1. 語言模型
2. Attention Is All You Need(Transformer)算法原理解析
3. ELMo算法原理解析
4. OpenAI GPT算法原理解析
5. BERT算法原理解析
6. 從Encoder-Decoder(Seq2Seq)理解Attention的本質
7. Transformer-XL原理介紹
1. 前言
谷歌在2017年發表了一篇論文名字教《Attention Is All You Need》,提出了一個只基於attention的結構來處理序列模型相關的問題,比如機器翻譯。傳統的神經機器翻譯大都是利用RNN或者CNN來作為encoder-decoder的模型基礎,而谷歌最新的只基於Attention的Transformer模型摒棄了固有的定式,並沒有用任何CNN或者RNN的結構。該模型可以高度並行地工作,所以在提升翻譯性能的同時訓練速度也特別快。
2. Transformer模型結構
Transformer的主體結構圖:
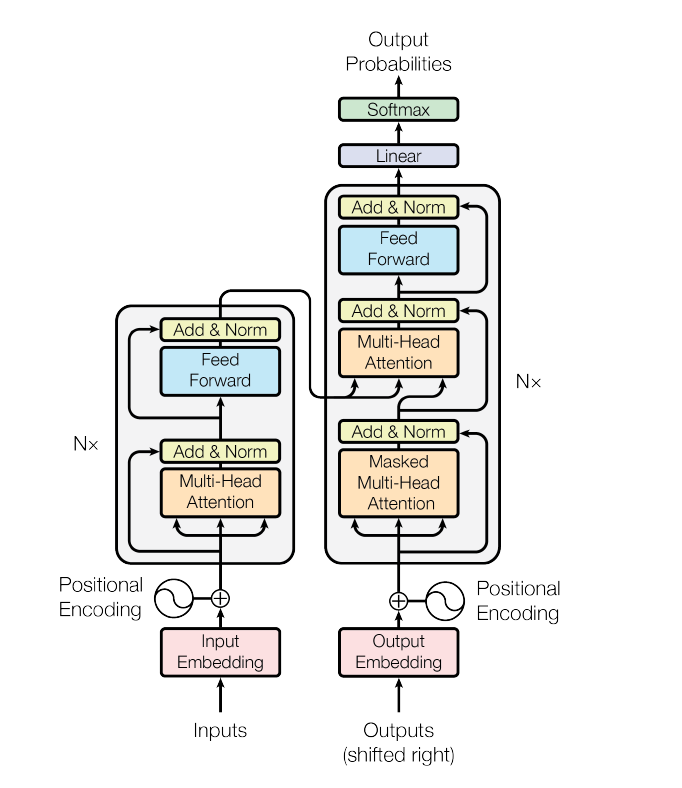
2.1 Transformer的編碼器解碼器
模型分為編碼器和解碼器兩個部分。
- 編碼器由6個相同的層堆疊在一起,每一層又有兩個支層。第一個支層是一個多頭的自注意機制,第二個支層是一個簡單的全連接前饋網絡。在兩個支層外面都添加了一個residual的連接,然后進行了layer nomalization的操作。模型所有的支層以及embedding層的輸出維度都是\(d_{model}\)。
- 解碼器也是堆疊了六個相同的層。不過每層除了編碼器中那兩個支層,解碼器還加入了第三個支層,如圖中所示同樣也用了residual以及layer normalization。具體的細節后面再講。
2.2 輸入層
編碼器和解碼器的輸入就是利用學習好的embeddings將tokens(一般應該是詞或者字符)轉化為d維向量。對解碼器來說,利用線性變換以及softmax函數將解碼的輸出轉化為一個預測下一個token的概率。
2.3 位置向量
由於模型沒有任何循環或者卷積,為了使用序列的順序信息,需要將tokens的相對以及絕對位置信息注入到模型中去。論文在輸入embeddings的基礎上加了一個“位置編碼”。位置編碼和embeddings由同樣的維度都是\(d_{model}\)所以兩者可以直接相加。有很多位置編碼的選擇,既有學習到的也有固定不變的。
2.4 Attention模型
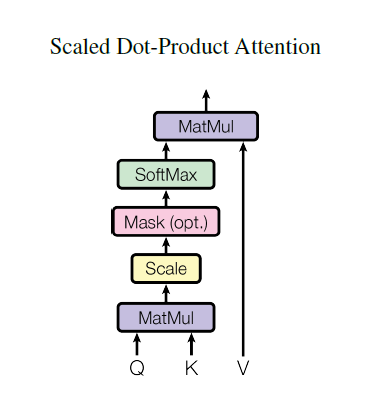
2.4.1 Scaled attention
論文中用的attention是基本的點乘的方式,就是多了一個所謂的scale。輸入包括維度為\(d_k\)的queries以及keys,還有維度為\(d_v\)的values。計算query和所有keys的點乘,然后每個都除以\(\sqrt{d_k}\)(這個操作就是所謂的Scaled)。之后利用一個softmax函數來獲取values的權重。
實際操作中,attention函數是在一些列queries上同時進行的,將這些queries並在一起形成一個矩陣\(Q\)同時keys以及values也並在一起形成了矩陣\(K\)以及\(V\)。則attention的輸出矩陣可以按照下述公式計算:
2.4.2 Multi-Head Attention
本文結構中的Attention並不是簡簡單單將一個點乘的attention應用進去。作者發現先對queries,keys以及values進行\(h\)次不同的線性映射效果特別好。學習到的線性映射分別映射到\(d_k\),\(d_k\)以及\(d_v\)維。分別對每一個映射之后的得到的queries,keys以及values進行attention函數的並行操作,生成\(dv\)維的output值。具體結構和公式如下。

2.4.3 模型中的attention
Transformer以三種不同的方式使用了多頭attention。
- 在encoder-decoder的attention層,queries來自於之前的decoder層,而keys和values都來自於encoder的輸出。這個類似於很多已經提出的seq2seq模型所使用的attention機制。
- 在encoder含有self-attention層。在一個self-attention層中,所有的keys,values以及queries都來自於同一個地方,本例中即encoder之前一層的的輸出。
- 類似的,decoder中的self-attention層也是一樣。不同的是在scaled點乘attention操作中加了一個mask的操作,這個操作是保證softmax操作之后不會將非法的values連到attention中。
2.4.4 Feed Foreword
每層由兩個支層,attention層就是其中一個,而attention之后的另一個支層就是一個前饋的網絡。公式描述如下。
3. 總結
模型的整體框架基本介紹完了,其最重要的創新應該就是Self-Attention和Multi-Head Attention的架構。在摒棄傳統CNN和RNN的情況下,還能提高表現,降低訓練時間。Transformer用於機器翻譯任務,表現極好,可並行化,並且大大減少訓練時間。並且也給我們開拓了一個思路,在處理問題時可以增加一種結構的選擇。