前言
前幾天我想看一個番劇, 正好搜索到了 PP視頻,我才知道PP視頻就是PPTV聚力,我想把番劇下載下來,結果發現視頻竟然不是m3u8格式,而是多段mp4,所以簡單的寫了個腳本,可以在不登錄的情況下直接下載vip和付費視頻藍光畫質(只能說明這個視頻網站做的不行)
開始分析
經過調試我首先得到了視頻地址的url

https://10314.vcdn.pplive.cn/0/0/1/2de8f8694a79c437a11b09941fb1cb0a.mp4?h5vod.ver=2.1.3&k=0b6a74e50374776203bd05d55a090fba-e800-1588284812&type=mhpptv
當然,我當時拿到的url 是很長的一段還有其他參數,但是我發現那些參數都是無用的影響訪問的參數只有這幾個
h5vod.ver : 固定值
type : 固定值
k : 變值
說明 k 是一個接口得到的, 所以我需要找到對應的接口就可以了
但是現在還有一個問題就是 這個只是視頻的一段, 其他視頻分段地址又是什么樣的呢?
經過我反復調試發現 url 中的
https://10314.vcdn.pplive.cn/a/b/c/
(對應位置我用字母來代替數字了,為了描述方便)
a 分段視頻的第幾段
b 默認為0 就可以(具體表示什么不清楚,但是瞎填肯定是不行的)
c 這個數字可以隨意瞎填,因為后台解析沒用到這個參數,但是要有這個參數
a 為 0 第一段視頻, a 為 1 為第二段視頻
所以接下來的問題就是找到那個接口了
經過調試發現了一個接口
https://web-play.pptv.com/webplay3-0-12407631.xml?o=0&version=6&type=mhpptv&appid=pptv.web.h5&appplt=web&appver=4.0.7&cb=a
這個接口參數只有一個變量 那就是12407631,也就是id,每一集都有唯一的 id ,而這個id 我們也可以通過訪問對應視頻播放界面的url后返回的html源碼中查看到

返回的不只是一集,而是全劇的每一集id都可以通過一個url來獲取到
那么我們來看看 這個接口返回了哪些內容

幾種畫質的 mp4,知道這些那么我們還差一個 k參數就可以構造視頻的url了
經過我查找發現了k值, 一個視頻的一種清晰度對應唯一一個k值

這里用了url編碼看起來亂七八糟,用python解碼一下
from urllib.parse import unquote print(unquote("4e6a8848fb388e09708a132bf4caeb4e-5775-1588285899%26bppcataid%3D17"))
輸出:
4e6a8848fb388e09708a132bf4caeb4e-5775-1588285899&bppcataid=17可以看到 & 符號前面的就是k ,所以到時候我們可以用& 進行分割然后取出 k
到此看起來問題全部解決了我們也可以構造視頻url 了,但是還有一個問題, 那就是視頻到底分多少段我們還不知道, 畢竟我們不能遍歷去訪問直到訪問不到數據(那樣太傻了)
其實接口里面也存在這樣的數據了
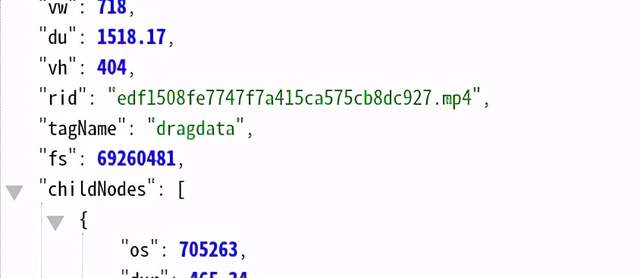
畫質下面mp4 字段 childNodes 是一個列表,這個列表的長度減1 就是不同畫質的分段數, 減1 是因為最后一個元素識別的內容不是描述視頻分段信息的, 不得不說這個接口返回的數據構造的真是及其混亂, 我解析的時候都費了很大勁!
到此為止問題全部解決
python代碼
import requests import re import json import os from threading import Thread import sys import time requests.packages.urllib3.disable_warnings() def progress(): width=30 while True: global all_num global now_num percent = now_num/all_num * 100 left = int(width * percent // 100) right = width - left print('\r[', '#' * left, ' ' * right, ']',f' {percent:.0f}%',sep='', end='', flush=True) if all_num == now_num: break time.sleep(1) def hecheng(sh,path): # 判斷是否只是一段視頻 if len(os.listdir(path)) <= 2: os.remove(path+os.sep+"1.txt") else: os.system(sh) for i in os.listdir(path): if i != 'output.mp4': os.remove(path+os.sep+i) def download(url,id_,name): global now_num data = requests.get(url,headers={"Range": "bytes=0-"},stream=True).content with open(name+os.sep+str(id_)+'.mp4','wb') as f: f.write(data) now_num += 1 def api_get(id_): global all_num global now_num all_num = 0 now_num = 0 api_url = f"https://web-play.pptv.com/webplay3-0-{id_}.xml?o=0&version=6&type=mhpptv&appid=pptv.web.h5&appplt=web&appver=4.0.7&cb=a" s = requests.get(api_url,verify=False,headers=headers) data = json.loads(s.text[2:-4]) try: name = data['childNodes'][2]['nm'] except Exception: name = data['childNodes'][0]['nm'] print("正在下載:"+name) rid = data['childNodes'][-4]['rid'] all_num = len(data['childNodes'][-4]['childNodes']) -1 kk = data['childNodes'][-5]['childNodes'][-1]['childNodes'][0].split('%26')[0] if not os.path.exists(name): os.makedirs(name) # 合成命令 a1 = os.path.abspath(name+os.sep+'1.txt') a2 = os.path.abspath(name+os.sep+'output.mp4') sh = f'ffmpeg -f concat -safe 0 -i "{a1}" -c copy "{a2}" -loglevel error' path = os.path.dirname(a1) # 啟動進度條線程 progress_t = Thread(target=progress) progress_t.start() t_list = [] t_list.append(progress_t) f = open(name+os.sep+'1.txt','w') for i in range(all_num): video_url = f"https://10314.vcdn.pplive.cn/{i}/0/1/{rid}?h5vod.ver=2.1.3&k={kk}&type=mhpptv" f.write("file "+ os.path.abspath(name+os.sep+f'{i}.mp4')+"\n") t = Thread(target=download,args=(video_url,i,name)) t_list.append(t) t.start() if not mul_t: t.join() f.close() for t in t_list: t.join() # print(sh) print("\n"+name+" 正在合成...") hecheng(sh,path) print(name+" 合並成功") def start(url,is_all,s,e,mul_t): response = requests.get(url,verify=False,headers=headers) if response.status_code == 200: result = re.findall("var webcfg = (.*?);",response.text) data = json.loads(result[0]) if is_all: # 下載劇集 try: for item in data['playList']['data']['list'][s-1:e]: api_get(item['id']) except Exception: for item in data['playList']['data']['list']: api_get(item['id']) else: # 下載單集 api_get(data['id']) if __name__ == "__main__": all_num = 0 now_num = 0 headers = { "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36" } url = input("輸入地址:") is_all = input("是否下載全劇(默認否):") if is_all: r = input("請輸入下載劇集(例如1-5,默認全部):") if r: s,e = r.split("-") s = int(s) if e: e = int(e) else: e = None else: s = None e = None mul_t = input("是否啟用多線程下載(默認否):") start(url,is_all,s,e,mul_t)
也是做了一個簡單的命令行工具,功能有限
- 通過一次輸入可以下載全集的藍光畫質視頻
- 下載vip 視頻
- 下載付費視頻
- 下載完分段視頻自動調用 ffmpeg 命令進行合成
- 選擇性 下載 m-n 集視頻
- 多線程下載(下載電影的時候最好不要開啟)
使用方法: 視頻播放界面的url輸入進去,然后回車, 剩下的參數不寫直接回車相當於默認, 隨意寫什么相當於是
其他注意 : windows 使用調用 ffmpeg先要把其加入系統環境變量里面,另外 第 81 行代碼應改為
f.write("file "+ (os.path.abspath(name+os.sep+f'{i}.mp4')+"\n").replace("\\","\\\\"))
這個主要是windows 腦殘的文件路徑問題