本文目錄:
一、消息隊列
Apache Pulsar
Pulsar 與 Kafka 對比
二、Kafka基礎
三、Kafka架構及組件
四、Kafka集群操作
五、Kafka的JavaAPI操作
六、Kafka中的數據不丟失機制
七、Kafka配置文件說明
八、CAP理論
九、Kafka中的CAP機制
十、Kafka監控及運維
十一、Kafka大廠面試題
Kafka 涉及的知識點如下圖所示,本文將逐一講解:
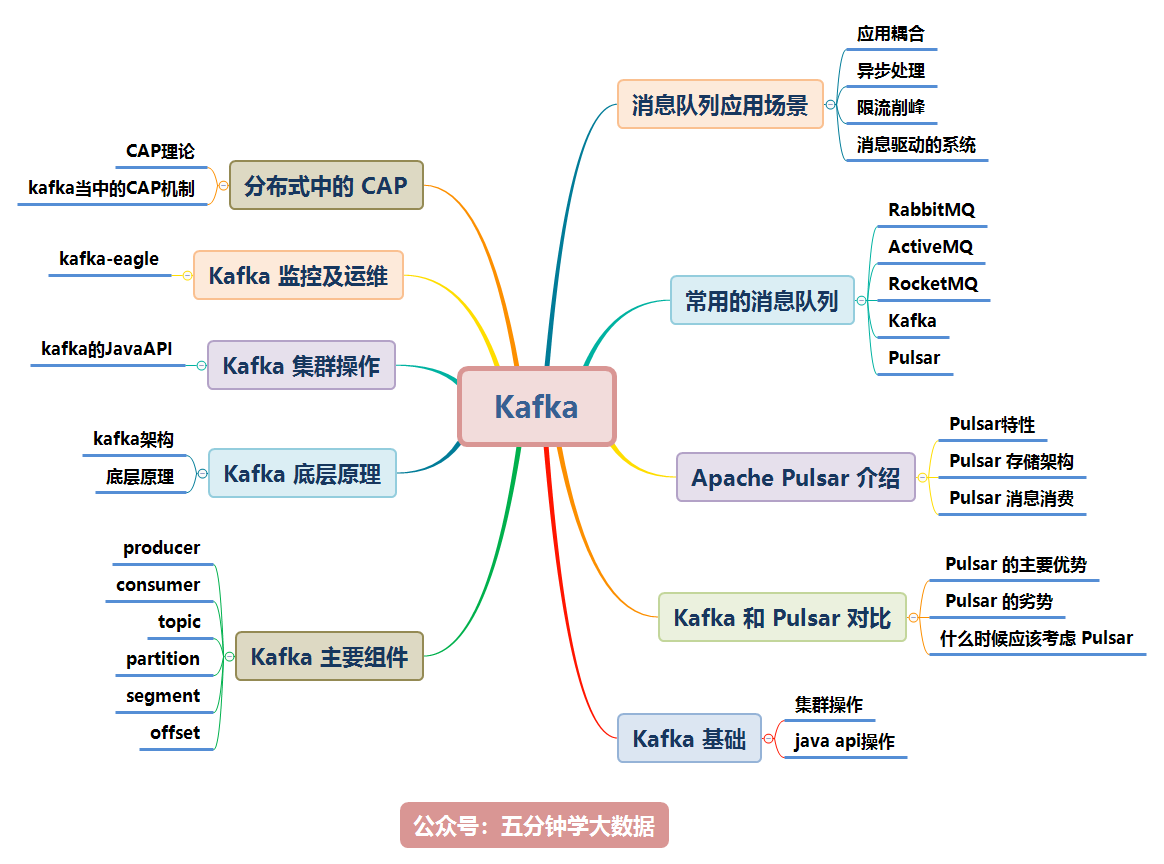
本文檔參考了關於 Kafka 的官網及其他眾多資料整理而成,為了整潔的排版及舒適的閱讀,對於模糊不清晰的圖片及黑白圖片進行重新繪制成了高清彩圖。
一、消息隊列
1. 消息隊列的介紹
消息(Message)是指在應用之間傳送的數據,消息可以非常簡單,比如只包含文本字符串,也可以更復雜,可能包含嵌入對象。
消息隊列(Message Queue)是一種應用間的通信方式,消息發送后可以立即返回,有消息系統來確保信息的可靠專遞,消息發布者只管把消息發布到MQ中而不管誰來取,消息使用者只管從MQ中取消息而不管誰發布的,這樣發布者和使用者都不用知道對方的存在。
2. 消息隊列的應用場景
消息隊列在實際應用中包括如下四個場景:
-
應用耦合:多應用間通過消息隊列對同一消息進行處理,避免調用接口失敗導致整個過程失敗;
-
異步處理:多應用對消息隊列中同一消息進行處理,應用間並發處理消息,相比串行處理,減少處理時間;
-
限流削峰:廣泛應用於秒殺或搶購活動中,避免流量過大導致應用系統掛掉的情況;
-
消息驅動的系統:系統分為消息隊列、消息生產者、消息消費者,生產者負責產生消息,消費者(可能有多個)負責對消息進行處理;
下面詳細介紹上述四個場景以及消息隊列如何在上述四個場景中使用:
- 異步處理
具體場景:用戶為了使用某個應用,進行注冊,系統需要發送注冊郵件並驗證短信。對這兩個操作的處理方式有兩種:串行及並行。
-
串行方式:新注冊信息生成后,先發送注冊郵件,再發送驗證短信;

在這種方式下,需要最終發送驗證短信后再返回給客戶端。
-
並行處理:新注冊信息寫入后,由發短信和發郵件並行處理;
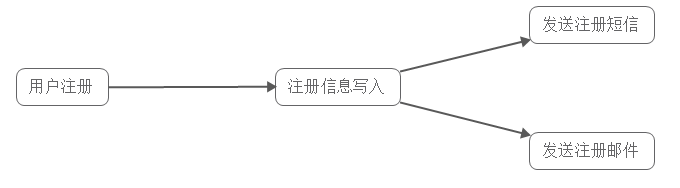
在這種方式下,發短信和發郵件 需處理完成后再返回給客戶端。
假設以上三個子系統處理的時間均為50ms,且不考慮網絡延遲,則總的處理時間:串行:50+50+50=150ms
並行:50+50 = 100ms -
若使用消息隊列:
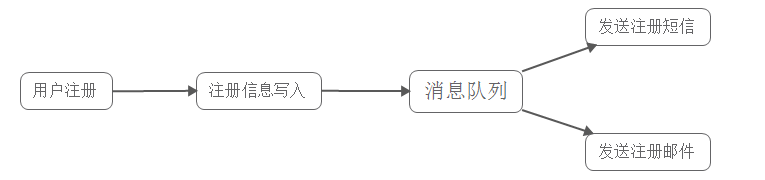
在寫入消息隊列后立即返回成功給客戶端,則總的響應時間依賴於寫入消息隊列的時間,而寫入消息隊列的時間本身是可以很快的,基本可以忽略不計,因此總的處理時間相比串行提高了2倍,相比並行提高了一倍;
- 應用耦合
具體場景:用戶使用QQ相冊上傳一張圖片,人臉識別系統會對該圖片進行人臉識別,一般的做法是,服務器接收到圖片后,圖片上傳系統立即調用人臉識別系統,調用完成后再返回成功,如下圖所示:
該方法有如下缺點:

-
人臉識別系統被調失敗,導致圖片上傳失敗;
-
延遲高,需要人臉識別系統處理完成后,再返回給客戶端,即使用戶並不需要立即知道結果;
-
圖片上傳系統與人臉識別系統之間互相調用,需要做耦合;
若使用消息隊列:

客戶端上傳圖片后,圖片上傳系統將圖片信息如uin、批次寫入消息隊列,直接返回成功;而人臉識別系統則定時從消息隊列中取數據,完成對新增圖片的識別。
此時圖片上傳系統並不需要關心人臉識別系統是否對這些圖片信息的處理、以及何時對這些圖片信息進行處理。事實上,由於用戶並不需要立即知道人臉識別結果,人臉識別系統可以選擇不同的調度策略,按照閑時、忙時、正常時間,對隊列中的圖片信息進行處理。
- 限流削峰
具體場景:購物網站開展秒殺活動,一般由於瞬時訪問量過大,服務器接收過大,會導致流量暴增,相關系統無法處理請求甚至崩潰。而加入消息隊列后,系統可以從消息隊列中取數據,相當於消息隊列做了一次緩沖。

該方法有如下優點:
-
請求先入消息隊列,而不是由業務處理系統直接處理,做了一次緩沖,極大地減少了業務處理系統的壓力;
-
隊列長度可以做限制,事實上,秒殺時,后入隊列的用戶無法秒殺到商品,這些請求可以直接被拋棄,返回活動已結束或商品已售完信息;
4.消息驅動的系統
具體場景:用戶新上傳了一批照片,人臉識別系統需要對這個用戶的所有照片進行聚類,聚類完成后由對賬系統重新生成用戶的人臉索引(加快查詢)。這三個子系統間由消息隊列連接起來,前一個階段的處理結果放入隊列中,后一個階段從隊列中獲取消息繼續處理。

該方法有如下優點:
-
避免了直接調用下一個系統導致當前系統失敗;
-
每個子系統對於消息的處理方式可以更為靈活,可以選擇收到消息時就處理,可以選擇定時處理,也可以划分時間段按不同處理速度處理;
3. 消息隊列的兩種模式
消息隊列包括兩種模式,點對點模式(point to point, queue)和發布/訂閱模式(publish/subscribe,topic)
1) 點對點模式
點對點模式下包括三個角色:
- 消息隊列
- 發送者 (生產者)
- 接收者(消費者)

消息發送者生產消息發送到queue中,然后消息接收者從queue中取出並且消費消息。消息被消費以后,queue中不再有存儲,所以消息接收者不可能消費到已經被消費的消息。
點對點模式特點:
- 每個消息只有一個接收者(Consumer)(即一旦被消費,消息就不再在消息隊列中);
- 發送者和接發收者間沒有依賴性,發送者發送消息之后,不管有沒有接收者在運行,都不會影響到發送者下次發送消息;
- 接收者在成功接收消息之后需向隊列應答成功,以便消息隊列刪除當前接收的消息;
2) 發布/訂閱模式
發布/訂閱模式下包括三個角色:
- 角色主題(Topic)
- 發布者(Publisher)
- 訂閱者(Subscriber)
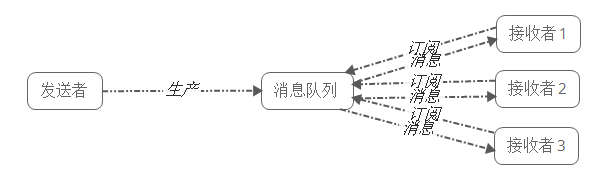
發布者將消息發送到Topic,系統將這些消息傳遞給多個訂閱者。
發布/訂閱模式特點:
- 每個消息可以有多個訂閱者;
- 發布者和訂閱者之間有時間上的依賴性。針對某個主題(Topic)的訂閱者,它必須創建一個訂閱者之后,才能消費發布者的消息。
- 為了消費消息,訂閱者需要提前訂閱該角色主題,並保持在線運行;
4. 常用的消息隊列介紹
1) RabbitMQ
RabbitMQ 2007年發布,是一個在AMQP(高級消息隊列協議)基礎上完成的,可復用的企業消息系統,是當前最主流的消息中間件之一。
2) ActiveMQ
ActiveMQ是由Apache出品,ActiveMQ 是一個完全支持JMS1.1和J2EE 1.4規范的 JMS Provider實現。它非常快速,支持多種語言的客戶端和協議,而且可以非常容易的嵌入到企業的應用環境中,並有許多高級功能。
3) RocketMQ
RocketMQ出自 阿里公司的開源產品,用 Java 語言實現,在設計時參考了 Kafka,並做出了自己的一些改進,消息可靠性上比 Kafka 更好。RocketMQ在阿里集團被廣泛應用在訂單,交易,充值,流計算,消息推送,日志流式處理等。
4) Kafka
Apache Kafka是一個分布式消息發布訂閱系統。它最初由LinkedIn公司基於獨特的設計實現為一個分布式的提交日志系統( a distributed commit log),,之后成為Apache項目的一部分。Kafka系統快速、可擴展並且可持久化。它的分區特性,可復制和可容錯都是其不錯的特性。
5. Pulsar
Apahce Pulasr是一個企業級的發布-訂閱消息系統,最初是由雅虎開發,是下一代雲原生分布式消息流平台,集消息、存儲、輕量化函數式計算為一體,采用計算與存儲分離架構設計,支持多租戶、持久化存儲、多機房跨區域數據復制,具有強一致性、高吞吐、低延時及高可擴展性等流數據存儲特性。
Pulsar 非常靈活:它既可以應用於像 Kafka 這樣的分布式日志應用場景,也可以應用於像 RabbitMQ 這樣的純消息傳遞系統場景。它支持多種類型的訂閱、多種交付保證、保留策略以及處理模式演變的方法,以及其他諸多特性。
1. Pulsar 的特性
-
內置多租戶:不同的團隊可以使用相同的集群並將其隔離,解決了許多管理難題。它支持隔離、身份驗證、授權和配額;
-
多層體系結構:Pulsar 將所有 topic 數據存儲在由 Apache BookKeeper 支持的專業數據層中。存儲和消息傳遞的分離解決了擴展、重新平衡和維護集群的許多問題。它還提高了可靠性,幾乎不可能丟失數據。另外,在讀取數據時可以直連 BookKeeper,且不影響實時攝取。例如,可以使用 Presto 對 topic 執行 SQL 查詢,類似於 KSQL,但不會影響實時數據處理;
-
虛擬 topic:由於采用 n 層體系結構,因此對 topic 的數量沒有限制,topic 及其存儲是分離的。用戶還可以創建非持久性 topic;
-
N 層存儲:Kafka 的一個問題是,存儲費用可能變高。因此,它很少用於存儲"冷"數據,並且消息經常被刪除,Apache Pulsar 可以借助分層存儲自動將舊數據卸載到 Amazon S3 或其他數據存儲系統,並且仍然向客戶端展示透明視圖;Pulsar 客戶端可以從時間開始節點讀取,就像所有消息都存在於日志中一樣;
2. Pulsar 存儲架構
Pulsar 的多層架構影響了存儲數據的方式。Pulsar 將 topic 分區划分為分片(segment),然后將這些分片存儲在 Apache BookKeeper 的存儲節點上,以提高性能、可伸縮性和可用性。
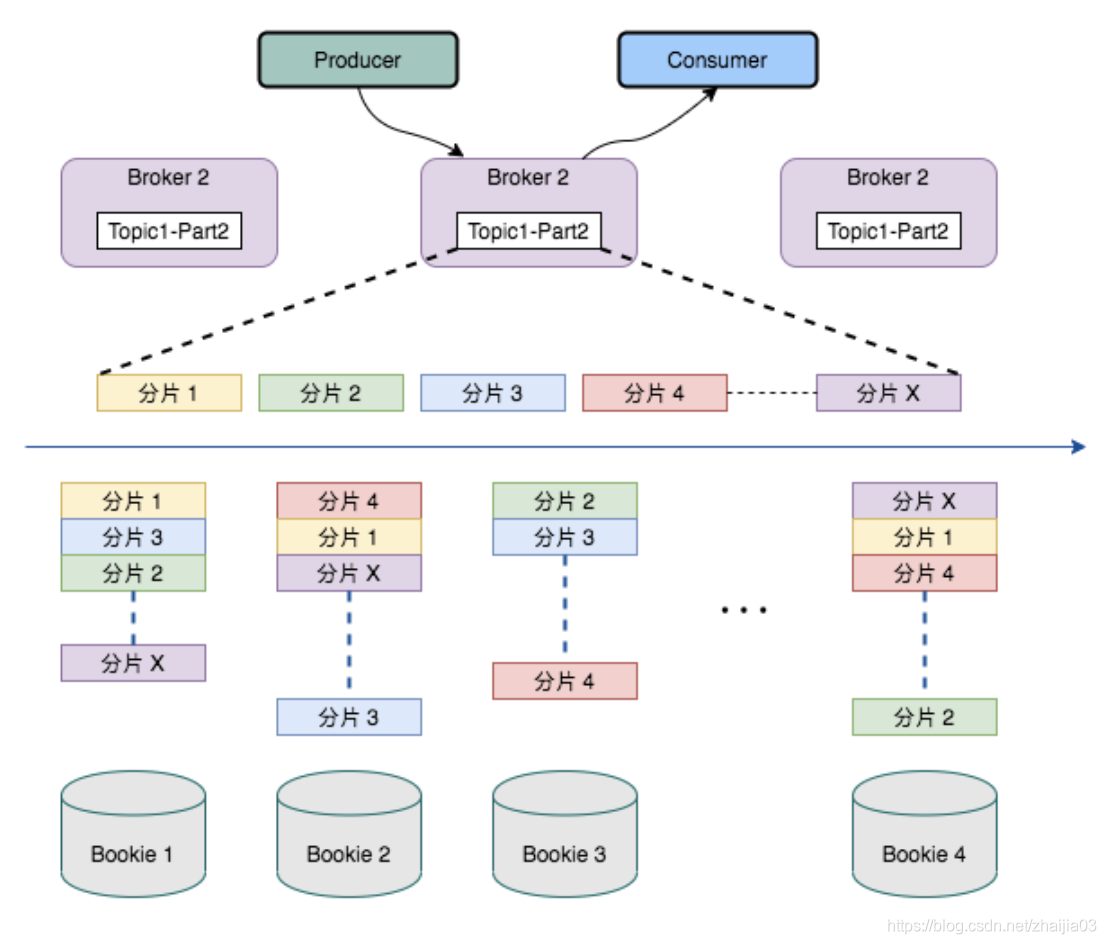
Pulsar 的無限分布式日志以分片為中心,借助擴展日志存儲(通過 Apache BookKeeper)實現,內置分層存儲支持,因此分片可以均勻地分布在存儲節點上。由於與任一給定 topic 相關的數據都不會與特定存儲節點進行捆綁,因此很容易替換存儲節點或縮擴容。另外,集群中最小或最慢的節點也不會成為存儲或帶寬的短板。
Pulsar 架構能實現分區管理,負載均衡,因此使用 Pulsar 能夠快速擴展並達到高可用。這兩點至關重要,所以 Pulsar 非常適合用來構建關鍵任務服務,如金融應用場景的計費平台,電子商務和零售商的交易處理系統,金融機構的實時風險控制系統等。
通過性能強大的 Netty 架構,數據從 producers 到 broker,再到 bookie 的轉移都是零拷貝,不會生成副本。這一特性對所有流應用場景都非常友好,因為數據直接通過網絡或磁盤進行傳輸,沒有任何性能損失。
3. Pulsar 消息消費
Pulsar 的消費模型采用了流拉取的方式。流拉取是長輪詢的改進版,不僅實現了單個調用和請求之間的零等待,還可以提供雙向消息流。通過流拉取模型,Pulsar 實現了端到端的低延遲,這種低延遲比所有現有的長輪詢消息系統(如 Kafka)都低。
6. Kafka與Pulsar對比
1. Pulsar 的主要優勢:
-
更多功能:Pulsar Function、多租戶、Schema registry、n 層存儲、多種消費模式和持久性模式等;
-
更大的靈活性:3 種訂閱類型(獨占,共享和故障轉移),用戶可以在一個訂閱上管理多個 topic;
-
易於操作運維:架構解耦和 n 層存儲;
-
與 Presto 的 SQL 集成,可直接查詢存儲而不會影響 broker;
-
借助 n 層自動存儲選項,可以更低成本地存儲;
2. Pulsar 的劣勢
Pulsar 並不完美,Pulsar 也存在一些問題:
-
相對缺乏支持、文檔和案例;
-
n 層體系結構導致需要更多組件:BookKeeper;
-
插件和客戶端相對 Kafka 較少;
-
雲中的支持較少,Confluent 具有托管雲產品。
3. 什么時候應該考慮 Pulsar
-
同時需要像 RabbitMQ 這樣的隊列和 Kafka 這樣的流處理程序;
-
需要易用的地理復制;
-
實現多租戶,並確保每個團隊的訪問權限;
-
需要長時間保留消息,並且不想將其卸載到另一個存儲中;
-
需要高性能,基准測試表明 Pulsar 提供了更低的延遲和更高的吞吐量;
總之,Pulsar還比較新,社區不完善,用的企業比較少,網上有價值的討論和問題的解決比較少,遠沒有Kafka生態系統龐大,且用戶量非常龐大,目前Kafka依舊是大數據領域消息隊列的王者!所以我們還是以Kafka為主!
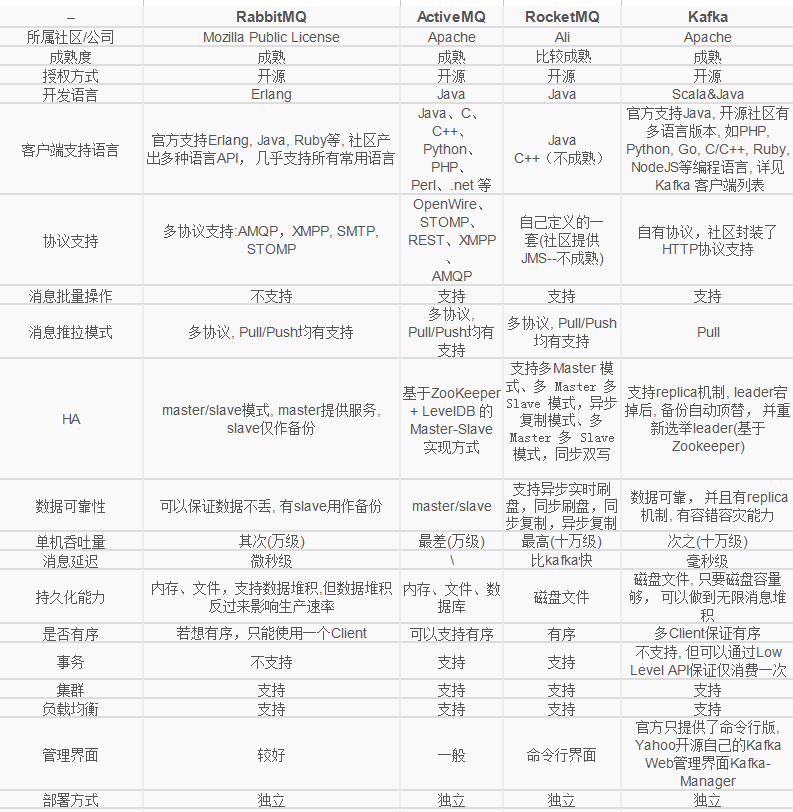
7. 其他消息隊列與Kafka對比
二、Kafka基礎
1. kafka的基本介紹
kafka是最初由linkedin公司開發的,使用scala語言編寫,kafka是一個分布式,分區的,多副本的,多訂閱者的日志系統(分布式MQ系統),可以用於搜索日志,監控日志,訪問日志等。
Kafka is a distributed,partitioned,replicated commit logservice。它提供了類似於JMS的特性,但是在設計實現上完全不同,此外它並不是JMS規范的實現。kafka對消息保存時根據Topic進行歸類,發送消息者成為Producer,消息接受者成為Consumer,此外kafka集群有多個kafka實例組成,每個實例(server)成為broker。無論是kafka集群,還是producer和consumer都依賴於zookeeper來保證系統可用性集群保存一些meta信息。
2. kafka的好處
- 可靠性:分布式的,分區,復本和容錯的。
- 可擴展性:kafka消息傳遞系統輕松縮放,無需停機。
- 耐用性:kafka使用分布式提交日志,這意味着消息會盡可能快速的保存在磁盤上,因此它是持久的。
- 性能:kafka對於發布和定於消息都具有高吞吐量。即使存儲了許多TB的消息,他也爆出穩定的性能。
- kafka非常快:保證零停機和零數據丟失。
3. 分布式的發布與訂閱系統
apache kafka是一個分布式發布-訂閱消息系統和一個強大的隊列,可以處理大量的數據,並使能夠將消息從一個端點傳遞到另一個端點,kafka適合離線和在線消息消費。kafka消息保留在磁盤上,並在集群內復制以防止數據丟失。kafka構建在zookeeper同步服務之上。它與apache和spark非常好的集成,應用於實時流式數據分析。
4. kafka的主要應用場景
1. 指標分析
kafka 通常用於操作監控數據。這設計聚合來自分布式應用程序的統計信息, 以產生操作的數據集中反饋
2. 日志聚合解決方法
kafka可用於跨組織從多個服務器收集日志,並使他們以標准的格式提供給多個服務器。
3. 流式處理
流式處理框架(spark,storm,flink)重主題中讀取數據,對齊進行處理,並將處理后的數據寫入新的主題,供 用戶和應用程序使用,kafka的強耐久性在流處理的上下文中也非常的有用。
三、Kafka架構及組件
1. kafka架構
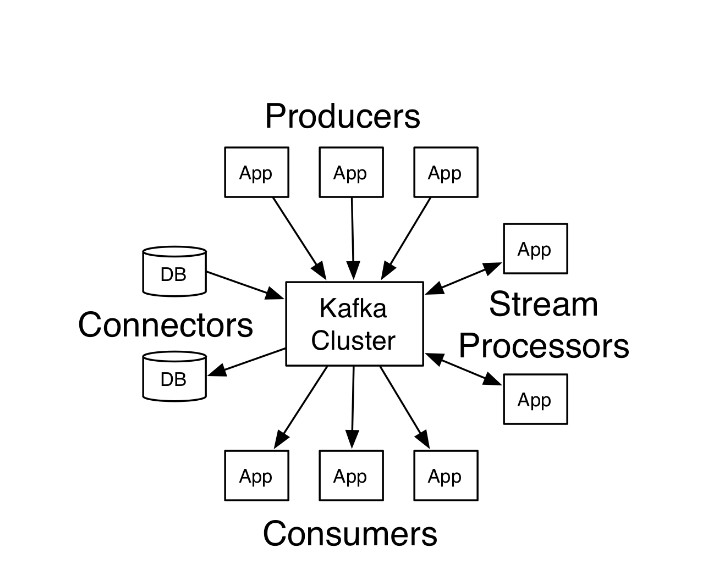
- 生產者API
允許應用程序發布記錄流至一個或者多個kafka的主題(topics)。
- 消費者API
允許應用程序訂閱一個或者多個主題,並處理這些主題接收到的記錄流。
3。 StreamsAPI
允許應用程序充當流處理器(stream processor),從一個或者多個主題獲取輸入流,並生產一個輸出流到一個或 者多個主題,能夠有效的變化輸入流為輸出流。
- ConnectAPI
允許構建和運行可重用的生產者或者消費者,能夠把kafka主題連接到現有的應用程序或數據系統。例如:一個連接到關系數據庫的連接器可能會獲取每個表的變化。
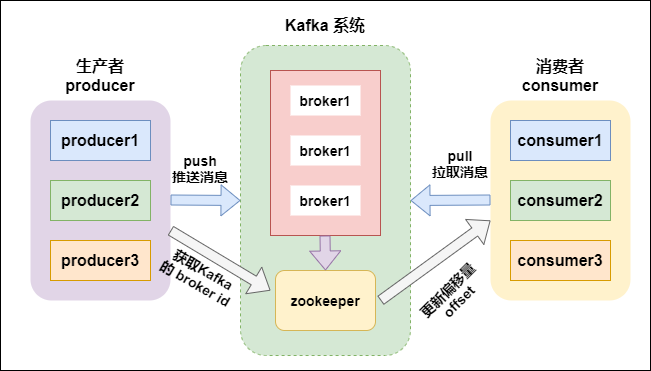
注:在Kafka 2.8.0 版本,移除了對Zookeeper的依賴,通過KRaft進行自己的集群管理,使用Kafka內部的Quorum控制器來取代ZooKeeper,因此用戶第一次可在完全不需要ZooKeeper的情況下執行Kafka,這不只節省運算資源,並且也使得Kafka效能更好,還可支持規模更大的集群。
過去Apache ZooKeeper是Kafka這類分布式系統的關鍵,ZooKeeper扮演協調代理的角色,所有代理服務器啟動時,都會連接到Zookeeper進行注冊,當代理狀態發生變化時,Zookeeper也會儲存這些數據,在過去,ZooKeeper是一個強大的工具,但是畢竟ZooKeeper是一個獨立的軟件,使得Kafka整個系統變得復雜,因此官方決定使用內部Quorum控制器來取代ZooKeeper。
這項工作從去年4月開始,而現在這項工作取得部分成果,用戶將可以在2.8版本,在沒有ZooKeeper的情況下執行Kafka,官方稱這項功能為Kafka Raft元數據模式(KRaft)。在KRaft模式,過去由Kafka控制器和ZooKeeper所操作的元數據,將合並到這個新的Quorum控制器,並且在Kafka集群內部執行,當然,如果使用者有特殊使用情境,Quorum控制器也可以在專用的硬件上執行。
好,說完在新版本中移除zookeeper這個事,咱們在接着聊kafka的其他功能:
kafka支持消息持久化,消費端是主動拉取數據,消費狀態和訂閱關系由客戶端負責維護,消息消費完后,不會立即刪除,會保留歷史消息。因此支持多訂閱時,消息只會存儲一份就可以。
- broker:kafka集群中包含一個或者多個服務實例(節點),這種服務實例被稱為broker(一個broker就是一個節點/一個服務器);
- topic:每條發布到kafka集群的消息都屬於某個類別,這個類別就叫做topic;
- partition:partition是一個物理上的概念,每個topic包含一個或者多個partition;
- segment:一個partition當中存在多個segment文件段,每個segment分為兩部分,.log文件和 .index 文件,其中 .index 文件是索引文件,主要用於快速查詢, .log 文件當中數據的偏移量位置;
- producer:消息的生產者,負責發布消息到 kafka 的 broker 中;
- consumer:消息的消費者,向 kafka 的 broker 中讀取消息的客戶端;
- consumer group:消費者組,每一個 consumer 屬於一個特定的 consumer group(可以為每個consumer指定 groupName);
- .log:存放數據文件;
- .index:存放.log文件的索引數據。
2. Kafka 主要組件
1. producer(生產者)
producer主要是用於生產消息,是kafka當中的消息生產者,生產的消息通過topic進行歸類,保存到kafka的broker里面去。
2. topic(主題)
- kafka將消息以topic為單位進行歸類;
- topic特指kafka處理的消息源(feeds of messages)的不同分類;
- topic是一種分類或者發布的一些列記錄的名義上的名字。kafka主題始終是支持多用戶訂閱的;也就是說,一 個主題可以有零個,一個或者多個消費者訂閱寫入的數據;
- 在kafka集群中,可以有無數的主題;
- 生產者和消費者消費數據一般以主題為單位。更細粒度可以到分區級別。
3. partition(分區)
kafka當中,topic是消息的歸類,一個topic可以有多個分區(partition),每個分區保存部分topic的數據,所有的partition當中的數據全部合並起來,就是一個topic當中的所有的數據。
一個broker服務下,可以創建多個分區,broker數與分區數沒有關系;
在kafka中,每一個分區會有一個編號:編號從0開始。
每一個分區內的數據是有序的,但全局的數據不能保證是有序的。(有序是指生產什么樣順序,消費時也是什么樣的順序)
4. consumer(消費者)
consumer是kafka當中的消費者,主要用於消費kafka當中的數據,消費者一定是歸屬於某個消費組中的。
5. consumer group(消費者組)
消費者組由一個或者多個消費者組成,同一個組中的消費者對於同一條消息只消費一次。
每個消費者都屬於某個消費者組,如果不指定,那么所有的消費者都屬於默認的組。
每個消費者組都有一個ID,即group ID。組內的所有消費者協調在一起來消費一個訂閱主題( topic)的所有分區(partition)。當然,每個分區只能由同一個消費組內的一個消費者(consumer)來消費,可以由不同的消費組來消費。
partition數量決定了每個consumer group中並發消費者的最大數量。如下圖:

如上面左圖所示,如果只有兩個分區,即使一個組內的消費者有4個,也會有兩個空閑的。
如上面右圖所示,有4個分區,每個消費者消費一個分區,並發量達到最大4。
在來看如下一幅圖:
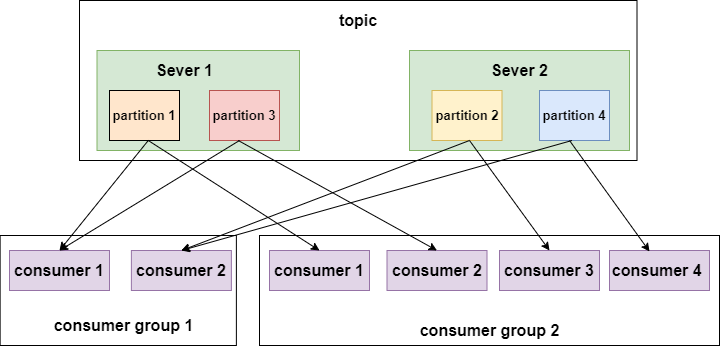
如上圖所示,不同的消費者組消費同一個topic,這個topic有4個分區,分布在兩個節點上。左邊的 消費組1有兩個消費者,每個消費者就要消費兩個分區才能把消息完整的消費完,右邊的 消費組2有四個消費者,每個消費者消費一個分區即可。
總結下kafka中分區與消費組的關系:
消費組: 由一個或者多個消費者組成,同一個組中的消費者對於同一條消息只消費一次。
某一個主題下的分區數,對於消費該主題的同一個消費組下的消費者數量,應該小於等於該主題下的分區數。
如:某一個主題有4個分區,那么消費組中的消費者應該小於等於4,而且最好與分區數成整數倍 1 2 4 這樣。同一個分區下的數據,在同一時刻,不能同一個消費組的不同消費者消費。
總結:分區數越多,同一時間可以有越多的消費者來進行消費,消費數據的速度就會越快,提高消費的性能。
6. partition replicas(分區副本)
kafka 中的分區副本如下圖所示:
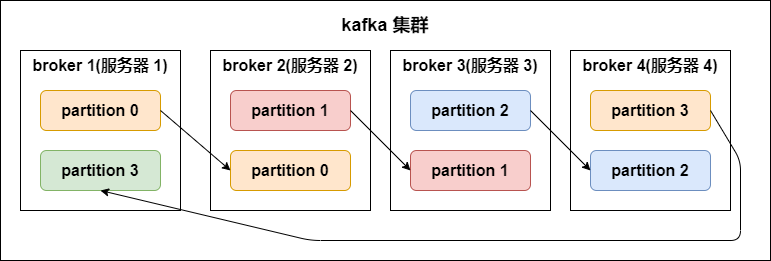
副本數(replication-factor):控制消息保存在幾個broker(服務器)上,一般情況下副本數等於broker的個數。
一個broker服務下,不可以創建多個副本因子。創建主題時,副本因子應該小於等於可用的broker數。
副本因子操作以分區為單位的。每個分區都有各自的主副本和從副本;
主副本叫做leader,從副本叫做 follower(在有多個副本的情況下,kafka會為同一個分區下的所有分區,設定角色關系:一個leader和N個 follower),處於同步狀態的副本叫做in-sync-replicas(ISR);
follower通過拉的方式從leader同步數據。
消費者和生產者都是從leader讀寫數據,不與follower交互。
副本因子的作用:讓kafka讀取數據和寫入數據時的可靠性。
副本因子是包含本身,同一個副本因子不能放在同一個broker中。
如果某一個分區有三個副本因子,就算其中一個掛掉,那么只會剩下的兩個中,選擇一個leader,但不會在其他的broker中,另啟動一個副本(因為在另一台啟動的話,存在數據傳遞,只要在機器之間有數據傳遞,就會長時間占用網絡IO,kafka是一個高吞吐量的消息系統,這個情況不允許發生)所以不會在另一個broker中啟動。
如果所有的副本都掛了,生產者如果生產數據到指定分區的話,將寫入不成功。
lsr表示:當前可用的副本。
7. segment文件
一個partition當中由多個segment文件組成,每個segment文件,包含兩部分,一個是 .log 文件,另外一個是 .index 文件,其中 .log 文件包含了我們發送的數據存儲,.index 文件,記錄的是我們.log文件的數據索引值,以便於我們加快數據的查詢速度。
索引文件與數據文件的關系
既然它們是一一對應成對出現,必然有關系。索引文件中元數據指向對應數據文件中message的物理偏移地址。
比如索引文件中 3,497 代表:數據文件中的第三個message,它的偏移地址為497。
再來看數據文件中,Message 368772表示:在全局partiton中是第368772個message。
注:segment index file 采取稀疏索引存儲方式,減少索引文件大小,通過mmap(內存映射)可以直接內存操作,稀疏索引為數據文件的每個對應message設置一個元數據指針,它比稠密索引節省了更多的存儲空間,但查找起來需要消耗更多的時間。
.index 與 .log 對應關系如下:

上圖左半部分是索引文件,里面存儲的是一對一對的key-value,其中key是消息在數據文件(對應的log文件)中的編號,比如“1,3,6,8……”,
分別表示在log文件中的第1條消息、第3條消息、第6條消息、第8條消息……
那么為什么在index文件中這些編號不是連續的呢?
這是因為index文件中並沒有為數據文件中的每條消息都建立索引,而是采用了稀疏存儲的方式,每隔一定字節的數據建立一條索引。
這樣避免了索引文件占用過多的空間,從而可以將索引文件保留在內存中。
但缺點是沒有建立索引的Message也不能一次定位到其在數據文件的位置,從而需要做一次順序掃描,但是這次順序掃描的范圍就很小了。
value 代表的是在全局partiton中的第幾個消息。
以索引文件中元數據 3,497 為例,其中3代表在右邊log數據文件中從上到下第3個消息,
497表示該消息的物理偏移地址(位置)為497(也表示在全局partiton表示第497個消息-順序寫入特性)。
log日志目錄及組成
kafka在我們指定的log.dir目錄下,會創建一些文件夾;名字是 (主題名字-分區名) 所組成的文件夾。 在(主題名字-分區名)的目錄下,會有兩個文件存在,如下所示:
#索引文件
00000000000000000000.index
#日志內容
00000000000000000000.log
在目錄下的文件,會根據log日志的大小進行切分,.log文件的大小為1G的時候,就會進行切分文件;如下:
-rw-r--r--. 1 root root 389k 1月 17 18:03 00000000000000000000.index
-rw-r--r--. 1 root root 1.0G 1月 17 18:03 00000000000000000000.log
-rw-r--r--. 1 root root 10M 1月 17 18:03 00000000000000077894.index
-rw-r--r--. 1 root root 127M 1月 17 18:03 00000000000000077894.log
在kafka的設計中,將offset值作為了文件名的一部分。
segment文件命名規則:partion全局的第一個segment從0開始,后續每個segment文件名為上一個全局 partion的最大offset(偏移message數)。數值最大為64位long大小,20位數字字符長度,沒有數字就用 0 填充。
通過索引信息可以快速定位到message。通過index元數據全部映射到內存,可以避免segment File的IO磁盤操作;
通過索引文件稀疏存儲,可以大幅降低index文件元數據占用空間大小。
稀疏索引:為了數據創建索引,但范圍並不是為每一條創建,而是為某一個區間創建;
好處:就是可以減少索引值的數量。
不好的地方:找到索引區間之后,要得進行第二次處理。
8. message的物理結構
生產者發送到kafka的每條消息,都被kafka包裝成了一個message
message 的物理結構如下圖所示:
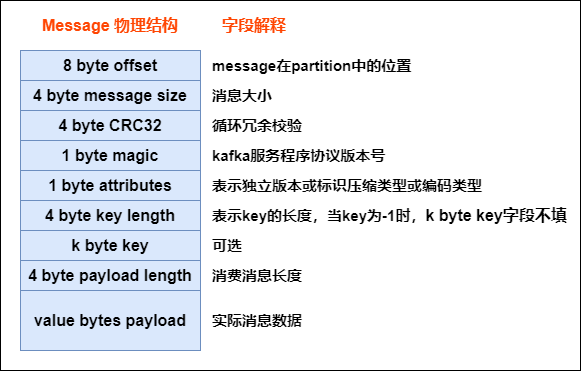
所以生產者發送給kafka的消息並不是直接存儲起來,而是經過kafka的包裝,每條消息都是上圖這個結構,只有最后一個字段才是真正生產者發送的消息數據。
四、Kafka集群操作
1. 創建topic
創建一個名字為test的主題, 有三個分區,有兩個副本:
bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 2 --partitions 3 --topic test
2. 查看主題命令
查看kafka當中存在的主題:
bin/kafka-topics.sh --list --zookeeper node01:2181,node02:2181,node03:2181
3. 生產者生產數據
模擬生產者來生產數據:
bin/kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic test
4. 消費者消費數據
執行以下命令來模擬消費者進行消費數據:
bin/kafka-console-consumer.sh --from-beginning --topic test --zookeeper node01:2181,node02:2181,node03:2181
5. 運行describe topics命令
執行以下命令運行describe查看topic的相關信息:
bin/kafka-topics.sh --describe --zookeeper node01:2181 --topic test
結果說明:
這是輸出的解釋。第一行給出了所有分區的摘要,每個附加行提供有關一個分區的信息。由於我們只有一個分 區用於此主題,因此只有一行。
“leader”是負責給定分區的所有讀取和寫入的節點。每個節點將成為隨機選擇的分區部分的領導者。(因為在kafka中 如果有多個副本的話,就會存在leader和follower的關系,表示當前這個副本為leader所在的broker是哪一個)
“replicas”是復制此分區日志的節點列表,無論它們是否為領導者,或者即使它們當前處於活動狀態。(所有副本列表0,1,2)
“isr”是“同步”復制品的集合。這是副本列表的子集,該列表當前處於活躍狀態並且已經被領導者捕獲。(可用的列表數)
6. 增加topic分區數
執行以下命令可以增加topic分區數:
bin/kafka-topics.sh --zookeeper zkhost:port --alter --topic topicName --partitions 8
7. 增加配置
動態修改kakfa的配置:
bin/kafka-topics.sh --zookeeper node01:2181 --alter --topic test --config flush.messages=1
8. 刪除配置
動態刪除kafka集群配置:
bin/kafka-topics.sh --zookeeper node01:2181 --alter --topic test --delete-config flush.messages
9. 刪除topic
目前刪除topic在默認情況下知識打上一個刪除的標記,在重新啟動kafka后才刪除。
如果需要立即刪除,則需要在
server.properties中配置:
delete.topic.enable=true
然后執行以下命令進行刪除topic:
kafka-topics.sh --zookeeper zkhost:port --delete --topic topicName
五、Kafka的JavaAPI操作
1. 生產者代碼
使用生產者,生產數據:
/**
* 訂單的生產者代碼,
*/
public class OrderProducer {
public static void main(String[] args) throws InterruptedException {
/* 1、連接集群,通過配置文件的方式
* 2、發送數據-topic:order,value
*/
Properties props = new Properties(); props.put("bootstrap.servers", "node01:9092"); props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>
(props);
for (int i = 0; i < 1000; i++) {
// 發送數據 ,需要一個producerRecord對象,最少參數 String topic, V value kafkaProducer.send(new ProducerRecord<String, String>("order", "訂單信
息!"+i));
Thread.sleep(100);
}
}
}
kafka當中的數據分區:
kafka生產者發送的消息,都是保存在broker當中,我們可以自定義分區規則,決定消息發送到哪個partition里面去進行保存
查看ProducerRecord這個類的源碼,就可以看到kafka的各種不同分區策略
kafka當中支持以下四種數據的分區方式:
//第一種分區策略,如果既沒有指定分區號,也沒有指定數據key,那么就會使用輪詢的方式將數據均勻的發送到不同的分區里面去
//ProducerRecord<String, String> producerRecord1 = new ProducerRecord<>("mypartition", "mymessage" + i);
//kafkaProducer.send(producerRecord1);
//第二種分區策略 如果沒有指定分區號,指定了數據key,通過key.hashCode % numPartitions來計算數據究竟會保存在哪一個分區里面
//注意:如果數據key,沒有變化 key.hashCode % numPartitions = 固定值 所有的數據都會寫入到某一個分區里面去
//ProducerRecord<String, String> producerRecord2 = new ProducerRecord<>("mypartition", "mykey", "mymessage" + i);
//kafkaProducer.send(producerRecord2);
//第三種分區策略:如果指定了分區號,那么就會將數據直接寫入到對應的分區里面去
// ProducerRecord<String, String> producerRecord3 = new ProducerRecord<>("mypartition", 0, "mykey", "mymessage" + i);
// kafkaProducer.send(producerRecord3);
//第四種分區策略:自定義分區策略。如果不自定義分區規則,那么會將數據使用輪詢的方式均勻的發送到各個分區里面去
kafkaProducer.send(new ProducerRecord<String, String>("mypartition","mymessage"+i));
自定義分區策略:
public class KafkaCustomPartitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object arg1, byte[] keyBytes, Object arg3, byte[] arg4, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int partitionNum = partitions.size();
Random random = new Random();
int partition = random.nextInt(partitionNum);
return partition;
}
@Override
public void close() {
}
}
主代碼中添加配置:
@Test
public void kafkaProducer() throws Exception {
//1、准備配置文件
Properties props = new Properties();
props.put("bootstrap.servers", "node01:9092,node02:9092,node03:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("partitioner.class", "cn.itcast.kafka.partitioner.KafkaCustomPartitioner");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//2、創建KafkaProducer
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(props);
for (int i=0;i<100;i++){
//3、發送數據
kafkaProducer.send(new ProducerRecord<String, String>("testpart","0","value"+i));
}
kafkaProducer.close();
}
2. 消費者代碼
消費必要條件:
消費者要從kafka Cluster進行消費數據,必要條件有以下四個:
-
地址:
bootstrap.servers=node01:9092 -
序列化:
key.serializer=org.apache.kafka.common.serialization.StringSerializer value.serializer=org.apache.kafka.common.serialization.StringSerializer -
主題(topic):需要制定具體的某個topic(order)即可。
-
消費者組:
group.id=test
1) 自動提交offset
消費完成之后,自動提交offset:
/**
* 消費訂單數據--- javaben.tojson
*/
public class OrderConsumer {
public static void main(String[] args) {
// 1\連接集群
Properties props = new Properties(); props.put("bootstrap.servers", "hadoop-01:9092"); props.put("group.id", "test");
//以下兩行代碼 ---消費者自動提交offset值
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>
(props);
// 2、發送數據 發送數據需要,訂閱下要消費的topic。 order kafkaConsumer.subscribe(Arrays.asList("order"));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(100);// jdk queue offer插入、poll獲取元素。 blockingqueue put插入原生, take獲取元素
for (ConsumerRecord<String, String> record : consumerRecords) { System.out.println("消費的數據為:" + record.value());
}
}
}
}
2) 手動提交offset
如果Consumer在獲取數據后,需要加入處理,數據完畢后才確認offset,需要程序來控制offset的確認。
關閉自動提交確認選項:props.put("enable.auto.commit", "false");
手動提交offset值:kafkaConsumer.commitSync();
完整代碼如下:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
//關閉自動提交確認選項
props.put("enable.auto.commit", "false");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("test"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
// 手動提交offset值
consumer.commitSync();
buffer.clear();
}
}
3) 消費完每個分區之后手動提交offset
上面的示例使用commitSync將所有已接收的記錄標記為已提交。在某些情況下,可能希望通過明確指定偏移量來更好地控制已提交的記錄。在下面的示例中,我們在完成處理每個分區中的記錄后提交偏移量:
try {
while(running) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) { System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() -1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} finally { consumer.close();}
注意事項:
提交的偏移量應始終是應用程序將讀取的下一條消息的偏移量。 因此,在調用commitSync(偏移量)時,應該在最后處理的消息的偏移量中添加一個。
4) 指定分區數據進行消費
-
如果進程正在維護與該分區關聯的某種本地狀態(如本地磁盤上的鍵值存儲),那么它應該只獲取它在磁盤上維護的分區的記錄。
-
如果進程本身具有高可用性,並且如果失敗則將重新啟動(可能使用YARN,Mesos或AWS工具等集群管理框 架,或作為流處理框架的一部分)。在這種情況下,Kafka不需要檢測故障並重新分配分區,因為消耗過程將在另一台機器上重新啟動。
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//consumer.subscribe(Arrays.asList("foo", "bar"));
//手動指定消費指定分區的數據---start
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1); consumer.assign(Arrays.asList(partition0, partition1));
//手動指定消費指定分區的數據---end
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
注意事項:
-
要使用此模式,只需使用要使用的分區的完整列表調用assign(Collection),而不是使用subscribe訂閱主題。
-
主題與分區訂閱只能二選一。
5) 重復消費與數據丟失
說明:
-
已經消費的數據對於kafka來說,會將消費組里面的offset值進行修改,那什么時候進行修改了?是在數據消費 完成之后,比如在控制台打印完后自動提交;
-
提交過程:是通過kafka將offset進行移動到下個message所處的offset的位置。
-
拿到數據后,存儲到hbase中或者mysql中,如果hbase或者mysql在這個時候連接不上,就會拋出異常,如果在處理數據的時候已經進行了提交,那么kafka傷的offset值已經進行了修改了,但是hbase或者mysql中沒有數據,這個時候就會出現數據丟失。
4.什么時候提交offset值?在Consumer將數據處理完成之后,再來進行offset的修改提交。默認情況下offset是 自動提交,需要修改為手動提交offset值。
- 如果在處理代碼中正常處理了,但是在提交offset請求的時候,沒有連接到kafka或者出現了故障,那么該次修 改offset的請求是失敗的,那么下次在進行讀取同一個分區中的數據時,會從已經處理掉的offset值再進行處理一 次,那么在hbase中或者mysql中就會產生兩條一樣的數據,也就是數據重復。
6) consumer消費者消費數據流程
流程描述:
Consumer連接指定的Topic partition所在leader broker,采用pull方式從kafkalogs中獲取消息。對於不同的消費模式,會將offset保存在不同的地方
官網關於high level API 以及low level API的簡介:
http://kafka.apache.org/0100/documentation.html#impl_consumer
高階API(High Level API):
kafka消費者高階API簡單;隱藏Consumer與Broker細節;相關信息保存在zookeeper中:
/* create a connection to the cluster */
ConsumerConnector connector = Consumer.create(consumerConfig);
interface ConsumerConnector {
/**
This method is used to get a list of KafkaStreams, which are iterators over
MessageAndMetadata objects from which you can obtain messages and their
associated metadata (currently only topic).
Input: a map of <topic, #streams>
Output: a map of <topic, list of message streams>
*/
public Map<String,List<KafkaStream>> createMessageStreams(Map<String,Int> topicCountMap);
/**
You can also obtain a list of KafkaStreams, that iterate over messages
from topics that match a TopicFilter. (A TopicFilter encapsulates a
whitelist or a blacklist which is a standard Java regex.)
*/
public List<KafkaStream> createMessageStreamsByFilter( TopicFilter topicFilter, int numStreams);
/* Commit the offsets of all messages consumed so far. */ public commitOffsets()
/* Shut down the connector */ public shutdown()
}
說明:大部分的操作都已經封裝好了,比如:當前消費到哪個位置下了,但是不夠靈活(工作過程推薦使用)
低級API(Low Level API):
kafka消費者低級API非常靈活;需要自己負責維護連接Controller Broker。保存offset,Consumer Partition對應關系:
class SimpleConsumer {
/* Send fetch request to a broker and get back a set of messages. */
public ByteBufferMessageSet fetch(FetchRequest request);
/* Send a list of fetch requests to a broker and get back a response set. */ public MultiFetchResponse multifetch(List<FetchRequest> fetches);
/**
Get a list of valid offsets (up to maxSize) before the given time.
The result is a list of offsets, in descending order.
@param time: time in millisecs,
if set to OffsetRequest$.MODULE$.LATEST_TIME(), get from the latest
offset available. if set to OffsetRequest$.MODULE$.EARLIEST_TIME(), get from the earliest
available. public long[] getOffsetsBefore(String topic, int partition, long time, int maxNumOffsets);
* offset
*/
說明:沒有進行包裝,所有的操作有用戶決定,如自己的保存某一個分區下的記錄,你當前消費到哪個位置。
3. kafka Streams API開發
需求:使用StreamAPI獲取test這個topic當中的數據,然后將數據全部轉為大寫,寫入到test2這個topic當中去。
第一步:創建一個topic
node01服務器使用以下命令來常見一個 topic 名稱為test2:
bin/kafka-topics.sh --create --partitions 3 --replication-factor 2 --topic test2 --zookeeper node01:2181,node02:2181,node03:2181
第二步:開發StreamAPI
public class StreamAPI {
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9092");
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
KStreamBuilder builder = new KStreamBuilder();
builder.stream("test").mapValues(line -> line.toString().toUpperCase()).to("test2");
KafkaStreams streams = new KafkaStreams(builder, props);
streams.start();
}
}
執行上述代碼,監聽獲取 test 中的數據,然后轉成大寫,將結果寫入 test2。
第三步:生產數據
node01執行以下命令,向test這個topic當中生產數據:
bin/kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic test
第四步:消費數據
node02執行一下命令消費test2這個topic當中的數據:
bin/kafka-console-consumer.sh --from-beginning --topic test2 --zookeeper node01:2181,node02:2181,node03:2181
六、Kafka中的數據不丟失機制
1. 生產者生產數據不丟失
發送消息方式
生產者發送給kafka數據,可以采用同步方式或異步方式
同步方式:
發送一批數據給kafka后,等待kafka返回結果:
- 生產者等待10s,如果broker沒有給出ack響應,就認為失敗。
- 生產者重試3次,如果還沒有響應,就報錯.
異步方式:
發送一批數據給kafka,只是提供一個回調函數:
- 先將數據保存在生產者端的buffer中。buffer大小是2萬條 。
- 滿足數據閾值或者數量閾值其中的一個條件就可以發送數據。
- 發送一批數據的大小是500條。
注:如果broker遲遲不給ack,而buffer又滿了,開發者可以設置是否直接清空buffer中的數據。
ack機制(確認機制)
生產者數據發送出去,需要服務端返回一個確認碼,即ack響應碼;ack的響應有三個狀態值0,1,-1
0:生產者只負責發送數據,不關心數據是否丟失,丟失的數據,需要再次發送
1:partition的leader收到數據,不管follow是否同步完數據,響應的狀態碼為1
-1:所有的從節點都收到數據,響應的狀態碼為-1
如果broker端一直不返回ack狀態,producer永遠不知道是否成功;producer可以設置一個超時時間10s,超過時間認為失敗。
2. broker中數據不丟失
在broker中,保證數據不丟失主要是通過副本因子(冗余),防止數據丟失。
3. 消費者消費數據不丟失
在消費者消費數據的時候,只要每個消費者記錄好offset值即可,就能保證數據不丟失。也就是需要我們自己維護偏移量(offset),可保存在 Redis 中。
文章首發於公眾號:五分鍾學大數據,深度鑽研大數據技術
七、Kafka配置文件說明
Server.properties配置文件說明:
#broker的全局唯一編號,不能重復
broker.id=0
#用來監聽鏈接的端口,producer或consumer將在此端口建立連接
port=9092
#處理網絡請求的線程數量
num.network.threads=3
#用來處理磁盤IO的線程數量
num.io.threads=8
#發送套接字的緩沖區大小
socket.send.buffer.bytes=102400
#接受套接字的緩沖區大小
socket.receive.buffer.bytes=102400
#請求套接字的緩沖區大小
socket.request.max.bytes=104857600
#kafka運行日志存放的路徑
log.dirs=/export/data/kafka/
#topic在當前broker上的分片個數
num.partitions=2
#用來恢復和清理data下數據的線程數量
num.recovery.threads.per.data.dir=1
#segment文件保留的最長時間,超時將被刪除
log.retention.hours=168
#滾動生成新的segment文件的最大時間
log.roll.hours=1
#日志文件中每個segment的大小,默認為1G
log.segment.bytes=1073741824
#周期性檢查文件大小的時間
log.retention.check.interval.ms=300000
#日志清理是否打開
log.cleaner.enable=true
#broker需要使用zookeeper保存meta數據
zookeeper.connect=zk01:2181,zk02:2181,zk03:2181
#zookeeper鏈接超時時間
zookeeper.connection.timeout.ms=6000
#partion buffer中,消息的條數達到閾值,將觸發flush到磁盤
log.flush.interval.messages=10000
#消息buffer的時間,達到閾值,將觸發flush到磁盤
log.flush.interval.ms=3000
#刪除topic需要server.properties中設置delete.topic.enable=true否則只是標記刪除
delete.topic.enable=true
#此處的host.name為本機IP(重要),如果不改,則客戶端會拋出:Producer connection to localhost:9092 unsuccessful 錯誤!
host.name=kafka01
advertised.host.name=192.168.140.128
producer生產者配置文件說明
#指定kafka節點列表,用於獲取metadata,不必全部指定
metadata.broker.list=node01:9092,node02:9092,node03:9092
# 指定分區處理類。默認kafka.producer.DefaultPartitioner,表通過key哈希到對應分區
#partitioner.class=kafka.producer.DefaultPartitioner
# 是否壓縮,默認0表示不壓縮,1表示用gzip壓縮,2表示用snappy壓縮。壓縮后消息中會有頭來指明消息壓縮類型,故在消費者端消息解壓是透明的無需指定。
compression.codec=none
# 指定序列化處理類
serializer.class=kafka.serializer.DefaultEncoder
# 如果要壓縮消息,這里指定哪些topic要壓縮消息,默認empty,表示不壓縮。
#compressed.topics=
# 設置發送數據是否需要服務端的反饋,有三個值0,1,-1
# 0: producer不會等待broker發送ack
# 1: 當leader接收到消息之后發送ack
# -1: 當所有的follower都同步消息成功后發送ack.
request.required.acks=0
# 在向producer發送ack之前,broker允許等待的最大時間 ,如果超時,broker將會向producer發送一個error ACK.意味着上一次消息因為某種原因未能成功(比如follower未能同步成功)
request.timeout.ms=10000
# 同步還是異步發送消息,默認“sync”表同步,"async"表異步。異步可以提高發送吞吐量,
也意味着消息將會在本地buffer中,並適時批量發送,但是也可能導致丟失未發送過去的消息
producer.type=sync
# 在async模式下,當message被緩存的時間超過此值后,將會批量發送給broker,默認為5000ms
# 此值和batch.num.messages協同工作.
queue.buffering.max.ms = 5000
# 在async模式下,producer端允許buffer的最大消息量
# 無論如何,producer都無法盡快的將消息發送給broker,從而導致消息在producer端大量沉積
# 此時,如果消息的條數達到閥值,將會導致producer端阻塞或者消息被拋棄,默認為10000
queue.buffering.max.messages=20000
# 如果是異步,指定每次批量發送數據量,默認為200
batch.num.messages=500
# 當消息在producer端沉積的條數達到"queue.buffering.max.meesages"后
# 阻塞一定時間后,隊列仍然沒有enqueue(producer仍然沒有發送出任何消息)
# 此時producer可以繼續阻塞或者將消息拋棄,此timeout值用於控制"阻塞"的時間
# -1: 無阻塞超時限制,消息不會被拋棄
# 0:立即清空隊列,消息被拋棄
queue.enqueue.timeout.ms=-1
# 當producer接收到error ACK,或者沒有接收到ACK時,允許消息重發的次數
# 因為broker並沒有完整的機制來避免消息重復,所以當網絡異常時(比如ACK丟失)
# 有可能導致broker接收到重復的消息,默認值為3.
message.send.max.retries=3
# producer刷新topic metada的時間間隔,producer需要知道partition leader的位置,以及當前topic的情況
# 因此producer需要一個機制來獲取最新的metadata,當producer遇到特定錯誤時,將會立即刷新
# (比如topic失效,partition丟失,leader失效等),此外也可以通過此參數來配置額外的刷新機制,默認值600000
topic.metadata.refresh.interval.ms=60000
consumer消費者配置詳細說明:
# zookeeper連接服務器地址
zookeeper.connect=zk01:2181,zk02:2181,zk03:2181
# zookeeper的session過期時間,默認5000ms,用於檢測消費者是否掛掉
zookeeper.session.timeout.ms=5000
#當消費者掛掉,其他消費者要等該指定時間才能檢查到並且觸發重新負載均衡
zookeeper.connection.timeout.ms=10000
# 指定多久消費者更新offset到zookeeper中。注意offset更新時基於time而不是每次獲得的消息。一旦在更新zookeeper發生異常並重啟,將可能拿到已拿到過的消息
zookeeper.sync.time.ms=2000
#指定消費
group.id=itcast
# 當consumer消費一定量的消息之后,將會自動向zookeeper提交offset信息
# 注意offset信息並不是每消費一次消息就向zk提交一次,而是現在本地保存(內存),並定期提交,默認為true
auto.commit.enable=true
# 自動更新時間。默認60 * 1000
auto.commit.interval.ms=1000
# 當前consumer的標識,可以設定,也可以有系統生成,主要用來跟蹤消息消費情況,便於觀察
conusmer.id=xxx
# 消費者客戶端編號,用於區分不同客戶端,默認客戶端程序自動產生
client.id=xxxx
# 最大取多少塊緩存到消費者(默認10)
queued.max.message.chunks=50
# 當有新的consumer加入到group時,將會reblance,此后將會有partitions的消費端遷移到新 的consumer上,如果一個consumer獲得了某個partition的消費權限,那么它將會向zk注冊 "Partition Owner registry"節點信息,但是有可能此時舊的consumer尚沒有釋放此節點, 此值用於控制,注冊節點的重試次數.
rebalance.max.retries=5
# 獲取消息的最大尺寸,broker不會像consumer輸出大於此值的消息chunk 每次feth將得到多條消息,此值為總大小,提升此值,將會消耗更多的consumer端內存
fetch.min.bytes=6553600
# 當消息的尺寸不足時,server阻塞的時間,如果超時,消息將立即發送給consumer
fetch.wait.max.ms=5000
socket.receive.buffer.bytes=655360
# 如果zookeeper沒有offset值或offset值超出范圍。那么就給個初始的offset。有smallest、largest、anything可選,分別表示給當前最小的offset、當前最大的offset、拋異常。默認largest
auto.offset.reset=smallest
# 指定序列化處理類
derializer.class=kafka.serializer.DefaultDecoder
八、CAP理論
1. 分布式系統當中的CAP理論
分布式系統(distributed system)正變得越來越重要,大型網站幾乎都是分布式的。
分布式系統的最大難點,就是各個節點的狀態如何同步。
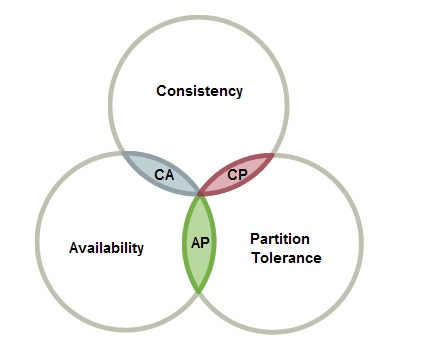
為了解決各個節點之間的狀態同步問題,在1998年,由加州大學的計算機科學家 Eric Brewer 提出分布式系統的三個指標,分別是:
-
Consistency:一致性
-
Availability:可用性
-
Partition tolerance:分區容錯性
Eric Brewer 說,這三個指標不可能同時做到。最多只能同時滿足其中兩個條件,這個結論就叫做 CAP 定理。
CAP理論是指:分布式系統中,一致性、可用性和分區容忍性最多只能同時滿足兩個。
一致性:Consistency
- 通過某個節點的寫操作結果對后面通過其它節點的讀操作可見
- 如果更新數據后,並發訪問情況下后續讀操作可立即感知該更新,稱為強一致性
- 如果允許之后部分或者全部感知不到該更新,稱為弱一致性
- 若在之后的一段時間(通常該時間不固定)后,一定可以感知到該更新,稱為最終一致性
可用性:Availability
- 任何一個沒有發生故障的節點必須在有限的時間內返回合理的結果
分區容錯性:Partition tolerance
- 部分節點宕機或者無法與其它節點通信時,各分區間還可保持分布式系統的功能
一般而言,都要求保證分區容忍性。所以在CAP理論下,更多的是需要在可用性和一致性之間做權衡。
2. Partition tolerance
先看 Partition tolerance,中文叫做"分區容錯"。
大多數分布式系統都分布在多個子網絡。每個子網絡就叫做一個區(partition)。分區容錯的意思是,區間通信可能失敗。比如,一台服務器放在中國,另一台服務器放在美國,這就是兩個區,它們之間可能無法通信。
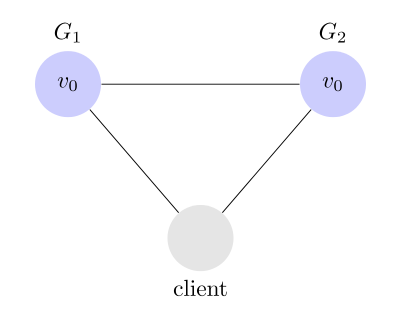
上圖中,G1 和 G2 是兩台跨區的服務器。G1 向 G2 發送一條消息,G2 可能無法收到。系統設計的時候,必須考慮到這種情況。
一般來說,分區容錯無法避免,因此可以認為 CAP 的 P 總是存在的。即永遠可能存在分區容錯這個問題
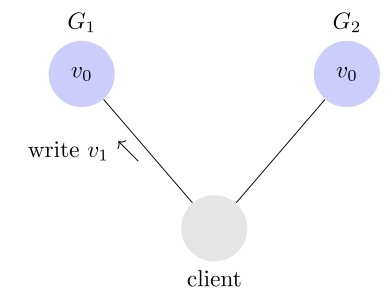
3. Consistency
Consistency 中文叫做"一致性"。意思是,寫操作之后的讀操作,必須返回該值。舉例來說,某條記錄是 v0,用戶向 G1 發起一個寫操作,將其改為 v1。
接下來,用戶的讀操作就會得到 v1。這就叫一致性。
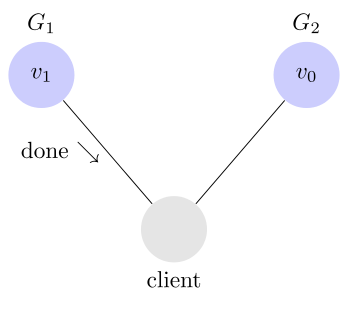
問題是,用戶有可能向 G2 發起讀操作,由於 G2 的值沒有發生變化,因此返回的是 v0。G1 和 G2 讀操作的結果不一致,這就不滿足一致性了。
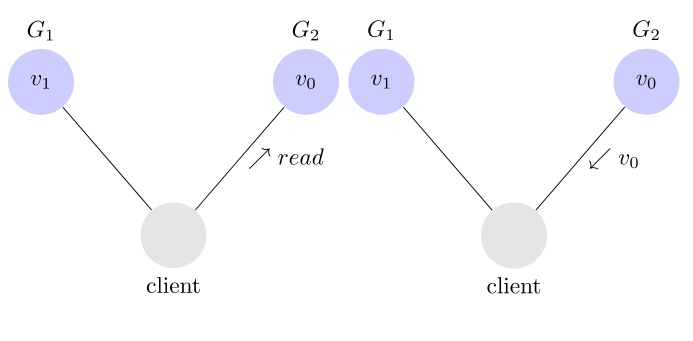
為了讓 G2 也能變為 v1,就要在 G1 寫操作的時候,讓 G1 向 G2 發送一條消息,要求 G2 也改成 v1。
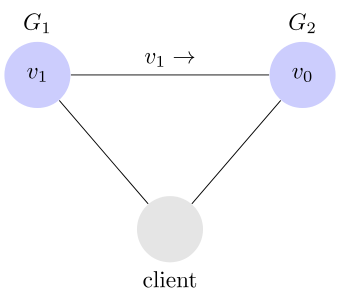
這樣的話,用戶向 G2 發起讀操作,也能得到 v1。
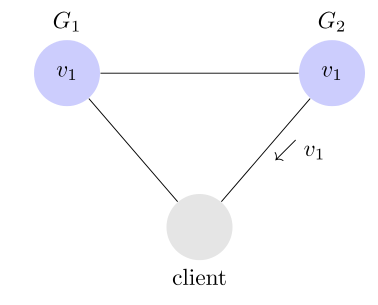
4. Availability
Availability 中文叫做"可用性",意思是只要收到用戶的請求,服務器就必須給出回應。
用戶可以選擇向 G1 或 G2 發起讀操作。不管是哪台服務器,只要收到請求,就必須告訴用戶,到底是 v0 還是 v1,否則就不滿足可用性。
九、Kafka中的CAP機制
kafka是一個分布式的消息隊列系統,既然是一個分布式的系統,那么就一定滿足CAP定律,那么在kafka當中是如何遵循CAP定律的呢?kafka滿足CAP定律當中的哪兩個呢?
kafka滿足的是CAP定律當中的CA,其中Partition tolerance通過的是一定的機制盡量的保證分區容錯性。
其中C表示的是數據一致性。A表示數據可用性。
kafka首先將數據寫入到不同的分區里面去,每個分區又可能有好多個副本,數據首先寫入到leader分區里面去,讀寫的操作都是與leader分區進行通信,保證了數據的一致性原則,也就是滿足了Consistency原則。然后kafka通過分區副本機制,來保證了kafka當中數據的可用性。但是也存在另外一個問題,就是副本分區當中的數據與leader當中的數據存在差別的問題如何解決,這個就是Partition tolerance的問題。
kafka為了解決Partition tolerance的問題,使用了ISR的同步策略,來盡最大可能減少Partition tolerance的問題。
每個leader會維護一個ISR(a set of in-sync replicas,基本同步)列表。
ISR列表主要的作用就是決定哪些副本分區是可用的,也就是說可以將leader分區里面的數據同步到副本分區里面去,決定一個副本分區是否可用的條件有兩個:
-
replica.lag.time.max.ms=10000 副本分區與主分區心跳時間延遲
-
replica.lag.max.messages=4000 副本分區與主分區消息同步最大差
produce 請求被認為完成時的確認值:request.required.acks=0。
- ack=0:producer不等待broker同步完成的確認,繼續發送下一條(批)信息。
- ack=1(默認):producer要等待leader成功收到數據並得到確認,才發送下一條message。
- ack=-1:producer得到follwer確認,才發送下一條數據。
十、Kafka監控及運維
在開發工作中,消費在Kafka集群中消息,數據變化是我們關注的問題,當業務前提不復雜時,我們可以使用Kafka 命令提供帶有Zookeeper客戶端工具的工具,可以輕松完成我們的工作。隨着業務的復雜性,增加Group和 Topic,那么我們使用Kafka提供命令工具,已經感到無能為力,那么Kafka監控系統目前尤為重要,我們需要觀察 消費者應用的細節。
1. kafka-eagle概述
為了簡化開發者和服務工程師維護Kafka集群的工作有一個監控管理工具,叫做 Kafka-eagle。這個管理工具可以很容易地發現分布在集群中的哪些topic分布不均勻,或者是分區在整個集群分布不均勻的的情況。它支持管理多個集群、選擇副本、副本重新分配以及創建Topic。同時,這個管理工具也是一個非常好的可以快速瀏覽這個集群的工具,
2. 環境和安裝
1. 環境要求
需要安裝jdk,啟動zk以及kafka的服務
2. 安裝步驟
- 下載源碼包
kafka-eagle官網:
http://download.kafka-eagle.org/
我們可以從官網上面直接下載最細的安裝包即可kafka-eagle-bin-1.3.2.tar.gz這個版本即可
代碼托管地址:
https://github.com/smartloli/kafka-eagle/releases
- 解壓
這里我們選擇將kafak-eagle安裝在第三台。
直接將kafka-eagle安裝包上傳到node03服務器的/export/softwares路徑下,然后進行解壓
node03服務器執行一下命令進行解壓。
- 准備數據庫
kafka-eagle需要使用一個數據庫來保存一些元數據信息,我們這里直接使用msyql數據庫來保存即可,在node03服務器執行以下命令創建一個mysql數據庫即可。
進入mysql客戶端:
create database eagle;
- 修改kafak-eagle配置文件
執行以下命令修改kafak-eagle配置文件:
vim system-config.properties
修改為如下:
kafka.eagle.zk.cluster.alias=cluster1,cluster2
cluster1.zk.list=node01:2181,node02:2181,node03:2181
cluster2.zk.list=node01:2181,node02:2181,node03:2181
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://node03:3306/eagle
kafka.eagle.username=root
kafka.eagle.password=123456
- 配置環境變量
kafka-eagle必須配置環境變量,node03服務器執行以下命令來進行配置環境變量: vim /etc/profile:
export KE_HOME=/opt//kafka-eagle-bin-1.3.2/kafka-eagle-web-1.3.2
export PATH=:$KE_HOME/bin:$PATH
修改立即生效,執行: source /etc/profile
- 啟動kafka-eagle
執行以下界面啟動kafka-eagle:
cd kafka-eagle-web-1.3.2/bin
chmod u+x ke.sh
./ke.sh start
- 主界面
訪問kafka-eagle
http://node03:8048/ke/account/signin?/ke/
用戶名:admin
密碼:123456
十一、Kafka大廠面試題
1. 為什么要使用 kafka?
-
緩沖和削峰:上游數據時有突發流量,下游可能扛不住,或者下游沒有足夠多的機器來保證冗余,kafka在中間可以起到一個緩沖的作用,把消息暫存在kafka中,下游服務就可以按照自己的節奏進行慢慢處理。
-
解耦和擴展性:項目開始的時候,並不能確定具體需求。消息隊列可以作為一個接口層,解耦重要的業務流程。只需要遵守約定,針對數據編程即可獲取擴展能力。
-
冗余:可以采用一對多的方式,一個生產者發布消息,可以被多個訂閱topic的服務消費到,供多個毫無關聯的業務使用。
-
健壯性:消息隊列可以堆積請求,所以消費端業務即使短時間死掉,也不會影響主要業務的正常進行。
-
異步通信:很多時候,用戶不想也不需要立即處理消息。消息隊列提供了異步處理機制,允許用戶把一個消息放入隊列,但並不立即處理它。想向隊列中放入多少消息就放多少,然后在需要的時候再去處理它們。
2. Kafka消費過的消息如何再消費?
kafka消費消息的offset是定義在zookeeper中的, 如果想重復消費kafka的消息,可以在redis中自己記錄offset的checkpoint點(n個),當想重復消費消息時,通過讀取redis中的checkpoint點進行zookeeper的offset重設,這樣就可以達到重復消費消息的目的了
3. kafka的數據是放在磁盤上還是內存上,為什么速度會快?
kafka使用的是磁盤存儲。
速度快是因為:
- 順序寫入:因為硬盤是機械結構,每次讀寫都會尋址->寫入,其中尋址是一個“機械動作”,它是耗時的。所以硬盤 “討厭”隨機I/O, 喜歡順序I/O。為了提高讀寫硬盤的速度,Kafka就是使用順序I/O。
- Memory Mapped Files(內存映射文件):64位操作系統中一般可以表示20G的數據文件,它的工作原理是直接利用操作系統的Page來實現文件到物理內存的直接映射。完成映射之后你對物理內存的操作會被同步到硬盤上。
- Kafka高效文件存儲設計: Kafka把topic中一個parition大文件分成多個小文件段,通過多個小文件段,就容易定期清除或刪除已經消費完文件,減少磁盤占用。通過索引信息可以快速定位
message和確定response的 大 小。通過index元數據全部映射到memory(內存映射文件),
可以避免segment file的IO磁盤操作。通過索引文件稀疏存儲,可以大幅降低index文件元數據占用空間大小。
注:
- Kafka解決查詢效率的手段之一是將數據文件分段,比如有100條Message,它們的offset是從0到99。假設將數據文件分成5段,第一段為0-19,第二段為20-39,以此類推,每段放在一個單獨的數據文件里面,數據文件以該段中 小的offset命名。這樣在查找指定offset的
Message的時候,用二分查找就可以定位到該Message在哪個段中。 - 為數據文件建 索引數據文件分段 使得可以在一個較小的數據文件中查找對應offset的Message 了,但是這依然需要順序掃描才能找到對應offset的Message。
為了進一步提高查找的效率,Kafka為每個分段后的數據文件建立了索引文件,文件名與數據文件的名字是一樣的,只是文件擴展名為.index。
4. Kafka數據怎么保障不丟失?
分三個點說,一個是生產者端,一個消費者端,一個broker端。
- 生產者數據的不丟失
kafka的ack機制:在kafka發送數據的時候,每次發送消息都會有一個確認反饋機制,確保消息正常的能夠被收到,其中狀態有0,1,-1。
如果是同步模式:
ack設置為0,風險很大,一般不建議設置為0。即使設置為1,也會隨着leader宕機丟失數據。所以如果要嚴格保證生產端數據不丟失,可設置為-1。
如果是異步模式:
也會考慮ack的狀態,除此之外,異步模式下的有個buffer,通過buffer來進行控制數據的發送,有兩個值來進行控制,時間閾值與消息的數量閾值,如果buffer滿了數據還沒有發送出去,有個選項是配置是否立即清空buffer。可以設置為-1,永久阻塞,也就數據不再生產。異步模式下,即使設置為-1。也可能因為程序員的不科學操作,操作數據丟失,比如kill -9,但這是特別的例外情況。
注:
ack=0:producer不等待broker同步完成的確認,繼續發送下一條(批)信息。
ack=1(默認):producer要等待leader成功收到數據並得到確認,才發送下一條message。
ack=-1:producer得到follwer確認,才發送下一條數據。
- 消費者數據的不丟失
通過offset commit 來保證數據的不丟失,kafka自己記錄了每次消費的offset數值,下次繼續消費的時候,會接着上次的offset進行消費。
而offset的信息在kafka0.8版本之前保存在zookeeper中,在0.8版本之后保存到topic中,即使消費者在運行過程中掛掉了,再次啟動的時候會找到offset的值,找到之前消費消息的位置,接着消費,由於 offset 的信息寫入的時候並不是每條消息消費完成后都寫入的,所以這種情況有可能會造成重復消費,但是不會丟失消息。
唯一例外的情況是,我們在程序中給原本做不同功能的兩個consumer組設置
KafkaSpoutConfig.bulider.setGroupid的時候設置成了一樣的groupid,這種情況會導致這兩個組共享同一份數據,就會產生組A消費partition1,partition2中的消息,組B消費partition3的消息,這樣每個組消費的消息都會丟失,都是不完整的。 為了保證每個組都獨享一份消息數據,groupid一定不要重復才行。
- kafka集群中的broker的數據不丟失
每個broker中的partition我們一般都會設置有replication(副本)的個數,生產者寫入的時候首先根據分發策略(有partition按partition,有key按key,都沒有輪詢)寫入到leader中,follower(副本)再跟leader同步數據,這樣有了備份,也可以保證消息數據的不丟失。
5. 采集數據為什么選擇kafka?
采集層 主要可以使用Flume, Kafka等技術。
Flume:Flume 是管道流方式,提供了很多的默認實現,讓用戶通過參數部署,及擴展API.
Kafka:Kafka是一個可持久化的分布式的消息隊列。 Kafka 是一個非常通用的系統。你可以有許多生產者和很多的消費者共享多個主題Topics。
相比之下,Flume是一個專用工具被設計為旨在往HDFS,HBase發送數據。它對HDFS有特殊的優化,並且集成了Hadoop的安全特性。
所以,Cloudera 建議如果數據被多個系統消費的話,使用kafka;如果數據被設計給Hadoop使用,使用Flume。
6. kafka 重啟是否會導致數據丟失?
- kafka是將數據寫到磁盤的,一般數據不會丟失。
- 但是在重啟kafka過程中,如果有消費者消費消息,那么kafka如果來不及提交offset,可能會造成數據的不准確(丟失或者重復消費)。
7. kafka 宕機了如何解決?
- 先考慮業務是否受到影響
kafka 宕機了,首先我們考慮的問題應該是所提供的服務是否因為宕機的機器而受到影響,如果服務提供沒問題,如果實現做好了集群的容災機制,那么這塊就不用擔心了。
- 節點排錯與恢復
想要恢復集群的節點,主要的步驟就是通過日志分析來查看節點宕機的原因,從而解決,重新恢復節點。
8. 為什么Kafka不支持讀寫分離?
在 Kafka 中,生產者寫入消息、消費者讀取消息的操作都是與 leader 副本進行交互的,從 而實現的是一種主寫主讀的生產消費模型。
Kafka 並不支持主寫從讀,因為主寫從讀有 2 個很明顯的缺點:
-
數據一致性問題:數據從主節點轉到從節點必然會有一個延時的時間窗口,這個時間 窗口會導致主從節點之間的數據不一致。某一時刻,在主節點和從節點中 A 數據的值都為 X, 之后將主節點中 A 的值修改為 Y,那么在這個變更通知到從節點之前,應用讀取從節點中的 A 數據的值並不為最新的 Y,由此便產生了數據不一致的問題。
-
延時問題:類似 Redis 這種組件,數據從寫入主節點到同步至從節點中的過程需要經歷 網絡→主節點內存→網絡→從節點內存 這幾個階段,整個過程會耗費一定的時間。而在 Kafka 中,主從同步會比 Redis 更加耗時,它需要經歷 網絡→主節點內存→主節點磁盤→網絡→從節 點內存→從節點磁盤 這幾個階段。對延時敏感的應用而言,主寫從讀的功能並不太適用。
而kafka的主寫主讀的優點就很多了:
- 可以簡化代碼的實現邏輯,減少出錯的可能;
- 將負載粒度細化均攤,與主寫從讀相比,不僅負載效能更好,而且對用戶可控;
- 沒有延時的影響;
- 在副本穩定的情況下,不會出現數據不一致的情況。
9. kafka數據分區和消費者的關系?
每個分區只能由同一個消費組內的一個消費者(consumer)來消費,可以由不同的消費組的消費者來消費,同組的消費者則起到並發的效果。
10. kafka的數據offset讀取流程
-
連接ZK集群,從ZK中拿到對應topic的partition信息和partition的Leader的相關信息
-
連接到對應Leader對應的broker
-
consumer將⾃自⼰己保存的offset發送給Leader
-
Leader根據offset等信息定位到segment(索引⽂文件和⽇日志⽂文件)
-
根據索引⽂文件中的內容,定位到⽇日志⽂文件中該偏移量量對應的開始位置讀取相應⻓長度的數據並返回給consumer
11. kafka內部如何保證順序,結合外部組件如何保證消費者的順序?
kafka只能保證partition內是有序的,但是partition間的有序是沒辦法的。愛奇藝的搜索架構,是從業務上把需要有序的打到同⼀個partition。
12. Kafka消息數據積壓,Kafka消費能力不足怎么處理?
-
如果是Kafka消費能力不足,則可以考慮增加Topic的分區數,並且同時提升消費組的消費者數量,消費者數=分區數。(兩者缺一不可)
-
如果是下游的數據處理不及時:提高每批次拉取的數量。批次拉取數據過少(拉取數據/處理時間<生產速度),使處理的數據小於生產的數據,也會造成數據積壓。
13. Kafka單條日志傳輸大小
kafka對於消息體的大小默認為單條最大值是1M但是在我們應用場景中, 常常會出現一條消息大於1M,如果不對kafka進行配置。則會出現生產者無法將消息推送到kafka或消費者無法去消費kafka里面的數據, 這時我們就要對kafka進行以下配置:server.properties
replica.fetch.max.bytes: 1048576 broker可復制的消息的最大字節數, 默認為1M
message.max.bytes: 1000012 kafka 會接收單個消息size的最大限制, 默認為1M左右
注意:message.max.bytes必須小於等於replica.fetch.max.bytes,否則就會導致replica之間數據同步失敗。