前言
開頭聲明,本教程僅供學習,請勿將其用於商業或非法用途。
個人感覺本文難度為爬蟲入門小進階,請大佬輕噴。
正文
登陸
網頁分析
超星平台的舊版登陸是需要驗證碼的
``` 當然在學習Python的道路上肯定會困難,沒有好的學習資料,怎么去學習呢? 學習Python中有不明白推薦加入交流Q群號:928946953 群里有志同道合的小伙伴,互幫互助, 群里有不錯的視頻學習教程和PDF! 還有大牛解答! ```
然而通過新版進去卻不需要直接輸入驗證碼(尚未測試過多次密碼錯誤后是否會出現驗證碼)
本着能簡化就簡化的理念(主要是懶),我們直接抓取這個新版的登陸頁面。
https://passport2.chaoxing.com/login?fid=&newversion=true&refer=http%3A%2F%2Fi.chaoxing.com
嘗試登陸,老套路了,避免登陸成功后跳轉出現很多包,我們直接輸入錯誤的登陸信息。結果很符合我們的預期,只多出了一個包
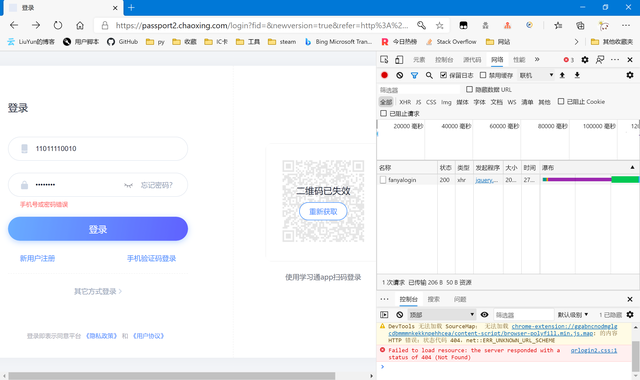
查看預覽,正好是提示我們的“用戶名或密碼錯誤”,我們查看提交的表單,一個個來分析。
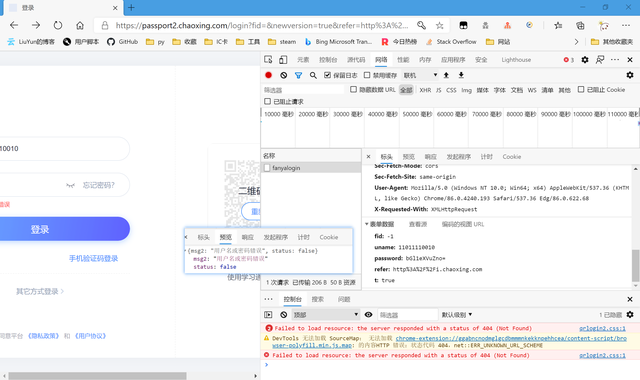
復制代碼 隱藏代碼 fid: -1 uname: 11011110010 password: bGl1eXVuZno= refer: http%3A%2F%2Fi.chaoxing.com t: true
不管fid,-1應該是一個常量。uname正好是我們輸入的手機號。password結尾有“=”,我們大膽猜測是base64編碼
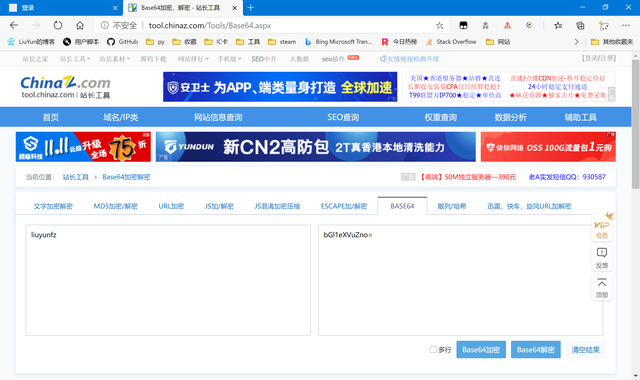
正好是我們輸入的密碼,那么password也搞定了。t是一個布爾值,也作為常量,refer我就不多解釋了,也把它作為常量吧。
代碼撰寫
照着我們的分析,我們嘗試利用python代碼模擬我們的登陸操作。
復制代碼 隱藏代碼 import requests,base64 def sign_in(username:str,password:str): url="https://passport2.chaoxing.com/fanyalogin" headers={ 'Accept':'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection':'keep-alive', 'Content-Length':'95', 'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8', 'Cookie':'', 'Host':'passport2.chaoxing.com', 'Origin':'https://passport2.chaoxing.com', 'Referer':'https://passport2.chaoxing.com/login?fid=&newversion=true&refer=http%3A%2F%2Fi.chaoxing.com', 'Sec-Fetch-Dest':'empty', 'Sec-Fetch-Mode':'cors', 'Sec-Fetch-Site':'same-origin', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36 Edg/86.0.622.68', 'X-Requested-With':'XMLHttpRequest' } data="fid=-1&uname={0}&password={1}&refer=http%253A%252F%252Fi.chaoxing.com&t=true".format(username,base64.b64encode(password.encode()).decode()) print(base64.b64encode(password.encode()).decode()) rsp=requests.post(url=url,headers=headers,data=data) print(rsp.text,rsp.status_code)
調試一下,我這里把私密信息打了馬賽克,但不影響看出成功。
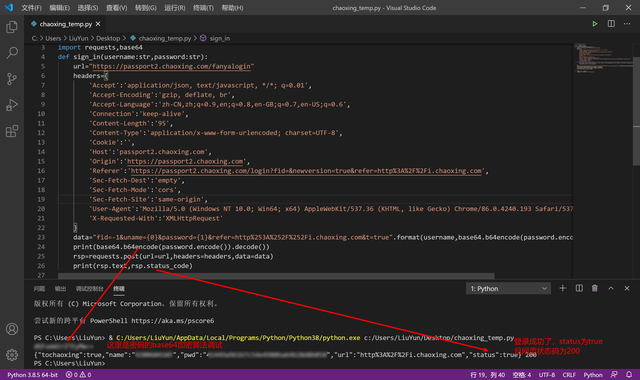
為了后續內容的順利進行,這邊我們再把登陸成功的cookie記錄下來
復制代碼 隱藏代碼
cookieStr = '' for item in rsp.cookies: cookieStr = cookieStr + item.name + '=' + item.value + ';' print(cookieStr)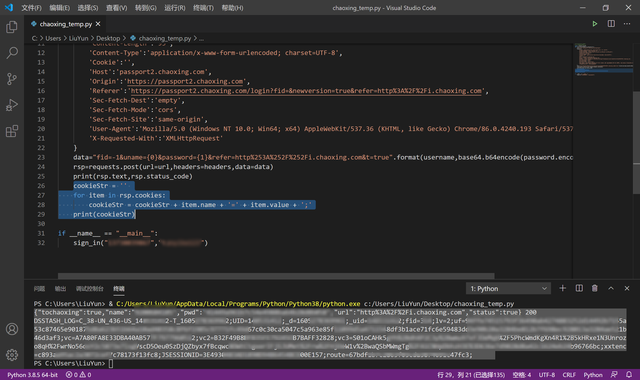
獲取課程
網頁分析
抓取課程信息
因為不能確定個人空間里面的課程內容是通過json獲取數據在本地渲染的還是服務器就渲染好后傳給用戶的。所以我們還是抓包看看。
查找我們的課程,發現在源代碼里並沒有找到,所以大概率是第一種可能,所以我們嘗試往下找傳遞課程數據的json包。
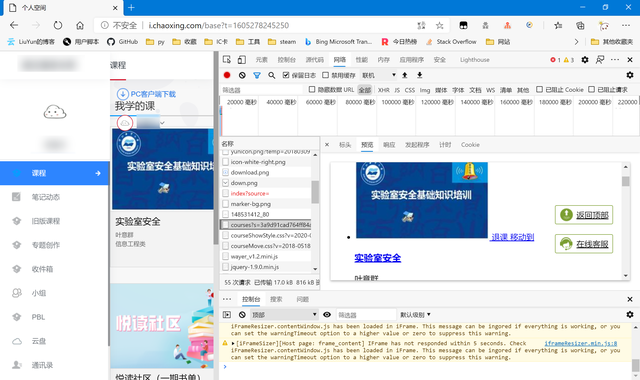
可以看到,成功找到了我們要的數據包,可惜並不是我們想要的json包,但問題也不大,只是增加了我們代碼解析時的復雜度。然后具體看我們抓到的這個課程數據包,請求方式為get,唯一麻煩的是參數s
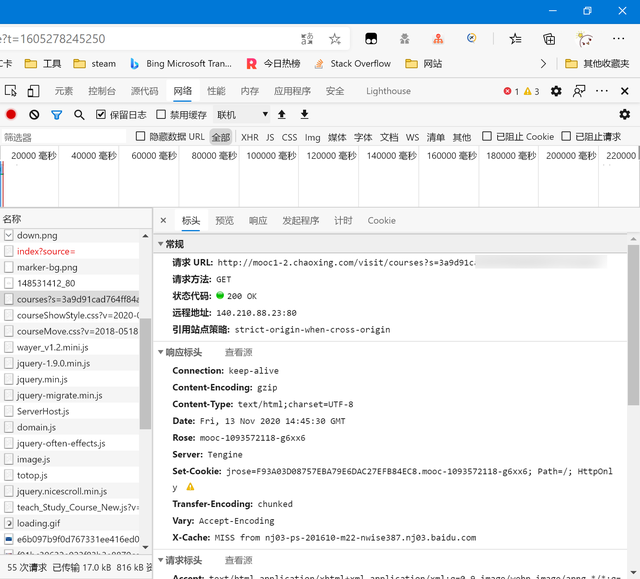
這個s參數肯定不會無故出現,所以我們往前尋找有沒有前面就給出了這個地址的,我們從最前面找,看看最初的那個空間地址包里面有沒有這個地址。
然而正當我打算嘗試時,我發現把s參數去掉了一樣可以正常訪問我們的課程數據
http://mooc1-2.chaoxing.com/visit/courses
那么為了盡可能簡化,我們還是能偷懶就偷懶。
然后我們跳到代碼階段,先試試前面的cookie能否正常使用,並且讀取到這個課程網頁的信息。
點我跳轉
解析課程信息
因為課程數據已經在
http://mooc1-2.chaoxing.com/visit/courses 這個包里給出了,但它又不是一個json,所以我們把它作為一個單獨的網頁來進行結構分析。
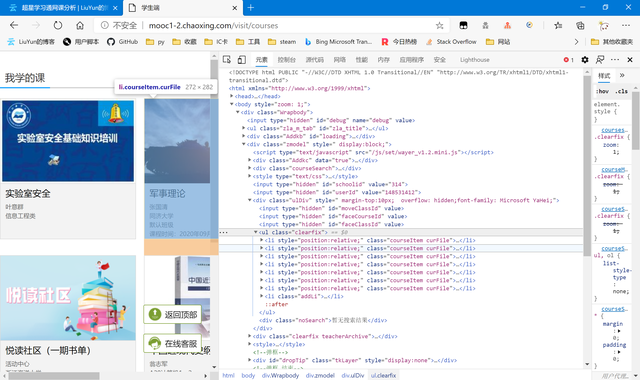
可以看到課程是一個ul結構下的多個li構成的。我們需要的里面每個課程的courseId classId與對應跳轉的url(因為url里包含了courseid與classid,所以我們可以選擇一是通過xpath先儲存並關聯url與對應的課程id;亦或是只獲取url,后面再從url里讀取參數courseid,classid等)。選中我們要的元素,右鍵復制xpath。
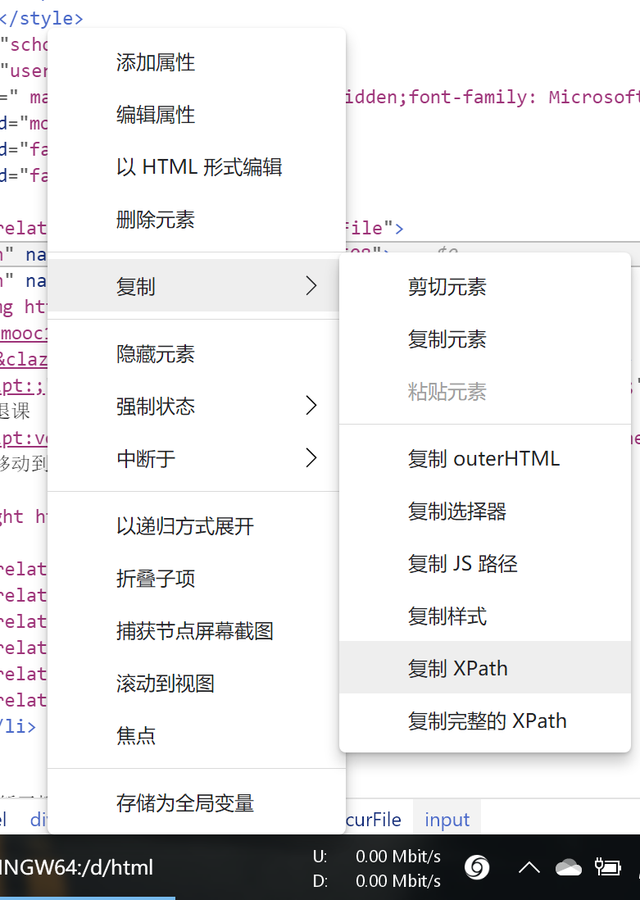
這里我選擇了第二種方案,只獲取url,courseid從url中讀取。我們繼續跳到代碼步驟。
點我跳轉
代碼撰寫
嘗試cookie與讀取課程信息
將登陸獲取到的cookie合並成cookiestr后傳入獲取課程信息的函數
復制代碼 隱藏代碼 def get_course(cookie:str): course_headers={ 'Cookie':cookie, 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51' } course_rsp=requests.get(url="http://mooc1-2.chaoxing.com/visit/courses",headers=course_headers) print(course_rsp.text)
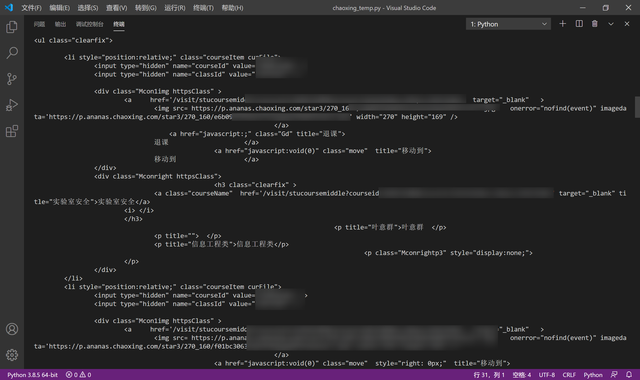
可以看到,成功獲取到了課程信息,同時也印證了我們前面登錄函數的可行性。
之后回到網頁,我們繼續分析網頁結構,使python可以解析我們的所有課程及相關信息。
點我跳轉
課程xpath書寫與重定向問題
復制代碼 隱藏代碼 def get_course(cookie:str): course_headers={ 'Cookie':cookie, 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51' } course_rsp=requests.get(url="http://mooc1-2.chaoxing.com/visit/courses",headers=course_headers) if course_rsp.status_code==200: from lxml import etree class_HTML=etree.HTML(course_rsp.text) print("處理成功,您當前已開啟的課程如下:\n") i=0 global course_dict course_dict={} for class_item in class_HTML.xpath("/html/body/div/div[2]/div[3]/ul/li[@class='courseItem curFile']"): #courseid=class_item.xpath("./input[@name='courseId']/@value")[0] #classid=class_item.xpath("./input[@name='classId']/@value")[0] try: class_item_name=class_item.xpath("./div[2]/h3/a/@title")[0] #等待開課的課程由於尚未對應鏈接,所有缺少a標簽。 i+=1 print(class_item_name) course_dict[i]=[class_item_name,"https://mooc1-2.chaoxing.com{}".format(class_item.xpath("./div[1]/a[1]/@href")[0])] except: pass print("———————————————————————————————————") else: print("error:課程處理失敗")

課程讀取成功了,課程的url與name也作為list被我們關聯儲存到了course_dict這個dict中(為了使序號與課程進行關聯,並且保持有序性)
課程獲取完后我們就可以開始針對單個課程,讀取里面的待完成視頻任務添加到程序任務里。然而,仔細觀察我們從html里獲取到的url

與我們手動訪問課程獲取的url

發現兩者並不相同,我們嘗試訪問html里的url,然后抓包看發生了什么
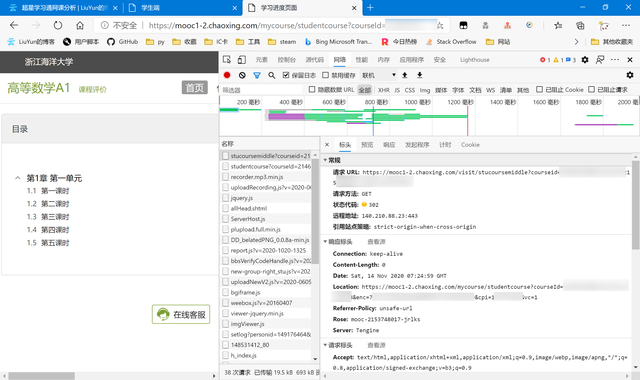
不出所料,果然url發生了302重定向。
本來requests庫是會識別302並自動跟隨跳轉的,但不知道為什么我這里出現了錯誤,並未跟隨跳轉,甚至讓我一度懷疑問題出在了cookie上。
復制代碼 隱藏代碼 def deal_course(url:str): course_302_url=url course_headers={ 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection':'keep-alive', 'Cookie':cookieStr, 'Host':'mooc1-2.chaoxing.com', 'Sec-Fetch-Dest':'document', 'Sec-Fetch-Mode':'navigate', 'Sec-Fetch-Site':'none', 'Upgrade-Insecure-Requests':'1', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51' } #302跳轉,requests庫默認追蹤headers里的location進行跳轉,使用allow_redirects=False course_302_rsp=requests.get(url=course_302_url,headers=course_headers,allow_redirects=False) new_url=course_302_rsp.headers['Location']
這樣,只需要將html里獲取到的url傳入到這個函數里,new_url就是我們要的真正的課程地址了。
真正的課程地址獲取完成了,接下來我們繼續回到網絡分析,分析單個課程中我們需要完成的任務。
課程任務
分析網頁
任意進入到一個課程中,通過觀察可以發現:白色無內容的——沒有任務;橙色有數字的——數字代表該章節的任務數;綠色勾勾的——有任務但已完成了的。
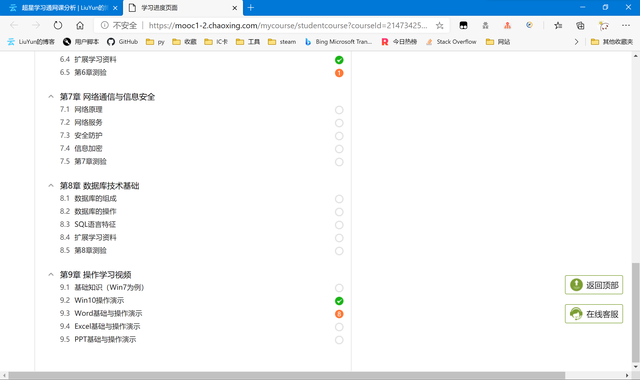
刷新一下,發現該課程地址就已經給出了相關的章節信息,即在服務端已經渲染好了再傳輸到用戶端,並沒有額外的json數據包。
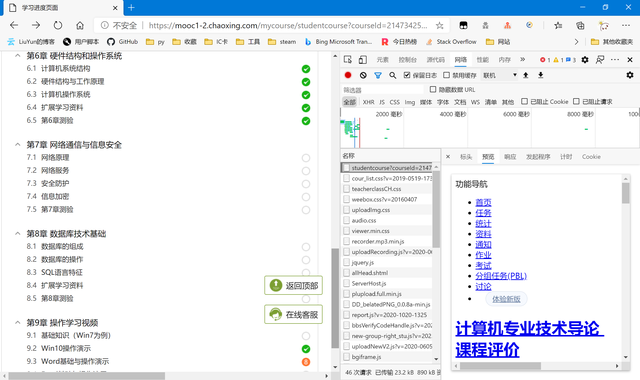
所以我們直接右鍵“檢查”,查看網頁元素。
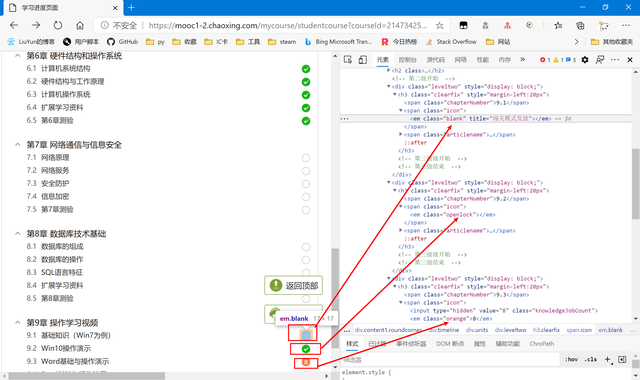
找規律可以發現,正常的沒有課程任務的,em元素的class是“blank”,如果有任務但已完成則是“openlock”,如果有任務但未完成則class為“orange”,且其text為任務數。
知道了這個,我們就好寫了,只需要判斷em元素class屬性是orange的,並把它對應的url寫入我們的任務列表里。所以接下來回到代碼環節
代碼編寫
章節信息判斷與未完成任務讀取
通過上面的分析,以及課程信息url的獲取,將其傳入的requests,獲取源代碼后即可進行判斷處理。
復制代碼 隱藏代碼 def add_misson(url:str): course_headers={ 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection':'keep-alive', 'Cookie':cookieStr, 'Host':'mooc1-2.chaoxing.com', 'Sec-Fetch-Dest':'document', 'Sec-Fetch-Mode':'navigate', 'Sec-Fetch-Site':'none', 'Upgrade-Insecure-Requests':'1', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51' } course_rsp=requests.get(url=url,headers=course_headers) course_HTML=etree.HTML(course_rsp.text) #為防止賬號沒有課程或沒有班級,需要后期在xpath獲取加入try,以防報錯 chapter_mission=[] try: for course_unit in course_HTML.xpath("/html/body/div[5]/div[1]/div[2]/div[3]/div"): print(course_unit.xpath("./h2/a/@title")[0]) for chapter_item in course_unit.xpath("./div"): chapter_status=chapter_item.xpath("./h3/span[@class='icon']/em/@class")[0] if chapter_status == "orange": print("----",chapter_item.xpath("./h3/span[@class='articlename']/a/@title")[0]," ",chapter_item.xpath("./h3/span[@class='icon']/em/text()")[0]) chapter_mission.append("https://mooc1-2.chaoxing.com{}".format(chapter_item.xpath("./h3/span[@class='articlename']/a/@href")[0])) else: print("----",chapter_item.xpath("./h3/span[@class='articlename']/a/@title")[0]," ",chapter_item.xpath("./h3/span[@class='icon']/em/@class")[0]) except: pass print("課程讀取完成,共有%d個章節可一鍵完成"%len(chapter_mission))
視頻任務點
因為要實現的是一鍵刷課程視頻,所以接下來我們要讀取的是章節任務里面的視頻任務點。
網頁分析
還是老樣子,先抓一下包。
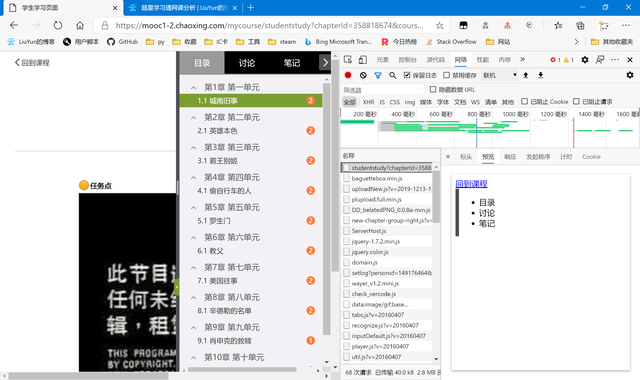
可以從預覽里看出,章節網頁似乎並沒有完全渲染完成后再傳輸給我們。通過查看響應里面的代碼,我們也驗證了猜想,並未找到有關的視頻數據。所以我們嘗試往下尋找包含視頻信息的json包或者html網頁。
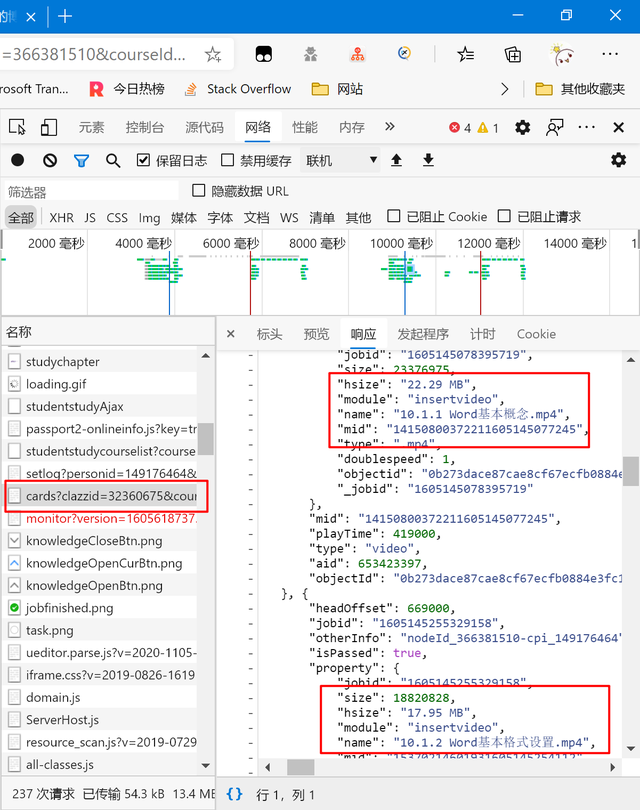
最后,在這個“/knowledge/cards”里的包里找到了我們要的數據,可惜它也不是json,而是一個html,里面有js代碼。所以我們還得自己提取代碼,並轉化成python可識別的內容。這邊的分析還是比較麻煩的,但並不算難,只能說不熟練的話需要多試試。這個就請自己嘗試看看吧,這邊就不給出具體分析過程了(因為自己也想不起來了,也不想再分析一遍,懶)。不過如果實在有問題的話也可以聯系我,和我交流交流。那我們就直接進入代碼環節然后給出代碼。
我們順便分析一下這些視頻數據代表的內容。
"isPassed"是任務點是否已完成,true為已完成,false為未完成,所以我們可以通過判斷它的屬性來直接判斷是否需要對該視頻進行處理。
"type": "video"是類型為視頻,也是我們判斷是否要添加到任務列表的一個條件(因為我們要實現的只有刷超星視頻),其他還有可能出現ppt這種。
其他其實通過名字也都能知道是什么,主要還是要看后面我們需要用到什么屬性。
代碼編寫
為了把js代碼提取出來並變成python中的dict或list,我這里用到了正則表達式,取出我們要的內容。
復制代碼 隱藏代碼 def deal_misson(missons:list,class_cpi:str): for chapter_mission_item in missons: result = parse.urlparse(chapter_mission_item) chapter_data=parse.parse_qs(result.query) print(chapter_data) medias_url="https://mooc1-2.chaoxing.com/knowledge/cards?clazzid={0}&courseid={1}&knowledgeid={2}&num=0&ut=s&cpi={3}&v=20160407-1".format(chapter_data.get('clazzid')[0],chapter_data.get('courseId')[0],chapter_data.get('chapterId')[0],class_cpi) class_headers={ 'Cookie':cookieStr, 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51' } medias_rsp=requests.get(url=medias_url,headers=class_headers) medias_HTML=etree.HTML(medias_rsp.text) medias_text=medias_HTML.xpath("//script[1]/text()")[0] import re,json pattern = re.compile(r'attachments":([\s\S]*),"defaults"') re_result=re.findall(pattern,medias_text)[0] reportUrl=re.findall(r'reportUrl":([\s\S]*),"chapterCapture"',medias_text)[0] reportUrl=reportUrl.replace("\"","") result_json=json.loads(re_result)
這里傳入的missons是每個章節的鏈接構成的一個list,至於class_cpi是課程的cpi信息,每個課程中的所有章節中的所有視頻都共用這個cpi屬性,而這個是后面完成視頻要用到的,針對我們現在判斷視頻任務並用不到。result_json即是我們從網頁代碼中提取出的json。
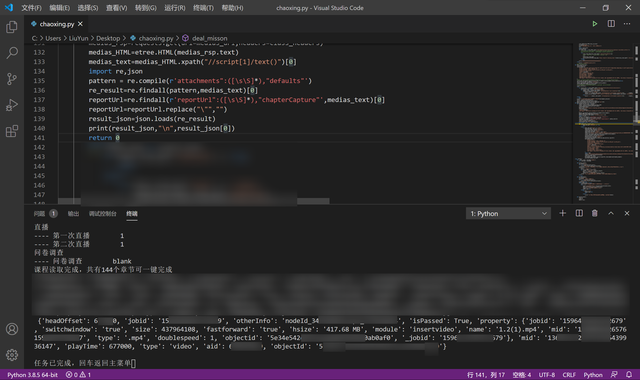
可以看到,調試成功了,而且是很完美的json格式,loads我們可以用list的操作方式輕松的調用其中的數據信息。
章節中的視頻信息我們也處理完成了,到此我們的准備工作已經都完成了。賬號登陸——判斷課程信息——判斷課程中的章節任務——判斷章節里面的視頻任務,最后一步就是完成章節里的視頻任務了,也是我們最后的大頭。
任務完成解析
抓包分析
打開“開發者選項”,進行抓包,然后播放視頻。出現了兩個包
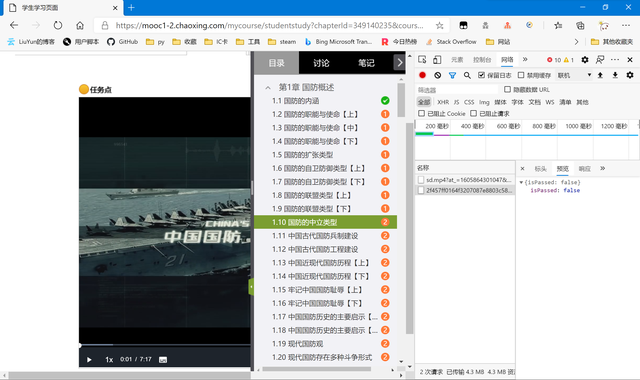
第一個是視頻的包,用於向服務器請求視頻數據,從其中的type,以及一些其他的headers都能看出來。
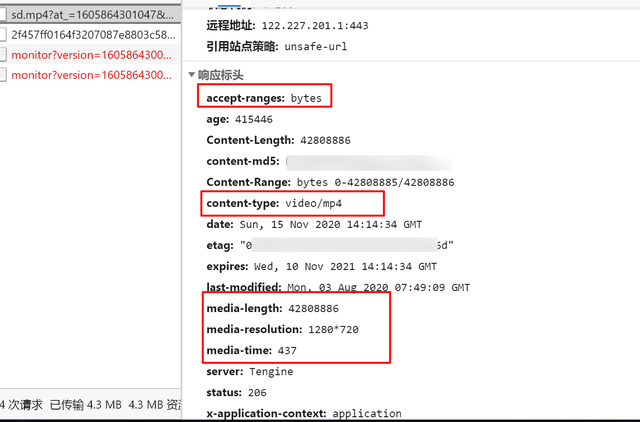
第二個包,就是我們要的用來完成任務的包了。它傳輸的是你觀看的數據,返回的isPassed來說明你的任務是否完成了。因為我們只是播放了一下,所以任務當然沒能完成,所以返回的數據是{"isPassed":false}。
然后我們等視頻放完,即將任務點完成,看它會發送什么包,與前面這個包有什么區別。

可以看出主要區別就在這個playingTime,翻譯下來也很好理解,應該就是我們播放了的時間。只要這個時間等於視頻的總長度,那么就算我們就完成了。接下來我們分析下提交的整個表單。
以下我將給出以上部分參數含義及來源的代碼依據。
clipTime
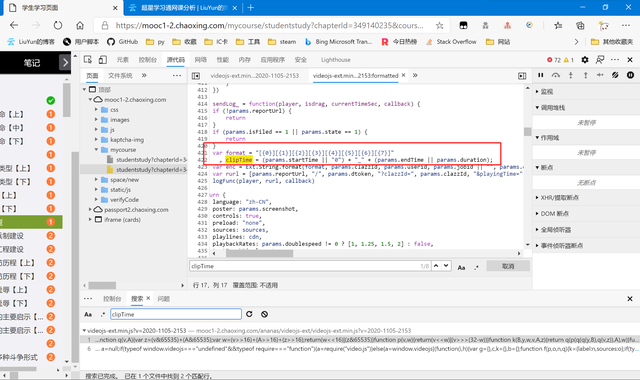
復制代碼 隱藏代碼 clipTime = (params.startTime || "0") + "_" + (params.endTime || params.duration);
以上是源代碼,不難看懂,clipTime的值是 起始時間或"0" + "_" + 終止時間或duration 。
isdrag
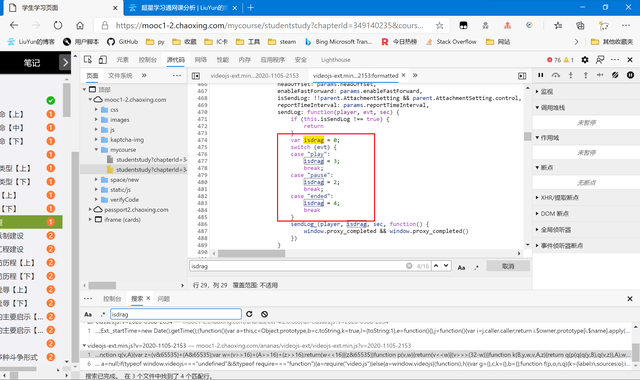
復制代碼 隱藏代碼 var isdrag = 0; switch (evt) { case "play": isdrag = 3; break; case "pause": isdrag = 2; break; case "ended": isdrag = 4; break }
因為我們要完成任務,自然是視頻播放完結束后發送的包,所以為ended,所以我們用“4”作為常量值。
rt
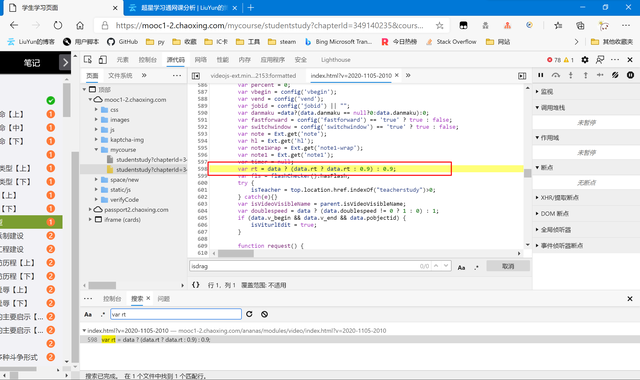
復制代碼 隱藏代碼
var rt = data ? (data.rt ? data.rt : 0.9) : 0.9;沒學過js的我也不太清楚這段話的具體作用,不過我們把“0.9”作為常量傳輸不會有任何異常。
這里有個小細節,就是當我們全站檢索“rt”時因為字符數較少,會出現較多的結果(因為很多函數或變量里都會包含這兩個字符,所以我們搜索 rt 的定義語句——“var rt”,即可減少結果。
enc
全文的最難點,以上所有數據的校驗碼。以下將給出我個人嘗試破解的詳細思路。
首先我選擇全站檢索enc,嘗試找到它的由來。
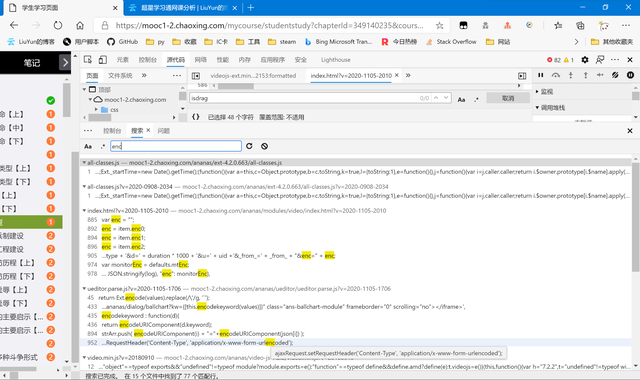
可以看到,出現了很多的數據(15個文件共77行匹配),所以為了縮小范圍,我嘗試跟上面的rt一樣操作,查詢enc的賦值語句。
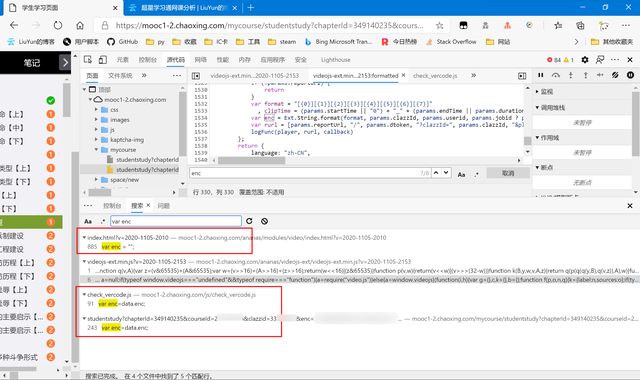
很有效果,結果只有4個文件5行匹配。而如圖紅色圈起來的代碼,雖然都對enc進行了賦值,但都不是我們要的語句。我們一個個手動排除,最后我鎖定了
https://mooc1-2.chaoxing.com/ananas/videojs-ext/videojs-ext.min.js 這個文件,細心的朋友可能已經發現了,就是我們剛才找clipTime的那個地方。
復制代碼 隱藏代碼 var sendLog_ = function(player, isdrag, currentTimeSec, callback) { if (!params.reportUrl) { return } if (params.isFiled == 1 || params.state == 1) { return } var format = "[{0}][{1}][{2}][{3}][{4}][{5}][{6}][{7}]" , clipTime = (params.startTime || "0") + "_" + (params.endTime || params.duration); var enc = Ext.String.format(format, params.clazzId, params.userid, params.jobid || "", params.objectId, currentTimeSec * 1000, "d_yHJ!$pdA~5", params.duration * 1000, clipTime); var rurl = [params.reportUrl, "/", params.dtoken, "?clazzId=", params.clazzId, "&playingTime=", currentTimeSec, "&duration=", params.duration, "&clipTime=", clipTime, "&objectId=", params.objectId, "&otherInfo=", params.otherInfo, "&jobid=", params.jobid, "&userid=", params.userid, "&isdrag=", isdrag, "&view=pc", "&enc=", md5(enc), "&rt=", params.rt, "&dtype=Video", "&_t=", new Date().getTime()].join(""); logFunc(player, rurl, callback) };
把里面關於enc的代碼提取出來
復制代碼 隱藏代碼 var format = "[{0}][{1}][{2}][{3}][{4}][{5}][{6}][{7}]" var enc = Ext.String.format(format, params.clazzId, params.userid, params.jobid || "", params.objectId, currentTimeSec * 1000, "d_yHJ!$pdA~5", params.duration * 1000, clipTime); "&enc=", md5(enc)
大致意思就是令
enc=[clazzId][userid][jobid][objectId][currentTimeSec 1000]["d_yHJ!$pdA~5"][duration 1000][clipTime]
然后再將取enc的md5,作為表單的校驗碼。這里面的參數多是前面已經分析過了的,只是中間多了一個字符串常量 \"d_yHJ!$pdA~5\" 。還有一個可能不太清楚的就是currentTimeSec了。
我們設置斷點,一邊看看這個currentTimeSec到底是啥,順便驗證下我們前面的是否正確。
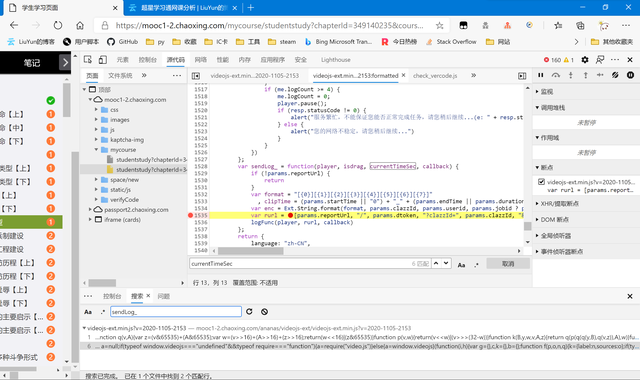
在這里設置斷點,然后我們刷新后重新播放視頻。將鼠標移到enc處,即可看到enc的值預覽。

這里因為隱私問題做打碼處理,可以自己嘗試,和我們前面說的基本無二。而currentTimeSec我們也發現了,currentTimeSec 1000跟 duration 1000 的值一模一樣。
截止目前,數據包里面的所有參數我們已經都弄明白了,接下來就是寫代碼就好了。
代碼書寫
以下是enc的返回函數
復制代碼 隱藏代碼 def encode_enc(clazzid:str,duration:int,objectId:str,otherinfo:str,jobid:str,userid:str): import hashlib data="[{0}][{1}][{2}][{3}][{4}][{5}][{6}][0_{7}]".format(clazzid,userid,jobid,objectId,duration*1000,"d_yHJ!$pdA~5",duration*1000,duration) print(data) return hashlib.md5(data.encode()).hexdigest()
然后是數據包的代碼
復制代碼 隱藏代碼 if video_item.get("isPassed") == True: pass else: if video_item.get("type") == "video": objectId=video_item.get("objectId") otherInfo=video_item.get("otherInfo") jobid=video_item.get("jobid") name=video_item.get('property').get('name') status_url="https://mooc1-1.chaoxing.com/ananas/status/{}?k=&flag=normal&_dc=1600850935908".format(objectId) status_rsp=requests.get(url=status_url,headers=class_headers) status_json=json.loads(status_rsp.text) duration=status_json.get('duration') dtoken=status_json.get('dtoken') print(objectId,otherInfo,jobid,uid,name,duration,reportUrl) multimedia_headers={ 'Accept':'*/*', 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection':'keep-alive', 'Content-Type':'application/json', 'Cookie':cookieStr, 'Host':'mooc1-1.chaoxing.com', 'Referer':'https://mooc1-1.chaoxing.com/ananas/modules/video/index.html?v=2020-0907-1546', 'Sec-Fetch-Dest':'empty', 'Sec-Fetch-Mode':'cors', 'Sec-Fetch-Site':'same-origin', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51' } import time elses="/{0}?clazzId={1}&playingTime={2}&duration={2}&clipTime=0_{2}&objectId={3}&otherInfo={4}&jobid={5}&userid={6}&isdrag=4&view=pc&enc={7}&rt=0.9&dtype=Video&_t={8}".format(dtoken,chapter_data.get('clazzid')[0],duration,objectId,otherInfo,jobid,uid,encode_enc(chapter_data.get('clazzid')[0],duration,objectId,otherInfo,jobid,uid),int(time.time()*1000)) reportUrl_item=reportUrl+str(elses) print(reportUrl_item) multimedia_rsp=requests.get(url=reportUrl_item,headers=multimedia_headers) print(multimedia_rsp.text)
結語
這篇文章還是斷斷續續寫了一個禮拜,里面我盡可能展示了我的思路。可以當作爬蟲學習入門的小進階,所以還是很值得記錄與分享的。
最后再次強調,本文僅作為經驗分享,請勿將其中內容二次修改用作商業用途。