Hive 概念
- Hive 由 Facebook 實現並開源
- 是基於 Hadoop 的一個數據倉庫工具
- 可以將結構化的數據映射為一張數據庫表
- 並提供 HQL(Hive SQL)查詢功能
- 底層數據是存儲在 HDFS 上
- Hive 的本質是將 SQL 語句轉換為 MapReduce/Spark 任務運行
- 使不熟悉 MapReduce 的用戶很方便地利用 HQL 處理和計算 HDFS 上的結構化的數據,適用於離線的批量數據計算
Hive 依賴於 HDFS 存儲數據,Hive 將 HQL 轉換成 MapReduce/Spark 執行,所以說 Hive 是基於 Hadoop 的一個數據倉庫工具(離線),實質就是一款基於 HDFS 的 MapReduce/Spark 計算框架,對存儲在 HDFS 中的數據進行分析和管理
Hive 特性
- 支持通過 SQL 輕松訪問數據的工具,從而支持數據倉庫任務,如提取/轉換/加載(ETL)、報告和數據分析。
- 支持多種數據格式(Parquet、OCR等)
- 訪問直接存儲在 HDFS 或其他數據存儲系統( 如 Apache HBase )中的文件
- 通過 Apache Tez、Apache Spark 或 MapReduce 執行查詢
Hive 架構
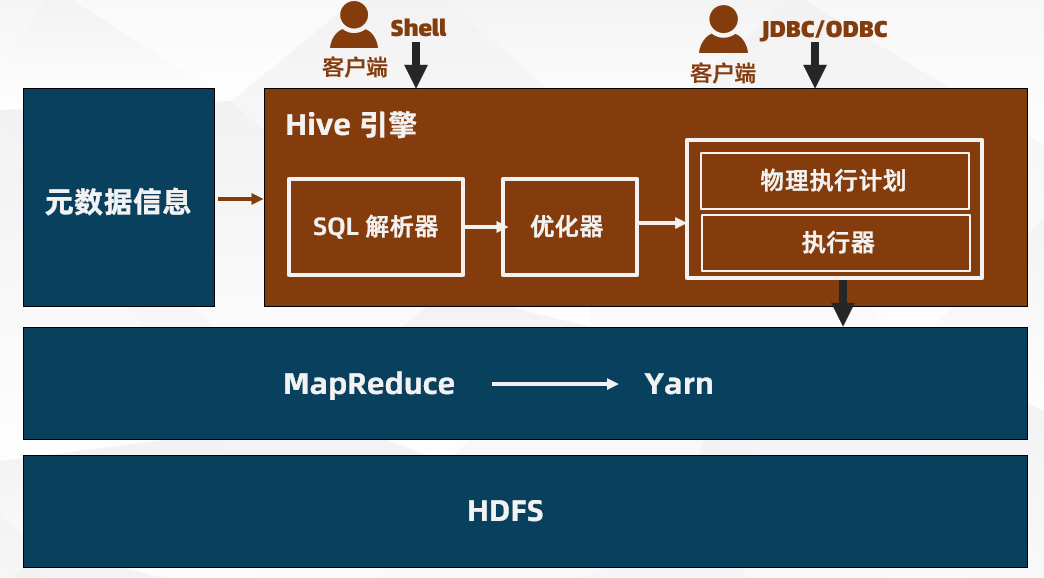
- 元數據信息(MetaStore):HIVE 將用戶定義的庫、表結構等元數據信息存儲在本地 derby 數據庫或遠程 MySQL 數據庫中
- SQL 解析器(SQL Parser):將 SQL 字符串轉換成抽象語法樹 AST,這一步一般都用第三方工具庫完成,比如antlr;對AST進行語法分析,比如表是否存在、字段是否存在、SQL語義是否有誤
-
編譯器(Physical Plan):將 AST 編譯生成邏輯執行計划
-
優化器(Query Optimizer):對邏輯執行計划進行優化
- 執行器(Execution):把邏輯執行計划轉換成可以運行的物理計划。對於 Hive 來說,就是 MapReduce 或 Spark
HIVE 用途
直接使用 MapReduce 程序所面臨的問題:
1、人員學習成本太高
2、項目周期要求太短
3、MapReduce實現復雜查詢邏輯開發難度太大
為什么要使用 Hive:
1、更友好的接口:操作接口采用類 SQL 的語法,提供快速開發的能力
2、更低的學習成本:避免了寫 MapReduce,減少開發人員的學習成本
3、更好的擴展性:可自由擴展集群規模而無需重啟服務,還支持用戶自定義函數
解放大數據分析程序員,不用自己寫大量的 mr 程序來分析數據,只需要寫 sql 腳本即可構建大數據體系下的數據倉庫
Hive 特點
優點:
1、可擴展性:Hive 可以自由的擴展集群的規模,一般情況下不需要重啟服務
2、延展性:Hive 支持自定義函數,用戶可以根據自己的需求來實現自己的函數
3、容錯性:可以保障即使有節點出現問題,SQL 語句仍可完成執行
缺點:
1、Hive 不支持記錄級別的增刪改操作,但是用戶可以通過查詢生成新表或者將查詢結果導入到文件中
2、Hive 的查詢延時很嚴重,因為 MapReduce Job 的啟動過程消耗很長時間,所以不能用在交互查詢系統中。
3、Hive 不支持事務(因為沒有增刪改,所以主要用來做 OLAP(聯機分析處理),而不是 OLTP(聯機事務處理),這就是數據處理的兩大級別)。
總結
Hive 具有 SQL 數據庫的外表,但應用場景完全不同,Hive 只適合用來做海量離線數據統計分析,也就是數據倉庫。