Summary
本文提出超越神經架構搜索(NAS)的高效神經架構搜索(ENAS),這是一種經濟的自動化模型設計方法,通過強制所有子模型共享權重從而提升了NAS的效率,克服了NAS算力成本巨大且耗時的缺陷,GPU運算時間縮短了1000倍以上。在Penn Treebank數據集上,ENAS實現了55.8的測試困惑度;在CIFAR-10數據集上,其測試誤差達到了2.89%,與NASNet不相上下(2.65%的測試誤差)
Research Objective 作者的研究目標
設計一種快速有效且耗費資源低的用於自動化網絡模型設計的方法。主要貢獻是基於NAS方法提升計算效率,使得各個子網絡模型共享權重,從而避免低效率的從頭訓練。
Problem Statement 問題陳述,要解決什么問題?
本文提出的方法是對NAS的改進。NAS存在的問題是它的計算瓶頸,因為NAS是每次將一個子網絡訓練到收斂,之后得到相應的reward,再將這個reward反饋給RNN controller。但是在下一輪訓練子網絡時,是從頭開始訓練,而上一輪的子網絡的訓練結果並沒有利用起來。
另外NAS雖然在每個節點上的operation設計靈活度較高,但是固定了網絡的拓撲結構為二叉樹。所以ENAS對於網絡拓撲結構的設計做了改進,有了更高的靈活性。
Method(s) 解決問題的方法/算法
ENAS算法核心
回顧NAS,可以知道其本質是在一個大的搜索圖中找到合適的子圖作為模型,也可以理解為使用單個有向無環圖(single directed acyclic graph, DAG)來表示NAS的搜索空間。
基於此,ENAS的DAG其實就是NAS搜索空間中所有可能的子模型的疊加。
下圖給出了一個通用的DAG示例

如圖示,各個節點表示本地運算,邊表示信息的流動方向。圖中的6個節點包含有多種單向DAG,而紅色線標出的DAG則是所選擇的的子圖。
以該子圖為例,節點1表示輸入,而節點3和節點6因為是端節點,所以作為輸出,一般是將而二者合並求均值后輸出。
在討論ENAS的搜索空間之前,需要介紹的是ENAS的測試數據集分別是CIFAR-10和Penn Treebank,前者需要通過ENAS生成CNN網絡,后者則需要生成RNN網絡。
所以下面會從生成RNN和生成CNN兩個方面來介紹ENAS算法。
1.Design Recurrent Cells
本小節介紹如何從特定的DAG和controller中設計一個遞歸神經網絡的cell(Section 2.1)?
首先假設共有\(N\)個節點,ENAS的controller其實就是一個RNN結構,它用於決定
- 哪條邊需要激活
- DAG中每個節點需要執行什么樣的計算
下圖以\(N=4\)為例子展示了如何生成RNN。

假設\(x[t]\)為輸入,\(h[t-1]\)表示上一個時刻的輸出狀態。
- 節點1:由圖可知,controller在節點1上選擇的操作是tanh運算,所以有\(h_1=tanh(X_t·W^{(X)}+h_{t-1}·W_1^{(h)})\)
- 節點2:同理有\(h_2 = ReLU(h_1·W_{2,1}^{(h)})\)
- 節點3:\(h_3 = ReLU(h_2·W_{3,2}^{(h)})\)
- 節點4:\(h_4 = ReLU(h_1·W_{4,1}^{(h)})\)
- 節點3和節點4因為不是其他節點的輸入,所以二者的平均值作為輸出,即\(h_t=\frac{h_3+h_4}{2}\)
由上面的例子可以看到對於每一組節點\((node_i,node_j),i<j\),都會有對應的權重矩陣\(W_{j,i}^{(h)}\)。因此在ENAS中,所有的recurrent cells其實是在搜索空間中共享這樣一組權重的。
2.1 Design Convolutional Networks
本小節解釋如何設計卷積結構的搜索空間
回顧上面的Recurrent Cell的設計,我們知道controller RNN在每一個節點會做如下兩個決定:a)該節點需要連接前面哪一個節點 b)使用何種激活函數。
而在卷積模型的搜索空間中,controller RNN也會做如下兩個覺得:a)該節點需要連接前面哪一個節點 b)使用何種計算操作。
在卷積模型中,(a)決定 (連接哪一個節點) 其實就是skip connections。(b)決定一共有6種選擇,分別是3*3和5*5大小的卷積核、3*3和5*5大小的深度可分離卷積核,3*3大小的最大池化和平均池化。
下圖展示了卷積網絡的生成示意圖。

2.2 Design Convolutional Cell
本文並沒有采用直接設計完整的卷積網絡的方法,而是先設計小型的模塊然后將模塊連接以構建完整的網絡(Zoph et al., 2018)。
下圖展示了這種設計的例子,其中設計了卷積單元和 reduction cell。

接下來將討論如何利用 ENAS 搜索由這些單元組成的架構。
假設下圖的DAG共有\(B\)個節點,其中節點1和節點2是輸入,所以controller只需要對剩下的\(B-2\)個節點都要做如下兩個決定:a)當前節點需要與那兩個節點相連 b)所選擇的兩個節點需要采用什么樣的操作。(可選擇的操作有5種:identity(id,相等),大小為3*3或者5*5的separate conv(sep),大小為3*3的最大池化。)
可以看到對於節點3而言,controller采樣的需要連接的兩個節點都是節點2,兩個節點預測的操作分別是sep 5*5和identity。

3.Training ENAS and Deriving Architectures
本小節介紹如何訓練ENAS以及如何從ENAS的controller中生成框架結構。(Section 2.2)
controller網絡是含有100個隱藏節點的LSTM。LSTM通過softmax分類器做出選擇。另外在第一步時controller會接收一個空的embedding作為輸入。
在ENAS中共有兩組可學習的參數:
- 子網絡模型的共享參數,用\(w\)表示。
- controller網絡(即LSTM網絡參數),用\(θ\)表示。
而訓練ENAS的步驟主要包含兩個交叉階段:第一部訓練子網絡的共享參數\(w\);第二個階段是訓練controller的參數\(θ\)。這兩個階段在ENAS的訓練過程中交替進行,具體介紹如下:
子網絡模型共享參數\(w\)的訓練
在這個步驟中,首先固定controller的policy network,即\(π(m;θ)\)。之后對\(w\)使用SGD算法來最小化期望損失函數\(E_{m~π}[L(m;w)]\)。
其中\(L(m;w)\)是標准的交叉熵損失函數:\(m\)表示根據policy network \(π(m;θ)\)生成的模型,然后用這個模型在一組訓練數據集上計算得到的損失值。
根據Monte Carlo估計計算梯度公式如下:
其中上式中的\(m_i\)表示由\(π(m;θ)\)生成的M個模型中的某一個模型。
雖然上式給出了梯度的無偏估計,但是方差比使用SGD得到的梯度的方差大。但是當\(M=1\)時,上式效果還可以。
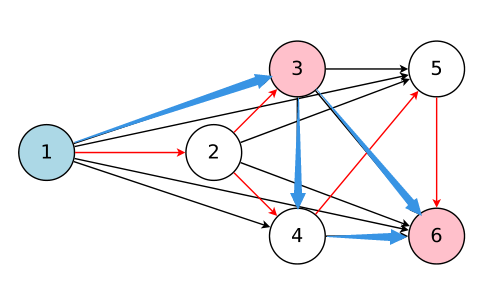
下面我們結合下圖來理解參數共享到底是什么意思(之前看文章一直沒明白什么意思,今天重新看居然恍然大悟。。。。)
可以看到下圖中的DAG由6個節點組成,不同節點和數據流向的組合可以得到不同的子網絡。下圖展示了兩個不同的網絡結構,為方便說明,我們把由紅色箭頭組成的網絡叫A網絡,把藍色箭頭組成的叫B網絡。以節點3為例,假設在A網絡中節點3的operation是3*3卷積,恰巧在B網絡也是這個操作,那么其實就可以重用這個卷積核的權重。
你可能會想,如果A網絡的節點3的operation是5*5的卷積怎么辦,沒關系啊,因為如果下次采樣的網絡C的數據流向和B一樣,剛好節點3的operation也是5*5卷積,那么此時A和C網絡就共享這個節點的權重了。
訓練controller參數θ
在這個步驟中,首先固定\(w\),之后通過求解最大化期望獎勵\(E_{m~π}[R(m;w)]\)來更新\(θ\)。
導出模型架構
首先使用\(π(m,θ)\)生成若干模型。
之后對於每一個采樣得到的模型,直接計算其在驗證集上得到的獎勵。
最后選擇獎勵最高的模型再次從頭訓練。
當然如果像NAS那樣把所有采樣得到的子模型都先從頭訓練一邊,也許會對實驗結果有所提升。但是ENAS之所以Efficient,就是因為它不用這么做,原理繼續看下文。
Evaluation 評估方法
1.在 Penn Treebank 數據集上訓練的語言模型


2.在 CIFAR-10 數據集上的圖像分類實驗

由上表可以看出,ENAS的最終結果不如NAS,這是因為ENAS沒有像NAS那樣從訓練后的controller中采樣多個模型架構,然后從中選出在驗證集上表現最好的一個。但是即便效果不如NAS,但是ENAS效果並不差太多,而且訓練效率大幅提升。
下圖是生成的宏觀搜索空間。

ENAS 用了 11.5 個小時來發現合適的卷積單元和 reduction 單元,如下圖所示。

Conclusion
ENAS能在Penn Treebank和CIFAR-10兩個數據集上得到和NAS差不多的效果,而且訓練時間大幅縮短,效率大大提升。
下面內容轉自一文看懂JeffDean等提出的ENAS到底好在哪?,感覺寫的很好:
前面一直介紹的是 NAS,為了讓大家了解 NAS 只是一種搜索算法。NAS 沒有學會建模也不能替代算法科學家設計出 Inception 這樣復雜的神經網絡結構,但它可以用啟發式的算法來進行大量計算,只要人類給出網絡結構的搜索空間,它就可以比人更快更准地找到效果好的模型結構。
ENAS 也是一種 NAS 實現,因此也是需要人類先給出基本的網絡結構搜索空間,這也是目前 ENAS 的一種限制(論文中並沒有提哦)。ENAS 需要人類給出生成的網絡模型的節點數,我們也可以理解為層數,也就是說人類讓 ENAS 設計一個復雜的神經網絡結構,但如果人類說只有 10 層那 ENAS 是不可能產出一個超過 10 層網絡結構,更加不可能憑空產生一個 ResNet 或者 Inception。當然我們是可以設計這個節點數為 10000 或者 1000000,這樣生成的網絡結構也會復雜很多。那為什么要有這個限制呢?這個原因就在於 ENAS 中的 E(Efficient)。
大家大概了解過 ENAS 為什么比其他 NAS 高效,因為做了權值共享 (Parameter sharing),這里的權值共享是什么意思呢?是大家理解的模型權重共享了嗎,但 ENAS 會產生和嘗試各種不同的模型結構,模型都不一樣的權重還能共享嗎?實際上這里我把 Parameter sharing 翻譯成權值共享就代表則這個 Parameter 就是模型權重的意思,而不同模型結構怎樣共享參數,就是 ENAS 的關鍵。ENAS 定義了節點(Node)的概念,這個節點和神經網絡中的層(Layer)類似,但因為 Layer 肯定是附着在前一個 Layer 的后面,而 Node 是可以任意替換前置輸入的。
下面有一個較為直觀的圖,對於普通的神經網絡,我們一般每一層都會接前一層的輸入作為輸出,當然我們也可以定義一些分支不一定是一條線的組合關系,而 ENAS 的每一個 Node 都會一個 pre-node index 屬性,在這個圖里 Node1 指向了 Node0,Node2 也指向了 Node0,Node3 指向了 Node1。
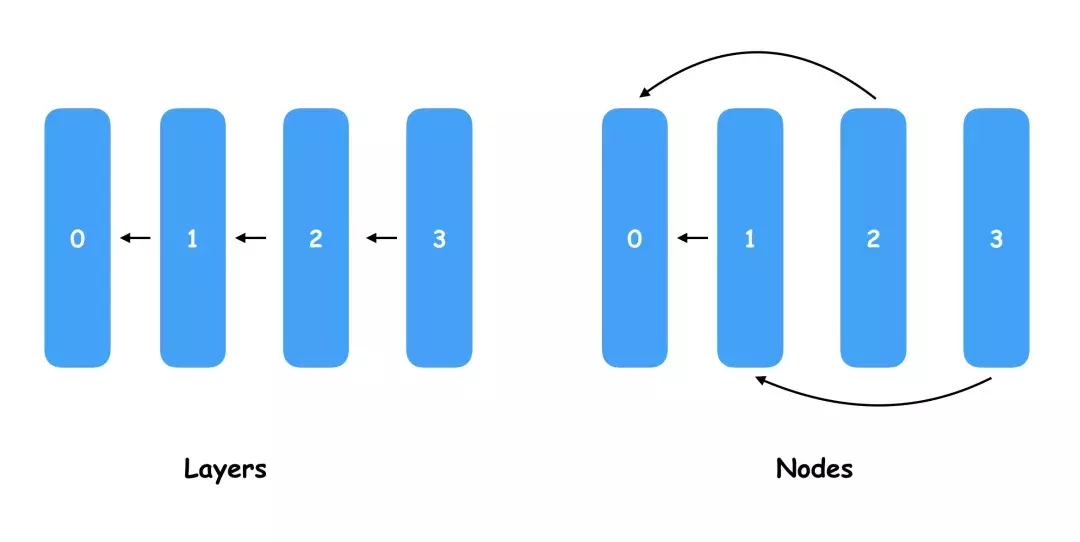
事實上,ENAS 要學習和挑選的就是 Node 之間的連線關系,通過不同的連線就會產生大量的神經網絡模型結構,從中選擇最優的連線相當於“設計”了新的神經網絡模型。如果大家理解了可能覺得這種生成神經網路的結構有點 low,因為生成的網絡結構樣式比較相似,而且節點數必須是固定的,甚至很難在其中創造出 1x1 polling 這樣的新型結構。是的,這些吐槽都是對的,目前 ENAS 可以做的就是幫你把連線改一下然后生成一個新的模型,但這個就是 ENAS 共享權重的基礎,而且可以以極低的代碼量幫你調整模型結構生成一個更好的模型,接下來就是本文最核心的 ENAS 的 E(Efficient)的實現原理介紹了。
我們知道,TensorFlow 表示了 Tensor 數據的流向,而流向的藍圖就是用戶用 Python 代碼定義的計算圖(Graph),如果我們要實現上圖中所有 Layer 連成一條直線的模型,我們就需要在代碼中指定多個 Layer,然后以此把輸入和輸出連接起來,這樣就可以訓練一個模型的權重了。當我們把上圖中所有 Layer 連成一條直線的模型改成右邊交叉連線的模型,顯然兩者是不同的 Graph,而前一個導出模型權重的 checkpoint 是無法導入到后一個模型中的。但直觀上看這幾個節點位置本沒有變,如果輸入和輸出的 Tensor 的 shape 不變,這些節點的權重個數是一樣的,也就是說左邊 Node0、Node1、Node2、Node3 的權重是可以完全復制到右邊對應的節點的。
這也就是 ENAS 實現權重共享的原理,首先會定義數量固定的 Node,然后通過一組參數去控制每個節點連接的前置節點索引,這組參數就是我們最終要挑選出來的,因為有了它就可以表示一個固定神經網絡結構,只要用前面提到的優化算法如貝葉斯優化、DQN 來調優選擇最好的這組參數就可以了。那評估模型也是先生成多組參數,然后用新的網絡結構來訓練模型得到 AUC 等指標嗎?答案是否定的,如果是這樣那就和普通的 NAS 算法沒什么區別了。因為訓練模型后評估就是非常不 Efficient 的操作,這里評估模型是指各組模型用相同的一組權重,各自在未被訓練的驗證集中做一次 Inference,最終選擇 AUC 或者正確率最好的模型結構,其實也就是選擇節點的連線方式或者是表示連線方式的一組參數。
稍微總結一下,因為 ENAS 生成的所有模型節點數是一樣的,而且節點的輸入和輸出都是一樣的,因此所有模型的所有節點的所有權重都是可以加載來使用的,因此我們 只需要訓練一次模型得到權重后,讓各個模型都去驗證集做一個預估,只要效果好的說明發現了更好的模型了。實際上這個過程會進行很多次,而這組共享的權重也會在一段時間后更新,例如我找到一個更好的模型結構了,就可以用這個接口來訓練更新權重,然后看有沒有其他模型結構在使用這組權重后能在驗證機有更好的表現。
回到前面 TensorFlow 實現 ENAS 的問題,我們知道 TensorFlow 要求開發者先定義 Graph,然后再加載權重來運行,但定義 Graph 的過程與模型訓練過程是分開的,而 ENAS 要求我們在模型訓練過程中不斷調整 Graph 的結構來嘗試更好的 Graph 模型結構。這在聲明式(Declarative)編程接口的 TensorFlow 上其實不好實現,而命令式(Imperative)編程接口的 PyTorch 上反而更好實現。當然這里可以為 TensorFlow 正名,因為 ENAS 的作者就提供了基於 TensorFlow 的 ENAS 源碼實現,開源地址 https://github.com/melodyguan/enas 。我們也深入看了下代碼,作者用了大量 tf.case()、tf.while() 這樣的接口,其實是 在 TensorFlow 的 Graph 中根據參數來生成最終訓練的 child 模型的 Graph,因此沒有用 Python 代碼定義所有 child 模型的 Graph 的集合,也不需要每次都重新構建 Graph 來影響模型訓練的性能。
除了 Node 之間的連線外,ENAS 論文里面可以訓練的超參數還包括上圖中的激活函數,也是通過 controller 模型輸出的一組參數來決定每個 Node 使用的激活函數,而這些激活函數不需要重新訓練,只需要直接加載共享權重然后做一次 Inference 來參與模型評估即可。

很多人可能覺得目前共享的權重比較簡單,只能實現矩陣乘法和加法,也就是全連接層的作用,但在圖像方面會用到更多的卷積網絡,也會有 filter size、polling kernel size 等參數需要選擇。實際上 ENAS 已經考慮這點了,這些 Node 擁有的權重以及使用權重的方法被稱為 Cell,目前已經提供乘法和卷積這兩種 Cell,並且在 PTB 和 Cifar10 數據集上做過驗證,當然未來還可以加入 RNN 等 Cell,甚至多種 Cell 一起混用,當然這個在實現上例如前置節點的連線上需要有更復雜的判斷和實現。
對於 ENAS 的 controller 模型的參數調優,論文中使用的是增強學習中的 Policy gradient,當然正如前面所提到的,使用貝葉斯優化、DQN、進化算法也是沒問題的。不過目前 ENAS 的 controller 模型和共享權重的實現放在了一起,因此要拓展新的 controller 提優算法比較困難,未來我們希望把更多的調優算法集成到 Advisor 中(目前已經支持 Bayesian optimization、Random search、Grid search,正在計划支持 Policy gradient、DQN、Evolution algorithm、Particle swarm optimization 等),讓 ENAS 和其他 NAS 算法也可以更簡單地使用已經實現的這些調優算法。
總體而言,ENAS 給我們自動超參調優、自動生成神經網絡結構提供了全新的思路。通過權值共享的方式讓所有生成的模型都不需要重新訓練了,只需要做一次 Inference 就可以獲得大量的 state 和 reward,為后面的調優算法提供了大量真實的訓練樣本和優化數據。這是一種成本非常低的調優嘗試,雖然不一定能找到更優的模型結構,但在這么大的搜索空間中可以快速驗證新的模型結構和調優生成模型結構的算法,至少在已經驗證過的 PTB 和 CIFAR-10 數據集上有了巨大的突破。
當然也不能忽略 ENAS 本身存在的缺陷(這也是未來優化 ENAS 考慮的方向)。首先是為了共享權重必須要求 Node 數量一致會限制生成模型的多樣性;其次目前只考慮記錄前一個 Node 的 index,后面可以考慮連接多個 Node 制造更大的搜索空間和更復雜的模型結構;第三是目前會使用某一個模型訓練的權重來讓所有模型復用進行評估,對其他模型不一定公平也可能導致找不到比當前訓練的模型效果更好的了;最后是目前基於 Inference 的評估可以調優的參數必須能體現到 Inference 過程中,例如 Learning rate、dropout 這些超參就無法調優和選擇了。
總結
最后總結下,本文介紹了業界主流的自動生成神經網絡模型的 NAS 算法以及目前最為落地的 ENAS 算法介紹。在整理本文的時候,發現 NAS 其實原理很簡單,在一定空間內搜索這個大家都很好理解,但要解決這個問題在優化上使用了貝葉斯優化、增強學習等黑盒優化算法、在樣本生成上使用了權值共享、多模型 Inference 的方式、在編碼實現用了編寫一個 Graph 來動態生成 Graph 的高級技巧,所以要 讀好一篇 Paper 需要有一對懂得欣賞的眼睛和無死角深挖的決心。