前言
pin_memory 和 non_blocking的作用分別是什么?網上看了很多解釋,只是稀里糊塗的有個感覺,就是用了這玩意速度能變快,但是不知所以然,這篇文章希望能幫助你解惑,也給自己做個筆記,以備日后查閱。
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset,
...,
pin_memory=True
)
for data, labels in train_loader:
data = data.to('cuda:0', non_blocking=True)
1. pin_memory
1.1 什么是鎖頁內存(Pinned Memory/PageLocked Memory)?什么是"Pinned"?
通常我們的主機處理器是支持虛擬內存系統的,即使用硬盤空間來代替內存。大多數系統中虛擬內存空間被划分成許多頁,它們是尋址的單元,頁的大小至少是4096個字節。虛擬尋址能使一個連續的虛擬地址空間映射到物理內存並不連續的一些頁。
如果某頁的物理內存被標記為換出狀態,它就可以被更換到磁盤上,也就是說被踢出內存了。如果下次需要該頁了,則重新加載到內存里。顯然如果這一頁切換的非常頻繁,那么會浪費不少時間。
鎖頁(pinned page)是操作系統常用的操作,就是為了使硬件外設直接訪問CPU內存,從而避免過多的復制操作。被鎖定的頁面會被操作系統標記為不可被換出的,所以設備驅動程序給這些外設編程時,可以使用頁面的物理地址直接訪問內存,CPU也可以訪問上述鎖頁內存,但是此內存是不能移動或換頁到磁盤上的。另外,在GPU上分配的內存默認都是鎖頁內存,這只是因為GPU不支持將內存交換到磁盤上。
1.2 什么時候設置pin_memory=True?
總結一下上一小節的內容就是:
內存可以分為 沒鎖的(pageable,可分頁的) 和 鎖了的(pinned)。
- 鎖頁內存和GPU顯存之間的拷貝速度大約是6GB/s
- 可分頁內存和GPU顯存間的拷貝速度大約是3GB/s。
- GPU內存間速度是30GB/s,CPU間內存速度是10GB/s
Host(例如CPU)的數據分配默認是pageable(可分頁的),但是GPU是沒法直接讀取pageable內存里的數據的,所以需要先創建一個臨時的緩沖區(pinned memory),把數據從pageable內存拷貝pinned內存上,然后GPU才能從pinned內存上讀取數據,如下圖(左)所示。
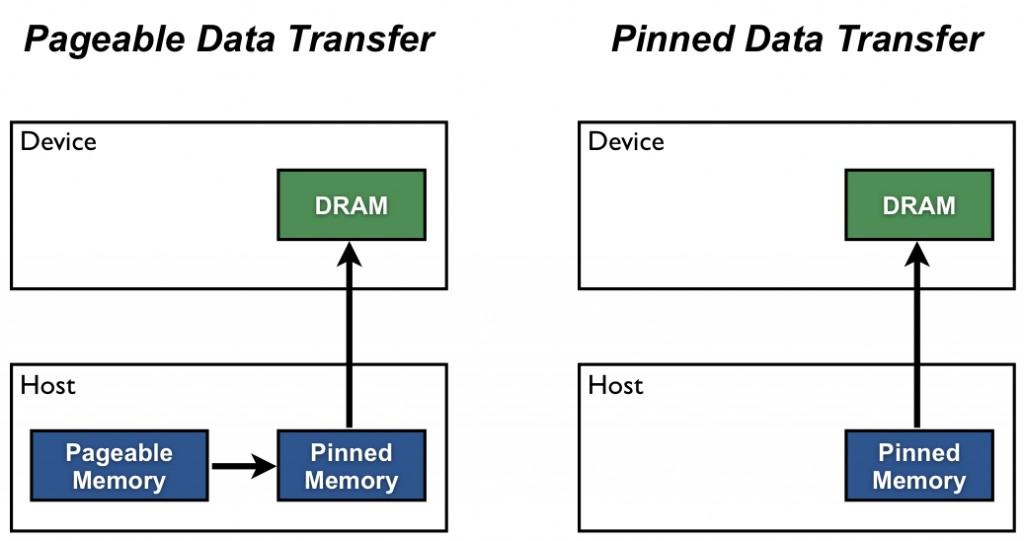
但是CPU將數據從pageable 內存拷貝到 臨時的 pinned 內存是有時間開銷的,而且這個pinned 內存 還只是臨時的,所以用完之后會被銷毀。所以為了進一步提高效率,我們需要設置pin_memory=True,作用就是從一開始就把一部分內存給鎖住(上圖(右)),這樣一來就減少了Host內部的開銷,避免了CPU內存拷貝時間。
按照官方的建議[1]是你默認設置為True就對了。
2. non_blocking
2.1 CUDA Default Streams
在CUDA里, "Stream"是指一系列的操作,這些操作按照主機代碼發出的順序在設備上執行。同一個Stream里的操作是按順序執行的,而不同Stream里的操作可以交錯執行,並且在可能的情況下,它們甚至可以並發執行。
stream有很多種,無特殊指定的話使用的就是默認stream(default stream,也稱作 null stream)。它和其他stream的卻比就在於:1)如果其他stream上的操作沒結束,null stream就不會開始; 2)在device上的其他stream要開始之前,null stream必須先完成。所以說null stream是設備相關操作的同步流(synchronizing stream)。
我們看下面使用default stream的例子,注意cuda代碼有個特點,即代碼是在Host和Device上通用的,換句話說有的代碼可能運行在Host上,有的是在Device上。
cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice);
increment<<<1,N>>>(d_a)
cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);
上面3行代碼都屬於 default stream,因此是按順序執行的。具體來說從device的角度看,從GPU上啟動一個kernel是異步的操作,而data transfer操作是一個blocking或者synchronous操作。
- 第一行是將數據從Host(CPU內存)拷貝到device(GPU顯存)。注意此時還是在Host上執行的,也就是說這個時候Host上的CPU在將數據拷貝到Device上,所以必須得等到第一行運行結束后,才會進入到第二行代碼
- 第二行代碼是在Device上啟動(launch)和執行(execute)的。注意分成啟動和執行兩步驟。一旦第二行啟動后,主機上的CPU就會立馬執行第三行,並不會再去等執行了
- 第三行代碼是將數據從Device拷貝到Host,但是此時的data transfer需要等到第二行Device執行結束才能開始。
通過上面的例子我們知道kernel的啟動是異步的,也就是說一旦kernel被啟動,Host就可以直接運行下一行代碼。比如我們更改一下代碼,如下所示。下面代碼當第二行kernel啟動后,Device就會開始執行increment計算,而Host上的CPU會立馬執行第三行。此時Host和Device同時都在干活,假設二者的計算時間相等,那么第四行基本上就可以無縫銜接了。
對於Device而言,上下兩個代碼示例並無差別,但是對於Host而言,其效率提升了。
cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice);
increment<<<1,N>>>(d_a)
myCpuFunction(b)
cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);
2.2 Non-default Stream
上面介紹的是default stream,那么就有non-defalut stream,CUDA代碼中定義的方法示例如下
cudaStream_t stream1;
cudaError_t result;
result = cudaStreamCreate(&stream1)
result = cudaStreamDestroy(stream1)
為了給non-defalut stream傳輸數據,我們使用cudaMemcpyAsync()函數,它類似於前一篇示例中討論的cudaMemcpy()函數,但需要將 stream 標識符作為第五個參數傳入,即
// 將數據從Host傳輸到Device
result = cudaMemcpyAsync(d_a, a, N, cudaMemcpyHostToDevice, stream1)
cudaMemcpyAsync在Host上是 non-blocking 的,也就是說數據傳輸kernel一啟動,控制權就直接回到Host上了,即Host不需要等數據從Host傳輸到Device了。
non-default stream上的所有操作相對於 host code 都是 non-blocking 的,即它們不會阻塞Host代碼。
所以下面代碼中的第二行應該是在第一行啟動后就立馬執行了。Pytorch官方的建議是pin_memory=True和non_blocking=True搭配使用,這樣能使得data transfer可以overlap computation。
x = x.cuda(non_blocking=True)
pre_compute()
...
y = model(x)
注意non_blocking=True后面緊跟與之相關的語句時,就會需要做同步操作,等到data transfer完成為止,如下面代碼示例
x=x.cuda(non_blocking=True)
y = model(x)