HDFS 簡介
集群與分布式
集群
- 集群是由多個完成相同功能的服務器節點組成的集合
- 集群中每個服務器節點處理相同的任務或存儲相同的數據
- 集群的關鍵特性是可擴展性和高可用性(支持負載均衡、錯誤恢復)
分布式
- 分布式是將一個系統拆分為多個不同的子系統,每個子系統運行在一個服務器節點上,最終共同完成系統的功能
- 分布式中每個服務器節點處理不同的任務或存儲不同的數據
- 分布式的關鍵特性是高性能和高可靠性
分布式軟件系統上運行的單個服務器節點可以通過搭建集群,從而獲得系統的高性能、高可靠、可擴展和高可用的特性。
HDFS 是什么
HDFS 即 分布式文件系統(Hadoop Distributed File System),是 Hadoop 三大核心組件之一,它的設計目標是把超大數據集存儲到網絡中的多台普通商用計算機上, 並為大數據分布式運算框架提供高可靠性和高吞吐率的數據存儲服務。
分布式文件系統要比普通磁盤文件系統復雜, 因為它要引入網絡編程: 分布式文件系統要容忍節點失效,這也是一個很大的挑戰,HDFS 出色完成了這一任務
HDFS 設計六大目標
-
可以存儲超大文件
HDFS 支持 GB 級別大小的文件,它能夠將文件分塊存儲,通過擴展更多節點增大其存儲容量
-
適用於流式的數據訪問
HDFS 適用於批處理的情況而不是交互式處理,它的重點是保證高吞吐量而不是低延遲的用戶響應
-
高容錯性
HDFS 有完善的冗余備份機制
-
支持簡單的一致性模型
HDFS 需要支持一次寫入多次讀取的模型,而且寫入過文件不會經常變化
-
移動計算優於移動數據
HDFS 提供使應用計算移動到離它最近數據位置的接口
-
異構軟硬件平台間的可移植性
HDFS 在設計時考慮到平台的可移植性,以方便 HDFS 作為大規模數據應用平台的推廣
HDFS 整體工作機制
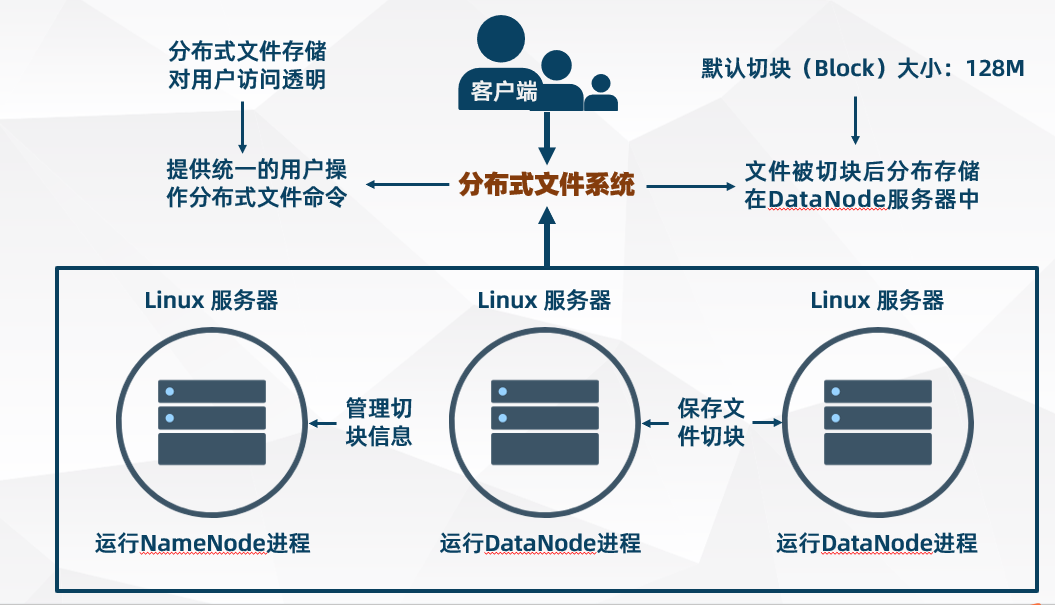
- HDFS 是一個文件系統,用於存儲和管理用戶上傳的文件
- HDFS 是分布式的,由很多服務器聯合起來組成集群實現其功能,集群中的服務器分為兩大角色:NameNode 服務器 和 DataNode 服務器
- HDFS 采用的是主/從架構:NameNode 是 HDFS 集群的主節點,而 DataNode 是 HDFS 集群的從節點
HDFS 特征
- HDFS 文件系統對客戶端訪問提供統一的抽象目錄樹,客戶端通過目錄樹路徑來訪問文件( 類似 Linux 文件系統 )
- HDFS 中的文件在物理上是分塊存儲(block),塊的大小在 hadoop3.x 版本中默認 128M(通過配置參數 dfs.blocksize 可設置)
- NameNode 負責維護和管理 HDFS 抽象目錄樹及文件分塊(block)的描述信息(元數據)
- DataNode 負責存儲和管理文件分塊(block),而且每一個文件分塊(block)都可以在多個 DataNode 上存儲多個副本,副本數量在 hadoop3.x 版本中默認 2 個 (通過參數 dfs.replication 可設置)
- HDFS 設計成適應一次寫入、多次讀出的場景,且不支持文件的修改
HDFS 優點與不足
HDFS 優點
- 高容錯性
- 適合離線批處理
- 適合大數據處理
- 可構建在廉價機器上
HDFS 不足
-
不擅長低延時數據訪問
由於 hadoop 針對高數據吞吐量做了優化,犧牲了獲取數據的延遲,所以對於低延遲訪問數據的業務需求不適合HDFS
-
不擅長大量小文件存儲
存儲大量小文件的話,它會占用 NameNode 大量的內存來存儲文件、目錄和塊信息,容易導致 NameNode 內存不足
-
不支持多用戶並發寫入一個文本
同一時間內只能有一個用戶執行寫操作
-
不支持文件隨機修改(多次寫入,一次讀取)
僅支持文件的數據追加,不支持文件的隨機修改