python數據分析之金融欺詐行為檢測
- 項目的思維導圖

- 數據分析與處理
- 聲明所使用的庫
`import numpy as np
import pandas as pd #panda主要用於處理結構化的數據列表,具有數據挖掘和數據分析,對數據進行清洗
import matplotlib.pyplot as plt #繪圖工具
import matplotlib.cm as cm #色彩映射函數
import seaborn as sns #基於Matplotlib圖形可視化的python包,便於做出統計圖表
from sklearn import preprocessing #數據建模用的一個庫
from scipy.stats import skew,boxcox
import os`
- 處理數據的結構
注意:代碼中處理的是csv文件,這里為了簡單明了,使用excel呈現出
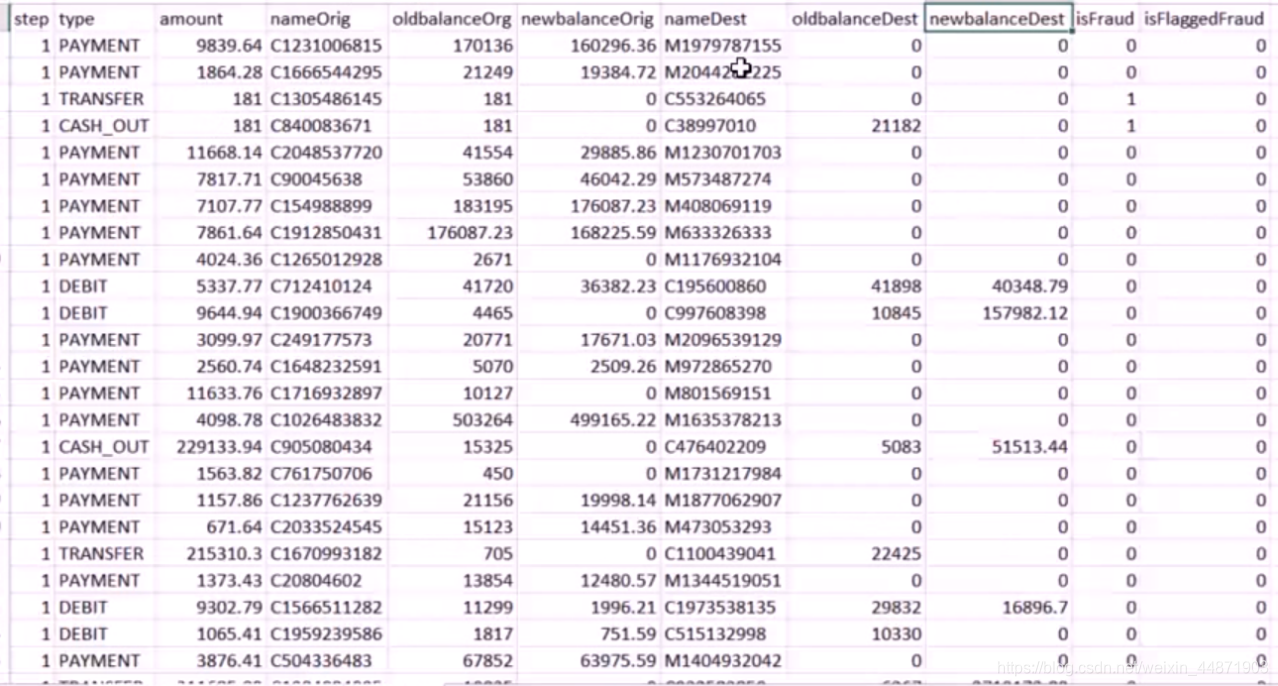
關於數據列的解釋如下
(1)step:對應現實中的時間單位(小時)
(2)type:轉賬類型
(3)amout:金額
(4)nameOrig: 轉賬發起人
(5)oldbalanceOrg: 轉帳前發起人賬戶余額
(6)newbalanceOrig: 轉賬后發起人賬戶余額
(7)nameDest: 轉賬收款人
(8)oldbalanceDest: 轉賬前收款人賬戶余額,收款人是商戶(M開頭)時沒有該項信息
(9)newbalanceDest: 轉賬后收款人余額,收款人是商戶(M開頭)時沒有該項信息
(10)isFraud:該轉賬行為是欺詐行為
(11)isFlaggedFraud: 商業模型為了控制大額轉賬並且標記為非法操作,在這兒,非法操作是指轉賬金額超過20萬。
- 讀取文件
在代碼所在的文件夾中創建一個新的文件夾,用於存放數據集
dataset_path='./pythonjinrong'
csvfile_path=os.path.join(dataset_path,'PS.csv')
#解壓數據集
raw_data=pd.read_csv(csvfile_path)
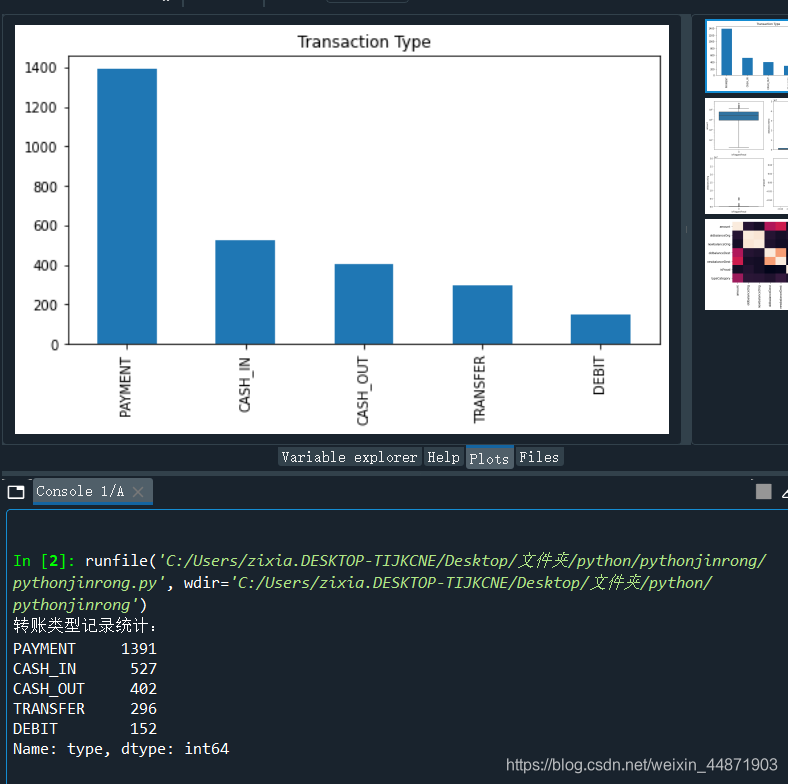
- 統計數據集中的各轉賬類型的數量
print('轉賬類型記錄統計:')
print(raw_data['type'].value_counts())
fig,ax=plt.subplots(1,1,figsize=(8,4))
raw_data['type'].value_counts().plot(kind='bar',title='Transaction Type',ax=ax,figsize=(8,4))
plt.show()
結果會輸出統計數量結果,以及繪制柱形圖,從下圖中可以看出數量最多的類型是支付類型(PAYMENT),共1391例,最少的是借款(DEBIT),共152例
- 查看各類型中欺詐行為的數量
(1)首先,用“0”表示沒有欺詐行為,用“1”表示存在欺詐行為
(2)統計存在欺詐行為的類型的數量
#查看轉賬類型和欺詐標記的記錄
ax=raw_data.groupby(['type','isFraud']).size().plot(kind='bar')
ax.set_title('#of transactions vs (type+isFraud)')
ax.set_xlabel('(type,isFraud)')
ax.set_ylabel('#of transaction')
#添加標注
for p in ax.patches:
ax.annotate(str(format(int(p.get_height()),',d')),(p.get_x(),p.get_height()*1.01))
(3)運行結果如下
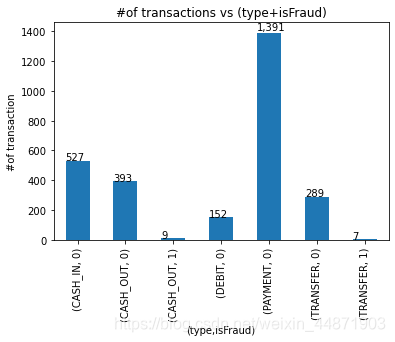
從結果分析,存在欺詐行為的類型有現金提取(CASH_OUT)和轉賬(DEBIT)
- 使用箱線圖比較欺詐行為和正常行為
#對數據進行分析
fig,axs=plt.subplots(2,2,figsize=(10,10))
transfer_data=raw_data[raw_data['type']=='TRANSFER']
a=sns.boxplot(x='isFlaggedFraud',y='amount',data=transfer_data,ax=axs[0][0])
axs[0][0].set_yscale('log') #比較金額
b=sns.boxplot(x='isFlaggedFraud',y='oldbalanceDest',data=transfer_data,ax=axs[0][1])
axs[0][1].set(ylim=(0,0.5e8)) #比較轉賬前收款人賬戶余額
c=sns.boxplot(x='isFlaggedFraud',y='oldbalanceOrg',data=transfer_data,ax=axs[1][0])
axs[1][0].set(ylim=(0,3e7)) #比較轉賬前付款人的賬戶余額
d=sns.regplot(x='oldbalanceOrg',y='amount',data=transfer_data[transfer_data['isFlaggedFraud']==1])
plt.show()
由於小編的電腦內存僅剩幾個G,所以跑不動高達481968k的數據集,所以自己提取了204K的數據運行,但結果不佳,圖1是204k數據跑的結果,圖2、3是換了設備后大數據集的結果
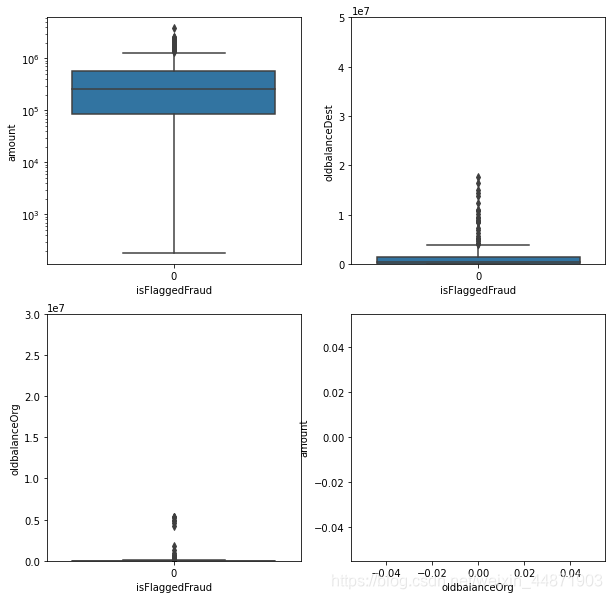
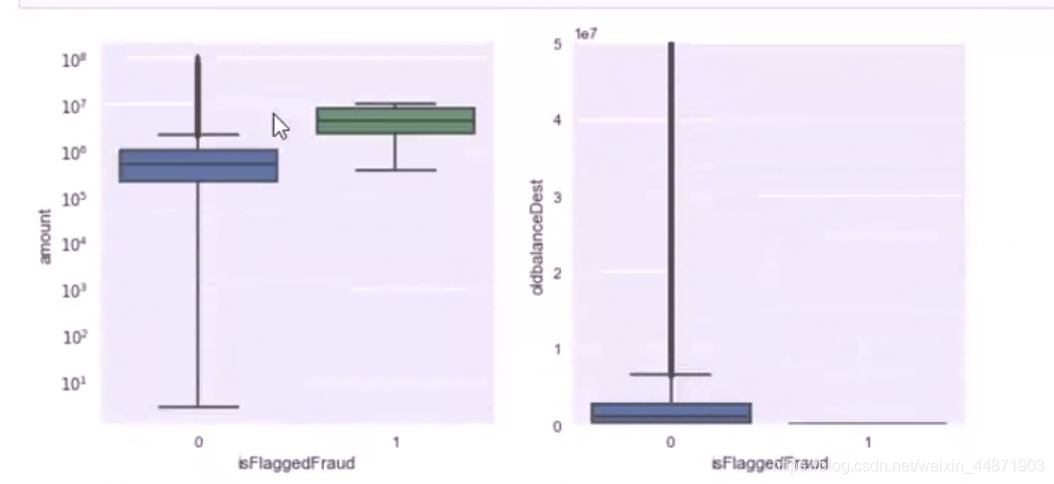
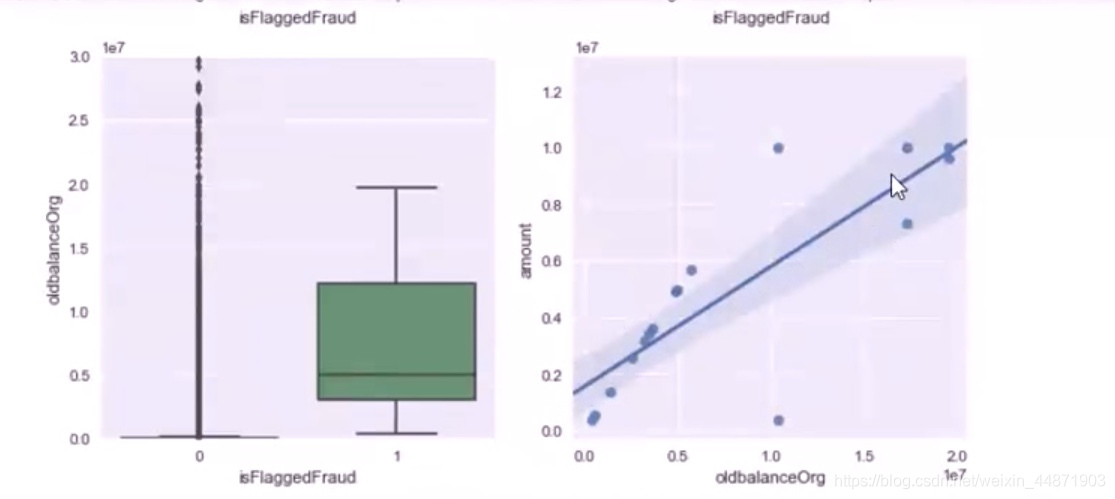
結果差別還是挺大的,所以還是要有一台配置好的電腦。
從大數據集跑出來的結果可以分析出以下幾個特點
圖(1)欺詐行為涉及的金額大——重要特點
圖(4)之前賬戶的余額與轉賬金額的關系——可能呈線性關系
- 數據處理(數據清洗和數據合並)
(1)首先將數據集中不存在欺詐行為的類型去掉,保留存在欺詐的取款和轉賬兩種類型,然后重新設置索引
#數據處理:包括數據清洗和樣本數據合並
used_data=raw_data[(raw_data['type']=='TRANSFER') | (raw_data['type']=='CASH_OUT')]
#去掉不用的數據
used_data.drop(['step','nameOrig','nameDest','isFlaggedFraud'],axis=1,inplace=True)
#重新設置索引
used_data=used_data.reset_index(drop=True)
(2)將取款(CASH_OUT)和轉賬(DEBIT)兩種類型分別表示為“0”和“1”
#將type轉換成類別數據,即0,1
type_label_encoder=preprocessing.LabelEncoder()
type_category=type_label_encoder.fit_transform(used_data['type'].values)
used_data['typeCategory']=type_category
#print(used_data.head())
sns.heatmap(used_data.corr()) #使用PRT相關技術分析變量間的相關性
預覽前五行數據可以看到處理后的表格

在輸出結果中,通過typeCategory這一列,我們可以看到兩種類型都已被編碼
相關程度圖如下,顏色越淺,相關度越高
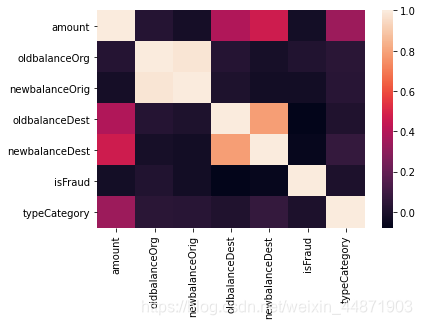
從圖中可以看出,轉帳前和轉賬后付款人和收款人的余額有很大的相關性,余額也跟轉賬金額有關系。
- 查看轉賬和取款類型數量
#查看轉賬類型記錄個數
ax=used_data['type'].value_counts().plot(kind='bar',title="Transaction Type",figsize=(6,6))
for p in ax.patches:
ax.annotate(str(format(int(p.get_height()),',d')),(p.get_x(),p.get_height()*1.01))
plt.show()
結果如下:
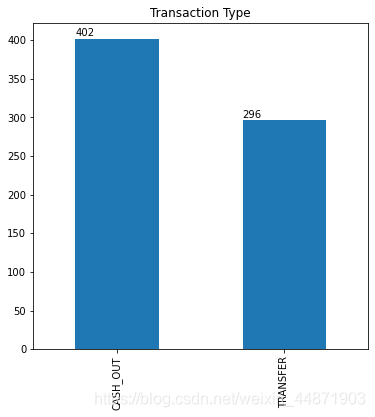
從這個圖中可以看出取款類型多於轉賬類型
注意:繪制此圖時,建議把繪制相關性圖的那行代碼注釋掉,不然畫出來的兩個圖就混到一起了。
- 查看正常行為與欺詐行為數量
#查看轉賬類型中欺詐記錄個數
ax1=pd.value_counts(used_data['isFraud'],sort=True).sort_index().plot(kind='bar',title="Fraud Transaction Count")
for p in ax1.patches:
ax1.annotate(str(format(int(p.get_height()),',d')),(p.get_x(),p.get_height()*1.01))
plt.show()
結果如下
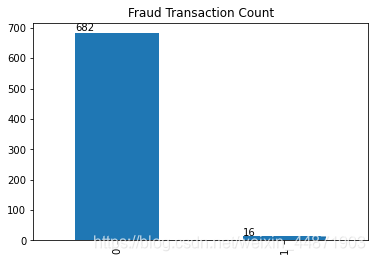
從這張圖可以看出,正常行為遠遠多於欺詐行為。
- 數學模型的構建
(1)准備模型
由上面的分析可知,金融欺詐行為數量遠遠小於正常行為,為了構建模型,采用下采樣法取出與欺詐行為數量相等的正常行為,然后輸出比例驗證下采樣法。
#准備模型
feature_names=['amount','oldbalanceOrg','newbalanceOrig','oldbalanceDest','newbalanceDest','typeCategory']
X=used_data[feature_names]
y=used_data['isFraud']
#print(X.head())
#print(y.head())
#用下采樣法處理不平衡數據
#欺詐記錄的條數
number_records_fraud=len(used_data[used_data['isFraud']==1])
#欺詐記錄的索引
fraud_indices=used_data[used_data['isFraud']==1].index.values
#得到非欺詐記錄的索引
nonfraud_indices=used_data[used_data['isFraud']==0].index
#隨即選取相同數量的非欺詐記錄
random_nonfraud_indices=np.random.choice(nonfraud_indices,number_records_fraud,replace=False)
random_nonfraud_indices=np.array(random_nonfraud_indices)
#整合兩樣本的索引
under_sample_indices=np.concatenate([fraud_indices,random_nonfraud_indices])
under_sample_data=used_data.iloc[under_sample_indices,:]
X_undersample=under_sample_data[feature_names].values
y_undersample=under_sample_data['isFraud'].values
print("非欺詐記錄比例:",len(under_sample_data[under_sample_data['isFraud']==0])/len(under_sample_data))
print("欺詐記錄比例:",len(under_sample_data[under_sample_data['isFraud']==1])/len(under_sample_data))
print("欠采樣記錄數:",len(under_sample_data))
比例輸出結果如下:

從之前的統計中可以知道金融欺詐行為的數量為16,取出相同數量的正常行為16例,所以欠采樣記錄數為32
(2)模型構建
采用邏輯回歸模型,該模型主要用於分類問題,特別是分為0和1兩類的問題
#數據建模
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve,auc
#分割訓練集和測試集
X_train,X_test,y_train,y_test=train_test_split(X_undersample,y_undersample,test_size=0.3,random_state=0)
lr_model=LogisticRegression()
lr_model.fit(X_train,y_train)
y_pred_score=lr_model.predict_proba(X_test)
fpr,tpr,thresholds=roc_curve(y_test,y_pred_score[:,1])
roc_auc=auc(fpr,tpr)
#繪制ROC曲線
plt.title('Receiver Operating Characteristic')
plt.plot(fpr,tpr,'b',label='AUC=%0.2f'%roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([-0.1,1.0])
plt.ylim([-0.1,1.01])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
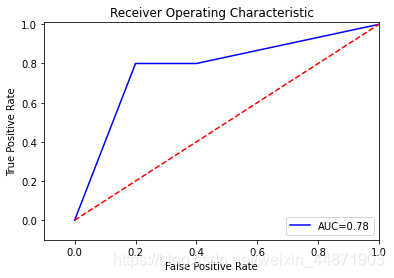
ROC曲線的AUC越接近1,說明模型越好,在這兒AUC=0.78,說明模型還可以。
然后,項目就做完了。
備注:數據在kaggle里,鏈接:https://www.kaggle.com/ntnu-testimon/paysim1
