ps :讀書筆記
海量數據解決方案
緩存和頁面靜態化
緩存就是把從數據庫中的數據暫時存起來,下次使用時無需在查詢數據庫。緩存分為程序直接保存到內存和框架框架2種。程序緩存一般使用currentHashMap直接保存到內存。框架緩存的話有redis,memcache等。
ps:空數據值問題。
緩存創建的時候把沒有數據的緩存用特定的符號來表示。因為這種模式下如果從緩存中獲取不到數據,就會查詢數據庫,但是其本身就沒有數據的話。那么每次都要查詢一次數據庫,不合理。
頁面靜態化:是將程序生成的頁面保存起來。這樣下次調用直接就使用。連程序這一關也過了。更加快速。可以在程序中使用velocity等技術來生成靜態頁面,也可以通過上層緩存Nginx來生成。
數據庫優化
1.表結構優化:設計合理的符合規范的表。
2.sql優化:根據日志以及其他工具分析那條sql語句最耗時,在針對性的有的放矢的優化,要統籌好,不能只針對一條語句,優化時要考慮到表上的其他語句綜合考慮。
3.分區:一個表中數據量太大時,那么分區就可以使用了。分區是將數據按照一定規則把數據分到不同區來保存,這樣子操作數據時,數據量更少。查詢數據時只在一定區間進行。且這種操作時對程序透明的。程序無需修改。
4.分表:分表就是把表橫向切分為幾個表。第一種方式就是為了減少數據,比如一張表里面某個字段是分類。可以更具這個分類來分為多個表。以此來減少每個表的數據量。第二種方式是由於某個表某些字段經常被查,但是不修改,某些字段需要進場修改,那么分表是個不錯的選擇,因為對於mysql之類的表來說,增刪改操作時要加鎖的,無論是什么隔離級別。,這樣子加鎖范圍就減少了。對於mysql來說不是問題,但是對於其他數據庫來說就不知道了。對於mysql來說可以照樣讀取數據,對於某些數據庫或者se隔離級別的mysql,這條記錄也是不可讀的。需要等待數據庫釋放這條記錄的鎖。
5.索引優化:對於mysql的innodb來說,我上篇博客已經說過了。這里簡單說下,最左匹配原則,綜合所有查詢語句,找出,最佳的索引創建原則和最佳的查詢語句,比如,你有聯合索引(a,b,c)。你的查詢語句為b=1 and c=1 那么要么調整查詢語句讓其條件多個a=?要么聯合索引(a,b,c)調整為(b,c,a)。其次對於mysql來說。一條語句有且只用一個表有且只用一條索引。至於多表查詢時連表的語句也會加入到索引里面。
6.存儲過程:對於復雜的sql來說來說,直接使用存儲過程來調用,可以有效提高效率。
活躍數據分離
一個數據量很大的表,只有一小部分數據是活躍數據,經常被查詢,更多的數據則是惰性數據,偶爾被調用一下。那么我們可以用2個表來保存,第一個表是活躍數據保存,第二個表是惰性數據保存。這樣子可以有效提高效率。至於是否活躍數據,怎么分配就要看自己方業務邏輯怎么實現的了。
批量讀取和延遲修改
1.批量讀取:故名思議,把一堆查詢結合成一條查詢,比如。有的業務是要查詢一次做個操作,那么可以把這些查詢放在一個in()語句里面。又或者高並發下,把幾秒的異步請求統一查詢處理。
2.延遲修改:就是把一些頻繁修改的數據放到一個緩存里面去,然后定時把緩存的數據刷到數據庫里面,這個緩存和普通緩存不一樣,這個緩存的數據庫不是完整的。程序查詢時同時讀取數據庫和緩存的數據,綜合讀取之。
讀寫分離
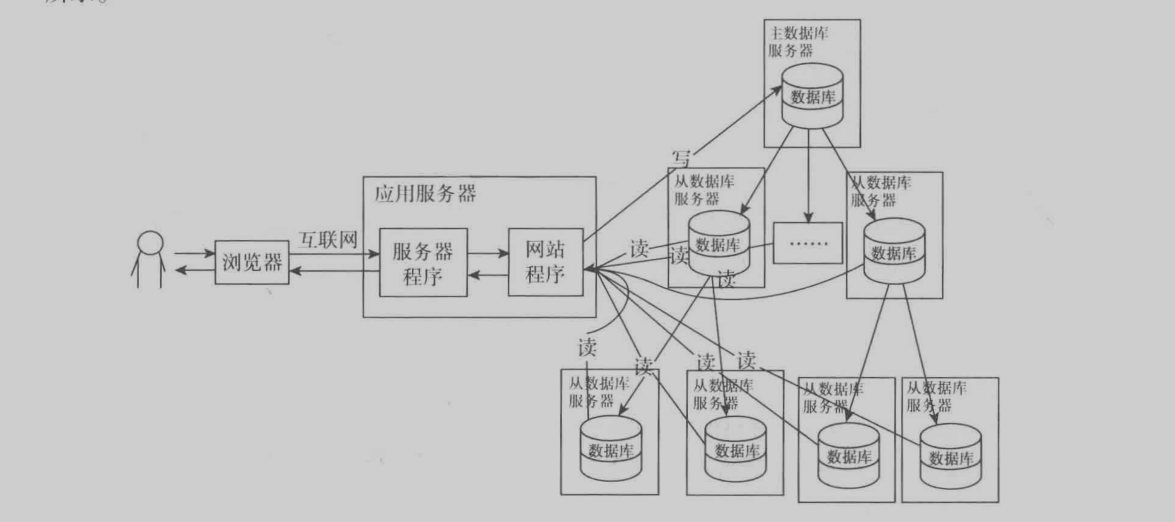
先上一張圖,這個圖是書里面的,說起來很簡單就是把讀取數據和增刪改數據分離到不同數據庫里面。增刪改放到主數據庫里面,讀取數據則是放到從數據庫里面。主數據的數據通過底層同步到從數據庫里面。
分布式數據庫
分布式數據庫是將不同的表放到不同的數據庫里面,然后再放到不同的服務器里面,這樣子查詢時可以使用多台服務器來運行,可以有效提高效率,主要用於超復雜耗時的查詢。這個可以和讀寫分離一起使用,搭配使用。另一種情況是不同業務的表放在不同數據庫里面,可以起到分流的作用
NoSql和Hadoop
NoSql和sql比起來就是非結構化的,就是沒有定義好的字段,類型啊之類的,但是NOsql是通過多個塊存儲數據,因此效率速度很快,被廣泛應用於大數據
Hadoop:Hadoop是針對大數據處理的一套框架。
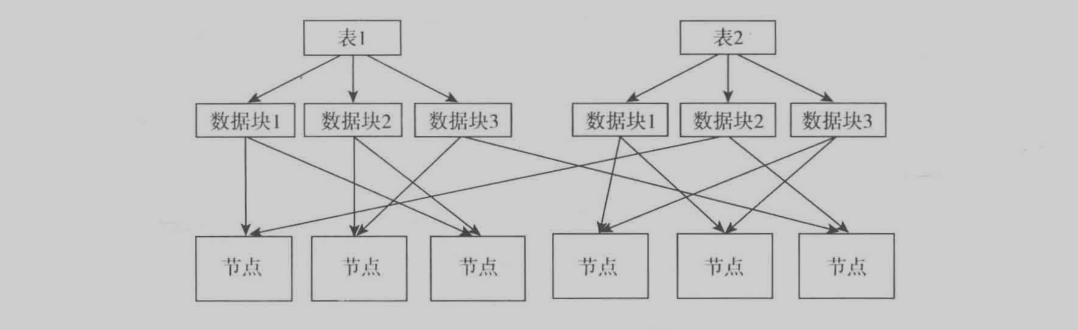
這個是Hadoop存儲圖,就是把表的數據塊分為多個節點保存。這樣子可以並發處理並且可以保存數據的穩定性。Hadoop是對每一個數據塊找到的節點並處理,然后在統一處理,得到最終結果(這塊不熟)
高並發處理方案
靜態資源分離
就是將圖片,視頻,css,等文件保存到另外一個服務器中,使用2級域名,通過不同域名,可以讓瀏覽器迅速獲取到資源而不用訪問應用服務器。
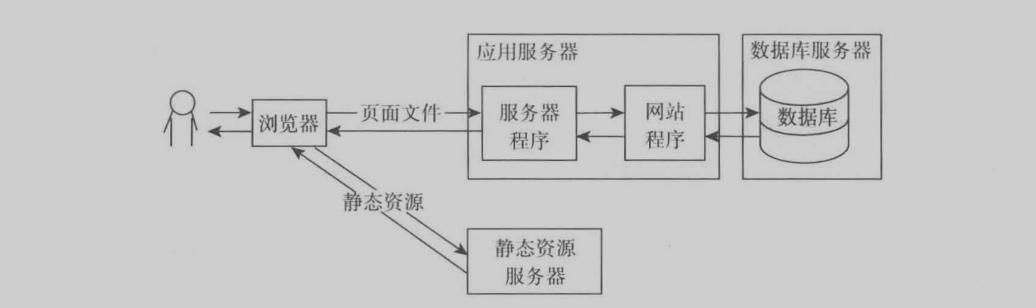
頁面緩存
就是將程序生成的頁面緩存保存下來,下次訪問時就不用再用cpu來生成數據了。浪費其資源。可以使用Nginx服務器自帶的緩存機制,也可以使用專門的squid來處理。(ps:對於一些頁面某些數據經常變化,但是整體不變,那么我們可以使用ajax來請求重新獲取數據來更新界面)
集群和分布式
集群就是相同的程序放到多個服務器里面,主要起到分流的作用。分布式就是更具業務邏輯將程序拆分到不同服務器上。這2個可以一起使用。(至於集群導致的session和token問題,下一章會有篇關於session和token)。不用業務之間的聯系可以通過RPC來處理,我們這邊業務較為復雜,將大量的程序拆分成一個個的微服務。每個微服務之間通過dubbo來傳遞消息。
反向代理
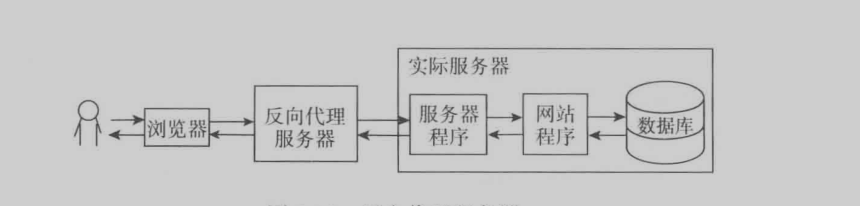
反向代理:就是客戶端訪問的服務器不直接提供資源,該服務器從別的服務器獲取資源並返回給用戶主要由3個作用
1.可以負載均衡
2.可以轉發請求
3.可以作為前端服務器和實際請求服務器集成。
ps:反向代理和代理服務器不一樣。反向代理是用戶不知道這個事,一切都是透明的。代理服務器則是用於代替用戶獲取資源在返回給用戶,需要用戶手動設置。
CDN
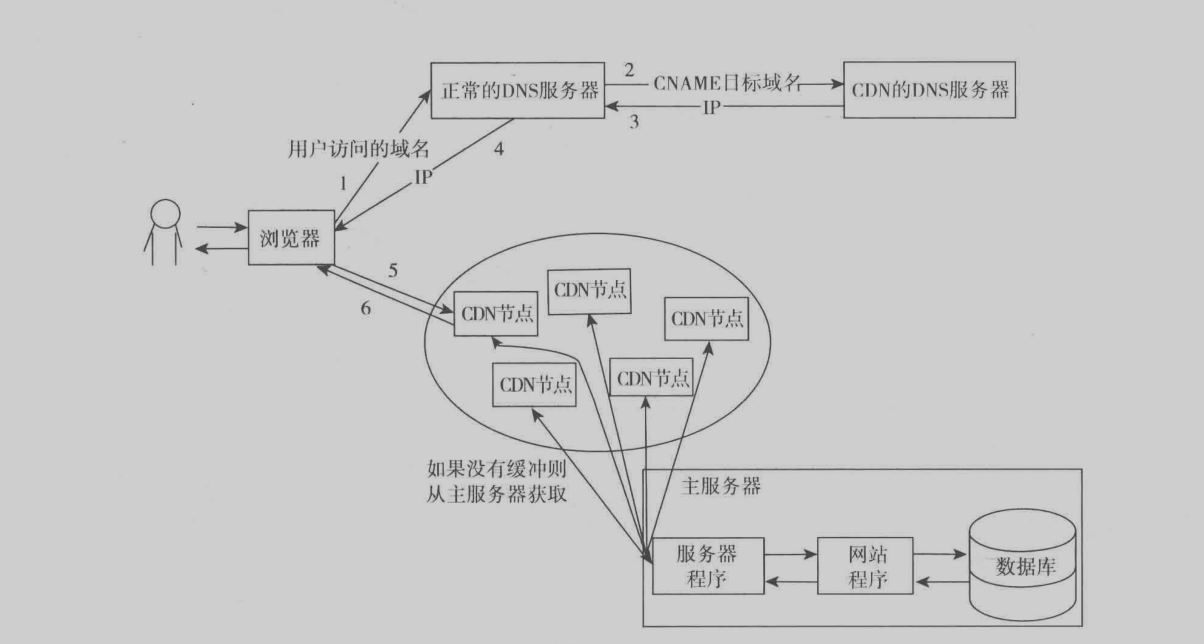
CDN是個特殊的頁面緩存服務器,和普通的服務器相比,CDN服務器遍布全國各地,當接受到用戶請求時,會將其分配到對應的最合適節點,根據地域等信息來分配,如圖所示為其中一個實現方式。