Service
Service 是應用服務的抽象,通過 labels 為應用提供負載均衡和服務發現。匹配 labels 的Pod IP 和端口列表組成 endpoints,由 kube-proxy 負責將服務 IP 負載均衡到這些endpoints 上。
每個 Service 都會自動分配一個 cluster IP(僅在集群內部可訪問的虛擬地址)和 DNS 名,其他容器可以通過該地址或 DNS 來訪問服務,而不需要了解后端容器的運行。
Pod、RC與Service的邏輯關系。

可以通過type在ServiceSpec中指定一個需要的類型的 Service,Service的四種type:
- ClusterIP(默認): 在集群中內部IP上暴露服務。此類型使Service只能從群集中訪問。
- NodePort :通過每個 Node 上的 IP 和靜態端口(NodePort)暴露服務。NodePort 服務會路由到 ClusterIP 服務,這個 ClusterIP 服務會自動創建。通過請求 nodeip: nodeport,可以從集群的外部訪問一個 NodePort 服務。
- LoadBalancer :使用雲提供商的負載均衡器(如果支持),可以向外部暴露服務。外部的負載均衡器可以路由到 NodePort 服務和 ClusterIP 服務。
- ExternalName :通過返回 CNAME 和它的值,可以將服務映射到 externalName 字段的內容,沒有任何類型代理被創建。這種類型需要v1.7版本或更高版本kube-dnsc才支持。
首先,Node IP是Kubernetes集群中每個節點的物理網卡的IP地址,是一個真實存在的物理網絡,所有屬於這個網絡的服務器都能通過這個網絡直接通信,不管其中是否有部分節點不屬於這個Kubernetes集群。這也表明在Kubernetes集群之外的節點訪問Kubernetes集群之內的某個節點或者TCP/IP服務時,都必須通過Node IP通信。
其次,Pod IP是每個Pod的IP地址,它是Docker Engine根據docker0網橋的IP地址段進行分配的,通常是一個虛擬的二層網絡,前面說過,Kubernetes要求位於不同Node上的Pod都能夠彼此直接通信,所以Kubernetes里一個Pod里的容器訪問另外一個Pod里的容器時,就是通過Pod IP所在的虛擬二層網絡進行通信的,而真實的TCP/IP流量是通過Node IP所在的物理網卡流出的。最后說說Service的Cluster IP,它也是一種虛擬的IP,但更像一個“偽造”的IP網絡,原因有以下幾點。
- Cluster IP僅僅作用於Kubernetes Service這個對象,並由Kubernetes管理和分配IP地址(來源於Cluster IP地址池)。
- Cluster IP無法被Ping,因為沒有一個“實體網絡對象”來響應。
- Cluster IP只能結合Service Port組成一個具體的通信端口,單獨的Cluster IP不具備TCP/IP通信的基礎,並且它們屬於Kubernetes集群這樣一個封閉的空間,集群外的節點如果要訪問這個通信端口,則需要做一些額外的工作。
在Kubernetes集群內,Node IP網、Pod IP網與Cluster IP網之間的通信,采用的是Kubernetes自己設計的一種編程方式的特殊路由規則,與我們熟知的IP路由有很大的不同。
Service的Cluster IP屬於Kubernetes集群內部的地址,無法在集群外部直接使用這個地址。那么矛盾來了:實際上在我們開發的業務系統中肯定多少有一部分服務是要提供給Kubernetes集群外部的應用或者用戶來使用的,典型的例子就是Web端的服務模塊,那么用戶怎么訪問它?采用NodePort是解決上述問題的最直接、有效的常見做法。
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
spec:
type: NodePort #
ports:
- port: 8080
nodePort: 31002 #
selector:
tier: frontend
nodePort:31002指定tomcat-service的NodePort的為31002,否則kubernetes會自動分配一個可用的端口。但NodePort還沒有完全解決外部訪問Service的所有問題,比如負載均衡問題。假如集群中有10個Node,則此時最好有一個負載均衡器,外部的請求只需訪問此負載均衡器的IP地址,由負載均衡器負責轉發流量到后面某個Node的NodePort上
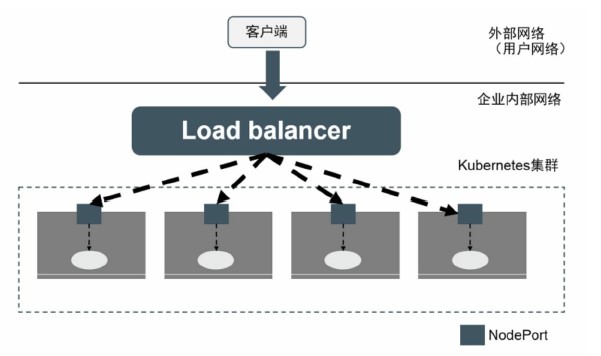
圖中的Load balancer組件獨立於Kubernetes集群之外,通常是一個硬件的負載均衡器,或者是以軟件方式實現的,例如HAProxy或者Nginx。對於每個Service,我們通常需要配置一個對應的Load balancer實例來轉發流量到后端的Node上,這的確增加了工作量及出錯的概率。
於是Kubernetes提供了自動化的解決方案,如果我們的集群運行在谷歌的公有雲GCE上,那么只要把Service的type=NodePort改為type=LoadBalancer,Kubernetes就會自動創建一個對應的Load balancer實例並返回它的IP地址供外部客戶端使用。其他公有雲提供商只要實現了支持此特性的驅動,則也可以達到上述目的。
Headless Service
在某些應用場景中,開發人員希望自己控制負載均衡策略,不使用Service提供的默認負載均衡功能,或者服務希望知道屬於同組的其他實例。此時可以使用Headless Service來實現,即不為Service設置ClusterIP,僅通過Label Selector將后端的Pod列表返回給調用的客戶端。
spec:
ports:
- port: 80
clusterIP: None
selector:
app: nginx
這樣,Service就不再具有一個特定的ClusterIP地址,對其進行訪問將獲得包含Label“app=nginx”的全部Pod列表,然后客戶端程序自行決定如何處理這個Pod列表。例如,StatefulSet就是使用Headless Service為客
戶端返回多個服務地址的。對於“去中心化”類的應用集群,Headless Service將非常有用。
service selector
service通過selector和pod建立關聯。
k8s會根據service關聯到pod的podIP信息組合成一個endpoint。
若service定義中沒有selector字段,service被創建時,endpoint controller不會自動創建endpoint。
service 負載分發策略有兩種
-
RoundRobin:輪詢模式,即輪詢將請求轉發到后端的各個pod上(默認模式);
-
SessionAffinity:基於客戶端IP地址進行會話保持的模式,第一次客戶端訪問后端某個pod,之后的請求都轉發到這個pod上。
服務發現
雖然Service解決了Pod的服務發現問題,但不提前知道Service的IP,怎么發現service服務呢?
k8s提供了兩種方式進行服務發現:
環境變量: 當創建一個Pod的時候,kubelet會在該Pod中注入集群內所有Service的相關環境變量。需要注意的是,要想一個Pod中注入某個Service的環境變量,則必須Service要先比該Pod創建。這一點,幾乎使得這種方式進行服務發現不可用。
一個ServiceName為redis-master的Service,對應的ClusterIP:Port為10.0.0.11:6379,則其在pod中對應的環境變量為:
REDIS_MASTER_SERVICE_HOST=10.0.0.11 REDIS_MASTER_SERVICE_PORT=6379 REDIS_MASTER_PORT=tcp://10.0.0.11:6379 REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379 REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379 REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
DNS:可以通過cluster add-on的方式輕松的創建KubeDNS來對集群內的Service進行服務發現————這也是k8s官方強烈推薦的方式。為了讓Pod中的容器可以使用kube-dns來解析域名,k8s會修改容器的/etc/resolv.conf配置。
Ingress
service的作用體現在兩個方面,對集群內部,它不斷跟蹤pod的變化,更新endpoint中對應pod的對象,提供了ip不斷變化的pod的服務發現機制,對集群外部,他類似負載均衡器,可以在集群內外部對pod進行訪問。但是,單獨用service暴露服務的方式,在實際生產環境中不太合適:
- ClusterIP 只能在集群內部訪問
- NodePort 測試環境使用還行,當有幾十上百的服務在集群中運行時,NodePort的端口管理簡直是災難
- LoadBalance 這種方式受限於雲平台,且通常在雲平台部署ELB還需要額外的費用。
所幸k8s還提供了一種集群維度暴露服務的方式,也就是ingress。ingress可以簡單理解為service的service,他通過獨立的ingress對象來制定請求轉發的規則,把請求路由到一個或多個service中。這樣就把服務與請求規則解耦了,可以從業務維度統一考慮業務的暴露,而不用為每個service單獨考慮。
舉個例子,現在集群有api、文件存儲、前端3個service,可以通過一個ingress對象來實現圖中的請求轉發:
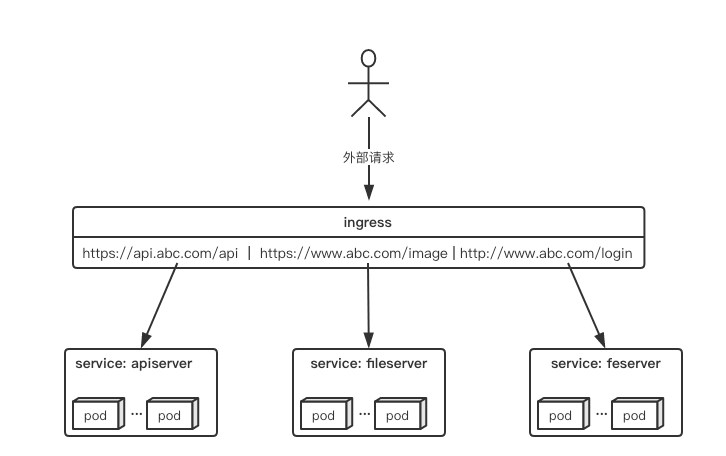
ingress與ingress-controller
要理解ingress,需要區分兩個概念,ingress和ingress-controller:
- ingress對象:指的是k8s中的一個api對象,一般用yaml配置。作用是定義請求如何轉發到service的規則,可以理解為配置模板。
- ingress-controller:具體實現反向代理及負載均衡的程序,對ingress定義的規則進行解析,根據配置的規則來實現請求轉發。
簡單來說,ingress-controller才是負責具體轉發的組件,通過各種方式將它暴露在集群入口,外部對集群的請求流量會先到ingress-controller,而ingress對象是用來告訴ingress-controller該如何轉發請求,比如哪些域名哪些path要轉發到哪些服務等等。
ingress-controller
實際上ingress-controller只是一個統稱,用戶可以選擇不同的ingress-controller實現,目前,由k8s維護的ingress-controller只有google雲的GCE與ingress-nginx兩個,其他還有很多第三方維護的ingress-controller,具體可以參考官方文檔。但是不管哪一種ingress-controller,實現的機制都大同小異。
一般來說,ingress-controller的形式都是一個pod,里面跑着daemon程序和反向代理程序。daemon負責不斷監控集群的變化,根據ingress對象生成配置並應用新配置到反向代理,比如nginx-ingress就是動態生成nginx配置,動態更新upstream,並在需要的時候reload程序應用新配置。
ingress
ingress是一個API對象,和其他對象一樣,通過yaml文件來配置。ingress通過http或https暴露集群內部service,給service提供外部URL、負載均衡、SSL/TLS能力以及基於host的方向代理。ingress要依靠ingress-controller來具體實現以上功能。上面的圖如果用ingress來表示,大概就是如下配置:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: abc-ingress
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/use-regex: "true"
spec:
tls:
- hosts:
- api.abc.com
secretName: abc-tls
rules:
- host: api.abc.com
http:
paths:
- backend:
serviceName: apiserver
servicePort: 80
- host: www.abc.com
http:
paths:
- path: /image/*
backend:
serviceName: fileserver
servicePort: 80
- host: www.abc.com
http:
paths:
- backend:
serviceName: feserver
servicePort: 8080
與其他k8s對象一樣,ingress配置也包含了apiVersion、kind、metadata、spec等關鍵字段。有幾個關注的在spec字段中,tls用於定義https密鑰、證書。rule用於指定請求路由規則。
ingress的部署方式
ingress的部署,需要考慮兩個方面:
- ingress-controller是作為pod來運行的,以什么方式部署比較好?
- ingress解決了把如何請求路由到集群內部,那它自己怎么暴露給外部比較好?
下面列舉一些目前常見的部署和暴露方式,具體使用哪種方式還是得根據實際需求來考慮決定。
Deployment+LoadBalancer模式
如果要把ingress部署在公有雲,那用這種方式比較合適。用Deployment部署ingress-controller,創建一個type為LoadBalancer的service關聯這組pod。大部分公有雲,都會為LoadBalancer的service自動創建一個負載均衡器,通常還綁定了公網地址。只要把域名解析指向該地址,就實現了集群服務的對外暴露。
Deployment+NodePort模式
同樣用deployment模式部署ingress-controller,並創建對應的服務,但是type為NodePort。這樣,ingress就會暴露在集群節點ip的特定端口上。由於nodeport暴露的端口是隨機端口,一般會在前面再搭建一套負載均衡器來轉發請求。該方式一般用於宿主機是相對固定的環境ip地址不變的場景。NodePort方式暴露ingress雖然簡單方便,但是NodePort多了一層NAT,在請求量級很大時可能對性能會有一定影響。
DaemonSet+HostNetwork+nodeSelector
用DaemonSet結合Nodeselector來部署ingress-controller到特定的node上,然后使用HostNetwork直接把該pod與宿主機node的網絡打通,直接使用宿主機的80/433端口就能訪問服務。
這時,ingress-controller所在的node機器就很類似傳統架構的邊緣節點,比如機房入口的nginx服務器。該方式整個請求鏈路最簡單,性能相對NodePort模式更好。缺點是由於直接利用宿主機節點的網絡和端口,一個node只能部署一個ingress-controller pod。比較適合大並發的生產環境使用。
關於ingress-nginx
具體可以參考ingress-nginx的官方文檔。同時,在生產環境使用ingress-nginx還有很多要考慮的地方,這篇文章寫得很好,總結了不少最佳實踐,值得參考。
最后
- ingress是k8s集群的請求入口,可以理解為對多個service的再次抽象
- 通常說的ingress一般包括ingress資源對象及ingress-controller兩部分組成
- ingress-controller有多種實現,社區原生的是ingress-nginx,根據具體需求選擇
- ingress自身的暴露有多種方式,需要根據基礎環境及業務類型選擇合適的方式
服務發現原理
endpoint
endpoint是k8s集群中的一個資源對象,存儲在etcd中,用來記錄一個service對應的所有pod的訪問地址。
service配置selector,endpoint controller才會自動創建對應的endpoint對象;否則,不會生成endpoint對象.
Endpoint地址會隨着Pod的銷毀和重新創建而發生改變,因為新Pod的IP地址與之前舊Pod的不同。而Service一旦被創建,Kubernetes就會自動為它分配一個可用的Cluster IP,而且在Service的整個生命周期內,它的Cluster IP不會發生改變。於是,服務發現這個棘手的問題在Kubernetes的架構里也得以輕松解決:只要用Service的Name與Service的Cluster IP地址做一個DNS域名映射即可完美解決問題。
例如,k8s集群中創建一個名為k8s-classic-1113-d3的service,就會生成一個同名的endpoint對象,如下圖所示。其中ENDPOINTS就是service關聯的pod的ip地址和端口。

endpoint controller
endpoint controller是k8s集群控制器的其中一個組件,其功能如下:
- 負責生成和維護所有endpoint對象的控制器
- 負責監聽service和對應pod的變化
- 監聽到service被刪除,則刪除和該service同名的endpoint對象
- 監聽到新的service被創建,則根據新建service信息獲取相關pod列表,然后創建對應endpoint對象
- 監聽到service被更新,則根據更新后的service信息獲取相關pod列表,然后更新對應endpoint對象
- 監聽到pod事件,則更新對應的service的endpoint對象,將podIp記錄到endpoint中
CoreDNS
CoreDNS總體架構圖

kube-proxy
kube-proxy負責service的實現,即實現了k8s內部從pod到service和外部從node port到service的訪問。
kube-proxy采用iptables的方式配置負載均衡,基於iptables的kube-proxy的主要職責包括兩大塊:一塊是偵聽service更新事件,並更新service相關的iptables規則,一塊是偵聽endpoint更新事件,更新endpoint相關的iptables規則(如 KUBE-SVC-鏈中的規則),然后將包請求轉入endpoint對應的Pod。如果某個service尚沒有Pod創建,那么針對此service的請求將會被drop掉。
kube-proxy的架構如下:

kube-proxy iptables
kube-proxy監聽service和endpoint的變化,將需要新增的規則添加到iptables中。
kube-proxy只是作為controller,而不是server,真正服務的是內核的netfilter,體現在用戶態則是iptables。
kube-proxy的iptables方式也支持RoundRobin(默認模式)和SessionAffinity負載分發策略。
kubernetes只操作了filter和nat表。
Filter:在該表中,一個基本原則是只過濾數據包而不修改他們。filter table的優勢是小而快,可以hook到input,output和forward。這意味着針對任何給定的數據包,只有可能有一個地方可以過濾它。
NAT:此表的主要作用是在PREROUTING和POSTROUNTING的鈎子中,修改目標地址和原地址。與filter表稍有不同的是,該表中只有新連接的第一個包會被修改,修改的結果會自動apply到同一連接的后續包中。
kube-proxy對iptables的鏈進行了擴充,自定義了KUBE-SERVICES,KUBE-NODEPORTS,KUBE-POSTROUTING,KUBE-MARK-MASQ和KUBE-MARK-DROP五個鏈,並主要通過為KUBE-SERVICES chain增加rule來配制traffic routing 規則。
同時,kube-proxy也為默認的prerouting、output和postrouting chain增加規則,使得數據包可以跳轉至k8s自定義的chain,規則如下:
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
如果service類型為nodePort,(從LB轉發至node的數據包均屬此類)那么將KUBE-NODEPORTS鏈中每個目的地址是NODE節點端口的數據包導入這個“KUBE-SVC-”鏈:
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http" -m tcp --dport 32135 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/es1:http" -m tcp --dport 32135 -j KUBE-SVC-LAS23QA33HXV7KBL
Iptables chain支持嵌套並因為依據不同的匹配條件可支持多種分支,比較難用標准的流程圖來體現調用關系,建單抽象為下圖:

舉個例子,在k8s集群中創建了一個名為my-service的服務,其中:
service vip:10.11.97.177
對應的后端兩副本pod ip:10.244.1.10、10.244.2.10
容器端口為:80
服務端口為:80
則kube-proxy為該service生成的iptables規則主要有以下幾條:
-A KUBE-SERVICES -d 10.11.97.177/32 -p tcp -m comment --comment "default/my-service: cluster IP" -m tcp --dport 80 -j KUBE-SVC-BEPXDJBUHFCSYIC3
-A KUBE-SVC-BEPXDJBUHFCSYIC3 -m comment --comment “default/my-service:” -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-U4UWLP4OR3LOJBXU #50%的概率輪詢后端pod
-A KUBE-SVC-BEPXDJBUHFCSYIC3 -m comment --comment "default/my-service:" -j KUBE-SEP-QHRWSLKOO5YUPI7O
-A KUBE-SEP-U4UWLP4OR3LOJBXU -s 10.244.1.10/32 -m comment --comment "default/my-service:" -j KUBE-MARK-MASQ
-A KUBE-SEP-U4UWLP4OR3LOJBXU -p tcp -m comment --comment "default/my-service:" -m tcp -j DNAT --to-destination 10.244.1.10:80
-A KUBE-SEP-QHRWSLKOO5YUPI7O -s 10.244.2.10/32 -m comment --comment "default/my-service:" -j KUBE-MARK-MASQ
-A KUBE-SEP-QHRWSLKOO5YUPI7O -p tcp -m comment --comment "default/my-service:" -m tcp -j DNAT --to-destination 10.244.2.10:80
kube-proxy通過循環的方式創建后端endpoint的轉發,概率是通過probability后的1.0/float64(n-i)計算出來的,譬如有兩個的場景,那么將會是一個0.5和1也就是第一個是50%概率第二個是100%概率,如果是三個的話類似,33%、50%、100%。
kube-proxy iptables的性能缺陷
k8s集群創建大規模服務時,會產生很多iptables規則,非增量式更新會引入一定的時延。iptables規則成倍增長,也會導致路由延遲帶來訪問延遲。大規模場景下,k8s 控制器和負載均衡都面臨這挑戰。例如,若集群中有N個節點,每個節點每秒有M個pod被創建,則控制器每秒需要創建N×M個endpoints,需要增加的iptables則是N*M的數倍。以下是k8s不同規模下訪問service的時延:


從上圖中可以看出,當集群中服務數量增長時,因為 IPTables天生不是被設計用來作為 LB 來使用的,IPTables 規則則會成倍增長,這樣帶來的路由延遲會導致的服務訪問延遲增加,直到無法忍受。
目前有以下幾種解決方案,但各有不足:
● 將endpoint對象拆分成多個對像
優點:減小了單個endpoint大小
缺點:增加了對象的數量和請求量
● 使用集中式負載均衡器
優點:減少了跟apiserver的連接和請求數
缺點:服務路由中又增加了一跳,並且需要集中式LB有很高的性能和高可用性
● 定期任務,批量創建/更新endpoint
優點:減少了每秒的處理數
缺點:在定期任務執行的間隔時間內,端對端延遲明顯增加
K8s 1.8 新特性—ipvs
ipvs與iptables的性能差異
隨着服務的數量增長,IPTables 規則則會成倍增長,這樣帶來的問題是路由延遲帶來的服務訪問延遲,同時添加或刪除一條規則也有較大延遲。不同規模下,kube-proxy添加一條規則所需時間如下所示:

可以看出當集群中服務數量達到5千個時,路由延遲成倍增加。添加 IPTables 規則的延遲,有多種產生的原因:
添加規則不是增量的,而是先把當前所有規則都拷貝出來,再做修改然后再把修改后的規則保存回去,這樣一個過程的結果就是 IPTables 在更新一條規則時會把 IPTables 鎖住,這樣的后果在服務數量達到一定量級的時候,性能基本不可接受:在有5千個服務(4萬條規則)時,添加一條規則耗時11分鍾;在右2萬個服務(16萬條規則)時,添加一條規則需要5個小時。
這樣的延遲時間,對生產環境是不可以的,那該性能問題有哪些解決方案呢?從根本上解決的話,可以使用 “IP Virtual Server”(IPVS )來替換當前 kube-proxy 中的 IPTables 實現,這樣能帶來顯著的性能提升以及更智能的負載均衡功能如支持權重、支持重試等等。
ipvs介紹
k8s 1.8 版本中,社區 SIG Network 增強了 NetworkPolicy API,以支持 Pod 出口流量策略,以及允許策略規則匹配源或目標 CIDR 的匹配條件。這兩個增強特性都被設計為 beta 版本。 SIG Network 還專注於改進 kube-proxy,除了當前的 iptables 和 userspace 模式,kube-proxy 還引入了一個 alpha 版本的 IPVS 模式。
作為 Linux Virtual Server(LVS) 項目的一部分,IPVS 是建立於 Netfilter之上的高效四層負載均衡器,支持 TCP 和 UDP 協議,支持3種負載均衡模式:NAT、直接路由(通過 MAC 重寫實現二層路由)和IP 隧道。ipvs(IP Virtual Server)安裝在LVS(Linux Virtual Server)集群作為負載均衡主節點上,通過虛擬出一個IP地址和端口對外提供服務。客戶端通過訪問虛擬IP+端口訪問該虛擬服務,之后訪問請求由負載均衡器調度到后端真實服務器上。
ipvs相當於工作在netfilter中的input鏈。

配置方法:IPVS 負載均衡模式在 kube-proxy 處於測試階段還未正式發布,完全兼容當前 Kubernetes 的行為,通過修改 kube-proxy 啟動參數,在 mode=userspace 和 mode=iptables 的基礎上,增加 mode=IPVS 即可啟用該功能。
ipvs轉發模式
DR模式(Direct Routing)
特點:
-
數據包在LB轉發過程中,源/目的IP和端口都不會變化。LB只修改數據包的MAC地址為RS的MAC地址
-
RS須在環回網卡上綁定LB的虛擬機服務IP
-
RS處理完請求后,響應包直接回給客戶端,不再經過LB
缺點:LB和RS必須位於同一子網
NAT模式(Network Address Translation)
特點:
-
LB會修改數據包地址:對於請求包,進行DNAT;對於響應包,進行SNAT
-
需要將RS的默認網關地址配置為LB的虛擬IP地址
缺點:LB和RS必須位於同一子網,且客戶端和LB不能位於同一子網
FULLNAT模式
特點:
-
LB會對請求包和響應包都做SNAT+DNAT
-
LB和RS對於組網結構沒有要求
-
LB和RS必須位於同一子網,且客戶端和LB不能位於同一子網
三種轉發模式性能從高到低:DR > NAT >FULLNAT
ipvs 負載均衡器常用調度算法
輪詢(Round Robin)
LB認為集群內每台RS都是相同的,會輪流進行調度分發。從數據統計上看,RR模式是調度最均衡的。
加權輪詢(Weighted Round Robin)
LB會根據RS上配置的權重,將消息按權重比分發到不同的RS上。可以給性能更好的RS節點配置更高的權重,提升集群整體的性能。
最少連接調度
LB會根據和集群內每台RS的連接數統計情況,將消息調度到連接數最少的RS節點上。在長連接業務場景下,LC算法對於系統整體負載均衡的情況較好;但是在短連接業務場景下,由於連接會迅速釋放,可能會導致消息每次都調度到同一個RS節點,造成嚴重的負載不均衡。
加權最少連接調度
最小連接數算法的加權版。
原地址哈希,鎖定請求的用戶
根據請求的源IP,作為散列鍵(Hash Key)從靜態分配的散列表中找出對應的服務器。若該服務器是可用的且未超載,將請求發送到該服務器。