之前了解過postgresql的Bitmap scan,只是粗略地了解到是通過標記數據頁面來實現數據檢索的,執行計划中的的Bitmap scan一些細節並不十分清楚。這里借助一個執行計划來分析bitmap scan以及index only scan,以及兩者的一些區別。
這里有關於Bitmap scan的一些實現過程,https://dba.stackexchange.com/questions/119386/understanding-bitmap-heap-scan-and-bitmap-index-scan
0. 構建測試環境
PG版本為11,如下測試腳本,構建一個簡單的測試表
create table my_test_table01 ( c1 serial not null primary key, c2 varchar(100), c3 timestamp ) --c3字段上建索引 create index ix_c3 on my_test_table01(c3); truncate table my_test_table01; --寫入300W行測試數據,c3列生成隨機時間 insert into my_test_table01 (c2,c3) select uuid_generate_v1(),NOW() - (random() * (NOW()+'1000 days' - NOW())) from generate_series(1,3000000);
1. Bitmap Scan的剖析
用最最容易理解的場景來測試Bitmap Index Scan,執行如下sql,來分析bitma scan這個執行計划的含義。
explain (analyze, buffers,verbose,timing) select count(1) from my_test_table01 a where a.c3 >'20220328' or a.c1 < 100;

對以上的執行計划,有幾個問題先弄清楚:
1,Bitmap Index Scan做了什么?
2,Bitmap Heap Scan做了什么?
3,Recheck Cond的目的是什么?
第一個問題:Bitmap Index Scan做了什么?
Bitmap scan的目標是一個bit數組,bit數組中的每一位映射到表中的一個數據頁Id(One bit per heap page, in the same order as the heap)。
Bitmap Index Scan對於所有的查詢條件,從掃描索引的所有頁面,如果數據頁面中有符合條件的數據,那么就將bit為標記為1,否則標記為0。
其他的查詢條件依次創建一個一樣的bit數組,同樣掃描索引的所有頁面,將符合條件的page的bit位標記為1。
最后多個條件生成的多個bit數組進行與(或)操作(取決於where多個條件是and組合或者or組合,上面截圖中的BitmapOr),合並成一個最終的bit數組。
此時最終的bit數組標記的符合條件的數據頁,而不是最終的數據行,所以最終還要去數據頁中進行篩選。
https://dba.stackexchange.com/questions/119386/understanding-bitmap-heap-scan-and-bitmap-index-scan
第二個問題:Bitmap Heap Scan做了什么
而BitMap Index Scan一次性將滿足條件的索引項全部取出,並在內存中進行排序, 然后根據排序后的索引項訪問表數據,也就是執行計划中的Bitmap Heap Scan。
bitmap index scan 內部優化機制:https://www.postgresql.org/message-id/12553.1135634231@sss.pgh.pa.us
第三個問題:Recheck Cond的目的是什么
BitMap Heap Scan指示找到符合條件的數據頁面,而不是具體的記錄,此時找到數據頁后再用where條件進行篩選其中的數據行,也就是執行計划中的Recheck Cond。
https://stackoverflow.com/questions/50959814/what-does-recheck-cond-in-explain-result-mean
If the bitmap gets too large we convert it to "lossy" style, in which we only remember which pages contain matching tuples instead of remembering each tuple individually. When that happens, the table-visiting phase has to examine each tuple on the page and recheck the scan condition to see which tuples to return.
bitmap scan示例圖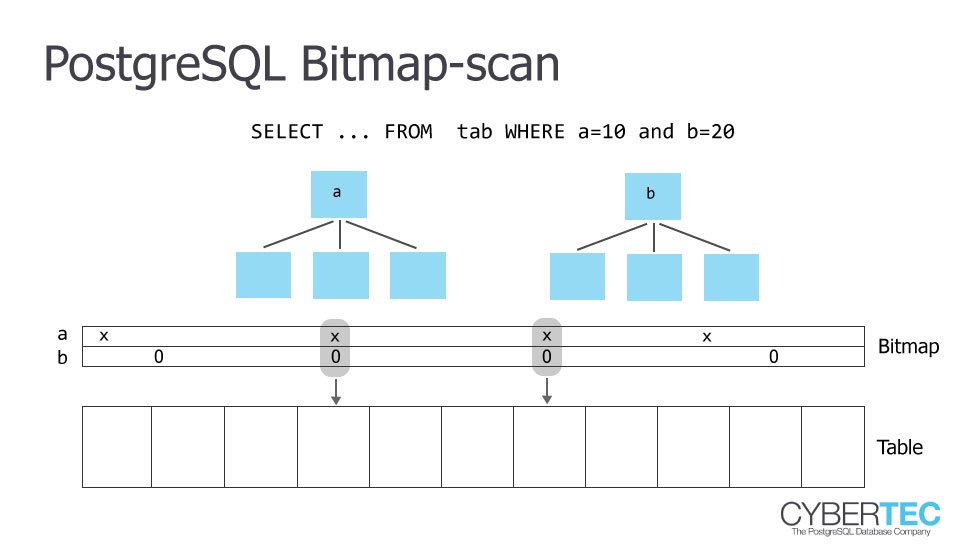
圖片來源:https://www.cybertec-postgresql.com/en/postgresql-indexing-index-scan-vs-bitmap-scan-vs-sequential-scan-basics/
bitmap index scan不僅僅發生在where條件中有多個篩選條件的場景(比如where c1 = m and c2 =n),其實對於一個條件的范圍查詢,也同樣適用bitmap index scan,見下例。
2. 為什么執行計划走Bitmap Index Scan,而不是Index only Scan?
對於如下這個查詢,表中有300W測試數據符合條件的數據比例很少,很明顯,ix_c3上的索引掃描才是更優化的執行計划,為什么在默認情況下是Bitmap Index Scan?
select count(1) from my_test_table01 a where a.c3 >'20220328' ;
從如下截圖可以看到,vacuum是打開的,在造完測試數據后,默認情況下上述sql查詢走了bitmap Index scan,因為c3上有索引,預期是走ix_c3上的索引。
原本以為vacuum是異步的,或者說有滯后性,但是這個case在測試數據構造完之后幾個小時甚至幾天,該查詢都依舊走bitmap Index scan的方式。
當關閉enable_bitmapscan和enable_seqscan,強制優化器走ix_c3上的index only scan,代價明顯更大,這就有點說不通了,原因下文會具體分析。
本人對該現象一開始也是百思不得其解,難道是bitmap scan有什么魔法?
看到這里有一個提到這個問題:https://www.datadoghq.com/blog/postgresql-vacuum-monitoring/,里面相關的內容的是這么說的:
1. Large insert-only tables. Large insert-only tables are not automatically vacuumed (except for transaction-ID wraparound), because autovacuum is triggered by updates and deletes. This is generally a good thing, because it saves a great deal of not-very-useful work. However, it's problematic for index-only scans, because it also means the visibility map bits won't get set. I don't have a very clear idea what to do about this, but it's likely to need thought and work. For a first version of this feature, we'll likely have to rely on users to do a manual VACUUM in this case.
既然這種場景無法主從出發vacuum,那么這里就手動vacuum測試表,然后打開bitmap scan選項,繼續觀察此時的默認情況下,該查詢是不是可以走index only scan,這一次終於是預期的ix_c3上的index only scan了。
同時還有一個疑問:對表執行vacuum前后,index only scan的shared hit差別這么大?
上述得知在large-insert的情況下,不會觸發表上的vacuum,此時如果強制使用index only scan,因為索引上的沒有數據行的可見性信息(Index Only Scan operation must visit the heap to check if the row is visible.)所以在vacuum之前,強制使用index only scan的過程中,對於任何一行數據都要回表進行可見性判斷,因此會產生大量的shared hit。一旦vacuum之后,由於索引上更新了數據行的可見性,不需要回表判斷,因此shared hit會大幅度地降低。
3. 主動觸發vacuum.
Large insert-only tables are not automatically vacuumed,也就是大批量的插入無法主動發出vacuum,vacuum由update和delete產生,那么嘗試對表執行一些update或者delete操作,會不會主動觸發vacuum?
基於第一步的腳本,重新初始化測試表,在插入300W行數據后,刪除其中一部分數據,目前是讓delete操作觸發vacuum,然后再通過執行計划,觀察是否會想手動vacuum一樣,走index only scan。
經過三次刪除,完美觸發vacuum,執行計划有一開始bitmap scan更新為index only scan。
4. bitmp index scan VS index-only scan
參考這里https://www.cybertec-postgresql.com/en/killed-index-tuples/ 對 bitmap index scan 和 index-only scan的解釋
PostgreSQL 8.1 introduced the “bitmp index scan”. This scan method first creates a list of heap blocks to visit and then scans them sequentially.
This not only reduces the random I/O, but also avoids that the same block is visited several times during an index scan. PostgreSQL 9.2 introduced the “index-only scan”, which avoids fetching the heap tuple.
This requires that all the required columns are in the index and the “visibility map” shows that all tuples in the table block are visible to everybody.
bitmp index scan不僅可以避免隨機的IO操作,而且可以避免同一個頁面(在一個查詢執行過程中)被重復讀取(一個頁面中可能存在多條滿足查詢條件的元組,其他方式可能會多次讀取同一個頁面)。
index-only scan避免了從堆中讀取數據,但是他要求所有請求的字段都在索引中,並且“visibility map” 中顯示表塊中的所有元組對所有事物都是可見的,但是索引中並不包含元組的可見性。
本文通過一個看似不起眼的問題sql執行計划的分析,嘗試分析bitmap scan 和index only scan的差異以及選擇二者的原因,同時會涉index索引元組的可見性及vacuum沒有觸發的一些特殊場景。一個問題往往不是一個點,是一系列問題的合集,此事要躬行。
參考鏈接:
https://stackoverflow.com/questions/55651068/why-is-bitmap-scan-faster-than-index-scan-when-fetching-a-moderately-large-perce
https://ask.use-the-index-luke.com/questions/148/why-is-this-postgres-query-doing-a-bitmap-heap-scan-after-the-index-scan
http://rhaas.blogspot.com/2010/11/index-only-scans.html
https://smartkeyerror.com/PostgreSQL-MVCC-01
https://www.cnblogs.com/haylee/p/12206170.html
https://stackoverflow.com/questions/20386719/postgres-not-using-index-on-select-count-for-a-large-table