一、互聯網架構遇到的問題
隨着大型互聯網公司業務的多元化發展,就拿滴滴、美團等大廠來講,如滴滴打車、單車、外賣、酒店、旅行、金融等業務持續高速增長,單個大型分布式體系的集群,通過加機器+集群內部拆分(kv、mq、Mysql等),雖然具備了一定的可擴展性。但是,隨着業務量的進一步增長,這個集群規模琢漸變的巨大,從而一定會在某個點達到性能瓶頸,無法滿足擴展性需要,並且大集群內核服務出現問題,會影響全網所有用戶。
以滴滴打車、美團外賣舉例來說:
打車業務體量巨大,尤其在早晚高峰期。全年訂單量已越10億。
外賣業務體量龐大,目前單量突破1700w/天,對應如此龐大的單個大型分布式集群,會面臨一下問題:
1、容災問題
2、資源擴展性問題
3、大集群拆分問
容災問題
核心服務(比如訂單服務)掛掉,會影影響全網所有的用戶,導致整個業務不可用;
數據庫主庫集中在一個IDC,主機房掛掉,會影響全網所有用戶,整個業務無法快速切換和恢復
資源擴展問題
單IDC的資源(機器、網絡帶寬等)已經沒法滿足,擴展IDC時,存在跨機房訪問延時問題(增加異地機房,時延問題嚴重)
數據庫主庫單點,連接數有限,不能支持應用程序的持續發展;
大集群拆分問題
核心問題:分布式集群規模擴大后,會響應的帶來資源擴展、大集群拆分以及容災問題
所有處於對業務擴展性以及容災需求的考慮,我們需要一套從底層架構徹底解決問題的方案,業界主流解決方案:單元化架構方案
二、SET單元化架構方案
(一)同城 "雙活" 架構介紹
同城雙活是在同城或相近區域內建立兩個機房。同城雙機房距離比較近,通信線路質量較好,比較容易實現數據的同步復制 ,保證高度的數據完整性和數據零丟失。同城兩個機房各承擔一部分流量,一般入口流量完全隨機,內部RPC調用盡量通過就近路由閉環在同機房,相當於兩個機房鏡像部署了兩個獨立集群,數據仍然是單點寫到主機房數據庫,然后實時同步到另外一個機房。下圖展示了同城雙活簡單部署架構,當然一般真實部署和考慮問題要遠遠比下圖復雜。

1、服務路由 zk集群:
每個機房都部署一個zk集群,機房之間zk數據進行實時雙向同步,每個機房都擁有所有機房zk注冊數據。 路由方案:條件路由 > 就近路由 > 跨機房路由,盡量避免跨機房調用。 訂閱方案:consumer訂閱所有機房服務,provider只向該機房zk集群進行注冊。
2、數據雙活 MySQL:
采用MHA部署方案,主從半同步方案保證數據一致性。讀寫分離、讀就近路由到機房內數據節點、寫路由到master節點所在機房。 Redis: Redis cluster模式主從同步,就近讀、寫路由主節點機房。采用原生主從同步跨機房寫性能較低,也可以依靠CRDT理論構建多節點雙向同步,實現機房就近讀寫,但是整體實現較為復雜。
3、同城雙活方案評估
優勢:
(1)服務同城雙活,數據同城災備,同城不丟失數據情況下跨機房級別容災。
(2)架構方案較為簡單,核心是解決底層數據雙活,由於雙機房距離近,通信質量好,底層儲存例如mysql可以采用同步復制,有效保證雙機房數據一致性。
劣勢:
(1)數據庫寫數據存在跨機房調用,在復雜業務以及鏈路下頻繁跨機房調用增加響應時間,影響系統性能和用戶體驗。
(2)保證同城市地區容災,當服務所在的城市或者地區網絡整體故障、發生不可抗拒的自然災害時候有服務故障以及丟失數據風險。對於核心金融業務至少要有跨地區級別的災備能力。
(3)服務規模足夠大(例如單體應用超過萬台機器),所有機器鏈接一個主數據庫實例會引起連接不足問題。
(二)兩地三中心架構介紹
所謂兩地三中心是指 同城雙中心 + 異地災備中心。異地災備中心是指在異地的城市建立一個備份的災備中心,用於雙中心的數據備份,數據和服務平時都是冷的,當雙中心所在城市或者地區出現異常而都無法對外提供服務的時候,異地災備中心可以用備份數據進行業務的恢復。

兩地三中心方案評估:
優勢:
(1)服務同城雙活,數據同城災備,同城不丟失數據情況下跨機房級別容災。
(2)架構方案較為簡單,核心是解決底層數據雙活,由於雙機房距離近,通信質量好,底層儲存例如mysql可以采用同步復制,有效保證雙機房數據一致性。
(3)災備中心能防范同城雙中心同時出現故障時候利用備份數據進行業務的恢復。
劣勢:
(1)數據庫寫數據存在跨機房調用,在復雜業務以及鏈路下頻繁跨機房調用增加響應時間,影響系統性能和用戶體驗。
(2)服務規模足夠大(例如單體應用超過萬台機器),所有機器鏈接一個主數據庫實例會引起連接不足問題。
(3)出問題不敢輕易將流量切往異地數據備份中心,異地的備份數據中心是冷的,平時沒有流量進入,因此出問題需要較長時間對異地災備機房進行驗證。
同城雙活和兩地三中心建設方案建設復雜度都不高,兩地三中心相比同城雙活有效解決了異地數據災備問題,但是依然不能解決同城雙活存在的多處缺點,想要解決這兩種架構存在的弊端就要引入更復雜的解決方案去解決這些問題。
三、異地多活與Set化部署
(一)異地多活
異地多活指分布在異地的多個站點同時對外提供服務的業務場景。異地多活是高可用架構設計的一種,與傳統的災備設計的最主要區別在於“多活”,即所有站點都是同時在對外提供服務的。
1、異地多活挑戰
(1)應用要走向異地,首先要面對的便是物理距離帶來的延時。如果某個應用請求需要在異地多個單元對同一行記錄進行修改,為滿足異地單元間數據庫數據的一致性和完整性,需要付出高昂的時間成本。
(2)解決異地高延時即要做到單元內數據讀寫封閉,不能出現不同單元對同一行數據進行修改,所以我們需要找到一個維度去划分單元。
(3)某個單元內訪問其他單元數據需要能正確路由到對應的單元,例如A用戶給B用戶轉賬,A用戶和B用戶數據不在一個單元內,對B用戶的操作能路由到相應的單元。
(4)面臨的數據同步挑戰,對於單元封閉的數據需全部同步到對應單元,對於讀寫分離類型的,我們要把中心的數據同步到單元。
2、單元化
所謂單元(下面我們用RZone代替),是指一個能完成所有業務操作的自包含集合,在這個集合中包含了所有業務所需的所有服務,以及分配給這個單元的數據。
單元化架構就是把單元作為系統部署的基本單位,在全站所有機房中部署數個單元,每個機房里的單元數目不定,任意一個單元都部署了系統所需的所有的應用。單元化架構下,服務仍然是分層的,不同的是每一層中的任意一個節點都屬於且僅屬於某一個單元,上層調用下層時,僅會選擇本單元內的節點。

選擇什么維度來進行流量切分,要從業務本身入手去分析。例如電商業務和金融的業務,最重要的流程即下單、支付、交易流程,通過對用戶id進行數據切分拆分是最好的選擇,買家的相關操作都會在買家所在的本單元內完成。對於商家相關操作則無法進行單元化,需要按照下面介紹的非單元化模式去部署。當然用戶操作業務並非完全能避免跨單元甚至是跨機房調用,例如兩個買家A和B轉賬業務,A和B所屬數據單元不一致的時候,對B進行操作就需要跨單元去完成,后面我們會介紹跨單元調用服務路由問題。
3、非單元化應用和數據
對於無法單元化的業務和應用,會存在下面兩種可能性:
(1)延時不銘感但是對數據一致性非常銘感,這類應用只能按照同城雙活方式部署。其他應用調用該類應用的時候會存在跨地區調用可能性,要能容忍延時,這類應用我們稱為MZone應用。
(2)對數據調用延時銘感但是可以容忍數據短時間不一致,這類應用和數據可以保持一個機房一份全量數據,機房之間以增量的方式實時同步,這類應用我們暫時稱為QZone。
加上兩種以上非單元化應用我們的機房部署可能是下面這樣,每個機房有兩個RZone,MZone保持類似兩地三中心部署方式,異地機房調用MZone服務需要跨地區、跨機房調用。而QZone每個機房都保持一份完整數據,機房之間通過數據鏈路實時相互同步。

4、請求路由
(1)Api入口網關
為了保證用戶請求能正確進入自己所屬單元,每一個機房都會部署流量入口網關集群。當用戶請求到達進入機房內最先進入到流量網關,流量網關能感知全局的流量分片情況,計算用戶所處流量單元並將流量轉發到對應的單元,這樣就可以將用戶請求路由到對應的單元內。

采用GateWayr轉發方式可以確定用戶單元從而將用戶流量路由到正確位置,但是HTTP轉發也會造成一定性能損耗。為了減少HTTP流量轉發量,可以在在用戶請求返回的時候在cookie上帶上該用戶的路由標識信息。當用戶下次在請求的時候請求的時候可以提前獲取到路由標識直接請求到對應的單元,這種方式可以大幅度減少HTTP流量轉發。
(2)服務路由
雖然應用已經進行了單元化,但是依然無法避免跨單元調用,例如A用戶給B用戶轉賬,如果A和B所處單元不同,對B用戶操作需要跨單元去調用,這個時候需要能將請求路由到B用戶數據所在的單元。異地多活情況下RPC、MQ、DB等等中間件都需要提供路由能力,將請求能正確路由到對應的單元。下面以RPC路由為例說明異地多活下中間件是如何進行路由的,對於其他中間件(數據庫中間件、緩存中間、消息中間件等)也是一樣方法。
public interface ManualInterventionFacade { @ZoneRoute(zoneType= ZoneType.RZone,uidClass = UidParseClass.class) ManualRecommendResponse getManualRecommendCommodity(ManualRecommendRequest request); }
上面展示了多活下的RPC接口定義方法,需要注明該RPC類型,如果是RZone服務必須要提供解析uid方法。下圖展示了RPC注冊中心路由尋址過程,和同城雙活有一定的差異性。

5、數據同步
(1)QZone類型數據:這種數據只需要保證最終一致性,對於短暫不一致無影響,但是對延時非常銘感,例如一些算法、風控、配置等數據。這類數據基本上都是每個機房部署一套QZone,然后機房之間相互同步。

(2)MZone數據:這類數據對一致性非常銘感,不能出現不一致,只能采用同城雙活部署方式,業務需要能容忍異地調用延時。

(3)RZone數據:這類數據每個Zone都有自己的主節點,如果數據不在該單元內需要路由到對應的節點去寫。這類數據部署情況像下面這樣

6、方案評估
優勢:
容災能力大幅度提高,服務異地多活,數據異地多活。
理論上系統服務可以水平擴展,異地多機房突破大幅度提升整體容量,理論上不會有性能擔憂。
將用戶流量切分到多個機房和地區去,有效能減少機房和地區級別的故障影響范圍。
劣勢
架構非常復雜,部署和運維成本很高,需要對公司依賴的中間件、儲存做多方面能力改造。
對業務系統有一定的侵入性,由於單元化影響服務調用或者寫入數據要路由到對應的單元,業務系統需要設置路由標識(例如uid)。
無法完全避免跨單元、跨地區調用服務,例如上面的轉賬業務。我們要做的是盡力避免跨地區的服務調用。
(二)Set化部署
Set化部署實際就是在異地多活的基礎上衍生出來的。
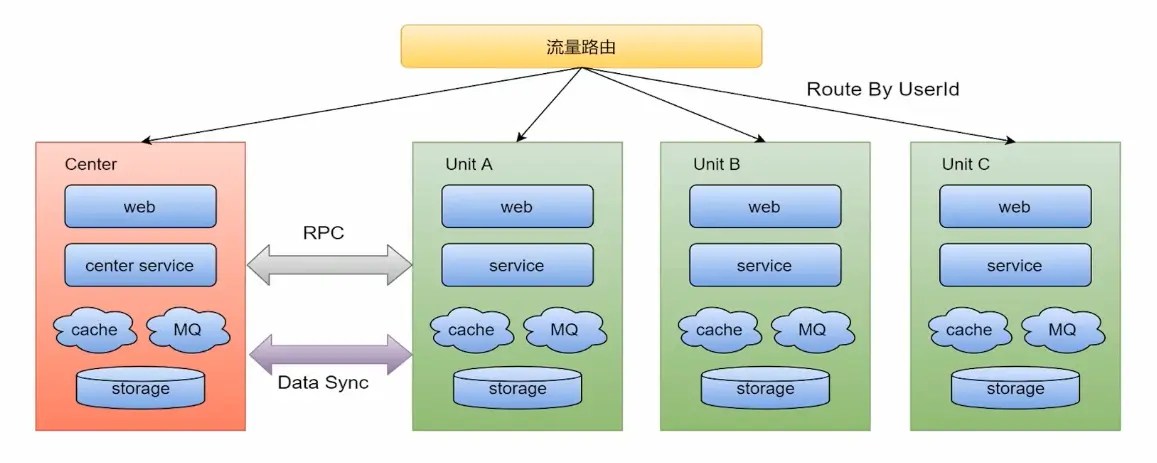
解決容災問題: UnitA一套業務的核心組件,比如網購,從加入購物車到下單,經過A、B、C、D等步驟,全部部署到UnitA的一個機房中,UnitB和UnitC是UnitA的備份,如果UnitA的服務或MQ發生故障,就會路由到UnitB或UnitC中 非核心的業務組件部署到center中 解決擴展問題: UnitA可以是旅游,UnitB可以是外賣,將來還可以擴展
相關概念
流量路由:按照特殊的key(通常為userid)進行路由,判斷某次請求該路由到中心集群還是單元化集群
中心集群:為進行單元化改造的服務(通常不在核心交易鏈路)成為中心集群,跟當前架構保存一致
單元化集群: 每個單元化集群只負責本單元內的流量處理,以及實現流量拆分及故障隔離。每個單元化集群前期只存儲本單元產生的交易數據,后續會做雙向數據同步,實現容災切換需求
中間件(RPC、KV、MQ等)
RPC:對於SET服務,調用封閉在SET內;對於非SET服務,沿用現有路由邏輯
KV:支持分SET的數據產生和查詢
MQ:支持分SET的消息生產和消費
數據同步:全局數據(數據量小且變化不大,比如商家的菜品數據)部署在中心集群,其他單元化集群同步全局數據到本單元化內。未來演變為異地多活架構時,各單元化集群數據需要進行雙向同步來實現容災需要
SET化路由策略及其能力
異地容災: 通過SET化架構的流量調度能力,將SET分別部署到不停地區的數據中心,實現跨地區容災支持
高效本地化服務:利用前端位置信息采集和域名解析策略,將流量路由由最近的SET,提供最高效的本地化服務 比如O2O場景天然具有本地生產,本地消費的特點,更加需要SET化支持
集裝箱式擴展 SET的封裝性支持更靈活的部署擴展性,比如SET一鍵創建/下線,SET一鍵發布等(比如docker)
(三)RabbitMQ-SET化架構實現
SET化消息中間件架構實現(RabbitMQ雙活)
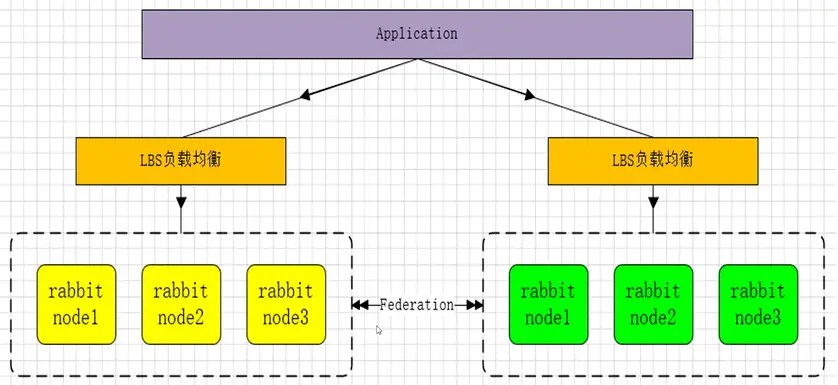
使用RabbitMQ異步消息通信插件 Federation(節點和節點、集群和集群之間通信) 安裝與配置:
安裝插件
rabbitmq-plugins enable rabbitmq_federation
rabbitmq-plugins enable rabbitmq_federation_management
備注:當你再一個cluster鍾使用了federation插件,所有在集群中的 nodes都需要安裝federation插件
使用RabbitMQ通信插件Rederation:
Federation插件是一個在不需要cluster進行數據同步的(選擇一個cluster中的節點和另一個cluster節點同步),而brokers之間傳輸消息的高新性能插件。
Federation插件可以在brokers或者cluster之間傳輸消息,鏈接的雙方可以使用不同的users和virtual hosts、或者雙方的rabbitmq和erlang版本不一致,federation插件使用AMQP協議通信,可以接受不連續的傳輸。
SET化配置規則:
1、Federation Exchanges,可以看成Downstream(82節點)從Upstream(81節點)主動拉取消息,並不是拉取所有消息,必須是在Downstream上已經明確定義Bindings關系的Exchange,也就是有實際的物理Queue來接收消息,才會從Upstream拉取消息到Downstream。使用AMQP協議實施代理間通信,Downstream會將綁定關系組合在一起,綁定/解綁命令將發送到Upstream交換機。
2、經過配置后,Upstream節點已經可以把消息直接通過Federation Exchanges路由給我們的Downstream節點,然后進行消費。
也就是說可以實現消息的轉發,接下來也可以在Upstream添加具體的隊列去進行消費Federation Exchanges里的消息,我們一條消息分別發送到2個RabbitMQ集群並且消費,這樣我們可以實現SET化的關鍵要素,就是集群間的消息同步了。
3、可以根據自己的業務規則去規划不同的集群去監聽不同的消息隊列,從而達到SET化的手段,保障了性能、可靠性、數據一致性。
MQ組件實現思路和架構設計方案
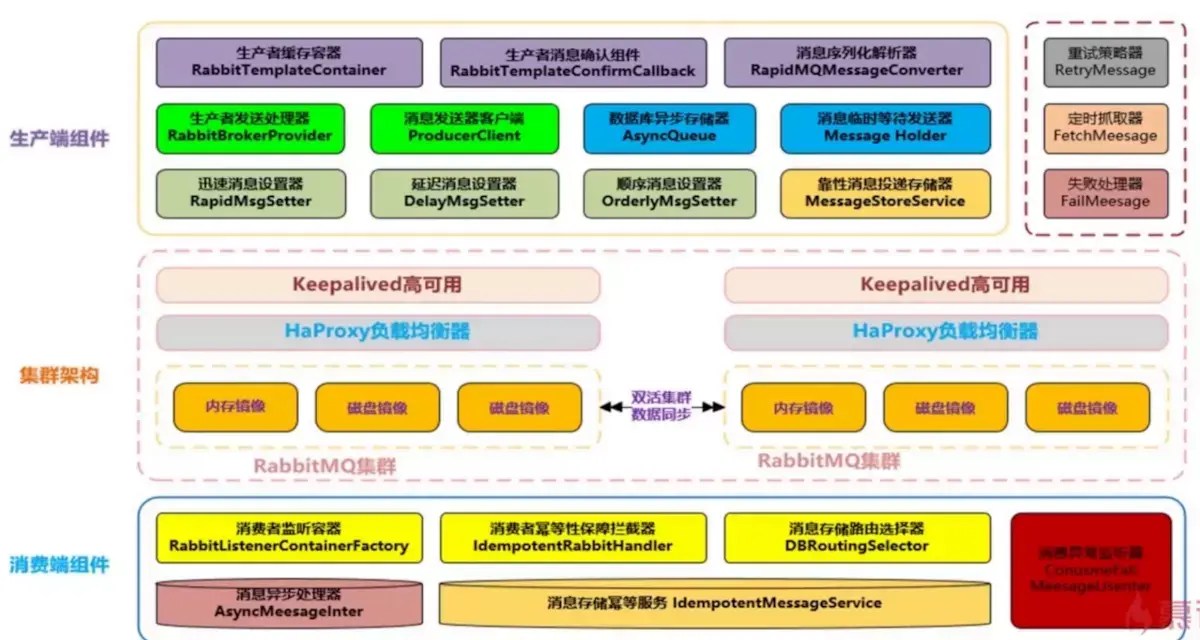
MQ組件需要實現功能點
支持消息高性能序列化轉換、異步化發送消息
支持消息生產實例與消費實例的鏈接池化、緩存化,提升性能
支持可靠性投遞消息,保障消息的100%不丟失
支持消費端的冪等操作,避免消費端重復消費的問題
支持迅速消息發送模式,在一些日志收集、統計分析等需求下可以保證高性能,超高吞吐量(可忽略100%投遞)
支持延遲消息模式,消息可以延遲發送,指定延遲時間,用於某些延遲檢查、服務限流場景
支持事務消息,且100%保障可靠性投遞,在金融行業單筆大金額操作是會有此類需求
支持順序消息,保證消費送達消費端的前后順序,例如下訂單,再送積分、優惠券等復合性操作
支持消息補償,重試,以及快速定位異常/失敗消息
支持集群消息負載均衡,保障消息落到具體SET集群的負責均衡
支持消息路由策略,指定某些消息路由到指定的SET集群