Hive 數據傾斜怎么發現,怎么定位,怎么解決
多數介紹數據傾斜的文章都是以大篇幅的理論為主,並沒有給出具體的數據傾斜案例。當工作中遇到了傾斜問題,這些理論很難直接應用,導致我們面對傾斜時還是不知所措。
今天我們不扯大篇理論,直接以例子來實踐,排查是否出現了數據傾斜,具體是哪段代碼導致的傾斜,怎么解決這段代碼的傾斜。
當執行過程中任務卡在 99%,大概率是出現了數據傾斜,但是通常我們的 SQL 很大,需要判斷出是哪段代碼導致的傾斜,才能利於我們解決傾斜。通過下面這個非常簡單的例子來看下如何定位產生數據傾斜的代碼。
表結構描述
先來了解下這些表中我們需要用的字段及數據量:
表的字段非常多,此處僅列出我們需要的字段
第一張表:user_info (用戶信息表,用戶粒度)
| 字段名 | 字段含義 | 字段描述 |
|---|---|---|
| userkey | 用戶 key | 用戶標識 |
| idno | 用戶的身份證號 | 用戶實名認證時獲取 |
| phone | 用戶的手機號 | 用戶注冊時的手機號 |
| name | 用戶的姓名 | 用戶的姓名 |
user_info 表的數據量:1.02 億,大小:13.9G,所占空間:41.7G(HDFS三副本)
第二張表:user_active (用戶活躍表,用戶粒度)
| 字段名 | 字段含義 | 字段描述 |
|---|---|---|
| userkey | 用戶 key | 用戶沒有注冊會分配一個 key |
| user_active_at | 用戶的最后活躍日期 | 從埋點日志表中獲取用戶的最后活躍日期 |
user_active 表的數據量:1.1 億
第三張表:user_intend(用戶意向表,此處只取近六個月的數據,用戶粒度)
| 字段名 | 字段含義 | 字段描述 |
|---|---|---|
| phone | 用戶的手機號 | 有意向的用戶必須是手機號注冊的用戶 |
| intend_commodity | 用戶意向次數最多的商品 | 客戶對某件商品意向次數最多 |
| intend_rank | 用戶意向等級 | 用戶的購買意願等級,級數越高,意向越大 |
user_intend 表的數據量:800 萬
第四張表:user_order(用戶訂單表,此處只取近六個月的訂單數據,用戶粒度)
| 字段名 | 字段含義 | 字段描述 |
|---|---|---|
| idno | 用戶的身份證號 | 下訂單的用戶都是實名認證的 |
| order_num | 用戶的訂單次數 | 用戶近六個月下單次數 |
| order_amount | 用戶的訂單總金額 | 用戶近六個月下單總金額 |
user_order 表的數據量:640 萬
1. 需求
需求非常簡單,就是將以上四張表關聯組成一張大寬表,大寬表中包含用戶的基本信息,活躍情況,購買意向及此用戶下訂單情況。
2. 代碼
根據以上需求,我們以 user_info 表為基礎表,將其余表關聯為一個寬表,代碼如下:
select
a.userkey,
a.idno,
a.phone,
a.name,
b.user_active_at,
c.intend_commodity,
c.intend_rank,
d.order_num,
d.order_amount
from user_info a
left join user_active b on a.userkey = b.userkey
left join user_intend c on a.phone = c.phone
left join user_order d on a.idno = d.idno;
執行上述語句,在執行到某個 job 時任務卡在 99%:
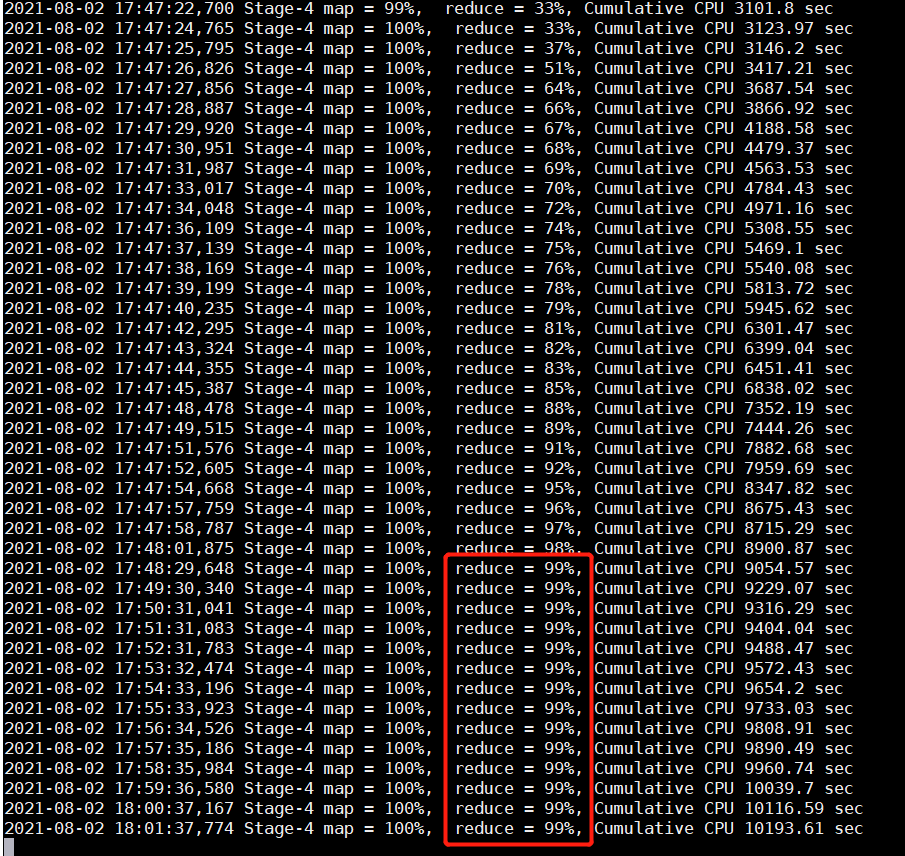
這時我們就應該考慮出現數據傾斜了。其實還有一種情況可能是數據傾斜,就是任務超時被殺掉,Reduce 處理的數據量巨大,在做 full gc 的時候,stop the world。導致響應超時,超出默認的 600 秒,任務被殺掉。報錯信息一般如下:
AttemptID:attempt_1624419433039_1569885_r_000000 Timed outafter 600 secs Container killed by the ApplicationMaster. Container killed onrequest. Exit code is 143 Container exited with a non-zero exit code 143
3. 傾斜問題排查
數據傾斜大多數都是大 key 問題導致的。
如何判斷是大 key 導致的問題,可以通過下面方法:
1. 通過時間判斷
如果某個 reduce 的時間比其他 reduce 時間長的多,如下圖,大部分 task 在 1 分鍾之內完成,只有 r_000000 這個 task 執行 20 多分鍾了還沒完成。
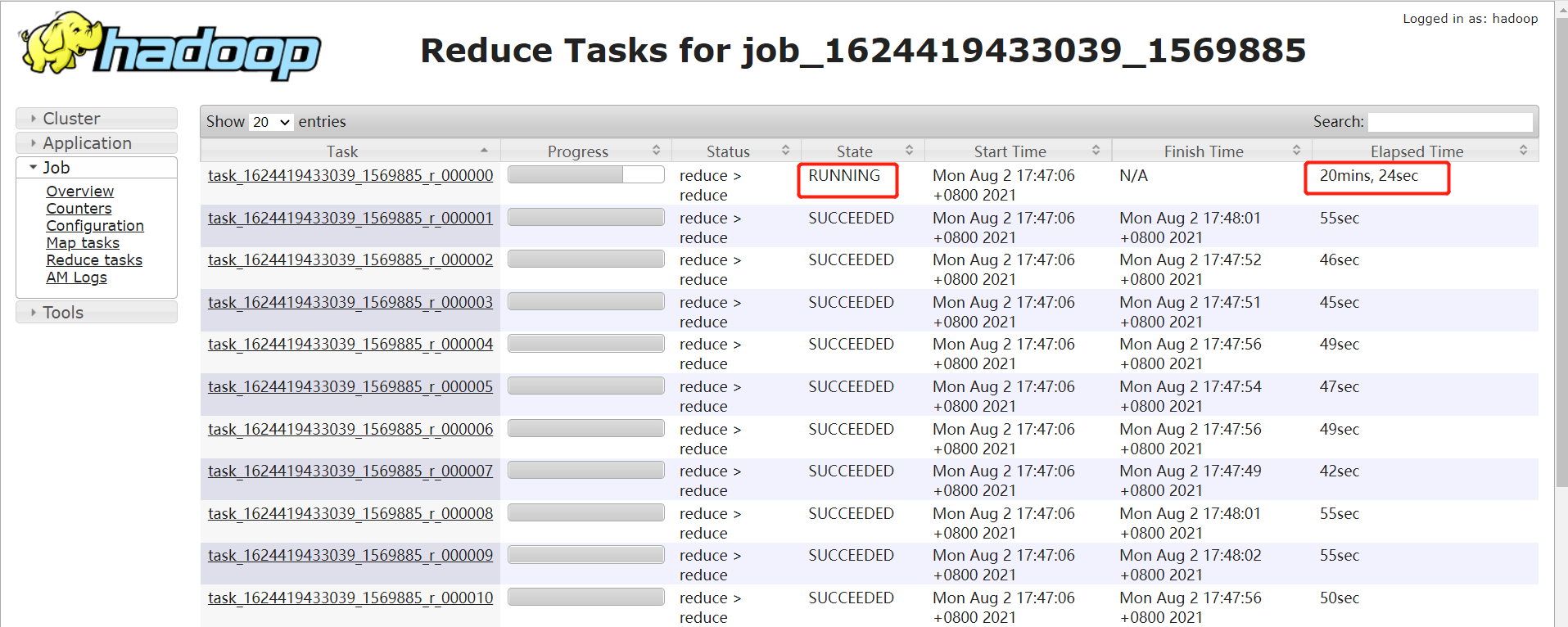
注意:要排除兩種情況:
-
如果每個 reduce 執行時間差不多,都特別長,不一定是數據傾斜導致的,可能是 reduce 設置過少導致的。
-
有時候,某個 task 執行的節點可能有問題,導致任務跑的特別慢。這個時候,mapreduce 的推測執行,會重啟一個任務。如果新的任務在很短時間內能完成,通常則是由於 task 執行節點問題導致的個別 task 慢。但是如果推測執行后的 task 執行任務也特別慢,那更說明該 task 可能會有傾斜問題。
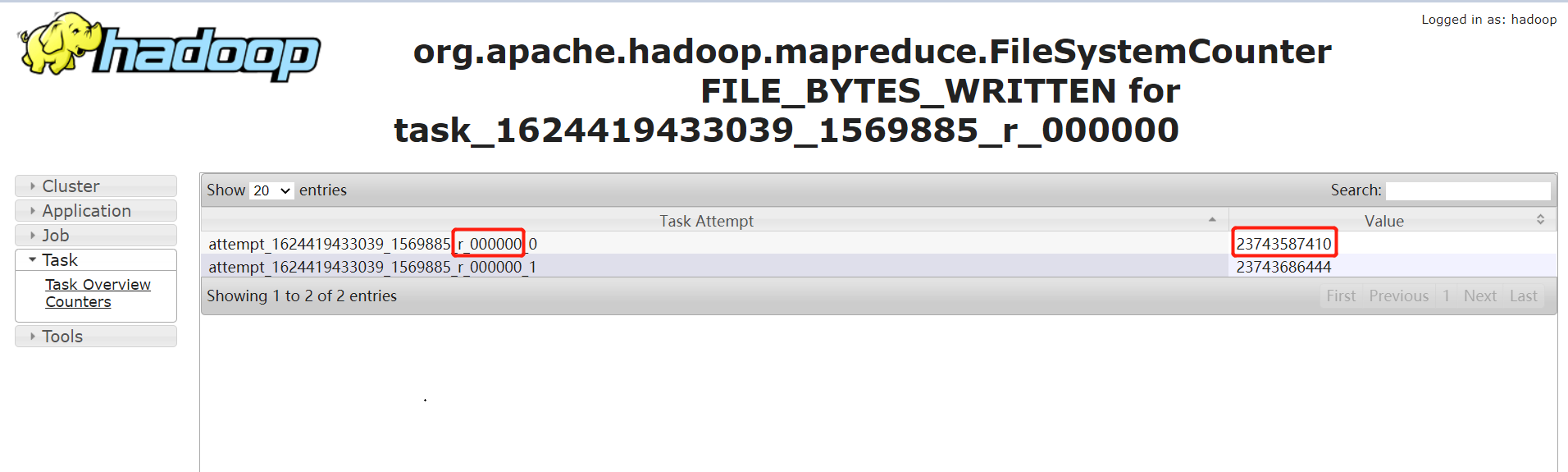
2. 通過任務 Counter 判斷
Counter 會記錄整個 job 以及每個 task 的統計信息。counter 的 url 一般類似:
http://bd001:8088/proxy/application_1624419433039_1569885/mapreduce/singletaskcounter/task_1624419433039_1569885_r_000000/org.apache.hadoop.mapreduce.FileSystemCounter
通過輸入記錄數,普通的 task counter 如下,輸入的記錄數是 13 億多:
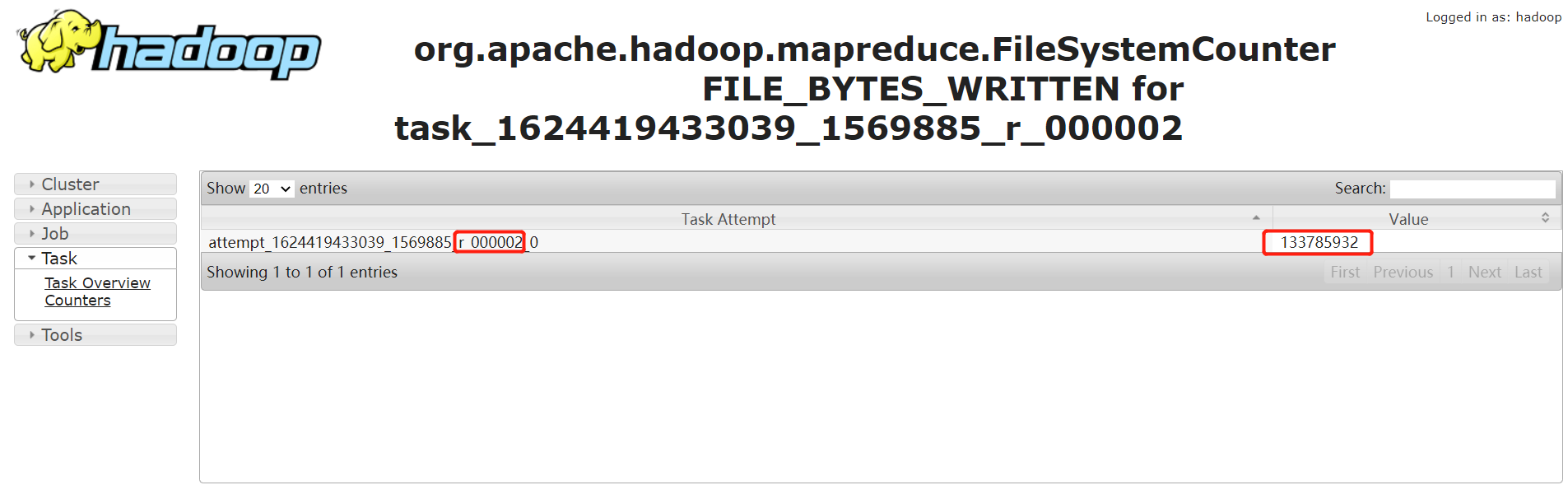
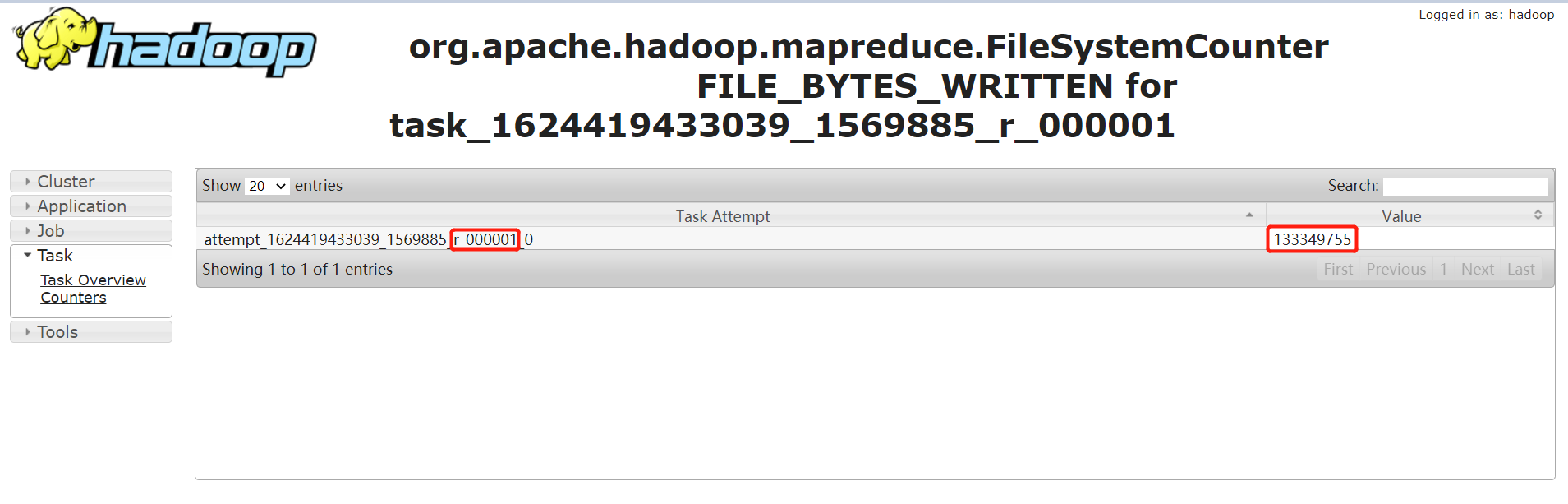
而 task=000000 的 counter 如下,其輸入記錄數是 230 多億。是其他任務的 100 多倍:
4. 定位 SQL 代碼
1. 確定任務卡住的 stage
-
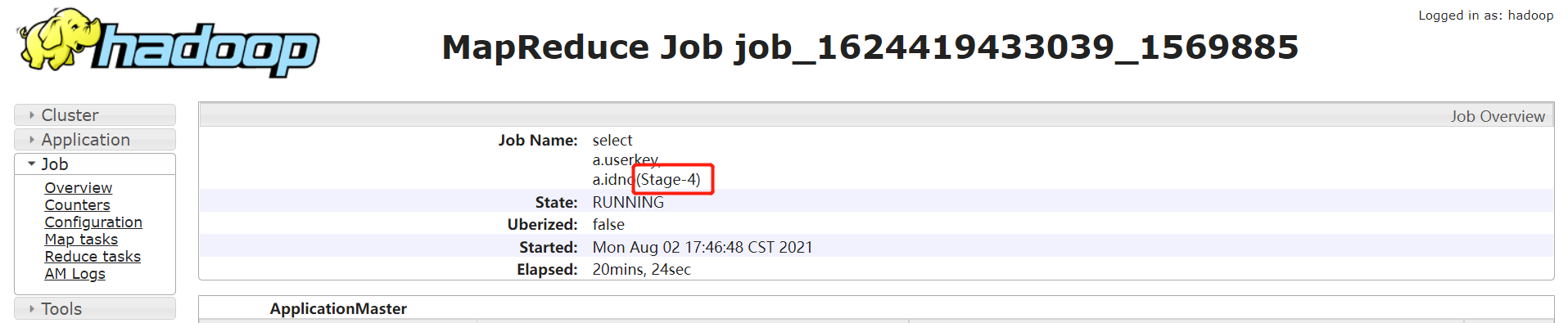
通過 jobname 確定 stage:
一般 Hive 默認的 jobname 名稱會帶上 stage 階段,如下通過 jobname 看到任務卡住的為 Stage-4:
-
如果 jobname 是自定義的,那可能沒法通過 jobname 判斷 stage。需要借助於任務日志:
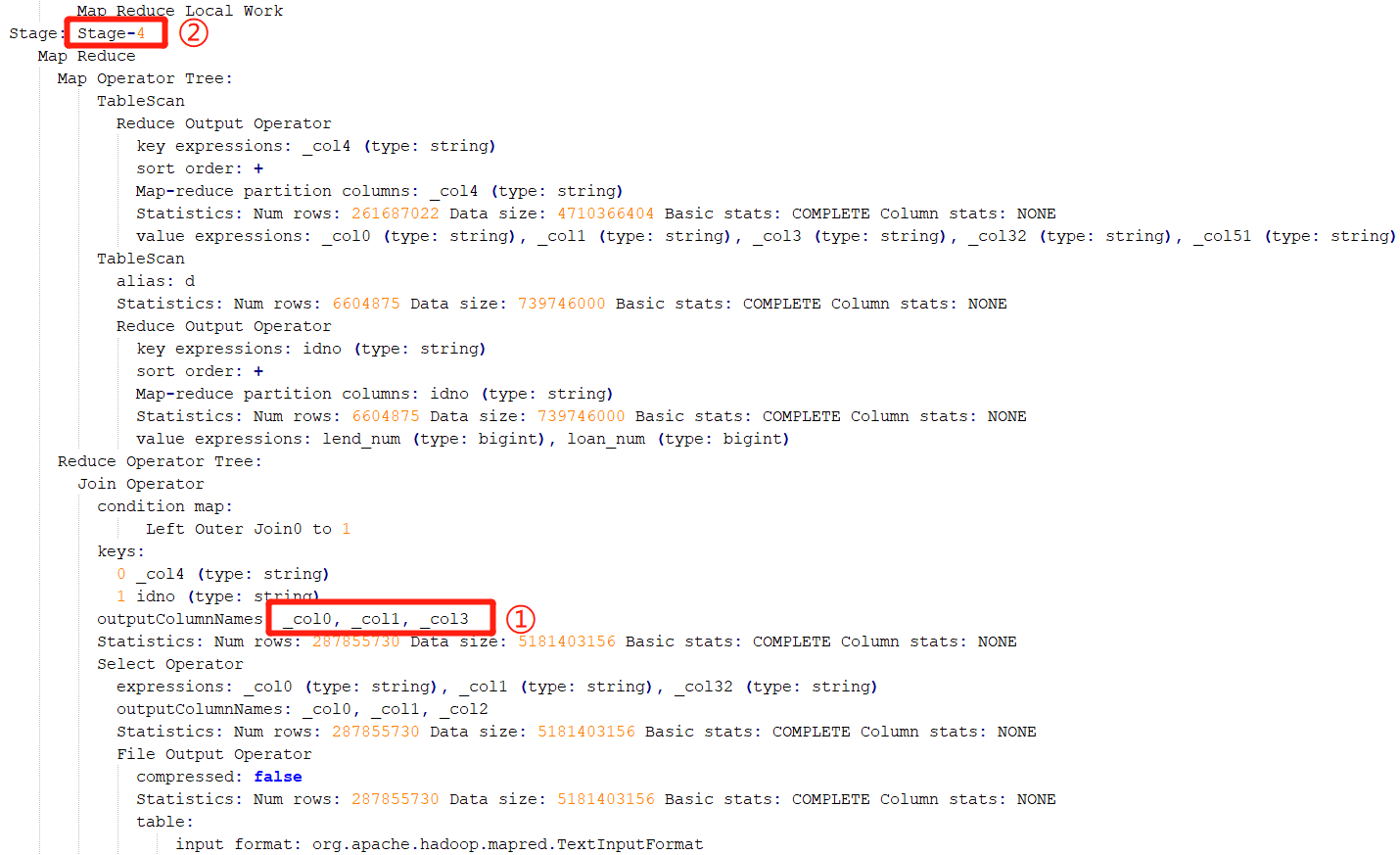
找到執行特別慢的那個 task,然后 Ctrl+F 搜索 “CommonJoinOperator: JOIN struct” 。Hive 在 join 的時候,會把 join 的 key 打印到日志中。如下:

上圖中的關鍵信息是:struct<_col0:string, _col1:string, _col3:string>
這時候,需要參考該 SQL 的執行計划。通過參考執行計划,可以斷定該階段為 Stage-4 階段:
2. 確定 SQL 執行代碼
確定了執行階段,即 stage。通過執行計划,則可以判斷出是執行哪段代碼時出現了傾斜。還是從此圖,這個 stage 中進行連接操作的表別名是 d:

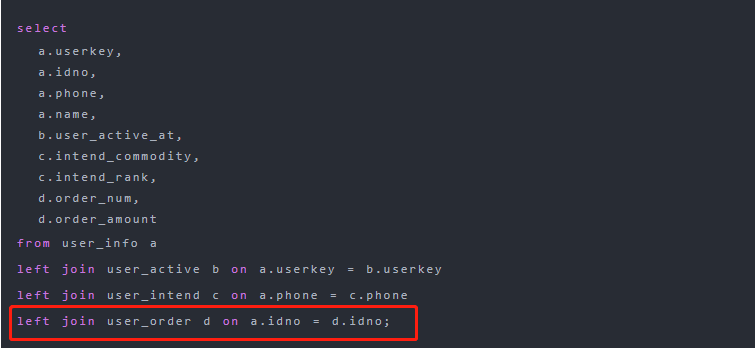
就可以推測出是在執行下面紅框中代碼時出現了數據傾斜,因為這行的表的別名是 d:
5. 解決傾斜
我們知道了哪段代碼引起的數據傾斜,就針對這段代碼查看傾斜原因,看下這段代碼的表中數據是否有異常。
傾斜原因:
本文的示例數據中 user_info 和 user_order 通過身份證號關聯,檢查發現 user_info 表中身份證號為空的有 7000 多萬,原因就是這 7000 多萬數據都分配到一個 reduce 去執行,導致數據傾斜。
解決方法:
- 可以先把身份證號為空的去除之后再關聯,最后按照 userkey 連接,因為 userkey 全部都是有值的:
with t1 as(
select
u.userkey,
o.*
from user_info u
left join user_order o
on u.idno = o.idno
where u.idno is not null
--是可以把where條件寫在后面的,hive會進行謂詞下推,先執行where條件在執行 left join
)
select
a.userkey,
a.idno,
a.phone,
a.name,
b.user_active_at,
c.intend_commodity,
c.intend_rank,
d.order_num,
d.order_amount
from user_info a
left join user_active b on a.userkey = b.userkey
left join user_intend c on a.phone = c.phone
left join t1 d on a.userkey = d.userkey;
- 也可以這樣,給身份證為空的數據賦個隨機值,但是要注意隨機值不能和表中的身份證號有重復:
select
a.userkey,
a.idno,
a.phone,
a.name,
b.user_active_at,
c.intend_commodity,
c.intend_rank,
d.order_num,
d.order_amount
from user_info a
left join user_active b on a.userkey = b.userkey
left join user_intend c on a.phone = c.phone
left join user_order d on nvl(a.idno,concat(rand(),'idnumber')) = d.idno;
其他的解決數據傾斜的方法:
1. 過濾掉臟數據
如果大 key 是無意義的臟數據,直接過濾掉。本場景中大 key 有實際意義,不能直接過濾掉。
2. 數據預處理
數據做一下預處理(如上面例子,對 null 值賦一個隨機值),盡量保證 join 的時候,同一個 key 對應的記錄不要有太多。
3. 增加 reduce 個數
如果數據中出現了多個大 key,增加 reduce 個數,可以讓這些大 key 落到同一個 reduce 的概率小很多。
配置 reduce 個數:
set mapred.reduce.tasks = 15;
4. 轉換為 mapjoin
如果兩個表 join 的時候,一個表為小表,可以用 mapjoin 做。
配置 mapjoin:
set hive.auto.convert.join = true; 是否開啟自動mapjoin,默認是true
set hive.mapjoin.smalltable.filesize=100000000; mapjoin的表size大小
5. 啟用傾斜連接優化
hive 中可以設置 hive.optimize.skewjoin 將一個 join sql 分為兩個 job。同時可以設置下 hive.skewjoin.key,此參數表示 join 連接的 key 的行數超過指定的行數,就認為該鍵是偏斜連接鍵,就對 join 啟用傾斜連接優化。默認 key 的行數是 100000。
配置傾斜連接優化:
set hive.optimize.skewjoin=true; 啟用傾斜連接優化
set hive.skewjoin.key=200000; 超過20萬行就認為該鍵是偏斜連接鍵
6. 調整內存設置
適用於那些由於內存超限任務被 kill 掉的場景。通過加大內存起碼能讓任務跑起來,不至於被殺掉。該參數不一定會明顯降低任務執行時間。
配置內存:
set mapreduce.reduce.memory.mb=5120; 設置reduce內存大小
set mapreduce.reduce.java.opts=-Xmx5000m -XX:MaxPermSize=128m;
附:Hive 配置屬性官方鏈接:https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties