出处 : 2019 CVPRW
摘要 : 基于神经网络的方法是通过利用篡改和非篡改区域间的差异来完成拼接篡改检测。
本文提出一个端到端的 image essence attribute segmentation 网络:RRU-net ,即环形残差U-net。
核心思想是强化CNN的学习方式。
受到大脑recall 和 consolidation 机制的启发,作者利用残差传播 recall 输入特征来解决gradient degradation 梯度退化问题,利用残差反馈 consolidate 输入特征使篡改区域和非篡改区域间的差异更加明显
数据集 CASIA [24] and COLUMB [8]
实验环境 a computer with Intel Xeon E5-2603 v4 CPU and NVIDIA GTX TITAN X GPU.
metrics precision 、recall 、f-score
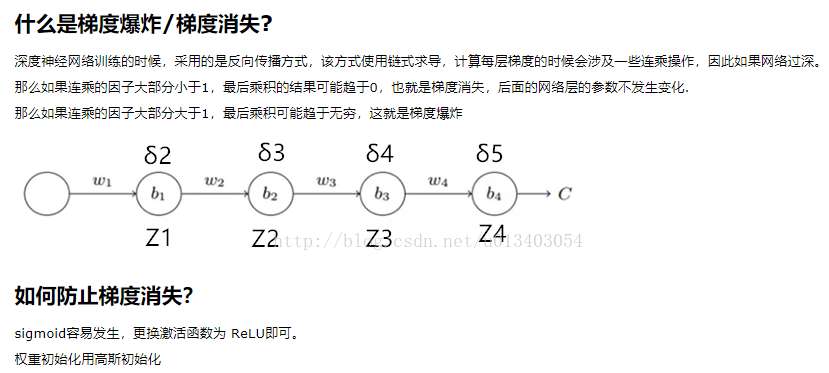
1 背景
传统的基于特征提取的方法:
有一种基于 image essence attribute 检测的方法,问题是如果拼接篡改后做了一些隐蔽处理(如整体模糊操作),这个方法会失败。
基于CNN的检测方法:
输入 image patch,可能会丢失 the contextual spatial information。
随着网络加深,梯度退化问题会使得特征的 discrimination 辨识度弱化,可能造成失败
U-net: 能够提取一些shallow discriminative features,只利用了u-net 的两边
ResNet: 为解决梯度退化问题而提出

2 网络结构
本文结构
-
是端到端的图像本质属性分割网络
-
无需预处理后处理,直接定位篡改区域
-
解决梯度退化问题
-
更好地利用了上下文空间信息
residual propagation
解决梯度退化问题,图2 是示意图,包含两个卷积层(稀疏卷积+relu)和残差传播

公式2 ,输入 x ,输出\(y_f\) ,\(W_i\) 是 i 层的权重,\(F(x,{W_i})\) 表示待学习的残差映射

其中  ,\(\sigma\) 表示 relu 。为简化表达,删去bias
,\(\sigma\) 表示 relu 。为简化表达,删去bias
残差传播类似于人脑的recall机制。当我们学习更多的新知识时,我们可能会忘记以前的知识,所以我们需要recall机制来帮助我们唤起那些以前模糊的记忆。
Residual Feedback
[36]通过将篡改图像通过SRM滤波层来叠加额外的噪声属性差异,增强检测效果。
但SRM 是一种手动选择方法,只适用于RGB图像篡改检测。当篡改区域和非篡改区域来自同一相机时,由于噪声属性相同,SRM方法表现不好
本文提出 residual feedback,强化图像本质属性的差异,不只局限于几个特定的图像属性。 根据[9],设计了一个简单有效的attention机制,加在residual feedback,给输入的辨识度高的特征分配更多注意力。attention机制采用带有sigmoid 激活函数的简单 gating 门控机制,学习有辨识度的特征通道之间的非线性相互作用,避免特征信息的扩散。我们将sigmoid激活得到的响应值叠加在输入信息上,放大未篡改区域和篡改区域的图像本质属性差异。
如图3 和公式 3


x 是输入,\(y_f\) 是公式 2 定义的输出,\(y_b\) 是增强的输入,G 是线性函数用于改变\(y_f\) 的维度,s 是 sigmoid 函数
residual feedback 类似人脑的 consolidation 机制,我们需要巩固我们已经学过的知识,获得新的特征理解。如图1 c ,通过残差反馈,篡改区域放大到全局最大响应值

还有两个影响:区别特征的强化可以看作是对负面标签特征的压制,网络在训练过程中的收敛速度更快。
RRU 网络结构
如图5

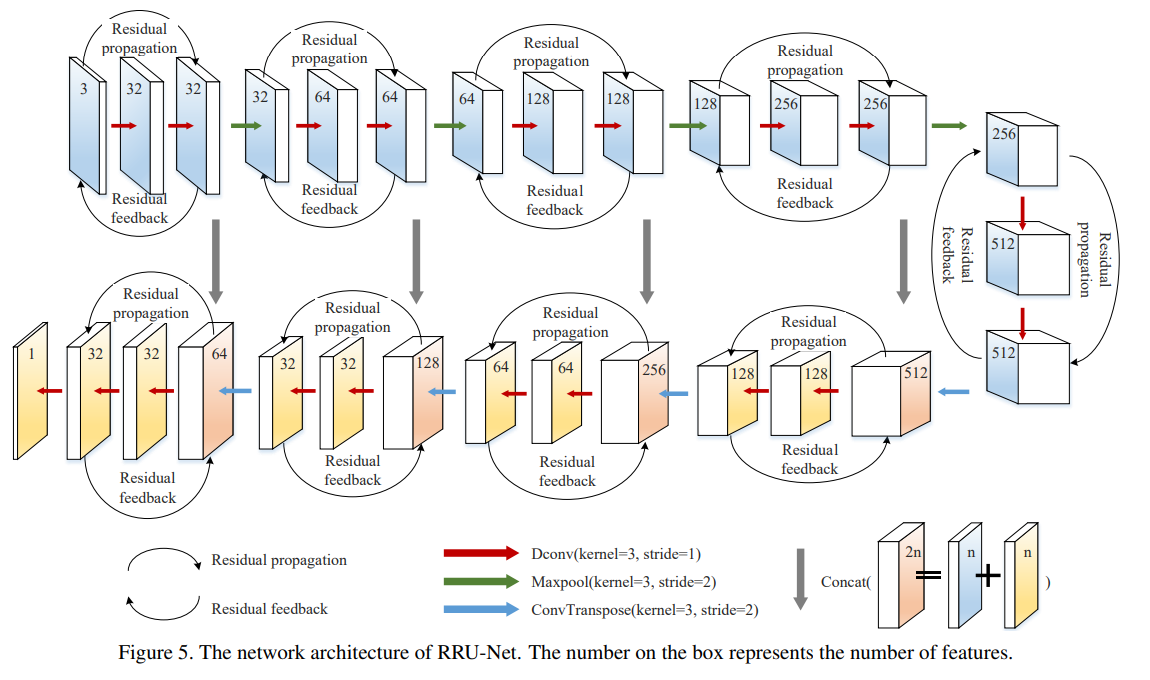
环形残差结构保证了在网络层间提取特征时,对图像本质属性特征的识别更加明显
3 实验
数据集
CASIA :拼接的篡改区域是小而精细的对象
COLUMB:拼接篡改区域是一些简单的、大的、无意义的区域
把训练集、验证集尺寸调整为384×256,数据增强采用随机高斯噪声,JPRG压缩,随机翻转,使数据集一变四,所有实验数据列在表1

augmented splicing 代表 2860 增强的数据集+715 简单拼接数据集
在 CASIA original 按 715:35:100 设置训练、验证、测试集
在 COLUMB original 按 125:10:44 设置训练、验证、测试集
总共使用 17038 个图像
evaluation metrics

对比方法
3个传统特征提取检测方法: 借用[32]的结果
DCT [30],DCT 系数直方图不一致检测方法
CFA [5],颜色滤波器阵列(CFA)插值模式中的干扰被建模为高斯分布的混合,以检测被篡改的区域
NOI [18] ,利用小波变换对拼接区域进行检测,滤波提取局部图像的噪声方差建模。
2个CNN检测方法:
DFNet[15] 在CASIA 的结果并不好,因为DFNET利用64*64的patch输入,CASIA的图像太小了
C2R-Net [27]
2个语义分割方法:FCN [16] and DeepLab v3 [2]
还有 UNET 和 residual UNET(没有residual feedback)
结果
图6,表2,是在plain splicing forgery的结果



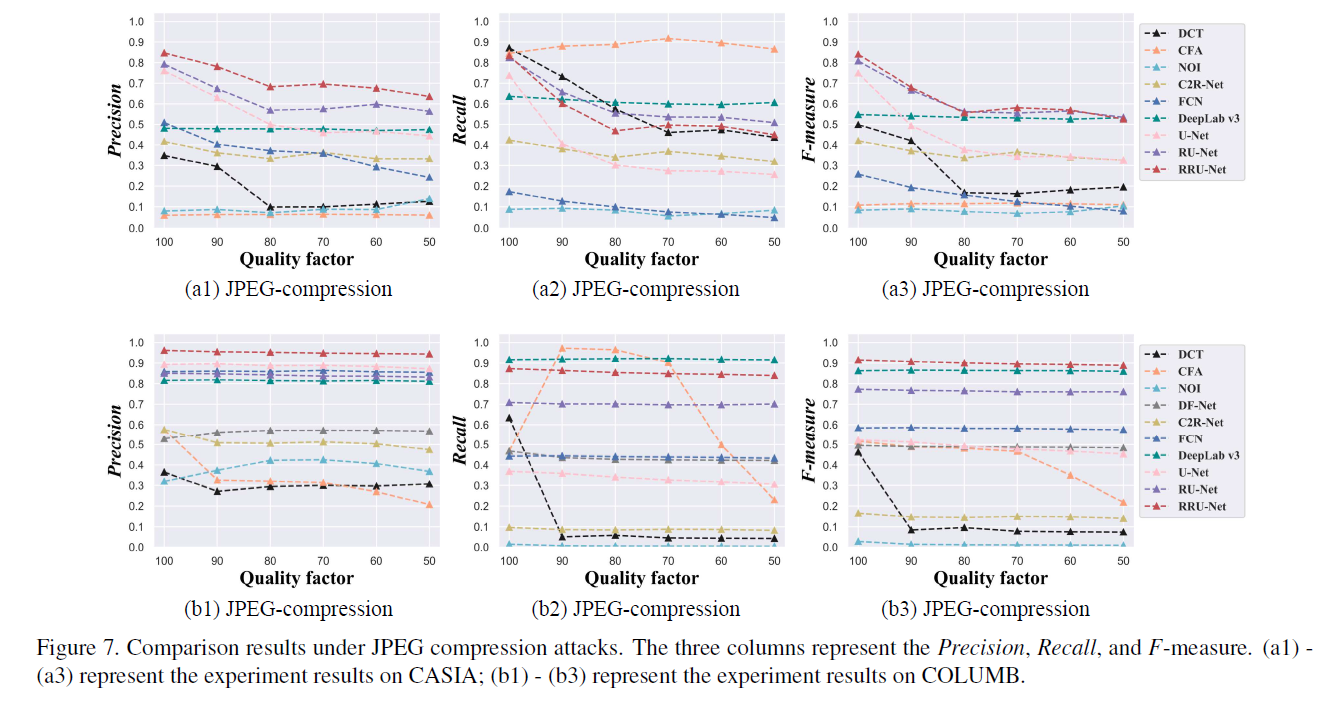
JPEG压缩结果

噪声 结果

image level 结果
