> 實現音頻PCM錄制的Github地址:https://github.com/crazydog-ki/MMSesssion
# 什么是PCM?
PCM全稱Pulse-Code Modulation,即脈沖編碼調制。簡單來說就是一種用數字信號表示采樣模擬信號的方法。
# 獲取PCM原始數據的步驟
## 采樣
通常自然界的聲音可通過一條曲線在坐標中顯示連續的模擬信號表示:

為了更加容易理解PCM,截取PCM部分波形,假設該波形表示1s的音頻模擬信號。則采樣可如下圖所示:
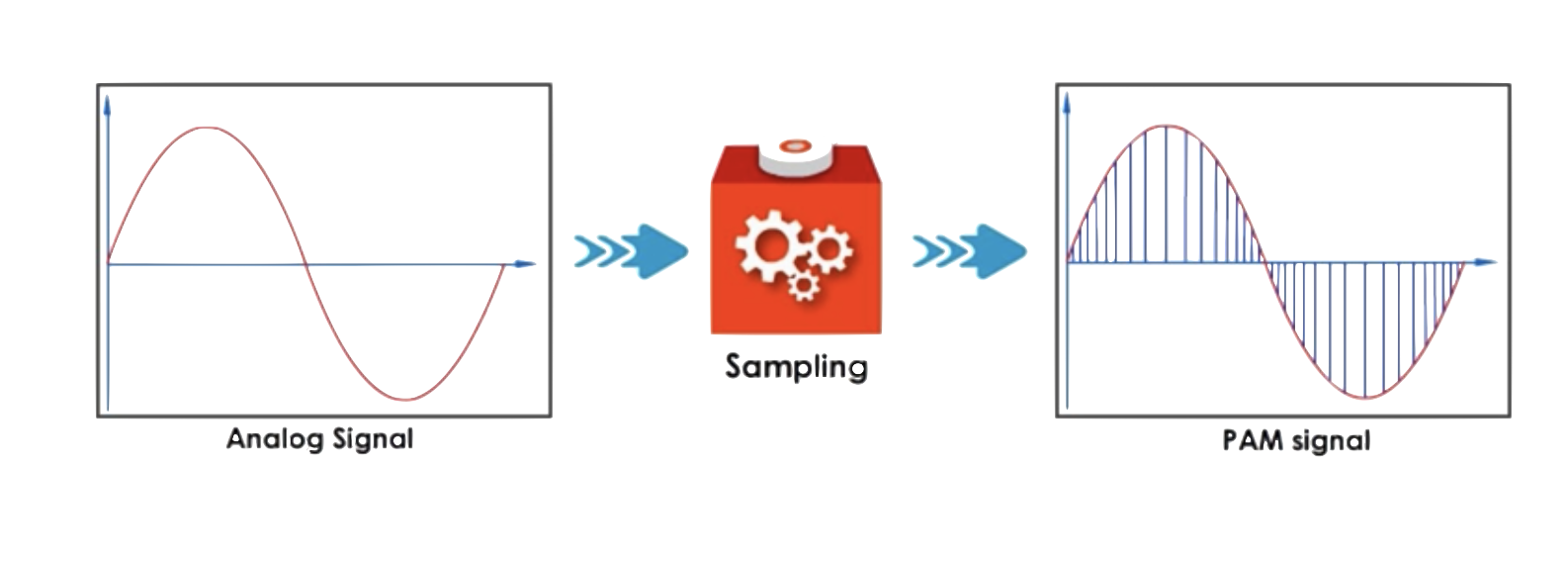
其中紅色的曲線表示**原始模擬信號**;藍色垂直線段表示當前時間點對原始模擬信號的**一次采樣**。采樣是一系列**基於振幅**的樣本,故采樣過程又被稱為PAM(Pulse Amplitude Modulation)。
**采樣率**(Sample Rate)表示**每秒采樣次數**,單位為Hz。根據場景不同,采樣率也會有所差異,采樣率越高,采樣的聲音就會越接近原始聲音,聲音的還原度就越好,質量越高,同時占用空間也會越大。例如,通話時的采樣率為8kHz,常用的媒體文件采樣率是44.1kHz。
## 量化
原始信號采樣后需要通過**量化**來描述采樣數據的大小。
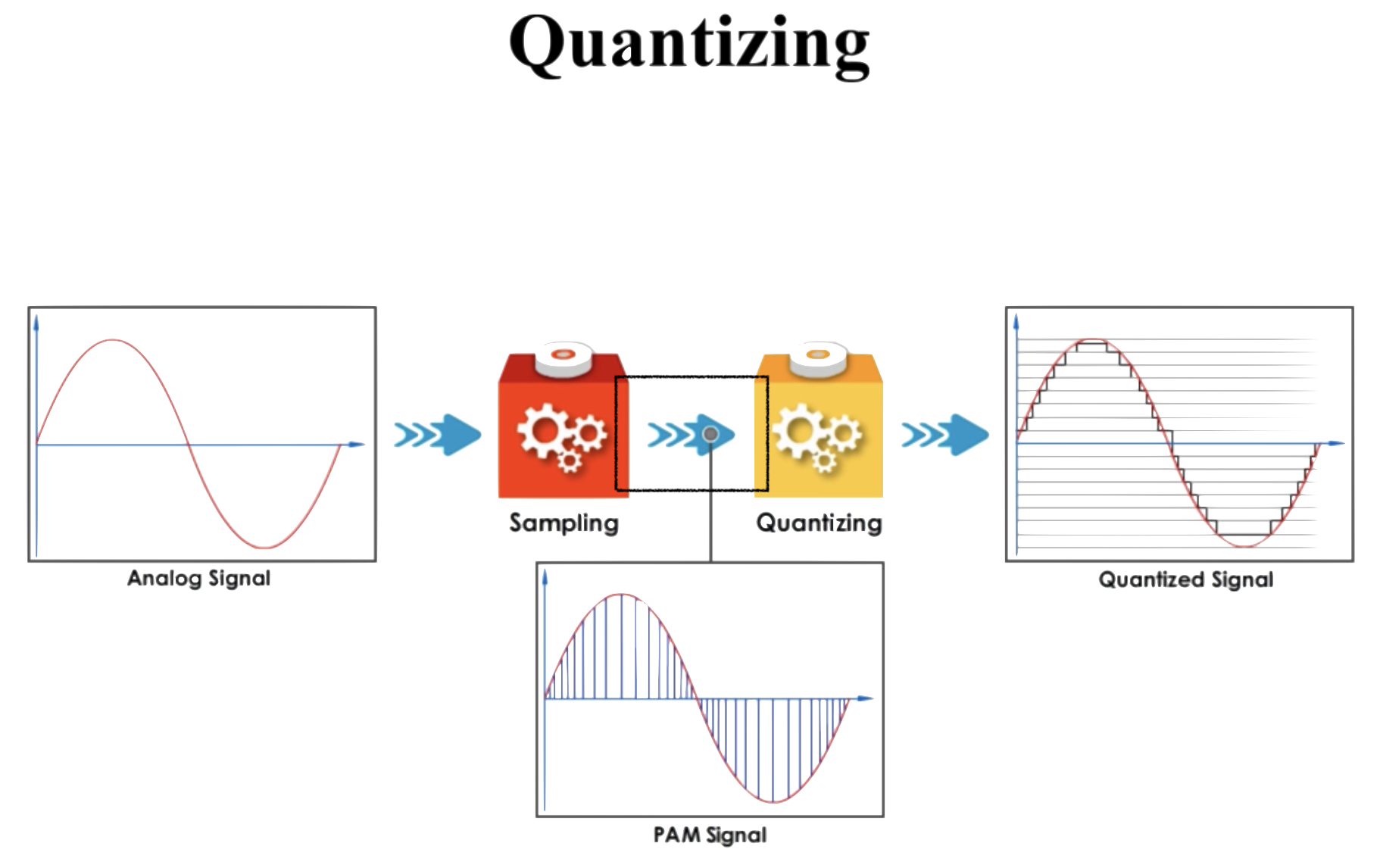
**量化處理過程**:就是將**時間連續的模擬信號**轉為**離散的數字信號**,並將數字信號轉換為二進制數,用於存儲和傳輸。
在圖例中,如果采樣是畫垂直線段,那么量化就是畫水平線段,用於衡量每次采樣的數字指標:

每條橫線代表一個等級,為更好地描述量化過程,引入**位深**的概念:
>位深:用於描述采用多少二進制位表示一個音頻模擬信號采樣,常見的位深有8bit、16bit、32bit、64bit,其中16bit最常見。顯而易見,位深度越大對模擬信號的描述越真實,對聲音的描述更加准確。
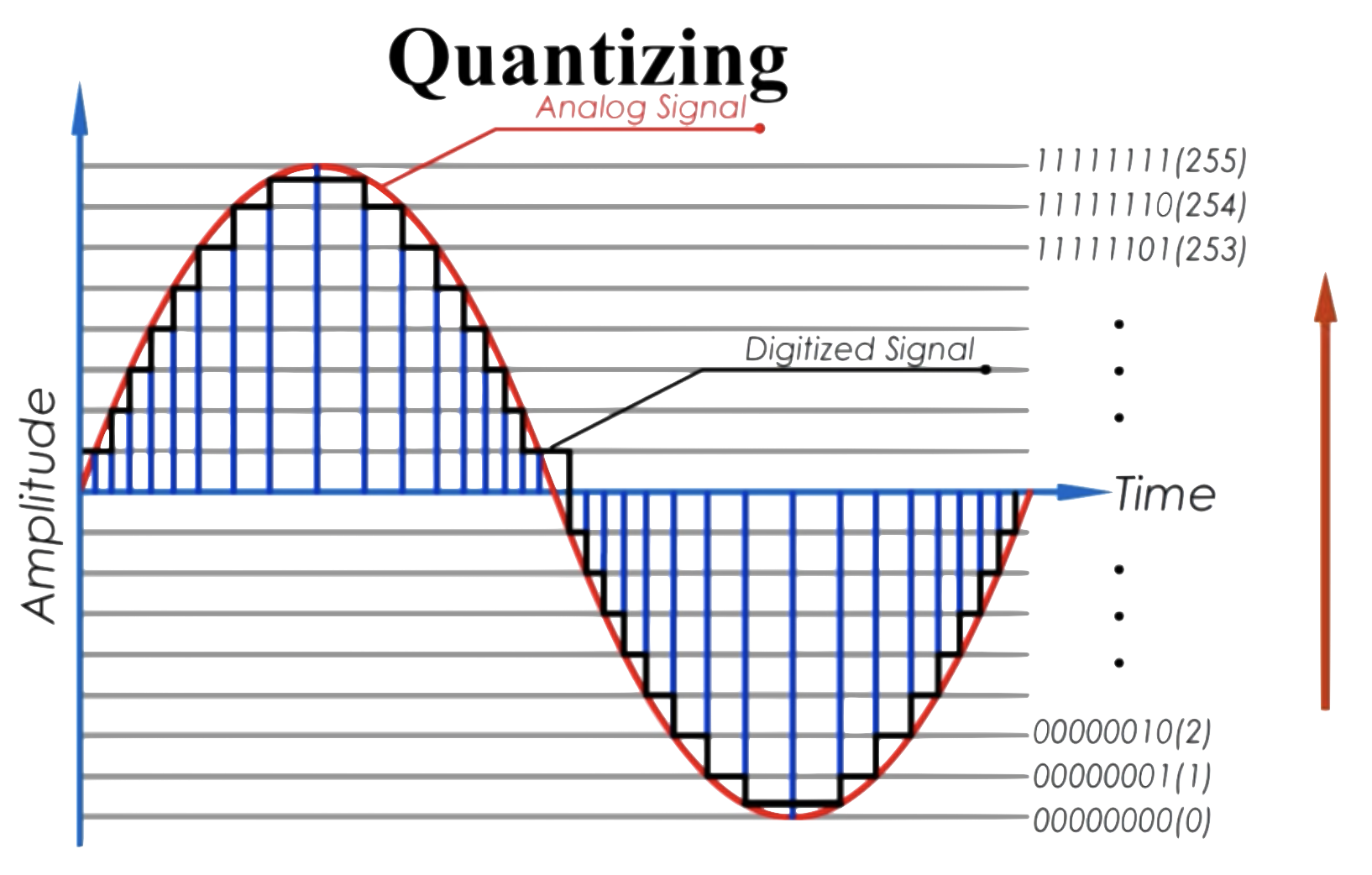
量化的過程就是將水平高度的樣本四舍五入到一個可用的並且最近的Level描述的過程。
## 編碼
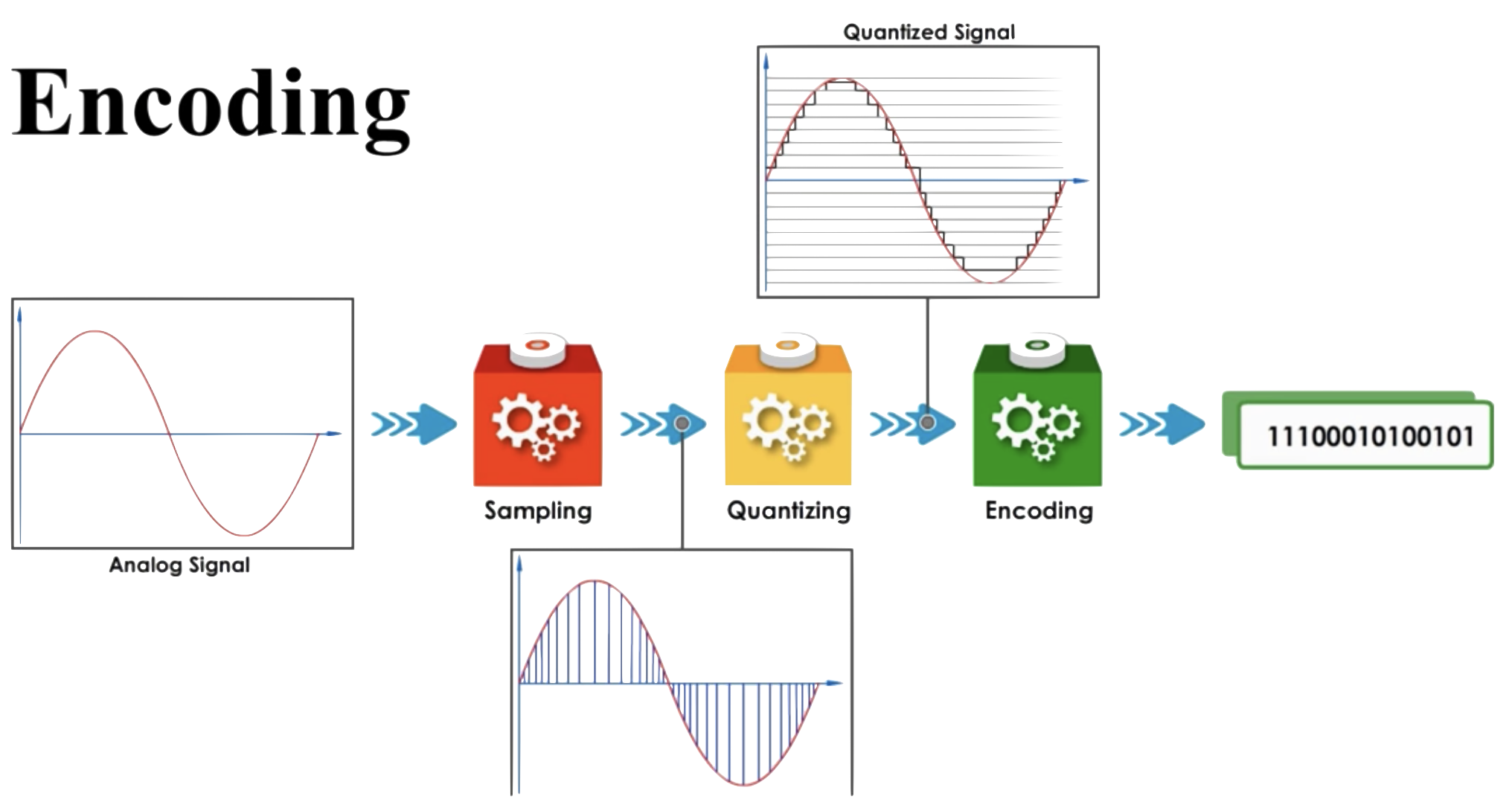
這里的編碼是指將每個sample數據轉換為二進制數據,該數據就是PCM數據。PCM數據可直接存儲在介質上,也可以經過編碼壓縮后進行存儲和傳輸。
PCM數據常用量化指標:**采樣率**、**位深度**、**聲道數**、**采樣數據是否有符號**(有符號的采樣數據不能使用無符號的方式播放)、**字節序**(表示PCM數據采樣是大端存儲還是小端存儲,通常為小端存儲)。例如:FFmpeg常見的PCM數據格式為s16le,表示有符號的16bit小端PCM數據。
## PCM數據存儲
例如一段有符號的8bit的PCM數據:
```
binary | 0010 0000 | 1010 0000 | ...
decimal| 32 | -96 | ...
```
其表示的采樣范圍是-128~127,當含有多個通道時,PCM數據通常會交織排列,以雙聲道為例:
```
FL | FR | FL | FR | FL | FR
```
對於8bit有符號的PCM數據而言,上圖表示第一個字節存放第一個左聲道數據、第二個字節存放第一個右聲道數據。不同的驅動程序對於多聲道數據的排列方式可能稍有區別,下面是常用的聲道排列圖:
```
2: FL FR (stereo)
3: FL FR LFE (2.1 surround)
4: FL FR BL BR (quad)
5: FL FR FC BL BR (quad + center)
6: FL FR FC LFE SL SR (5.1 surround - last two can also be BL BR)
7: FL FR FC LFE BC SL SR (6.1 surround)
8: FL FR FC LFE BL BR SL SR (7.1 surround)
```
## 音量調整
音量的表示實際上就是量化過程中每個采樣數據的Level值,只要適當地增大或者縮小采樣的Level就可以達到更改音量的目的。但是需要說明的是,並不是將Level乘以2就能得到兩倍於原聲的音量。
**數據溢出**:每個采樣數據的取值范圍是有限制的,例如一個signed 8bit的樣本,取值范圍為-128~127,值為125時,放大兩倍后的值為250,超過了可描述的范圍,此時發生了數據溢出。這個時候就需要我們做策略性的裁剪處理,使放大后的值符合當前格式的取值區間。
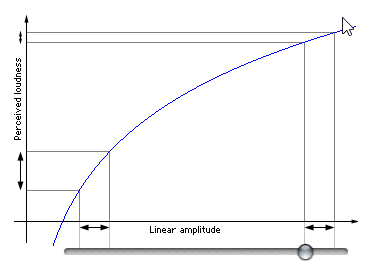
**對數描述**:平時表示聲音強度都是用分貝(db)作單位的,聲學領域中,分貝的定義是聲源功率與基准聲功率比值的對數乘以10的數值。**根據人耳的心理聲學模型,人耳對聲音感知程度是對數關系,而不是線性關系**。人類的聽覺反應是基於聲音的相對變化而非絕對的變化。對數標度正好能模仿人類耳朵對聲音的反應。所以用分貝作單位描述聲音強度更符合人類對聲音強度的感知。前面我們直接將聲音乘以某個值,也就是線性調節,調節音量時會感覺到剛開始音量變化很快,后面調的話好像都沒啥變化,使用對數關系調節音量的話聲音聽起來就會均勻增大.
如下圖,橫軸表示音量調節滑塊,縱坐標表示人耳感知到的音量,圖中取了兩塊橫軸變化相同的區域,音量滑塊滑動變化一樣, 但是人耳感覺到的音量變化是不一樣的,在左側也就是較安靜的地方,感覺到音量變化大,在右側聲音較大區域人耳感覺到的音量變化較小: