前言
Thanos 已成為目前 Kubernetes 集群監控的標准解決方案之一。它基於 Prometheus 之上,可以為我們提供:
- 全局的指標查詢視圖
- 近乎無限的數據保留期限
- 包含 Prometheus 在內所有組件的高可用性
在擬定監控方案之前,閱讀一些成熟的 用戶案例 是十分必要的。這些博文首先分析了各自團隊的集群現狀以及當前監控方案難以解決的痛點,再對目前流行的幾種技術棧進行對比,最后介紹投入生產使用的部署方案,因此非常值得一讀。
不過,由於 Thanos 的組件眾多,且每種組件都有較多參數需要配置。對於剛接觸 Thanos 的用戶來說,可能難以快速上手。考慮到上述博文均未給出組件的具體配置信息,而官方提供的 部署清單 又稍顯復雜並缺少詳細說明。因此本文將介紹一個使用 Thanos 實現多集群(租戶)監控的簡單 Demo,希望能對試圖嘗鮮 Thanos 的用戶有所幫助。它實現了以下功能:
- 能夠監控多個集群,並提供一個全局的指標查詢視圖;
- 每個集群都對應了一個唯一的租戶 ID,可以通過租戶標簽區分不同集群的指標數據;
- 如果某個租戶創建了新的集群,只需在新集群中部署 Prometheus 並配置遠程寫入;
- 簡單的告警規則和告警消息推送。
Sidecar vs. Receiver
Thanos 支持 Sidecar 和 Receiver 兩種部署模式。它們各有利弊,需要我們根據實際情況進行取舍。
Sidecar 通常每隔 2 小時才會把 Prometheus 采集到的指標上傳到對象存儲中,因此 Query 查詢近期數據時需要向所有 Sidecar 發起請求並合並返回結果。但這並非是 Thanos 團隊引入 Receiver 的決定性因素。
Receiver is only recommended for uses for whom pushing is the only viable solution, for example, analytics use cases or cases where the data ingestion must be client initiated, such as software as a service type environments.
按照文檔中的說法,Receiver 只推薦用於多租戶以及 Prometheus 配置受限的場景下,比如:
- 租戶使用某些 SaaS 服務對集群進行監控,如 Openshift Operator 部署的 Prometheus;
- 由於安全或權限問題,監控團隊無法在被監控集群中配置 Sidecar;
- 被監控集群部署的是非容器化部署的 Prometheus。
這是因為 Receiver 會暫存多個 Prometheus 實例的 TSDB,當數據量較大時可能會發生 OOM。另外根據 官方文檔,開啟遠程寫入還將增加 Prometheus 約 25% 的內存使用。
我們並非一定要在 Receiver 和 Sidecar 之間做出抉擇,比如 Lastpass 就采用了 Sidecar 與 Receiver 混合部署的方式:
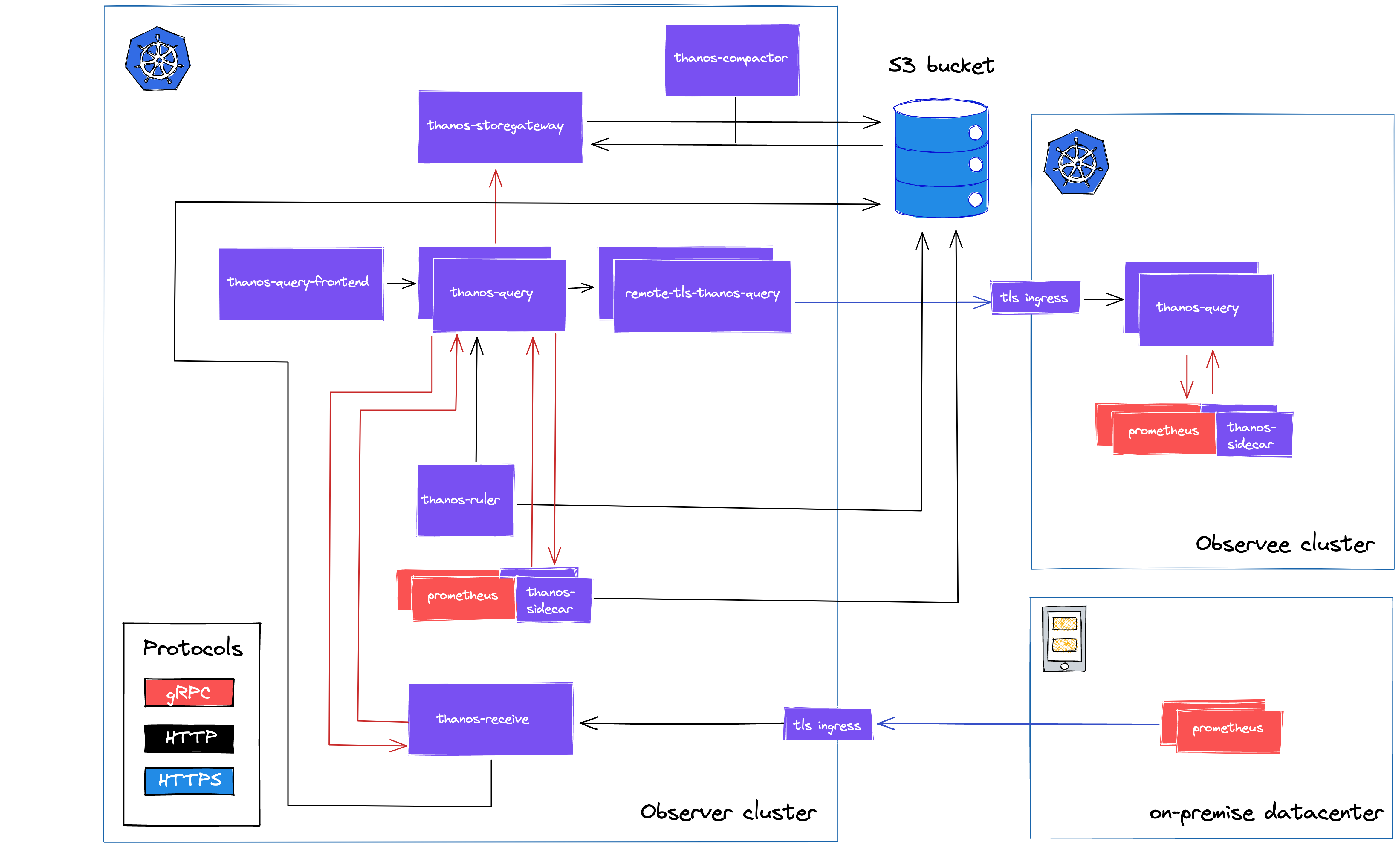
由於我們的 Demo 優先考慮實現的簡單性以及對多租戶的支持,對資源占用和性能的要求並不高,因此決定選用 Receiver 模式。
快速開始
- Thanos 版本:v0.24.0
- Kubernetes 版本:v1.16.9-aliyun.1
- 環境:阿里雲 ACK
git clone https://github.com/koktlzz/thanos-k8s-deployment.git
cd thanos-k8s-deployment
kubectl apply -k overlays/aliclound/
部署 Prometheus
git clone https://github.com/coreos/kube-prometheus.git
cd kube-prometheus
kubectl create -f manifests/setup
# wait for namespaces and CRDs to become available, then
kubectl create -f manifests/
在國內環境拉取 k8s.gcr.io 上的鏡像可能會失敗,需要將鏡像名稱改為 bitnami/kube-state-metrics:2.3.0 和 willdockerhub/prometheus-adapter:v0.9.0。
為 Prometheus 實例配置遠程寫入
使用 kubectl edit -n monitoring prometheus k8s命令開啟 Prometheus 的遠程寫入:
# local cluster
spec:
remoteWrite:
- url: http://thanos-receiver.thanos.svc.cluster.local:19291/api/v1/receive
# cluster kazusa
spec:
remoteWrite:
- url: http://thanos-receiver.uuid.cn-shanghai.alicontainer.com/api/v1/receive
headers:
THANOS-TENANT: kazusa
# cluster setsuna
spec:
remoteWrite:
- url: http://thanos-receiver.uuid.cn-shanghai.alicontainer.com/api/v1/receive
headers:
THANOS-TENANT: setsuna
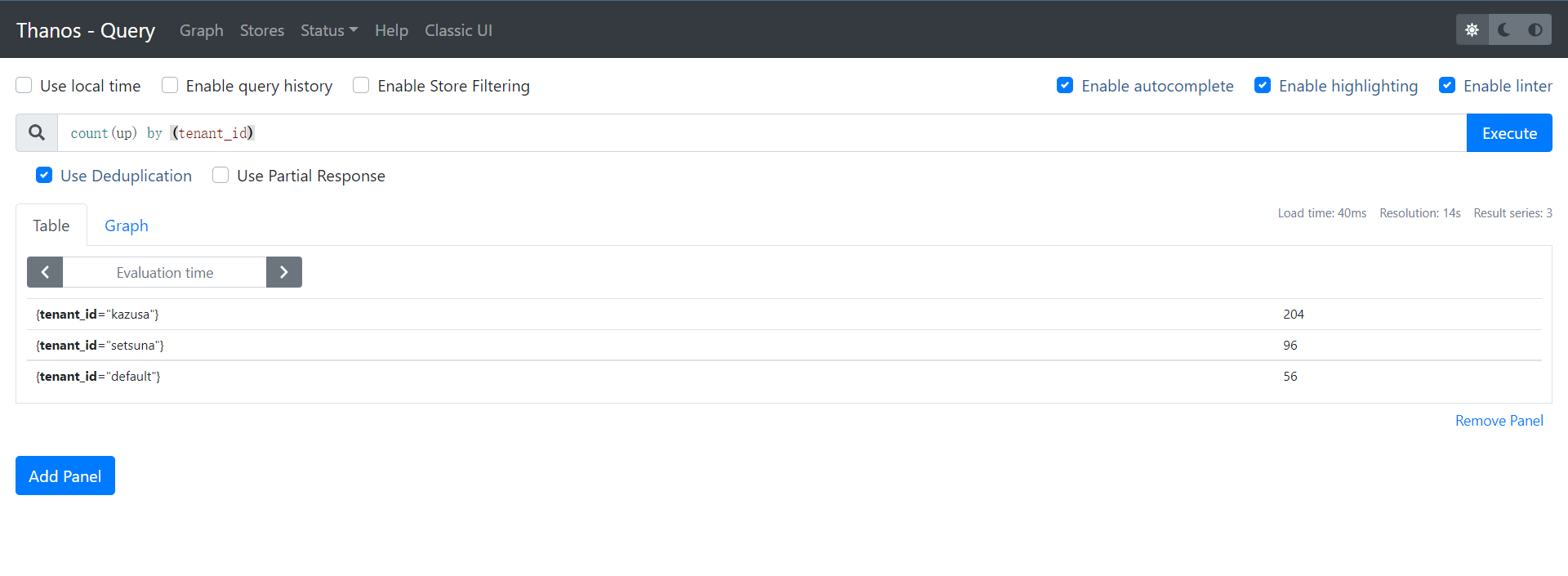
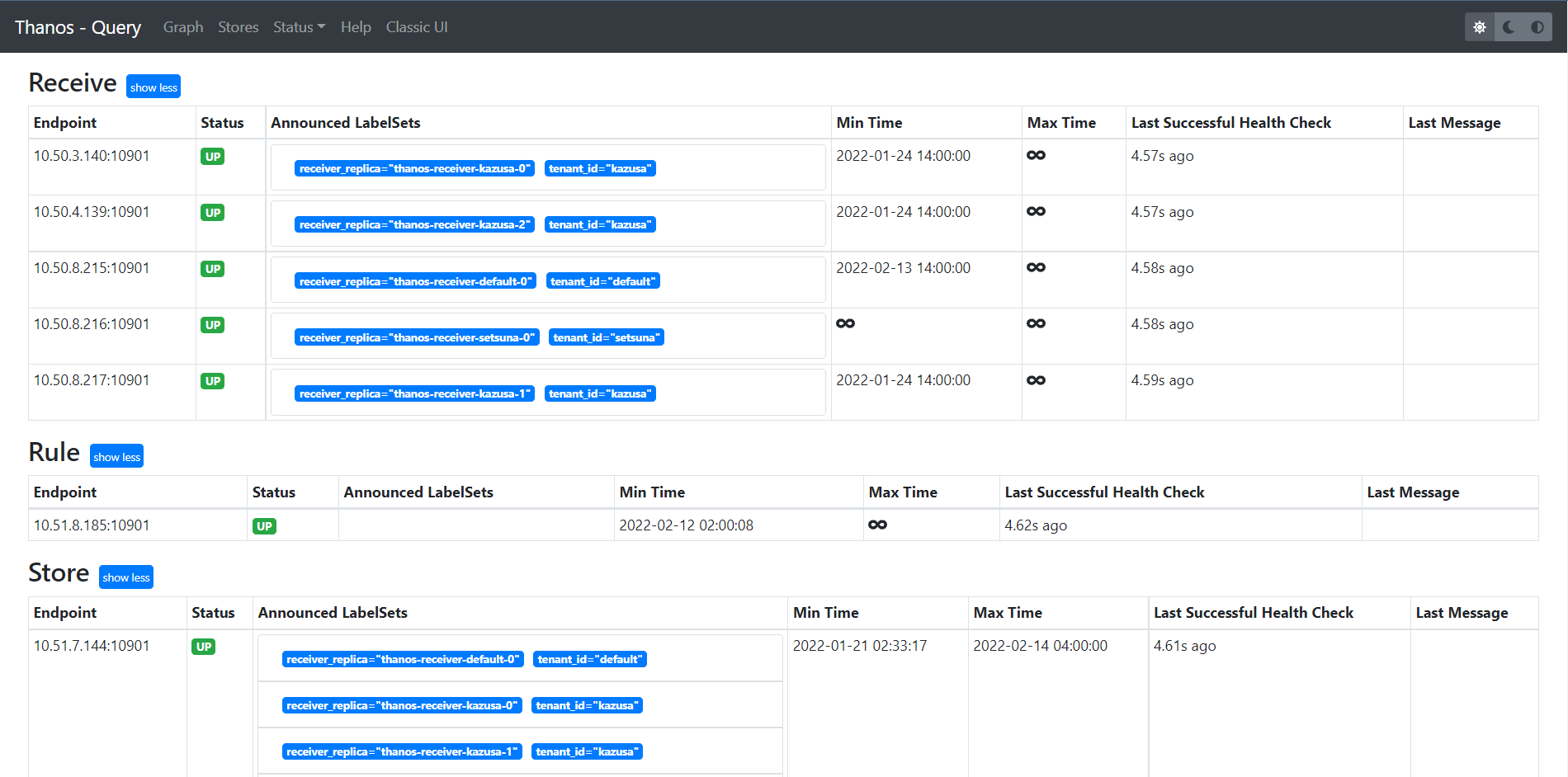
一段時間后將在 Query UI(kubectl get ingresses -n thanos | grep querier)中看到三個集群(租戶)的實例:
架構說明
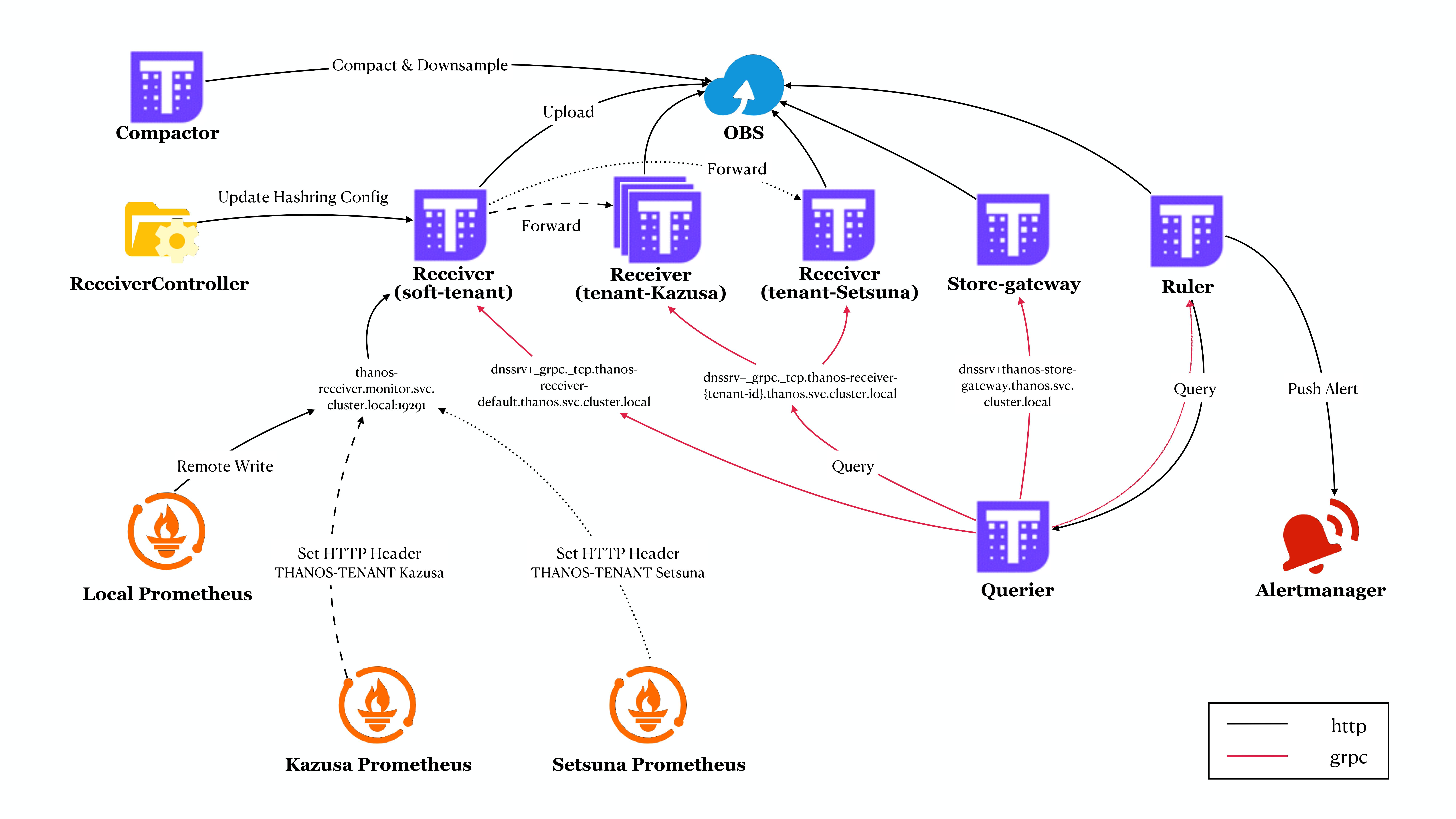
指標數據流向
如上圖所示,監控集群(Local)以及兩個外部集群(Kazusa 和 Setsuna)中的 Prometheus 均將指標數據寫入到軟租戶(soft-tenant)的 Receiver 中。而由於 Kazusa 和 Setsuna 的 Prometheus 還在遠程寫入中配置了 HTTP 頭部,因此軟租戶 Receiver 會根據其中的租戶 ID 將其轉發到對應的硬租戶 Receiver 中。
我們可以在 Receiver 容器掛載的 Hashring 配置文件中找到每個租戶 Receiver 的 endpoints:
[root@master1 thanos]# kubectl exec -n thanos thanos-receiver-default-0 -- cat /etc/prometheus/hashring-config/hashrings.json | jq
[
{
"hashring": "hashring-setsuna",
"tenants": [
"setsuna"
],
"endpoints": [
"thanos-receiver-setsuna-0.thanos-receiver-setsuna.thanos.svc.cluster.local:10901"
]
},
{
"hashring": "hashring-kazusa",
"tenants": [
"kazusa"
],
"endpoints": [
"thanos-receiver-kazusa-0.thanos-receiver-kazusa.thanos.svc.cluster.local:10901",
"thanos-receiver-kazusa-1.thanos-receiver-kazusa.thanos.svc.cluster.local:10901",
"thanos-receiver-kazusa-2.thanos-receiver-kazusa.thanos.svc.cluster.local:10901"
]
},
{
"hashring": "default",
"endpoints": [
"thanos-receiver-default-0.thanos-receiver-default.thanos.svc.cluster.local:10901"
]
}
]
實際上該文件來自於 Configmap thanos-receiver-hashring-generated-config,它是由 Thanos-Receive-Controller 讀取當前集群中的 Receiver 實例並根據 Configmap thanos-receiver-hashring-config 動態生成的。
Receiver 使用一致性哈希作為數據分發策略的原因詳見:Thanos Receiver - why does it need consistent hashing?
Receiver 的可擴展性和高可用性
假設 Kazusa 集群中的工作負載比較多,其指標數據量也比較大。為了防止接收 Kazusa 集群指標數據的 Receiver 發生 OOM,我們增加其 Statefulset 的 副本數。
上一節提到,指標數據是軟租戶 Receiver 根據 Hashring 配置分發到硬租戶 Receiver 的。這意味着即使我們將 Kazusa 的 Receiver 擴展到三個,數據也不會在某台 Receiver 宕機后分發到其他可用的 Receiver 中。因此我們還要為數據設置 副本,從而實現高可用。Receiver 的副本包含 receiver_replica 標簽,Query 可以根據它來對數據 去重。
關於 Receiver 的可擴展性和高可用性,詳見 Turn It Up to a Million: Ingesting Millions of Metrics with Thanos Receive.
Headless Service
我們為每個租戶的 Receiver 都創建了各自的 Headless Service,這樣 Query 就可以通過 DNS 的 SRV 記錄動態發現所有的 Receiver 實例:
- --store=dnssrv+_grpc._tcp.thanos-receiver-default.thanos.svc.cluster.local
- --store=dnssrv+_grpc._tcp.thanos-receiver-kazusa.thanos.svc.cluster.local
- --store=dnssrv+_grpc._tcp.thanos-receiver-setsuna.thanos.svc.cluster.local
如果將其改為 ClusterIP 類型,Store API 的 grpc 請求將通過輪詢發往其中一台 Receiver 實例。這樣在 Query UI 中就只能看到一台 Kazusa Receiver:
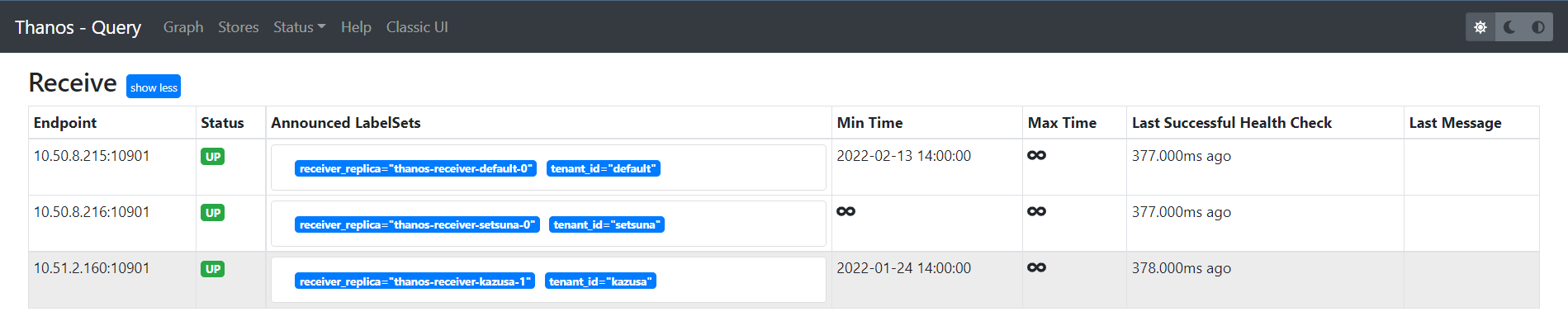
值得注意的是,用於處理指標數據的寫入請求的 Service 是 ClusterIP 類型的。
Future Work
本文介紹的 Demo 僅供讀者參考,若想要將其投入生產使用,還需要考慮以下方面:
- 為軟租戶的 Receiver 配置 TLS 證書校驗;
- 上文提到,開啟遠程寫入將增加 Prometheus 的內存使用,我們應當根據 文檔 中的建議對其參數進行調優;
- 持久化 Compactor 和 Storegateway 的數據目錄可以減少其重啟時間,存儲空間的大小可以參考 Slack 中的 討論;
- 部署前根據指標數據量評估 Receiver 的 Request、Limit 以及副本數,防止其因數據量過大而導致 OOM;
- 此 Demo 使用 Ruler 進行全局告警,可能因查詢超時而發生 報警失效。
參考文獻
Multi cluster monitoring with Thanos · Banzai Cloud
Achieve Multi-tenancy in Monitoring with Prometheus & Thanos Receiver