第4章 Hadoop運行模式4.1 本地運行模式4.1.1 官方Grep案例4.1.2 官方WordCount案例4.2 偽分布式運行模式4.2.1 啟動HDFS並運行MapReduce程序4.2.2 啟動YARN並運行MapReduce程序4.2.3 配置歷史服務器4.2.4 配置日志的聚集4.2.5 配置文件說明4.3 完全分布式運行模式(開發重點)4.3.1 虛擬機准備4.3.2 編寫集群分發腳本xsync4.3.3 集群配置4.3.4 集群單點啟動4.3.5 SSH無密登錄配置4.3.6 群起集群4.3.7 集群啟動/停止方式總結4.3.8 集群時間同步第5章 Hadoop編譯源碼(面試重點)5.1 前期准備工作5.2 jar包安裝5.3 編譯源碼第6章 常見錯誤及解決方案
第4章 Hadoop運行模式
Hadoop運行模式包括:本地模式、偽分布式模式以及完全分布式模式。
Hadoop官方網站:http://hadoop.apache.org/
4.1 本地運行模式
4.1.1 官方Grep案例
1、創建在hadoop-2.7.2文件下面創建一個input文件夾
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir input
2、將Hadoop的xml配置文件復制到input
[atguigu@hadoop101 hadoop-2.7.2]$ cp etc/hadoop/*.xml input/
3、執行share目錄下的MapReduce程序
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input/ output/ 'dfs[a-z.]+'
4、查看輸出結果
[atguigu@hadoop101 hadoop-2.7.2]$ cat output/*
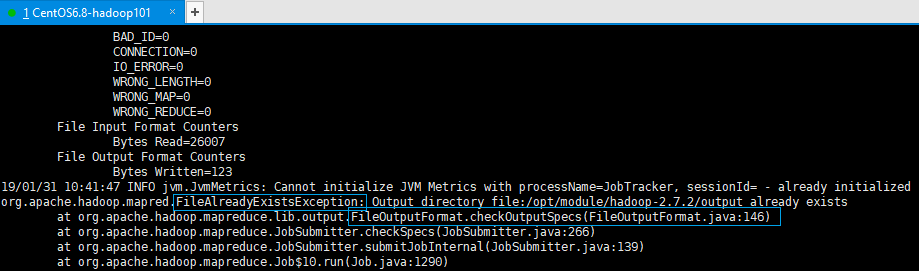
注意1:在大數據案例中,所有代碼必須有輸入路徑和輸出路徑。注意2:output目錄不能先存在,否則會報“文件夾已存在”異常。如下圖所示:
4.1.2 官方WordCount案例
1、創建在hadoop-2.7.2文件下面創建一個wcinput文件夾
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir wcinput
2、在wcinput文件下創建一個wc.input文件
[atguigu@hadoop101 hadoop-2.7.2]$ cd wcinput
[atguigu@hadoop101 wcinput]$ touch wc.input
3、編輯wc.input文件
[atguigu@hadoop101 wcinput]$ vim wc.input
在文件中輸入如下內容
hadoop yarn
hadoop mapreduce
atguigu
atguigu
保存退出 :wq
4、回到Hadoop目錄/opt/module/hadoop-2.7.2
5、執行程序
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput/ wcoutput/
6、查看結果
[atguigu@hadoop101 hadoop-2.7.2]$ cat wcoutput/part-r-00000
atguigu 2
doop 1
hadoop 1
mapreduce 1
yarn 1
4.2 偽分布式運行模式
4.2.1 啟動HDFS並運行MapReduce程序
1、分析
(1)配置集群
(2)啟動、測試集群增、刪、查
(3)執行WordCount案例
2、執行步驟
(1)配置集群
(a)配置:hadoop-env.sh
先Linux系統中獲取JDK的安裝路徑:
[atguigu@ hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
修改JAVA_HOME路徑:
export JAVA_HOME=/opt/module/jdk1.8.0_144
(b)配置:core-site.xml
[atguigu@hadoop101 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[atguigu@hadoop101 hadoop]$ vim core-site.xml
修改如下:
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop運行時產生文件的存儲目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
(c)配置:hdfs-site.xml
<!-- 指定HDFS副本的數量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
注意:默認是3個HDFS副本(3台服務器各備份1份,不是1台服務器備份3份)。
(2)啟動集群
(a)格式化NameNode(第一次啟動時格式化,以后就不要總格式化!)
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
(b)啟動NameNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
(c)啟動DataNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
(3)查看集群
(a)查看是否啟動成功
[atguigu@hadoop101 hadoop-2.7.2]$ jps
3090 DataNode
2995 NameNode
3161 Jps
注意:jps是JDK中的命令,不是Linux命令。不安裝JDK不能使用jps。
(b)web端查看HDFS文件系統
http://hadoop101:50070/dfshealth.html#tab-overview注意:如果不能查看,看如下帖子處理:
http://www.cnblogs.com/zlslch/p/6604189.html
(c)查看產生的logs日志說明:在企業中遇到Bug時,經常根據日志提示信息去分析問題、解決Bug。
當前目錄:/opt/module/hadoop-2.7.2/logs
[atguigu@hadoop101 logs]$ ls
hadoop-atguigu-datanode-hadoop.atguigu.com.log
hadoop-atguigu-datanode-hadoop.atguigu.com.out
hadoop-atguigu-namenode-hadoop.atguigu.com.log
hadoop-atguigu-namenode-hadoop.atguigu.com.out
SecurityAuth-root.audit
[atguigu@hadoop101 logs]# cat hadoop-atguigu-datanode-hadoop101.log
(d)思考:為什么不能一直格式化NameNode,格式化NameNode,要注意什么?
[atguigu@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/name/current/
[atguigu@hadoop101 current]$ cat VERSION
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
[atguigu@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/data/current/
[atguigu@hadoop101 current]$ cat VERSION
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
注意:格式化NameNode,會產生新的集群id,導致NameNode和DataNode的集群id不一致,集群找不到已往數據。所以,格式NameNode時,一定要先刪除data數據目錄和logs日志目錄,然后再格式化NameNode。
(4)操作集群
(a)在HDFS文件系統上創建一個input文件夾
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/atguigu/input/
(b)將測試文件內容上傳到文件系統上
[atguigu@hadoop101 hadoop-2.7.2]$bin/hdfs dfs -put wcinput/wc.input /user/atguigu/input/
(c)查看上傳的文件是否正確
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -ls /user/atguigu/input/
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/input/wc.input
(d)運行MapReduce程序
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input/ /user/atguigu/output/
(e)查看輸出結果
命令行查看:
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/output/p*
瀏覽器查看output文件,如下圖所示:

(f)將測試文件內容下載到本地
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -get /user/atguigu/output/part-r-00000 ./wcoutput/
(g)刪除輸出結果
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -rm -r /user/atguigu/output/
4.2.2 啟動YARN並運行MapReduce程序
1、分析
(1)配置集群在YARN上運行MR
(2)啟動、測試集群增、刪、查
(3)在YARN上執行WordCount案例
2、執行步驟
(1)配置集群
(a)配置yarn-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
(b)配置yarn-site.xml
<!-- Reducer獲取數據的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
(c)配置:mapred-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
(d)配置:對mapred-site.xml.template重新命名為mapred-site.xml
[atguigu@hadoop101 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[atguigu@hadoop101 hadoop]$ vim mapred-site.xml
<!-- 指定MR運行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(2)啟動集群
(a)啟動前必須保證NameNode和DataNode已經啟動
(b)啟動ResourceManager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
(c)啟動NodeManager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
(3)集群操作
(a)YARN的瀏覽器頁面查看,如下圖所示:
http://hadoop101:8088/cluster

(b)刪除文件系統上的output文件
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/atguigu/output/
(c)執行MapReduce程序
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input/ /user/atguigu/output/
(d)查看運行結果,如下圖所示:
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/output/*
運行結果:

4.2.3 配置歷史服務器
為了查看程序的歷史運行情況,需要配置一下歷史服務器。具體配置步驟如下:
1、配置mapred-site.xml
[atguigu@hadoop101 hadoop-2.7.2]$ vim etc/hadoop/mapred-site.xml
在該文件里面增加如下配置:
<!-- 歷史服務器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<!-- 歷史服務器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
2、啟動歷史服務器
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
3、查看歷史服務器是否啟動
[atguigu@hadoop101 hadoop-2.7.2]$ jps
4、查看JobHistory
http://hadoop101:19888/jobhistory
說明:該功能實際開發過程中需要打開。學習測試的時候不用打開,影響性能。
4.2.4 配置日志的聚集
日志聚集概念:應用運行完成以后,將程序運行日志信息上傳到HDFS系統上。
日志聚集功能好處:可以方便的查看到程序運行詳情,方便開發調試。
注意:開啟日志聚集功能,需要重新啟動NodeManager、ResourceManager和HistoryManager。
該功能實際開發過程中需要打開。學習測試的時候不用打開,影響性能。
開啟日志聚集功能具體步驟如下:
1、配置yarn-site.xml
[atguigu@hadoop101 hadoop]$ vim yarn-site.xml
在該文件里面增加如下配置:
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留時間設置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2、關閉NodeManager、ResourceManager和HistoryManager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop resourcemanager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver
3、啟動NodeManager、ResourceManager和HistoryManager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
4、刪除HDFS上已經存在的輸出文件
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/atguigu/output/
5、執行WordCount程序
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input/ /user/atguigu/output/
6、查看日志,如下圖所示:
http://hadoop101:19888/jobhistory
Job History
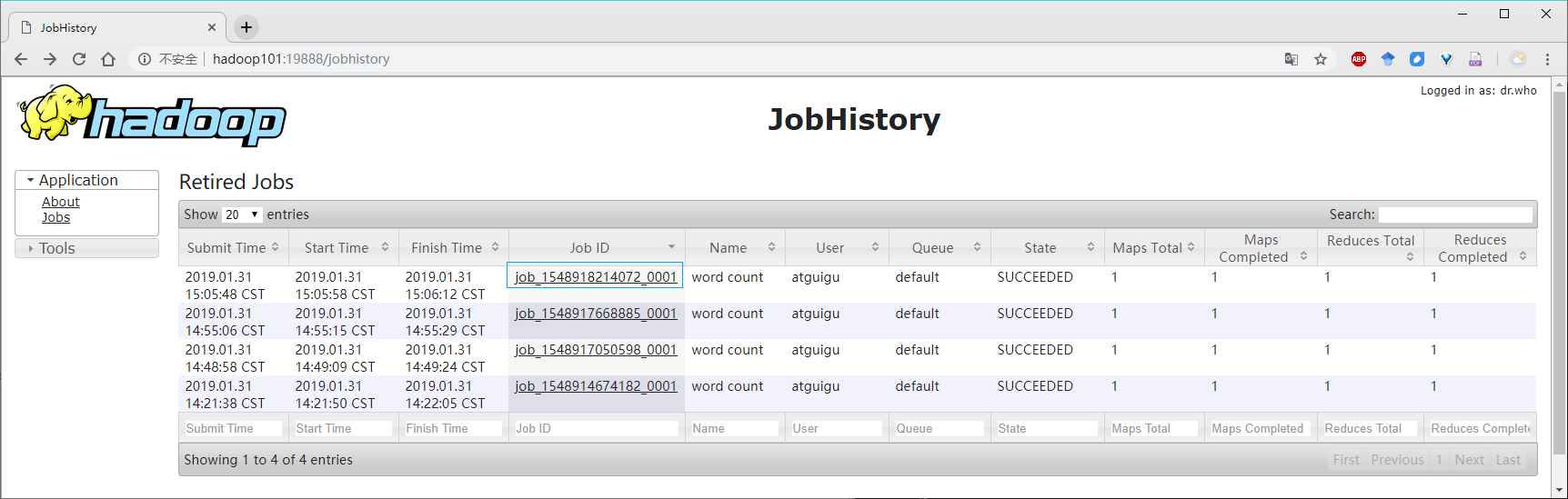
job運行情況
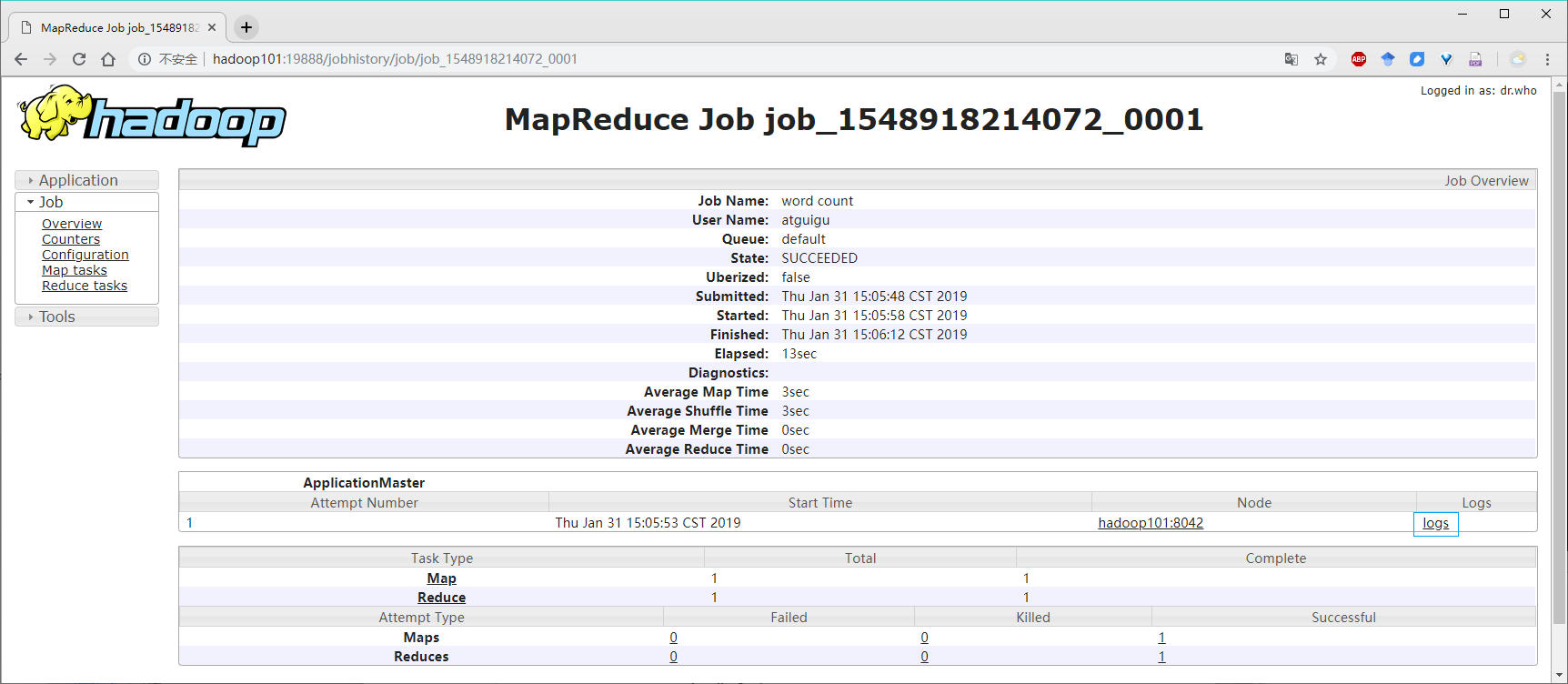
查看日志
4.2.5 配置文件說明
Hadoop配置文件分兩類:默認配置文件和自定義配置文件,只有用戶想修改某一默認配置值時,才需要修改自定義配置文件,更改相應屬性值。
(1)默認配置文件:

(2)自定義配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四個配置文件存放在$HADOOP_HOME/etc/hadoop這個路徑上,用戶可以根據項目需求重新進行修改配置。
自定義的配置文件的優先級高於默認的配置文件。
4.3 完全分布式運行模式(開發重點)
分析:
1)准備3台客戶機(永久關閉防火牆、設置靜態ip、設置主機名稱、配置主機名稱和ip地址映射)

2)安裝JDK
3)配置環境變量
4)安裝Hadoop
5)配置環境變量
6)配置集群
7)單點啟動
8)配置ssh
9)群起並測試集群
4.3.1 虛擬機准備
詳見3.1章節內容。
4.3.2 編寫集群分發腳本xsync
1、scp(secure copy)安全拷貝
(1)scp定義:
scp可以實現服務器與服務器之間的數據拷貝。(from server1 to server2)
(2)基本語法
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 遞歸 要拷貝的文件路徑/名稱 目的用戶@主機:目的路徑/名稱
(3)案例實操
(a)在hadoop101上,將hadoop101中/opt/module/目錄下的軟件拷貝到hadoop102上。
[atguigu@hadoop101 /]$ scp -r /opt/module/ root@hadoop102:/opt/module/
(b)在hadoop103上,將hadoop101中/opt/module/目錄下的軟件拷貝到hadoop103上。
[atguigu@hadoop103 opt]$sudo scp -r atguigu@hadoop101:/opt/module/ root@hadoop103:/opt/module/
(c)在hadoop103上,將hadoop101中/opt/module/目錄下的軟件拷貝到hadoop104上。
[atguigu@hadoop103 opt]$ scp -r atguigu@hadoop101:/opt/module/ root@hadoop104:/opt/module/
注意:拷貝過來的/opt/module/目錄,別忘了在hadoop102、hadoop103、hadoop104上修改所有文件的,所有者和所有者組。
sudo chown atguigu:atguigu -R /opt/module/
(d)將hadoop101中/etc/profile文件拷貝到hadoop102的/etc/profile上。
[atguigu@hadoop101 ~]$ sudo scp /etc/profile root@hadoop102:/etc/profile
(e)將hadoop101中/etc/profile文件拷貝到hadoop103的/etc/profile上。
[atguigu@hadoop101 ~]$ sudo scp /etc/profile root@hadoop103:/etc/profile
(f)將hadoop101中/etc/profile文件拷貝到hadoop104的/etc/profile上。
[atguigu@hadoop101 ~]$ sudo scp /etc/profile root@hadoop104:/etc/profile
注意:拷貝過來的配置文件別忘了source一下/etc/profile。
練習:我們將software軟件夾也拷貝過去並修改所有文件的,所有者和所有者組。
2、rsync 遠程同步工具
rsync主要用於備份和鏡像。具有速度快、避免復制相同內容和支持符號鏈接的優點。
rsync和scp區別:用rsync做文件的復制要比scp的速度快,rsync只對差異文件做更新。scp是把所有文件都復制過去。
(1)基本語法
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 選項參數 要拷貝的文件路徑/名稱 目的用戶@主機:目的路徑/名稱
選項參數說明:
選項 功能
-r 遞歸
-v 顯示復制過程
-l 拷貝符號連接
(2)案例實操
(a)把hadoop101機器上的/opt/software/目錄同步到hadoop102服務器的root用戶下的/opt/目錄
[atguigu@hadoop101 opt]$ rsync -rvl /opt/software/ root@hadoop102:/opt/software/
3、xsync 集群分發腳本
(1)需求:循環復制文件到所有節點的相同目錄下
(2)需求分析:
(a)rsync命令原始拷貝:
rsync -rvl /opt/module/ root@hadoop103:/opt/
(b)期望腳本:
xsync 要同步的文件名稱
(c)說明:在/home/atguigu/bin/這個目錄下存放的腳本,atguigu用戶可以在系統任何地方直接執行。
(3)腳本實現
(a)在/home/atguigu/目錄下創建bin目錄,並在bin目錄下創建文件xsync,文件內容如下:
[atguigu@hadoop102 ~]$ mkdir bin
[atguigu@hadoop102 ~]$ cd bin/
[atguigu@hadoop102 bin]$ touch xsync
[atguigu@hadoop102 bin]$ vim xsync
在該文件中編寫如下代碼:
#!/bin/bash
#1 獲取輸入參數個數,如果沒有參數,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 獲取文件名稱
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 獲取上級目錄到絕對路徑
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 獲取當前用戶名稱
user=`whoami`
#5 循環
for((host=103; host<105; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
(b)修改腳本 xsync 具有執行權限
[atguigu@hadoop102 bin]$ chmod 777 xsync
(c)調用腳本形式:xsync 文件名稱
[atguigu@hadoop102 bin]$ xsync /home/atguigu/bin/
注意:如果將xsync放到/home/atguigu/bin/目錄下仍然不能實現全局使用,可以將xsync移動到/usr/local/bin/目錄下。
4.3.3 集群配置
1、集群部署規划

2、配置集群
(1)核心配置文件
配置core-site.xml
[atguigu@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[atguigu@hadoop102 hadoop]$ vim core-site.xml
在該文件中編寫如下配置:
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!-- 指定Hadoop運行時產生文件的存儲目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
(2)HDFS配置文件
配置hadoop-env.sh
[atguigu@hadoop102 hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置hdfs-site.xml
[atguigu@hadoop102 hadoop]$ vim hdfs-site.xml
在該文件中編寫如下配置
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop輔助名稱節點主機配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
(3)YARN配置文件
配置yarn-env.sh
[atguigu@hadoop102 hadoop]$ vim yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置yarn-site.xml
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
在該文件中增加如下配置:
<!-- Reducer獲取數據的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
(4)MapReduce配置文件
配置mapred-env.sh
[atguigu@hadoop102 hadoop]$ vim mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置mapred-site.xml
[atguigu@hadoop102 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
在該文件中增加如下配置:
<!-- 指定MR運行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)slaves配置文件
配置slaves
[atguigu@hadoop102 hadoop]$ vim slaves
hadoop102
hadoop103
hadoop104
保存退出。
3、在集群上分發配置好的Hadoop配置文件
[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-2.7.2/
4、查看文件分發情況
[atguigu@hadoop103 hadoop]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
4.3.4 集群單點啟動
(0)格式NameNode時,一定要先刪除每一個服務器的data數據目錄和logs日志目錄,然后再格式化NameNode。
[atguigu@hadoop102 hadoop-2.7.2]$ rm -rf data/ logs/
[atguigu@hadoop103 hadoop-2.7.2]$ rm -rf data/ logs/
[atguigu@hadoop104 hadoop-2.7.2]$ rm -rf data/ logs/
(1)如果集群是第一次啟動,需要格式化NameNode
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
(2)在hadoop102上啟動NameNode
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode #或者
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop-daemon.sh start namenode #因為該命令是全局的
[atguigu@hadoop102 hadoop-2.7.2]$ jps
3461 NameNode
(3)在hadoop102、hadoop103以及hadoop104上分別啟動DataNode
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
[atguigu@hadoop102 hadoop-2.7.2]$ jps
3461 NameNode
3608 Jps
3561 DataNode
[atguigu@hadoop103 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
[atguigu@hadoop103 hadoop-2.7.2]$ jps
3190 DataNode
3279 Jps
[atguigu@hadoop104 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
[atguigu@hadoop104 hadoop-2.7.2]$ jps
3237 Jps
3163 DataNode
(4)思考:每次都一個一個節點啟動,如果節點數增加到1000個怎么辦?
早上來了開始一個一個節點啟動,到晚上下班剛好完成,下班?
4.3.5 SSH無密登錄配置
1、配置ssh
(1)基本語法
ssh 另一台電腦的ip地址
(2)ssh連接時出現Host key verification failed的解決方法
[atguigu@hadoop103 ~]$ ssh hadoop104
The authenticity of host 'hadoop104 (192.168.25.104)' can't be established.
RSA key fingerprint is 4d:6f:ae:ff:49:7d:f6:9a:8d:f8:05:0f:db:aa:85:fb.
Are you sure you want to continue connecting (yes/no)?
(3)解決方案如下:直接輸入yes
2、無密鑰配置
(1)免密登錄原理,如下圖所示:

(2)生成公鑰和私鑰:
[atguigu@hadoop102 .ssh]$ pwd
/home/atguigu/.ssh
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三個回車),就會生成兩個文件id_rsa(私鑰)、id_rsa.pub(公鑰)。
(3)將公鑰拷貝到要免密登錄的目標機器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
注意:
需要在hadoop102上采用root賬號,配置一下無密登錄到hadoop102、hadoop103、hadoop104。配置同上。
還需要在hadoop103上采用atguigu賬號,配置一下無密登錄到hadoop102、hadoop103、hadoop104服務器上(因為 yarn 的 ResourceManager 在 hadoop103 上)。配置同上。
3、.ssh文件夾下(~/.ssh)的文件功能解釋

4.3.6 群起集群
1、配置slaves
[root@hadoop102 hadoop]# pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[atguigu@hadoop102 hadoop]$ vim slaves
在該文件中增加如下內容:
hadoop102
hadoop103
hadoop104
注意:該文件中添加的內容結尾不允許有空格,文件中不允許有空行。
同步所有節點配置文件
[atguigu@hadoop102 hadoop]$ xsync slaves
2、啟動集群
(1)如果集群是第一次啟動,需要格式化NameNode
(注意:格式化之前,一定要先停止上次啟動的所有namenode和datanode進程,然后再刪除data和log數據)
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
(2)啟動HDFS
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop102 hadoop-2.7.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
[atguigu@hadoop103 hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
[atguigu@hadoop104 hadoop-2.7.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
(3)啟動YARN
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台機器,不能在NameNode上啟動YARN,應該在ResouceManager所在的機器上啟動YARN。
(4)Web端查看SecondaryNameNode
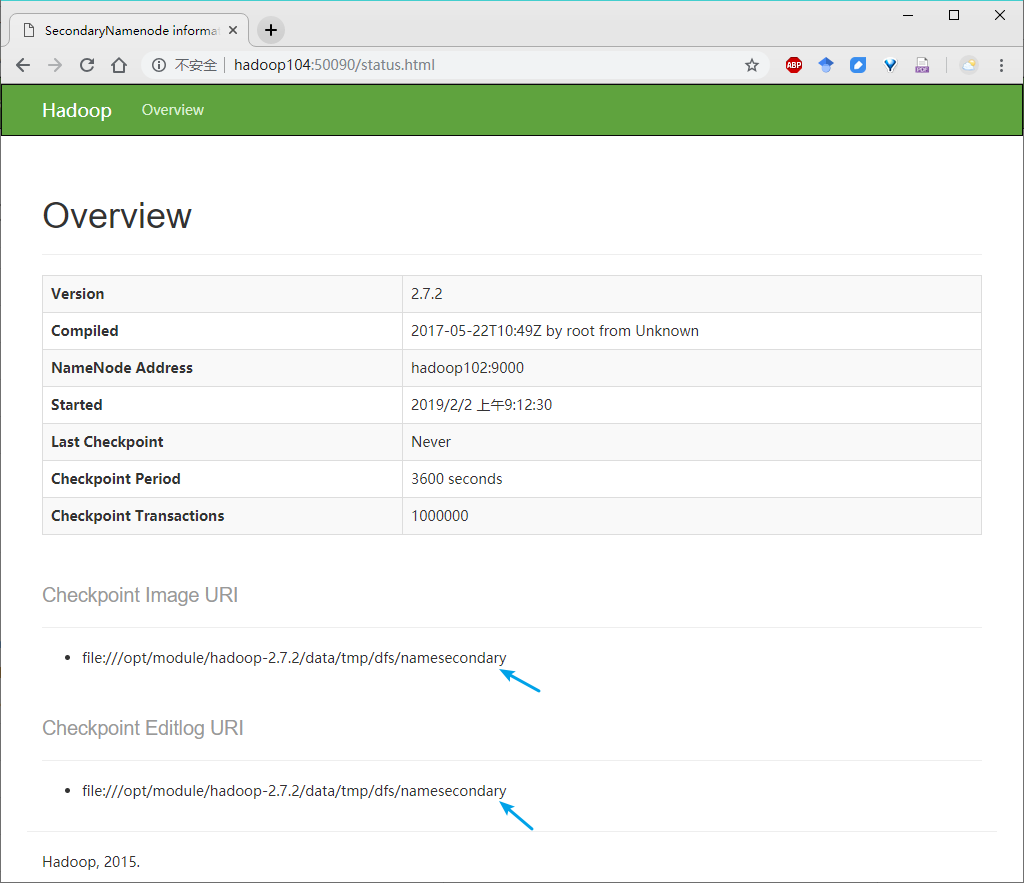
(a)瀏覽器中輸入:http://hadoop104:50090/status.html
(b)查看SecondaryNameNode信息,如下圖所示。
3、集群基本測試
(1)上傳文件到集群
上傳小文件
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -mkdir -p /user/atguigu/input/
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -put wcinput/wc.input /user/atguigu/input/
上傳大文件
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop dfs -put /opt/software/hadoop-2.7.2.tar.gz /user/atguigu/input/
(2)上傳文件后查看文件存放在什么位置
(a)查看HDFS文件存儲路徑
[atguigu@hadoop102 subdir0]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-938951106-192.168.25.102-1549038116413/current/finalized/subdir0/subdir0
(b)查看HDFS在磁盤存儲文件內容
[atguigu@hadoop102 subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
atguigu
atguigu
(3)拼接
-rw-rw-r--. 1 atguigu atguigu 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r--. 1 atguigu atguigu 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r--. 1 atguigu atguigu 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r--. 1 atguigu atguigu 495635 5月 23 16:01 blk_1073741837_1013.meta
[atguigu@hadoop102 subdir0]$ cat blk_1073741836 >> tmp.file
[atguigu@hadoop102 subdir0]$ cat blk_1073741837 >> tmp.file
[atguigu@hadoop102 subdir0]$ tar -zxvf tmp.file
(4)下載
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop dfs -get /user/atguigu/input/hadoop-2.7.2.tar.gz ./
4.3.7 集群啟動/停止方式總結
1、各個服務組件逐一啟動/停止
(1)分別啟動/停止HDFS組件
hadoop-daemon.sh start/stop namenode/datanode/secondarynamenode
(2)啟動/停止YARN
yarn-daemon.sh start/stop resourcemanager/nodemanager
2、各個模塊分開啟動/停止(配置ssh是前提)常用
(1)整體啟動/停止HDFS
start-dfs.sh / stop-dfs.sh
(2)整體啟動/停止YARN
start-yarn.sh / stop-yarn.sh
4.3.8 集群時間同步
時間同步的方式:找一個機器,作為時間服務器,所有的機器與這台集群時間進行定時的同步,比如,每隔十分鍾,同步一次時間。
集群時間同步過程:

配置時間同步具體實操:
1、時間服務器配置(必須root用戶)
(1)檢查ntp是否安裝
[root@hadoop102 桌面]# rpm -qa | grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.6p5-10.el6.centos.x86_64
(2)修改ntp配置文件
[root@hadoop102 桌面]# vim /etc/ntp.conf
修改內容如下:
a)修改1(授權192.168.25.0-192.168.25.255網段上的所有機器可以從這台機器上查詢和同步時間)
將
# restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap 修改為
restrict 192.168.25.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域網中,不使用其他互聯網上的時間)
將
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst 修改為
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(當該節點丟失網絡連接,依然可以采用本地時間作為時間服務器為集群中的其他節點提供時間同步)
添加內容如下:
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改 /etc/sysconfig/ntpd 文件
[root@hadoop102 桌面]# vim /etc/sysconfig/ntpd
增加內容如下(讓硬件時間與系統時間一起同步)
SYNC_HWCLOCK=yes
(4)重新啟動ntpd服務
[root@hadoop102 桌面]# service ntpd status
ntpd 已停
[root@hadoop102 桌面]# service ntpd start
正在啟動 ntpd: [確定]
[root@hadoop102 ~]# service ntpd status
ntpd (pid 3321) 正在運行...
(5)設置ntpd服務開機啟動(在企業開發中需要打開)
[root@hadoop102 桌面]# chkconfig ntpd on
2、其他機器配置(必須root用戶)
(1)在其他機器配置10分鍾與時間服務器同步一次
[root@hadoop103 桌面]# crontab -e
編寫定時任務如下:
*/10 * * * * /usr/sbin/ntpdate hadoop102
(2)修改任意機器時間
[root@hadoop103 桌面]# date -s "2017-9-11 11:11:11"
(3)十分鍾后查看機器是否與時間服務器同步
[root@hadoop103 桌面]# date
說明:測試的時候可以將10分鍾調整為1分鍾,節省時間。
第5章 Hadoop編譯源碼(面試重點)
為什么要編譯源碼包呢?
答:從官網默認下載的tar.gz包是32位的,而我們的電腦是64位的。所以要將32位的ar.gz包編譯成64位的。
5.1 前期准備工作
0、干凈的虛擬機
先准備一台干凈的虛擬機(已配置好靜態ip、主機名、永久關閉防火牆、創建一個用戶並配置該用戶具有root權限),內存建議4G以上,越大越好。這樣能大大節省時間。
1、CentOS聯網
配置CentOS能連接外網。Linux虛擬機 ping www.baidu.com 是暢通的。
注意:采用root角色編譯,減少文件夾權限出現問題。
2、jar包准備(hadoop源碼、JDK8、maven、ant、protobuf)
(1)hadoop-2.7.2-src.tar.gz
(2)jdk-8u144-linux-x64.tar.gz
(3)apache-ant-1.9.9-bin.tar.gz(build工具,打包用的)
(4)apache-maven-3.0.5-bin.tar.gz
(5)protobuf-2.5.0.tar.gz(序列化的框架)
5.2 jar包安裝
注意:所有操作必須在root用戶下完成。
1、JDK解壓、配置環境變量JAVA_HOME和PATH,驗證java -version
(如下都需要驗證是否配置成功)
[root@hadoop105 software]# pwd
/opt/software
[root@hadoop101 software] # tar -zxf jdk-8u144-linux-x64.tar.gz -C /opt/module/
[root@hadoop101 software]# vim /etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
[root@hadoop101 software]# source /etc/profile
驗證命令:java -version

2、Maven解壓、配置MAVEN_HOME和PATH
[root@hadoop101 software]# tar -zxvf apache-maven-3.0.5-bin.tar.gz -C /opt/module/
[root@hadoop105 apache-maven-3.0.5]# pwd
/opt/module/apache-maven-3.0.5
[root@hadoop101 apache-maven-3.0.5]# vim conf/settings.xml
<mirrors>
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
|
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
-->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
[root@hadoop101 apache-maven-3.0.5]# vim /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/opt/module/apache-maven-3.0.5
export PATH=$PATH:$MAVEN_HOME/bin
[root@hadoop101 software]# source /etc/profile
驗證命令:mvn -version

3、ant解壓、配置ANT _HOME和PATH
[root@hadoop101 software]# tar -zxvf apache-ant-1.9.9-bin.tar.gz -C /opt/module/
[root@hadoop105 apache-ant-1.9.9]# pwd
/opt/module/apache-ant-1.9.9
[root@hadoop101 apache-ant-1.9.9]# vim /etc/profile
#ANT_HOME
export ANT_HOME=/opt/module/apache-ant-1.9.9
export PATH=$PATH:$ANT_HOME/bin
[root@hadoop101 software]# source /etc/profile
驗證命令:ant -version

4、安裝 glibc-headers 和 g++ 命令如下
[root@hadoop101 apache-ant-1.9.9]# yum install glibc-headers
[root@hadoop101 apache-ant-1.9.9]# yum install gcc-c++
5、安裝make和cmake
[root@hadoop101 apache-ant-1.9.9]# yum install make
[root@hadoop101 apache-ant-1.9.9]# yum install cmake
6、解壓protobuf,進入到解壓后protobuf主目錄,/opt/module/protobuf-2.5.0,然后相繼執行命令
[root@hadoop101 software]# tar -zxvf protobuf-2.5.0.tar.gz -C /opt/module/
[root@hadoop101 opt]# cd /opt/module/protobuf-2.5.0/
[root@hadoop105 protobuf-2.5.0]# pwd
/opt/module/protobuf-2.5.0
[root@hadoop101 protobuf-2.5.0]# ./configure
[root@hadoop101 protobuf-2.5.0]# make
[root@hadoop101 protobuf-2.5.0]# make check
[root@hadoop101 protobuf-2.5.0]# make install
[root@hadoop101 protobuf-2.5.0]# ldconfig
[root@hadoop101 hadoop-dist]# vim /etc/profile
#LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/opt/module/protobuf-2.5.0
export PATH=$PATH:$LD_LIBRARY_PATH
[root@hadoop101 software]# source /etc/profile
驗證命令:protoc --version

7、安裝openssl庫
[root@hadoop101 software]# yum install openssl-devel
8、安裝 ncurses-devel庫
[root@hadoop101 software]# yum install ncurses-devel
到此,編譯工具安裝基本完成。
5.3 編譯源碼
1、解壓源碼到/opt/目錄
[root@hadoop101 software]# tar -zxvf hadoop-2.7.2-src.tar.gz -C /opt/
2、進入到hadoop源碼主目錄
[root@hadoop101 hadoop-2.7.2-src]# pwd
/opt/hadoop-2.7.2-src
3、通過maven執行編譯命令
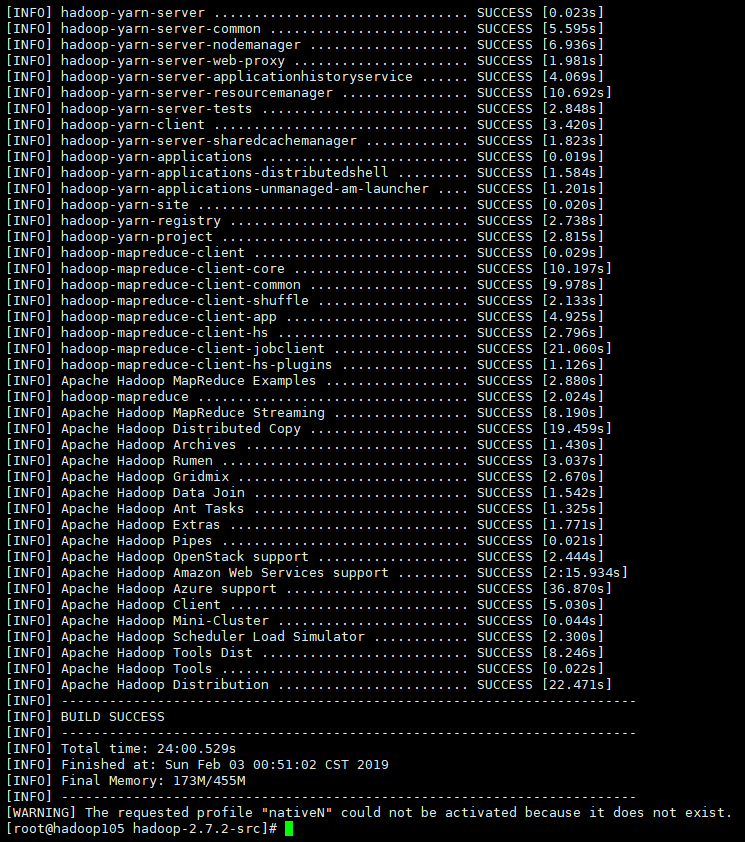
[root@hadoop101 hadoop-2.7.2-src]# mvn package -Pdist,native -DskipTests -Dtar
等待時間30分鍾左右,最終成功是全部SUCCESS,如下圖所示。
4、成功的64位hadoop包在/opt/hadoop-2.7.2-src/hadoop-dist/target/下
[root@hadoop101 target]# pwd
/opt/hadoop-2.7.2-src/hadoop-dist/target
如下圖所示:

5、編譯源碼過程中常見的問題及解決方案
(1)MAVEN install時候JVM內存溢出
處理方式:在環境配置文件和maven的執行文件均可調整MAVEN_OPT的heap大小。
詳情查閱MAVEN編譯 JVM調優問題,如:http://outofmemory.cn/code-snippet/12652/maven-outofmemoryerror-method
(2)編譯期間maven報錯。可能網絡阻塞問題導致依賴庫下載不完整導致,多次執行命令(一次通過比較難):
[root@hadoop101 hadoop-2.7.2-src]# mvn package -Pdist,nativeN -DskipTests -Dtar
(3)報ant、protobuf等錯誤,插件下載未完整或者插件版本問題,最開始鏈接有較多特殊情況,同時推薦
2.7.0版本的問題匯總帖子:http://www.tuicool.com/articles/IBn63qf
第6章 常見錯誤及解決方案
1)防火牆沒關閉、或者沒有啟動YARN
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.25.108:8032
2)主機名稱配置錯誤
3)IP地址配置錯誤
4)ssh沒有配置好
5)root用戶和atguigu兩個用戶啟動集群不統一
6)配置文件修改不細心
7)未編譯源碼
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/05/22 15:38:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
8)不識別主機名稱
java.net.UnknownHostException: hadoop102: hadoop102
at java.net.InetAddress.getLocalHost(InetAddress.java:1475)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
解決辦法:
(1)在/etc/hosts文件中添加192.168.25.102 hadoop102
(2)主機名稱不要起hadoop、hadoop000等特殊名稱
9)DataNode和NameNode進程同時只能工作一個
10)執行命令不生效,粘貼word中命令時,遇到-和長–沒區分開。導致命令失效
解決辦法:盡量不要粘貼word中代碼。
11)jps發現進程已經沒有,但是重新啟動集群,提示進程已經開啟。原因是在linux的根目錄下/tmp目錄中存在啟動的進程臨時文件,將集群相關進程刪除掉,再重新啟動集群。
12)jps不生效
原因:全局變量hadoop java沒有生效。解決辦法:需要source /etc/profile文件。
13)8088端口連接不上
[atguigu@hadoop102 桌面]$ cat /etc/hosts
注釋掉如下代碼
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6