©原創作者 | FLPPED
論文:
Self-Attention Attribution: Interpreting Information Interactions Inside Transformer (2021 AAAI論文亞軍)
地址:
https://arxiv.org/pdf/2004.11207.pdf
01 研究背景
隨着transformer模型的提出與不斷發展,NLP領域迎來了近乎大一統的時代,絕大多數預訓練方法例如BERT等都將transformer結構作為模型的框架基礎,在NLP許多領域的SOTA框架中也常常能看到它的身影。
而transformer的成功很大程度上得益於多頭注意力機制,這一機制可對輸入的上下文信息進行編碼,並且使得模型學習到不同輸入token之間的依賴關系。
在多頭注意力的可解釋性研究方面,有些學者側重於對注意力權重的分析,重點討論權重大的特征,有些將模型決策的關注點放在輸入的token上,還有部分學者認為注意力機制的分布是無法直接解釋的。
相比於過去的研究,本文提出了一種自注意力機制的歸因算法,可對transformer內部的信息交互進行可解釋性的說明。
通過該方法,模型可識別較重要的注意力head,將其他不重要的head進行有效裁剪。還可通過構建歸因樹(attribution tree)將不同層之間的信息交互進行直觀的可視化表示。
最后,文章還以bert作為擴展的實例應用,通過對歸因結果分析構建的Adversarial trigger對Bert發動攻擊,使得bert的預測能力顯著下降。
02 Transformer簡介
首先讓我們來重新回顧一下Transformer結構。一般Transformer的結構是由encoder和decoder兩部分組成,兩者各包含N=6的layer,每個layer由兩個sub-layer組成,分別為多頭自注意力和全連接網絡,具體如圖1所示。
Transformer模型的成功很大程度上得益於多頭注意力機制。假定每個layer的attention heads數量為h,第h個attention head可用下式(1),(2),(3)表示
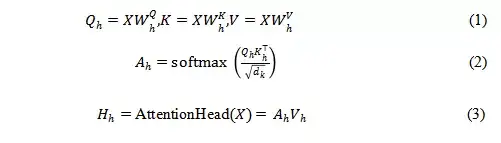
那么每一層多頭注意力可表示為:
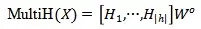
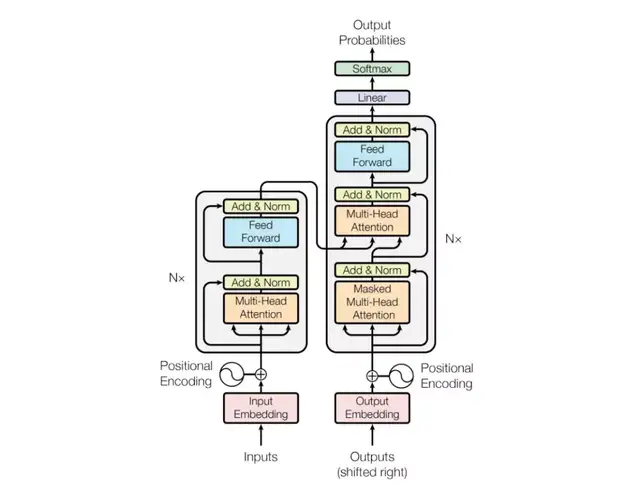
圖1 transformer結構示意圖
03 self-attention attribution 概念的提出
以往文章在對attention進行解釋時,常常關注計算得來的attention score,由圖二中的(a)圖可以看出,通過(2)式計算的attention score matrix是十分稠密的,無法直接獲得transformer內部真實的交互信息,並且兩個單詞之間的權重較大,也無法直接說明他們對最終的模型預測產生了重要的影響。
為此作者提出了一種自注意力的歸因方法。
假設輸入的句子為x,
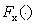
表示transformer模型,
注意力權重矩陣A代表模型的輸入,作者希望計算每一對注意力之間的歸因分數 (attention attribution: ATTATTR) 來表示其對模型決策的影響大小。
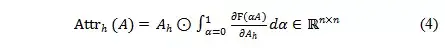
以第h個attention head為例,其歸因分數的計算法方法如式(4)所示,值從0到1的積分過程中,每一對attention connection (i,j)對模型的預測影響越大,它的梯度大小就會越顯著,因此積分的值也會越大。
在實際的計算中,作者通過(5)式Riemman 估計來對積分過程進行了簡化,
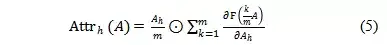
以一個finetune過后的bert模型中的某一個head為例,通過圖2可以看出,attention score值較大並不意味着對最終的預測有更大的貢獻,例如[SEP] 和其他token之間的attention score很大,但是最終計算的歸因分數卻很小。
對上下兩句之間關系“contradiction”的預測,主要還是歸因於第一個句子中的“don’t”和第二句中的“I know”,這一結果也基本符合常識。
可以看出,attribution score更能體現出輸入token之間attention的依賴關系對模型預測的貢獻。

圖2 attention score 和attribution score 示意圖
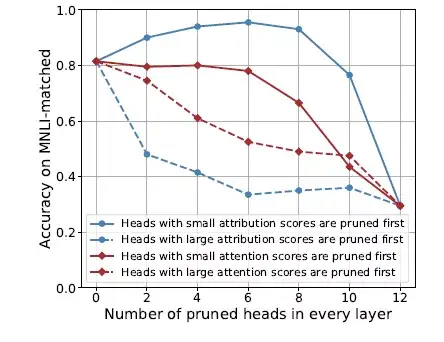
圖3 ATTATTR有效性分析
如圖3所示,在MNLI(Multi-genre Natural Language Inference) 數據集上,對BERT每一層中attribution scores最高的head進行裁剪,對下游任務預測的准確率影響要大於按照attention scores裁剪,進一步說明attribution score的大小更能反映attention connection 對模型預測能力的影響大小。
從藍色虛線可以進一步看出僅僅對每一層中top2 的attribution scores進行裁剪就會造成模型預測准確率的巨大下降。
04 研究應用
既然知道每個head中attribution score的“強大威力”, 我們又該如何有效的利用它呢?
在本文的實驗部分,作者基於Bert的預訓練模型,對下游的四個典型分類任務進行了微調,並基於此說明了attribution 方法的實用價值。
l Attention head 的裁剪
已知attribution score的大小體現了自注意力之間的關系對模型最終決策的影響,作者又對每個attention head定義了其重要性,如(6)式所示,
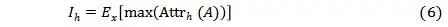
其中x代表了從留出的數據集中采樣出的樣本, max(Attrh(A)) 代表第h個attention head中最大的attribution value。
將該指標和其他的重要性對比評價指標:准確率差異和Taylor展開方法對比,實驗時,將對應指標下重要性較低的head先進行裁剪。
由圖4可以看出,按照ATTATTR方法對head進行裁剪的方法對模型預測准確率的損失要明顯低於按照准確率差異的方法,並且取得了和Taylor展開方法相當甚至更好的結果。
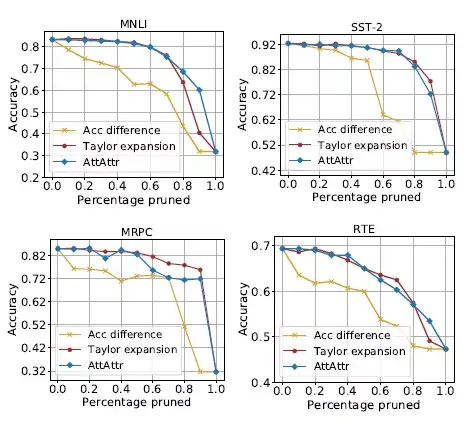
圖4 按照不同重要性方法對head裁剪后模型預測准確率的變化情況
Transformer內部信息交互的可視化
基於前面提出的attribution score的方法,文章又提出了一種啟發式的算法來構建attribution tree,以進一步揭示transformer內部的信息流動,使人能夠更直觀地理解輸入的單詞和最終預測之間的聯系。
首先在計算每一層的attribution score的時候,需要將每個head的score做加和。
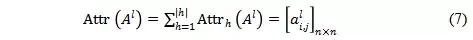
最終構建的attribution tree 需要在最大化attribution score 和使得樹中維持邊的數量最小之間權衡,因此目標函數可以表示為,
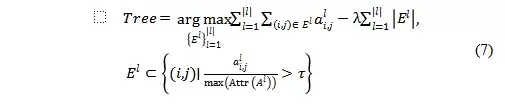
為了避免求解這個聯合優化的問題,作者使用了一種自上而下的啟發式的算法來生成attribution tree的邊,具體算法細節可以參考下圖。

圖5 Attribution Tree的構建方法
那么通過attribution tree, 又具體得到什么有趣的信息呢?
文章以MNLI數據集中的一對語句為例進行了解釋,如下圖6所示,該任務的目標是判斷兩句話之間的關系是矛盾、中立還是相似。
從樹的底部可以看到,信息之間的交互僅局限於本句中,是相對local的。
然后隨着信息的聚合匯總,兩個句子分別聚焦在“supplement”和“extra”兩個單詞上,從“extra”中可以明顯看到“add something extra”信息和“supplement”是強相關且相似的,最終所有信息匯聚到[CLS] token上,做出“entailment”的預測。
可以看出,attribution tree 將整個信息流動的過程清晰的可視化了,增強了transformer模型的可解釋性,使人能夠更方便的去理解任務以及找到模型可能的改進方向。
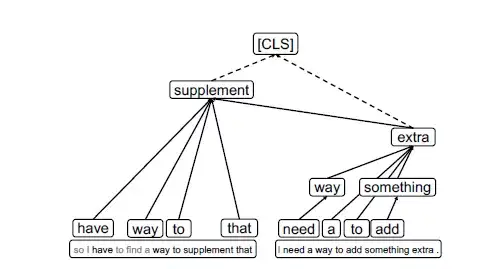
圖6 MNLI數據集中的某一例子
對BERT模型的非目標攻擊
通過對transformer內部信息流動觀察,可以進一步發現模型的預測受attribution score較大的一些attention connection的影響較大,而很容易忽視其他大部分的輸入信息。
因此文章這里采用over-confident 的模式作為adversarial triggers 來攻擊bert模型。
具體實驗時,文章首先通過不同層中最大的attribution scores 來提取attention 之間的依賴關系,然后將提取出來的這些依賴關系的對應模式當做adversarial triggers添加到想要攻擊的樣本中,從而改變原始樣本的預測結果。
如下圖7所示,整個攻擊過程首先將最上方這個預測為contradict的句子對中對結果貢獻最大的兩個模式“floods-ice”和“Iowa-Florida”抽提出來, 將他們作為trigger加入到下面兩個測試的樣本中去,可以看到模型的預測結果從原來准確的“entailment”和“neutral”錯誤的預測成了“contradict”,是不是非常神奇!

圖7使用ATTATTR來提取trigger進行攻擊
由此也可以看出,bert模型在預測時會過度依賴一些特定的trigger模式來做預測,這樣一旦添加一些其他容易混淆的trigger時,就很容易受到攻擊從而造成預測顯著失真。
05 總結
相比於其他文章將關注點放在注意力權重上的分析和討論,這篇文章從attribution score這個全新的角度分析了注意力依賴之間的關系以及它對模型預測結果的影響。
此外在應用方面,作者從head 裁剪、transformer內部信息流的可視化以及通過構建adversarial triggers來攻擊bert等方面給出了非常有趣且實用的示例,可以看到以transformer為基礎架構的預訓練模型的預測還十分依賴學到的某種特殊關系對,未來在充分了解attention內部的真實依賴關系的前提下,還需要針對下游任務引入一些新的約束和指導,以便更好地利用輸入的信息,提升模型預測的魯棒性。
參考文獻
[1] Hao Y, Dong L, Wei F, et al. Self-Attention Attribution: Interpreting Information Interactions Inside Transformer[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(14): 12963-12971.
私信我領取目標檢測與R-CNN/數據分析的應用/電商數據分析/數據分析在醫療領域的應用/NLP學員項目展示/中文NLP的介紹與實際應用/NLP系列直播課/NLP前沿模型訓練營等干貨學習資源。