Github地址
https://github.com/huangyivi/3119005415
PSP表格
| *PSP2.1* | *Personal Software Process Stages* | *預估耗時(分鍾)* | *實際耗時(分鍾)* |
|---|---|---|---|
| Planning | 計划 | 30 | 40 |
| · Estimate | · 估計這個任務需要多少時間 | 30 | 30 |
| Development | 開發 | 1320 | 880 |
| · Analysis | · 需求分析 (包括學習新技術) | 30 | 40 |
| · Design Spec | · 生成設計文檔 | 40 | 40 |
| · Design Review | · 設計復審 | 20 | 20 |
| · Coding Standard | · 代碼規范 (為目前的開發制定合適的規范) | 10 | 10 |
| · Design | · 具體設計 | 60 | 60 |
| · Coding | · 具體編碼 | 240 | 180 |
| · Code Review | · 代碼復審 | 30 | 30 |
| · Test | · 測試(自我測試,修改代碼,提交修改) | 200 | 200 |
| Reporting | 報告 | 40 | 50 |
| · Test Repor | · 測試報告 | 20 | 20 |
| · Size Measurement | · 計算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后總結, 並提出過程改進計划 | 20 | 20 |
| · 合計 | 2400 | 1630 |
依賴介紹
jieba v0.42.1
- 支持三種分詞模式:
精確模式,試圖將句子最精確地切開,適合文本分析;
全模式,把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義;
搜索引擎模式,在精確模式的基礎上,對長詞再次切分,提高召回率,適合用於搜索引擎分詞。
- 支持繁體分詞
- 支持自定義詞典
- MIT 授權協議
gensim v4.1.0
-
介紹:Gensim(generate similarity)是一個簡單高效的自然語言處理Python庫,用於抽取文檔的語義主題(semantic topics)。Gensim的輸入是原始的、無結構的數字文本(純文本),內置的算法包括Word2Vec,FastText,潛在語義分析(Latent Semantic Analysis,LSA),潛在狄利克雷分布(Latent Dirichlet Allocation,LDA)等,通過計算訓練語料中的統計共現模式自動發現文檔的語義結構。這些算法都是非監督的,這意味着不需要人工輸入——僅僅需要一組純文本語料。一旦發現這些統計模式后,任何純文本(句子、短語、單詞)就能采用語義表示簡潔地表達。
-
特點:
- Memory independence: 不需要一次性將整個訓練語料讀入內存,Gensim充分利用了Python內置的生成器(generator)和迭代器(iterator)用於流式數據處理,內存效率是Gensim設計目標之一。
- Memory sharing: 訓練好的模型可以持久化到硬盤,和重載到內存。多個進程之間可以共享相同的數據,減少了內存消耗。
- 多種向量空間算法的高效實現: 包括Word2Vec,Doc2Vec,FastText,TF-IDF,LSA,LDA,隨機映射等。
- 支持多種數據結構。
- 基於語義表示的文檔相似度查詢
主要實現
流程圖

TF算法
TF-IDF(term frequency–inverse document frequency)是一種用於信息檢索與數據挖掘的常用加權技術,常用於挖掘文章中的關鍵詞,而且算法簡單高效,常被工業用於最開始的文本數據清洗。
TF-IDF有兩層意思,一層是"詞頻"(Term Frequency,縮寫為TF),另一層是"逆文檔頻率"(Inverse Document Frequency,縮寫為IDF)。
當有TF(詞頻)和IDF(逆文檔頻率)后,將這兩個詞相乘,就能得到一個詞的TF-IDF的值。某個詞在文章中的TF-IDF越大,那么一般而言這個詞在這篇文章的重要性會越高,所以通過計算文章中各個詞的TF-IDF,由大到小排序,排在最前面的幾個詞,就是該文章的關鍵詞。
第一步,計算詞頻:

考慮到文章有長短之分,為了便於不同文章的比較,進行"詞頻"標准化。

第二步,計算逆文檔頻率:
這時,需要一個語料庫(corpus),用來模擬語言的使用環境。

如果一個詞越常見,那么分母就越大,逆文檔頻率就越小越接近0。分母之所以要加1,是為了避免分母為0(即所有文檔都不包含該詞)。log表示對得到的值取對數。
第三步,計算TF-IDF:
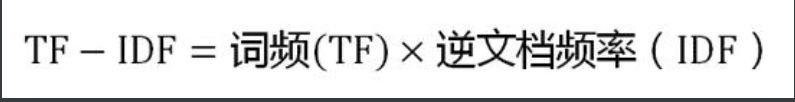
可以看到,TF-IDF與一個詞在文檔中的出現次數成正比,與該詞在整個語言中的出現次數成反比。所以,自動提取關鍵詞的算法就很清楚了,就是計算出文檔的每個詞的TF-IDF值,然后按降序排列,取排在最前面的幾個詞。
思路
- 首先,對文章句子進行拆分,生成句子列表,然后對每個句子進行分詞。
- 調用gensim模塊的corpora.Dictionary方法,對原文件進行詞典分析,生成語料庫。
- 通過gensim模塊的models.tf模型算法進行余弦相似度計算,並建立索引。
- 對待檢測文件進行遍歷,對每個句子選出最大相似度計算權重。
- 利用加權后的文章總權重除以文章總長度,得到結果。
關鍵函數
-
對文章進行分句

-
對句子進行分詞

-
計算相似度

異常處理
- 如果傳入路徑的目標文件不存在或者為空,則會拋出異常:

單元測試
-
引入unitest模塊,分別對五個待檢測的文件進行論文查重。
-
部分代碼:

-
運行結果如下:

性能分析
- 使用Pycharm性能分析工具的結果如下:

代碼覆蓋率
- 使用Pycharm的代碼覆蓋率查看如下,其中77%的代碼執行,剩余代碼為異常處理:

個人總結
- 由於之前沒有接觸過python代碼,因此在上手語言的部分花了比較多的時間,后面了解了TF算法以及python相關的庫,最后將本系統成功做出來了。
- 本項目讓我了解到一個工程需要注意的點,特別是在寫PSP表格的過程中,在完成項目的過程中根本沒有考慮這么多工序,相信在以后的開發中會對我有很大的幫助。