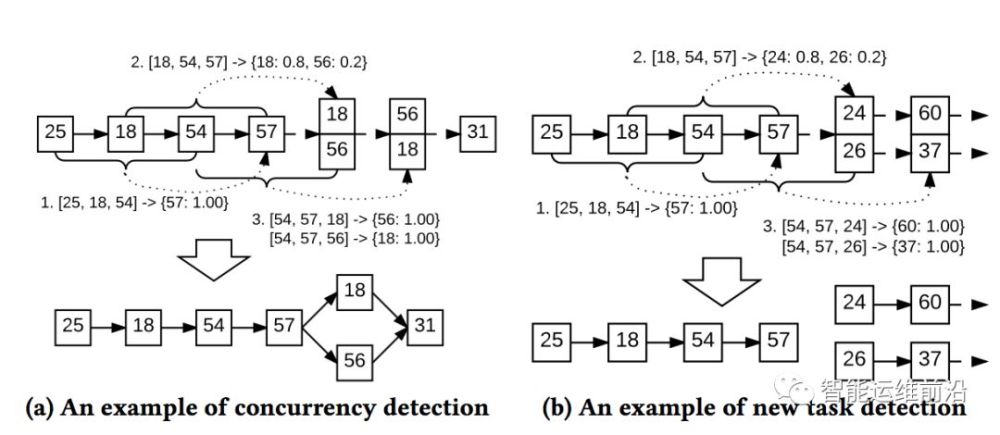
在許多系統日志中,日志消息是由多個不同的線程或並發運行的任務生成的。然而現有的方法都是基於單個任務的日志來生成工作流模型。所以在創建工作流模型時,會下圖兩種情況。圖a表示的是同一個任務並發產生了不同的日志,圖b表示新的任務產生了新的日志類型。DeepLog會將日志分類成不同任務對應下的日志,然后使用傳統的工作流模型來生成工作流,方便運維工程師查看異常原因。
實驗驗證
DeepLog使用了兩個數據集來驗證DeepLog的有效性,分別是從亞馬遜獲取的HDFS日志和自己模擬的OpenStack日志。首先作者使用HDFS日志對比了DeepLog與PCA、IM等傳統方法在執行路徑異常檢測的准確率。
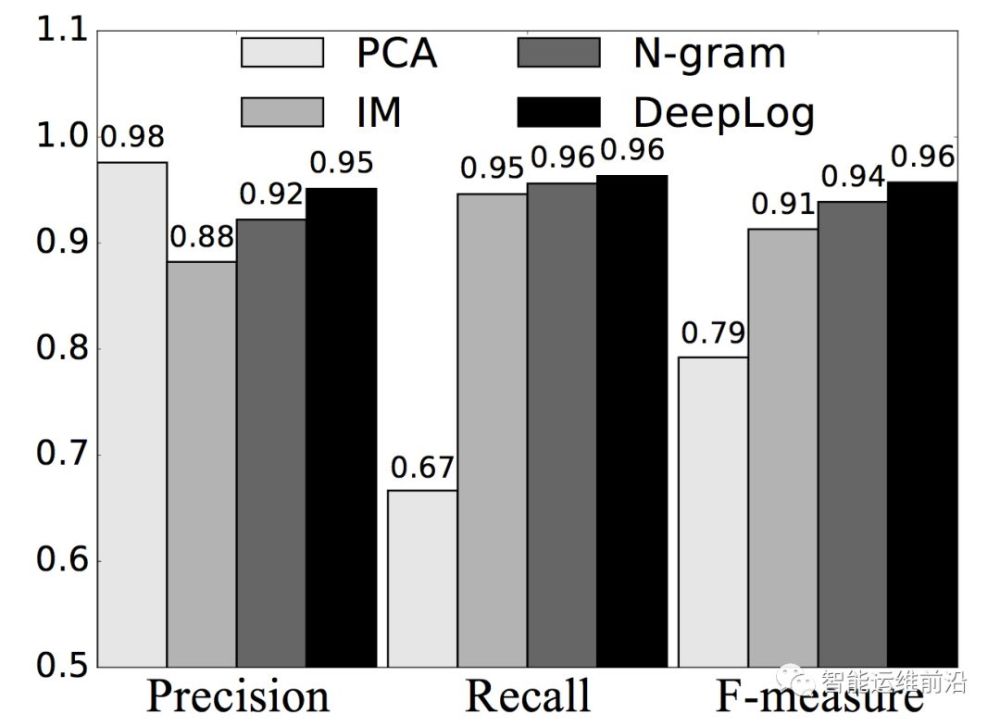
從圖中我們看到,DeepLog的Precision、Recall、F-measure都高於其他傳統的異常檢測算法。然后作者通過自己模擬的OpenStack異常來證明參數和性能異常檢測的有效性,下圖中a、b兩個子圖展示的是正常的日志參數對應的MSE(均方誤差),c、d兩個子圖是有異常時MSE的變化,紅色虛線代表的是不同置信區間的邊界。通過對比這四個子圖,我們可以看出DeepLog可以有效的從數值型參數中檢測異常。

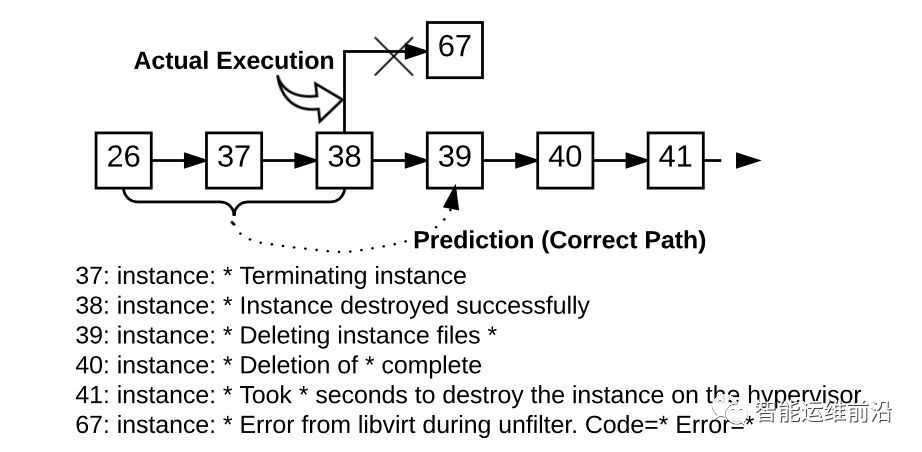
最后,作者使用OpenStack異常的例子解釋了工作流模型的使用場景。下圖展示的是一個OpenStack系統異常的例子。在log key序列出現之后,理論上下一個log key應該是k39,但是實際的log key為k67,即發生了異常。通過查看工作流,我們可以發現異常發生在"Instance destroyed successfully"之后,"Deleting instance files *"之前,說明異常發生在清理虛擬機的過程中。
結論
本文介紹了一種基於日志的異常檢測系統——DeepLog,用於自動、准確的檢測系統異常。DeepLog分別包含執行路徑、參數和性能、工作流異常檢測三個部分,綜合的來判斷系統是否發生了異常。由於長度限制,本文沒有介紹DeepLog的算法細節,特此附上論文鏈接。