操作系統
清華大學ucore操作系統課筆記
全文思維導圖

1. 操作系統概述
1.1 什么是操作系統?
操作系統的定義
沒有公認的精確定義
-
一個控制程序
- 一個系統軟件
- 控制程序執行過程,防止錯誤和計算機的不當使用
- 執行用戶程序,給用戶程序提供各種服務
- 方便用戶使用計算機系統
-
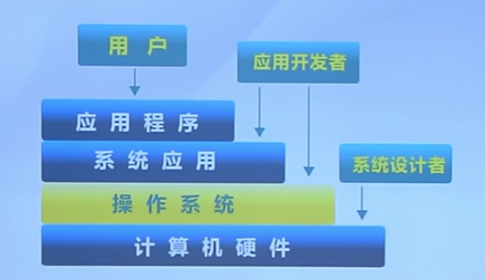
一個資源管理器
- 應用程序和硬件之間的中間層
- 管理各種計算機軟硬件資源
- 提供訪問計算機軟件硬件資源的高效手段
- 解決資源訪問沖突,保證資源公平使用
操作系統的地位
操作系統軟件的組成
- shell--命令行接口
- GUI--圖像用戶接口
- Kernel--系統內部
- 執行各種資源管理的功能
ucore教學操作系統內核
組成

操作系統內核特征
-
並發
計算機同時存在多個運行的程序,需要OS管理和調度
-
共享
同時”訪問“,互斥共享
-
虛擬
利用多道程序設計技術,讓每個用戶都覺得有一個計算機為他服務
-
異步
程序是走走停停的,推進速度不可知
只要運行環境相同,OS要確保程序運行結果的一致性
1.2 操作系統實例
三大家族
UNIX BSD

Linux

Windows

1.3 操作系統的演變
單用戶系統
時間:1945-1955
操作系統=裝載器+通用子程序庫
問題:昂貴組件的低利用率
批處理系統
時間:1955-1965
順序執行與批處理

多道程序系統
時間:1965-1980
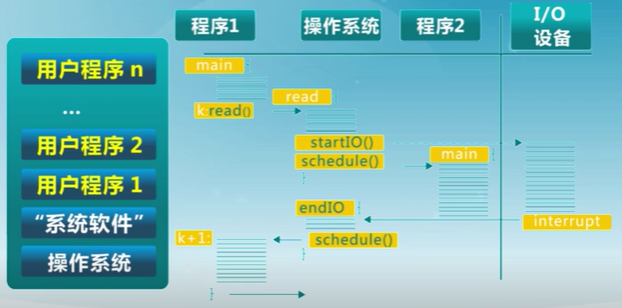
保持多個工作在內存中並且在各個工作之間復用CPU,由順序執行變成了多道程序的交替執行
多道系統只是為了讓CPU一直處於工作狀態,當目前程序出現I/O請求即暫時不再使用CPU時,CPU才去運行另一道程序。多道批處理系統的目的是為了解決人機矛盾及CPU和I/O設備速度不匹配的矛盾,提高系統的有效性(包括資源利用率和吞吐量),並不提供人機交互能力。
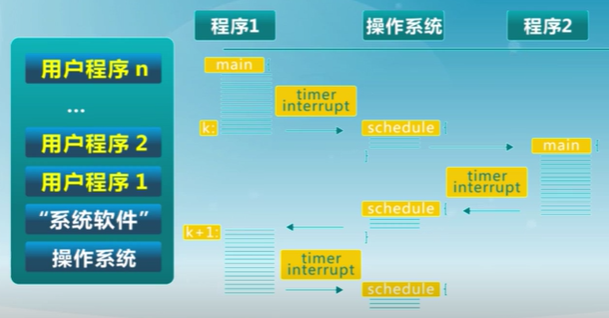
分時系統
時間:1970-
定時中斷用於工作對CPU的復用
程序運行公平性更好,提高短作業的速度
分時系統中會將處理器的時間分成短的時間片,定時會切換不同的程序執行。這與多道批處理系統有本質上的區別。
分時系統是實現人機交互的系統。
個人電腦操作系統
個人計算機:每個用戶一個系統
-
單用戶
-
利用率不再是關注點
-
重點是用戶界面和多媒體功能
-
很多舊的服務和功能不再存在
分布式操作系統
分布式計算機:每個用戶多個系統
-
網絡支持成為一個重要的功能
-
支持分布式服務
- 跨多系統的數據共享和協調
-
可能使用多個處理器
- 松、緊耦合系統
-
高可用性與可靠性的要求
計算機系統的演變

1.4 操作系統的結構
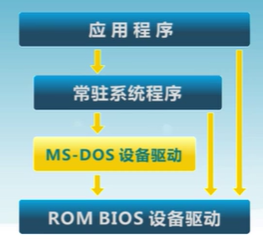
簡單結構
MS-DOS
在最小的空間,設計用於提供大部分功能(1981-1994)
-
沒有拆分模塊
-
雖然MS-DOS在接口和功能水平沒有很好地分離,主要用匯編匯編
-
每一種硬件對應一種操作系統,沒有通用的
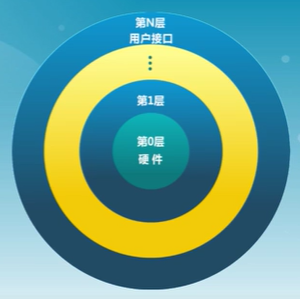
分層結構
-
操作系統分為很多層
- 每層建立在低層之上
- 最底層是硬件
- 最高層是用戶界面
-
每一層僅使用更低一層的功能(操作)和服務
UNIX操作系統與C語言
-
設計用於UNIX操作系統的編碼例程
-
”高級“系統編程語言創建可移植操作系統的概念
將操作系統的代碼分為兩部分:一部分與硬件平台無關的部分(高級語言),特定硬件平台相關的部分(匯編語言)。實現操作系統的可移植性。
ucore也是分層結構,本課程涉及到的部分(紅線部分)
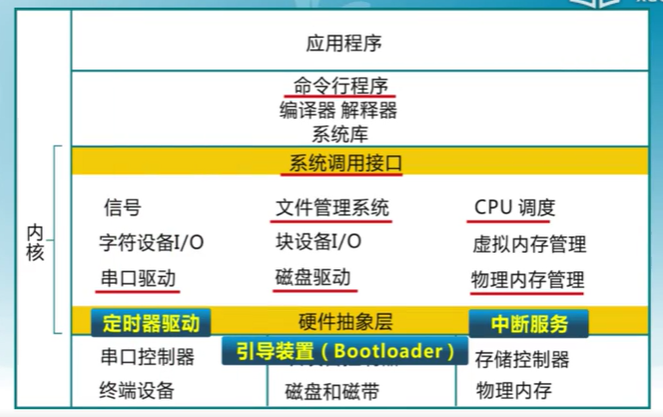
分層結構層次越來越復雜,會導致效率的下降
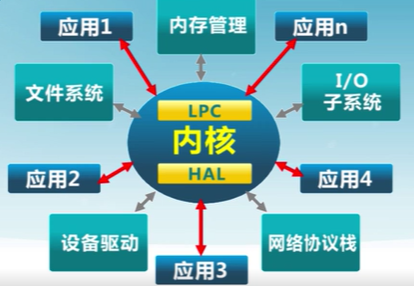
微內核結構(Microkernel)
盡可能把內核功能移到用戶空間
用戶模塊間的通信使用消息傳遞
好處:靈活安全
缺點:性能下降
外核結構(Exokernel)
讓內核分配機器的物理資源給多個應用程序,並讓每個程序決定如何處理這些資源。
(原來操作系統的功能是由用戶態的函數庫來提供)
程序能鏈接到操作系統庫(libOS)實現操作系統抽象
保護與控制分離
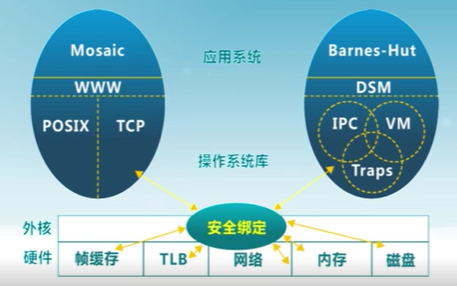
VMM(虛擬機管理器)
負責把真實的硬件虛擬成若干個虛擬的硬件,虛擬機管理器決定每個虛擬機可以使用哪些硬件資源

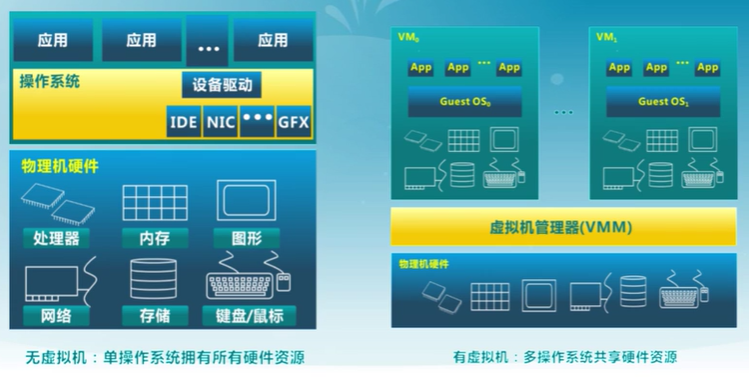
2. 啟動、中斷、異常和系統調用
2.1 啟動
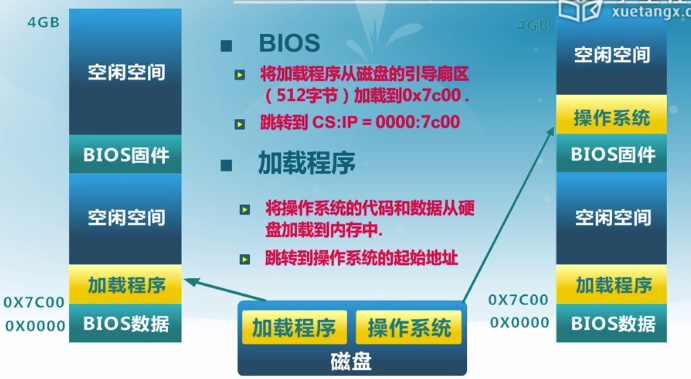
BIOS
- 計算機體系結構概述
- 計算機內存和硬盤布局
啟動時計算機內存和磁盤布局
ROM只讀存儲
實模式只有20位,地址空間為1mb

加載程序的內存地址空間
BIOS系統調用
BIOS以中斷調用的方式,提供了基本的I/O功能
- INT 10h: 字符顯示
- INT 13h: 磁盤扇區讀寫
- INT 15h: 檢測內存大小
- INT 16h: 鍵盤輸入
只能在x86的實模式下訪問
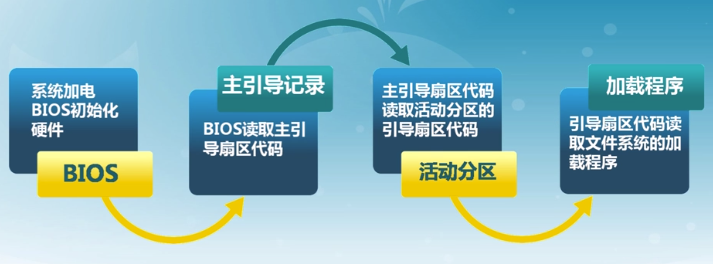
系統啟動流程
CPU初始化
- CPU加電穩定后從0XFFFF0讀第一條指令
- CS:IP = 0xf000:fff0
- 第一條指令是跳轉指令
- CPU初始狀態為16位實模式
- CS:IP是16位寄存器
- 指令指針PC = 16*CS +IP
- 最大地址空間是1MB
BIOS初始化
- 硬件自檢POST
- 檢測系統中內存和顯卡等關鍵部件的存在和工作狀態
- 查找並執行顯卡等接口卡BIOS,進行設置初始化
- 執行系統BIOS,進行系統檢測
- 檢測和配置系統中安裝的即插即用設備
- 更新CMOS中的擴展系統配置數據表ESCD(改寫硬件配置表)
- 按指定啟動順序從軟盤、硬盤或光驅啟動(交出控制權)
主引導記錄MBR格式
為了解決多分區啟動問題,選擇其中一個分區啟動
最多四個分區
- 啟動代碼:446字節
- 檢查分區表正確性
- 加載並跳轉到磁盤上的引導程序
- 硬盤分區表:64字節
- 描述分區狀態和位置
- 每個分區描述信息占據16字節
- 結束標志:2字節(55AA)
- 主引導記錄的有效標志

分區引導扇區格式
- 跳轉指令:跳轉到啟動代碼
- 與平台相關代碼
- 文件卷頭:文件系統描述信息
- 啟動代碼:跳轉到加載程序 (放在硬盤上的,可以改)
- 結束標注:55AA

加載程序(BootLoader)
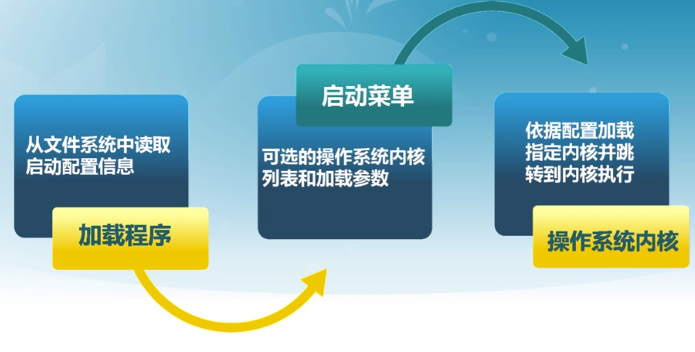
系統啟動規范
BIOS
- 固化到計算機主板上的程序
- 包括系統設置、自檢程序和系統自啟動程序
- BIOS-MBR(最多四個分區)、BIOS-GPT(全局分區表大於4個)、PXE(網絡啟動)
UEFI
統一可擴展固定接口
可信度檢查
- 接口標准
- 在所有平台上一致的操作系統啟動服務
2.2 中斷、異常和系統調用
為什么需要中斷、異常和系統調用?
-
在計算機運行中,內核是被信任的第三方
-
只有內核可以執行特權指令
-
方便應用程序
中斷和異常希望解決的問題
- 當外設連接計算機時,會出現什么現象?
- 當應用程序處理意想不到的行為時,會出現什么現象?
系統調用希望解決的問題
- 用戶應用程序是如何得到系統服務?
- 系統調用和功能調用的不同之處是是什么?
內核的進入與退出
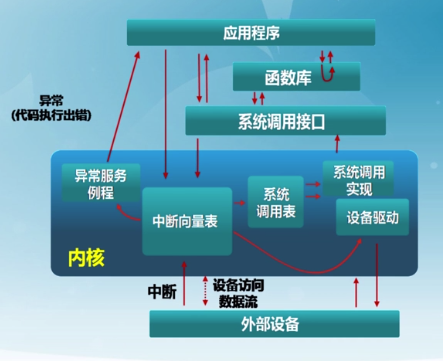
定義
系統調用(system recall)
- 應用程序主動向操作系統發出的服務請求
異常(exception)
- 非法指令或者其他原因導致當前指令執行失敗(如內存出錯)后的處理請求
中斷(hardware interrupt)
- 來自硬件設備的處理請求
三者比較
源頭
- 中斷:外設
- 異常:應用程序意想不到的行為(內核代碼也可能出現問題)
- 系統調用:應用程序請求提供操作服務
響應方式
- 中斷:異步(不會被感知)
- 異常:同步(必須處理異常)
- 系統調用:異步或同步
處理機制
- 中斷:持續,對用戶應用程序是透明的
- 異常:殺死或重新執行意想不到的應用程序指令
- 系統調用:等待或持續
中斷處理機制
這里的中斷是指三種形式的總稱
硬件處理
- 在CPU初始化時設置中斷使能標志(初始化時不進行處理)
- 依據內部或外部事件設置中斷標志
- 依據中斷向量調用相應中斷服務例程
內核軟件
- 現場保護(編譯器)
- 中斷服務處理(服務例程)
- 清楚中斷標記(服務例程)
- 現場恢復(編譯器)
中斷嵌套
硬件中斷服務例程可被打斷
- 不同硬件中斷源可能硬件中斷處理時出現
- 硬件中斷服務例程中需要臨時禁止中斷請求
- 中斷請求會保持到CPU做出響應
異常服務例程可被打斷
- 異常服務例程執行時可能出現硬件中斷
異常服務例程可嵌套
- 異常服務例程可能出現缺頁
系統調用
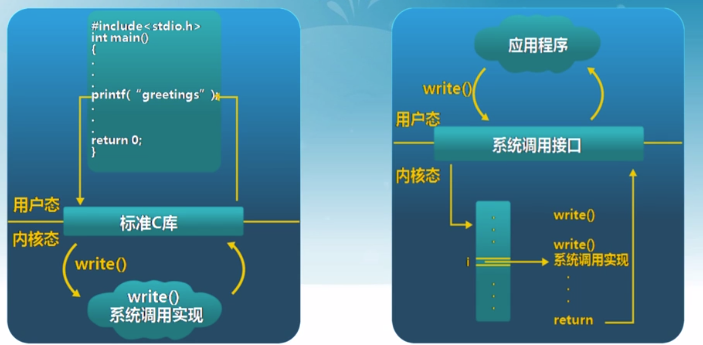
-
操作系統服務的編譯接口
-
通常由高級語言編寫(c/c++)
-
程序訪問通常是通過高層次的API接口而不是直接進行系統調用
-
常見的應用程序編程接口(API)
Win32 API用於windowsPOSIX API用於POSIX-based systems(包括UNIX,LINUX,Mac OS X的所有版本)Java API用於JAVA虛擬機(JVM)
系統調用的實現
-
每個系統調用對應一個系統調用號
- 系統調用接口根據系統調用號來維護表的索引
-
系統調用接口調用內核態中的系統調用功能實現,並返回系統調用的狀態和結構
-
用戶不需要知道系統調用的實現
- 需要設置調用參數和獲取返回結果
- 操作系統接口的細節大部分都隱藏在應用編程接口后
- 通過運行程序支持的庫來管理
函數調用和系統調用的不同之處
- 系統調用
INT和IRET指令用於系統調用- 系統調用時,堆棧切換和特權級的轉換
- 函數調用
CALL和RET用於常規調用- 常規調用時沒有堆棧切換
三者開銷
開銷大於函數調用
中斷、異常和系統調用開銷
- 引導機制
- 建立內核堆棧
- 驗證參數
- 內核態映射到用戶態的地址空間
- 更新頁面映射權限
- 內核態獨立地址空間
TLB
系統調用示例
ucore中庫函數read()的功能是讀文件
user/libs/file.h: int read(int fd, void *buf, int length)
庫函數read()的參數和返回值
int fd—文件句柄void *buf—數據緩沖區指針int length—數據緩沖區長度int return_value: 返回讀出數據長度
庫函數read()使用示例
in sfs_filtest1.c: ret = read(fd, data, len)
read函數實現
-
kern/trap/tranpentry.S: alltraps()獲取中斷信息組成的數據結構 -
kern/trap/trap.c: trap()
tf->trapno == T_SYSCALL(系統調用對應的中斷向量) -
kern/syscall/syscall.c: syscall()
tf->tf_regs.reg_eax == SYS.read(系統調用編號) -
kern/syscal/syscall.c: sys_read() 從
tf->sp獲取fd, buf, length -
kern/fs/sysfile.c: sysfile_read() 讀取文件
-
kern/trap/trapentry.S: trapret()
IRET
3. 內存管理
3.1 計算機體系結構/內存層次
計算機體系結構
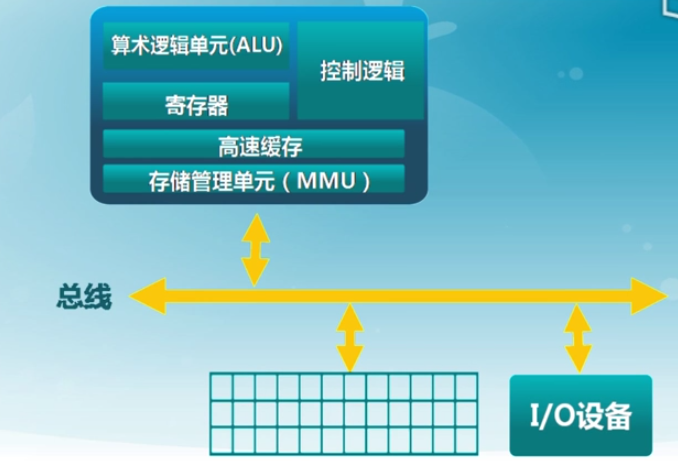
內存層次
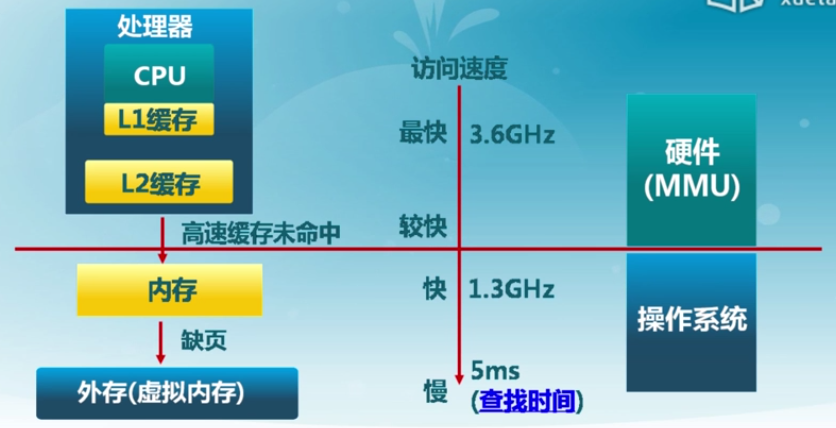
操作系統的內存管理方式
-
抽象
-
保護
-
共享
-
虛擬化
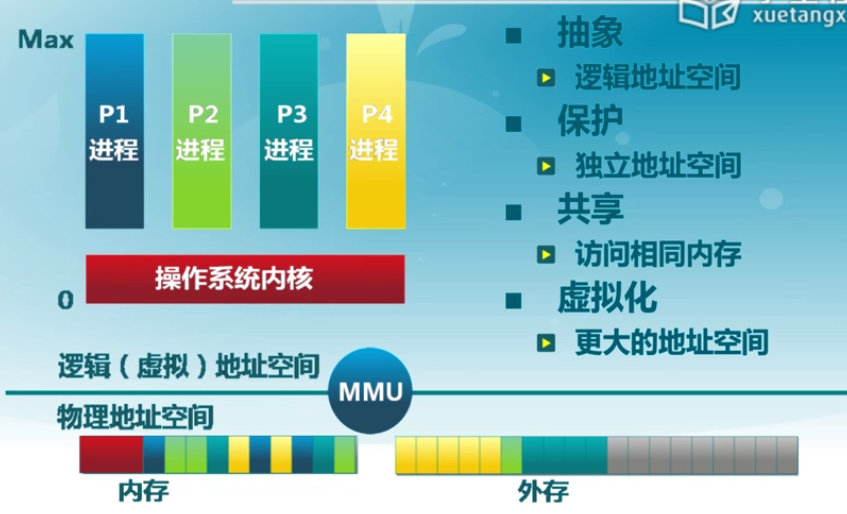
內存管理方式
- 重定位(relocation)一個進程占一個連續的地址空間(太大不好放置)
- 分段(segmentation)將程序分段,段內地址連續
- 分頁(paging)
- 虛擬存儲(virtual memory)
- 目前多數系統如linux 采用按需頁式虛擬存儲
實現高度依賴硬件
- 與計算機存儲架構耦合
- MMU(內存管理單元):處理CPU存儲訪問請求的硬件
3.2 地址空間 & 地址生成
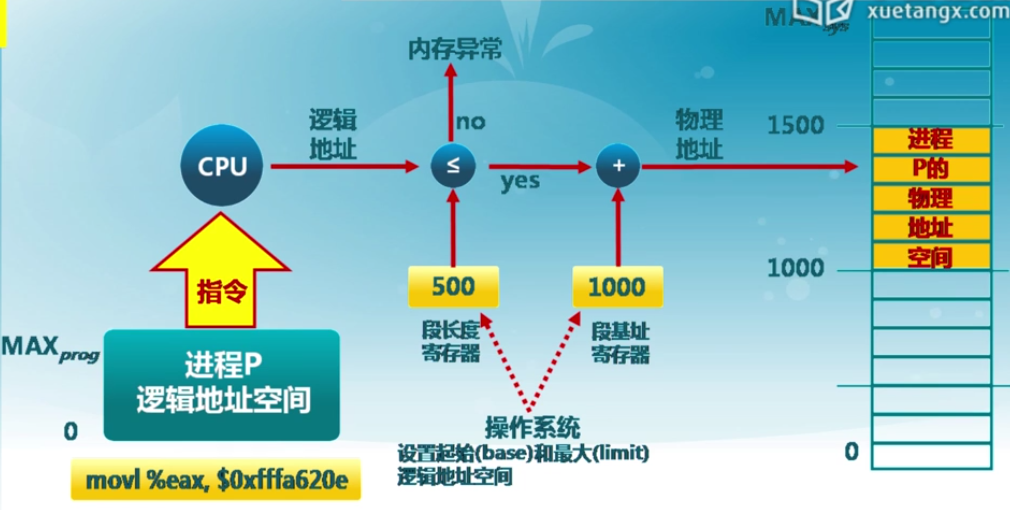
地址空間定義
物理地址空間——硬件支持的地址空間
- 起始地址0,直到\(MAX_{sys}\)
邏輯地址空間——在CPU運行的進程看到的地址
- 起始地址0,直到\(MAX_{prog}\)
邏輯地址生成
編譯->匯編->鏈接->程序加載(重定位)
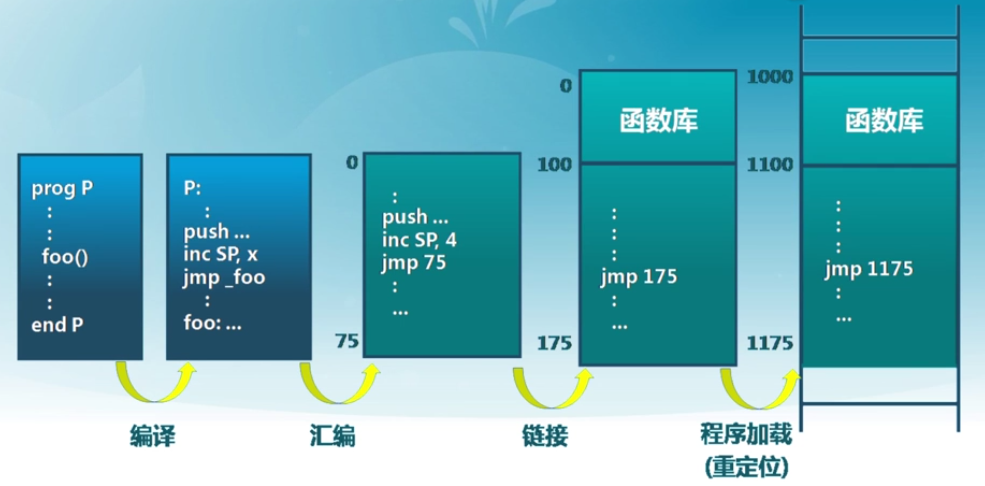
地址生成時機和限制
- 編譯時
- 假設起始地址已知
- 如果起始地址改變,必須重新編譯
- 加載時
- 編譯時起始位置未知,編譯器需生成可重定位的代碼(relocatable code)
- 加載時,生成絕對地址
- 執行時
- 執行時代碼可移動
- 虛地址轉換(映射)硬件支持
地址生成過程
- CPU
- ALU:需要邏輯地址的內容
- MMU:進行邏輯地址和物理地址的轉換
- CPU控制邏輯:給總線發送物理地址請求
- 內存
- 發送物理地址的內容給CPU
- 或接收CPU數據到物理地址
- 操作系統
- 建立邏輯地址LA和物理地址PA的映射
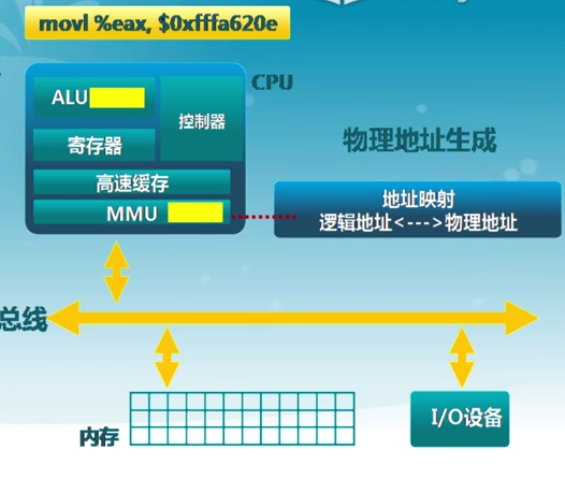
地址檢查
3.3 連續內存分配
給進程分配一塊不小於指定大小的連續的物理內存區域(重定位)
內存碎片
空閑內存不能被利用
外部碎片:分配單元之間的未被使用內存
內部碎片:分配單元內部的未被使用內存,取決於分配單元大小是否要取整
動態分配
動態分區分配
- 當程序被加載執行時,分配一個進程指定大小可變的分區(塊,內存塊)
- 分區的地址是連續的
操作系統需要維護的數據結構
- 所有進程的已分配分區
- 空閑分區(empty-blocks)
動態分區分配策略
最先匹配
找到第一個滿足的就行
原理&實現
- 空閑分區列表按照地址順序排序
- 分配過程中,搜索一個合適的分區(大於指定大小)
- 釋放分區時,檢查是否可與臨近的空閑分區合並
優點
- 簡單
- 在高地址空間有大塊的空閑分區
缺點
- 外部碎片
- 分配大塊時較慢
最佳匹配
遍歷一個最佳的
原理&實現
- 空閑分區列表按照大小排序
- 分配時,查找一個合適的分區
- 釋放時,查找並且合並臨近的空閑分區(如果找到)
優點
- 大部分分配的尺寸較小時,效果很好
- 可避免大的空閑分區被拆分
- 可減小外部碎片的大小
- 相對簡單
缺點
- 外部碎片
- 釋放分區較慢
- 容易產生很多無用的小碎片
最差匹配
找到最大空閑空間
原理&實現
- 空閑分區列表按由大到小排序
- 分配時,選最大的分區
- 釋放時,檢查是否可與臨近的空閑分區合並,進行合並,並調整空閑分區列表順序
優點
- 中等大小的分配較多時,效果最好
- 避免出現太多的小碎片
缺點
- 釋放分區較慢
- 外部碎片
- 容易破壞大的空閑分區,因此難以分配大的分區
碎片整理
通過調整進程占用的分區位置來減少或避免分區碎片
碎片緊湊(compaction)
- 通過移動分配給進程的內存分區,以合並外部碎片
- 碎片緊湊的條件
- 所有的應用程序可動態重定位
- 解決的問題
- 運行時不能搬動
- 開銷
分區對換(swap in/out)
通過搶占並回收處於等待狀態進程的分區,以增大可用內存空間
需要解決的問題?
- 交換哪個進程
開銷大
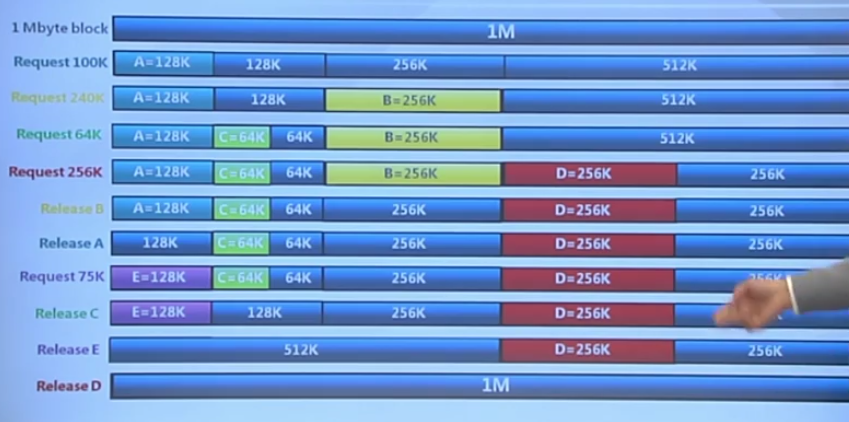
3.4 伙伴系統
buddy system
整個可分配的分區大小為 \(2^u\),需要的分區大小\(s\)
- 若 \(2^{u-1} < s \leq 2^u\),把整個塊分配給該進程
- 若 \(s \leq 2^{u-1}\),將當前空閑分區等分為兩個大小相同的空閑分區,重復划分,直到大於0.5倍區域
伙伴系統的實現
數據結構
- 空閑塊按大小和起始地址組織成二維數組
- 初始狀態:只有一個空閑塊
分配過程
- 由小到大在空閑塊數組中找最小的可用空閑塊
- 如空閑塊過大,對可用空閑塊進行二等分,直到得到合適的可用空閑塊
釋放過程
- 把釋放的塊放入空閑塊數組
- 合並滿足合並條件的空閑塊
合並條件
- 大小相同\(2^i\)
- 地址相鄰
- 起始地址較小的塊的起始地址必須是\(2^{i+1}\)的倍數
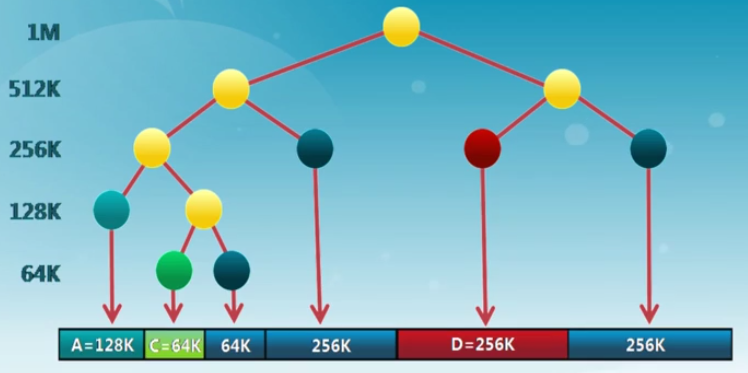
用於做內核的分配
例子
3.5 非連續內存分配
連續內存分配缺點
- 分配給程序的物理內存必須連續
- 存在外碎片和內碎片
- 內存分配的動態修改困難
- 內存利用率低
設計目標
提高內存利用效率和管理靈活性
- 允許一個程序使用非連續的物理地址空間
- 允許共享代碼與數據
- 支持動態加載和動態鏈接
實現
需要解決的問題
- 如何實現虛擬地址和物理地址的轉換
- 軟件實現(靈活,開銷大)
- 硬件實現(夠用,開銷小)
- 非連續分配的硬件輔助機制
- 如何選擇非連續分配中的內存分塊大小
- 段式存儲管理(segmentation)
- 頁式存儲管理(paging)
- 如何選擇非連續分配中的內存分塊大小
3.5 段式存儲管理
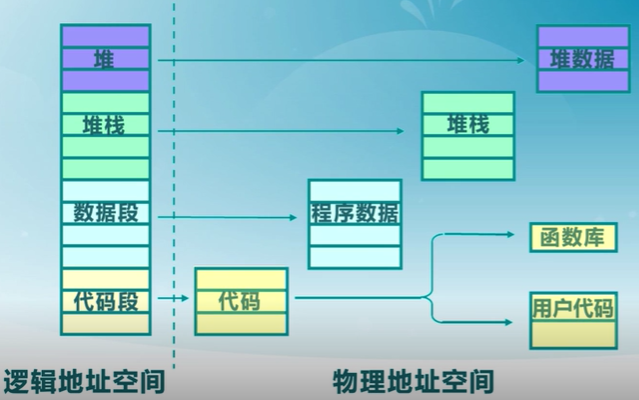
段地址空間
進程的段地址空間由多個段組成
- 主代碼段
- 子模塊代碼段
- 公用庫代碼段
- 堆棧段(stack)
- 堆數據(heap)
- 初始化數據段
- 符號表等
段式存儲的目的:更細粒度和靈活的分離與共享
段內需要連續,段之間不連續
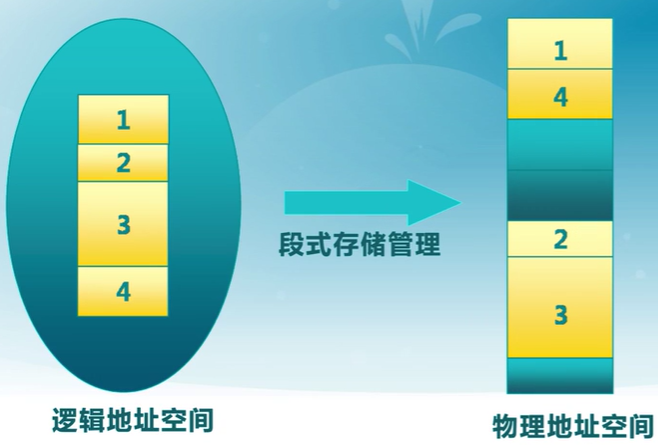
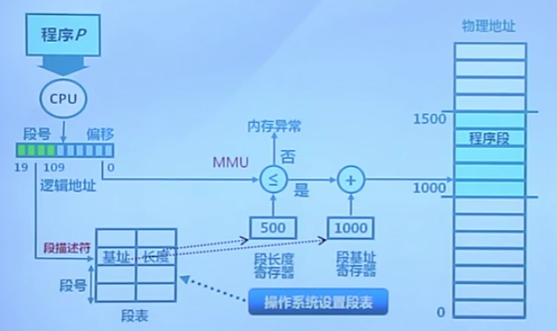
段訪問機制
段的概念
- 段表示訪問方式和存儲數據等屬性相同的一段地址空間
- 對應一個連續的內存“塊”
- 若干個段組成進程邏輯地址空間
段訪問
邏輯地址由二元組(s, addr)表示
- s: 段號
- addr: 段內偏移
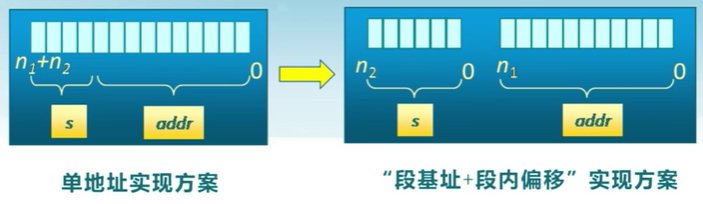
段訪問的硬件實現
3.6 頁式存儲管理
概念
頁幀(幀、物理頁面,Frame,Page Frame)
- 把物理地址空間划分為大小相同的基本分配單位
- 2的n次方,如512,4096,8192
- 物理內存被划分成大小相等的幀
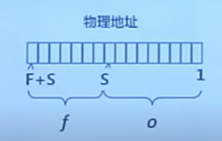
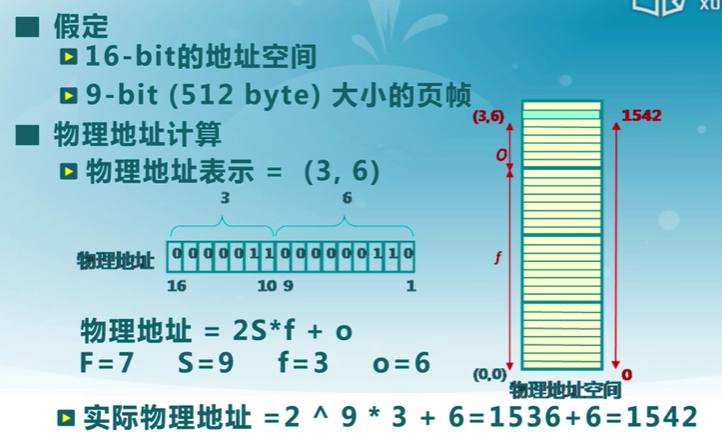
- 內存物理地址的表示:二元組\((f, o)\)
- \(f\)——幀號(\(F\)位,共有\(2^F\)個幀)
- \(o\)——幀內偏移(\(S\)位,每幀有\(2^S字節\))
- 物理地址 \(= f * 2^S + o\)
計算實例
頁面(頁、邏輯頁面,Page)
-
進程邏輯地址空間被划分為大小相等的頁
-
頁內偏移 = 幀內偏移
-
通常:頁號大小不等於幀號大小
-
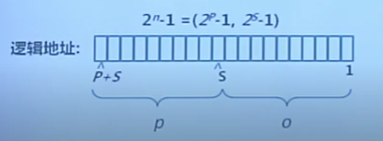
進程邏輯地址的表示:二元組 \((p, o)\)
- \(p\)——頁號(\(P\)位,共有\(2^P\)個幀)
- \(o\)——頁內偏移(\(S\)位,每幀有\(2^s字節\))
- 虛擬地址 \(= p * 2^S + o\)

頁面到頁幀
- 邏輯地址到物理地址
- 頁表
- MMU/TLB
地址轉換
- 頁到幀的映射
- 邏輯地址中的頁號是連續的
- 物理地址中的幀號是不連續的
- 不是所有的頁都有對應的幀
轉換過程

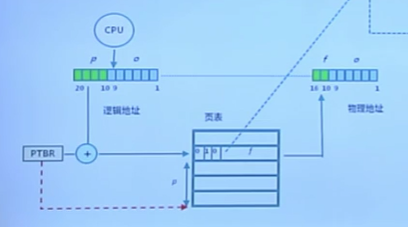
3.7 頁表
頁表結構
-
每個進程都有一個頁表
- 每個頁面對應一個頁表項
- 隨進程運行狀態而動態變化
- 頁表基址寄存器(PTBR:Page Table Base Register)(存儲基地址位置)
- 頁表項組成:
- 幀號: f
- 頁表項標志:
- 存在位 resident bit
- 修改位 dirty bit
- 引用位 clock / reference bit
頁表轉換實例
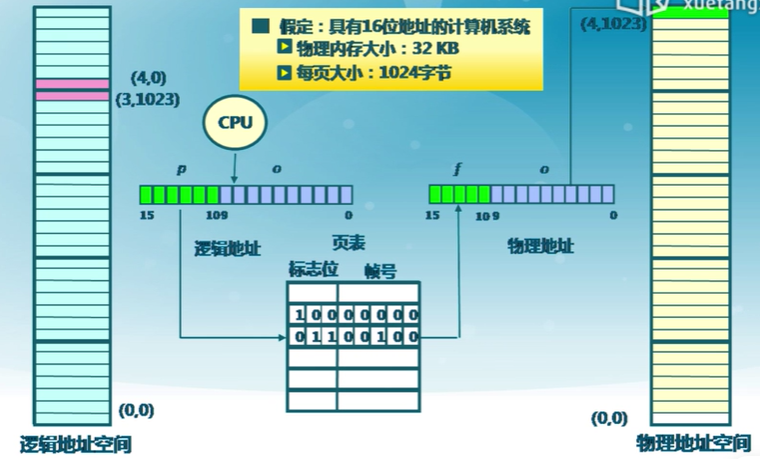
性能問題
- 內存訪問性能問題
- 訪問一個內存單元需要2次訪問
- 第一次訪問:獲取頁表項
- 第二次訪問:訪問數據
- 訪問一個內存單元需要2次訪問
- 頁表大小問題
- 頁表可能非常大
- 64位機器如果每頁1024字節,那么一個頁表的大小會是多少?
- 如何處理?
- 緩存(Caching)(減少訪存次數,快表)
- 間接(Indirection)訪問(多級頁表)
快表TLB
translation look-aside Buffer
緩存近期訪問的頁表項
-
TLB使用關聯存儲(associateive memory)實現,具備快速訪問性能
-
如果TLB命中,物理頁號可用很好被獲取
-
未命中,對應的表項被更新到TLB中

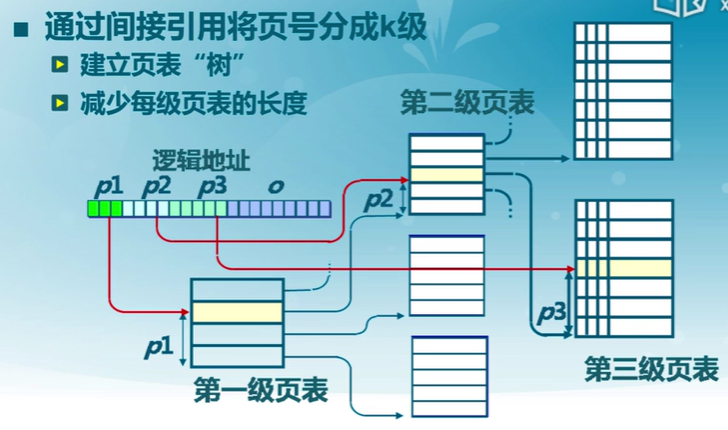
多級頁表
通過間接引用將頁號分成k級
- 建立頁表“樹”
- 減少每級頁表的長度
- 通過存在位,若不存在,則不構建下一級的頁表
實例

反置頁表
減少頁表存儲空間
大地址空間(64-bits)系統,多級頁表變得繁瑣
- 比如:5級頁表
- 邏輯(虛擬)地址空間增長速度快於物理地址空間
頁寄存器和反置頁面的思路
- 不讓頁表與邏輯地址空間的大小相對應
- 讓頁表與物理地址空間的大小相對應
頁寄存器
page registers
物理幀直接與頁寄存器關聯
每個物理幀與一個頁寄存器(page register)關聯,寄存器內容包括:
- 使用位:此幀是否被進程占用
- 占用頁號:對應的頁號p
- 保護位: 標記可讀可寫
頁寄存器示例
- 物理內存大小:4096*4096 = 4 K * 4 KB = 16 MB
- 頁面大小:4096 bytes = 4 KB
- 頁幀數:4096 = 4 K
- 頁寄存器使用的空間(假設每個頁寄存器占8字節):
- 8 * 4096 = 32 KB
- 頁寄存器帶來的開銷:
- 32 K / 16 M = 0.2%
- 虛擬內存的大小:任意
優點
- 頁表大小相對於物理內存而言很小
- 頁表大小與邏輯地址空間大小無關
缺點
- 頁表信息對調后,需要依據幀號可找頁號
- 在頁寄存器中搜索邏輯地址的頁號
頁寄存器中的地址轉換
-
對邏輯地址進行Hash映射,以減小搜索范圍
-
需要解決可能的沖突
用快表緩存頁表項后的頁寄存器搜索步驟
- 對邏輯地址進行Hash變換
- 在快表中查找對應頁表項
- 有沖突時遍歷沖突項鏈表
- 查找失敗時,產生異常
快表的限制
- 快表的容量限制
- 功耗限制(StrongARM上快表功耗占27%)
反置頁表
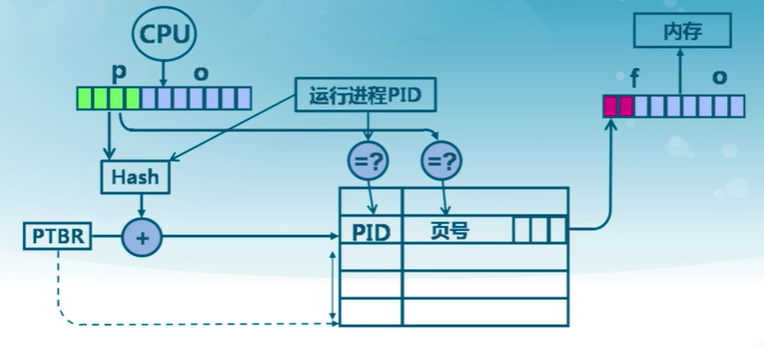
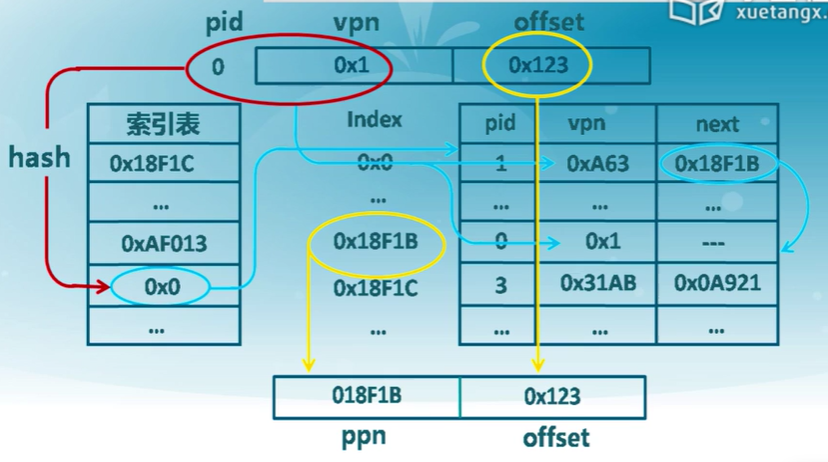
所有的進程共同使用一張頁表,這張頁表中的條目的數量和內存中物理的頁框的數量是一樣的。
反置頁表中每個條目擁有以下字段:
- 頁號
- 進程ID
- 控制位
- 鏈接指針---如果出現進程共享內存的情況,就會用到鏈接指針
基於Hash映射值查找對應頁表項中的幀號
- 進程標識與頁號的Hash值可能有沖突
- 頁表項中包括保護位、修改位、訪問位和存在位等表示
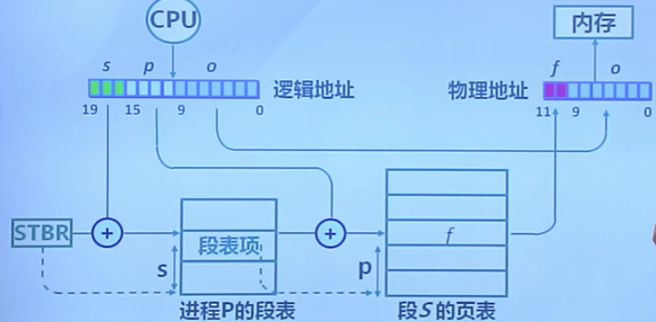
3.8 段頁式存儲管理
段式存儲在內存保護方面有優勢,頁式存儲在內存利用和優化轉移到存儲方面有優勢
在段式存儲管理基礎上,給每個段加一級頁表
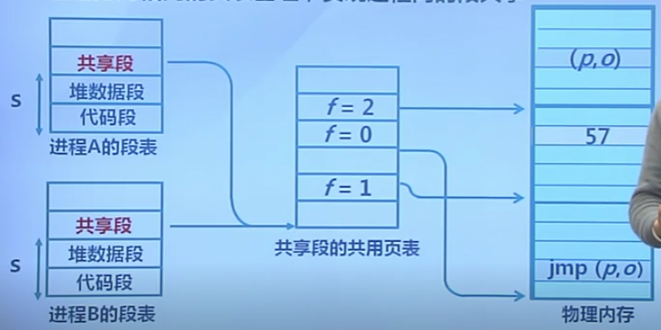
內存共享
通過指向相同的頁表基地址,實現進程間的段共享
4. 虛擬存儲
4.1 需求背景
程序規模的增長速度遠遠大於存儲器容量的增長速度
理想的存儲器
- 容量大,速度快,價格低的非易失性存儲器
實際存儲器
-
存儲器層次結構
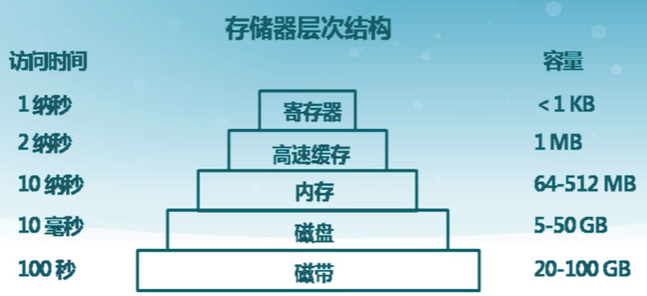
存儲抽象
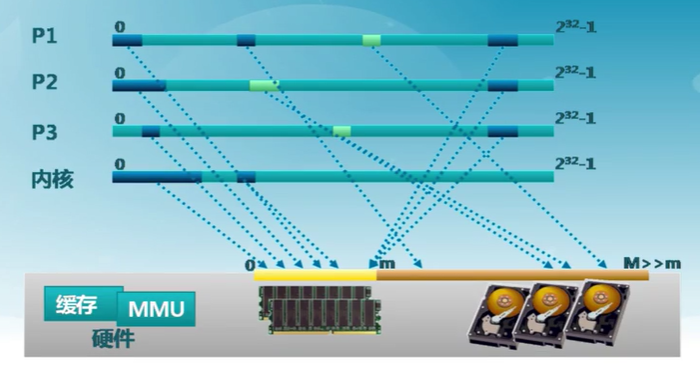
計算機系統時常出現內存空間不夠用
-
覆蓋
應用程序手動把需要的指令和數據保存在內存中
-
交換
操作系統自動把暫時不能執行的程序保存到外存中
-
虛擬存儲
在有限容量的內存中,以頁為單位自動裝入更多更大程序
虛擬存儲技術的目標
只把部分程序放到內存中,從而運行比物理內存大的程序
- 由操作系統自動完成
實現進程在內存與外存之間的交換,從而獲取更多的空閑內存空間
- 在內存和外存之間只交換進程的部分內容
4.2 覆蓋技術
在較小的可用內存中運行較大的程序
實現方法
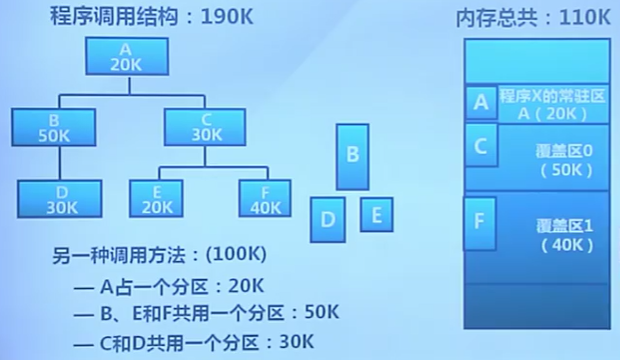
依據程序邏輯結構,將程序划分為若干功能相對獨立的模塊,將不會同時執行的模塊共享同一塊內存區域。
- 必要部分的代碼和數據常駐
- 可選部分放在其他程序模塊中,在需要的時候裝載
- 不存在調用關系的模塊,可相互覆蓋,共同用同一塊內存區域
示例
不足
-
增加編程困難
-
增加執行時間
4.3 交換技術
增加正在運行或需要運行的程序的內存
實現方法
-
可將暫時不能運行的程序放到外存
-
換入換出的基本單位
- 整個進程的地址空間
-
換出
- 把一個進程的整個地址空間保存到外存
-
換入
- 將外存中某進程的地址空間讀入到內存

問題
- 何時交換?
- 只當內存空間不夠或有不夠的可能時換出
- 交換區大小
- 存放所有用戶進程的所有內存映像的拷貝
- 換入之后的重定位(地址位置可能發生了改變)
- 采用動態地址映射的方法
覆蓋與交換的比較
覆蓋
- 只能發生在沒有調用關系的模塊間
- 程序員需要給出模塊間的邏輯覆蓋結構
- 發生在運行程序的內部模塊間
交換
- 以進程位單位
- 不需要模塊間的邏輯覆蓋結構
- 發生在內存進程間
4.4 局部性原理
principle of locality
程序在執行過程中的一個較短時期,所執行的指令地址和指令的操作數地址,分別局限於一定區域
-
時間局部性
一條指令或者數據的一次執行和下次執行(訪問)都集中在一個較短的時期內
-
空間局部性
當前指令和臨近的幾條指令,都集中在一個較小的區域
-
分支局部性
一條跳轉指令的兩次執行,很可能跳到相同的內存位置
4.5 虛擬存儲概念
將不常用的部分內存塊暫存到外存
原理
-
裝載程序時
只將當前指令執行需要的部分頁面或段裝入內存
-
指令執行中需要的指令和數據不在內存中稱為缺頁或缺段
處理器通知操作系統將相應的頁面或段調入內存
-
操作系統將內存中暫時不用的頁面或段保存到外存中去
實現方式
- 虛擬頁式存儲
- 虛擬段式存儲
基本特征
- 不連續性
- 物理內存分配非連續
- 虛擬地址空間使用非連續
- 大用戶空間
- 提供給用戶的虛擬內存大於實際的物理內存
- 部分交換
- 虛擬存儲只對部分虛擬地址空間進行調入和調出
支持技術
- 硬件
- 頁式或短時存儲中的地址轉換機制
- 操作系統
- 管理內存和外存間頁面或段的換入和換出
4.6 虛擬頁式存儲
在頁式存儲管理的基礎上,增加請求調頁和頁面置換
思路
- 當用戶程序裝載到內存運行時,只裝入部分頁面,就啟動程序
- 進程在運行中發現有需要的代碼或數據不在內存時,則向系統發出缺頁異常請求
- 操作系統在處理缺頁異常時,將外存中相應的頁面調入內存,使得進程能繼續進行
虛擬頁式存儲中的地址轉換
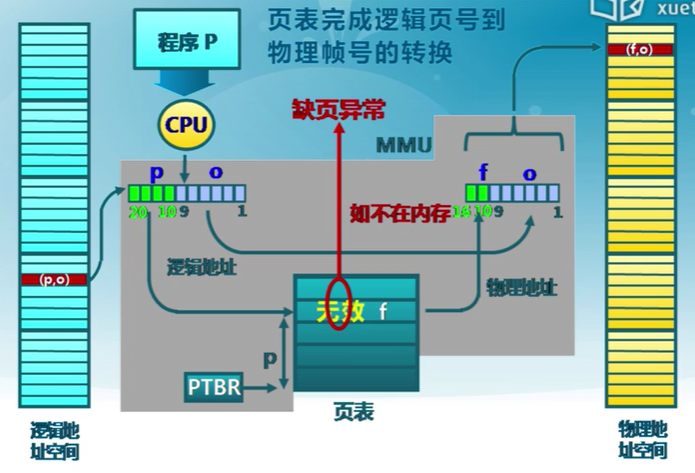
頁表項結構
- 駐留位:表示該頁是否在內存
- 1:在內存,頁表項有效,可用
- 0:在外存,訪問該頁表項將導致缺頁異常
- 修改位:表示在內存中的該頁是否被修改過
- 回收該物理頁面時。據此判斷是否要把它的內容寫回
- 訪問位:表示該頁面是否被訪問過(讀或寫)
- 用於頁面置換算法
- 保護位:表示該頁的訪問方式
- 可讀可寫等
虛擬頁式存儲示例
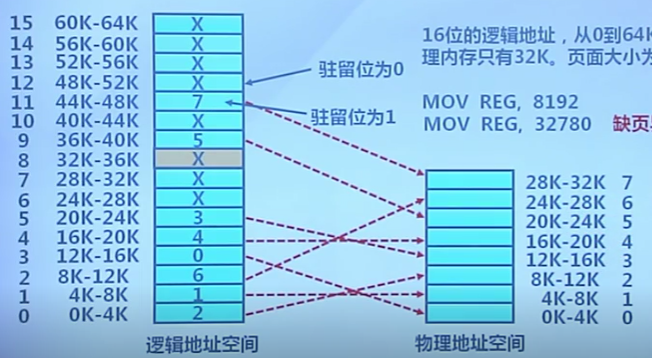
X86頁表結構

4.7 缺頁異常
處理流程
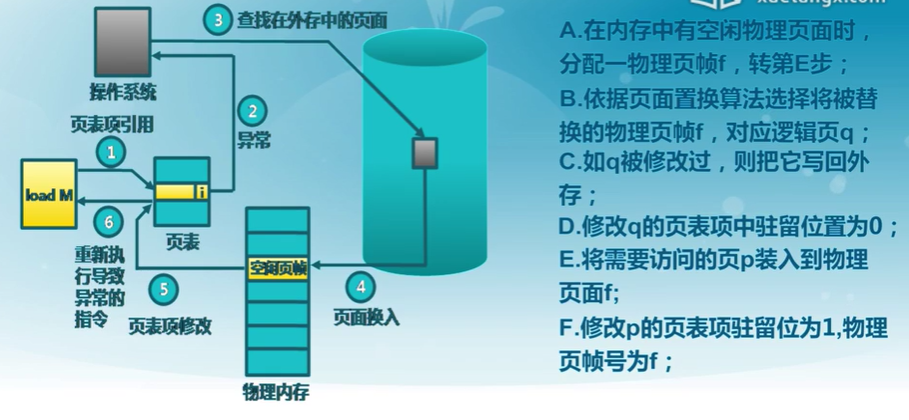
外存管理
- 何處保存未被映射的頁?
- 方便找到外村中的頁面內容
- 交換空間(磁盤或者文件)
- 采用特殊格式存儲未被映射的頁面
- 虛擬頁式存儲中的外存選擇
- 代碼段:可執行二進制文件
- 動態加載的共享庫程序段:動態調用的庫文件
- 其他段:交換空間
虛擬頁式存儲管理的性能
-
有效存儲訪問時間(effective memory access time EAT)
EAT = 訪存時間*(1-p)+缺頁異常處理時間 *缺頁率 p
5. 置換算法
5.1 概念
當出現缺頁異常,需調入新頁面而內存已滿時,置換算法選擇被置換的物理頁面
設計目標
-
盡可能減少頁面的調入調出次數
-
把未來不再訪問或短期內不訪問的頁面調出
頁面鎖定(frame locking)
- 描述必須常駐內存的邏輯頁面
- 操作系統的關鍵部分
- 要求響應速度的代碼和數據
- 頁表中的鎖定標注位 lock bit
評價方法
- 記錄進程訪問內存的頁面軌跡
- 評價方法
- 模擬頁面置換行為,記錄產生缺頁的次數
- 更少的缺頁,更好的性能
分類
- 局部頁面置換算法
- 置換頁面的選擇范圍僅限於當前進程占用的物理頁面內
- 最優算法、先進先出算法、最近最久未使用算法
- 時鍾算法、最不常用算法
- 全局頁面置換算法
- 置換頁面的選擇范圍是所有可換出的物理頁面
- 工作集算法、缺頁率算法
5.2 局部頁面置換算法
最優置換算法
置換在未來最長時間不訪問頁面
算法實現
- 缺頁時,計算內存中每個邏輯頁面的下次訪問時間
- 選擇未來最長時間不訪問的頁面
算法特征
- 缺頁最少,是理想情況
- 無法預知訪問時間,無法實現
- 作為置換算法的性能評價依據
算法示例

先進先出算法
First-In, First-out, FIFO
算法實現
- 維護一個記錄所有位於內存中的邏輯頁面鏈表
- 鏈表元素按駐留內存的時間排序,鏈首最長,鏈尾最短
- 出現缺頁是,選擇鏈首進行置換,新頁面加到鏈尾
特征
- 實現簡單
- 性能較差,調出的頁面可能是經常訪問的
- 進程分配物理頁面數增加時,缺頁並不一定減少(Belady現象)
- 很少單獨使用
算法示例
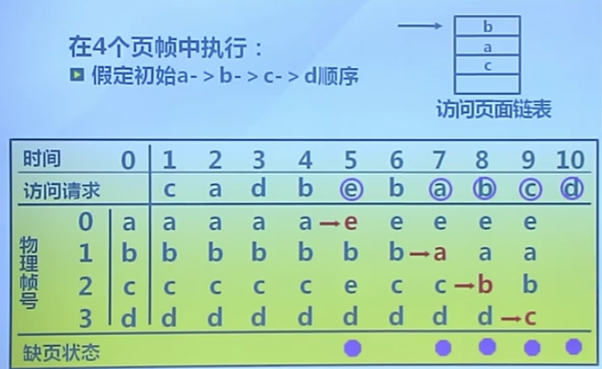
最近最久未使用算法
Least Recently Used, LRU
算法思路
- 選擇最長時間沒有被引用的頁面進行置換
- 如某些頁面長時間未被訪問,則再將來還可能會長時間不會被訪問
算法實現
- 缺頁時,計算內存中每個邏輯頁面的上次訪問時間
- 選擇上一次使用到當前時間最長的頁面
特征
- 最優置換算法的近似
算法示例
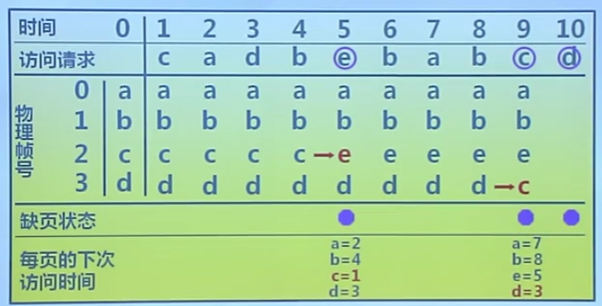
LRU算法的可能實現方法
頁面鏈表
- 系統維護一個按最近一次訪問時間排序的頁面鏈表
- 鏈表首節點是最近使用的頁面
- 鏈表尾節點是最久未使用的頁面
- 訪問內存時,找到相應的頁面,並把它移到鏈表之首
- 缺頁時,置換鏈表尾節點的頁面
活動頁面棧
- 訪問頁面時,將此號壓入棧頂,並將棧內相同的頁號抽出
- 缺頁時,置換棧底的頁面
特征
- 開銷大
算法示例
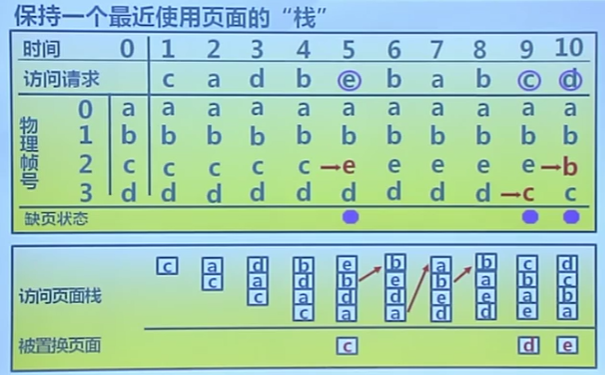
時鍾置換算法
Clock
僅對頁面的訪問情況進行大致統計
數據結構
- 在頁表項增加訪問位
- 頁面組織成環形鏈表
- 指針指向最先調入的頁面
算法
- 訪問頁面時,在頁表項記錄頁面訪問情況
- 缺頁時,從指針處開始順序查找未被訪問的頁面進行置換
特征
算法是LRU和FIFO的折中
算法實現
- 頁面裝如內存時,訪問位初始化位0
- 訪問頁面時,訪問位置1
- 缺頁時,從指針當前位置順序檢查環形鏈表
- 訪問位為0,則置換該頁
- 訪問位為1,則訪問位置0,並指針移動到下一頁面,直到找到可置換的頁面
算法示例
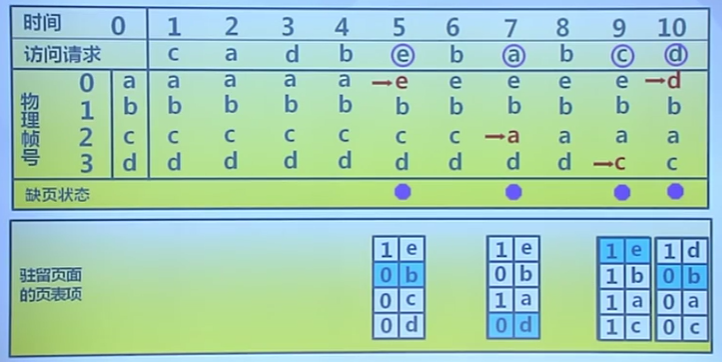
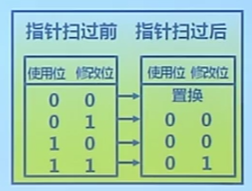
改進的Clock算法
減少修改頁的缺頁處理開銷
算法
- 在頁面中增加修改位,並在訪問時進行相應修改
- 缺頁時,修改頁面標志位,以跳過有修改的頁面
算法示例
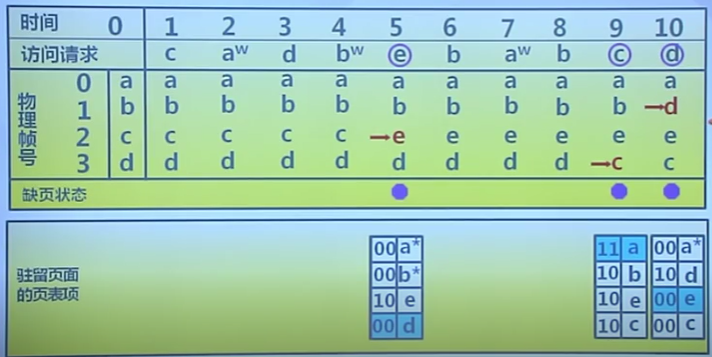
最不常用算法
LFU Least Frequently Used
缺頁時,置換訪問次數最少的頁面
算法實現
- 每個頁面設置一個訪問計數
- 訪問頁面時,訪問計算+1
- 缺頁時,置換計算最小的頁面
特征
- 算法開銷大
- 開始時頻繁使用,但以后不使用的頁面很難置換
- 解決方法:計數定期右移
LRU和LFU區別
- LRU關注多久未訪問,時間越短越好
- LFU關注訪問次數,次數越多越好
算法示例
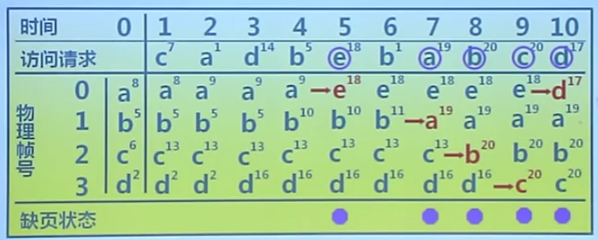
Belady現象
采用FIFO等算法時,可能出現分配的物理頁面數增加,缺頁次數反而升高的異常現象
原因
- FIFO算法的置換特征與進程訪問內存的動態特征矛盾
- 被它置換出去的頁面並不一定是進程近期不會訪問的
思考
哪些算法沒有此現象?
FIFO有,LRU沒有此現象
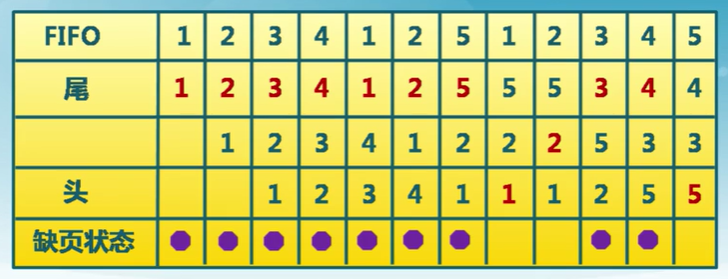
FIFO算法示例
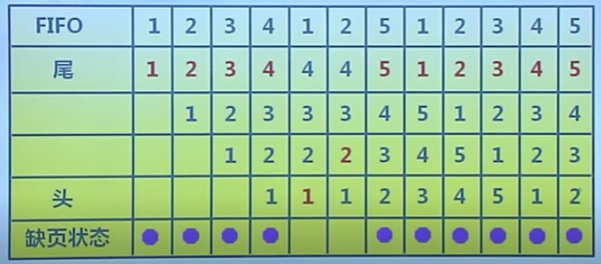
三個頁,缺頁次數9
四個頁,缺頁次數10
LRU、FIFO和Clock的比較
LRU算法和FIFO本質上都是先進先出的思路
- LRU依據頁面的最近訪問時間排序
- LRU需要動態調整順序
- FIFO依據頁面進入內存的時間排序
- FIFO的頁面進入時間是固定不變的
LRU可退化成FIFO
- 所有頁面進入內存后沒有再次訪問,最近訪問和進入時間相同
LRU算法性能好,但系統開銷較大
FIFO算法系統開銷較小,會發生Belady現象
Clock算法是它們的折中
- 頁面訪問時,不動態調整頁面在鏈表中的順序,僅做標記
- 缺頁時,再把它移動到鏈表末尾
對於未被訪問的頁面,Clock和LRU算法的表現以一樣好
對於被訪問過的頁面,Clock算法不能記錄准確訪問順序,而LRU可以
5.3 全局頁面置換算法
工作集置換算法
給進程分配可變數目的物理頁面
需要解決的問題
- 進程在不同階段的內存需求是變化的
- 分配給進程的內存也需要在不同的階段有所變化
- 全局置換算法需要確定分配給進程的物理頁面數
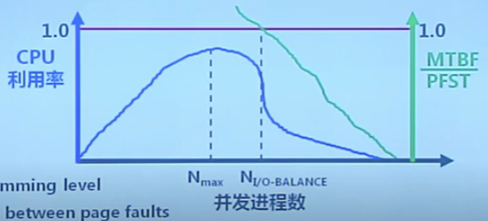
CPU利用率與並發進程數的關系

CPU利用率與並發進程存在相互促進與制約的關系
- 進程數少時,提高並發進程數,可提高CPU利用率
- 並發進程導致內存訪問增加
- 並發進程的內存訪問會降低了訪存的局部性特征
- 局部特征的下降會導致缺頁率上升和CPU利用率下降
工作集
一個進程當前正在使用的邏輯頁面集合,可表示位二元函數\(W(t, \Delta)\)
- \(t\)當前時刻
- \(\Delta\)稱為工作集窗口,即一個定長的頁面訪問時間窗口
- \(W(t, \Delta)\)是指在當前時刻 $t $ 前的 $\Delta $ 時間窗口中所有訪問頁面所組成的集合
- \(|W(t, \Delta)|\)指工作集的大小,即頁面數目

工作集的變化
-
進程開始執行后,隨着訪問新頁面逐步建立較穩定的工作集
-
當內存訪問的局部性區域的位置大致穩定時,工作集的大小也大致穩定
-
局部性區域的位置改變時,工作集快速擴張和收縮過渡到下一個穩定值
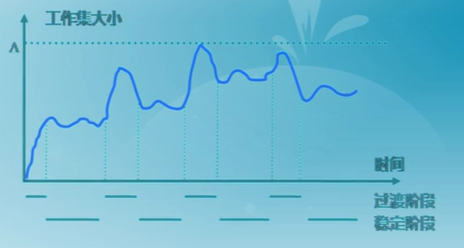
常駐集
在當前時刻,進程實際駐留在內存當中的頁面集合
工作集與常駐集的關系
- 工作集是進程在運行過程中固有的性質
- 常駐集取決於系統分配給進程的物理頁面數目和頁面置換算法
缺頁率與常駐集的關系
- 常駐集包含工作集時,缺頁率小
- 工作集發生劇烈變動時,缺頁多
- 進程常駐集大小達到一定數目后,缺頁率也不會明顯下降
思路
- 換出不在工作集中的頁面
窗口大小x
- 當前時刻前x個內存訪問的頁引用是工作集,x被稱為窗口的大小
實現方法
- 訪存鏈表:維護窗口內的訪存頁面鏈表
- 訪存時,換出不在工作集的頁面;更新訪存鏈表
- 缺頁時,換入頁面;更新訪存鏈表
算法示例
缺頁率置換算法
PFF,Page-Fault-Frequency
缺頁率(page fault rate)
缺頁次數/內存訪問次數 或 缺頁平均時間間隔的倒數
- 影響缺頁率的因素
- 頁面置換算法
- 分配給進程的物理頁面數目
- 頁面大小
- 程序的編寫方法
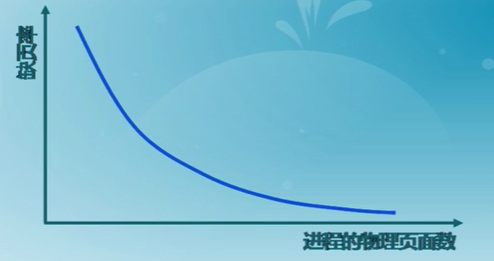
通過調節常駐集大小,使每個進程的缺頁率保持一個合理的范圍內
- 若進程缺頁率過高,則增加常駐集以分配更多的物理頁面
- 若進程缺頁率過低,則減少常駐集以減少物理頁面
算法實現
- 訪存時,設置引用標志位
- 缺頁時,計算從上次缺頁時間到現在時間的間隔
- 如果時間間隔大於給定時間T,則置換所有在間隔時間內沒有被引用的頁
- 如果時間間隔小於等於給定時間T,則增加缺失頁到常駐集
缺頁率置換算法示例
窗口大小為2

抖動和負載控制
抖動問題(thrashing)
- 進程物理頁面太少,不能包含工作集
- 造成大量缺頁,頻繁置換
- 進程運行速度變慢
產生抖動的原因
- 隨着駐留內存的進程數目增加,分配給每個進程的物理頁面數不斷減少,缺頁率上升
操作系統需在並發水平和缺頁率之間達到一個平衡
- 選擇一個適當的進程數目和進程需要的物理頁面數
負載控制
通過調節並發進程數(MPL)來進行系統負載控制
- \(\sum WSi\) = 內存的大小
- 平均缺頁時間間隔(MTBF)= 缺頁異常處理時間(PFST)
6. 進程
6.1 進程的概念
進程是指一個具有一定獨立功能的程序在一個數據集合上的一次動態執行過程
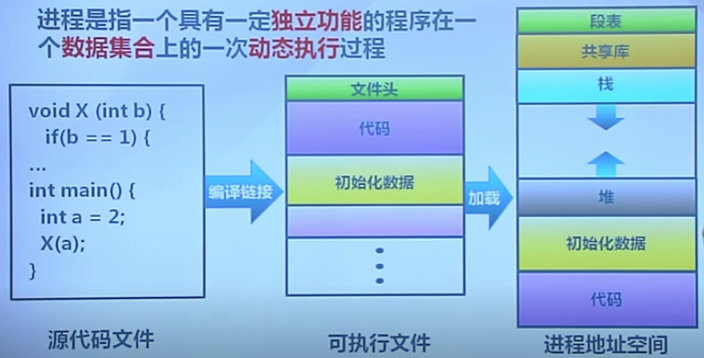
進程組成
進程包含了正在運行的一個程序的所有狀態信息
- 代碼
- 數據
- 狀態寄存器
- 通用寄存器
- 進程占用系統資源
進程特點
- 動態性
- 並發性
- 進程可以被獨立調度並占用處理機運行
- 獨立性
- 不同的進程不會互相影響
- 制約性
- 因訪問共享數據、資源或進程間同步而產生的制約
進程與程序的聯系
- 進程是操作系統處於執行狀態程序的抽象
- 程序 = 文件(靜態可執行文件)
- 進程 = 執行中的程序 = 程序 + 執行狀態
- 同一個程序的多次執行過程對應為不同進程
- 如命令 ls 的多次執行對應多個不同進程
- 進程執行需要的資源
- 內存:保存代碼和數據
- CPU:執行指令
進程與程序的區別
- 進程是動態的,程序是靜態的
- 程序是有序代碼的集合
- 進程是程序的執行,進程有核心態、用戶態
- 進程是暫時的,程序是永久的
- 進程是一個狀態變化的過程
- 程序可長久保存
- 進程與程序的組成不同
- 進程的組成包括程序、數據和進程控制塊
6.2 進程控制塊
PCB,Process Control Block
操作系統管理控制進程運行所用的信息集合
- 操作系統由PCB來描述進程的基本情況以及運行變化的過程
- PCB是進程存在的唯一標志
- 每個進程都在操作系統中有一個對應的PCB
使用流程
- 進程創建
- 生成該進程的PCB
- 進程終止
- 回收它的PCB
- 進程的組織管理
- 通過對PCB的組織管理來實現
控制塊內容
- 進程標識信息
- 處理機現場保護
- 進程控制信息
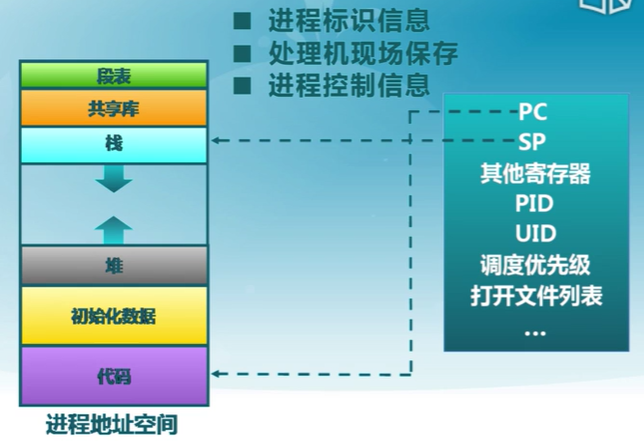
進程控制信息
- 調度信息和狀態信息
- 進程和處理機使用情況調度
- 進程間通信信息
- 進程間通信相關的各種標識
- 存儲管理信息
- 指向進程映像存儲空間數據結構
- 進程所占資源
- 進程使用的系統資源,如打開文件等
- 有關數據結構連接信息
- 與PCB相關的進程隊列
進程控制塊的組織
鏈表
同一狀態的進程其PCB成一鏈表,多個狀態對應多個不同的鏈表
- 各狀態的進程形成不同的鏈表:就緒鏈表、阻塞鏈表
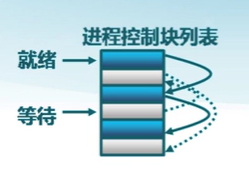
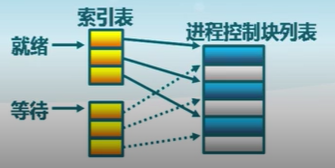
索引表
同一狀態的進程歸入一個索引表(由索引指向PCB)
多個狀態對應多個不同的索引表
- 各狀態的進行形成不同的索引表:就緒索引表、阻塞索引表
6.3 進程狀態
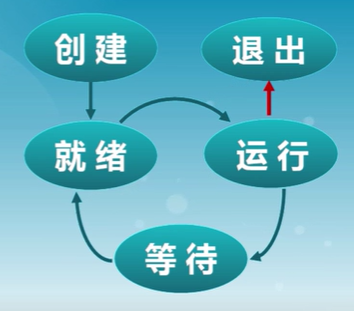
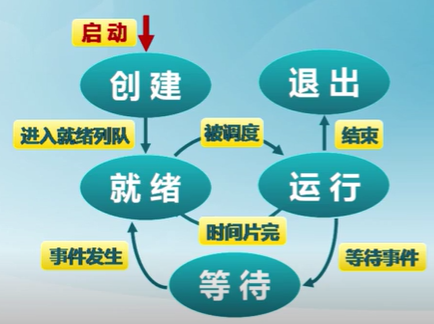
進程的生命周期划分
- 進程創建
- 進程執行
- 進程等待
- 進程搶占
- 進程喚醒
- 進程結束
進程切換
6.4 三狀態進程模型
6.5 掛起進程模型
處於掛起狀態的進程映像在磁盤上,目的是減少進程占用內存
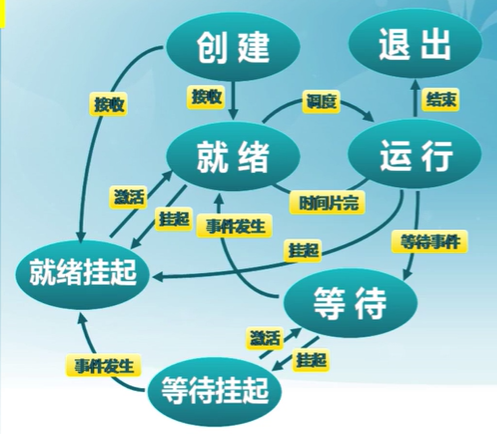
- 等待掛起狀態(Blocked-suspend)
- 進程在外存並等待某事件的出現
- 就緒掛起狀態(Ready-suspend)
- 進程在外存,但只要進入內存,即可運行
- 掛起(Suspend):把一個進程從內存轉到外存
- 等待到等待掛起
- 沒有進程處於就緒狀態或就緒進程要求更多內存資源
- 就緒到就緒掛起
- 當由高優先級等待(系統認為會很快就緒的)進程和低優先級就緒進程
- 運行到就緒掛起
- 對搶先式分時系統,當有高優先級等待掛起進程因事件出現而進入就緒掛起
- 等待到等待掛起
在外存時的狀態轉換
-
等待掛起到就緒掛起
- 當有等待掛起進程因相關事件出現
-
激活(Activate):把一個進程從外存轉到內存
-
就緒掛起到就緒
沒有就緒進程或掛起就緒進程優先級高於就緒進程
-
等待掛起到等待
當一個進程釋放足夠內存,並有高優先級等待掛起進程
-
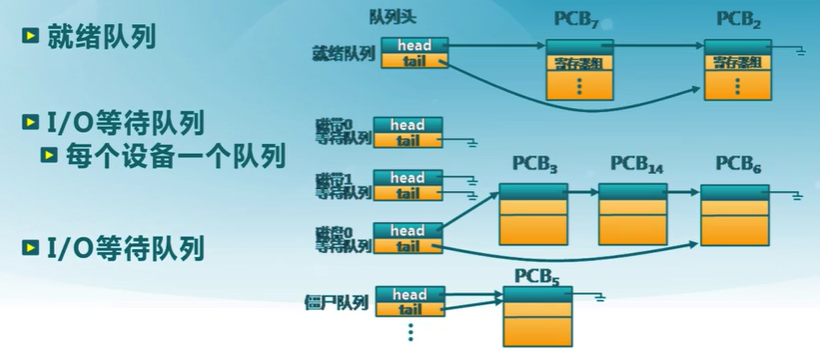
狀態隊列
- 由操作系統來維護一組隊列,表示系統中所有進程的當前狀態
- 不同隊列表示不同狀態
- 就緒隊列、各種等待隊列
- 根據進程狀態不同,進程PCB加入相應隊列

7. 線程
7.1 為什么需要線程?
單進程播放

多進程實現

解決思路
在進程內部增加一類實體,滿足以下特性:
- 實體之間可以並發執行
- 實體之間共享相同的地址空間
這種實體就是線程(Thread)
7.2 線程的概念
線程是進程的一部分,描述指令流執行狀態。它是進程中的指令執行流的最小單元,是CPU調度的基本單位。
進程的資源分配角色:進程由一組相關資源構成,包括地址空間(代碼段、數據段)、打開的文件等各種資源
線程的處理機調度角色:線程描述在進程資源環境中的指令流執行狀態
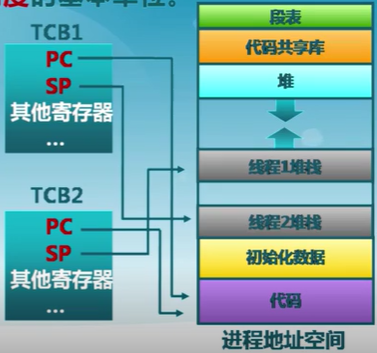
進程和線程的關系
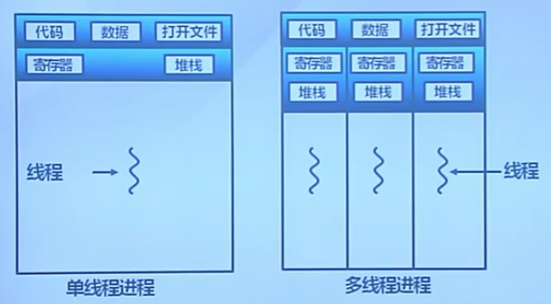
線程 = 進程 - 共享資源
線程的優點
- 一個進程中可以同時存在多個線程
- 各個線程之間可以並發執行
- 各個線程之間可以共享地址空間和文件資源
線程的缺點
- 一個線程崩潰,會導致其所屬進程的所有線程崩潰
不同操作系統對線程的支持
路由器就是單進程多線程系統

進程與線程的比較
- 進程是資源分配的單位,線程是CPU調度單位
- 進程擁有一個完整的資源平台,而線程只獨享指令流執行的必要資源,如寄存器和棧
- 線程具有就緒、等待和運行三種基本狀態和狀態間的轉換關系
- 線程能減少並發執行的時間和空間開銷
- 線程的創建時間比進程短
- 線程的終止時間比進程短
- 同一進程內的線程切換時間比進程短
- 由於同一進程的各線程間共享內存和文件資源,可不通過內核進行直接通信
7.3 用戶線程
線程的三種實現方式
-
用戶線程:在用戶空間實現
POSIX Pthreads, Mach C-threads, Solaris threads
-
內核線程:在內核中實現
Window,Solaris, Linux
-
輕量級進程:在內核中實現,支持用戶線程
Solaris (LightWeight Process)
概念
由一組用戶級的線程庫函數來完成線程的管理,包括線程的創建、終止、同步和調度等。
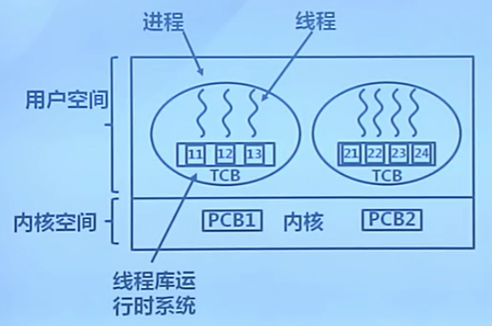
- 不依賴與操作系統的內核
- 內核不了解用戶線程的存在
- 可用於不支持線程的多進程操作系統
- 在用戶空間實現的線程機制
- 每個進程由私有的線程控制塊(TCB)列表
- TCB由線程庫函數維護
- 同一進程內的用戶線程切換速度快
- 無需內核態和用戶態切換
- 允許每個進程擁有自己的線程調度算法
不足
- 線程發起系統調用而阻塞時,則整個系統進入等待
- 不支持基於線程的處理機搶占
- 除非當前運行線程主動放棄,他所在進程的其他線程無法搶占CPU
- 只能按進程分配CPU時間
- 多個線程進程中,每個線程時間會變少
7.4 內核線程
進程由內核通過系統調用實現的線程機制,由內核完成線程的創建、終止和管理。
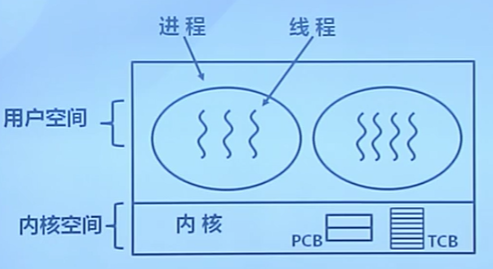
特征
- 由內核維護PCB和TCB
- 線程執行系統調用而被阻塞不影響其他線程
- 線程的創建、終止和切換相對較大
- 通過系統調用/內核函數,在內核實現
- 以線程為單位進行CPU時間分配
- 多線程的進程可獲得更多CPU時間
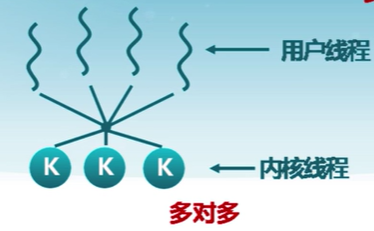
7.5 輕權進程(LightWeight Process)
內核支持的用戶線程。一個進程可有一個或多個輕量級進程,每個輕權進程由一個單獨的內核線程來支持。

用戶線程和內核線程的對應關系

8. 進程控制
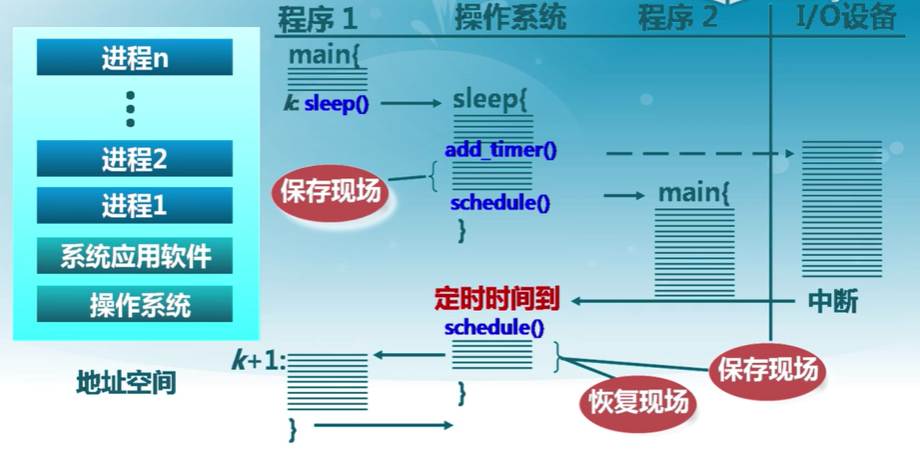
8.1 進程切換
(進程切換)上下文切換
- 暫停當前運行進程,從運行狀態變成其他狀態
- 調度另一個進程從就緒狀態變成運行狀態
進程切換的要求
- 切換前,保存進程上下文
- 切換后,恢復進程上下文
- 快速切換
進程生命周期的信息
- 寄存器(PC,SP, )
- CPU狀態
- 內存地址空間
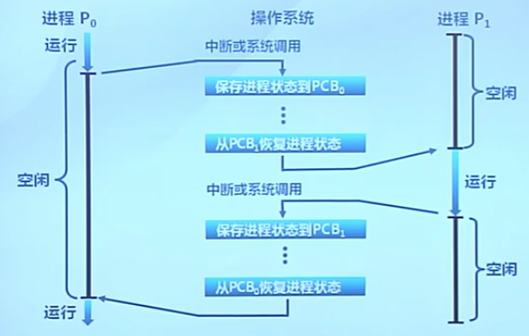
進程控制塊PCB:內核的進程狀態記錄
- 內核為每個進程維護了對應的進程控制塊(PCB)
- 內核將相同狀態的進程的PCB放置在同一隊列
8.2 進程創建
Windows進程創建API:CreateProcess(filename)
-
創建時關閉所有在子進程里的文件描述符
CreateProcess(filename,CLOSE_FD)
-
創建時改變子進程的環境
CreateProcess(filename,CLOSE_FD,new_envp)
-
等等
Unix進程創建系統調用:fork/exec
-
fork()把一個進程復制成二個進程
parent(old PID),child(new PID)
-
exec()用新程序來重寫當前進程
PID沒有該變

fork的地址空間復制
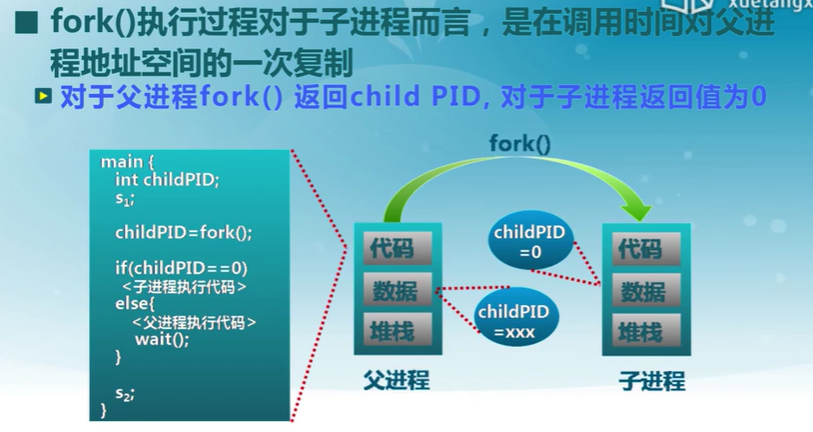

fork使用示例
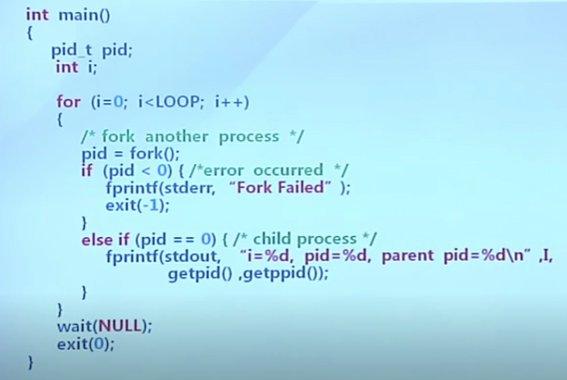
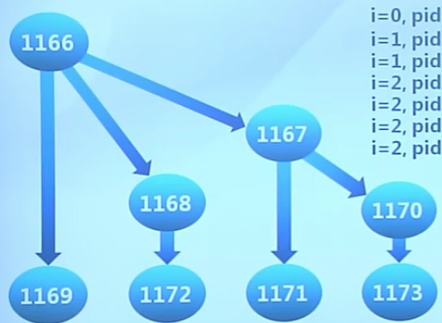
代碼
8.3 進程加載
程序加載和執行系統調用exec()
- 允許進程,“加載”一個完全不同的程序,並從main開始執行(即_start)
- 允許進程加載時指定啟動參數(argc, argv)
- exec調用成功時
- 是相同的進程
- 運行了不同的程序
- 代碼段、堆棧和堆(heap)等完全重寫
8.4 進程等待與退出
wait()系統調用用於父進程等待子進程的結束
- 子進程結束時通過exit()向父進程返回一個值
- 父進程通過wait()處理返回值
wait()系統調用的功能
-
有子進程存活時,父進程進入等待狀態,等待子進程的返回結果
當某子進程調用exit()時,喚醒父進程,將exit()返回值作為父進程中wait的返回值
-
有僵屍子進程等待時,wait()立即返回其中一個值
-
無子進程存活時,wait()立刻返回
程序的有序終止exit()
- 進程結束執行時調用exit,完成資源回收
- exit系統調用的功能
- 將調用參數作為進程的“結果”
- 關閉所有打開的文件等占用資源
- 釋放內存
- 釋放大部分進程相關的內核數據結構
- 檢查是否父進程是存活着的
- 如存活,保留結果的值直到父進程需要它,進入僵屍(zombie/defunct)狀態
- 如果沒有,它釋放所有的數據結構,進程結束
- 清理所有等待的僵屍進程
- 進程終止是最終的垃圾收集(資源回收)
9. 處理機調度
9.1 處理機調度概念
CPU資源的時分復用
-
進程切換:CPU資源的當前占用者切換
- 保存當前進程在PCB中的執行上下文(CPU狀態)
- 恢復下一個進程的執行上下文
-
處理機調度
- 從就緒隊列中挑選下一個占用CPU運行的進程
- 從多個可用CPU中挑選就緒進程可使用的CPU資源
-
調度程序:挑選就緒進程的內核函數
調度策略:依據什么原則挑選進程/線程?
調度時機:什么時候進行調度?
調度時機
- 內核運行調度程序的條件
- 進程從運行狀態切換到等待狀態
- 進程被終結了
- 非搶占系統
- 當前進程主動放棄CPU時
- 可搶占系統
- 中斷請求被服務例程響應完成時
- 當前進程被搶占
- 進程時間片用完
- 進程從等待切換到就緒
9.2 調度准則
調度策略
確定如何從就緒隊列中選擇下一個執行進程
調度策略要解決的問題
- 挑選就緒隊列中的哪一個進程?
- 通過什么樣的准則來挑選?
調度算法
- 在調度程序中實現的調度策略
比較調度算法的准則
- 哪一個策略/算法較好?
- CPU使用率
- CPU處於忙狀態的時間百分比
- 吞吐量
- 單位時間內完成的進程數量
- 周轉時間
- 進程從初始化到結束的總時間
- 等待時間
- 進程在就緒隊列中的總時間
- 響應時間
- 從提交請求搭配產生響應所花費的總時間
- CPU使用率
處理機資源的使用模式
- 進程在CPU計算和I/O操作間交替
- 每次調度決定在下一個CPU計算時將哪個工作交給CPU
- 在時間片機制下,進程可能在結束當前CPU計算前被迫放棄CPU
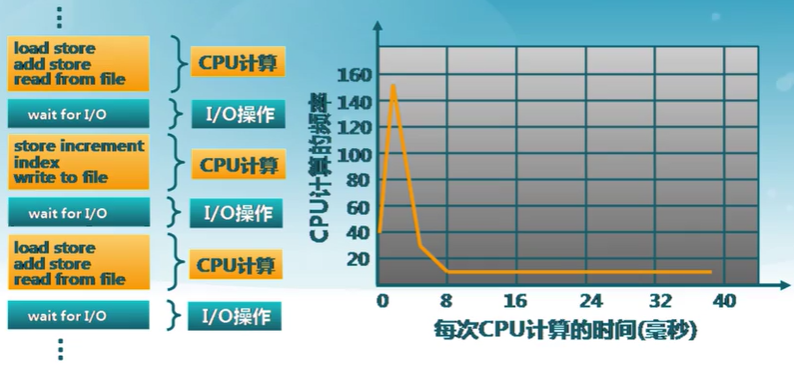
吞吐量與延遲
-
調度算法的要求
- 希望更快的服務
-
什么是更快?
- 傳輸文件的高帶寬、調度算法的高吞吐量
- 玩游戲的低延遲,調度算法的低響應延遲
- 這兩個因素是獨立的
-
與水管的類比
- 低延遲:喝水的時候想要一打開水龍頭就留出來
- 高帶寬:給游泳池充水希望從水龍頭里同時流出大量的水,不介意是否存在延遲
處理機調度策略的響應時間目標
-
減少響應時間
及時處理用戶的輸入請求,盡快輸出反饋給用戶
-
減少平均響應時間的波動
在交互系統中,可預測性比高差異低平均更重要
-
低延遲調度改善了用戶的交互體驗
如果移動鼠標時,屏幕中的光標沒動,用戶可能會重啟電腦
-
響應時間是操作系統的計算延遲
處理機調度策略的吞吐量目標
- 增加吞吐量
- 減少開銷(操作系統開銷,上下文切換)
- 系統資源的高效利用(CPU,I/O設備)
- 減少等待時間
- 減少每個進程的等待時間
- 操作系統需要保證吞吐量不受用戶交互的影響
- 操作系統必須不時進行調度,即使存在許多交互任務
- 吞吐量是操作系統的計算帶寬
處理機調度策略的公平性目標
- 公平的定義
- 保證每個進程占用相同的CPU時間
- 保證每個進程的等待時間相同
9.3 調度算法
先來先服務算法
FCFS:First Come First Served
依據進程進入就緒狀態的先后順序排列
- 進程進入等待或結束狀態時,就緒隊列中的下一個進程占用CPU
FCFS算法的周轉時間

先來先服務算法的特征
-
優點
- 簡單
-
缺點
-
平均等待時間波動較大
短進程可能排在長進程后面
-
I/O資源和CPU資源的利用率低
CPU密集型進程會導致I/O設備閑置時,I/O密集型進程也等待
-
短進程優先算法
SPN
選擇就緒隊列中執行時間最短進程占用CPU進入運行狀態
- 就緒隊列按預期的執行時間來排序
短剩余時間優先算法(SRT):可運行搶占CPU,只要執行時間更短
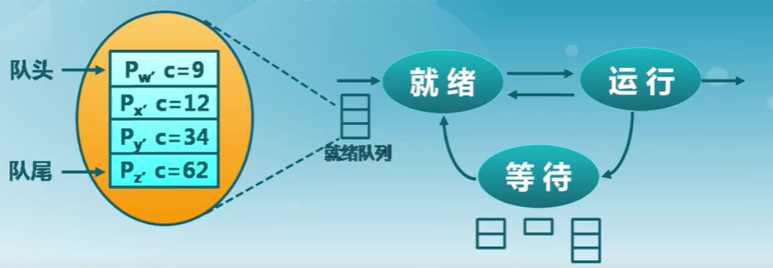
短進程優先算法具有最優平均周轉時間

缺點
-
可能導致飢餓
連續的短進程流會使長進程無法獲得CPU資源
-
需要預知未來
- 如何預估下一個CPU計算的持續時間
- 簡單的解決方法:詢問用戶
- 用戶欺騙就殺死進程
- 用戶不知道
短進程優先算法的執行時間預估
- 用歷史的執行時間來預估未來的執行時間

最高響應比優先算法
HRRN
選擇就緒隊列中響應比R值最高的進程
- 基於短進程優先算法基礎上改進
- 不可搶占
- 關注進程的等待時間
- 防止無限制等待
時間片輪轉算法
RR,Round-Robin
時間片
- 分配處理機資源的基本時間單元
算法思路
- 時間片結束時,按FCFS算法切換到下一個就緒進程
- 每隔(n-1)個時間片進程執行一個時間片q

算法示例

時間片長度
- RR算法開銷
- 額外的上下文切換
- 時間片太大
- 等待時間太長
- 極限情況退化成FCFS
- 時間片太小
- 反應快,但產生大量上下文切換
- 大量上下文切換開銷影響到系統吞吐量
- 時間片長度選擇目標
- 選擇一個合適的時間片長度
- 經驗規則:維持上下文切換開銷處於1%以內
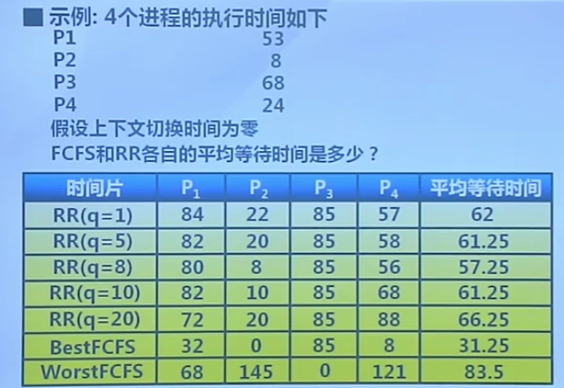
多級隊列調度算法
MQ
- 就緒隊列被划分成多個獨立的子隊列
- 如:前台(交互)、后台(批處理)
- 每個隊列擁有自己的調度策略
- 如:前台-RR、后台-FCFS
- 隊列間的調度
- 固定優先級
- 先處理前台,然后處理后台
- 可能導致飢餓
- 時間片輪轉
- 每個隊列都得到一個確定的能夠調度其進程的CPU總時間
- 如:80%CPU時間用於前台,20%CPU時間用於后台
- 固定優先級
多級反饋隊列算法
MLFQ
- 進程可在不同隊列間移動的多級隊列算法
- 時間片大小隨優先級級別增加而增加
- 如進程在當前的時間片沒有完成,則降到下一個優先級
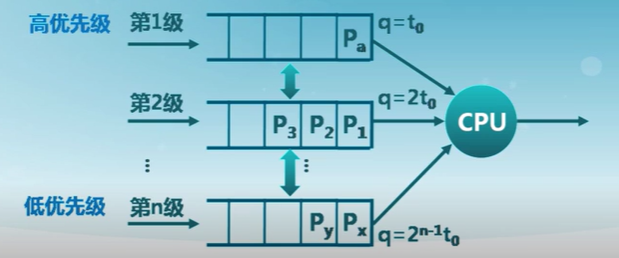
- MLFQ算法的特征
- CPU密集型進程的優先級下降很快
- I/O密集型進程停留在高優先級
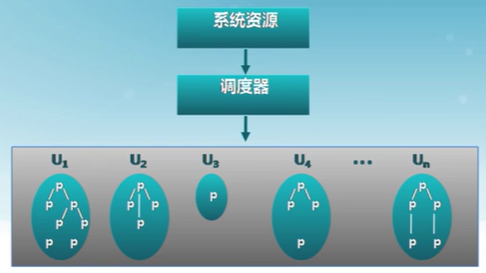
公平共享調度算法
FSS,Fair Share Scheduling
FSS控制用戶對系統資源的訪問
- 一些用戶組比其他用戶組更重要
- 保證不重要的組無法壟斷資源
- 未使用的資源按比例分配
- 沒有達到資源使用率目標的組獲得更高的優先級
總結
- 先來先服務算法(FCFS)
- 不公平,平均等待時間較差
- 短進程優先算法(SPN)
- 不公平,平均周轉時間最小
- 需要精確預測計算時間
- 可能導致飢餓
- 最高響應比算法(HRRN)
- 基於SPN調度
- 不可搶占
- 時間片輪轉算法(RR)
- 公平,平均等待時間較差
- 交互性很好
- 多級反饋隊列算法(MLFQ)
- 多種算法的集成
- 公平共享調度算法(FSS)
- 公平是第一要素
9.4 實時調度和多處理器調度
實時操作系統
實時操作系統的定義
正確性依賴於其時間和功能兩方面的操作系統
實時操作系統的性能指標
- 時間約束的及時性(deadlines)
- 速度和平均性能相對不重要
實時操作系統的特性
- 時間約束的可預測性
實時任務
- 任務(工作單元)
- 一次計算,一次文件讀取,一次信息傳遞等等
- 任務屬性
- 完成任務所需要的資源
- 定時參數

周期實時任務
一系列相似的任務
- 任務有規律地重復
- 周期 p = 任務請求時間間隔 (0 < p)
- 執行時間 e = 最大執行時間 (0 < e < p)
- 使用率 U = e / p

硬時限和軟時限
- 硬時限(hard deadline)
- 錯過任務時限會導致災難性或非常嚴重的后果
- 必須驗證,在最壞情況下能夠滿足時限
- 軟時限(soft deadline)
- 通常能滿足任務時限
- 有時不能滿足,則降低要求
- 盡力保證滿足任務時限
- 通常能滿足任務時限
可調度性
可調度表示一個實時操作系統能夠滿足任務時限要求
- 需要確定實時任務的執行順序
- 靜態優先級調度
- 動態優先級調度
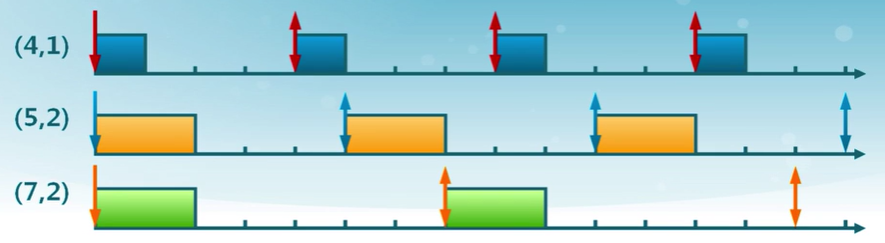
速率單調調度
(RM,Rate Monotonic)
- 通過周期安排優先級
- 周期越短優先級越高
- 執行周期最短的任務
最早截止時間優先算法
(EDF,Earilest Deadline First)
- 截止時間越早優先級越高
- 執行截止時間最早的任務
多處理器調度
特征
- 多個處理機組成的一個多處理機系統
- 多處理機間可負載共享
對稱多處理器(SMP,Symmetric multiprocessing)調度
- 截止時間越早優先級越高每個處理器運行自己的調度程序
- 調度程序對共享資源的訪問要進行同步

對稱多處理器的進程分配
- 靜態進程分配
- 進程從開始到結束都被分配到一個固定的處理機上執行
- 每個處理機有自己的就緒隊列
- 調度開銷小
- 各處理機可能忙閑不均
- 動態進程分配
- 進程在執行種可分配到任意空閑處理機執行
- 所有處理機共享一個公共的就緒隊列
- 調度開銷大
- 各處理機的負載是均衡的
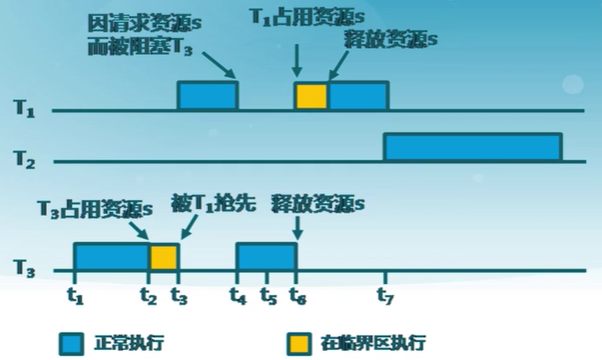
9.5 優先級反置
priority inversion
-
操作系統中出現高優先級進程長時間等待低優先級進程所占用資源的現場
-
基於優先級的可搶占調度算法存在優先級反置
例如:有優先級為A、B和C三個任務,優先級A>B>C,任務A,B處於掛起狀態,等待某一事件發生,任務C正在運行,此時任務C開始使用某一共享資源S。在使用中,任務A等待事件到來,任務A轉為就緒態,因為它比任務C優先級高,所以立即執行。當任務A要使用共享資源S時,由於其正在被任務C使用,因此任務A被掛起,任務C開始運行。如果此時任務B等待事件到來,則任務B轉為就緒態。由於任務B優先級比任務C高,因此任務B開始運行,直到其運行完畢,任務C才開始運行。直到任務C釋放共享資源S后,任務A才得以執行。在這種情況下,優先級發生了翻轉,任務B先於任務A運行。

優先級繼承
Priority Inheritance
占用資源的低優先級進程繼承申請資源的高優先級進程的優先級
- 只在占有資源的低優先級進程被阻塞時,才提高占有資源進程的優先級
優先級天花板協議
priority ceiling protocol
占有資源進程的優先級和所有可能申請該資源的進程的最高優先級相同
-
不管是否發生等待,都提升占用資源進程的優先級
-
優先級高於系統中的所有被鎖定的資源的優先級上限,任務執行臨界區時就不會被阻塞
10. 同步互斥
10.1 背景
獨立進程:不和其他進程共享資源或狀態
- 確定性 輸入決定結果
- 可重現 能夠重現起始條件
- 調度順序不重要
並發進程:在多個進程間有資源共享
- 不確定性
- 不可重現
並發進程的正確性
- 執行過程是不確定性和不可重現的
- 程序錯誤可能是間歇性發生的
進程並發執行的好處
進程需要與計算機中的其他進程和設備進行協作
-
共享資源
- 多個用戶使用一台計算機
- 銀行賬戶存款余額在多台ATM機操作
- 機器人上的手臂和手的動作
-
加速
- I/O操作和CPU計算可用重疊(並行)
- 程序可划分成多個模塊放在多個處理器上並行執行
-
模塊化
- 將大程序分解成小程序
- 以編譯為例,gcc會調用cpp,cc1,cc2
- 是系統易於復用和擴展
可能導致的錯誤
- 將大程序分解成小程序
原子操作
Atomic Operation
原子操作是一次不存在任何中斷或失敗的操作
- 要么操作完成
- 或者操作沒有執行
- 不會出現部分執行的狀態
操作系統利用同步機制在並發執行的同時,保證一些操作是原子操作
10.2 現實生活中的同步問題
操作系統和現實生活的問題類比
- 利用現實生活問題幫助理解操作系統同步問題
- 同時注意,計算機與人的差異
例如:家庭采購協調
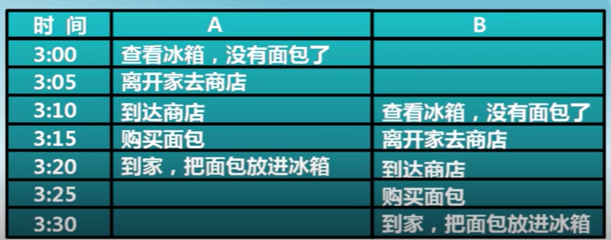
如何保證家庭協調的成功和高效
- 有人去買
- 需要采購時,有人去買面包
- 最多只有一個人去買面包
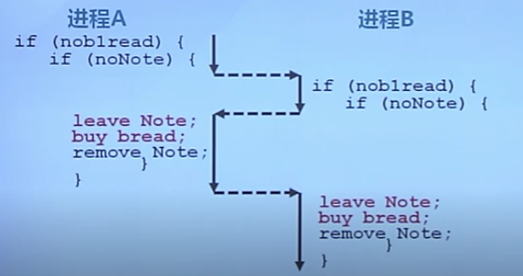
方案一
- 使用便簽來避免購買太多面包
- 購買之前留下一張便簽
- 買完后移除
- 別人看到就不去購買
分析
面包還是買多了
方案二
先留便簽,后檢查面包和便簽
會導致不會有人買面包

方案三
為便簽增加標識,以區別不同人的便簽
還是會導致有人不買
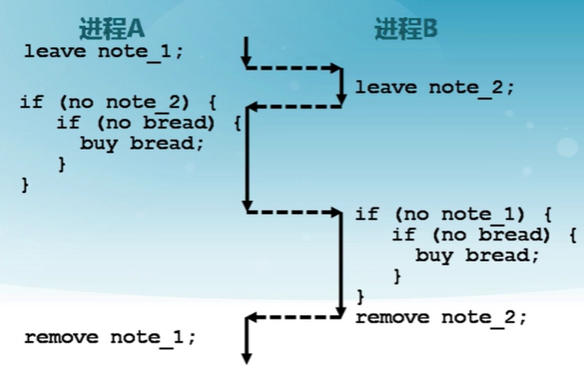
方案四
兩個人采用不同的處理流程
- 有效,但復雜
- 很難驗證其有效性
- A和B的代碼不同
- 每個進程的代碼也會略有不同
- 如果進程更多,怎么辦?
- 當A在等待時,它不能做其他事
- 忙等待(busy-waiting)

方案五
利用兩個原子操作實現一個鎖(lock)
- Lock.Acquire()
- 在鎖被釋放前一直等待,然后獲得鎖
- 如果兩個線程都在等待同一個鎖,並且同時發現鎖被釋放了,那么只有一個能夠獲得鎖
- Lock.Relese()
- 解鎖並喚醒任何等待種的進程

進程的交互關系:相互感知程度
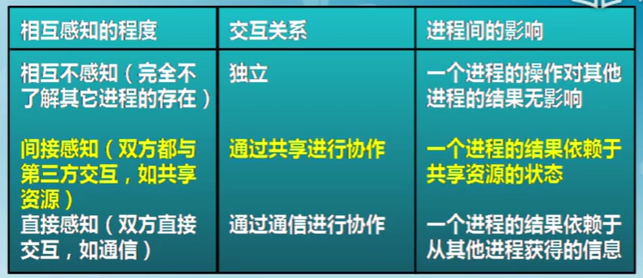
- 互斥(mutual exclusion)
- 一個進程占用資源,其它進程不能使用
- 死鎖(deadlock)
- 多個進程各占用部分資源,形成循環等待
- 飢餓(starvation)
- 其他進程可能輪流占用資源,一個進程一直得不到資源
10.3 臨界區

臨界區(Critical Section):進程中訪問臨界資源的一段需要互斥執行的代碼
進入區(entry section):
- 檢查可否進入臨界區的一段代碼
- 如可進入,設置相應“正在訪問臨界區”標志
退出區(exit section):
- 清除“正在訪問臨界區”標志
剩余區(remainder section)
- 代碼中其余部分
臨界區的訪問規則
- 空閑則入
- 沒有進程在臨界區,任何進程可進入
- 忙則等待
- 有進程在臨界區,其他進程均不能進入臨界區
- 有限等待
- 等待進入臨界區的進程不能無限期等待
- 讓權等待(可選)
- 不能進入臨界區的進程,應釋放CPU(如轉換到阻塞狀態)
臨界區實現方法
- 禁用硬件中斷
- 軟件同步方法
- 更高級的抽象方法
不同的臨界區實現機制的比較
- 性能:並發級別
10.4 禁用硬件中斷
- 沒有中斷,沒有上下文切換,因此沒有並發執行
- 硬件將中斷處理延遲到中斷被啟用之后
- 現代計算機體系結構都提供指令來實現禁用中斷
- 進入臨界區
- 禁止所有中斷,並保存標志
- 離開臨界區
- 使能所有中斷,並恢復標志

缺點
- 禁用中斷后,進程無法被停止
- 整個系統都會為此停下來
- 可能導致其他進程處於飢餓狀態
- 臨界區可能很長
- 無法確定響應中斷所需的時間(可能存在硬件影響)
- 要小心使用
10.5 軟件同步方法

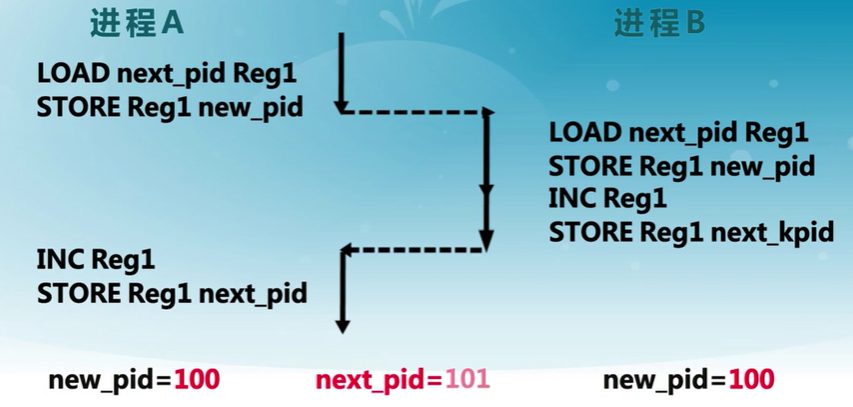
第一次嘗試
滿足“忙則等待”,但是有時不滿足“空閑則入”
- Ti不在臨界區,Tj想要繼續運行,但是必須等待Ti進入過臨界區后
- Ti可能會被阻塞,所以Tj就會一直等待,不滿足空閑則入

第二次嘗試
不滿足忙則等待

第三次嘗試
滿足忙則等待,不滿足空閑則入

Peterson算法
- 滿足線程Ti和Tj之間互斥的經典的基於軟件的解決方法


Dekkers算法

N線程的軟件方法
Eisenberg和McGuire
分析
- 復雜
- 需要兩個進程間的共享數據項
- 需要忙等待
- 浪費CPU時間
10.5 更高級的抽象方法
硬件提供了一些同步原語
- 中斷禁用,原子操作指令等
操作系統提供更高級的變成抽象來簡化進程同步
- 例如:鎖、信號量
- 用硬件原語來構建
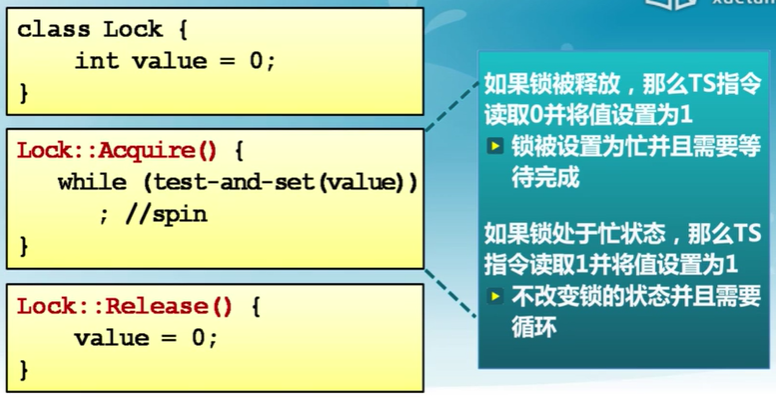
鎖(lock)
鎖是一個抽象數據結構
-
是一個二進制變量(鎖定/解鎖)
-
Lock::Acquire()
鎖被釋放前一直等待,然后得到鎖
-
Lock::Release()
釋放鎖,喚醒任何等待的進程
使用鎖來控制臨界區訪問

原子操作指令
現代CPU體系結構都提供一些特殊的原子操作指令
- 測試和置位(Test-and-Set)指令
- 從內存單元中讀值
- 測試該值是否為1(然后返回真或假)
- 內存單元值設置為1

-
交換指令(exchange)
- 交換內存中的兩個值

自旋鎖
使用TS指令實現自旋鎖(spinlock)
線程在等待的時候消耗CPU時間
無忙等待鎖
schedule()放棄占用CPU,讓CPU調度其他進程
wakeup(t)喚醒線程,占用資源

原子操作指令鎖的特征
優點
- 適用於單處理器或者共享主存的多處理器中任意數量的進程同步
- 簡單並且容易證明
- 支持多臨界區
缺點
- 如果是忙等待鎖會占用CPU時間
- 可能導致飢餓
- 進程離開臨界區時有多個等待進程的情況
- 死鎖
- 擁有臨界區的低優先級進程,請求訪問臨界區的高優先級進程獲得處理器並等待臨界區
總結
- 鎖是一種高級的同步抽象方法
- 互斥可以使用鎖來實現
- 需要硬件支持
- 常用的三種同步實現方法
- 禁用中斷(僅限於單處理)
- 軟件方法(復雜)
- 原子操作指令(單處理器或多處理器均可)
11. 信號量與管程
11.1 信號量
並發問題
- 多線程並發導致資源競爭
同步概念
- 協調多線程對共享數據的訪問
- 任何時刻只能有一個線程執行臨界區代碼
確保同步正確的方法
- 底層硬件支持
- 高層次的編程抽象
基本同步方法

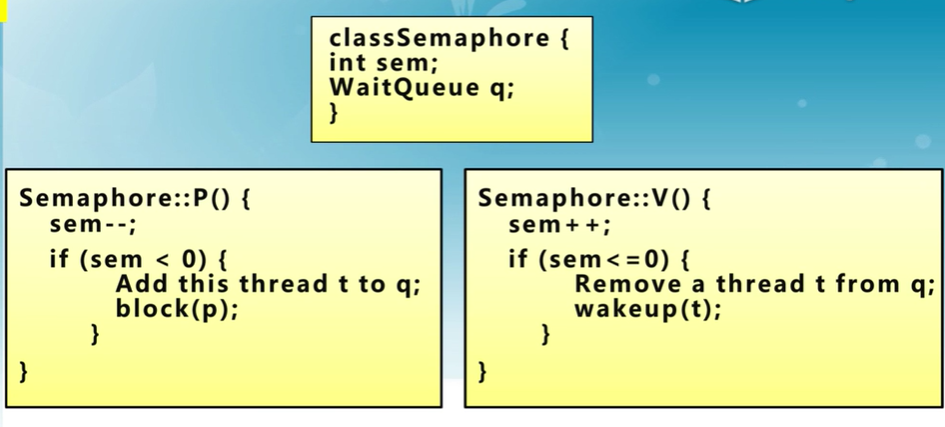
信號量的定義
semaphore:信號量
信號量是操作系統提供的一種協調共享資源訪問的方法
- 軟件同步是平等線程間的一種同步協商機制
- OS是管理者,地位高於進程
- 用信號量標識系統資源的數量
由Dijkstra在20世紀60年代提出,早期的操作系統的主要同步機制
- 現在很少用---但還是非常重要在計算機科學研究
信號是一種抽象的數據類型
- 由一個整型(sem)變量和兩個原子操作P和V
- P()(Prolaag(荷蘭語嘗試減少)
- sem減一
- 如sem<0,進入等待,否則繼續
- V()(Verhoog(荷蘭語增加))
- sem加1
- 如sem<=0,喚醒一個等待進程
信號量與鐵路的類比
- 2個站台的車站
- 2個資源的信號量
信號量是被保護的整數變量
- 初始化完成后,只能通過P()和V()操作修改
- 由操作系統保證,PV操作是原子操作
P()可能阻塞,V()不會阻塞
- P操作可能沒有資源而進入等待狀態
通常假定信號量是“公平的”
- 線程不會被無限期阻塞在P()操作
- 假定信號量等待按先進先出排隊
自旋鎖不能實現先進先出
信號量的實現
信號量的使用
信號量分類
- 二進制信號量:資源數目為0或1
- 資源信號量:資源數目為任何非負值
- 兩者等價:基於一個可以實現另一個
信號量的使用
-
互斥訪問
-
臨界區的互斥訪問控制

-
-
條件同步
-
線程間的時間等待

-
生產者-消費者問題
有界緩沖區的生產者-消費者問題描述
- 一個或多個生產者在生成數據后放在一個緩沖區里
- 單個消費者從緩沖區取出數據處理
- 任何時刻只能有一個生產者或消費者可訪問緩沖區

問題分析
- 任何時候只能有一個線程操作緩沖區(互斥訪問)
- 緩沖區空時,消費者必須等待生產者(條件同步)
- 緩沖區滿時,生產者必須等待消費者(條件同步)
用信號量描述每個約束
- 二進制信號量 mutex
- 資源信號量 fullBuffers
- 資源信號量 emptyBuffers
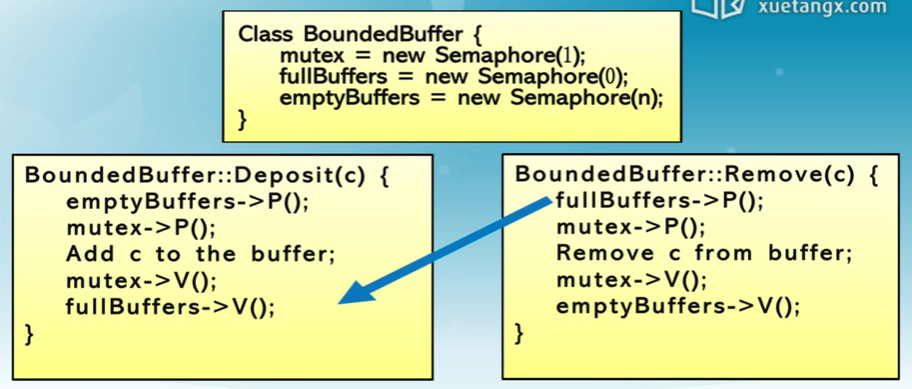
PV操作不能調換,檢查緩沖區是否有空地和占有緩沖區的操作不能調換
因為一旦先占有緩沖區,那就無法釋放緩沖區,導致死鎖現象
阻塞不代表會釋放資源,資源的釋放是通過對變量的加減來進行的。
使用信號量的困難
- 讀開發代碼比較困難
- 程序員需要能運用信號量機制
- 容易出錯
- 使用信號量已經被另一個線程占用
- 忘記釋放信號量
- 不能處理死鎖問題(只能在寫程序的時候解決)
11.3 管程
Moniter
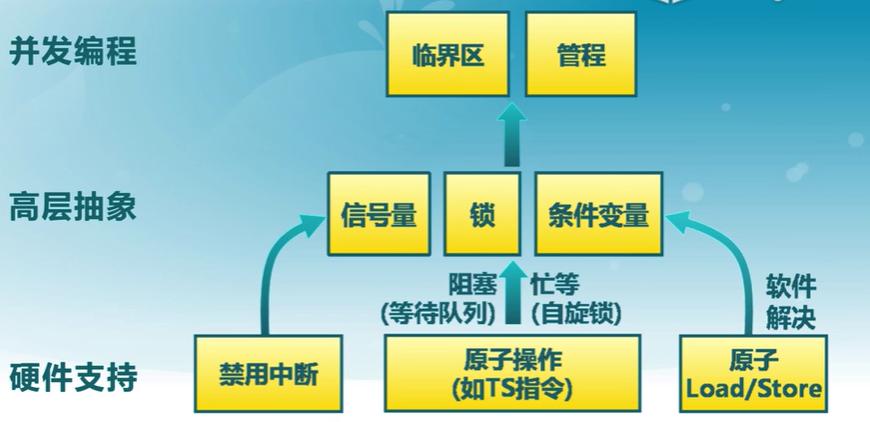
管程是一種多線程互斥訪問共享資源的程序結構
- 采用面向對象方法,簡化了線程間的同步控制
- 任一時刻最多只有一個線程執行管程代碼
- 正在管程中的線程可臨時放棄管程的互斥訪問,等待事件出現時恢復
管程的使用
- 在對象/模塊,收集相關共享數據
- 定義訪問共享數據的方法
管程的組成
-
一個鎖
- 控制管程代碼的互斥訪問
-
0個或者多個條件變量
- 管理共享數據的並發訪問
條件變量(Condition Variable)
- 條件變量是管程內的等待機制
- 進入管程的線程因資源被占用進入等待狀態
- 每個條件變量表示一種等待原因,對應一個等待隊列
- wait()操作
- 將自己阻塞在等待隊列中
- 喚醒一個等待者或釋放管程的互斥訪問
- signal()操作
- 將等待隊列中的一個線程喚醒
- 如果等待隊列為空,則等同空操作
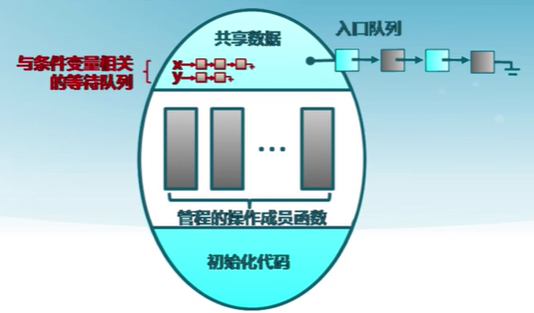
條件變量實現
wait操作中會釋放對資源的占用,進程返回回來之后還會再次占據lock

生產者-消費者問題
因為wait會釋放對資源的占用,所以檢查緩沖區和資源的占用的順序可用調換,不會造成死鎖的現象

條件變量的釋放處理方式
Hansen管程:主要用於真實OS、Java中
Hoare管程:主要見於教材中


11.4 經典同步問題
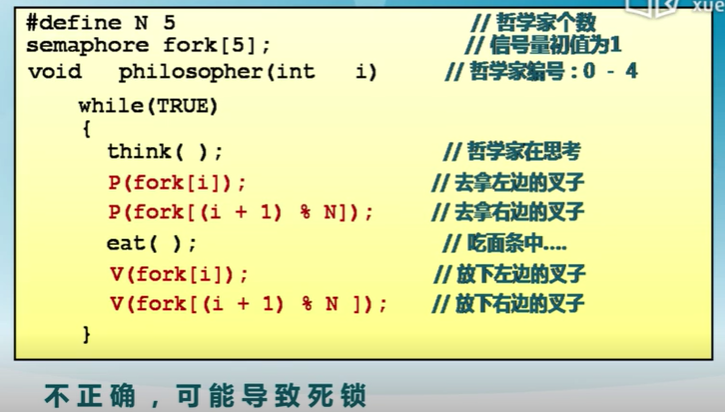
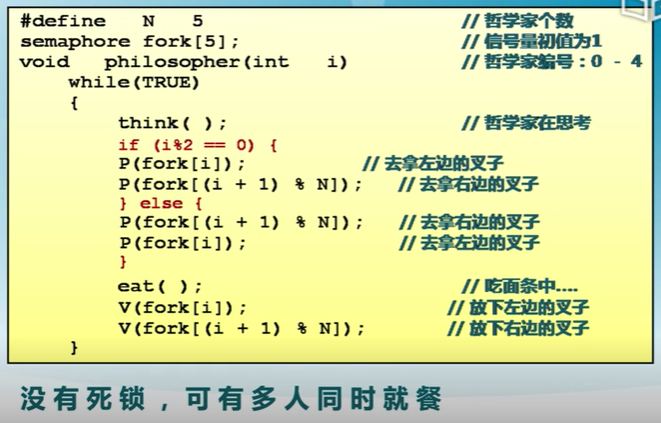
哲學家就餐問題
問題描述:
-
5個哲學家圍繞一張圓桌而坐
- 桌子上放着5支叉子
- 每兩個哲學家之間放一支
-
哲學家的動作包括思考喝進餐
- 進餐時需要同時拿到左右兩邊的叉子
- 思考時將兩只叉子放回原處
-
如何保證哲學家們的動作有序進行?
如:不出現有人永遠拿不到叉子?
方案一
方案二

方案三
讀者-寫者問題
問題描述
- 共享數據的兩類使用者
- 讀者:只讀取數據,不修改
- 寫者:讀取和修改數據
- 對共享數據的讀寫
- 讀-讀允許:允許多個讀者同時讀
- 讀-寫互斥
- 寫-寫互斥
用信號量解決讀者-寫者問題
用信號量描述每個約束
- 信號量 WriteMutex
- 控制讀寫操作的互斥
- 初始化為1
- 讀者計數 Rcount
- 正在進行讀操作的讀者數目
- 初始化為0
- 信號量 CountMutex
- 控制對讀者計數的互斥修改
- 初始化為1

- 讀者優先策略
- 只要有讀者正在讀狀態,后來的讀者都能直接進入
- 如讀者持續不斷進入,則寫者就處於飢餓
- 寫者策略
- 只要有寫者就緒,寫者應盡快執行寫操作
- 如寫者持續不斷就緒,則讀者就處於飢餓狀態
用管程解決讀者-寫者問題
寫者優先

判斷AW+WW是因為采用了Hansen管程,在返回途中可能被寫操作搶先了


12. 死鎖和進程通信
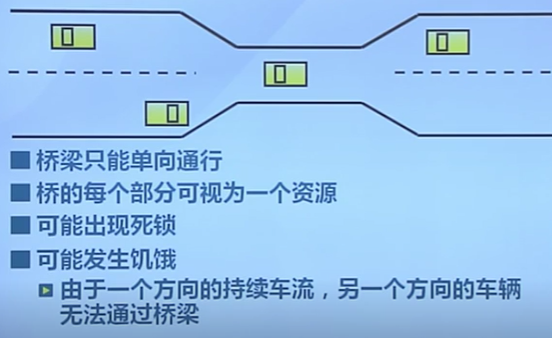
12.1 死鎖
由於競爭資源或通信關系,兩個或更多線程在執行中出現,永遠相互等待只能由其他進程引發的事件
死鎖示例
進程訪問資源的流程
- 資源類型\(R_1,R_2, ...,R_m\)
- CPU執行時間、內存空間、I/O設備
- 每類資源\(R_i\)有\(W_i\)個實例
- 進程訪問資源的流程
- 請求/獲取:申請空閑資源
- 使用/占用:進程占用資源
- 釋放
資源分類
-
可重用資源
- 資源不能被刪除且在任意時刻只能有一個進程使用
- 進程釋放資源后,其他進程可重用
- 可重用資源示例
- 硬件:處理器、I/O通道、主和副存儲器、設備等
- 軟件:文件、數據庫和信號量等數據結構
- 可能出現死鎖
- 每個進程占用一部分資源並請求其他資源
-
消費資源
- 資源創建和銷毀
- 消耗資源示例
- 在I/O緩沖區的中斷、信號、消息等
- 可能出現死鎖
- 進程間相互等待接收對方的消息
資源分配圖
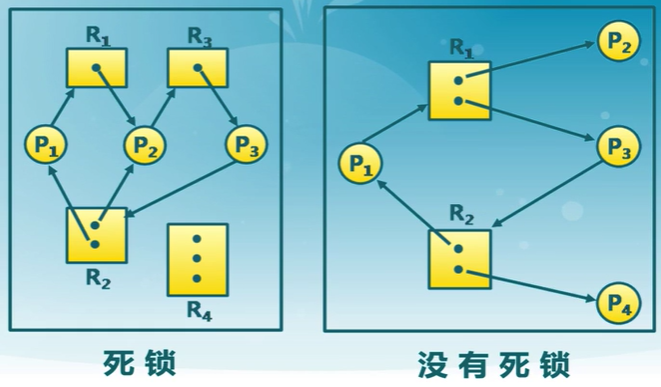
描述資源和進程間的分配和占用關系的有向圖

出現死鎖的必要條件
- 互斥
- 任何時刻只能有一個進程使用一個資源實例
- 持有並等待
- 進程至少保持一種資源,並正在等待獲取其他進程持有的資源
- 非搶占
- 資源只能在進程使用后資源釋放
- 循環等待
12.2 死鎖處理方法
死鎖預防(Deadlock Prevention)
- 確保系統永遠不會進入死鎖狀態
死鎖避免(Deadlock Avoidance)
- 在使用前進行判斷,只允許不會出現死鎖的進程請求資源
死鎖檢測和恢復(Deadlock Detection & Recover)
- 在檢測到運行系統進入死鎖狀態后,進行恢復
由應用進程處理死鎖
- 通常操作系統忽略死鎖
- 大多數操作系統(包括UNIX)的做法
死鎖預防
限制申請方式
預防是采用某種策略,限制並發進程對資源的請求,使系統在任何時刻都不滿足死鎖的必要條件。
- 互斥
- 把互斥的共享資源封裝成可同時訪問
- 持有並等待
- 進程請求資源時,要求它不持有任何其他資源
- 僅允許進程在開始執行時,一次請求所有需要的資源
- 資源利用率低
- 非搶占
- 如進程請求不能立即分配的資源,則釋放已占有資源
- 只在能夠同時獲取所有需要資源時,才執行分配操作
- 循環等待
- 對資源排序,要求進程按順序請求資源
死鎖避免
利用額外的先驗信息,在分配資源時判斷是否會出現死鎖,只在不會死鎖時分配資源
-
要求進程聲明需要資源的最大數目
-
限定提供與分配的資源數目,確保滿足進程的最大需求
-
動態檢查資源分配狀態,確保不會出現環形等待
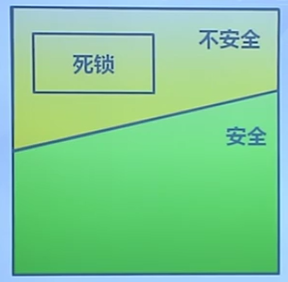
系統資源分配的安全狀態
- 當進程請求資源時,系統判斷分配后是否處於安全狀態
- 系統處於安全狀態
- 針對所有已占用進程,存在安全序列
安全狀態與死鎖的關系
12.3 銀行家算法
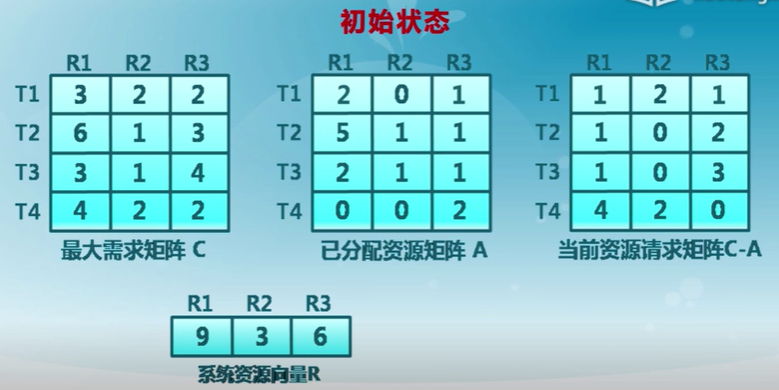
銀行家算法是一個避免死鎖產生的算法。以銀行借貸分配策略為基礎,判斷並保證系統處於安全狀態
- 客戶在第一次申請貸款時,聲明所需最大資金量,在滿足所有貸款要求並完成項目時,即使規划
- 在客戶貸款數量不超過銀行擁有的最大值時,銀行家盡量滿足客戶要求
- 類比
- 銀行家 → 操作系統
- 資金 → 資源
- 客戶 → 申請資源的進程
數據結構
n = 線程數量,m = 資源類型數量

安全狀態判斷算法
當前的剩余資源是否可以滿足其中一個線程的未來需要
遍歷完成實際是找到一個安全序列

銀行家算法

判斷示例
不安全的
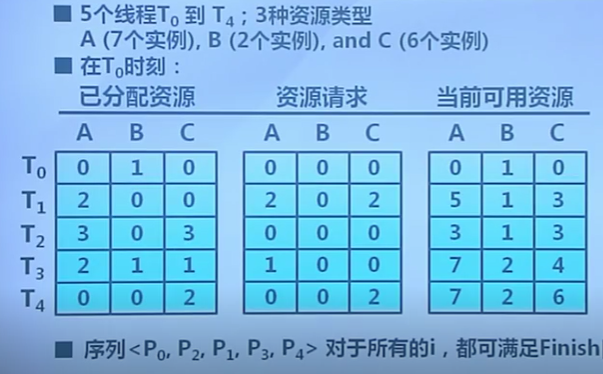
12.4 死鎖檢測
- 允許系統進入死鎖狀態
- 維護系統的資源分配圖
- 定期調用死鎖檢測算法來搜索圖中是否存在死鎖
- 出現死鎖時,用死鎖恢復機制進行恢復
數據結構
- Available:長度為m的向量,每種類型可用資源的數量
- Allocation:一個n×m矩陣,當前分配給各個進程每種類型資源的數量

檢測算法

檢測示例
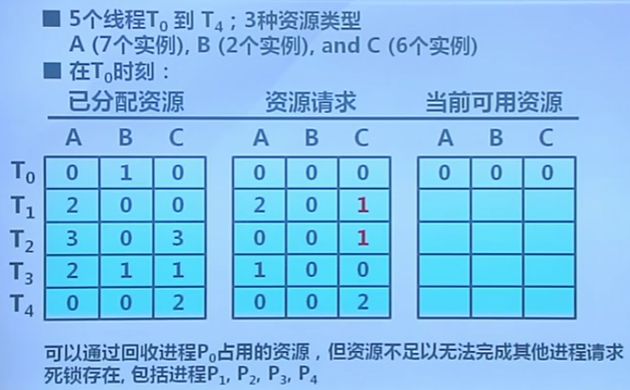
算法使用
- 死鎖檢測的時間和周期選擇依據
- 死鎖多久可能會發生
- 多少進程需要回滾
- 資源圖可能有多個循環
- 難於分辨“造成”死鎖的關鍵進程
死鎖恢復:進程終止
- 終止所有的死鎖進程
- 一次只終止一個進程直到死鎖消除
- 終止進程的順序:
- 進程的優先級
- 進程的已運行時間以及還需運行時間
- 進程已占用資源
- 進程完成需要的資源
- 終止進程的數目
- 進程是交互還是批處理
死鎖恢復:資源搶占
- 選擇被搶占進程
- 最小成本目標
- 進程回退
- 返回到一些安全狀態,重啟進程到安全狀態
- 可能會出現飢餓
- 同一進程可能一直被選為被搶占者
12.5 進程通信
IPC,Inter-Process Communication
- 進程通信是進程進行通信和同步的機制
- IPC提供兩個基本操作
- 發送操作:send(message)
- 接收操作:receive(message)
- 進程間通信
- 在通信進程間建立通信鏈路
- 通過send/receive交換信息
- 進程鏈路特征
- 物理(如共享內存,硬件總線)
- 邏輯(如邏輯屬性)
通信方式

直接通信
- 進程必須正確的命名對方
- send(P,message)發送信息到進程P
- receive(Q,message)從進程Q接收消息
- 通信鏈路的屬性
- 自動建立鏈路
- 一條鏈路恰好對應一對通信進程
- 每隊進程之間只有一個鏈接存在
- 鏈接可以是單向和雙向的
間接通信
-
通過操作系統維護的消息隊列實現進程間的消息接收和發送
- 每個消息隊列都有一個唯一的標識
- 只有共享了相同消息隊列的進程,才能夠通信
-
通信鏈路的屬性
- 只有共享了相同消息隊列的進程,才建立連接
- 連接可以是單向和雙向的
- 消息隊列可以與多個進程相關聯
- 每隊進程可以共享多個消息隊列
-
通信流程
- 創建一個新的消息隊列
- 通過消息隊列發送和接收消息
- 銷毀消息隊列
-
基本通信操作
- send(A,message)發送消息到隊列A
- receive(A,message)從隊列A接收消息
阻塞與非阻塞通信
同步與異步通信
阻塞通信
- 阻塞發送:發送者在發送消息后進入等待,直到接收者成功收到
- 阻塞接收:接收方在請求接收消息后進入等待,直到成功收到一個消息
非阻塞通信
- 非阻塞發送:發送者在發送消息后,可立即進行其他操作
- 非阻塞接收:沒有消息發送時,接收者在請求接收消息后,接收不到任何消息
通信鏈路緩沖
緩沖方式
- 0容量:發送方必須等待接收方
- 有限容量:通信鏈路緩沖隊列滿時,發送方必須等待
- 無限容量:發送方無需等待
12.6 信號和管道
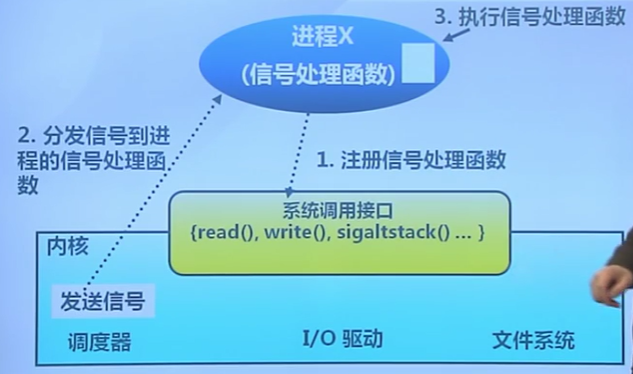
信號
信號的定義
進程間的軟件中斷通知和處理機制
- 如:SIGKILL,SIGSTOP,SIGCONT等
信號的接收處理
- 捕獲(catch):執行進程指定的信號處理函數被調用
- 忽略(Ignore):執行操作系統指定的缺省處理
- 例如:進程終止、進程掛起等
- 屏蔽(Mask):禁止進程接收和處理信號
- 可能是暫時的(當處理同樣類型的信號)
不足
- 傳送的信息量小,只有一個信號類型
信號的實現
使用示例

管道
進程間基於內存文件的通信機制
- 子進程從父進程繼承文件描述符
- 缺省文件描述符:
0 stdin1 stdout2 stderr
進程不知道(或不關心)的另一端
- 可能從鍵盤、文件、程序讀取
- 可能寫入到終端、文件、程序
與管道相關的系統調用
-
讀管道:
read(fd, buffer, nbytes)scanf()基於它實現的
-
寫管道:
write(fd, buffer, nbytes)printf()基於它實現的
-
創建管道:
pipe(rgfd)rgfd是2個文件描述符組成的數組rgfd[0]是讀文件描述符rgfd[1]是寫文件描述符
管道示例

12.7 消息隊列和共享內存
消息隊列
消息隊列是由操作系統維護的以字節序列為基本單位的間接通信機制
- 消息是一個字節序列
- 相同標識的消息組成按先進先出順序組成一個消息隊列(message queues)
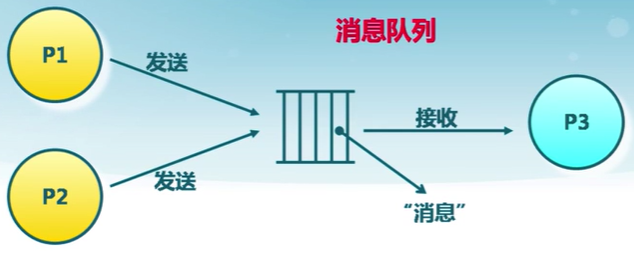
消息隊列的系統調用
-
msgget(key, flags)獲取消息隊列標識
-
msgsnd(QID, buf, size, flags)發送消息
-
msgrcv(QID, buf, size, type, flags)接收消息
-
msgctl(...)消息隊列控制
共享內存
共享內存是把同一個物理內存區域同時映射到多個進程的內存地址空間的通信機制
進程
- 每個進程都有私有內存地址空間
- 每個進程的內存地址空間需明確設置共享內存段
線程
- 同一進程中的線程總是共享相同的內存地址空間
優點
- 快速方便地共享數據
不足
- 必須用額外的同步機制來協調訪問數據
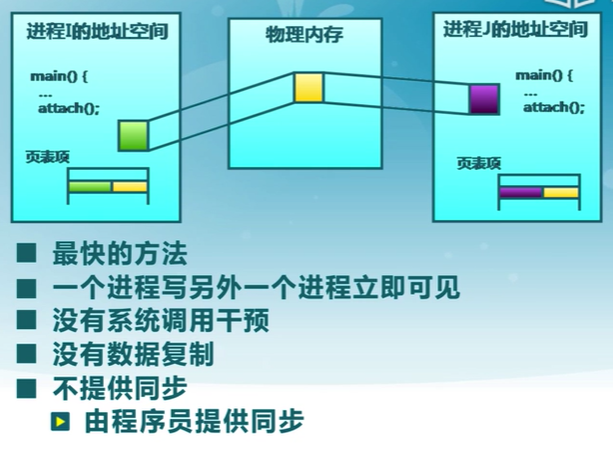
共享內存系統調用
-
shmget(key, size, flags)創建共享段
-
shmat(shmid, *shmaddr, flags)把共享段映射到進程地址空間
-
shmdt(*shmaddr)取消共享段到進程地址空間
-
shmctl(...)共享段控制
-
需要信號量等機制協調共享內存的訪問沖突
13. 文件系統
13.1 文件系統的概念
文件系統和文件
文件系統是操作系統中管理持久性數據的子系統,提供數據存儲和訪問功能。
- 組織、檢索、讀寫訪問功能
- 大多數計算機系統都有文件系統
- Google也是一個文件系統
文件是具有符號名,由字節序列構成的數據項集合
- 文件系統的基本數據單位
- 文件名是文件的表示符號
文件系統的功能
-
分配文件磁盤空間
- 管理文件塊(位置和順序)
- 管理空閑空間(位置)
- 分配算法(策略)
-
管理文件集合
- 定位:文件及其內容
- 命名:通過名字找到文件
- 文件系統結構:文件組織方式
-
數據可靠和安全
- 安全:多層次保護數據安全
- 可靠
- 持久保存文件
- 避免系統崩潰,媒體錯誤,攻擊等
文件屬性
- 名稱、類型、位置、大小、保護、創建者、創建時間、最近修改時間...
文件頭:文件系統元數據中的文件信息
- 文件屬性
- 文件存儲位置和順序
文件描述符
文件訪問模式
- 進程訪問文件數據前必須先“打開”文件
內核跟蹤進程打開的所有文件
- 操作系統為每個進程維護一個打開文件表
- 文件描述符是打開文件的標識
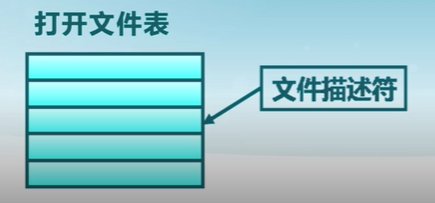
操作系統在打開文件表中維護的打開文件狀態和信息
- 文件指針:最近一次讀寫位置,每個進程分別維護自己的打開文件指針
- 文件打開計數:當前打開文件的次數,最后一個進程關閉文件時,將其從打開文件表中移除
- 文件的磁盤位置:緩存數據訪問位置
- 訪問權限:每個進程的文件訪問模式信息
文件的用戶視圖和系統視圖
文件的用戶視圖
- 持久的數據結構
系統訪問接口
- 字節序列的集合(UNIX)
- 系統不關心存儲在磁盤上的數據結構
操作系統的文件視圖
- 數據塊的集合
- 數據塊是邏輯存儲單元,而扇區是物理存儲單元
- 塊大小<>扇區大小(大小可能不一樣)
用戶視圖到系統視圖的轉換
進程讀文件
- 獲取字節所在的數據塊
- 返回數據塊內對應部分
進程寫文件
- 獲取數據塊
- 修改數據塊中對應部分
- 寫回數據塊
文件系統中的基本操作單位是數據塊
訪問模式
- 操作系統需要了解進程如何訪問文件
- 順序訪問:按字節一次讀取
- 大多數的文件訪問都是順序訪問
- 隨機訪問:從中間讀取?
- 不常用,但重要
- 例如:虛擬內存中把內存頁存儲在文件
- 不常用,但重要
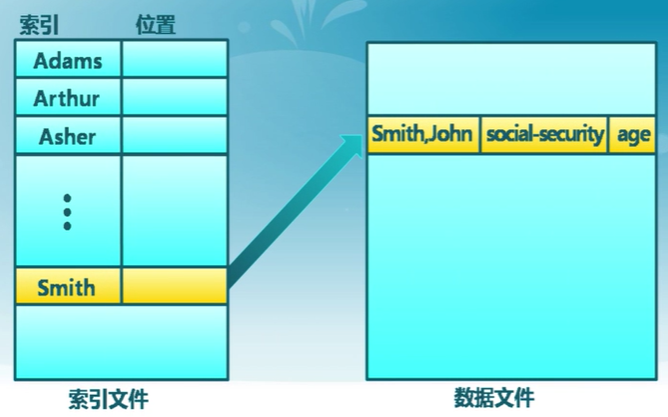
- 索引訪問:依據數據特征索引
- 通常操作系統不完整提供索引訪問
- 數據庫是建立在索引內容的磁盤訪問上
索引文件示例
文件內部結構
- 無結構
- 單詞、字節序列
- 簡單記錄結構
- 分列
- 固定長度
- 可變長度
- 復雜結構
- 格式化文檔(Word PDF)
- 可執行文件等
文件共享和訪問控制
- 多用戶系統中的文件共享是很必要的
- 訪問控制
- 每個用戶能夠獲得哪些文件的哪些訪問權限
- 訪問模式:讀、寫、執行、刪除、列表等
- 文件訪問控制列表(ACL)
- <文件實體,權限>
- 文件訪問控制列表(ACL)
- <用戶|組|所有人,讀|寫|可執行>
- 用戶標識ID
- 識別用戶,表明每個用戶所允許的權限及保護模式
- 組標識ID
- 允許用戶成組,並指定了組訪問權限
語義一致性
- 規定多進程如何同時訪問共享文件
- 與同步算法相似
- 因磁盤I/O和網絡延遲而設計簡單
- UNIX文件系統(UFS)語義
- 對打開文件的寫入內容立即對其他打開同一文件的其他用戶可見
- 共享文件指針允許多用戶同時讀取和寫入文件
- 會話語義
- 寫入內容只有當文件關閉時可見
- 讀寫鎖(一些基本的互斥訪問鎖,用戶進程選擇)
- 一些操作系統和文件系統提供該功能
目錄、文件別名和文件系統種類
- 文件以目錄的方式組織起來
- 目錄是一類特殊的文件
- 目錄的內容是文件索引表<文件名,指向文件的指針>
- 目錄和文件的樹形結構
- 早期的文件系統是扁平的(只有一層目錄)
目錄操作
典型目錄操作
- 搜索文件
- 創建文件
- 刪除文件
- 列目錄
- 重命名文件
- 遍歷路徑
操作系統應該只允許內核修改目錄
- 確保映射的完整性
- 應用程序通過系統調用訪問目錄
目錄實現
- 文件名的線性列表,包涵了指向數據塊的指針
- 編程簡單
- 執行耗時
- 哈希表——哈希數據結構的線性表
- 減少目錄搜索時間
- 沖突——兩個文件名的哈希值相同
- 固定大小
文件別名
兩個或多個文件名關聯同一個文件

硬鏈接:多個文件項指向一個文件
軟鏈接:以”快捷方式“指向其他文件
- 通過存儲真實文件的邏輯名稱來實現
若刪除文件,硬鏈接的文件還是會在,軟鏈接的文件就不在了
文件目錄中的循環
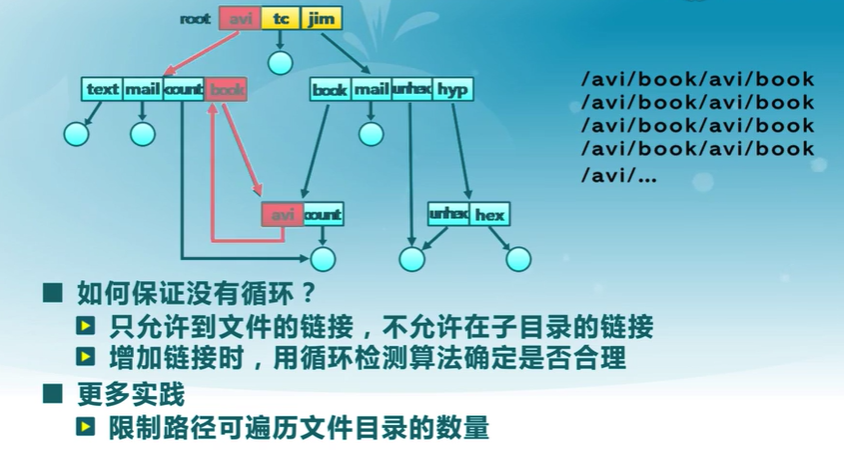
名字解析(路徑遍歷)
- 名字解析:把邏輯名字轉換成物理資源
- 依據路徑名,在文件系統中找到實際文件位置
- 遍歷文件目錄直到找到目標文件

-
當前工作目錄(PWD)
-
每個進程都會指向一個文件目錄用於解析文件名
-
允許用戶指定相對路徑來代替絕對路徑
如,用PWD = ”/bin“ 能夠解析 ”ls“
-
文件系統掛載
- 文件系統需要先掛載才能被訪問
- 未掛載的文件系統被掛載在掛載點
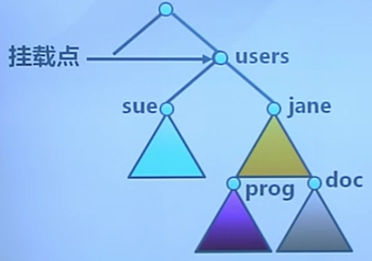
文件系統種類
- 磁盤文件系統
- 文件存儲在數據存儲設備上,如磁盤
- 例如:FAT,NTFS,ext2/3,ISO9660等
- 數據庫文件系統
- 文件特征是可被尋址(辨識)的
- 例如:WinFS
- 日志文件系統
- 記錄文件系統的修改/事件
- 網絡文件系統
- 例如:NFS,SMB,AFS,GFS
- 特殊/虛擬文件系統
網絡/分布式文件系統
- 文件可以通過網絡被共享
- 文件位於遠程服務器
- 客戶端遠程掛載服務器文件系統
- 標准系統文件訪問被轉換成遠程訪問
- 標准文件共享協議
- NFS for UNIX,CIFS for Windows
- 分布式文件系統的挑戰
- 客戶端和客戶端上的用戶辨別起來很復雜
- NFS是不安全的
- 一致性問題
- 錯誤處理模式
- 客戶端和客戶端上的用戶辨別起來很復雜
13.2 虛擬文件系統
文件系統的實現
- 分層結構
- 虛擬(邏輯)文件系統(VFS,Virtual File System)
- 特定文件系統模塊

- 目的
- 對所有不同文件系統的抽象
- 功能
- 提供相同的文件和文件系統接口
- 管理所有文件和文件系統關聯的數據結構
- 高效查詢例程,遍歷文件系統
- 與特定文件系統模塊的交互
文件系統基本數據結構
- 文件卷控制塊(Unix: "superblock")
- 每個文件系統一個
- 文件系統詳細信息
- 塊、塊大小、空余塊、計數/指針等
- 文件控制塊(Unix: "vnode" or "inode")
- 每個文件一個
- 文件詳細信息
- 訪問權限、擁有者、大小、數據塊位置等
- 目錄項(Linux: "dentry")
- 每個目錄項一個(目錄和文件)
- 將目錄項數據結構及樹形布局編碼成樹形數據結構
- 指向文件控制塊、父目錄、子目錄等
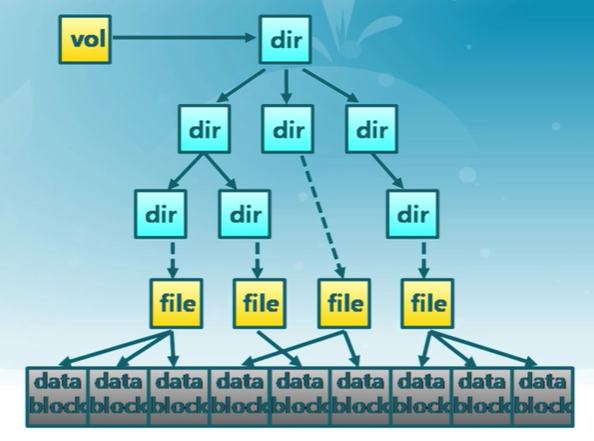
文件系統的存儲結構
文件系統數據結構
- 卷控制塊(每個文件系統一個)
- 文件控制塊(每個文件一個)
- 目錄節點(每個目錄項一個)
持久存儲在外存中
- 存儲設備的數據塊中
當需要時加載進內存
-
卷控制模塊:當文件系統掛載時進入內存
-
文件控制塊:當文件被訪問時進入每次
-
目錄節點:在遍歷一個文件路徑時進入內存
文件系統的存儲視圖
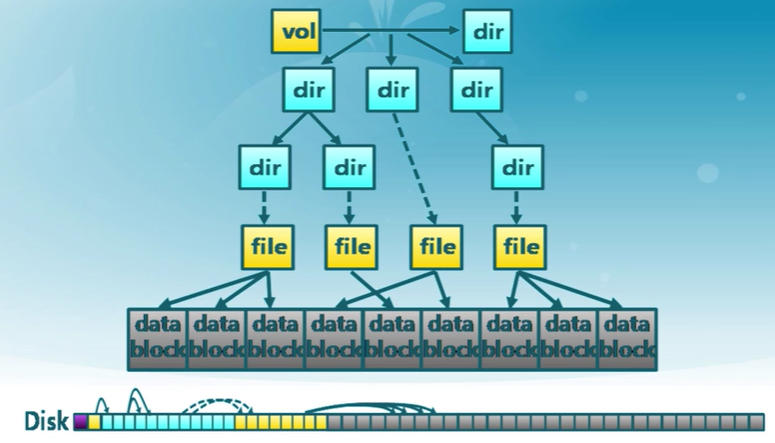
13.3 文件緩存和打開文件
多種磁盤緩存位置
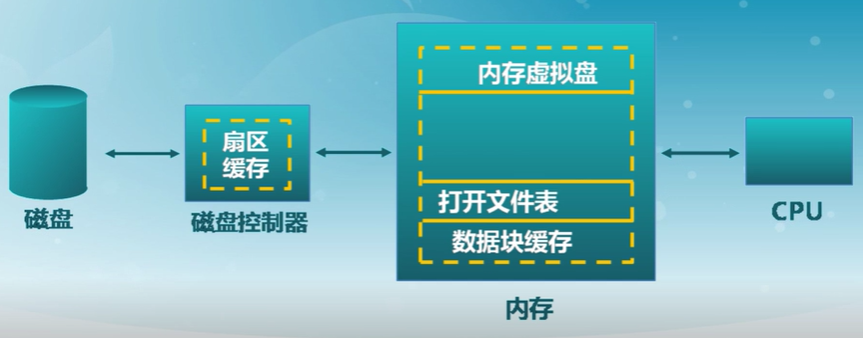
數據塊緩存
- 數據塊按需讀入內存
- 提供read()操作
- 預讀:預先讀取后面的數據塊
- 數據塊使用后被緩存
- 假設數據將會再次用到
- 寫操作可能被緩存和延遲寫入
- 兩種數據塊緩存方式
- 數據塊緩存
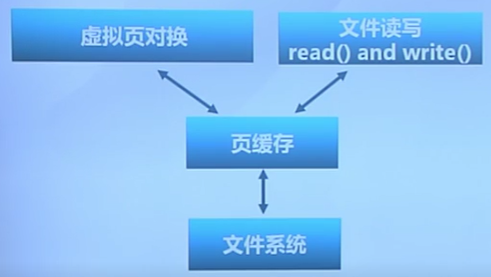
- 頁緩存:統一緩存數據塊和內存頁

頁緩存
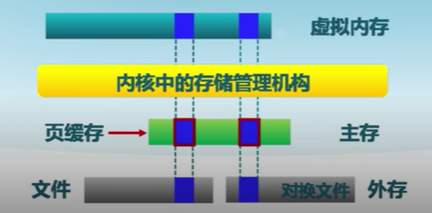
-
虛擬頁式存儲
- 在虛擬地址空間中虛擬頁面可映射到本地外存文件中
-
文件數據塊的頁緩存
- 在虛擬內存中文件數據塊被映射成頁
- 文件的讀/寫操作被轉換成對內存的訪問
- 可能導致缺頁和/或設置為臟頁
- 問題:頁置換算法需要協調虛擬存儲和頁緩存間的頁面數
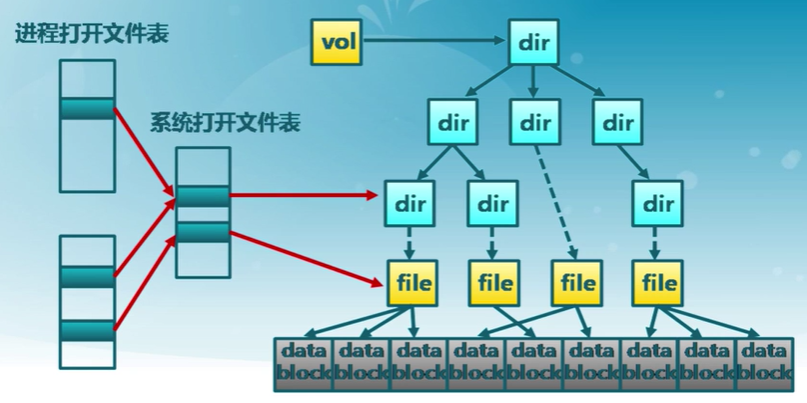
文件系統中打開文件的數據結構
- 文件描述符
- 每個被打開的文件都有一個文件描述符
- 文件狀態信息
- 目錄項、當前文件指針、文件操作設置等
- 打開文件表
- 每個進程一個進程打開文件表
- 一個系統級的打開文件表
- 有文件被打開時,文件卷就不能被卸載
打開文件鎖
一些文件系統提供文件鎖,用於協調多進程的文件訪問
- 強制—根據鎖保持情況和訪問需求確定是否拒絕訪問
- 勸告—進程可以查找鎖的狀態來決定怎么做
13.4 文件分配
文件大小
大多數文件都很小
- 需要對小文件提供很好的支持
- 塊空間不能太大
一些文件非常大
- 必須支持大文件(64位文件偏移)
- 大文件訪問需要高效
如何表示分配給一個文件數據塊的位置和順序
分配方式
- 連續分配
- 鏈式分配
- 索引分配
指標
- 存儲效率:外部碎片等
- 讀寫性能:訪問速度
連續分配

文件頭指定起始塊和長度
分配策略
- 最先匹配、最佳匹配
優點
- 文件讀取表現好
- 高效的順序和隨機訪問
缺點
- 碎片
- 文件增長問題
- 預分配?按需分配?
鏈式分配

文件以數據塊鏈表方式存儲
文件頭包含了第一塊和最后一塊的指針
優點
- 創建、增大、縮小很容易
- 沒有碎片
缺點
- 無法實現真正的隨機訪問
- 可靠性差
- 破壞一個鏈,后面的數據塊也就丟了
索引分配
為每個文件創建一個索引數據塊
- 指向文件數據塊的指針列表
文件頭包含了索引數據塊指針

優點
- 創建、增大、縮小很容易
- 沒有碎片
- 支持直接訪問
缺點
- 當文件很小時索引開銷
- 如何處理大文件?(需要多個索引塊)
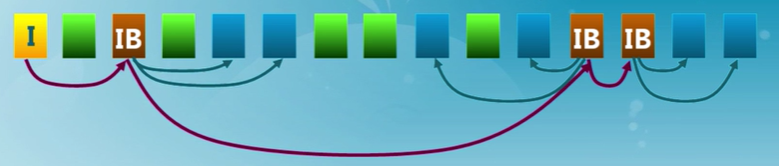
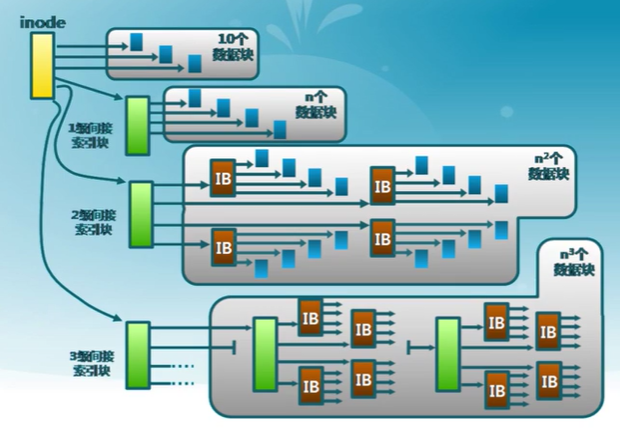
UFS多級索引分配
Unix File System
效果
- 提高了文件大小的限制閾值
- 動態分配數據塊,文件擴展很容易
- 小文件開銷小
- 只為大文件分配間接數據塊,大文件在訪問數據塊時需要大量查詢

13.5 空閑空間管理
跟蹤記錄文件卷中未分配的數據塊
位圖

鏈表

鏈式索引

13.6 冗余磁盤陣列RAID
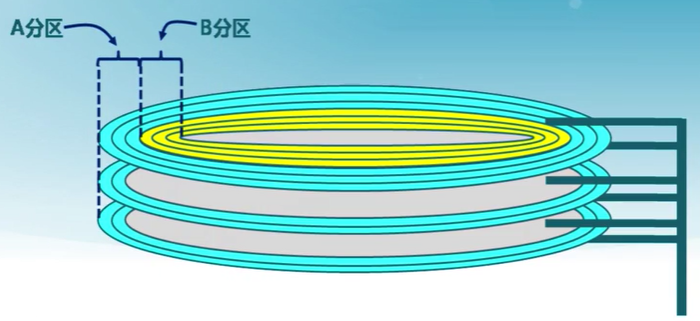
磁盤分區
通常磁盤通過分區來最大限度減小尋道時間
- 分區是一組柱面的集合
- 每個分區都可視為邏輯上獨立的磁盤(切換分區性能很差)
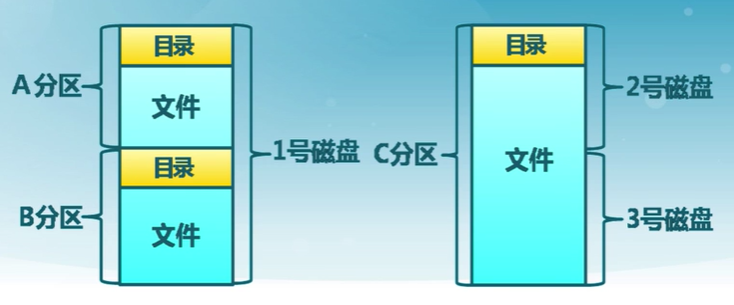
一個典型的磁盤文件系統組織
文件卷:一個擁有完整文件系統實例的外存空間
通常常駐在磁盤的單個分區上
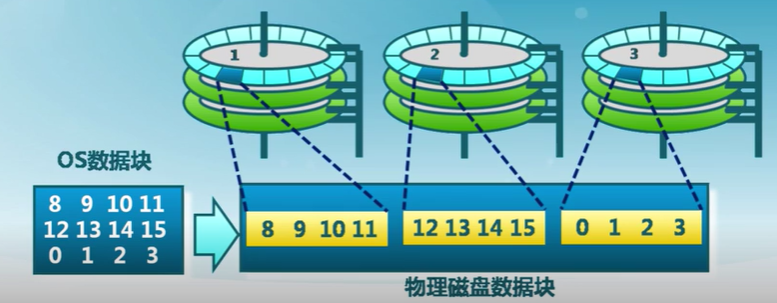
多磁盤管理
使用多磁盤可改善
- 吞吐量(通過並行)
- 可靠性和可用性(通過冗余,數據存多份)
冗余磁盤陣列
RAID,Redundant Array of Inexpensive Disks
- 多種磁盤管理技術
- RAID分類,如 RAID-0, RAID-1, RAID-5
冗余磁盤陣列的實現
- 軟件:操作系統內核的文件卷管理
- 硬件:RAID硬件控制器(I/O)
RAID-0
磁盤條帶化
把數據塊分成多個子塊,存儲在獨立的磁盤中
- 通過獨立磁盤上並行數據訪問提供更大的磁盤帶寬
RAID-1
磁盤鏡像
向兩個磁盤寫入,從任何一個讀取
- 可靠性成倍增長
- 讀取性能線性增加
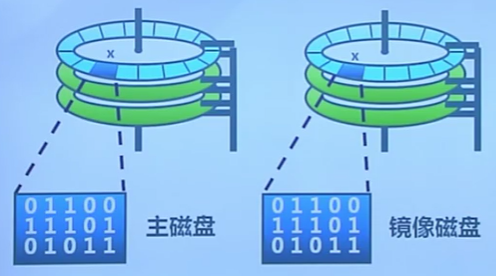
RAID-4
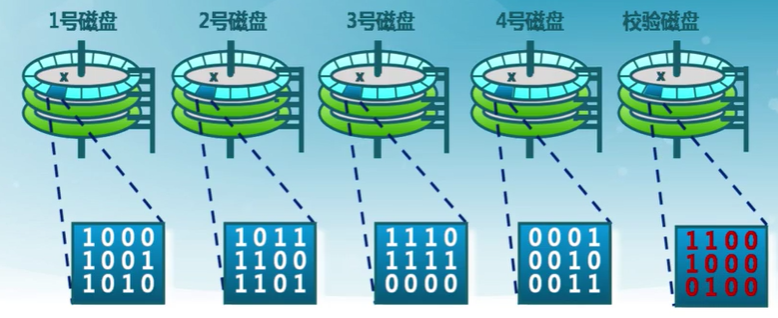
帶校驗的磁盤條帶化
數據塊級的磁盤條帶化加專用的奇偶校驗磁盤
- 允許從任意一個故障磁盤中恢復
提高可靠性和讀寫性能
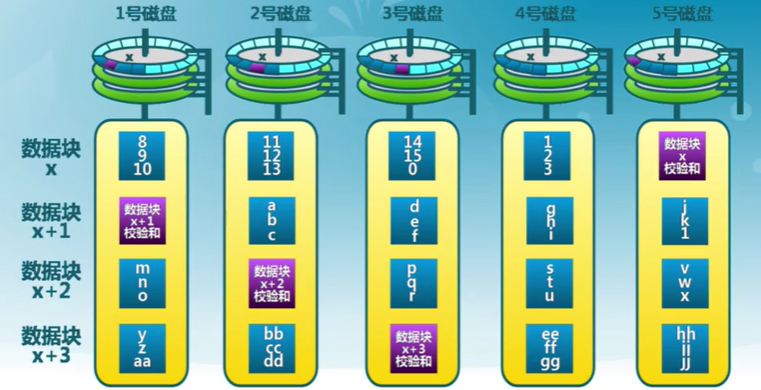
RAID-5
帶分布式校驗的磁盤條帶化
基於位和基於塊的磁盤條帶化
條帶化和奇偶校驗按字節或者位
- RAID-0/4/5:基於數據塊
- RAID-3:基於位

可糾正多個磁盤錯誤的冗余磁盤陣列
RAID-6:每組條帶快帶有兩個冗余塊
- 允許兩個磁盤錯誤
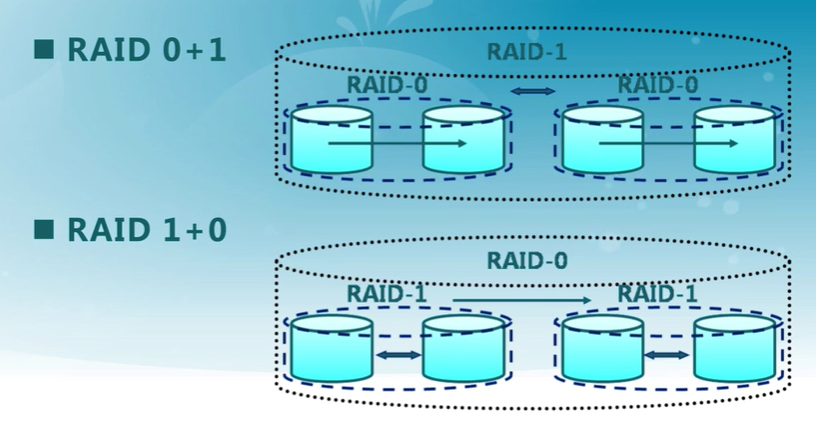
RAID嵌套
14. I/O 子系統
14.1 I/O 特點
設備類型
三種常見設備接口類型
- 字符設備
- 串口、鍵盤、鼠標等
- 訪問特征
- 以字節為單位順序訪問
- I/O命令
- get(), put()等
- 通常使用文件訪問接口和語義
- 塊設備
- 磁盤驅動器、磁帶驅動器、光驅等
- 訪問特征
- 均勻的數據塊訪問
- I/O命令
- 內存映射文件訪問
- 原始I/O或文件系統接口
- 網絡設備
- 以太網、無線、藍牙等
- 訪問特征
- 格式化報文交換
- I/O命令
- send/receive網絡報文
- 通過網絡接口支持多種網絡協議
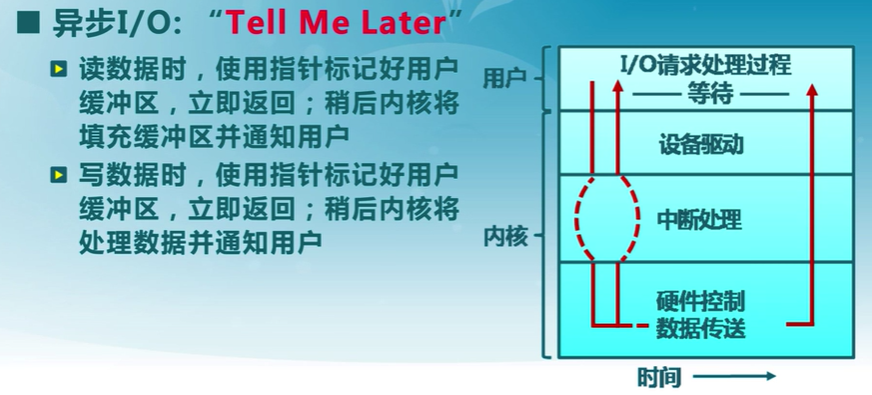
同步與異步I/O
同步
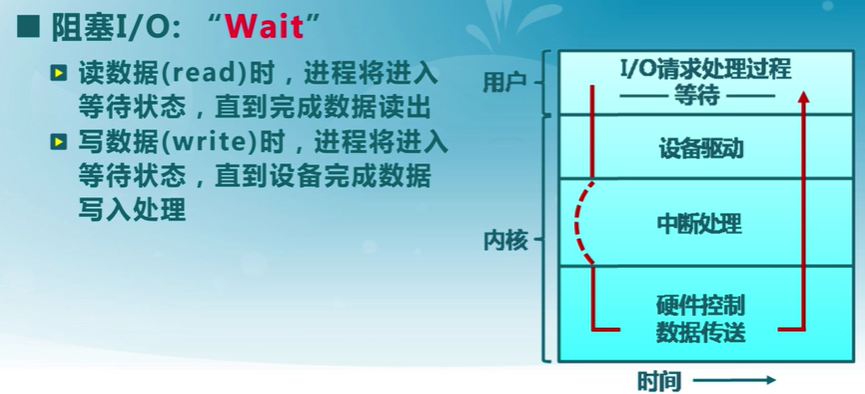
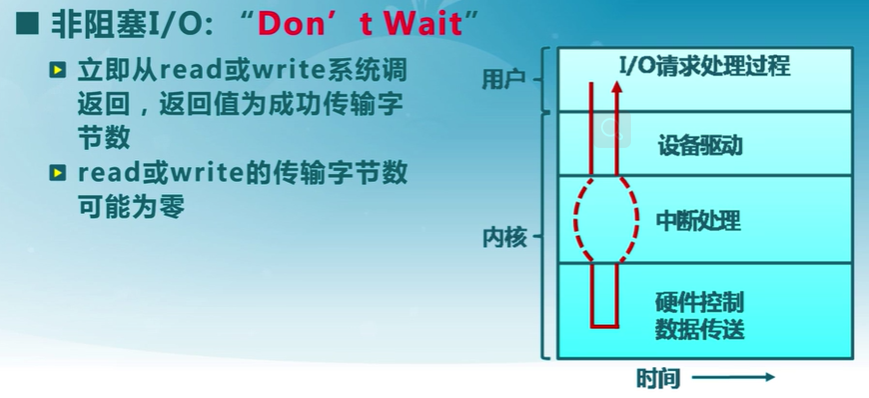
異步
14.2 I/O 結構
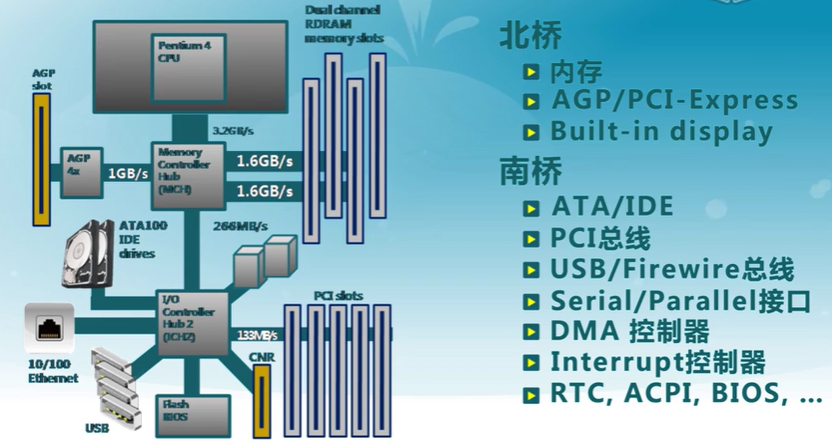
CPU與設備的連接
- 設備控制器
- CPU與I/O設備間的接口
- 向CPU提供特殊指令和寄存器
- I/O地址
- CPU用來控制I/O硬件
- 內存地址或端口號
- I/O指令
- 內存映射I/O
- CPU與設備的通信方式
- 輪詢、設備中斷和DMA(IO直接到內存)
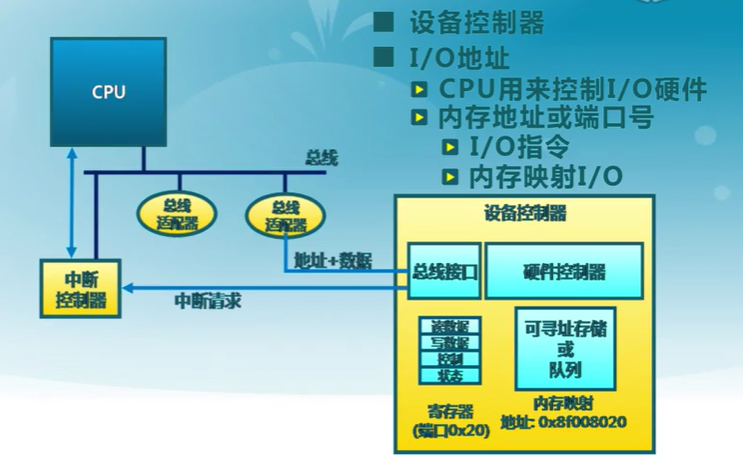
I/O指令和內存映射I/O
- I/O指令
- 通過I/O端口號訪問設備寄存器
- 特殊的CPU指令
- out 0x21, AL
- 內存映射I/O
- 設備的寄存器/存儲被映射到內存物理地址單元
- 通過內存load/store指令完成I/O操作
- MMU設置映射,硬件跳線或程序在啟動時設置地址
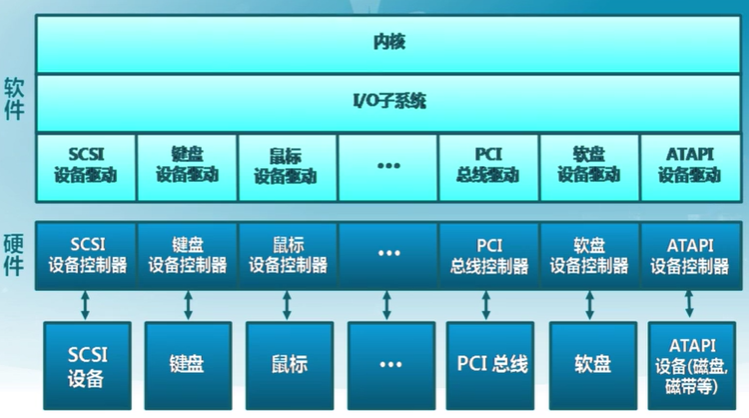
內核I/O結構
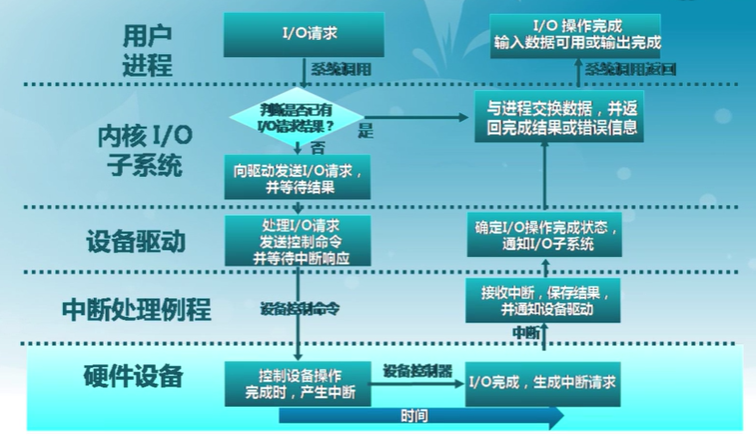
I/O請求生存周期
14.3 I/O 數據傳輸
程序控制I/O(PIO, programmed I/O)
- 通過CPU的in/out或者load/store傳輸所有數據
- 特點
- 硬件簡單、編程容易
- 消耗的CPU時間和數據量成正比
- 適用於簡單的、小型的設備I/O
直接內存訪問(DMA)
- 設備控制器可直接訪問系統總線
- 控制器直接與內存互相傳輸數據
- 特點
- 設備傳輸數據不影響CPU
- 需要CPU參與設置
- 適用於高吞吐量I/O
實例
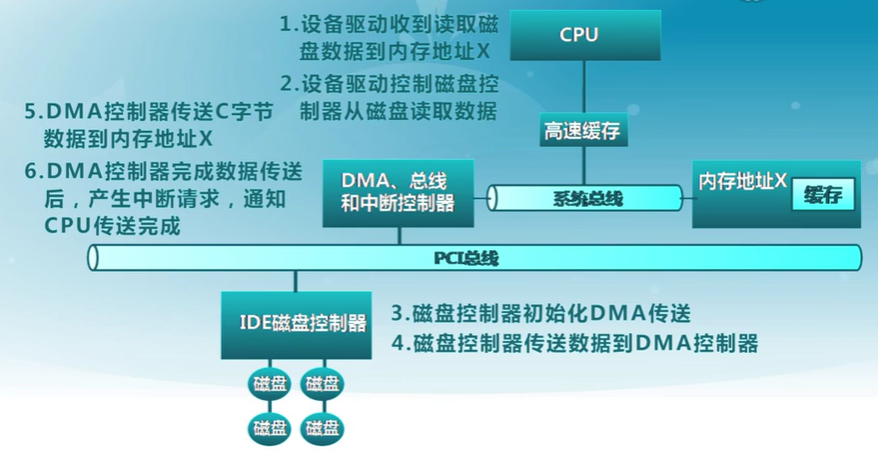
I/O設備通知操作系統的機制
- 操作系統需要了解設備狀態
- IO操作完成時間
- IO操作遇到錯誤
- 兩種方式
- CPU主動輪詢
- 設備中斷
輪詢
- IO設備在特點的狀態寄存器中放置狀態和錯誤信息
- 操作系統定期檢測狀態寄存器
- 特點
- 簡單
- IO操作頻繁或不可預測時,開銷大和延遲長
設備中斷
- 設備中斷處理流程
- CPU在IO之前設置任務參數
- CPU在發出IO請求之后,繼續執行其他任務
- IO設備處理IO請求
- IO設備處理完成時,觸發CPU中斷請求
- CPU接收中斷,分發到相應中斷處理例程
- 特點
- 處理不可預測事件效果好
- 開銷相對較高
- 一些設備可能結合輪詢和設備中斷
- 如 :高帶寬網絡設備
- 第一個傳入數據包到達前采用中斷
- 輪詢后面的數據包直到硬件緩存為空
- 如 :高帶寬網絡設備
設備中斷IO處理流程
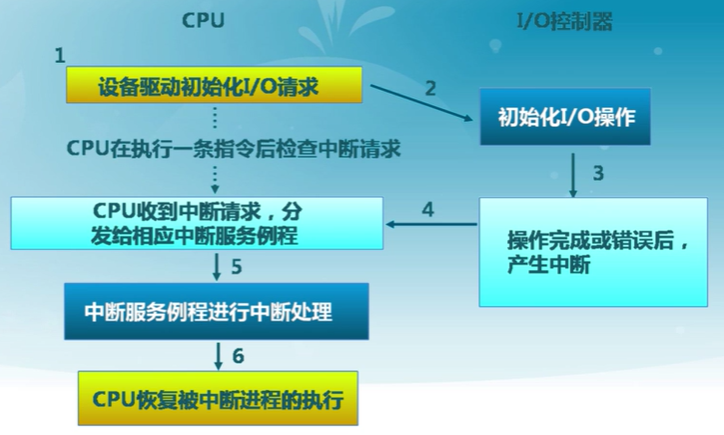
14.4 磁盤調度
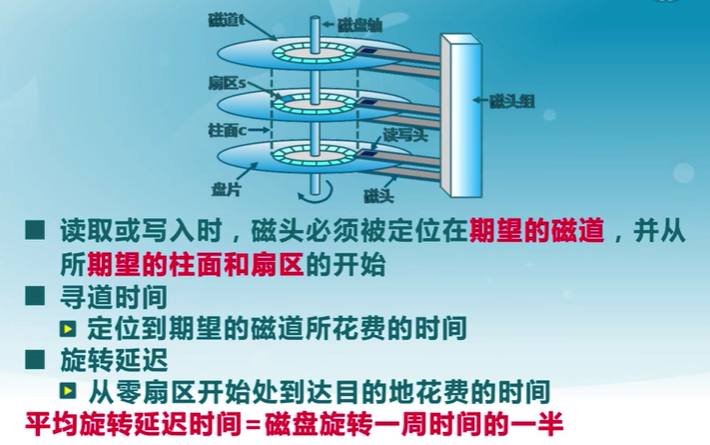
磁盤工作機制和性能參數
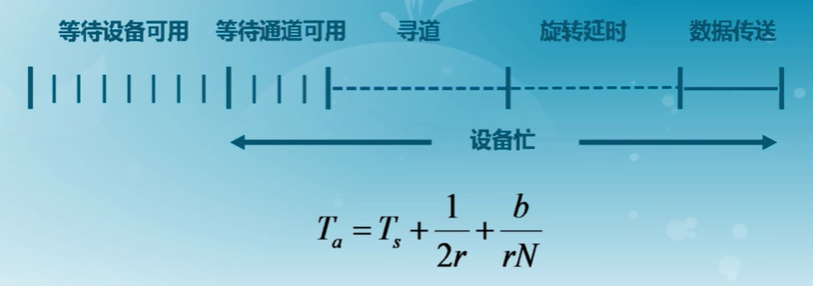
傳輸時間
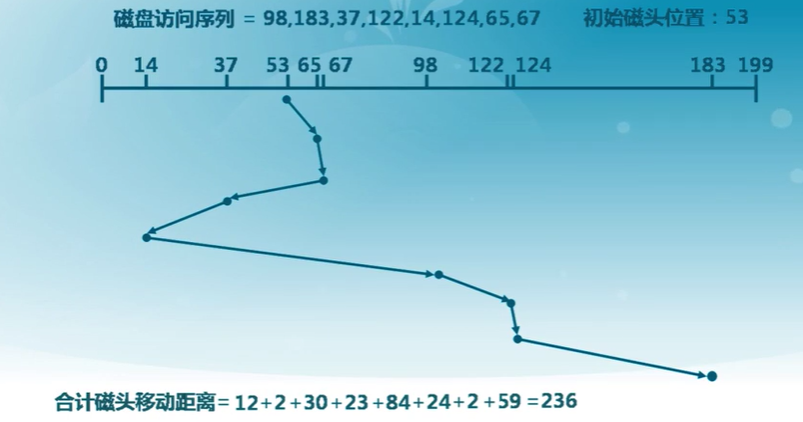
磁盤調度算法
通過優化磁盤訪問請求順序來提高磁盤訪問性能
- 尋道時間是磁盤訪問最耗時的部分
- 同時會有多個在同一磁盤上的IO請求
- 隨機處理磁盤訪問請求的性能表現很差
先進先出(FIFO)算法
- 按順序處理算法
- 公平對待所有進程
- 在有很多進程的情況下,接近隨機調度的性能

最短服務時間優先(SSTF)
- 選擇從磁臂當前位置需要移動最少的IO請求
- 總是選擇最短尋道時間
掃描算法(SCAN)
-
磁臂在一個方向移動,訪問所有未完成的請求,直到磁臂到達該方向上最后的磁道
-
調換方向
-
也稱電梯算法
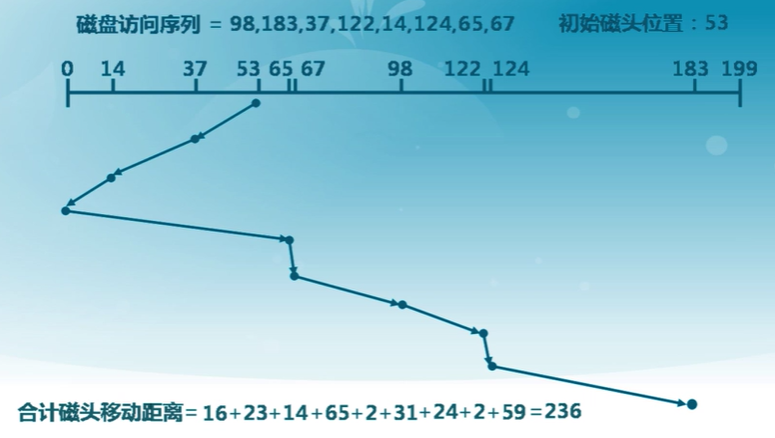
循環掃描算法(C-SCAN)
- 限制了僅在一個方向上掃描
- 當最后一個磁道也被訪問過了后,磁臂返回到磁盤的另外一端再次進行
C-LOOK算法
- 磁臂先到達該方向上最后一個請求處,然后立即反轉,而不是先到最后點路徑上的所有請求
N步掃描算法(N-step-SCAN)
- 磁頭粘着現象(Arm Stickiness)
- SSTF、SCAN和CSCAN的算法中,可能出現磁頭停留在某處不動的情況
- 如:進程反復請求對某一磁道的IO操作
- N步掃描算法
- 將磁盤請求隊列分成長度為N的子隊列
- 按FIFO算法依次處理所有子隊列
- 掃描算法處理每個隊列
雙隊列掃描(FSCAN)算法
- FSCAN是N步掃描的簡化
- 只分為兩個隊列
- FSCAN算法
- 把磁盤IO請求分成兩個隊列
- 交替使用掃描算法處理一個隊列
- 新生成的磁盤IO請求放入另一個隊列中,所有的新請求都將推遲到下一次掃描時處理
14.5 磁盤緩存
緩存
數據傳輸雙方訪問速度差異較大時,引入的速度匹配中間層
磁盤緩存是磁盤扇區在內存中的緩存區
-
磁盤緩存的調度算法很類似虛擬存儲調度算法
-
磁盤的訪問頻率遠低於虛擬存儲中的內存訪問頻率
-
通常磁盤緩存調度算法會比虛擬存儲復雜
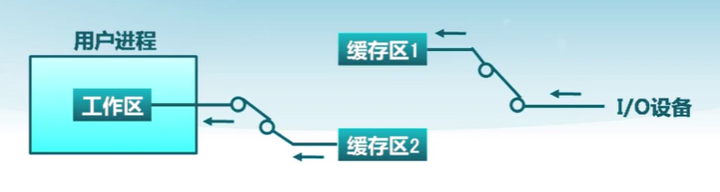
單緩存與雙緩存
單緩存(Single Buffer Cache)

雙緩存(Double Buffer Cache)
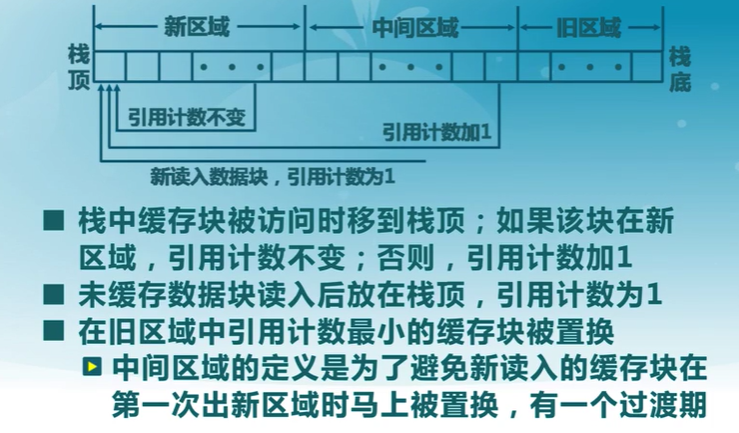
訪問頻率置換算法
Frequency-based Replacement
問題
- 在一段密集磁盤訪問后,LFU算法的引用計數變化無法反映當前的引用情況
算法思路
- 考慮磁盤訪問的密集特征,對密集引用不計數
- 在短周期內使用LRU算法,而在長周期中使用LFU算法