
此面試題來自牛客網友分享的字節跳動應屆一面,面試時長一小時。
網友情況:985 本碩。
以下為面試過程中提問,崗位為大數據開發:
-
自我介紹+項目介紹
-
為什么用 kafka、sparkstreaming、hbase?有什么替代方案嗎?
-
聊聊你覺得大數據的整個體系?
-
你看過 hdfs 源碼?nn 的高可用說一下
-
zookeeper 簡單介紹一下,為什么要用 zk?zk 的架構?zab?
-
hbase 的架構,讀寫緩存?
-
blockcache 的底層實現?你提到了 LRU 那除了 LRU 還可以有什么方案?
-
聊聊 sparkstreaming 和 flink?flink 流批一體解釋一下?
-
spark 的幾種 shuffle 說下?為什么要丟棄 hashshuffle?
-
java gc 可達性分析+垃圾回收器+垃圾回收算法+為什么分代垃圾回收+調優
-
數據庫引擎,innodb 索引實現+聚集和非聚集區別+為什么用 b+樹不用 hash
-
聊聊 tcp 和 udp 的區別
-
http 知道嗎?說一下
-
http 版本之間的比較
-
讓你設計一個 hash 表,怎么設計?
-
時間不多了,手擼一個二分查找
答案解析
1. 自我介紹+項目介紹
自我介紹可以參考美團面試的這篇文章:美團優選大數據開發崗面試題
2. 為什么用 kafka、sparkstreaming、hbase?有什么替代方案嗎?
根據簡歷中寫的項目,談談為什么用這幾個框架,是公司大數據平台歷史選擇還是更適合公司業務。
然后在說下每個框架的優點:
Kafka:
-
高吞吐量、低延遲:kafka 每秒可以處理幾十萬條消息,它的延遲最低只有幾毫秒; -
可擴展性:kafka 集群支持熱擴展; -
持久性、可靠性:消息被持久化到本地磁盤,並且支持數據備份防止數據丟失; -
容錯性:允許集群中節點故障(若副本數量為 n,則允許 n-1 個節點故障); -
高並發:支持數千個客戶端同時讀寫。
Kafka 應用場景:
-
日志收集:一個公司可以用 Kafka 可以收集各種服務的 log,通過 kafka 以統一接口服務的方式開放給各種 consumer; -
消息系統:解耦生產者和消費者、緩存消息等; -
用戶活動跟蹤:kafka 經常被用來記錄 web 用戶或者 app 用戶的各種活動,如瀏覽網頁、搜索、點擊等活動,這些活動信息被各個服務器發布到 kafka 的 topic 中,然后消費者通過訂閱這些 topic 來做實時的監控分析,亦可保存到數據庫; -
運營指標:kafka 也經常用來記錄運營監控數據。包括收集各種分布式應用的數據,生產各種操作的集中反饋,比如報警和報告; -
流式處理:比如 spark streaming 和 flink。
Spark Streaming 優點:
-
spark streaming 會被轉化為 spark 作業執行,由於 spark 作業依賴 DAGScheduler 和 RDD,所以是粗粒度方式而不是細粒度方式,可以快速處理小批量數據,獲得准實時的特性;
-
以 spark 作業提交和執行,很方便的實現容錯機制;
-
DStreaming 是在 RDD 上的抽象,更容易與 RDD 進行交互操作。需要將流式數據與批數據結合分析的情況下,非常方便。
因為我們的業務對實時性要求不是特別高,所以使用 spark streaming 是非常合適的。
HBase 優點:
-
HDFS 有高容錯,高擴展的特點,而 Hbase 基於 HDFS 實現數據的存儲,因此 Hbase 擁有與生俱來的超強的擴展性和吞吐量。
-
HBase 采用的是 Key/Value 的存儲方式,這意味着,即便面臨海量數據的增長,也幾乎不會導致查詢性能下降。
-
HBase 是一個列式數據庫,相對於於傳統的行式數據庫而言。當你的單張表字段很多的時候,可以將相同的列(以 regin 為單位)存在到不同的服務實例上,分散負載壓力。
有什么替代方案,就可以聊聊和這幾個功能類似的框架,它們的優缺點等,比如 Apache kafka 對應的 Apache Pulsar;Spark Streaming 對應的 Flink;HBase 對應的列式數據庫可以舉幾個例子,如 Cassandra、MongoDB 等。
3. 聊聊你覺得大數據的整個體系?
這個是一個開放性題,把你知道的大數據框架都可以說下,下面是我做的一個 Apache 大數據框架的集合圖,當然也沒有包含全部,只是比較常見的幾個:

說的時候盡量按照它們的功能划分及時間先后順序講解。
4. 你看過 hdfs 源碼?nn 的高可用說一下
一個 NameNode 有單點故障的問題,那就配置雙 NameNode,配置有兩個關鍵點,一是必須要保證這兩個 NN 的元數據信息必須要同步的,二是一個 NN 掛掉之后另一個要立馬補上。
-
元數據信息同步在 HA 方案中采用的是“共享存儲”。每次寫文件時,需要將日志同步寫入共享存儲,這個步驟成功才能認定寫文件成功。然后備份節點定期從共享存儲同步日志,以便進行主備切換。 -
監控 NN 狀態采用 zookeeper,兩個 NN 節點的狀態存放在 ZK 中,另外兩個 NN 節點分別有一個進程監控程序,實施讀取 ZK 中有 NN 的狀態,來判斷當前的 NN 是不是已經 down 機。如果 standby 的 NN 節點的 ZKFC 發現主節點已經掛掉,那么就會強制給原本的 active NN 節點發送強制關閉請求,之后將備用的 NN 設置為 active。
如果面試官再問 HA 中的 共享存儲 是怎么實現的知道嗎?
可以進行解釋下:NameNode 共享存儲方案有很多,比如 Linux HA, VMware FT, QJM 等,目前社區已經把由 Clouderea 公司實現的基於 QJM(Quorum Journal Manager)的方案合並到 HDFS 的 trunk 之中並且作為默認的共享存儲實現
基於 QJM 的共享存儲系統主要用於保存 EditLog,並不保存 FSImage 文件。FSImage 文件還是在 NameNode 的本地磁盤上。QJM 共享存儲的基本思想來自於 Paxos 算法,采用多個稱為 JournalNode 的節點組成的 JournalNode 集群來存儲 EditLog。每個 JournalNode 保存同樣的 EditLog 副本。每次 NameNode 寫 EditLog 的時候,除了向本地磁盤寫入 EditLog 之外,也會並行地向 JournalNode 集群之中的每一個 JournalNode 發送寫請求,只要大多數 (majority) 的 JournalNode 節點返回成功就認為向 JournalNode 集群寫入 EditLog 成功。如果有 2N+1 台 JournalNode,那么根據大多數的原則,最多可以容忍有 N 台 JournalNode 節點掛掉
注:Hadoop3.x 允許用戶運行多個備用 NameNode。例如,通過配置三個 NameNode 和五個 JournalNode,群集能夠容忍兩個節點而不是一個節點的故障。
HDFS 的其他內容可看之前寫的這篇文章:HDFS 分布式文件系統詳解
5. zookeeper 簡單介紹一下,為什么要用 zk?zk 的架構?zab?
zk 介紹及功能:
Zookeeper 是一個分布式協調服務的開源框架。 主要用來解決分布式集群中應用系統的一致性問題,例如怎樣避免同時操作同一數據造成臟讀的問題。
ZooKeeper 本質上是一個分布式的小文件存儲系統。提供基於類似於文件系統的目錄樹方式的數據存儲,並且可以對樹中的節點進行有效管理。從而用來維護和監控你存儲的數據的狀態變化。通過監控這些數據狀態的變化,從而可以達到基於數據的集群管理。 諸如: 統一命名服務(dubbo)、分布式配置管理(solr 的配置集中管理)、分布式消息隊列(sub/pub)、分布式鎖、分布式協調等功能。
zk 架構:
zk 架構圖:
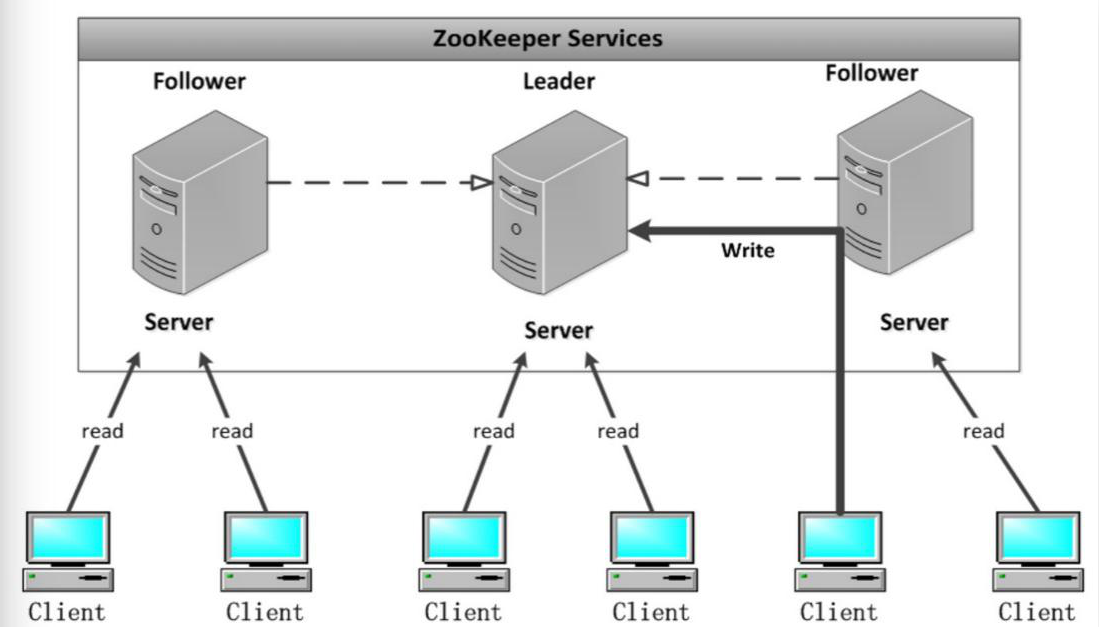
Leader:
Zookeeper 集群工作的核心;
事務請求(寫操作) 的唯一調度和處理者,保證集群事務處理的順序性;
集群內部各個服務器的調度者。
對於 create, setData, delete 等有寫操作的請求,則需要統一轉發給 leader 處理, leader 需要決定編號、執行操作,這個過程稱為一個事務。
Follower:
處理客戶端非事務(讀操作) 請求,
轉發事務請求給 Leader;
參與集群 Leader 選舉投票 2n-1 台可以做集群投票。
此外,針對訪問量比較大的 zookeeper 集群, 還可新增觀察者角色。
Observer:
觀察者角色,觀察 Zookeeper 集群的最新狀態變化並將這些狀態同步過來,其對於非事務請求可以進行獨立處理,對於事務請求,則會轉發給 Leader 服務器進行處理。
不會參與任何形式的投票只提供非事務服務,通常用於在不影響集群事務 處理能力的前提下提升集群的非事務處理能力。
簡答:說白了就是增加並發的讀請求
ZAB 協議全稱:Zookeeper Atomic Broadcast(Zookeeper 原子廣播協議)。
ZAB 協議是專門為 zookeeper 實現分布式協調功能而設計。zookeeper 主要是根據 ZAB 協議是實現分布式系統數據一致性。
zookeeper 根據 ZAB 協議建立了主備模型完成 zookeeper 集群中數據的同步。這里所說的主備系統架構模型是指,在 zookeeper 集群中,只有一台 leader 負責處理外部客戶端的事物請求(或寫操作),然后 leader 服務器將客戶端的寫操作數據同步到所有的 follower 節點中。
6. HBase 的架構,讀寫緩存?
HBase 的架構可以看這篇文章,非常詳細:HBase 底層原理詳解
下面說下HBase 的讀寫緩存:
HBase 的 RegionServer 的緩存主要分為兩個部分,分別是MemStore和BlockCache,其中 MemStore 主要用於寫緩存,而 BlockCache 用於讀緩存。
HBase 執行寫操作首先會將數據寫入 MemStore,並順序寫入 HLog,等滿足一定條件后統一將 MemStore 中數據刷新到磁盤,這種設計可以極大地提升 HBase 的寫性能。
不僅如此,MemStore 對於讀性能也至關重要,假如沒有 MemStore,讀取剛寫入的數據就需要從文件中通過 IO 查找,這種代價顯然是昂貴的!
BlockCache 稱為讀緩存,HBase 會將一次文件查找的 Block 塊緩存到 Cache 中,以便后續同一請求或者鄰近數據查找請求,可以直接從內存中獲取,避免昂貴的 IO 操作。
7. BlockCache 的底層實現?你提到了 LRU 那除了 LRU 還可以有什么方案?
我們知道緩存有三種不同的更新策略,分別是FIFO(先入先出)、LRU(最近最少使用)和 LFU(最近最不常使用)。
HBase 的 block 默認使用的是 LRU 策略:LRUBlockCache。此外還有 BucketCache、SlabCache(此緩存在 0.98 版本已經不被建議使用)
LRUBlockCache 實現機制:
LRUBlockCache 是 HBase 目前默認的 BlockCache 機制,實現機制比較簡單。它使用一個 ConcurrentHashMap 管理 BlockKey 到 Block 的映射關系,緩存 Block 只需要將 BlockKey 和對應的 Block 放入該 HashMap 中,查詢緩存就根據 BlockKey 從 HashMap 中獲取即可。
同時該方案采用嚴格的 LRU 淘汰算法,當 Block Cache 總量達到一定閾值之后就會啟動淘汰機制,最近最少使用的 Block 會被置換出來。在具體的實現細節方面,需要關注幾點:
-
緩存分層策略
HBase 在 LRU 緩存基礎上,采用了緩存分層設計,將整個 BlockCache 分為三個部分:single-access、mutil-access 和 inMemory。
需要特別注意的是,HBase 系統元數據存放在 InMemory 區,因此設置數據屬性 InMemory = true 需要非常謹慎,確保此列族數據量很小且訪問頻繁,否則有可能會將 hbase.meta 元數據擠出內存,嚴重影響所有業務性能。
-
LRU 淘汰算法實現
系統在每次 cache block 時將 BlockKey 和 Block 放入 HashMap 后都會檢查 BlockCache 總量是否達到閾值,如果達到閾值,就會喚醒淘汰線程對 Map 中的 Block 進行淘汰。
系統設置三個 MinMaxPriorityQueue 隊列,分別對應上述三個分層,每個隊列中的元素按照最近最少被使用排列,系統會優先 poll 出最近最少使用的元素,將其對應的內存釋放。可見,三個分層中的 Block 會分別執行 LRU 淘汰算法進行淘汰。
8. 聊聊 sparkstreaming 和 flink?flink 流批一體解釋一下?
Flink 是標准的實時處理引擎,基於事件驅動。而 Spark Streaming 是微批( Micro-Batch )的模型。
下面就分幾個方面介紹兩個框架的主要區別:
-
架構模型:
-
Spark Streaming 在運行時的主要角色包括:Master、Worker、Driver、Executor; -
Flink 在運行時主要包:Jobmanager、Taskmanager 和 Slot。
-
-
任務調度:
-
Spark Streaming 連續不斷的生成微小的數據批次,構建有向無環圖 DAG, Spark Streaming 會依次創 DStreamGraph、JobGenerator、JobScheduler; -
Flink 根據用戶提交的代碼生成 StreamGraph,經過優化生成 JobGraph,然后提交給 JobManager 進行處理, JobManager 會根據 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 調度最核心的數據結構,JobManager 根據 ExecutionGraph 對 Job 進行調度。
-
-
時間機制:
-
Spark Streaming 支持的時間機制有限,只支持處理時間。 -
Flink 支持了流處理程序在時間上的三個定義:處理時間、事件時間、注入時間。同時也支持 watermark 機 制來處理滯后數據。
-
-
容錯機制:
-
對於 Spark Streaming 任務,我們可以設置 checkpoint,然后假如發生故障並重啟,我們可以從上次 checkpoint 之處恢復,但是這個行為只能使得數據不丟失,可能 會重復處理,不能做到恰好一次處理語義。 -
Flink 則使用 兩階段提交協議來解決這個問題。
-
Flink 的兩階段提交協議具體可以看這篇文章:八張圖搞懂 Flink 端到端精准一次處理語義 Exactly-once
9. spark 的幾種 shuffle 說下?為什么要丟棄 hashshuffle?
前段時間剛寫的,可以看下:Spark 的兩種核心 Shuffle 詳解
10. java gc 可達性分析+垃圾回收器+垃圾回收算法+為什么分代垃圾回收+調優
JVM 相關的面試題可看這篇文章,文中第四、五題和本問題相關:精選大數據面試真題 JVM 專項
11. 數據庫引擎,innodb 索引實現+聚集和非聚集區別+為什么用 b+樹不用 hash
innodb 索引實現:
innoDB使用的是聚集索引,將主鍵組織到一棵B+樹中,而行數據就儲存在葉子節點上,若使用"where id = 14"這樣的條件查找主鍵,則按照B+樹的檢索算法即可查找到對應的葉節點,之后獲得行數據。若對Name列進行條件搜索,則需要兩個步驟:第一步在輔助索引B+樹中檢索Name,到達其葉子節點獲取對應的主鍵。
第二步使用主鍵在主索引B+樹中再執行一次B+樹檢索操作,最終到達葉子節點即可獲取整行數據。
聚集索引和非聚集索引的區別:
-
聚集索引一個表只能有一個,而非聚集索引一個表可以存在多個。
-
聚集索引存儲記錄是物理上連續存在,而非聚集索引是邏輯上的連續,物理存儲並不連續。
-
聚集索引:物理存儲按照索引排序;聚集索引是一種索引組織形式,索引的鍵值邏輯順序決定了表數據行的物理存儲順序。
-
非聚集索引:物理存儲不按照索引排序;非聚集索引則就是普通索引了,僅僅只是對數據列創建相應的索引,不影響整個表的物理存儲順序。
-
索引是通過二叉樹的數據結構來描述的,我們可以這么理解聚簇索引:索引的葉節點就是數據節點。而非聚簇索引的葉節點仍然是索引節點,只不過有一個指針指向對應的數據塊。
數據庫索引使用B+樹原因:
InnoDB采用B+樹結構,是因為B+樹能夠很好地配合磁盤的讀寫特性,減少單次查詢的磁盤訪問次數,降低IO、提升性能等。
數據庫索引不適合用hash的原因:
-
區間值難找。因為單個值計算會很快,而找區間值,比如 100 < id < 200 就悲催了,需要遍歷全部hash節點。
-
排序難。通過hash算法,也就是壓縮算法,可能會很大的值和很小的值落在同一個hash桶里,比如一萬個數壓縮成1000個數存到hash桶里,也就是會產生hash沖突。
-
不支持利用索引完成排序、以及like ‘xxx%’ 這樣的部分模糊查詢。
-
不支持聯合索引的最左前綴匹配規則。
12. 聊聊 tcp 和 udp 的區別
簡單說下:
-
TCP面向連接 (如打電話要先撥號建立連接);UDP是無連接的,即發送數據之前不需要建立連接。
-
TCP提供可靠的服務。也就是說,通過TCP連接傳送的數據,無差錯,不丟失,不重復,且按序到達;UDP盡最大努力交付,即不保證可靠交付。
Tcp通過校驗和,重傳控制,序號標識,滑動窗口、確認應答實現可靠傳輸。如丟包時的重發控制,還可以對次序亂掉的分包進行順序控制。
-
UDP具有較好的實時性,工作效率比TCP高,適用於對高速傳輸和實時性有較高的通信或廣播通信。
-
每一條TCP連接只能是點到點的;UDP支持一對一,一對多,多對一和多對多的交互通信。
-
TCP對系統資源要求較多;UDP對系統資源要求較少。
13. http 知道嗎?說一下
超文本傳輸協議(縮寫:HTTP)是一種用於分布式、協作式和超媒體信息系統的應用層協議。HTTP是萬維網的數據通信的基礎。
HTTP協議定義Web客戶端如何從Web服務器請求Web頁面,以及服務器如何把Web頁面傳送給客戶端。HTTP協議采用了請求/響應模型。客戶端向服務器發送一個請求報文,請求報文包含請求的方法、URL、協議版本、請求頭部和請求數據。服務器以一個狀態行作為響應,響應的內容包括協議的版本、成功或者錯誤代碼、服務器信息、響應頭部和響應數據。
以下是 HTTP 請求/響應的步驟:
-
客戶端連接到Web服務器:
一個HTTP客戶端,通常是瀏覽器,與Web服務器的HTTP端口(默認為80)建立一個TCP套接字連接。例如,http://www.baidu.com。
-
發送HTTP請求:
通過TCP套接字,客戶端向Web服務器發送一個文本的請求報文,一個請求報文由請求行、請求頭部、空行和請求數據4部分組成。
-
服務器接受請求並返回HTTP響應:
Web服務器解析請求,定位請求資源。服務器將資源復本寫到TCP套接字,由客戶端讀取。一個響應由狀態行、響應頭部、空行和響應數據4部分組成。
-
釋放連接TCP連接:
若connection 模式為close,則服務器主動關閉TCP連接,客戶端被動關閉連接,釋放TCP連接;若connection 模式為keepalive,則該連接會保持一段時間,在該時間內可以繼續接收請求;
-
客戶端瀏覽器解析HTML內容:
客戶端瀏覽器首先解析狀態行,查看表明請求是否成功的狀態代碼。然后解析每一個響應頭,響應頭告知以下為若干字節的HTML文檔和文檔的字符集。客戶端瀏覽器讀取響應數據HTML,根據HTML的語法對其進行格式化,並在瀏覽器窗口中顯示。
14. http 版本之間的比較
這道題字節經常問,需要記住:
http0.9:
最初的http版本,僅支持get方法,只能傳輸純文本內容,所以請求結束服務段會給客戶端返回一個HTML格式的字符串,然后由瀏覽器自己渲染。
http0.9是典型的無狀態連接(無狀態是指協議對於事務處理沒有記憶功能,對同一個url請求沒有上下文關系,每次的請求都是獨立的,服務器中沒有保存客戶端的狀態)
http1.0:
這個版本后任何文件形式都可以被傳輸,本質上支持長連接,但是默認還是短連接,增加了keep-alive關鍵字來由短鏈接變成長連接。
HTTP的請求和回應格式也發生了變化,除了要傳輸的數據之外,每次通信都包含頭信息,用來描述一些信息。
還增加了狀態碼(status code)、多字符集支持、多部分發送(multi-part type)、權限(authorization)、緩存(cache)、內容編碼(content encoding)等。
http1.1:
HTTP1.1最大的變化就是引入了長鏈接,也就是TCP鏈接默認是不關閉的可以被多個請求復用。客戶端或者服務器如果長時間發現對方沒有活動就會關閉鏈接,但是規范的做法是客戶端在最后一個請求的時候要求服務器關閉鏈接。對於同一個域名,目前瀏覽器支持建立6個長鏈接。
節約帶寬,HTTP1.1支持只發送header頭信息不帶任何body信息,如果服務器認為客戶端有權限請求指定數據那就返回100,沒有就返回401,當客戶端收到100的時候可以才把要請求的信息發給服務器。並且1.1還支持了請求部分內容,如果當前客戶端已經有一部分資源了,只需要向服務器請求另外的部分資源即可,這也是支持文件斷點續傳的基礎。
1.1版本中增加了host處理,在HTTP1.0中認為每台服務器都綁定一個唯一的ip地址,因此在URL中並沒有傳遞主機名,但是隨着虛擬機技術的發展,可能在一台物理機器上存在多個虛擬主機,並且他們共享了一個ip地址,http1.1中請求消息和響應消息都支持host頭域,如果不存在還會報出錯誤。
http2.0:
多路復用:在一個連接里面並發處理請求,不像http1.1在一個tcp連接中各個請求是串行的,花銷很大。
在1.0版本后增加了header頭信息,2.0版本通過算法把header進行了壓縮這樣數據體積就更小,在網絡上傳輸就更快。
服務端有了推送功能,將客戶端感興趣的東西推給客戶端,當客戶端請求這些時,直接去緩存中取就行。
15. 讓你設計一個 hash 表,怎么設計?
可以把java的hashmap的實現原理說下,因為這就是hash表的經典設計!內容較多,並且網上資料很多,可以自己搜索查看!
16. 時間不多了,手擼一個二分查找
二分查找圖解:

二分查找:時間復雜度O(log2n);空間復雜度O(1)
def binarySearch(arr:Array[Int],left:Int,right:Int,findVal:Int): Int={
if(left>right){//遞歸退出條件,找不到,返回-1
-1
}
val midIndex = (left+right)/2
if (findVal < arr(midIndex)){//向左遞歸查找
binarySearch(arr,left,midIndex,findVal)
}else if(findVal > arr(midIndex)){//向右遞歸查找
binarySearch(arr,midIndex,right,findVal)
}else{//查找到,返回下標
midIndex
}
}
拓展需求:當一個有序數組中,有多個相同的數值時,如何將所有的數值都查找到。
/*
{1,8, 10, 89, 1000, 1000,1234} 當一個有序數組中,有多個相同的數值時,如何將所有的數值都查找到,比如這里的 1000.
//分析
1. 返回的結果是一個可變數組 ArrayBuffer
2. 在找到結果時,向左邊掃描,向右邊掃描 [條件]
3. 找到結果后,就加入到ArrayBuffer
*/
def binarySearch2(arr: Array[Int], l: Int, r: Int,
findVal: Int): ArrayBuffer[Int] = {
//找不到條件?
if (l > r) {
return ArrayBuffer()
}
val midIndex = (l + r) / 2
val midVal = arr(midIndex)
if (midVal > findVal) {
//向左進行遞歸查找
binarySearch2(arr, l, midIndex - 1, findVal)
} else if (midVal < findVal) { //向右進行遞歸查找
binarySearch2(arr, midIndex + 1, r, findVal)
} else {
println("midIndex=" + midIndex)
//定義一個可變數組
val resArr = ArrayBuffer[Int]()
//向左邊掃描
var temp = midIndex - 1
breakable {
while (true) {
if (temp < 0 || arr(temp) != findVal) {
break()
}
if (arr(temp) == findVal) {
resArr.append(temp)
}
temp -= 1
}
}
//將中間這個索引加入
resArr.append(midIndex)
//向右邊掃描
temp = midIndex + 1
breakable {
while (true) {
if (temp > arr.length - 1 || arr(temp) != findVal) {
break()
}
if (arr(temp) == findVal) {
resArr.append(temp)
}
temp += 1
}
}
return resArr
}