目錄
前言
分析(x0)
分析(x1)
分析(x2)
分析(x3)
分析(x4)
總結
我有話說
前言
大家好,我叫善念,這是我的第三篇技術博文。音樂、小說、這次是視頻,估計下次就是圖片吧。
文章都是當天現寫的,自己也沒有去做過。
我們將要采集的網站是網頁版的DY數據:目標網址
咱們隨便選擇一個博主的視頻進行采集,我餓了我就找了個美食博主。
分析(x0)
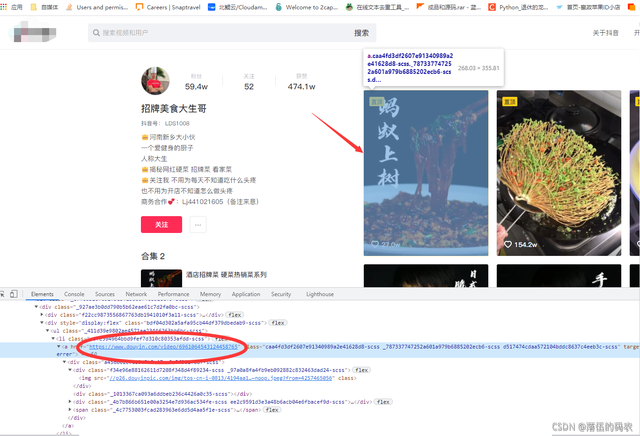
在網頁的元素中咱們可以找到當前視頻的跳轉鏈接:
而經過我觀察了一下我發現每個li標簽都包含了一條短視頻的信息:
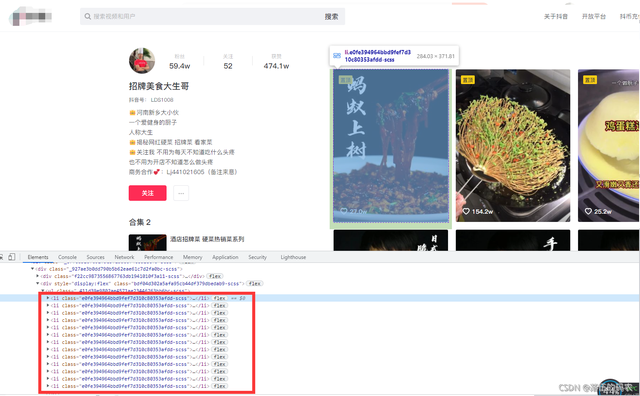
那么這里總共是13個li標簽,而咱們的這個博主肯定不止發了13個視頻吧?又不是我善念這種貨色只有幾十個粉絲,所以問題出在哪?
我已經猜到這個是一種瀑布流的模式加載視頻了,跟大家解釋一下。就是比如說一個網頁上面你只能看到十條數據,當你拉動網頁下滑條后它會自動加載一些新的數據出來。像瀑布一樣數據流出來,原理很簡單,就是你拉動下滑條的時候會觸發JavaScript腳本生成一些新數據
來做個測試:
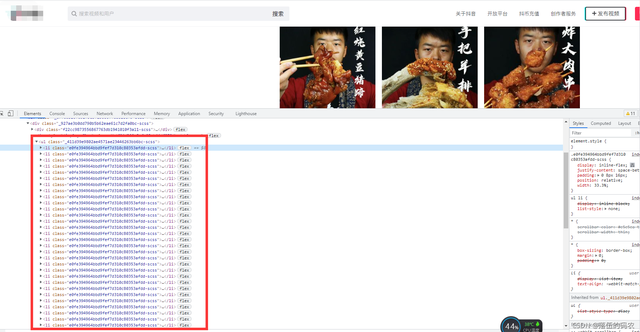
當我拉動瀏覽器的下滑條后,數據明顯增多,改變了網頁上的元素。
這里我再次解釋一下,網頁元素與網頁源代碼的區別:
網頁元素:瀏覽器執行一些JavaScript渲染之后的一個呈現(所以它會改變)
網頁源代碼:服務器傳給咱們瀏覽器的原始數據(經過瀏覽器的渲染后才會變成網頁元素)所以原始數據是不會變化的。
那么瀑布流的一個優勢是什么呢?明顯就是降低服務器的一個負荷吧?用戶想看多少數據就傳輸多少數據,而不是一股腦的全部加載完!
分析(x1)
也就是說明咱們根本無需去考慮網頁源代碼(因為不可變),已知網頁的視頻是由認為拉動瀏覽器下滑條執行JavaScript腳本然后通過接口傳輸數據給我們。
首先咱們可以觀察得到,每個視頻后面的那串數字就是視頻對應的ID值,前面肯定是不變的。
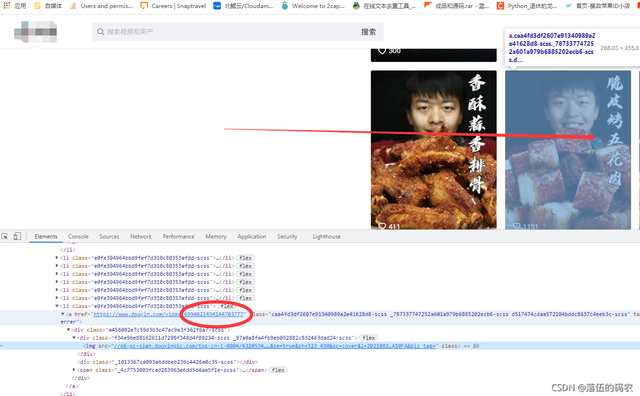
咱們直接抓包:
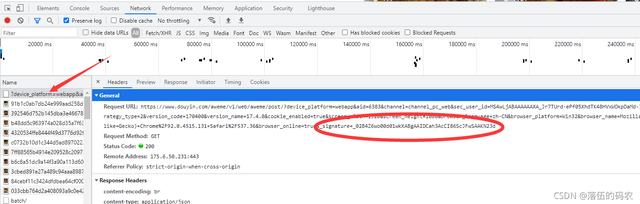
根據瀑布流的規律很容易抓到這個包,因為每滑動一下下拉條它就會生成一個新的這樣的包
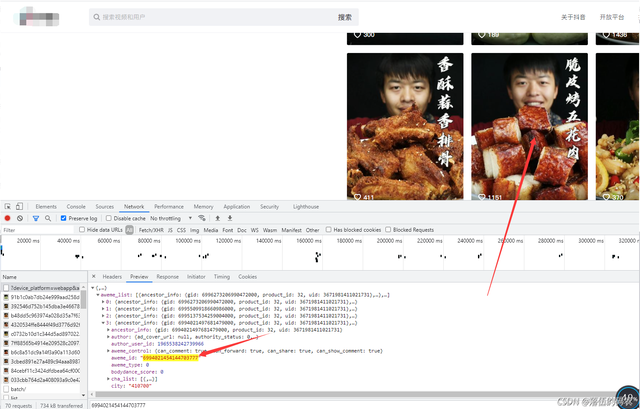
確實這個值是對應的,但是別忘了看我上上圖圈出來的那個_signature參數,傳說中的DY簽名加密。其它值均為固定值都是一些電腦信息,瀏覽器的版本。只有這個_signature是加密的,自己去手動拉動下滑條多抓幾個包就可以對比知道了。
分析(x2)
好吧,很多人覺得我會去解密這個參數,但是新版DY加密是有混淆的,就算是我能教各位也未必能學,所以我決定退而求次的用另外一種方法。
我們當時分析出,只要我們拉動滑塊,那么在網頁元素element中就會加載出新的視頻資料,出現更多的li標簽。
那么我們可以利用selenium去模擬人拉動下滑條吧?然后采集到視頻的跳轉鏈接,進行requests訪問,問題就解決了!
但是得到視頻跳轉鏈接有什么用呢?
分析(x3)
咱們先點到視頻里面看看:
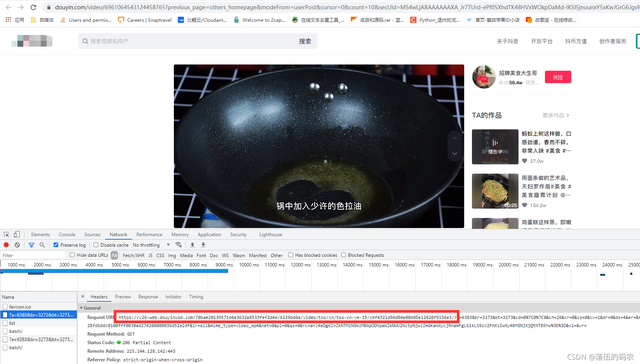
一下子就把視頻的源地址抓到了,可是這個地址完全看不出任何的規律......不過經過我上次給你們講的音樂的文章,你們應該知道如何分析了,首先這么長久嘗試着刪除一些參數,看是否還可以正常訪問。最短並且可以訪問的鏈接為我在紅色框框的鏈接。
那么然后.......還是找不到規律,不知道如何生成的,抓包也發現此包之前就是一個圖片的包而已。
分析(x4)
繼續看網頁元素中是否有咱們的視頻源地址吧:
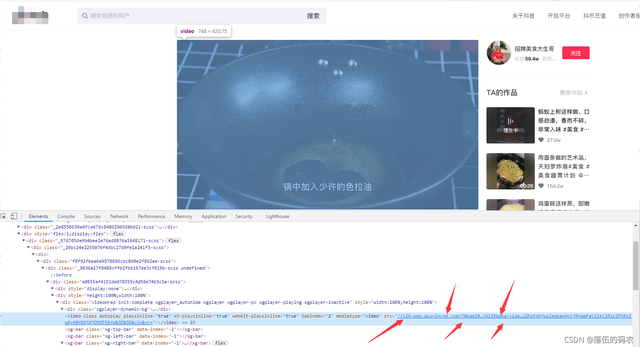
emmm果然有,我現在好希望源代碼中也有,因為我前面采集跳轉鏈接用了selenium已經降低了采集的速度,如果這里還是這樣用selenium的話速度就太慢了。
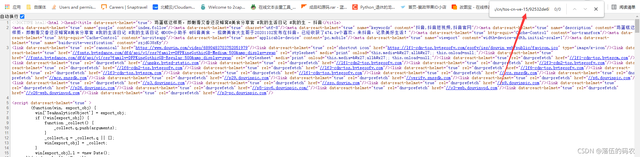
啥也沒搜到......按道理我前面抓包它也沒有JavaScript文件,就一個圖片的包,沒理由不存在網頁源代碼中的,我搜短一點試試:

不瞞你們說,我是自己第一次做,邊寫邊研究的,純粹的實戰。就這個東西我剛才眼睛都看花了,它把url進行編碼了,所以咱們看起來就很傷眼睛。
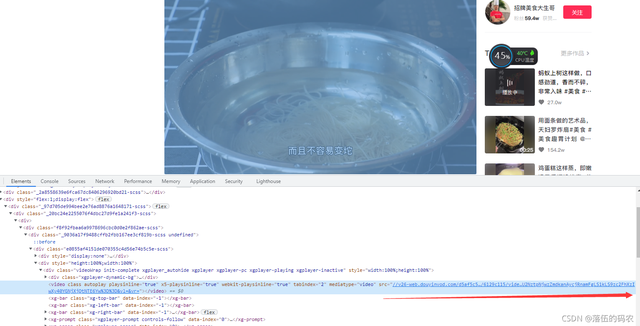
好吧,咱們只要采集到縮到最短的鏈接就可以了。
轉碼給大家看看:
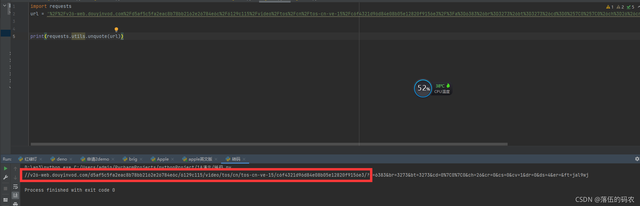
咱們只要紅框中的即可。
那么到現在的話所有的流程思路是不是走完了?
先用selenium采集到跳轉的url,然后用requests模塊請求跳轉的url,獲取到視頻源地址,最后請求源地址下載就好啦。
總結
這個只是采集單個博主的視頻,那么能否整站采集所有的視頻呢?我分析了一下,發現原理是一模一樣的.....是可以的!
我有話說
你是否在找源代碼?可惜了,我也是第一次做這個東西,我文章寫完的時候就是我最后分析完的時候,我自己也沒源代碼。
—— 紙上得來終覺淺,絕知此事要躬行。
如果這樣分析后還讓有些朋友覺得有難度,那么我再給大家看一個我之前講過的完美采集某寶的案例,selenium部分完美契合(在我主頁的聯系我中),requests部分就不說了,完全沒什么技術含量的,就兩個請求。
文章的話是現寫的,每篇文章我都會說得很細致,所以花費的時間比較久,一般都是兩個小時以上。
原創不易,再次謝謝大家的支持。
① 2000多本Python電子書(主流和經典的書籍應該都有了)
② Python標准庫資料(最全中文版)
③ 項目源碼(四五十個有趣且經典的練手項目及源碼)
④ Python基礎入門、爬蟲、web開發、大數據分析方面的視頻(適合小白學習)
⑤ Python學習路線圖(告別不入流的學習)
``` 當然在學習Python的道路上肯定會困難,沒有好的學習資料,怎么去學習呢? 學習Python中有不明白推薦加入交流Q群號:928946953 群里有志同道合的小伙伴,互幫互助, 群里有不錯的視頻學習教程和PDF! 還有大牛解答! ```
