采集並匯總GBase 8a,oceanbase,tidb,polardb-O,gaussdb200,clickhouse,flink,spark等數據庫的整體架構圖和對應說明,方便從整體上看數據庫之間的差異。
新搜集到的數據庫材料,我放到了最前面。
目錄導航
星環TDH
來源: https://www.transwarp.cn/transwarp/product-TDH.html?categoryId=18
核心: Inceptor 基於Hadoop和Spark技術平台打造
 星環TDH 產品架構圖
星環TDH 產品架構圖
易鯨捷 EsgynDB
來源:http://www.esgyn.cn/wp-content/uploads/avatar_images/EsgynDB%E5%8F%82%E8%80%83%E6%9E%B6%E6%9E%84.pdf
https://www.modb.pro/wiki/43
核心:基於Apache Trafodion, 2021年4月改名叫 attic
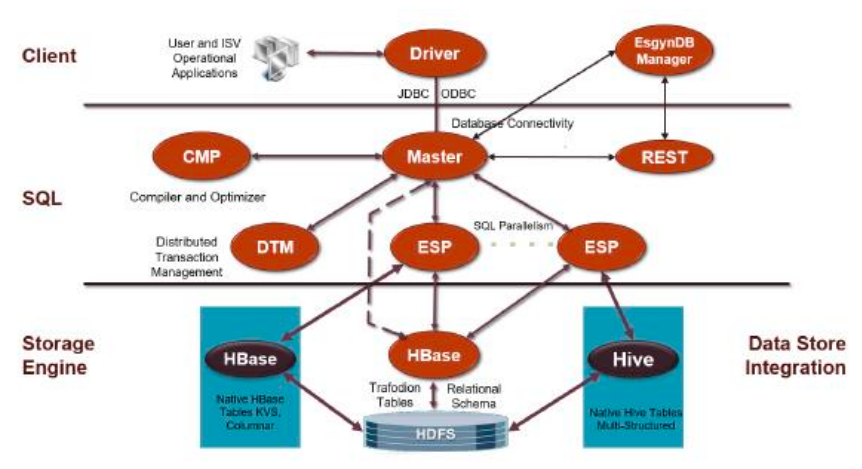 易鯨捷 EsgynDB 產品整體架構圖
易鯨捷 EsgynDB 產品整體架構圖 易鯨捷 EsgynDB 產品生態集成圖
易鯨捷 EsgynDB 產品生態集成圖 易鯨捷 EsgynDB 產品整體架構圖
易鯨捷 EsgynDB 產品整體架構圖
中興通訊GoldenDB
來源:https://www.zte.com.cn/china/products/202003190856/202003190858/201707311038
 中興通訊GoldenDB產品架構圖
中興通訊GoldenDB產品架構圖
神通數據庫MPP集群
來源:http://www.shentongdata.com/index.php/product/view-103
 神通數據庫MPP集群產品架構圖
神通數據庫MPP集群產品架構圖
巨杉Sequoiadb
來源:http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1558957225-edition_id-500
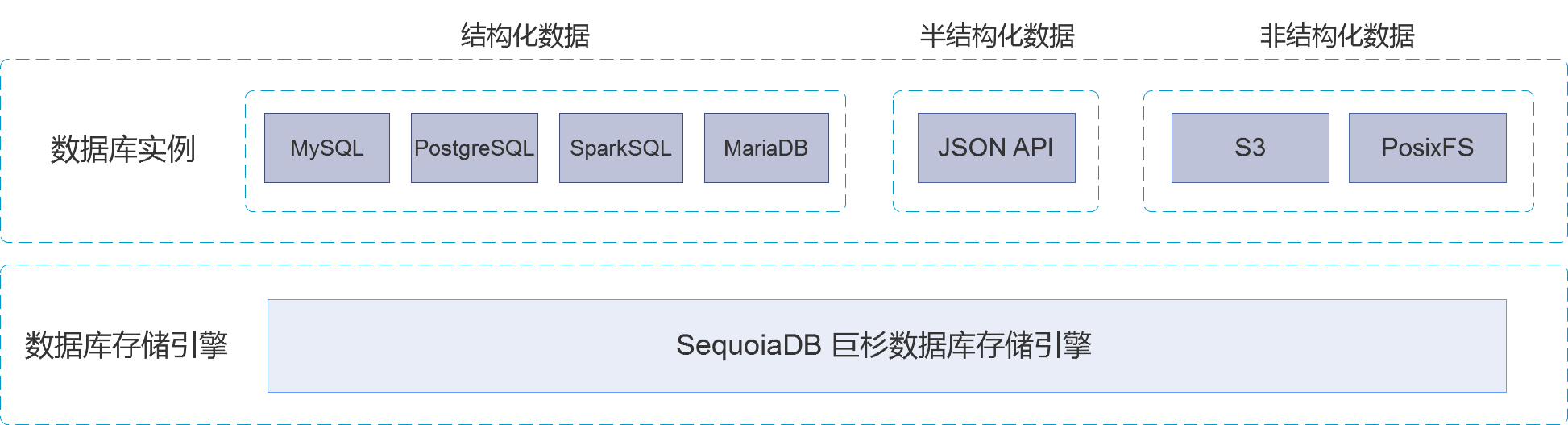 巨杉Sequoiadb產品整體邏輯框架圖
巨杉Sequoiadb產品整體邏輯框架圖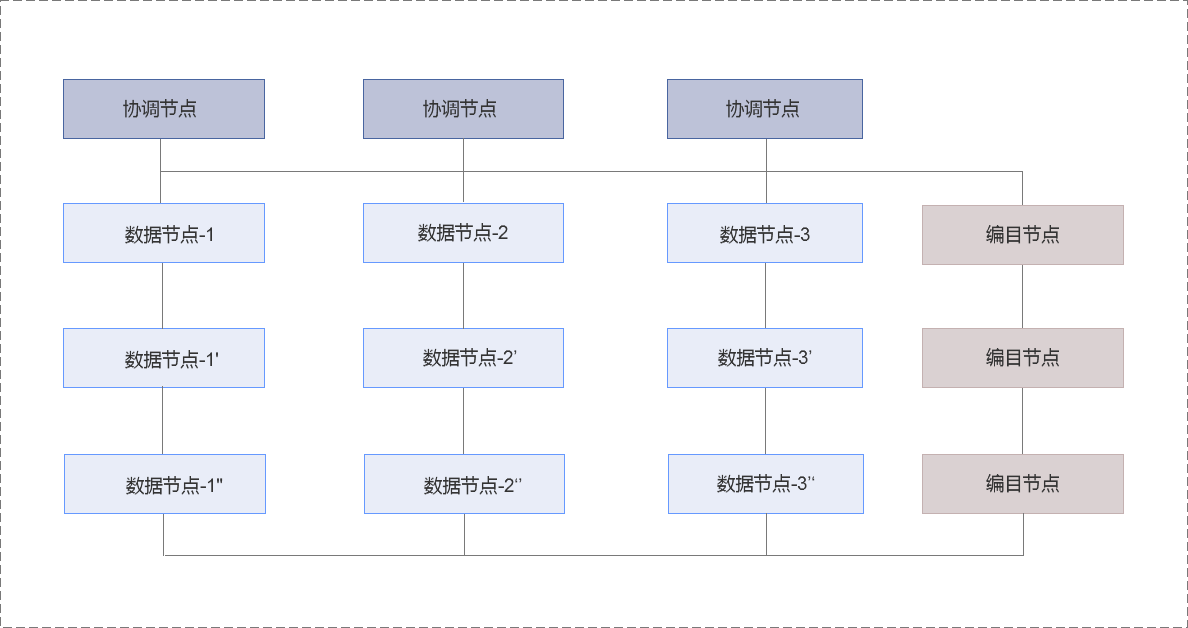 巨杉Sequoiadb產品存儲引擎框架圖
巨杉Sequoiadb產品存儲引擎框架圖
協調節點
協調節點不存儲任何用戶數據。作為外部訪問的接入與請求分發節點,協調節點將用戶請求分發至相應的數據節點,最終合並數據節點的結果應答對外進行響應。
編目節點
編目節點主要存儲系統的節點信息、用戶信息、分區信息以及對象定義等元數據。在特定操作下,協調節點與數據節點均會向編目節點請求元數據信息,以感知數據的分布規律和校驗請求的正確性。
數據節點
數據節點為用戶數據的物理存儲節點,海量數據通過分片切分的方式被分散至不同的數據節點。在關系型與 JSON 數據庫實例中,每一條記錄會被完整地存放在其中一個或多個數據節點中;而在對象存儲實例中,每一個文件將會依據數據頁大小被拆分成多個數據塊,並被分散至不同的數據節點進行存放。
阿里雲 AnalyticDB PostgreSQL
來源:https://www.aliyun.com/product/gpdb
 阿里雲 AnalyticDB 產品架構圖
阿里雲 AnalyticDB 產品架構圖
AnalyticDB PostgreSQL版采用MPP架構,實例由多個計算節點組成,存儲磁盤類型支持高效雲盤和ESSD雲盤,計算和存儲分離,可以獨立增加節點或擴容,且保持查詢響應時間不變。集群實例包括的組件有 :
- 協調節點(Master Node)。
- 接收請求,制定分布式執行計划。
- 計算節點(Compute Groups)。
- 全並行分析計算
- 數據分區雙副本存儲
- 定期自動備份至OSS
區別於Greenplum, 2021年2月8日,AnalyticDB PostgreSQL版正式開放多Master的能力,支持通過水平擴展協調節點(Master Node)來突破原架構單Master的限制,在計算節點不存在瓶頸的情況下,系統連接數及讀寫能力可以隨着Master節點數增加實現線性擴展,從而進一步提升系統整體能力,更好的滿足實時數倉及HTAP等業務場景的需求。
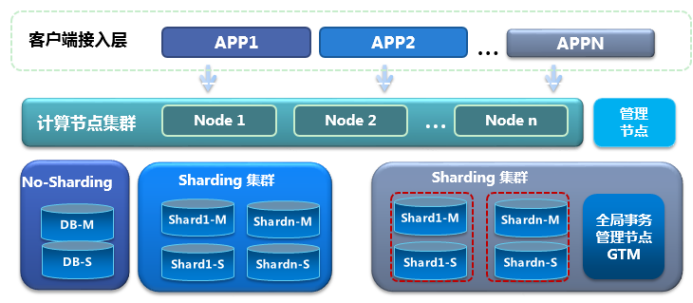
騰訊TDSQL MySQL
來源:https://cloud.tencent.com/product/dcdb
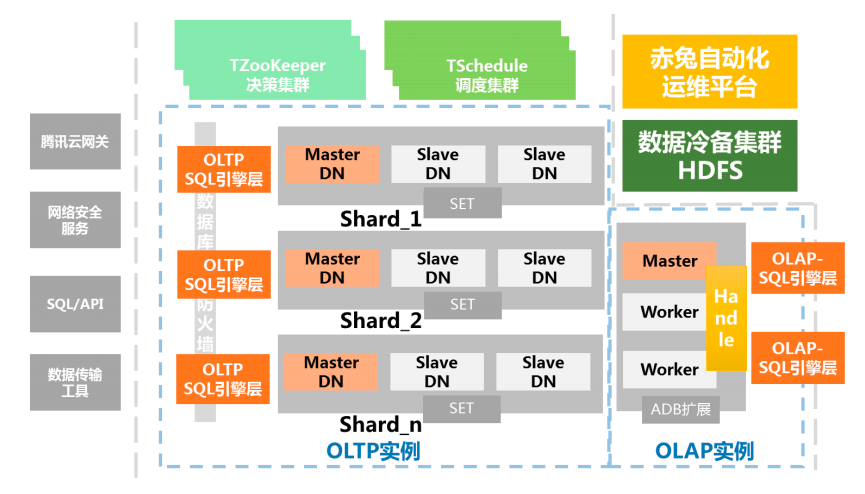 騰訊TDSQL MySQL 產品架構圖
騰訊TDSQL MySQL 產品架構圖
實例:從業務視角看到的一個具有完整能力的數據庫;
分片(Sharding):是由數據庫節點組(SET)和 SQL Engine(SQL Engine)和支撐系統組成一主多從數據庫,也是水平拆分后承載數據的基本單元;
節點組(SET):由數據庫節點(DataNode)組成的,通常包括一個主、從節點的集合。說明:雲數據庫支持虛擬化多租戶能力,節點即可以是物理節點(一台物理設備),也可以是邏輯節點(一台物理設備的一部分資源)
SQL 引擎層(SQL Engine):賬號鑒權、管理連接、SQL 解析、分配路由的 SQL Engine模塊;SQL Engine 可以混合部署在數據庫節點(DataNode)之上,也可以獨立部署在一台物理機中。SQL Engine 也是采用分布式架構設計,提供並行負載和高可用容災能力;調度集群、決策集群:作為集群的管理調度中心,主要保證數據庫節點組、接入 SQL Engine 集群的正常運行;
調度集群(Scheduler): 幫助 DBA 或者數據庫用戶自動調度和運行各種類型的作業,比如數據庫備份、收集監控、生成各種報表或者執行業務流程等等,TDSQL 把 Schedule、Zookeeper、Oss(運營支撐系統)結合起來,通過時間窗口激活指定的資源計划,完成數據庫在資源管理和作業調度上的各種復雜需求,Oracle 也用 DBMS_SCHEDULER 支持類似的能力。
決策集群(ZooKeeper):在 TDSQL 中,它的主要功能是配置維護、選舉決策、路由同步等,ZooKeeper 支撐數據庫節點組(分片)的創建、刪除、替換等工作,集群部署要求大於等於 3組且跨機房部署。
TDSpark 節點:基於 Spark 擴展的計算節點,采用只讀的方式與 SET 連接,以 JDBC的方式獲取數據。
赤兔運營平台(chitu):基於 TDSQL 定制開發的一套綜合的業務運營和管理平台,將
數據庫的管理特點,將網絡管理、系統管理、監控服務有機整合在一起。
達夢MPP
來源:https://www.modb.pro/doc/252
 DM MPP 數據庫集群 產品系統架構圖
DM MPP 數據庫集群 產品系統架構圖
DM MPP 中的每一個 DM 數據庫服務器實例作為一個執行節點,簡稱 EP。客戶端可連接任意一個 EP 節點進行操作,所有 EP 對客戶來說都是對等的。
DM MPP 系統內每個 EP 只負責自身部分數據的讀寫,執行計划在所有 EP 並行執行,能充分利用各 EP 的計算能力及發揮各 EP 獨立存儲的優勢。數據只在必要時通過 DM 的高速郵件 MAL 系統在 EP 間傳遞。當通信代價占整體執行代價的比例較小時,更能體現大規模並行處理的優勢,隨着系統規模的擴大,並行支路越多,優勢越明顯。
Flink 架構圖
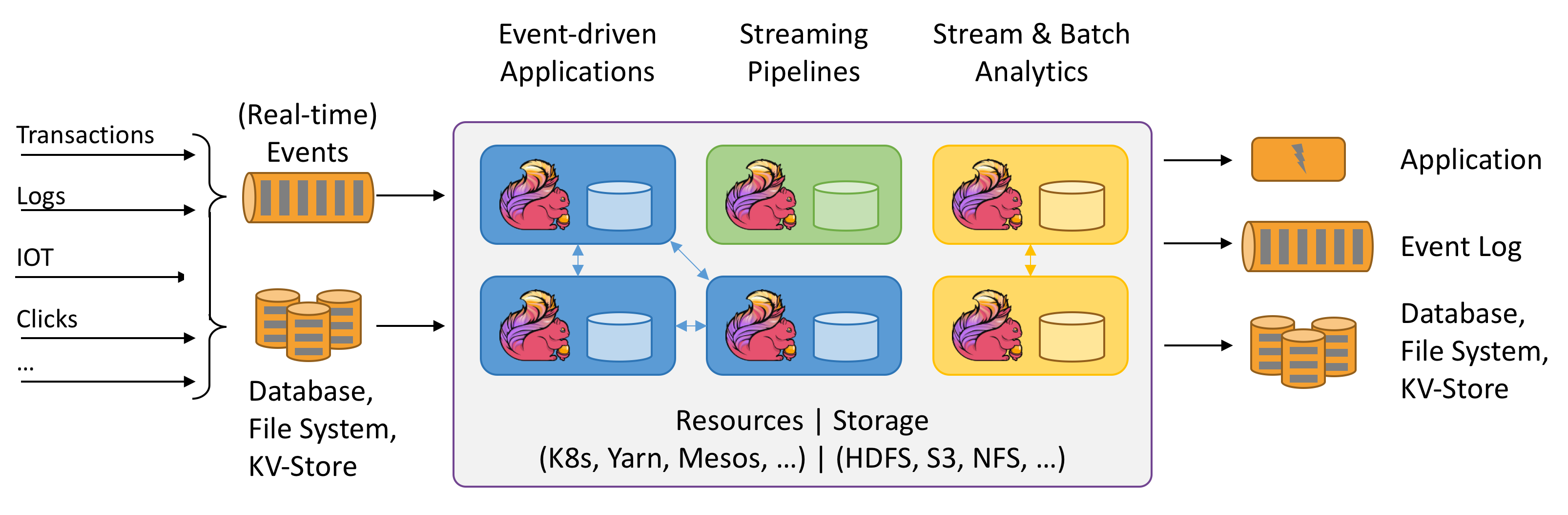 flink 產品架構圖
flink 產品架構圖
Spark架構圖
來源:https://new.qq.com/rain/a/20210525A006XF00
https://dongkelun.com/2018/06/09/sparkArchitecturePrinciples/
 Spark Streaming
Spark Streaming Spark 產品架構圖
Spark 產品架構圖
一個詳細圖
 spark產品使用架構圖
spark產品使用架構圖
Clickhouse 架構圖
官網沒有圖: https://clickhouse.tech/docs/zh/development/architecture/
第三方找到的圖:https://segmentfault.com/a/1190000039292250?utm_source=tag-newest
 clickhouse 產品架構圖
clickhouse 產品架構圖
1)Parser與Interpreter
Parser和Interpreter是非常重要的兩組接口:Parser分析器是將sql語句已遞歸的方式形成AST語法樹的形式,並且不同類型的sql都會調用不同的parse實現類。而Interpreter解釋器則負責解釋AST,並進一步創建查詢的執行管道。Interpreter解釋器的作用就像Service服務層一樣,起到串聯整個查詢過程的作用,它會根據解釋器的類型,聚合它所需要的資源。首先它會解析AST對象;然后執行”業務邏輯” ( 例如分支判斷、設置參數、調用接口等 );最終返回IBlock對象,以線程的形式建立起一個查詢執行管道。
2)表引擎
表引擎是ClickHouse的一個顯著特性,上文也有提到,clickhouse有很多種表引擎。不同的表引擎由不同的子類實現。表引擎是使用IStorage接口的,該接口定義了DDL ( 如ALTER、RENAME、OPTIMIZE和DROP等 ) 、read和write方法,它們分別負責數據的定義、查詢與寫入。
3)DataType
數據的序列化和反序列化工作由DataType負責。根據不同的數據類型,IDataType接口會有不同的實現類。DataType雖然會對數據進行正反序列化,但是它不會直接和內存或者磁盤做交互,而是轉交給Column和Filed處理。
4)Column與Field
Column和Field是ClickHouse數據最基礎的映射單元。作為一款百分之百的列式存儲數據庫,ClickHouse按列存儲數據,內存中的一列數據由一個Column對象表示。Column對象分為接口和實現兩個部分,在IColumn接口對象中,定義了對數據進行各種關系運算的方法,例如插入數據的insertRangeFrom和insertFrom方法、用於分頁的cut,以及用於過濾的filter方法等。而這些方法的具體實現對象則根據數據類型的不同,由相應的對象實現,例如ColumnString、ColumnArray和ColumnTuple等。在大多數場合,ClickHouse都會以整列的方式操作數據,但凡事也有例外。如果需要操作單個具體的數值 ( 也就是單列中的一行數據 ),則需要使用Field對象,Field對象代表一個單值。與Column對象的泛化設計思路不同,Field對象使用了聚合的設計模式。在Field對象內部聚合了Null、UInt64、String和Array等13種數據類型及相應的處理邏輯。
5)Block
ClickHouse內部的數據操作是面向Block對象進行的,並且采用了流的形式。雖然Column和Filed組成了數據的基本映射單元,但對應到實際操作,它們還缺少了一些必要的信息,比如數據的類型及列的名稱。於是ClickHouse設計了Block對象,Block對象可以看作數據表的子集。Block對象的本質是由數據對象、數據類型和列名稱組成的三元組,即Column、DataType及列名稱字符串。Column提供了數據的讀取能力,而DataType知道如何正反序列化,所以Block在這些對象的基礎之上實現了進一步的抽象和封裝,從而簡化了整個使用的過程,僅通過Block對象就能完成一系列的數據操作。在具體的實現過程中,Block並沒有直接聚合Column和DataType對象,而是通過ColumnWith TypeAndName對象進行間接引用。
Greenplum 架構圖
來源:https://docs.greenplum.org/6-13/admin_guide/intro/arch_overview.html
https://www.sohu.com/a/235952294_747818
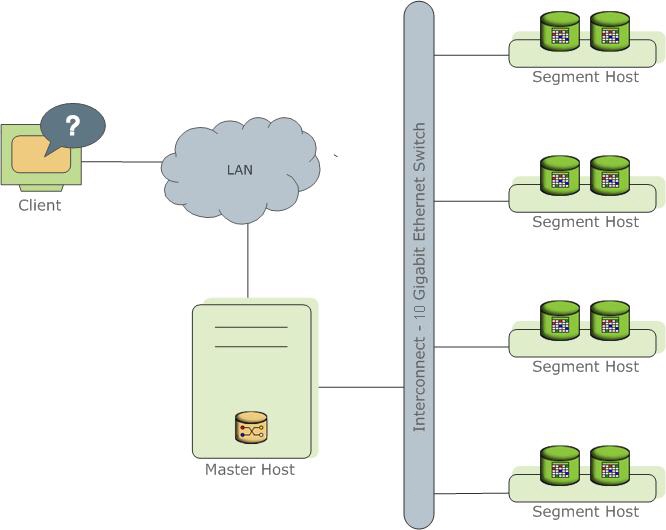 Greenplum 產品架構圖
Greenplum 產品架構圖 Greenplum 產品架構圖
Greenplum 產品架構圖
Gaussdb for opengauss_架構圖
來源:https://support.huaweicloud.com/productdesc-opengauss/opengauss_01_0002.html
 gaussdb_for_opengauss_產品架構圖.png
gaussdb_for_opengauss_產品架構圖.png
Gaussdb200架構圖
來源:https://bbs.huaweicloud.com/blogs/102536
 Gaussdb200 產品架構圖
Gaussdb200 產品架構圖
Gaussdb200架構說明如下圖
 Gaussdb200架構
Gaussdb200架構
Polardb整體架構圖
如下幾個不同的數據庫從架構上是相同的。
polardb-O來源:https://help.aliyun.com/document_detail/173254.html
polardb Mysql來源:https://help.aliyun.com/document_detail/58766.html
 Polardb-O 產品整體架構圖
Polardb-O 產品整體架構圖
PolarDB-X 整體架構圖
來源:https://help.aliyun.com/document_detail/117771.html
 PolarDB-X 產品整體架構圖
PolarDB-X 產品整體架構圖
GBase 8a整體架構圖
來源:http://www.gbase.cn/pro/361.html
 GBase 8a 產品整體架構圖
GBase 8a 產品整體架構圖
OceanBase 整體架構圖
來源 https://www.oceanbase.com/docs/oceanbase-database/oceanbase-database/V3.1.1/system-architecture
 OceanBase 產品整體架構圖
OceanBase 產品整體架構圖
OceanBase 數據庫支持數據跨地域(Region)部署,每個地域可能位於不同的城市,距離通常比較遠,所以 OceanBase 數據庫可以支持多城市部署,也支持多城市級別的容災。一個 Region 可以包含一個或者多個 Zone,Zone 是一個邏輯的概念,它包含了 1 台或者多台運行了 OBServer 進程的服務器(以下簡稱 OBServer)。每一個 Zone 上包含一個完整的數據副本,由於 OceanBase 數據庫的數據副本是以分區為單位的,所以同一個分區的數據會分布在多個 Zone 上。每個分區的主副本所在服務器被稱為 Leader,所在的 Zone 被稱為 Primary Zone。如果不設定 Primary Zone,系統會根據負載均衡的策略,在多個全功能副本里自動選擇一個作為 Leader。
每個 Zone 會提供兩種服務:總控服務(RootService)和分區服務(PartitionService)。其中每個 Zone 上都會存在一個總控服務,運行在某一個 OBServer 上,整個集群中只存在一個主總控服務,其他的總控服務作為主總控服務的備用服務運行。總控服務負責整個集群的資源調度、資源分配、數據分布信息管理以及 Schema 管理等功能。 其中:
- 資源調度主要包含了向集群中添加、刪除 OBServer,在 OBServer 中創建資源規格、Tenant 等供用戶使用的資源;
- 資源均衡主要是指各種資源(例如:Unit)在各個 Zone 或者 OBServer 之間的遷移。
- 數據分布管理是指總控服務會決定數據分布的位置信息,例如:某一個分區的數據分布到哪些 OBServer 上。
- Schema 管理是指總控服務會負責調度和管理各種 DDL 語句。
分區服務用於負責每個 OBServer 上各個分區的管理和操作功能的模塊,這個模塊與事務引擎、存儲引擎存在很多調用關系。
OceanBase 數據庫基於 Paxos 的分布式選舉算法來實現系統的高可用,最小的粒度可以做到分區級別。集群中數據的一個分區(或者稱為副本)會被保存到所有的 Zone 上,整個系統中該副本的多個分區之間通過 Paxos 協議進行日志同步。每個分區和它的副本構成一個獨立的 Paxos 復制組,其中一個分區為主分區(Leader),其它分區為備分區(Follower)。所有針對這個副本的寫請求,都會自動路由到對應的主分區上進行。主分區可以分布在不同的 OBServer 上,這樣對於不同副本的寫操作也會分布到不同的數據節點上,從而實現數據多點寫入,提高系統性能。
TiDB整體架構圖
來源:https://docs.pingcap.com/zh/tidb/stable/tidb-architecture
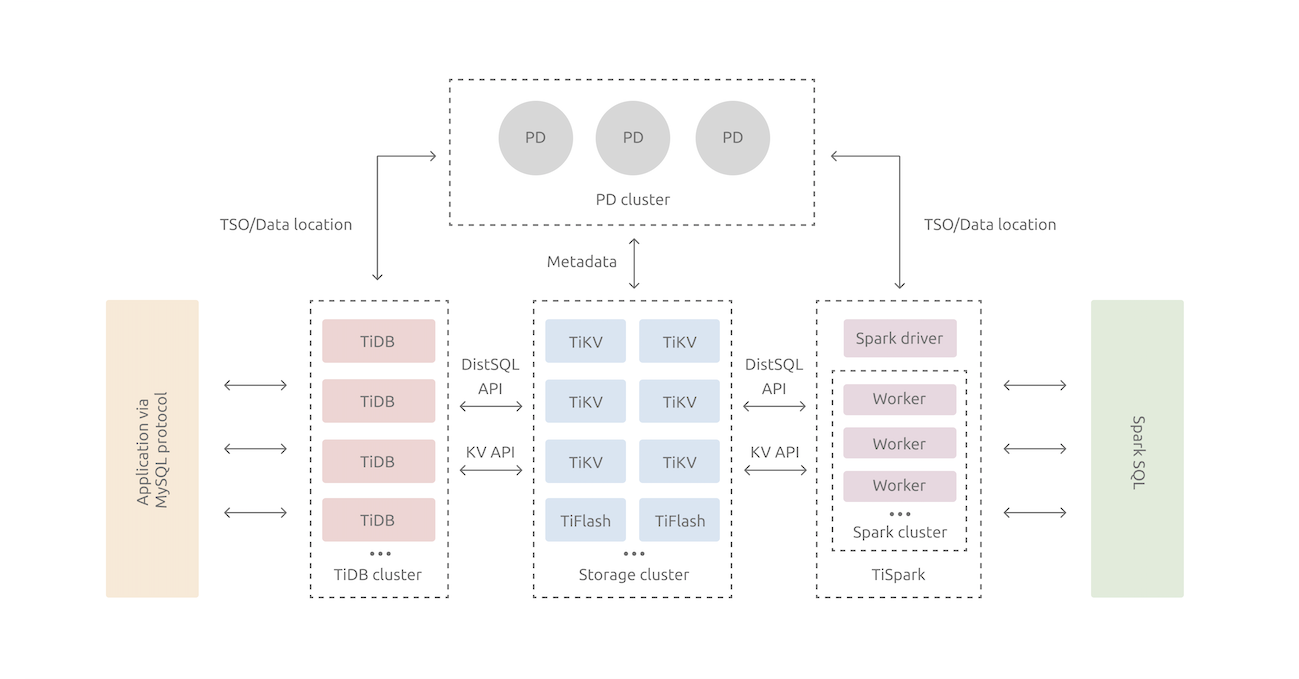 TiDB 產品整體架構圖
TiDB 產品整體架構圖
- TiDB Server:SQL 層,對外暴露 MySQL 協議的連接 endpoint,負責接受客戶端的連接,執行 SQL 解析和優化,最終生成分布式執行計划。TiDB 層本身是無狀態的,實踐中可以啟動多個 TiDB 實例,通過負載均衡組件(如 LVS、HAProxy 或 F5)對外提供統一的接入地址,客戶端的連接可以均勻地分攤在多個 TiDB 實例上以達到負載均衡的效果。TiDB Server 本身並不存儲數據,只是解析 SQL,將實際的數據讀取請求轉發給底層的存儲節點 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整個 TiDB 集群的元信息管理模塊,負責存儲每個 TiKV 節點實時的數據分布情況和集群的整體拓撲結構,提供 TiDB Dashboard 管控界面,並為分布式事務分配事務 ID。PD 不僅存儲元信息,同時還會根據 TiKV 節點實時上報的數據分布狀態,下發數據調度命令給具體的 TiKV 節點,可以說是整個集群的“大腦”。此外,PD 本身也是由至少 3 個節點構成,擁有高可用的能力。建議部署奇數個 PD 節點。
- 存儲節點
- TiKV Server:負責存儲數據,從外部看 TiKV 是一個分布式的提供事務的 Key-Value 存儲引擎。存儲數據的基本單位是 Region,每個 Region 負責存儲一個 Key Range(從 StartKey 到 EndKey 的左閉右開區間)的數據,每個 TiKV 節點會負責多個 Region。TiKV 的 API 在 KV 鍵值對層面提供對分布式事務的原生支持,默認提供了 SI (Snapshot Isolation) 的隔離級別,這也是 TiDB 在 SQL 層面支持分布式事務的核心。TiDB 的 SQL 層做完 SQL 解析后,會將 SQL 的執行計划轉換為對 TiKV API 的實際調用。所以,數據都存儲在 TiKV 中。另外,TiKV 中的數據都會自動維護多副本(默認為三副本),天然支持高可用和自動故障轉移。
- TiFlash:TiFlash 是一類特殊的存儲節點。和普通 TiKV 節點不一樣的是,在 TiFlash 內部,數據是以列式的形式進行存儲,主要的功能是為分析型的場景加速。