- 核心參考:
- Motivation & Review
- 圖像數據與點雲存在着巨大的差別
- 融合數據的特征/信號表示形式(Feature/Signal Representation)
- 幾何約束 Encoding Geometric Constraint
- 時間上下文Encoding Temporal Context
- 神經網絡搜索結構( NASNet[1])
Y. Xing, C. Lv, L. Chen, H. Wang, H. Wang, D. Cao, E. Velenis,and F.-Y. Wang, “Advances in vision-based lane detection: algorithms,integration, assessment, and perspectives on acp-based parallel vision,”IEEE/CAA Journal of Automatica Sinica, vol. 5, no. 3, pp. 645–661,2018. ↩︎
- 傳感器類型與標定
- 1. 具體應用
- 未來趨勢
- 融合策略
- 參考文獻
KeyWords: 環境感知,多模態融合
核心參考:
滑鐵盧大學的一篇綜述論文[1]寫的很好
同時也借鑒了國內的論文導讀論文導讀
Motivation & Review
圖像數據與點雲存在着巨大的差別
| 圖像數據 | 點雲 | |
|---|---|---|
| be like |  |
 |
| Permutation 排列 | Ordered | Orderless |
| Data Structure | Regular | Irregular |
| Data Type | Discrete 離散的 | Continuous |
| Dimension | 2D | 3D |
| Coordinates 視角 | Projective 投影的 | Euclidean 歐氏幾何的 |
| Resolution 空間分辨率 | High | Low |
融合數據的特征/信號表示形式(Feature/Signal Representation)
- 單純融合:RGB-D不太行,2D場景太受限;點雲上加RGB,有分辨率不匹配的問題
改進:使用深度補全or點雲上采樣,對相鄰連續幀引入自監督,或者進行單目學習,比如自監督模型PackNet
TODO

- 先將兩種數據轉換為其他數據表現形式:體素化點雲(voxelized point cloud)[2]、晶格(lattice)[3]。未來的研究可以探索其他新穎的中間數據結構,例如圖(graph)、樹(tree)等,從而提高性能。
幾何約束 Encoding Geometric Constraint
時間上下文Encoding Temporal Context
神經網絡搜索結構( NASNet[4])
傳感器類型與標定

| 類型 | 內容 | 方式 | 備注 |
|---|---|---|---|
| Lidar內參標定 | 不同路的激光探頭的相對角度 | 未知 | 廠商給的參數未必一定對 |
| Lidar-to-GPS外參標定 | Lidar的原點與GPS有個平移 | 在室外開8字開幾圈 | |
| Lidar-to-Lidar外參標定 | R,T,放縮 | (Iterative Closest Point,ICP)迭代最近點算法 | 詳情見博客 |
| Lidar-to-Camera外參標定 | 兩個有個RT | 具體算法見博客-Lidar-Camera 聯合標定算法 | |
| Camera-to-Camera外參標定 | 外參標定 | 室內場景會使用標定間進行標定 | 標定間一般使用高精度的地標雷達進行掃描 |
| 自然場景中 Lidar-to-Camera外參標定 | 外參標定 | 利用標志物,如交通牌的銳利邊緣(點雲有很大的depth變化) | |
| 自然場景中 Bifocal cameras外參標定 | 內外參驗證 | 把兩個部分的圖片進行變換重疊,觀察是否具有重影 | 廠商給的參數未必一定對 |
| Camera-to-Radar外參標定 | t與pitch角標定 | 測量相機pitch角度與t | radar一定是水平的,而camera不一定 |

外參自校准
在實際應用中因為震動等原因,出廠的標定數據可能會有微小的偏差,因此需要進行自校准。自校准目前有兩種解決方案,運動引導[5]和無目標[6]
TODO 有機會學習一下
時間同步
晶振時間戳(基本完備),不過經常還是會出現時間差,是一個工程上較為常見的小bug,但是會導致嚴重的融合問題。
深度補全

激光點雲具有稀疏性,進行上采樣
同甘融合來引導上采樣
encoder-decoder結構
3D-object Det(經典1)
核心參考:知乎專欄-自動駕駛環境感知-激光雷達:3D物體檢測算法

LiDAR的優勢:能夠非常精確的測量物體在3D空間中的位置和形狀,性能遠超Camera和Rader
Multi-view
Voxel
Point
Point + Voxel
基本概念
- 輸入:\((x,y,z,R)\) 其中R為反射強度
- 輸出:3D BBox(BoundingBox): \((x_0,y_0,z_0,h,w,l, \theta),\ \theta\)為3D旋轉角度
- Det結果的評價
3D IoU(Intersection over Unoin), 也即兩個3D框(GT(Ground Truth) & Det(Detecion)) 重合部分的比例,設定閾值,超過即為TP,反之即為FN。如果憑空出框就是FP。
根據TP,FN,FP的相關比例能夠得到一個綜合的評價指標
編年史
### 萌芽期 Det相關的算法最早都起步於CV領域,CV領域經典算法層出不窮,出現了R-CNN,Faster R-CNN,YOLO,以及衍生出許多當前SOTA的CenterNet #### VeloFCN^[Qian et al., 3D Object Detection for Autonomous Driving: A Survey, 2021] 將3D點雲轉換到正視圖(Front View)再套用圖像det,不過因為造成了信息缺失,丟失了深度信息,效果很差 #### MV3D^[Chen, et al., Multi-view 3d object detection network for autonomous driving, CVPR, 2017] 17年的MV3D增加了一個新的視角:鳥瞰圖 BEV(Bird's Eye View),加上VeloFCN的正視圖,與2D數據進行融合,一同進行檢測(R-CNN) 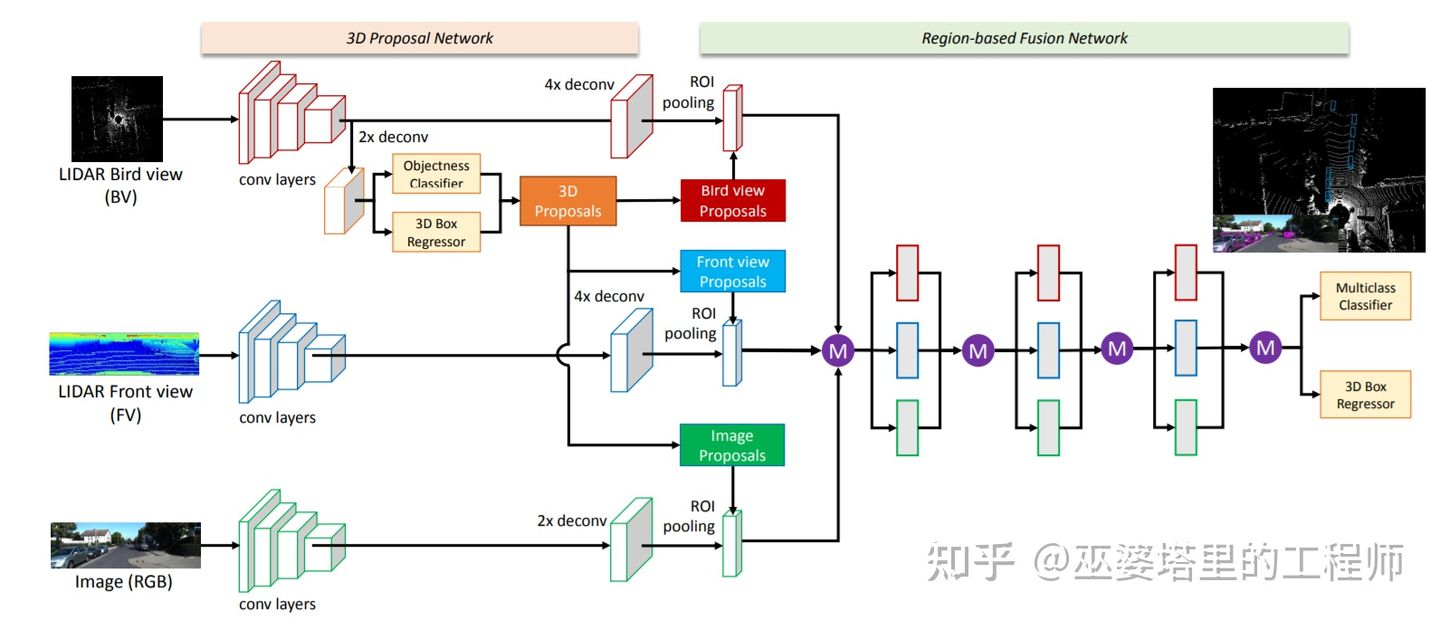 ### 起步期 2017年 #### VoxelNet^[Zhou and Tuzel, Voxelnet: End-to-end learning for point cloud based 3d object detection, CVPR, 2018.] CVPR 2018的一篇文章,作者是蘋果公司的兩位研究員。 步驟: 1. Grouping: 將點雲量化到一個均勻的3D網格中 2. Random Sampling: 每個網格中隨機采樣固定數量的點(不足就重復),輸入點坐標為 $(x,y,z,R,\Delta X,\Delta Y,\Delta Z)$ 3. Stacked Voxel Feature Encoding: 全連接層被用來提取點的特征,然后每個點的特征再與網格內所有點的特征均值進行拼接,得到新的點特征。這種特征的優點在於同時保留了單個點的特性和該點周圍一個局部小區域(網格)的特性。這個點特征提取的過程可以重復多次,以增強特征的描述能力 4. 最終網格內的所有點進行最大池化操作(Max Pooling),以得到一個固定長度的特征向量 5. 輸出為4D Tensor,$(x,y,z,f)$,f為feature map。為了套用3D的檢測算法,本文使用多次3D卷積壓縮z維度的大小至2: $(H\times W \times 2 \times C')$,然后將最后連個維度合並$(H\times W \times 2C')$。然后使用RPN(Region Proposal Network)進行 3D BBox 生成。 從上面的介紹可以看出,VoxelNet的框架非常簡潔,也是第一個可以真正進行端對端的學習的點雲物體檢測網絡。實驗結果表明,這種端對端的方式可以自動地從點雲中學習到可用的信息,比手工設計特征的方式更為高效 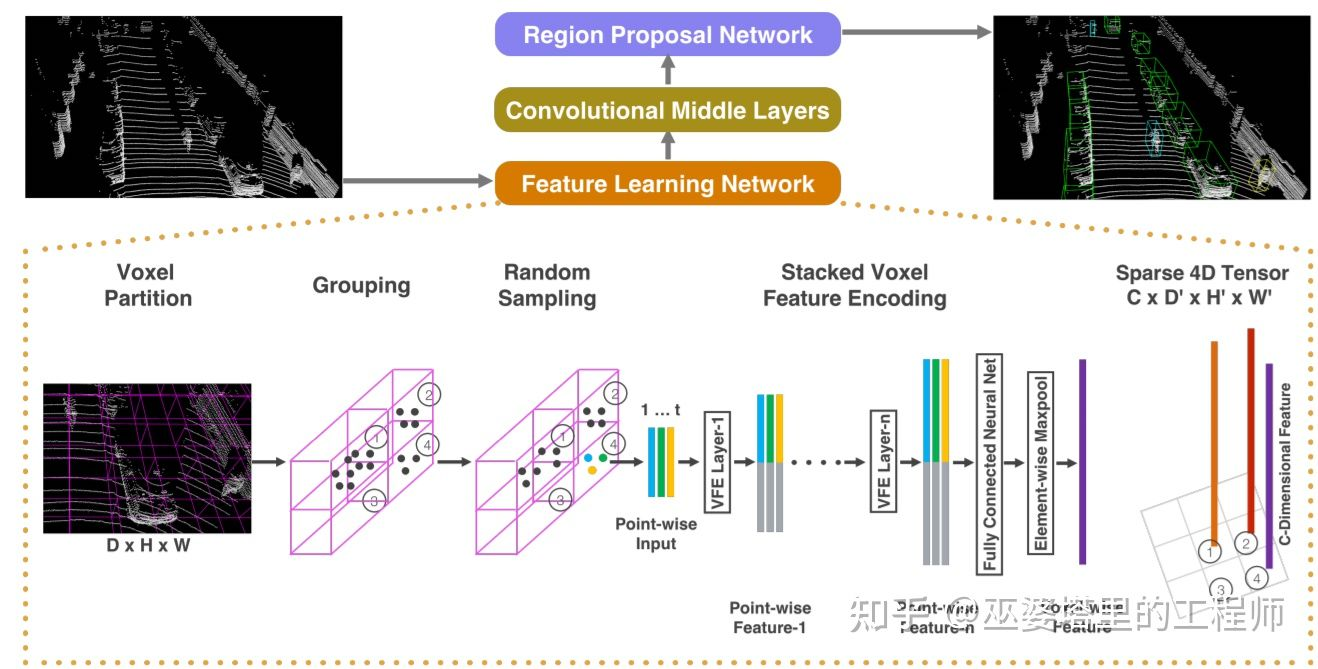 #### PointNet++^[Qi et al., Pointnet++: Deep hierarchical feature learning on point sets in a metric space, NeurIPS, 2017.]2D、3D語義分割(經典2)、實例分割

SOT(Single-Object Tracking), MOT(Multi-Object Tracking)
Track-by-Detection
TODO
One shot modle
TODO
1. 具體應用
深度補全
語義分割
目標檢測及跟蹤
特種場景
???真的能做得更好
找找應用場景!
未來趨勢
2D——3D
單任務——多任務
信號級——多級融合
早期融合
晚期融合
時間上下文
融合策略
決策層融合
決策+特征層融合
用一種數據生成Proposal,再將proposal與另一種數據結合生成Det結果。結合的方式就是將proposal與另一種data統一到相同的坐標系下
F-PointNet[7]
由圖像數據生成2D物體候選框,然后將這些候選框投影到3D空間。每個2D候選框在3D空間對應一個視椎體(Frustum),並將落到視椎體中所有點合並起來作為該候選框的特征。視椎體中的點可能來自前景的遮擋物體或者背景物體,所以需要進行3D實例分割來去除這些干擾,只保留物體上的點,用來進行后續的物體框估計(類似PointNet中的處理方式)。這種基於視椎的方法,其缺點在於每個視椎中只能處理一個要檢測的物體,這對於擁擠的場景和小目標(比如行人)來說是不能滿足要求的。
IPOD[8]
IPOD提出采用2D語義分割來替換2D物體檢測。首先,圖像上的語義分割結果被用來去除點雲中的背景點,這是通過將點雲投影到2D圖像空間來完成的。接下來,在每個前景點處生成候選物體框,並采用NMS去除重疊的候選框,最后每幀點雲大約保留500個候選框。同時,PointNet++網格被用來進行點特征提取。有了候選框和點特征,最后一步采用一個小規模的PointNet++來預測類別和准確的物體框(當然這里也可以用別的網絡,比如MLP)。IPOD在語義分割的基礎上生成了稠密的候選物體框,因此在含有大量物體和互相遮擋的場景中效果比較好。
上面兩個方法分別通過2D圖像上的物體檢測和語義分割結果來生成候選框,然后只在點雲數據上進行后續的處理。
SIFRNet[9]
提出在視椎體上融合點雲和圖像特征,以增強視椎體所包含的信息量,用來進一步提高物體框預測的質量。
特征層融合
參考文獻
[5] Chen et.al., Multi-View 3D Object Detection Network for Autonomous Driving, 2016.
[6] Ku et.al., Joint 3D Proposal Generation and Object Detection from View Aggregation, 2017.
[7] Liang et.al., Deep Continuous Fusion for Multi-Sensor 3D Object Detection, 2018.
[8] Vora et.al., PointPainting: Sequential Fusion for 3D Object Detection, 2019.
[9] Sindagi et.al., MVX-Net: Multimodal VoxelNet for 3D Object Detection, 2019.、、、
Cui et.al., Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review, 2020. arXiv ↩︎
S. Gupta, R. Girshick, P. Arbelez, and J. Malik, “Learning rich features from rgb-d images for object detection and segmentation,” Lecture Notes in Computer Science, p. 345360, 2014. [Available](http://dx.doi.org/10.1007/978-3-319-10584-0 23) ↩︎
X. Lv, Z. Liu, J. Xin, and N. Zheng, “A novel approach for detecting road based on two-stream fusion fully convolutional network,” in 2018 IEEE Intelligent Vehicles Symposium (IV), 2018, pp. 1464–1469. ↩︎
Y. Xing, C. Lv, L. Chen, H. Wang, H. Wang, D. Cao, E. Velenis,and F.-Y. Wang, “Advances in vision-based lane detection: algorithms,integration, assessment, and perspectives on acp-based parallel vision,”IEEE/CAA Journal of Automatica Sinica, vol. 5, no. 3, pp. 645–661,2018. ↩︎
A. S. Huang, D. Moore, M. Antone, E. Olson, and S. Teller, “Findingmultiple lanes in urban road networks with vision and lidar,” Au-tonomous Robots, vol. 26, no. 2-3, pp. 103–122, 2009. ↩︎
P . Y . Shinzato, D. F. Wolf, and C. Stiller, “Road terrain detection:Avoiding common obstacle detection assumptions using sensor fusion,”in 2014 IEEE Intelligent V ehicles Symposium Proceedings, 2014, pp.687–692. ↩︎
Qi et.al., Frustum Pointnets for 3d Object Detection from RGB-D Data, 2018. ↩︎
Yang et.al., IPOD: Intensive Point-based Object Detector for Point Cloud, 2018. ↩︎
Zhao et.al., 3D Object Detection Using Scale Invariant and Feature Re-weighting Networks, 2019. ↩︎