文章轉載自:https://mp.weixin.qq.com/s/alHHxXont6XFm_m9PfsGfw
1、什么是跨集群復制?
跨集群復制(Cross-cluster replication,簡稱:CCR)指的是:索引數據從一個 Elasticsearch 集群復制到另一個 Elasticsearch 集群。
對於主集群的索引數據的任何修改都會直接復制同步到從索引集群。
2、跨集群復制最早發布版本
Elasticsearch 6.7 版本。
3、跨集群復制的好處?
3.1 支持災難恢復(DR)、確保高可用性(HA)
跨集群復制確保了不間斷的服務可用性,能夠承受住數據中心或區域服務中斷的影響,降低了復雜性、節省了成本。
3.2 降低延遲
將數據復制到更靠近應用程序用戶的集群可以最大限度地減少查詢延遲。
3.3 水平可擴展性
跨多個副本集群拆分查詢繁重的工作負載可提高應用程序可用性。
3.4 集中式匯報
企業客戶可以將屬於不同業務線的較小集群(數百個分支銀行中心)中的報告不斷匯總到一個中央集群(大型全球銀行)中,以用於整合報告、方便可視化呈現。
PS:關於高可用,讀者可能會有疑惑?
● 副本的目的是高可用,集群的快照和恢復和功能是高可用,怎么又來個跨集群復制呢?
副本主要體現在分片層面,可以看做分片的復制,一般集群至少設置一個副本,當主副本故障時,副本分片會提升為主分片。
● 快照和恢復主要體現在:集群級別和索引層面,可以全量或者增量。但,做不到實時備份和恢復。也就是說,快照會設定一個時間間隔,比如每 5 分鍾備份一次。
當集群出現故障需要恢復時,極有可能會少備份最近 5 分鍾的數據,
綜上,才會有了跨集群復制的概念。
4、跨集群復制的核心概念

跨集群復制使用主動-被動模型(active-passive model)。
數據索引到一個領導者索引(leader index),並且數據被復制到一個或多個只讀跟隨者索引(read-only follower indices)。在向集群添加跟隨者索引之前,必須配置包含領導者索引的遠程集群。
leader-follower 模式在 kafka、zookeeper等中都有涉及,我認為翻譯為:主、從模型比較契合。
核心釋義解讀如下:
- active-passive model:主動-被動模型。
- leader index:主索引或領導者索引。
- read-only follower indices:從索引或跟隨者索引。
5、跨集群復制的設計原則
5.1 高安全性
跨集群復制應該為所有數據流和 API 提供強大的安全控制。
5.2 准確性
跟隨者索引和領導者索引的預期內容之間必須沒有差異。
5.3 高性能
復制不應影響領導集群的索引率(數據寫入速率)。
5.4 最終一致性
領導者和跟隨者集群之間的復制延遲應該在幾秒鍾之內。
5.5 資源使用率低
復制應該使用最少的資源。
6、跨集群復制的實戰一把
6.1 必備前置條件
6.1.1 前置條件1:激活License

CCR 是白金版付費功能,需要激活 30 天的 License,如果僅學習了解功能,建議先試用。


6.1.2 前置條件2:備好至少 2 個集群
跨集群復制,核心是“跨”和“復制”。
“跨”體現在至少得兩個集群,否則沒有意義。
最簡單模型如圖所示,我們用一台宿主機搭建兩套集群環境,如下所示:

● 集群A:遠端集群,remote cluster leader
Elasticsearch: 172.21.0.14:19203
kibana:172.21.0.14:5613
● 集群B:本地集群,local cluster follower
Elasticsearch: 172.21.0.14:19202
kibana:172.21.0.14:5612
6.1.3前置配置:開啟軟刪除
7.0+之后版本已默認開啟,無需單獨配置。
早期版本,需參考官方文檔進行靜態配置,需要修改配置文件實現。
index.soft_deletes.enabled:true
跨集群復制的工作原理是:重放對 leader 索引分片執行的單個寫入操作的歷史記錄。
Elasticsearch 需要在 leader 分片上保留這些操作的歷史記錄,以便它們可以被 follower 分片任務拉取。用於保留這些操作的底層機制是軟刪除。
6.1.4 前置配置:xpack 設置true
因為需要配置角色、權限等,Elasitcsearch 設置了xpack,就意味着 kibana 端需要設置賬號、密碼。
在 elasticsearch.yml 文件中添加如下配置。
xpack.security.enabled: true
通過:./elasticsearch-setup-passwords 命令行工具實現用戶名和密碼的設置。
auto 自動設置的結果參考如下:
./elasticsearch-setup-passwords auto
Changed password for user apm_system
PASSWORD apm_system = m5ob2a8OvoKuYpPPsiRd
Changed password for user kibana_system
PASSWORD kibana_system = xwdrhpVPSsbxxY1l0b50
Changed password for user kibana
PASSWORD kibana = xwdrhpVPSsbxxY1l0b50
Changed password for user logstash_system
PASSWORD logstash_system = 1zweZhAVEnqwh1flHBkz
Changed password for user beats_system
PASSWORD beats_system = 7Fo3bvmLISshjvHXTqAY
Changed password for user remote_monitoring_user
PASSWORD remote_monitoring_user = EvB4FkFs88gsCP073YGt
Changed password for user elastic
PASSWORD elastic = c7KmLqGTm6cyl2ABJPBY
否則會報錯如下:
{
"error" : {
"root_cause" : [
{
"type" : "exception",
"reason" : "Security must be explicitly enabled when using a [trial] license. Enable security by setting [xpack.security.enabled] to [true] in the elasticsearch.yml file and restart the node."
}
],
"type" : "exception",
"reason" : "Security must be explicitly enabled when using a [trial] license. Enable security by setting [xpack.security.enabled] to [true] in the elasticsearch.yml file and restart the node."
},
"status" : 500
}
6.2 跨集群復制完整設置步驟
6.2.1 步驟1:從集群設置 remote cluster
在從集群上配置包含主索引的遠程集群(remote cluster)
其實看到:remote cluster,第一時間要想到:跨集群檢索(CCR)也需要配置它。
從集群配置主集群 leader,參考如下:
PUT /_cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"leader": {
"seeds": [
"172.21.0.14:19303"
]
}
}
}
}
}
從集群監測一下remote配置是否成功。
GET /_remote/info
檢測是否配置成功。
6.2.2 步驟2:配置權限
為跨集群復制配置權限。
跨集群復制用戶在遠程集群和本地集群上需要不同的集群和索引權限。
使用以下請求在本地和遠程集群上創建單獨的角色,然后創建具有所需角色的用戶。
6.2.2.1 remote 集群配置權限
前置條件:設置 xpack 為 true,kibana 端配置賬號和密碼。
POST /_security/role/remote-replication
{
"cluster": [
"read_ccr"
],
"indices": [
{
"names": [
"kibana_sample_data_logs"
],
"privileges": [
"monitor",
"read"
]
}
]
}
6.2.2.2 local 集群配置權限
在本地集群上創建從索引。
POST /_security/role/remote-replication
{
"cluster": [
"manage_ccr"
],
"indices": [
{
"names": [
"kibana_sample_data_logs_follower"
],
"privileges": [
"monitor",
"read",
"write",
"manage_follow_index"
]
}
]
}
6.2.3 步驟3:創建自動跟蹤模式以自動跟蹤在遠程集群中創建的索引
可以使用 Kibana 圖形化界面配置或者命令行配置。
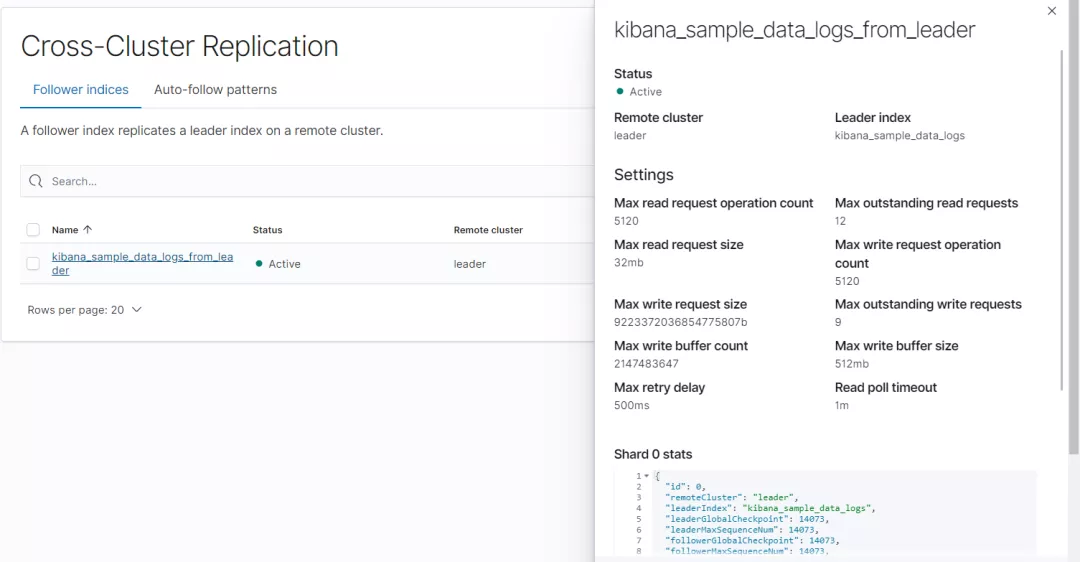
位置:Stack Management->Data->Cross-Cluster Replication。
步驟1:創建 follower index。

步驟2:配置 follower index。

需要設置如下:
- Remote cluster, 從集群對leader 的設置。
- Leader index,主集群的索引。
- Follower index,從集群的索引名稱,與 Leader index 是一一對應的關系,是從 Leader 索引復制過來的數據。
執行成功后截圖如下:

檢查是否成功:
GET /kibana_sample_data_logs_from_leader/_ccr/stats
``
以上,跨集群同步設置成功之后,可以進一步做很多驗證。
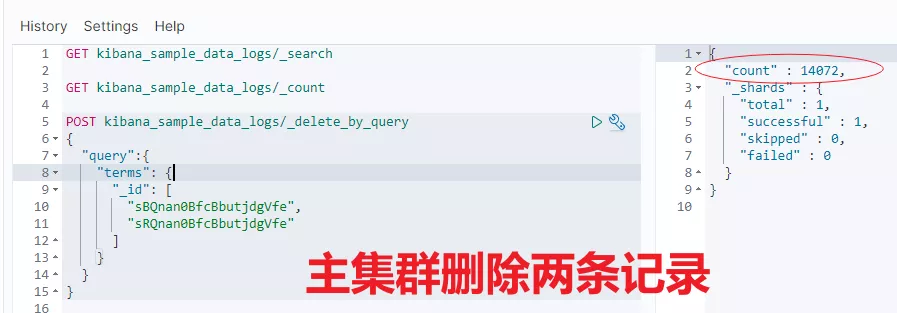
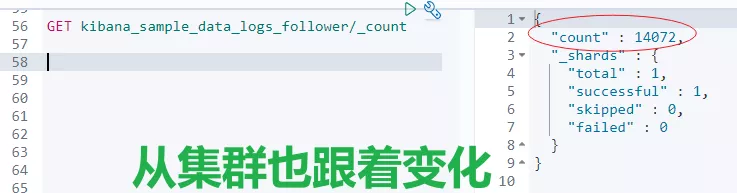
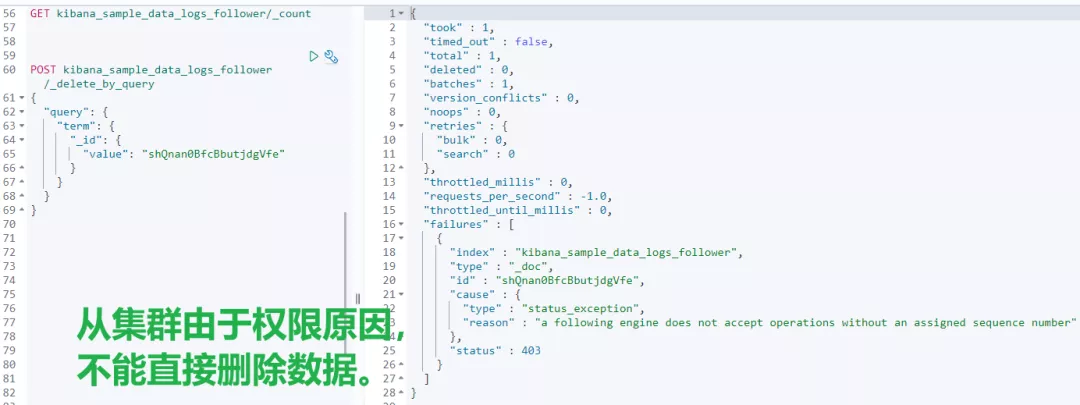
比如:主集群 leader 索引刪除兩條數據,從集群查看結果。對比發現,從集群也會跟着變化,這說明了跨集群復制已生效。
# 7、跨集群復制常用命令清單
包含但不限於:檢查復制進度、暫停和恢復復制、重新創建跟隨者索引和終止復制。
## 7.1 檢查復制進度
GET /kibana_sample_data_logs_from_leader/_ccr/stats
## 7.2 暫停和恢復復制
POST kibana_sample_data_logs_from_leader/_ccr/pause_follow
POST kibana_sample_data_logs_from_leader/_ccr/resume_follow
{
}

## 7.3 重新創建跟隨者索引
分三步驟:
暫停
POST /follower_index/_ccr/pause_follow
關閉
POST /follower_index/_close?wait_for_active_shards=0
重建
PUT /follower_index/_ccr/follow?wait_for_active_shards=1
{
"remote_cluster" : "remote_cluster",
"leader_index" : "leader_index"
}
## 7.4 終止復制
需要先暫停、然后關閉,最后終止復制。
POST kibana_sample_data_logs_from_leader/_ccr/unfollow
# 8、小結
實戰出真知,由於這部分是收費功能,可能會用的少。這塊一直是新知盲點,實戰一把,才知道究竟!
針對data stream 數據流的處理,跨集群也是支持的,限於篇幅原因,本文沒有展開,更多內容推薦閱讀官方文檔。
耗時12小時+,希望對你有幫助!