©原創作者 | 王翔
論文名稱:
Template-free Prompt Tuning for Few-shot NER
文獻鏈接:
https://arxiv.org/abs/2109.13532
01 前言
1.論文的相關背景
Prompt Learning通過設計一組合適的prompt將下游任務的輸入輸出形式重構成預訓練任務中的形式,充分利用預訓練階段學習的信息,減少訓練模型對大規模標注數據集的需求。
例如對於用戶評論的情感分析任務:判斷用戶評論的“交通太不方便了。”這句話蘊含的情感是“正面”還是“負面”。原有的處理范式是將其建模成一個文本分類問題,輸入“交通太不方便了。”,輸出“正面”或者 “負面”。
但如果使用Prompt Learning范式,則會將輸入重構成“交通太不方便了。感覺很“[MASK]”,輸出“好”或者“差”。
Prompt Learning借助合適的prompt減少了預訓練和微調之間的差異,進而使得模型在少量的樣本上進行微調,即可取得不錯的效果,因此受到大量專家學者的關注,被譽為自然語言處理的第四范式。
命名實體識別是指識別文本中具有特定意義的實體,主要包括人名、地名、 機構名、專有名詞等。
目前基於深度學習的命名實體識別方法已經取得了較高的識別精度,但由於深度學習模型依賴於大量的標注語料,因此在缺少大規模標注數據的垂直領域很難取得較好的效果。
針對少樣本命名實體識別問題,常規的方案是基於相似性的度量方法,但該方法無法利用模型參數中的知識進行遷移。
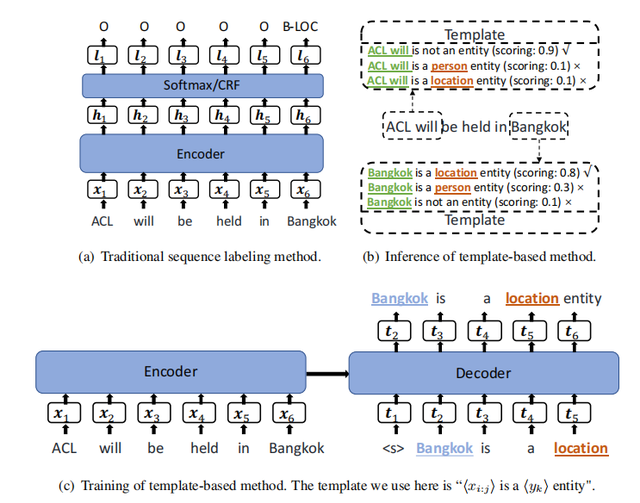
為了解決該問題,如下圖所示的TemplateNER引入Prompt Learning通過人工設計的實體模板(<候選實體> is a <實體類型> entity)和非實體模板(<候選實體> is not a named entity)將命名實體識別問題建模成seq2seq框架下的語言模型打分任務,具體過程如下圖所示。
TemplateNER在跨域和少樣本場景下顯著優於傳統的序列標記方法和基於距離的少樣本NER方法,但TemplateNER在生成候選實體時需要使用n-grams方法進行枚舉,因此存在嚴重的效率問題。
2. 論文主要解決的問題
TemplateNER等基於Prompt Learning命名實體識別模型在識別效率上的問題
3. 論文的主要創新和貢獻
● 提出了一種少樣本場景下無模板的基於Prompt Learning的命名實體識別算法
● 舍棄了使用n-grams方法生成候選實體的思路,進而解決了TemplateNER等基於Prompt Learning命名實體識別模型的效率問題
02 論文摘要
Prompt Learning已被廣泛應用於句子級自然語言處理任務中,但其在命名實體識別這類字符級的標記任務上取得的進展卻相當有限。
TemplateNER通過n-grams方法枚舉所有的潛在實體構建prompt進行命名實體識別任務,使得Prompt Learning得以應用於命名實體識別任務,但該構建方法容易產生大量的冗余數據,影響模型的效率。
針對上述問題,本文放棄了常規的prompt構建方法,采用預訓練任務中的掩碼預測任務的形式,將命名實體識別任務轉化成將實體位置的詞預測為選定的標簽詞的任務。
同時,為了標簽詞可以適配預訓練語言模型的分布,本文提供了四種搜索適配模型的標簽詞的方法。
實驗結果表明,在少樣本場景下,本文方法優於直接使用BERT進行命名實體識別和TemplateNER。此外,在解碼速度方面該方法比TemplateNER快1930.12倍。
03 論文模型
3.1 Entity-Oriented LM Fine-tuning
為了解決TemplateNER存在的效率問題,論文提出了一種Entity-Oriented LM(EntLM)微調方法,整體形式與圖(a)所示的傳統序列標注任務范式一致,不同的是,傳統的序列標注任務的輸出是輸入句子中每個字符所對應的實體類型標簽,EntLM則是輸出的非實體部分同輸入字符,實體部分為預設的最能代表該實體類型的字符。
如下圖(b)所示,輸入為`Obama was born in America`,其中`Obama `是實體類型標簽為`PER`(人物)的實體,`America`是實體類型標簽為`LOC`(地名)的實體,預設最能代表`PER`類型的字符是`John`,最能代表`LOC`類型的字符是`Australia`,則`was born in`所對應的輸出為`was born in`,`Obama `所對應的輸出為`John`,`America`所對應的輸出為`Australia`。
與圖(c)所示的TemplateNER需要針對實體類型和候選實體構建不同的模板進行輸入相比,EntLM的實體識別過程僅需要一次前向計算即可完成,大大減少了冗余計算,提高了算法識別的效率。
至此,論文已經解決了TemplateNER等基於Prompt Learning命名實體識別模型的效率問題,但同時也延伸出了新的問題,即如何選定代表實體類型的字符(論文將該類字符成為label word)。

3.2 Label Word Engineering
EntLM面對的是少樣本場景,因此如果只使用訓練數據來生成label word,不論是使用何種算法都會面臨label word不置信的問題。
為了解決上述問題,論文采用了BOND[1]中遠程監督生成偽標簽數據的方法(盡管論文中提到該方法引用自BOND,但其實該部分就是一個普通的遠程監督生成偽標簽數據的過程,並未實際使用BOND算法),借助外部知識庫為數據提供標簽,該方法的假設便是如果文本中的字符串包含在預定義的實體字典中,則該字符串可能是一個實體。
遠程監督生成偽標簽的方法存在噪聲標注的問題,但EntLM使用遠程監督的目標是為了找到相對置信的label word,而不是將其直接作為標簽使用,因此,噪聲標注對其影響相對較小。
生成偽標簽數據后,論文提供了四種方法用來選定label word。
●Searching with data distribution (Data search)
每類實體類型均選擇出現頻率最高的字符作為label word,例如在偽標簽數據中屬於`LOC`類型的字符僅有`America`和`Australia`,其中`America`出現的頻率為5,`Australia`出現的頻率為6,則選擇`Australia`作為label word。
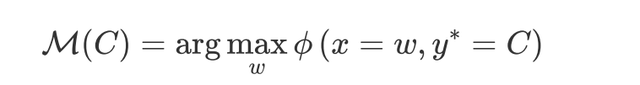
●Searching with LM output distribution (LM search)
使用預訓練模型對偽標簽數據中的每個樣本進行掩碼預測,獲取模型在每個實體位置上的預測分布,選擇每個實體位置預測TOPK的字符進行頻率統計。
例如,對`Obama was born in America`進行掩碼預測,`America`位置對應的預測TOP3為`America`、`Australia`和`Beijing`,若選擇TOP2進行頻率統計,則`America`作為`LOC`類型出現的頻率加1,`Australia`作為`LOC`類型出現的頻率加1。
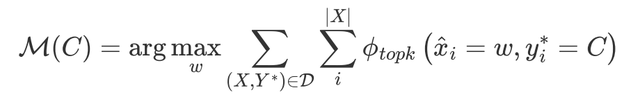
●Searching with both data & LM output distribution (Data&LM seach)
綜合上述兩個方法,使用兩種頻率的乘積作為最終的頻率
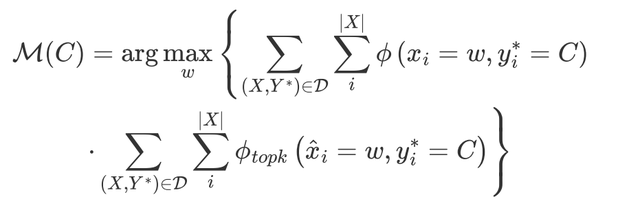
●Virtual label word (Virtual)
選擇實體類型中出現頻率TOPK的字符的詞向量(通過預訓練模型生成)進行平均作為代表該類實體類型的向量,進而生成虛擬label word。
例如,`LOC`類型中出現頻率TOP2的字符分別為`America`和`Australia`,將這兩個字符的詞向量進行平均,生成的新詞向量記為`LOC`的詞向量。
生成`LOC`的詞向量后,將`LOC`和`LOC`的詞向量加入到預訓練模型的詞典。
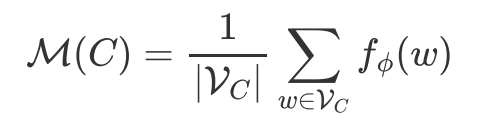
3.3 Removing conflict label words
因為存在一個高頻詞出現在多個實體類型中的情況,因此論文設置了一個閾值Th來判斷高頻詞是否能屬於某一類實體:
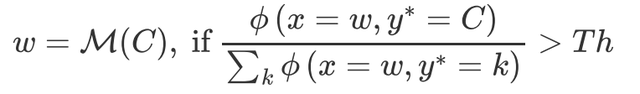
04 論文實驗
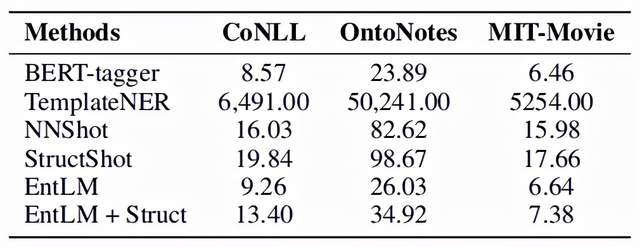
EntLM主要在`CoNLL2003`、`OntoNotes 5.0`和`MIT-Movie`上進行實驗,由於主要是驗證模型對於文本中出現的實體的識別能力,因此刪去了OntoNotes 5.0數據集中值、數字、時間和日期等實體類型。
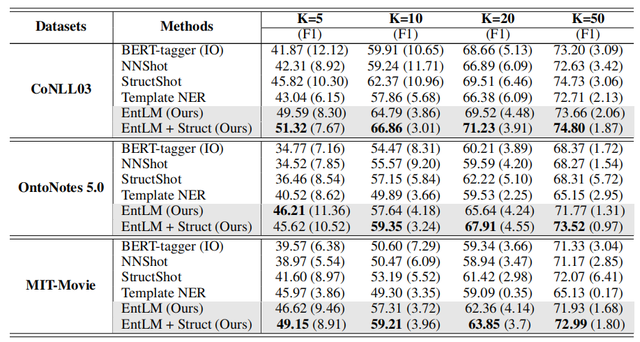
評價指標采用了F1-score。實驗結果如下圖,其中BERT-tagger是直接使用BERT微調的模型,NNShot和StructShot是基於相似性的度量方法,EntLM+Struct則是在EntLM的基礎上使用維特比算法對輸出進行解碼[2],可以看出EntLM在三個數據集上都取得了不錯的效果。
論文對EntLM的效率進行了實驗,由於EntLM摒棄了人工設計模板和使用n-grams方法生成候選實體的做法,因此EntLM在推理速度上相比於TemplateNER有明顯的優勢:
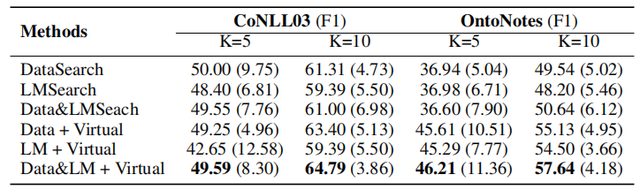
此外,論文還針對不同label word搜索方法對EntLM的影響進行了實驗,結果如下圖所示,可以發現將Data search、LM search和Virtual結合使用可以獲得最佳的效果。
參考文獻
[1] [BOND: BERT-Assisted Open-Domain Named Entity Recognition with Distant Supervision](https://arxiv.org/abs/2006.15509)
[2] [Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning](https://aclanthology.org/2020.emnlp-main.516.pdf)