Hadoop 涉及的知識點如下圖所示,本文將逐一講解:
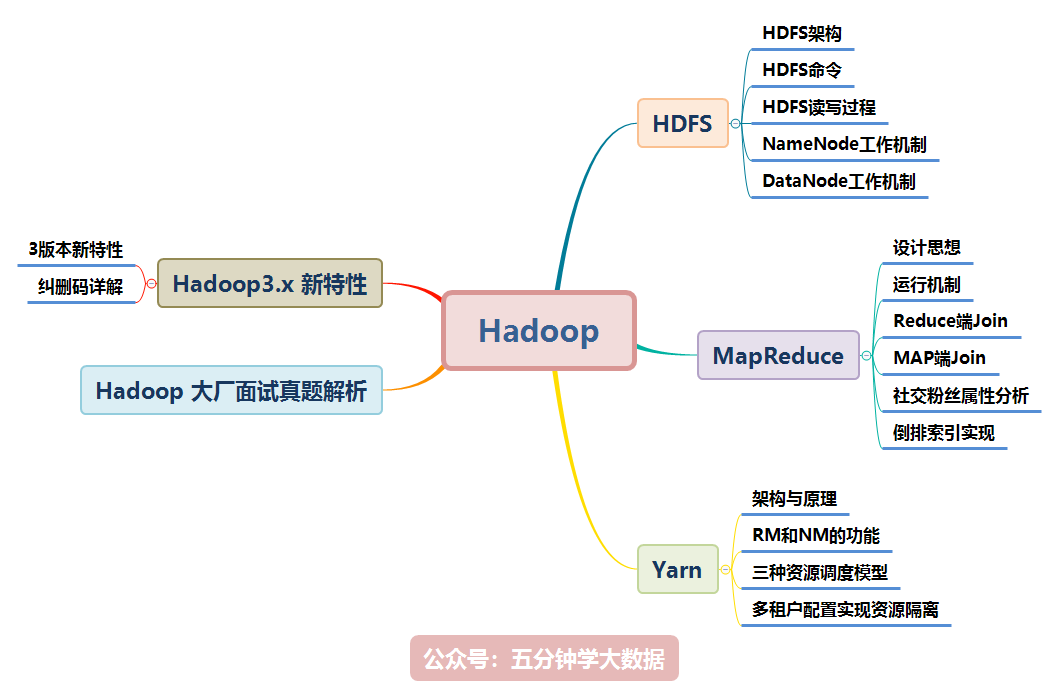
本文檔參考了關於 Hadoop 的官網及其他眾多資料整理而成,為了整潔的排版及舒適的閱讀,對於模糊不清晰的圖片及黑白圖片進行重新繪制成了高清彩圖。
目前企業應用較多的是Hadoop2.x,所以本文是以Hadoop2.x為主,對於Hadoop3.x新增的內容會進行說明!
二、MapReduce
1. MapReduce 介紹
MapReduce思想在生活中處處可見。或多或少都曾接觸過這種思想。MapReduce的思想核心是“分而治之”,適用於大量復雜的任務處理場景(大規模數據處理場景)。即使是發布過論文實現分布式計算的谷歌也只是實現了這種思想,而不是自己原創。
- Map負責“分”,即把復雜的任務分解為若干個“簡單的任務”來並行處理。可以進行拆分的前提是這些小任務可以並行計算,彼此間幾乎沒有依賴關系。
- Reduce負責“合”,即對map階段的結果進行全局匯總。
- MapReduce運行在yarn集群
- ResourceManager
- NodeManager
這兩個階段合起來正是MapReduce思想的體現。
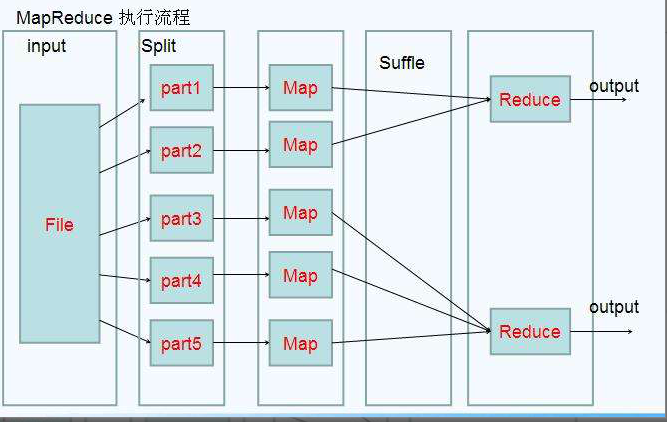
還有一個比較形象的語言解釋MapReduce:
我們要數圖書館中的所有書。你數1號書架,我數2號書架。這就是“Map”。我們人越多,數書就更快。
現在我們到一起,把所有人的統計數加在一起。這就是“Reduce”。
1.1 MapReduce 設計構思
MapReduce是一個分布式運算程序的編程框架,核心功能是將用戶編寫的業務邏輯代碼和自帶默認組件整合成一個完整的分布式運算程序,並發運行在Hadoop集群上。
既然是做計算的框架,那么表現形式就是有個輸入(input),MapReduce操作這個輸入(input),通過本身定義好的計算模型,得到一個輸出(output)。
對許多開發者來說,自己完完全全實現一個並行計算程序難度太大,而MapReduce就是一種簡化並行計算的編程模型,降低了開發並行應用的入門門檻。
Hadoop MapReduce構思體現在如下的三個方面:
- 如何對付大數據處理:分而治之
對相互間不具有計算依賴關系的大數據,實現並行最自然的辦法就是采取分而治之的策略。並行計算的第一個重要問題是如何划分計算任務或者計算數據以便對划分的子任務或數據塊同時進行計算。不可分拆的計算任務或相互間有依賴關系的數據無法進行並行計算!
- 構建抽象模型:Map和Reduce
MapReduce借鑒了函數式語言中的思想,用Map和Reduce兩個函數提供了高層的並行編程抽象模型。
Map: 對一組數據元素進行某種重復式的處理;
Reduce: 對Map的中間結果進行某種進一步的結果整理。
MapReduce中定義了如下的Map和Reduce兩個抽象的編程接口,由用戶去編程實現:
map: (k1; v1) → [(k2; v2)]
reduce: (k2; [v2]) → [(k3; v3)]
Map和Reduce為程序員提供了一個清晰的操作接口抽象描述。通過以上兩個編程接口,大家可以看出MapReduce處理的數據類型是<key,value>鍵值對。
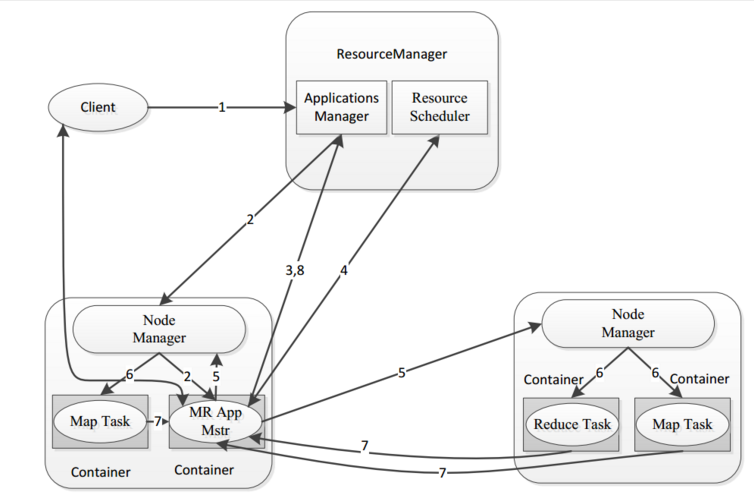
- MapReduce框架結構
一個完整的mapreduce程序在分布式運行時有三類實例進程:
- MR AppMaster:負責整個程序的過程調度及狀態協調;
- MapTask:負責map階段的整個數據處理流程;
- ReduceTask:負責reduce階段的整個數據處理流程。
2. MapReduce 編程規范
MapReduce 的開發一共有八個步驟, 其中 Map 階段分為 2 個步驟,Shuffle 階段 4 個步驟,Reduce 階段分為 2 個步驟
- Map 階段 2 個步驟:
- 1.1 設置 InputFormat 類, 將數據切分為 Key-Value(K1和V1) 對, 輸入到第二步
- 1.2 自定義 Map 邏輯, 將第一步的結果轉換成另外的 Key-Value(K2和V2) 對, 輸出結果
- Shuffle 階段 4 個步驟:
- 2.1 對輸出的 Key-Value 對進行分區
- 2.2 對不同分區的數據按照相同的 Key 排序
- 2.3 (可選) 對分組過的數據初步規約, 降低數據的網絡拷貝
- 2.4 對數據進行分組, 相同 Key 的 Value 放入一個集合中
- Reduce 階段 2 個步驟:
- 3.1 對多個 Map 任務的結果進行排序以及合並, 編寫 Reduce 函數實現自己的邏輯, 對輸入的 Key-Value 進行處理, 轉為新的 Key-Value(K3和V3)輸出
- 3.2 設置 OutputFormat 處理並保存 Reduce 輸出的 Key-Value 數據
3. Mapper以及Reducer抽象類介紹
為了開發我們的MapReduce程序,一共可以分為以上八個步驟,其中每個步驟都是一個class類,我們通過job對象將我們的程序組裝成一個任務提交即可。為了簡化我們的MapReduce程序的開發,每一個步驟的class類,都有一個既定的父類,讓我們直接繼承即可,因此可以大大簡化我們的MapReduce程序的開發難度,也可以讓我們快速的實現功能開發。
MapReduce編程當中,其中最重要的兩個步驟就是我們的Mapper類和Reducer類
- Mapper抽象類的基本介紹
在hadoop2.x當中Mapper類是一個抽象類,我們只需要覆寫一個java類,繼承自Mapper類即可,然后重寫里面的一些方法,就可以實現我們特定的功能,接下來我們來介紹一下Mapper類當中比較重要的四個方法
-
setup方法:
我們Mapper類當中的初始化方法,我們一些對象的初始化工作都可以放到這個方法里面來實現 -
map方法:
讀取的每一行數據,都會來調用一次map方法,這個方法也是我們最重要的方法,可以通過這個方法來實現我們每一條數據的處理 -
cleanup方法:
在我們整個maptask執行完成之后,會馬上調用cleanup方法,這個方法主要是用於做我們的一些清理工作,例如連接的斷開,資源的關閉等等 -
run方法:
如果我們需要更精細的控制我們的整個MapTask的執行,那么我們可以覆寫這個方法,實現對我們所有的MapTask更精確的操作控制
- Reducer抽象類基本介紹
同樣的道理,在我們的hadoop2.x當中,reducer類也是一個抽象類,抽象類允許我們可以繼承這個抽象類之后,重新覆寫抽象類當中的方法,實現我們的邏輯的自定義控制。接下來我們也來介紹一下Reducer抽象類當中的四個抽象方法
-
setup方法:
在我們的ReduceTask初始化之后馬上調用,我們的一些對象的初始化工作,都可以在這個類當中實現 -
reduce方法:
所有從MapTask發送過來的數據,都會調用reduce方法,這個方法也是我們reduce當中最重要的方法,可以通過這個方法實現我們的數據的處理 -
cleanup方法:
在我們整個ReduceTask執行完成之后,會馬上調用cleanup方法,這個方法主要就是在我們reduce階段處理做我們一些清理工作,例如連接的斷開,資源的關閉等等 -
run方法:
如果我們需要更精細的控制我們的整個ReduceTask的執行,那么我們可以覆寫這個方法,實現對我們所有的ReduceTask更精確的操作控制
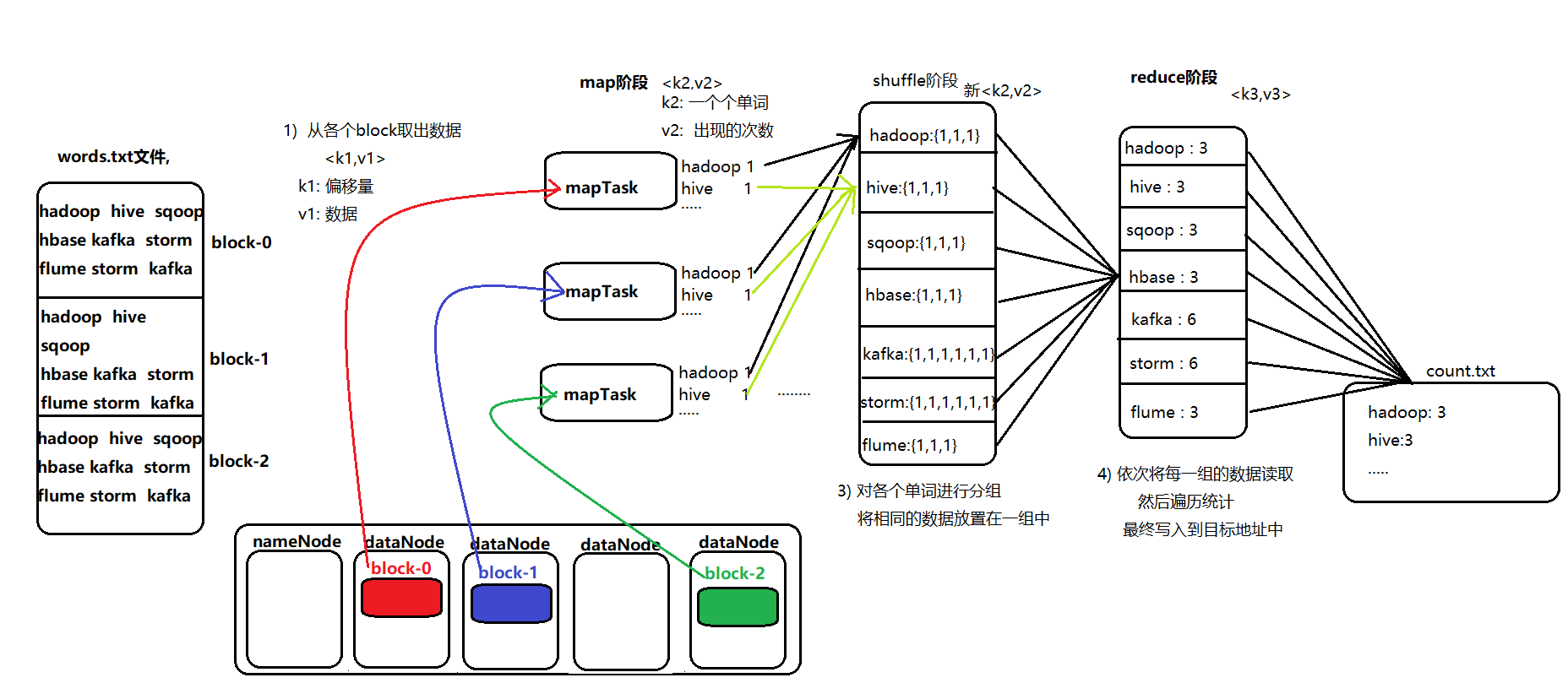
4. WordCount示例編寫
需求:在一堆給定的文本文件中統計輸出每一個單詞出現的總次數
node01服務器執行以下命令,准備數,數據格式准備如下:
cd /export/servers
vim wordcount.txt
#添加以下內容:
hello hello
world world
hadoop hadoop
hello world
hello flume
hadoop hive
hive kafka
flume storm
hive oozie
將數據文件上傳到hdfs上面去
hdfs dfs -mkdir /wordcount/
hdfs dfs -put wordcount.txt /wordcount/
- 定義一個mapper類
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// mapper程序: 需要繼承 mapper類, 需要傳入 四個類型:
/* 在hadoop中, 對java的類型都進行包裝, 以提高傳輸的效率 writable
keyin : k1 Long ---- LongWritable
valin : v1 String ------ Text
keyout : k2 String ------- Text
valout : v2 Long -------LongWritable
*/
public class MapTask extends Mapper<LongWritable,Text,Text,LongWritable> {
/**
*
* @param key : k1
* @param value v1
* @param context 上下文對象 承上啟下功能
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1. 獲取 v1 中數據
String val = value.toString();
//2. 切割數據
String[] words = val.split(" ");
Text text = new Text();
LongWritable longWritable = new LongWritable(1);
//3. 遍歷循環, 發給 reduce
for (String word : words) {
text.set(word);
context.write(text,longWritable);
}
}
}
- 定義一個reducer類
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN : k2 -----Text
* VALUEIN : v2 ------LongWritable
* KEYOUT : k3 ------ Text
* VALUEOUT : v3 ------ LongWritable
*/
public class ReducerTask extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//1. 遍歷 values 獲取每一個值
long v3 = 0;
for (LongWritable longWritable : values) {
v3 += longWritable.get(); //1
}
//2. 輸出
context.write(key,new LongWritable(v3));
}
}
- 定義一個主類,用來描述job並提交job
import com.sun.org.apache.bcel.internal.generic.NEW;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.nativeio.NativeIO;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
// 任務的執行入口: 將八步組合在一起
public class JobMain extends Configured implements Tool {
// 在run方法中編寫組裝八步
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), "JobMain");
//如果提交到集群操作. 需要添加一步 : 指定入口類
job.setJarByClass(JobMain.class);
//1. 封裝第一步: 讀取數據
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("hdfs://node01:8020/wordcount.txt"));
//2. 封裝第二步: 自定義 map程序
job.setMapperClass(MapTask.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//3. 第三步 第四步 第五步 第六步 省略
//4. 第七步: 自定義reduce程序
job.setReducerClass(ReducerTask.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//5) 第八步 : 輸出路徑是一個目錄, 而且這個目錄必須不存在的
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("hdfs://node01:8020/output"));
//6) 提交任務:
boolean flag = job.waitForCompletion(true); // 成功 true 不成功 false
return flag ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
JobMain jobMain = new JobMain();
int i = ToolRunner.run(configuration, jobMain, args); //返回值 退出碼
System.exit(i); // 退出程序 0 表示正常 其他值表示有異常 1
}
}
提醒:代碼開發完成之后,就可以打成jar包放到服務器上面去運行了,實際工作當中,都是將代碼打成jar包,開發main方法作為程序的入口,然后放到集群上面去運行
5. MapReduce程序運行模式
- 本地運行模式
- mapreduce程序是被提交給LocalJobRunner在本地以單進程的形式運行
- 而處理的數據及輸出結果可以在本地文件系統,也可以在hdfs上
- 怎樣實現本地運行?寫一個程序,不要帶集群的配置文件本質是程序的conf中是否有
mapreduce.framework.name=local以及yarn.resourcemanager.hostname=local參數 - 本地模式非常便於進行業務邏輯的debug,只要在idea中打斷點即可
【本地模式運行代碼設置】
configuration.set("mapreduce.framework.name","local");
configuration.set("yarn.resourcemanager.hostname","local");
-----------以上兩個是不需要修改的,如果要在本地目錄測試, 可有修改hdfs的路徑-----------------
TextInputFormat.addInputPath(job,new Path("file:///D:\\wordcount\\input"));
TextOutputFormat.setOutputPath(job,new Path("file:///D:\\wordcount\\output"));
- 集群運行模式
-
將mapreduce程序提交給yarn集群,分發到很多的節點上並發執行
-
處理的數據和輸出結果應該位於hdfs文件系統
-
提交集群的實現步驟:
將程序打成JAR包,然后在集群的任意一個節點上用hadoop命令啟動
yarn jar hadoop_hdfs_operate-1.0-SNAPSHOT.jar cn.itcast.hdfs.demo1.JobMain
6. MapReduce的運行機制詳解
6.1 MapTask 工作機制
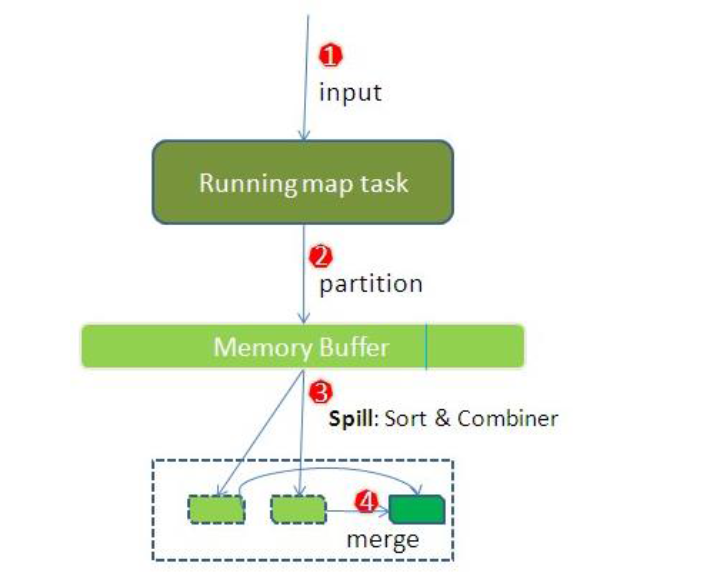
整個Map階段流程大體如上圖所示。
簡單概述:inputFile通過split被邏輯切分為多個split文件,通過Record按行讀取內容給map(用戶自己實現的)進行處理,數據被map處理結束之后交給OutputCollector收集器,對其結果key進行分區(默認使用hash分區),然后寫入buffer,每個map task都有一個內存緩沖區,存儲着map的輸出結果,當緩沖區快滿的時候需要將緩沖區的數據以一個臨時文件的方式存放到磁盤,當整個map task結束后再對磁盤中這個map task產生的所有臨時文件做合並,生成最終的正式輸出文件,然后等待reduce task來拉數據
詳細步驟
- 讀取數據組件 InputFormat (默認 TextInputFormat) 會通過
getSplits方法對輸入目錄中文件進行邏輯切片規划得到block, 有多少個block就對應啟動多少個MapTask - 將輸入文件切分為
block之后, 由RecordReader對象 (默認是LineRecordReader) 進行讀取, 以\n作為分隔符, 讀取一行數據, 返回<key,value>. Key 表示每行首字符偏移值, Value 表示這一行文本內容 - 讀取
block返回<key,value>, 進入用戶自己繼承的 Mapper 類中,執行用戶重寫的 map 函數, RecordReader 讀取一行這里調用一次 - Mapper 邏輯結束之后, 將 Mapper 的每條結果通過
context.write進行collect數據收集. 在 collect 中, 會先對其進行分區處理,默認使用 HashPartitioner
MapReduce 提供 Partitioner 接口, 它的作用就是根據 Key 或 Value 及 Reducer 的數量來決定當前的這對輸出數據最終應該交由哪個 Reduce task 處理, 默認對 Key Hash 后再以 Reducer 數量取模. 默認的取模方式只是為了平均 Reducer 的處理能力, 如果用戶自己對 Partitioner 有需求, 可以訂制並設置到 Job 上
- 接下來, 會將數據寫入內存, 內存中這片區域叫做環形緩沖區, 緩沖區的作用是批量收集 Mapper 結果, 減少磁盤 IO 的影響. 我們的 Key/Value 對以及 Partition 的結果都會被寫入緩沖區. 當然, 寫入之前,Key 與 Value 值都會被序列化成字節數組
環形緩沖區其實是一個數組, 數組中存放着 Key, Value 的序列化數據和 Key, Value 的元數據信息, 包括 Partition, Key 的起始位置, Value 的起始位置以及 Value 的長度. 環形結構是一個抽象概念。
緩沖區是有大小限制, 默認是 100MB. 當 Mapper 的輸出結果很多時, 就可能會撐爆內存, 所以需要在一定條件下將緩沖區中的數據臨時寫入磁盤, 然后重新利用這塊緩沖區. 這個從內存往磁盤寫數據的過程被稱為 Spill, 中文可譯為溢寫. 這個溢寫是由單獨線程來完成, 不影響往緩沖區寫 Mapper 結果的線程. 溢寫線程啟動時不應該阻止 Mapper 的結果輸出, 所以整個緩沖區有個溢寫的比例 spill.percent. 這個比例默認是 0.8, 也就是當緩沖區的數據已經達到閾值 buffer size * spill percent = 100MB * 0.8 = 80MB, 溢寫線程啟動, 鎖定這 80MB 的內存, 執行溢寫過程. Mapper 的輸出結果還可以往剩下的 20MB 內存中寫, 互不影響
- 當溢寫線程啟動后, 需要對這 80MB 空間內的 Key 做排序 (Sort). 排序是 MapReduce 模型默認的行為, 這里的排序也是對序列化的字節做的排序
如果 Job 設置過 Combiner, 那么現在就是使用 Combiner 的時候了. 將有相同 Key 的 Key/Value 對的 Value 合並在起來, 減少溢寫到磁盤的數據量. Combiner 會優化 MapReduce 的中間結果, 所以它在整個模型中會多次使用
\
那哪些場景才能使用 Combiner 呢? 從這里分析, Combiner 的輸出是 Reducer 的輸入, Combiner 絕不能改變最終的計算結果. Combiner 只應該用於那種 Reduce 的輸入 Key/Value 與輸出 Key/Value 類型完全一致, 且不影響最終結果的場景. 比如累加, 最大值等. Combiner 的使用一定得慎重, 如果用好, 它對 Job 執行效率有幫助, 反之會影響 Reducer 的最終結果
- 合並溢寫文件, 每次溢寫會在磁盤上生成一個臨時文件 (寫之前判斷是否有 Combiner), 如果 Mapper 的輸出結果真的很大, 有多次這樣的溢寫發生, 磁盤上相應的就會有多個臨時文件存在. 當整個數據處理結束之后開始對磁盤中的臨時文件進行 Merge 合並, 因為最終的文件只有一個, 寫入磁盤, 並且為這個文件提供了一個索引文件, 以記錄每個reduce對應數據的偏移量
【mapTask的一些基礎設置配置】
| 配置 | 默認值 | 解釋 |
|---|---|---|
mapreduce.task.io.sort.mb |
100 | 設置環型緩沖區的內存值大小 |
mapreduce.map.sort.spill.percent |
0.8 | 設置溢寫的比例 |
mapreduce.cluster.local.dir |
${hadoop.tmp.dir}/mapred/local |
溢寫數據目錄 |
mapreduce.task.io.sort.factor |
10 | 設置一次合並多少個溢寫文件 |
6.2 ReduceTask 工作機制
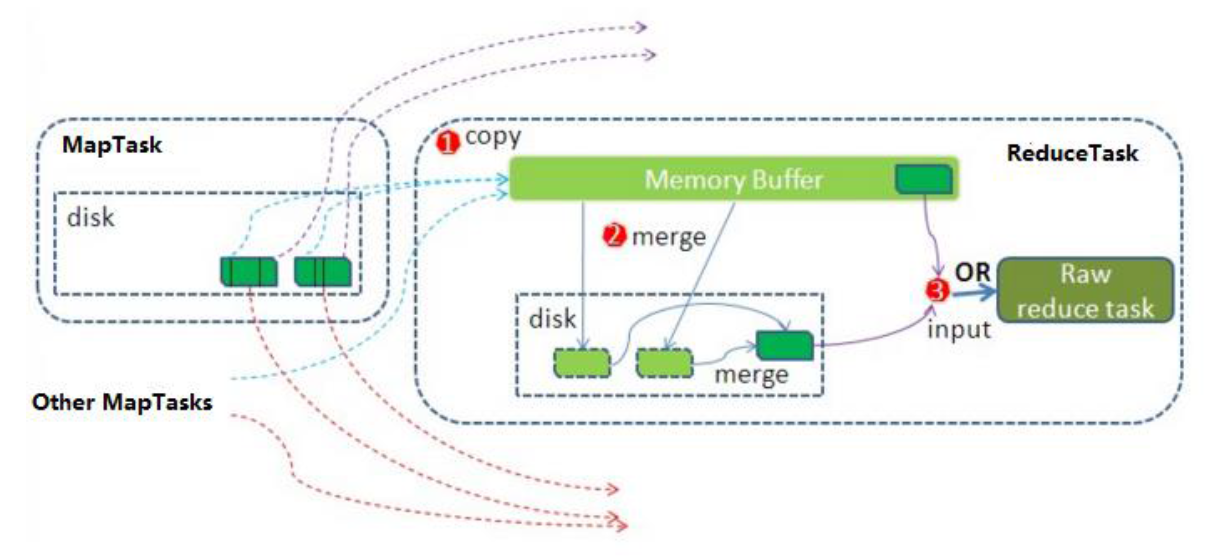
Reduce 大致分為 copy、sort、reduce 三個階段,重點在前兩個階段。copy 階段包含一個 eventFetcher 來獲取已完成的 map 列表,由 Fetcher 線程去 copy 數據,在此過程中會啟動兩個 merge 線程,分別為 inMemoryMerger 和 onDiskMerger,分別將內存中的數據 merge 到磁盤和將磁盤中的數據進行 merge。待數據 copy 完成之后,copy 階段就完成了,開始進行 sort 階段,sort 階段主要是執行 finalMerge 操作,純粹的 sort 階段,完成之后就是 reduce 階段,調用用戶定義的 reduce 函數進行處理
詳細步驟
- Copy階段,簡單地拉取數據。Reduce進程啟動一些數據copy線程(Fetcher),通過HTTP方式請求maptask獲取屬於自己的文件。
- Merge階段。這里的merge如map端的merge動作,只是數組中存放的是不同map端copy來的數值。Copy過來的數據會先放入內存緩沖區中,這里的緩沖區大小要比map端的更為靈活。merge有三種形式:內存到內存;內存到磁盤;磁盤到磁盤。默認情況下第一種形式不啟用。當內存中的數據量到達一定閾值,就啟動內存到磁盤的merge。與map 端類似,這也是溢寫的過程,這個過程中如果你設置有Combiner,也是會啟用的,然后在磁盤中生成了眾多的溢寫文件。第二種merge方式一直在運行,直到沒有map端的數據時才結束,然后啟動第三種磁盤到磁盤的merge方式生成最終的文件。
- 合並排序。把分散的數據合並成一個大的數據后,還會再對合並后的數據排序。
- 對排序后的鍵值對調用reduce方法,鍵相等的鍵值對調用一次reduce方法,每次調用會產生零個或者多個鍵值對,最后把這些輸出的鍵值對寫入到HDFS文件中。
6.3 Shuffle 過程
map 階段處理的數據如何傳遞給 reduce 階段,是 MapReduce 框架中最關鍵的一個流程,這個流程就叫 shuffle
shuffle: 洗牌、發牌 ——(核心機制:數據分區,排序,分組,規約,合並等過程)
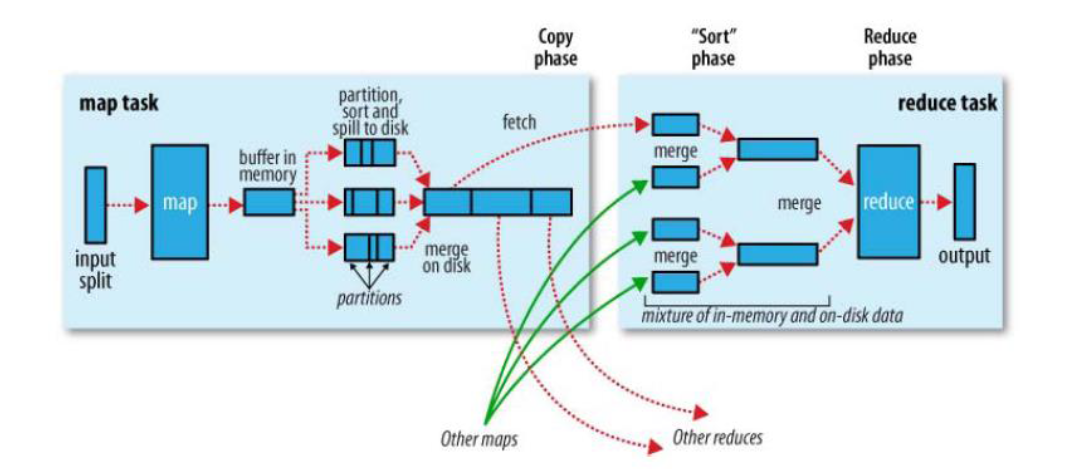
shuffle 是 Mapreduce 的核心,它分布在 Mapreduce 的 map 階段和 reduce 階段。一般把從 Map 產生輸出開始到 Reduce 取得數據作為輸入之前的過程稱作 shuffle。
Collect階段:將 MapTask 的結果輸出到默認大小為 100M 的環形緩沖區,保存的是 key/value,Partition 分區信息等。Spill階段:當內存中的數據量達到一定的閥值的時候,就會將數據寫入本地磁盤,在將數據寫入磁盤之前需要對數據進行一次排序的操作,如果配置了 combiner,還會將有相同分區號和 key 的數據進行排序。Merge階段:把所有溢出的臨時文件進行一次合並操作,以確保一個 MapTask 最終只產生一個中間數據文件。Copy階段:ReduceTask 啟動 Fetcher 線程到已經完成 MapTask 的節點上復制一份屬於自己的數據,這些數據默認會保存在內存的緩沖區中,當內存的緩沖區達到一定的閥值的時候,就會將數據寫到磁盤之上。Merge階段:在 ReduceTask 遠程復制數據的同時,會在后台開啟兩個線程對內存到本地的數據文件進行合並操作。Sort階段:在對數據進行合並的同時,會進行排序操作,由於 MapTask 階段已經對數據進行了局部的排序,ReduceTask 只需保證 Copy 的數據的最終整體有效性即可。
Shuffle 中的緩沖區大小會影響到 mapreduce 程序的執行效率,原則上說,緩沖區越大,磁盤io的次數越少,執行速度就越快
緩沖區的大小可以通過參數調整, 參數:mapreduce.task.io.sort.mb 默認100M
7. Reduce 端實現 JOIN
7.1 需求
假如數據量巨大,兩表的數據是以文件的形式存儲在 HDFS 中, 需要用 MapReduce 程序來實現以下 SQL 查詢運算
select a.id,a.date,b.name,b.category_id,b.price from t_order a left join t_product b on a.pid = b.id
- 商品表
| id | pname | category_id | price |
|---|---|---|---|
| P0001 | 小米5 | 1000 | 2000 |
| P0002 | 錘子T1 | 1000 | 3000 |
- 訂單數據表
| id | date | pid | amount |
|---|---|---|---|
| 1001 | 20150710 | P0001 | 2 |
| 1002 | 20150710 | P0002 | 3 |
7.2 實現步驟
通過將關聯的條件作為map輸出的key,將兩表滿足join條件的數據並攜帶數據所來源的文件信息,發往同一個reduce task,在reduce中進行數據的串聯
- 定義orderBean
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderJoinBean implements Writable {
private String id=""; // 訂單id
private String date=""; //訂單時間
private String pid=""; // 商品的id
private String amount=""; // 訂單的數量
private String name=""; //商品的名稱
private String categoryId=""; // 商品的分類id
private String price=""; //商品的價格
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public String getAmount() {
return amount;
}
public void setAmount(String amount) {
this.amount = amount;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCategoryId() {
return categoryId;
}
public void setCategoryId(String categoryId) {
this.categoryId = categoryId;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
@Override
public String toString() {
return id + "\t" + date + "\t" + pid + "\t" + amount + "\t" + name + "\t" + categoryId + "\t" + price;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(date);
out.writeUTF(pid);
out.writeUTF(amount);
out.writeUTF(name);
out.writeUTF(categoryId);
out.writeUTF(price);
}
@Override
public void readFields(DataInput in) throws IOException {
id = in.readUTF();
date = in.readUTF();
pid = in.readUTF();
amount = in.readUTF();
name = in.readUTF();
categoryId = in.readUTF();
price = in.readUTF();
}
}
- 定義 Mapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class MapperJoinTask extends Mapper<LongWritable,Text,Text,OrderJoinBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 通過文件片的方式獲取文件的名稱
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName();
//1. 獲取每一行的數據
String line = value.toString();
//2. 切割處理
String[] split = line.split(",");
OrderJoinBean orderJoinBean = new OrderJoinBean();
if(fileName.equals("orders.txt")){
// 訂單的數據
orderJoinBean.setId(split[0]);
orderJoinBean.setDate(split[1]);
orderJoinBean.setPid(split[2]);
orderJoinBean.setAmount(split[3]);
}else{
// 商品的數據
orderJoinBean.setPid(split[0]);
orderJoinBean.setName(split[1]);
orderJoinBean.setCategoryId(split[2]);
orderJoinBean.setPrice(split[3]);
}
//3. 發送給reduceTask
context.write(new Text(orderJoinBean.getPid()),orderJoinBean);
}
}
- 定義 Reducer
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ReducerJoinTask extends Reducer<Text,OrderJoinBean,Text,OrderJoinBean> {
@Override
protected void reduce(Text key, Iterable<OrderJoinBean> values, Context context) throws IOException, InterruptedException {
//1. 遍歷 : 相同的key會發給同一個reduce, 相同key的value的值形成一個集合
OrderJoinBean orderJoinBean = new OrderJoinBean();
for (OrderJoinBean value : values) {
String id = value.getId();
if(id.equals("")){
// 商品的數據
orderJoinBean.setPid(value.getPid());
orderJoinBean.setName(value.getName());
orderJoinBean.setCategoryId(value.getCategoryId());
orderJoinBean.setPrice(value.getPrice());
}else {
// 訂單數據
orderJoinBean.setId(value.getId());
orderJoinBean.setDate(value.getDate());
orderJoinBean.setPid(value.getPid());
orderJoinBean.setAmount(value.getAmount());
}
}
//2. 輸出即可
context.write(key,orderJoinBean);
}
}
- 定義主類
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobReduceJoinMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//1. 獲取job對象
Job job = Job.getInstance(super.getConf(), "jobReduceJoinMain");
//2. 拼裝八大步驟
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///D:\\reduce端join\\input"));
job.setMapperClass(MapperJoinTask.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(OrderJoinBean.class);
job.setReducerClass(ReducerJoinTask.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(OrderJoinBean.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("D:\\reduce端join\\out_put"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
JobReduceJoinMain jobReduceJoinMain = new JobReduceJoinMain();
int i = ToolRunner.run(conf, jobReduceJoinMain, args);
System.exit(i);
}
}
缺點:這種方式中,join的操作是在reduce階段完成,reduce端的處理壓力太大,map節點的運算負載則很低,資源利用率不高,且在reduce階段極易產生數據傾斜
8. Map端實現 JOIN
8.1 概述
適用於關聯表中有小表的情形.
使用分布式緩存,可以將小表分發到所有的map節點,這樣,map節點就可以在本地對自己所讀到的大表數據進行join並輸出最終結果,可以大大提高join操作的並發度,加快處理速度
8.2 實現步驟
先在mapper類中預先定義好小表,進行join
引入實際場景中的解決方案:一次加載數據庫
- 定義Mapper
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class MapperTask extends Mapper<LongWritable, Text, Text, Text> {
private Map<String,String> map = new HashMap<>();
// 初始化的方法, 只會被初始化一次
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] cacheFiles = DistributedCache.getCacheFiles(context.getConfiguration());
URI fileURI = cacheFiles[0];
FileSystem fs = FileSystem.get(fileURI, context.getConfiguration());
FSDataInputStream inputStream = fs.open(new Path(fileURI));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String readLine ="";
while ((readLine = bufferedReader.readLine() ) != null ) {
// readlLine: product一行數據
String[] split = readLine.split(",");
String pid = split[0];
map.put(pid,split[1]+"\t"+split[2]+"\t"+split[3]);
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1. 讀取一行數據: orders數據
String line = value.toString();
//2. 切割
String[] split = line.split(",");
String pid = split[2];
//3. 到map中獲取商品信息:
String product = map.get(pid);
//4. 發送給reduce: 輸出
context.write(new Text(pid),new Text(split[0]+"\t"+split[1]+"\t"+product +"\t"+split[3]));
}
}
- 定義主類
import com.itheima.join.reduce.JobReduceJoinMain;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class JobMapperJoinMain extends Configured implements Tool{
@Override
public int run(String[] args) throws Exception {
//設置緩存的位置, 必須在run的方法的最前, 如果放置在job任務創建后, 將無效
// 緩存文件的路徑, 必須存儲在hdfs上, 否則也是無效的
DistributedCache.addCacheFile(new URI("hdfs://node01:8020/cache/pdts.txt"),super.getConf());
//1. 獲取job 任務
Job job = Job.getInstance(super.getConf(), "jobMapperJoinMain");
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("E:\\傳智工作\\上課\\北京大數據30期\\大數據第六天\\資料\\map端join\\map_join_iput"));
job.setMapperClass(MapperTask.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("E:\\傳智工作\\上課\\北京大數據30期\\大數據第六天\\資料\\map端join\\out_put_map"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
JobMapperJoinMain jobMapperJoinMain = new JobMapperJoinMain();
int i = ToolRunner.run(conf, jobMapperJoinMain, args);
System.exit(i);
}
}
9. 社交粉絲數據分析
9.1 需求分析
以下是qq的好友列表數據,冒號前是一個用戶,冒號后是該用戶的所有好友(數據中的好友關系是單向的)
A:B,C,D,F,E,O
B:A,C,E,K
C:A,B,D,E,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
求出哪些人兩兩之間有共同好友,及他倆的共同好友都有誰?
【解題思路】
第一步
map
讀一行 A:B,C,D,F,E,O
輸出 <B,A><C,A><D,A><F,A><E,A><O,A>
在讀一行 B:A,C,E,K
輸出 <A,B><C,B><E,B><K,B>
REDUCE
拿到的數據比如<C,A><C,B><C,E><C,F><C,G>......
輸出:
<A-B,C>
<A-E,C>
<A-F,C>
<A-G,C>
<B-E,C>
<B-F,C>.....
第二步
map
讀入一行<A-B,C>
直接輸出<A-B,C>
reduce
讀入數據 <A-B,C><A-B,F><A-B,G>.......
輸出: A-B C,F,G,.....
9.2 實現步驟
第一個MapReduce代碼實現
【Mapper類】
public class Step1Mapper extends Mapper<LongWritable,Text,Text,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1:以冒號拆分行文本數據: 冒號左邊就是V2
String[] split = value.toString().split(":");
String userStr = split[0];
//2:將冒號右邊的字符串以逗號拆分,每個成員就是K2
String[] split1 = split[1].split(",");
for (String s : split1) {
//3:將K2和v2寫入上下文中
context.write(new Text(s), new Text(userStr));
}
}
}
【Reducer類】
public class Step1Reducer extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//1:遍歷集合,並將每一個元素拼接,得到K3
StringBuffer buffer = new StringBuffer();
for (Text value : values) {
buffer.append(value.toString()).append("-");
}
//2:K2就是V3
//3:將K3和V3寫入上下文中
context.write(new Text(buffer.toString()), key);
}
}
JobMain:
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//1:獲取Job對象
Job job = Job.getInstance(super.getConf(), "common_friends_step1_job");
//2:設置job任務
//第一步:設置輸入類和輸入路徑
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("file:///D:\\input\\common_friends_step1_input"));
//第二步:設置Mapper類和數據類型
job.setMapperClass(Step1Mapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//第三,四,五,六
//第七步:設置Reducer類和數據類型
job.setReducerClass(Step1Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//第八步:設置輸出類和輸出的路徑
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("file:///D:\\out\\common_friends_step1_out"));
//3:等待job任務結束
boolean bl = job.waitForCompletion(true);
return bl ? 0: 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//啟動job任務
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
第二個MapReduce代碼實現
【Mapper類】
public class Step2Mapper extends Mapper<LongWritable,Text,Text,Text> {
/*
K1 V1
0 A-F-C-J-E- B
----------------------------------
K2 V2
A-C B
A-E B
A-F B
C-E B
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1:拆分行文本數據,結果的第二部分可以得到V2
String[] split = value.toString().split("\t");
String friendStr =split[1];
//2:繼續以'-'為分隔符拆分行文本數據第一部分,得到數組
String[] userArray = split[0].split("-");
//3:對數組做一個排序
Arrays.sort(userArray);
//4:對數組中的元素進行兩兩組合,得到K2
/*
A-E-C -----> A C E
A C E
A C E
*/
for (int i = 0; i <userArray.length -1 ; i++) {
for (int j = i+1; j < userArray.length ; j++) {
//5:將K2和V2寫入上下文中
context.write(new Text(userArray[i] +"-"+userArray[j]), new Text(friendStr));
}
}
}
}
【Reducer類】
public class Step2Reducer extends Reducer<Text,Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//1:原來的K2就是K3
//2:將集合進行遍歷,將集合中的元素拼接,得到V3
StringBuffer buffer = new StringBuffer();
for (Text value : values) {
buffer.append(value.toString()).append("-");
}
//3:將K3和V3寫入上下文中
context.write(key, new Text(buffer.toString()));
}
}
【JobMain】
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//1:獲取Job對象
Job job = Job.getInstance(super.getConf(), "common_friends_step2_job");
//2:設置job任務
//第一步:設置輸入類和輸入路徑
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("file:///D:\\out\\common_friends_step1_out"));
//第二步:設置Mapper類和數據類型
job.setMapperClass(Step2Mapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//第三,四,五,六
//第七步:設置Reducer類和數據類型
job.setReducerClass(Step2Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//第八步:設置輸出類和輸出的路徑
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("file:///D:\\out\\common_friends_step2_out"));
//3:等待job任務結束
boolean bl = job.waitForCompletion(true);
return bl ? 0: 1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//啟動job任務
int run = ToolRunner.run(configuration, new JobMain(), args);
System.exit(run);
}
}
10. 倒排索引建立
10.1 需求分析
需求:有大量的文本(文檔、網頁),需要建立搜索索引
思路分析:
首選將文檔的內容全部讀取出來,加上文檔的名字作為key,文檔的value為1,組織成這樣的一種形式的數據
map端數據輸出:
hello-a.txt 1
hello-a.txt 1
hello-a.txt 1
reduce端數據輸出:
hello-a.txt 3
10.2 代碼實現
public class IndexCreate extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(),new IndexCreate(),args);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), IndexCreate.class.getSimpleName());
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///D:\\倒排索引\\input"));
job.setMapperClass(IndexCreateMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(IndexCreateReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///D:\\倒排索引\\outindex"));
boolean bool = job.waitForCompletion(true);
return bool?0:1;
}
public static class IndexCreateMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
Text text = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//獲取文件切片
FileSplit fileSplit = (FileSplit) context.getInputSplit();
//通過文件切片獲取文件名
String name = fileSplit.getPath().getName();
String line = value.toString();
String[] split = line.split(" ");
//輸出 單詞--文件名作為key value是1
for (String word : split) {
text.set(word+"--"+name);
context.write(text,v);
}
}
}
public static class IndexCreateReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
IntWritable value = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
value.set(count);
context.write(key,value);
}
}
}