
一、提出問題
你要么獲取一批數據,然后根據它提問,或者先提問,然后根據問題收集數據。在這兩種情況下,好的問題可以幫助你將精力集中在數據的相關部分,並幫助你得出有洞察力的分析。
二、理解數據
1、理解各字段的意思,如果有英文可修改成中文更易理解。
2、在數據清洗前復制一份保存,將CSV文件另存為xlsx類型保存。
3、Excel有四種數據了類型:
(1)文本型:中、英文、混合文本、符號和字符串形成存儲的數值(123)
(2)數值型:數值、科學計數法、時間、日期和貨幣.....
(3)邏輯性:TRUE和FALSE
(4)錯誤值:#NAME?、#N/A、#DIV/0、#REF!、#VALUE!、#NUM!、#NULL! 三、數據清洗 1.選擇子集
不需要的列可以隱藏,不要刪除。需要用到隱藏子集的操作:格式--隱藏和取消隱藏 或者選擇取消隱藏的行/列,右鍵點取消隱藏。 2.列名重命名
雙擊列名字段進行修改。 3.刪除重復數據項
操作:數據---刪除重復項---取消全選---選擇需要檢查的列---確定。選擇數據集中的唯一編號列。 4.缺失值處理
單擊唯一編號列,右下角查看該數據集的總行數。依次點擊其他列。缺失值數據 = 唯一編號列總數 - 其他列總數。 缺失值處理的4種方法
,根據情況靈活使用:
(1)通過人工手動補全:缺失值很少的情況下。
定位缺失值操作:開始---查找和選擇---定位條件---空值---輸入填充的值---同時按住Ctrl+Enter,填充到其他空白單元格。
(2)刪除缺失的數據 :字段缺失數據超過50%,缺失過多就沒有意義,考慮刪除。
(3)用平均值代替缺失值:計算該列的平均值代替。
(4)用統計模型計算出的值去代替缺失值。 5.一致化處理
(1)分列一致化:列中有多個標簽(企業服務,數據服務),需要分列處理,分列功能會覆蓋掉右列單元格,所以我們先要復制這一列到最后一個空白列的地方,再進行分列操作。
分列操作:選中該列---數據---分列---分隔符號---下一步---取消Tab鍵,選擇其他(本例中用逗號,)---下一步---確定。
(2)插入幾個數據清洗常用函數:
①篩選列數據信息:IF(COUNT(FIND({關鍵字1,關鍵字2},單元格)),"是","否") 篩選單元格中的關鍵字,有則顯示是,沒有則顯示否。
②平均數AVERAGE(A1:A3),
③查找函數Find(要查找的字符串,字符串所在單元格位置),
④數據抽取Left/Right(字符串所在單元格位置,從左/右開始到XX位置進行截取,從第幾個位置開始截取[默認為1]),Mid(字符串所在單元格位置,開始位置,截取長度),
⑤統計單元格長度函數Len(A1)。
(3)錯誤值處理
用復制粘貼為數值將以字符串形式存儲的數字轉化為純數值。
使用函數查找字符串要注意字符串的大小寫,不匹配會報錯。
善於利用查找替換功能,去除多余的字或轉換大小寫。“以上”--->“”;k --> K 6.數據排序
排序操作:開始---排序和降序---降序/自定義排序---擴展選定區域。 7.異常值處理
過大或過小,在實際中不可能存在的數據。如年齡:120歲,-1歲,薪資:1000萬.... 四、構建模型
1.數據透視表:Ctrl+A選擇整個數據表,插入---數據透視表。
(1)數據透視表有四個區域:篩選器,列,行,值。
(2)數據透視表的幾個常用功能:
①將所需字段拖入透視表的區域,篩選器和值區域可同時拖入多個字段。
②值字段設置:值---右鍵---值字段設置---總和/計數/
③排序:單擊行標簽/列標簽---右鍵---升序/降序。
④值匯總方式:單擊值標簽---值匯總依據---求和/計數/平均值/最大值/最小值....
⑤值顯示方式:單擊值標簽---值顯示方式---總計的百分比/列匯總的百分比/行匯總的百分比...
2.分析工具庫:數據分析
安裝數據分析功能:文件---選項---excel加載表>轉到---分析工具庫。
如何應用?數據---數據分析---描述統計,接着操作如下:
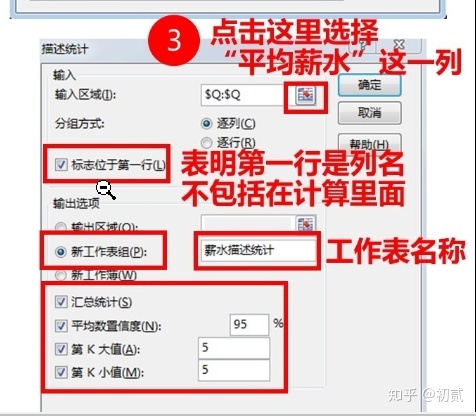
3.多表關聯查詢:vlookup函數
(1)精確查找和近似查找(模糊查找)的區別。
①精確查找是指從第一行開始往最后一行逐個查找。一找到匹配項就停止查詢,所以返回找到的第一個值。
②當你要近似查找的時候,它就會苦逼地查遍所有的數據,返回的是最后一個匹配到的值。
(2)在使用vlookup函數時,在很多情況下使用的是精確匹配,而在進行分組時需要用模糊匹配,所以這里要輸入“1”來進行模糊匹配。分組時要注意三要素:閾值,分組名稱,區域范圍。
(3)Excel設置了快捷鍵F4幫助用戶迅速切換相對引用、絕對引用和混合引用。步驟如下:
①選定包含該公式的單元格;
②在編輯欄中選擇要更改的公式內容,並按 F4 鍵;
③以引用單元格A1為例,每次按 F4 鍵時,Excel會依次在以下組合間切換: 按一次F4是絕對引用 按兩次、三次F4是混合引用 按四次F4是相對引用。
(4)使用這個函數過程中,如果出現錯誤標識“#N/A”,一般是3個原因導致:
①第2個參數:查找范圍里第一列的值必須是要查找的值。 比如這個案例里第2個參數選定的的范圍里第一列是姓名,是要查找值的列。
②數據存在空格,此時可以嵌套使用TRIM函數將空格批量刪除。
③數據類型或格式不一致,此時將數據類型或格式轉為一致即可。 六、得出結論
根據數據透視表的數據分析得出結論。
