
官方網站 官方代碼
## 第一章 基礎
1.1 基礎編程模型
1.1節的內容主要為介紹Java的基本語法以及書中會用到的庫。
下圖為一個Java程序示例和相應的注解:
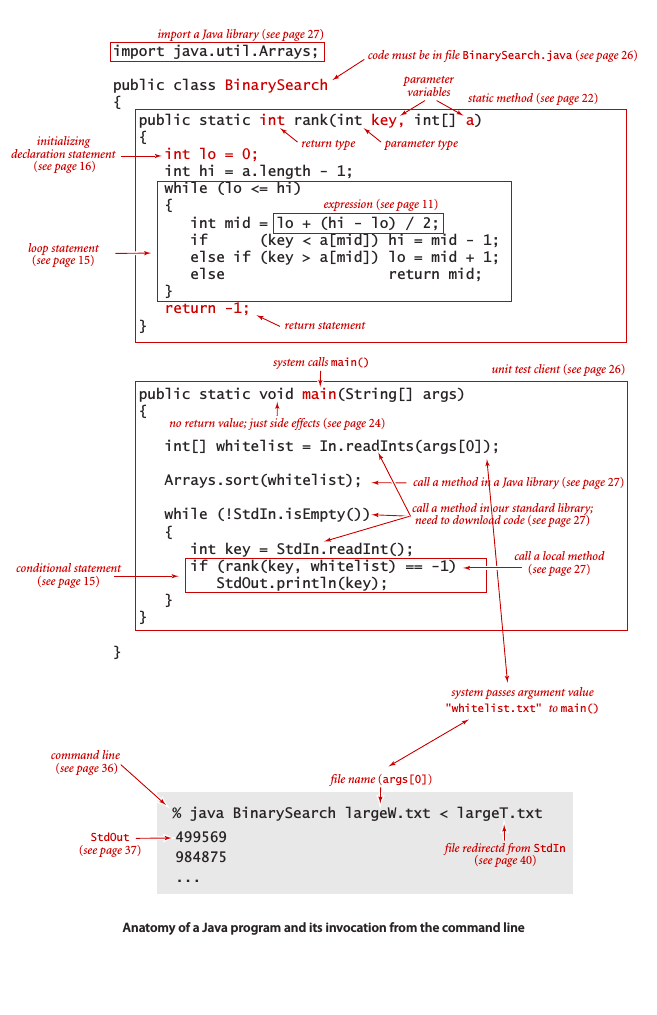
本書用到的幾種基本語法:
- 初始數據類型 (primitive data tyoes):整型 (int),浮點型 (double),布爾型 (boolean),字符型 (char)以及組合起來的表達式。
- 語句 (statements):聲明 (declarations),賦值 (assignments),條件 (conditionals),循環 (loops),調用 (calls),返回 (returns)。
- 數組 (arrays)
- 靜態方法 (static methods):即函數。
- 字符串 (strings)
- 標准輸入/輸出 (input/output)
- 數據抽象 (data abstraction)
+ Java的`int`為32位,`double`為64位 + 除`int`和`double`以外的其他初始數據類型: 1. 64位整數 (long) 2. 16位整數 (short) 3. 16位字符 (char) 4. 8位整數 (byte) 5. 32位單精度實數 (float)
- i++和++i的區別:
++i等價於i = i + 1和i += 1,即先+1,再進行運算;而i++是先運算再+1。下面演示一下:
public class i_test
{
public static void main(String[] args)
{
int i = 0;
int j = 0;
System.out.printf("%s: %d%n","++i",++i);
System.out.printf("%s: %d%n","i++",j++);
}
}
/**輸出:
++i: 1
i++: 0
*/
數組
1. 創建數組
- 長模式:
double[] a;
a = new double[N];
for (int i = 0; i < N; i++)
a[i] = 0.0
- 短模式
double[] a = new double[N];
int[] a = {1,1,2,3,6}
- 二維數組
double[][] a = new double[M][N];
2. 別名
數組名表示的是整個數組,如果將一個數組變量賦給另外一個變量,則兩個變量將會指向同一個數組:
int[] a = new int[N];
a[i] = 1234;
int[] b = a;
b[i] = 5678 // a[i]也變成5678, 不改變原數組的復制方法見下文
3. 幾種數組操作
1)找最大值
double max = a[0];
for (int i = 1;i < a.length; i++)
if (a[i] > max) max = a[i];
2)計算平均值
int N = a.length;
double sum = 0.0;
for (int i = 0; i < N; i++)
sum += a[i];
double average = sum / N;
3)復制數組
int N = a.length;
double[] b = new double[N];
for (int i = 0; i < N; i++)
b[i] = a[i];
4)反轉數組中元素
int N = a.length;
for (int i = 0; i < N/2; i++)
{
double temp = a[i];
a[i] = a[N-i-1];
a[N-i-1] = temp;
}
5)矩陣乘法
int N = a.length;
double[][] c = new double[N][N];
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
{// Compute dot product of row i and column j
for (int k = 0; k < N; k++)
c[i][j] += a[i][k]*b[k][j];
}
靜態方法
典型的靜態方法如下圖所示:

1. 幾種靜態方法實現
1)判斷是否為素數
public static boolean isPrime(int N)
{
if (N < 2) return false;
for (int N = 2; i*i <= N; i++)
if (N % i == 0) return false;
return true;
}
2)計算調和級數
public static double H(int N)
{
double sum = 0.0;
for (int i = 1; i < N; i++)
sum += 1.0 / i;
return sum;
}
輸入與輸出
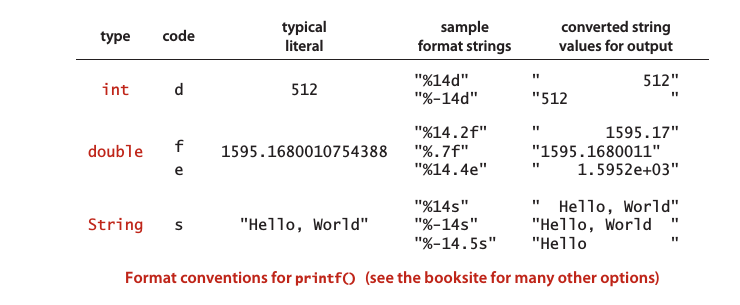
1. 格式化輸出:
2. 標准輸入

3. 重定向和管道
"<" 表示從文件讀取,">"表示寫入文件

4. 從文件輸入輸出

1.2 數據抽象
數據類型是指一組值和一組對值的操作的集合,對象是能夠存儲任意該數據類型的實體,或數據類型的實例。
一個數據類型的例子:

抽象數據類型和靜態方法的相同點:
- 兩者的實現均為Java類
- 實例方法可能接受0個或多個指定類型的參數,在括號中以逗號分隔
- 可能返回一個指定類型的值,也可能不會(用void表示)
不同點:
- API中可能會出現名稱與類名相同且沒有返回值的函數,這些特殊的函數被稱為構造函數。在上例中,Counter對象有一個接受一個String參數的構造函數
- 實例方法不需要static關鍵字,它們不是靜態方法,它們的目的是操作該數據類型中的值
- 某些實例方法的存在是為了符合Java的習慣,我們將此類方法稱為_繼承_方法,如上例的toString方法
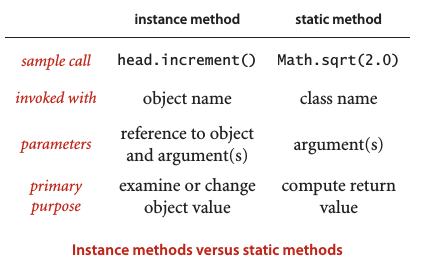
實例方法和靜態方法 :
對象
Java中,所有非原始數據類型的值都是對象。對象的三大特性:狀態、標識、行為。
引用 (reference) 是訪問對象的一種方式,如圖所示:

創建對象
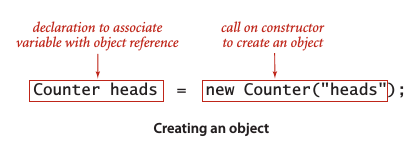
要創建 (或實例化) 一個對象,用關鍵字new並緊跟類名以及 () 來觸發它的構造函數。每當用例調用new (),系統都會:1. 為新對象分配內存空間。 2. 調用構造函數初始化對象中的值。 3. 返回該對象的一個引用。
創建一個對象,並通過聲明語句將變量與對象的引用關聯起來:
抽象數據類型的實現
組成部分:私有實例變量 (private instance variable),構造函數 (constructor),實例方法 (instance method) 和一個測試用例(client) 。
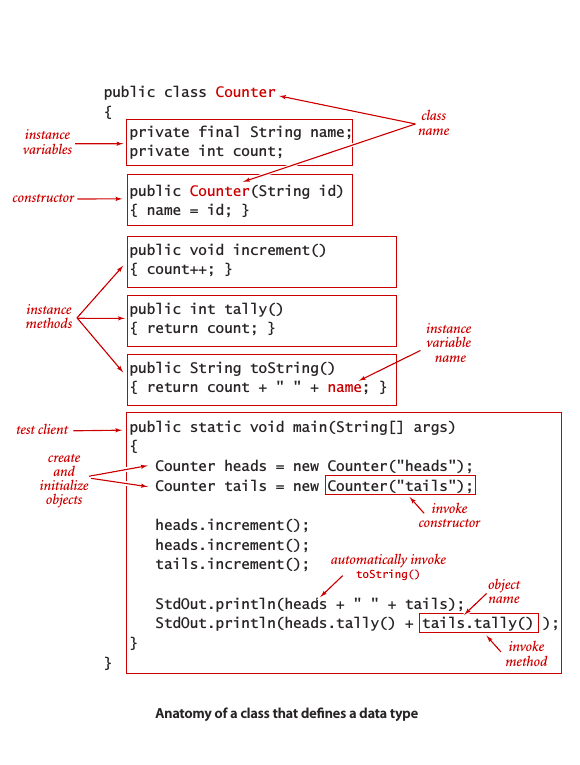
構造函數
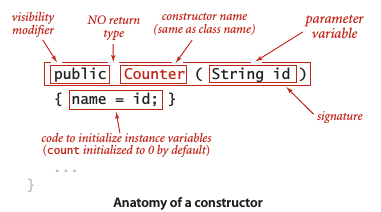
每個Java類都至少含有一個構造函數以創建一個對象的標識。一般來說,構造函數的作用是初始化實例變量。如果沒有定義構造函數,類將會隱式將所有實例變量初始化為默認值,原始數字類型默認值為0,布爾型為false,引用類型變量為null。
作用域
在方法中調用實例變量,若出現二義性,可使用 this 來區別:

1.3 背包、隊列和棧
- 本節用到的API:

鏈表 (Linked List)
鏈表是一種遞歸的數據結構,它或者為空 (Null),或者是指向一個結點 (Node) 的引用,該結點包含一個泛型元素和一個指向另一條鏈表的引用。
使用嵌套類定義結點的抽象數據類型:
private class Node
{
Item item;
Node next;
}
一個Node對象包含兩個實例變量,類型分別為Item (參數類型) 和Node,通過new Node () 觸發構造函數來創建一個Node類型的對象。調用的對象是一個指向Node對象的引用,它的實例變量均被初始化為null。
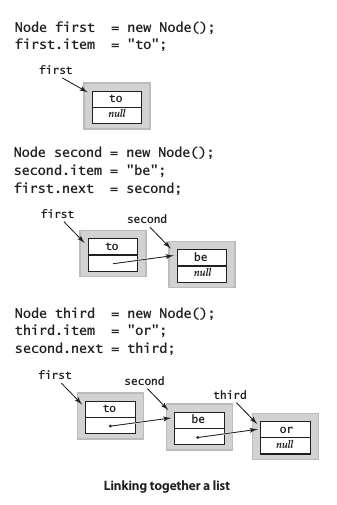
構造鏈表
構造一條含有元素to、be和or的鏈表,首先為每個元素創建結點:
Node first = new Node();
Node second = new Node();
Node third = new Node();
將每個結點的item域設為所需的值:
first.item = "to";
second.item = "be";
third.item = "or";
然后用next域構造鏈表:
first.next = second;
second.next = third;
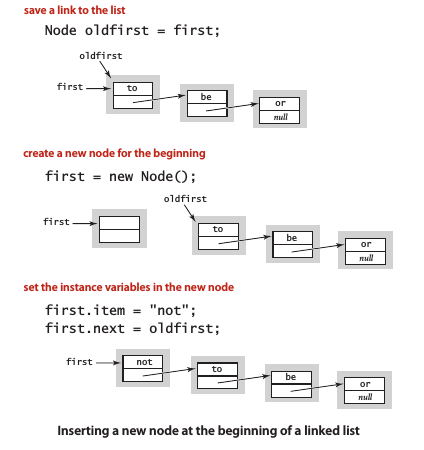
在表頭插入結點
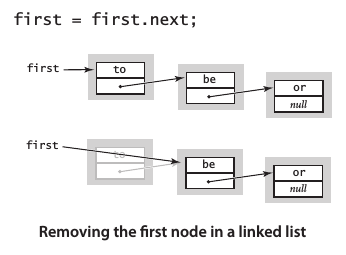
在表頭刪除節點
將first指向first.next:
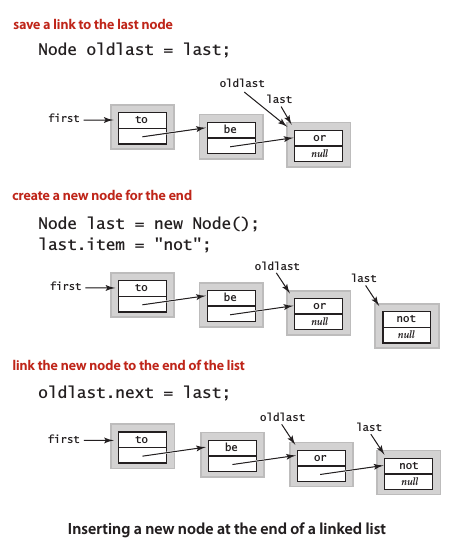
在表尾插入節點
鏈表的遍歷
一般數組a[] 的遍歷:
for (int i = 0; i < N; i++)
{
// Process a[i].
}
鏈表的遍歷:
for (Node x = first; x != null; x = x.next)
{
// Process x.item.
}
棧 (stack)
棧是一種基於后進先出 (LIFO) 策略的集合類型。
棧的鏈表實現:
public class Stack<Item>
{
private Node first;
private int N;
private class Node
{
Item item;
Node next;
}
public boolean isEmpty() { return first == null; }
public int size() { return N; }
public void push(Item item)
{
Node oldfirst = first;
first = new Node();
first.item = item;
first.next = oldfirst;
N++;
}
public Item pop()
{
Item item = first.item;
first = first.next;
N--;
return item;
}
}
棧測試用例:
public static void main(String[] args)
{ // Create a stack and push/pop strings as directed on StdIn.
Stack<String> s = new Stack<String>();
while (!StdIn.isEmpty())
{
String item = StdIn.readString();
if (!item.equals("-"))
s.push(item);
else if (!s.isEmpty()) StdOut.print(s.pop() + " ");
}
StdOut.println("(" + s.size() + " left on stack)");
}
用鏈表實現棧的優點:
- 可以處理任意類型的數據
- 所需的空間總與集合的大小成正比
- 操作所需的時間和集合的大小無關
隊列 (queues)
隊列是一種基於先進先出(FIFO)策略的集合類型。
隊列的鏈表實現:
public class Queue<Item>
{
private Node first;
private Node last;
private int N;
private class Node
{
Item item;
Node next;
}
public boolean isEmpty() { return first == null; }
public int size() { return N; }
public void enqueue(Item item)
{
Node oldlast = last;
last = new Node();
last.item = item;
last.next = null;
if (isEmpty()) first = last;
else oldlast.next = last;
N++;
}
public Item dequeue()
{
Item item = first.item;
first = first.next;
if (isEmpty()) last = null;
N--;
return item;
}
}
隊列測試用例:
public static void main(String[] args)
{ // Create a queue and enqueue/dequeue strings.
Queue<String> q = new Queue<String>();
while (!StdIn.isEmpty())
{
String item = StdIn.readString();
if (!item.equals("-"))
q.enqueue(item);
else if (!q.isEmpty()) StdOut.print(q.dequeue() + " ");
}
StdOut.println("(" + q.size() + " left on queue)");
}
背包 (bag)
背包是一種不支持從中刪除元素的集合數據類型,它的目的是收集元素並迭代遍歷所有收集到的元素。使用背包說明元素的處理順序不重要。
背包的鏈表實現 + 迭代
import java.util.Iterator;
public class Bag<Item> implements Iterable<Item>
{
private Node first;
private class Node
{
Item item;
Node next;
}
public void add(Item item)
{
Node oldfirst = first;
first = new Node();
first.item = item;
first.next = oldfirst;
}
public Iterator<Item> iterator()
{ return new ListIterator(); }
private class ListIterator implements Iterator<Item>
{
private Node current = first;
public boolean hasNext()
{ return current != null; }
public void remove() { }
public Item next()
{
Item item = current.item;
current = current.next;
return item;
}
}
}
兩種基本的數據結構
- 數組,順序存儲 (sequential allocation)
- 鏈表,鏈式存儲 (linked allocation)
本書所采取的研究新應用的步驟
- 定義API
- 根據特定的應用場景開發用例代碼
- 描述一種數據結構 (一組值的表示),在此基礎上定義類的實例變量,該類將實現一種抽象數據類型來滿足API中的說明
- 描述一種算法 (實現一組操作的方式),在此基礎上實現類的實例方法
- 分析算法的性能特點
1.4 算法分析
計時器 —— Stopwatch實現
基於Java中的currentTimeMillis() 方法,該方法能返回以毫秒計數的當前時間。

常見的增長數量級函數

成本模型 (cose model)
本書使用成本模型來評估算法的性質,這個模型定義了算法中的基本操作。例如3-sum問題的成本模型是訪問數組元素的次數。
得到運行時間的數學模型,步驟如下:
1. 確定輸入模型,定義問題的規模
2. 識別內循環
3. 根據內循環中的操作確定成本模型
4. 對於給定的輸入,判斷這些操作的執行頻率
算法分析的常見函數:

常見增長數量級:

原始數據類型的內存:
