前言
在訓練神經網絡時,調參占了很大一部分工作比例,下面主要介紹在學習cs231n過程中做assignment1的調參經驗。
主要涉及的參數有隱藏層大小hidden_size,學習率learn_rate以及訓練時的batch_size.
理論部分
首先介紹一下講義上關於以上三個參數的可視化分析。

上圖是learn_rate對最終loss的影響,可以從圖中看到低的learn_rate曲線會趨近於線性(藍線),而過高的learn_rate曲線會趨近於指數(綠線)。
高的學習率會使得曲線迅速下降,但是可能會在一個不好的結果下收斂。過高的學習率甚至會使得結果往差的方向發展(黃線)。比較合理的學習率應該體現出入紅色線所示的形狀。
 實際中學習曲線可能不是平滑的,而是如圖上所示有很多的噪聲,曲線的震幅反映了batch_size選擇的合理程度,一般batch_size大的話曲線會變得更加平滑,也就是說訓練的參數和實際的參數擬合度更高。 極端情況是batch_size的大小和dataset的大小一樣,那么曲線很可能就是平滑的。
實際中學習曲線可能不是平滑的,而是如圖上所示有很多的噪聲,曲線的震幅反映了batch_size選擇的合理程度,一般batch_size大的話曲線會變得更加平滑,也就是說訓練的參數和實際的參數擬合度更高。 極端情況是batch_size的大小和dataset的大小一樣,那么曲線很可能就是平滑的。

藍色的曲線顯示出驗證准確率和訓練准確率差別較大,說明可能出現過擬合現象,這種情況可以通過增加正則化項的懲罰系數,或者增加訓練樣本大小。
綠色曲線顯示出驗證准確率和訓練准確率差別較小,說明可能訓練模型過小,可以適當增加網絡的參數。
實踐部分
下面是根據以上的理論進行調參的過程。
首先是原始的參數
batch_size=200
learning_rate=1e-4
learning_rate_decay=0.95```
得到的曲線如下所示

准確率為28%,從分析圖像開始,上圖的第二部分訓練集合驗證集曲線並沒有一個合理的gap說明訓練模型可能過小,所以我們需增加hidden_size,或者增加batch_size的大小。
上圖的第一部分的曲線形狀也不太對,在最初的迭代過程中loss並沒有下降,可能learn_rate過低或者learning_rate_decay不明顯。
所以首先提高learn_rate
```hidden_size = 50
batch_size=200
learning_rate=1e-3
learning_rate_decay=0.9```
運行之后得到的結果是准確率到了47%
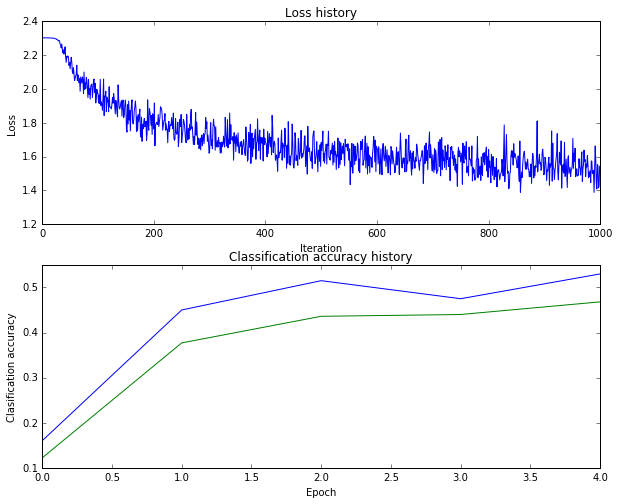
這個修改出乎意料的有效,但是上圖的曲線振幅較大,我們適當增加batch_size來平滑准確率曲線。
```hidden_size = 50
batch_size=300
learning_rate=1e-3
learning_rate_decay=0.9```
運行之后得到的結果是46%
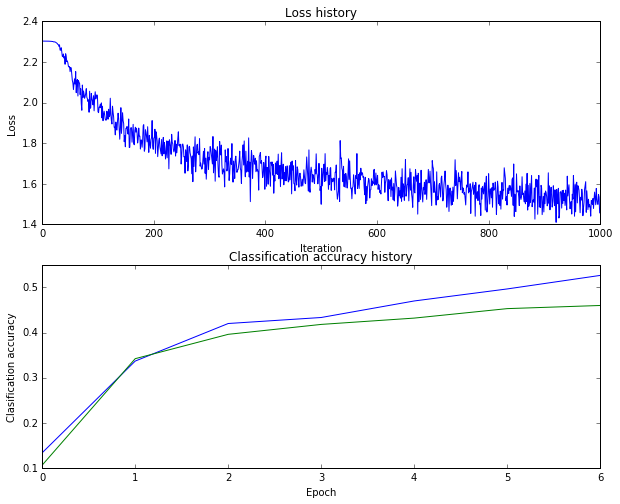
出現了過擬合現象。而且圖的上部分曲線后期震盪過大了,說明learning_rate_decay可能還是不夠明顯
```hidden_size =100
batch_size=300
learning_rate=1e-3
learning_rate_decay=0.8```
識別率依然是46%
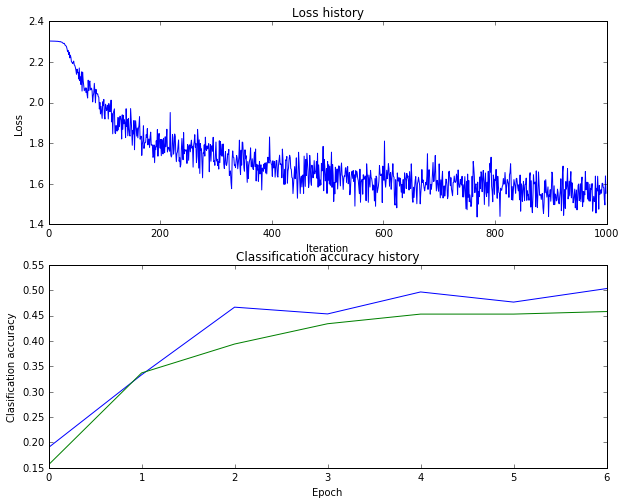
結果不明顯,但是過擬合現象有所緩解。
。
。
。
最后
```hidden_size =100
batch_size=400
learning_rate=5e-4
learning_rate_decay=0.95```
識別率是48%
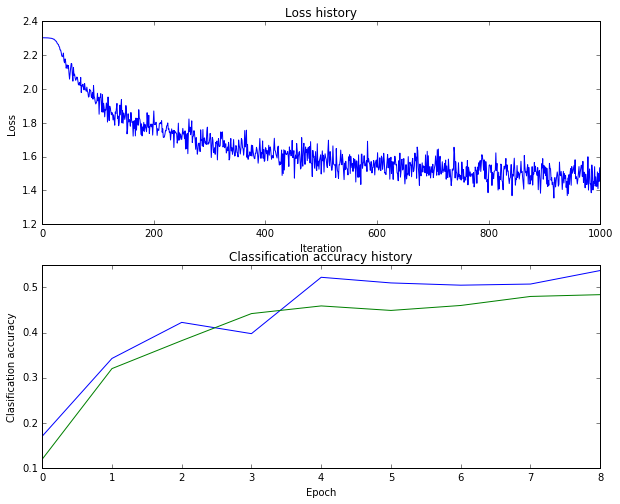
應該還是有點過擬合
#總結
第一次調參,確實很難調試。先到這里吧。