完整代碼實現及訓練與測試數據:click me
一、任務描述
自然語言通順與否的判定,即給定一個句子,要求判定所給的句子是否通順。
二、問題探索與分析
拿到這個問題便開始思索用什么方法來解決比較合適。在看了一些錯誤的句子之后,給我的第一直覺就是某些類型的詞不應該拼接在一起,比如動詞接動詞(e.g.我打開聽見)這種情況基本不會出現在我們的用語中。於是就有了第一個idea基於規則來解決這個問題。但是發現很難建立完善的語言規則也缺乏相關的語言學知識,實現這么完整的一套規則也不簡單,因此就放棄了基於規則來實現,但還是想抓住某些類型的詞互斥的特性,就想到了N-Gram,但是這里的N-Gram不是基於詞來做,而是基於詞的詞性來做。基於詞來做參數量巨大,需要非常完善且高質量的語料庫,而詞的詞性種類數目很小,基於詞性來做就不會有基於詞的困擾,而且基於詞性來做直覺上更能貼合想到的這個idea。除了這個naive的idea之外,后面還有嘗試用深度學習來學習句子通順與否的特征,但是難點在於特征工程怎么做才能學習到句子不通順的特征。下面我會詳細說明我的具體實現。
三、代碼設計與實現
3.1 基於詞性的N-Gram
環境:
python 3.6.7
pyltp 0.2.1(匹配的ltp mode 3.4.0)
numpy 1.15.4
-
pyltp用於分詞和詞性標注,首先加載分詞和詞性標注模型
from pyltp import Segmentor from pyltp import Postagger seg = Segmentor() seg.load(os.path.join('../input/ltp_data_v3.4.0', 'cws.model')) pos = Postagger() pos.load(os.path.join('../input/ltp_data_v3.4.0', 'pos.model')) -
加載訓練數據,並對數據進行分詞和詞性標注,在句首句尾分別加上<s>和</s>作為句子開始和結束的標記
train_sent = [] trainid = [] train_sent_map = {} #[id:[ngram value, label]] with open('../input/train.txt', 'r') as trainf: for line in trainf: if len(line.strip()) != 0: items = line.strip().split('\t') tags = ['<s>'] for tag in pos.postag(seg.segment(items[1])): tags.append(tag) tags.append('</s>') train_sent.append(tags) trainid.append(int(items[0])) train_sent_map[trainid[-1]] = [0.0, int(items[2])] -
測試數據的加載方式與訓練數據一致不再贅述,接下來就是對訓練數據中標簽為0的數據進行1gram和2grams的詞性頻率計數
train_1gram_freq = {} train_2grams_freq = {} for sent in test_sent: train_1gram_freq[sent[0]] = 1 for j in range(1, len(sent)): train_1gram_freq[sent[j]] = 1 train_2grams_freq[' '.join(sent[j-1:j+1])] = 1e-100 for i in range(len(trainid)): if train_sent_map[trainid[i]][1] == 0: sent = train_sent[i] train_1gram_freq[sent[0]] = 0 for j in range(1, len(sent)): train_1gram_freq[sent[j]] = 0 train_2grams_freq[' '.join(sent[j-1:j+1])] = 0 # 預處理訓練集0標記的正確句子 for i in range(len(trainid)): if train_sent_map[trainid[i]][1] == 0: sent = train_sent[i] train_1gram_freq[sent[0]] += 1 for j in range(1, len(sent)): train_1gram_freq[sent[j]] += 1 train_2grams_freq[' '.join(sent[j-1:j+1])] += 1由於測試數據中可能包含訓練數據中未包含的詞性組合,用python的dict存儲詞性到頻度的映射,在對測試集中句子的N-Gram概率進行計算時會報KeyError的錯誤。為了解決這個問題,就有了上面看起來似乎有點冗余的代碼。先將測試集中1gram和2grams的詞性寫到dict中,這樣就至少保證了不會出現KeyError的錯誤。然后將訓練集中1gram和2grams的詞性寫到dict中,覆蓋了測試集寫入的相同的key,再進行頻度計數。對於只在測試集中出現的key還保留着原來的值,這里對測試集中的2grams組合賦值為1e-100是為了在計算2-Grams模型概率值時突顯出未在訓練集中出現的特征,從而能夠從測試集中辨識出這些異常的句子。
-
由於句子長短不一,計算出來的句子的概率差距甚遠,所以需要對相同長度的句子進行一個聚類,然后用計算出來的概率值除以句子字長,這樣才能保證句子的概率基本保持在一個較小的范圍內,設置的閾值才能較好地將不同類型句子區分開來。
# 計算句子基於2-grams的概率值 def compute_2grams_prob(sent, train_1gram_freq, train_2grams_freq): p = 0.0 for j in range(1, len(sent)): p += math.log(train_2grams_freq[' '.join(sent[j-1:j+1])] * 1.0 \ / train_1gram_freq[sent[j-1]]) return p / len(sent) # 計算訓練集中句子的概率值 for i, sent in enumerate(train_sent): if train_sent_map[trainid[i]][1] == 0: train_sent_map[trainid[i]][0] = compute_2grams_prob(sent, train_1gram_freq, train_2grams_freq) # 對不同長度的句子進行聚類,然后計算等長句子類的平均概率值 train_samesize_avgprob = {} for i, sent in enumerate(train_sent): train_samesize_avgprob[len(sent)] = [0.0, 0] for i, sent in enumerate(train_sent): train_samesize_avgprob[len(sent)][0] += train_sent_map[trainid[i]][0] train_samesize_avgprob[len(sent)][1] += 1 for key in train_samesize_avgprob.keys(): train_samesize_avgprob[key][0] = train_samesize_avgprob[key][0] / train_samesize_avgprob[key][1] -
統計訓練集中2-Grams概率的最小值,最大值,以及平均值,其中平均值將被用作判斷句子好壞的閾值
thresh = {'min0':0.0, 'max0':-np.inf, 'avg0':0.0} c0 = 0 for id in trainid: if train_sent_map[id][1] == 0: if train_sent_map[id][0] < thresh['min0']: thresh['min0'] = train_sent_map[id][0] if train_sent_map[id][0] > thresh['max0']: thresh['max0'] = train_sent_map[id][0] thresh['avg0'] += train_sent_map[id][0] c0 += 1 thresh['avg0'] /= c0 -
接着計算測試集中每個句子基於2-Grams的除以字長的概率值,然后與由訓練集計算得到的與其等字長類的平均概率值進行對比。如果訓練集中沒有找到與測試集中某個句子的等長的句子,則測試集中該句子概率值直接去總體訓練樣本計算得到的概率值進行對比。
thresh_tx = {'min':0.0, 'max':-np.inf, 'avg':0.0} TX = [] with open('../output/ngramfluent_postag_pyltp.txt', 'w') as resf: for sent in test_sent: TX.append([compute_2grams_prob(sent, train_1gram_freq, train_2grams_freq)]) for i in range(len(TX)): if thresh_tx['min'] > TX[i][0]: thresh_tx['min'] = TX[i][0] if thresh_tx['max'] < TX[i][0]: thresh_tx['max'] = TX[i][0] thresh_tx['avg'] += TX[i][0] thresh_tx['avg'] /= len(TX) print('測試集:', thresh_tx) for i in range(len(testid)): if len(test_sent[i]) in train_samesize_avgprob.keys(): if TX[i][0] >= train_samesize_avgprob[len(test_sent[i])][0]: resf.write(testid[i] + '\t0\n') else: resf.write(testid[i] + '\t1\n') else: if TX[i][0] >= thresh['avg'] - 0.1: resf.write(testid[i] + '\t0\n') else: resf.write(testid[i] + '\t1\n')thresh['avg']-0.1之后再比較是因為訓練集基於2-Grams計算的概率平均值與測試集基於2-Grams計算的概率平均值相比有一點小小上下波動,減0.1相當於一個微調的優化操作。
-
以上便是基於詞性的2-Grams方法的具體實現,最后提交的結果65%的樣子,同時我也使用了直接基於詞的2-Grams方法,但是提交的結果沒有基於詞性的方法好,應該是語料庫內容不足以支撐,然后我又嘗試將wiki中文數據集內容提取出來並划分成句子作為正類輸入,但是結果還是沒有基於詞性的好,可能是wiki數據集太大,而我處理得很粗糙,數據清洗工作不到位導致的。
3.2 深度學習學習句法特征
環境:
python 3.6.7
bert-serving-server
bert-serving-client
sklearn
numpy
深度學習我沒有系統地學過,Google最近提出的bert很火,於是就想嘗試使用bert來基於句子做特征工程,學習病句特征,然后再用SVM做一個分類。都是調用的接口,代碼很少,但是最后效果卻很差。可能是bert參數沒調好,但是目前對bert了解甚少不知該怎么調,而時間有限所以也就沒進一步深入了。后續有時間學習一下bert再回過頭來優化模型。
四、性能分析
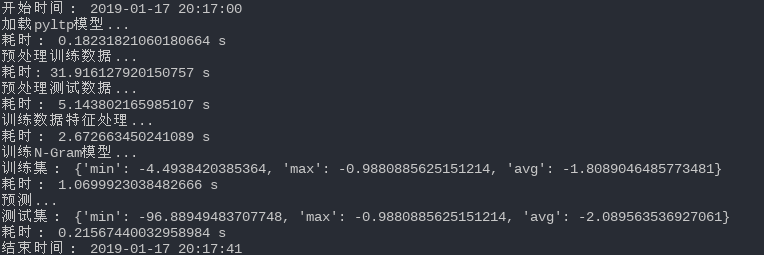
使用基於統計的方法做計算復雜度很低,除去分詞模塊,2-Grams模型的計算復雜度為O(樣本數*句子平均字長),所以代碼運行起來很快,下面是代碼運行截圖:
五、遇到的問題及解決方案
-
對於未包含在訓練集中的測試集2-Grams,在計算概率值時怎么做平滑處理?
具體解決方案在第三節中有詳細描述。
-
不同句長的句子基於2-Grams計算出來的log概率值相差甚遠,這給設置分類閾值帶來了麻煩,該如何解決?
計算得到的概率值除以句子字長,具體實現時還加入了等句長的聚類,詳細解決方案在第三節中有描述。
-
概率比對閾值設置多大才能最准確地進行分類?
這個問題我目前也沒有很好的解決方法,只能多試幾個看看實際的結果。
六、未來改進
估計使用2-Grams方法的瓶頸不到70%,當下深度學習在NLP中應用很火熱,未來可以深入學習以下深度學習在NLP中的應用然后再回過頭來用深度學習的視角來重新看待這個問題。