numpy (Numerical Python) 是 Python
語言的一個擴展程序庫,支持大量的維度數組與矩陣運算,此外也針對數組運算提供大量的數學函數庫。numpy 通常與 SciPy(Scientific
Python)和 Matplotlib(繪圖庫)一起使用.
numpy 是一個運行速度非常快的數學庫,主要用於數組計算,包含:
- 一個強大的N維數組對象 ndarray
- 廣播功能函數
- 整合 C/C++/Fortran 代碼的工具
- 線性代數、傅里葉變換、隨機數生成等功能
-
-
1.numpy的數組對象
1.數組屬性:ndarray(數組)是存儲單一數據類型的多維數組。使用array函數創建數組時,數組的數據類型默認是浮點型。自定義數組數據,則需預先指定數據類型。

2.創建數組:numpy.array(object, dtype=None, copy=True, order=‘K’,subok=False,
ndmin=0)
3.numpy中數組的應用:
代碼如下;
import numpy as np # 導入類庫 numpy
'''數組對象array實例化'''
array = np.array(([1, 3, 5, 7], [2, 4, 6, 8], [1, 1, 1, 1])) # 創建三維數組
# 創建一維數組
array0 = np.array(([1, 2, 3, 4]))
# 創建二維數組
array1 = np.array(([1, 2, 3, 4], [1, 2, 3, 4]))
# 創建三維數組
array2 = np.array(([1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]))
# linspace 函數創建數組
array3 = np.linspace(0, 10, 2)
# logspace 函數創建等比數列
array4 = np.logspace(0, 1, 2)
# zeros函數創建數組
array5 = np.zeros((2, 4))
# eye函數創建數組
array6 = np.eye(3)
# diag函數創建數組
array7 = np.diag([1, 3, 5, 7])
# ones函數創建數組
array8 = np.ones((3, 3))
a = np.ndim(array) # 獲取數組的維數
b = np.shape(array) # 獲取數組的尺寸 eg:(x, y) 解釋: x 行 y 列
c = np.size(array) # 獲取數組的元素個數
print('當前數組' '\n' + str(array) + '的維數(維度)為:', a)
print('當前數組' '\n' + str(array) + '的尺寸為:', b)
print('當前數組' '\n' + str(array) + '的元素總數為:', c)
d = array1.shape = 4, 2
print('經過' + str(d) + '的變形后數組為:''\n', array1)
'''數組數據類型轉換'''
# 整型和浮點型的相互轉換
print('轉換結果為:', np.float64(24))
print('轉換結果為:', np.int8(24.0))
# 整型轉換為布爾型
print('轉換結果為:', np.bool(24))
print('轉換結果為:', np.bool(0))
# 布爾型和浮點型的相互轉換
print('轉換結果為:', np.float(True))
print('轉換結果為:', np.float(False))
'''numpy中的隨機數函數random'''
# 生成隨機數組(無約束條件)
array9 = np.random.random(5)
# 生成隨機數組(服從均勻分布)
array10 = np.random.rand(2)
# 生成隨機數組(服從正態分布)
array11 = np.random.randn(3, 3)
# 生成隨機數組(給定上下范圍)
array12 = np.random.randint(1, 6, size=[2, 2]) # min=1 max=6 2行X2列e
'''通過索引訪問數組'''
array2[:1, :1] = 100 # 修改(1 ,1)元素為100
'''變換數組的形態'''
e = array2.reshape(1, 12) # 修改數組的形狀
f = array2.ravel() # 用ravel函數展平數組
g = array2.flatten() # 用flatten函數展平數組 默認為橫向展平
h = array2.flatten('F') # 用flatten函數展平數組 縱向展平
2. numpy中的矩陣及通用函數
1.矩陣的創建與組合:
import numpy as np # 導入類庫 numpy
'''矩陣創建'''
array = np.array(([1, 3, 5, 7], [2, 4, 6, 8], [1, 1, 1, 1])) # 創建三維數組
arr1 = np.mat("1 2 3;4 5 6;7 8 9") # 使用mat函數創建矩陣
arr2 = np.matrix([[123], [456], [789]]) # 使用matrix函數創建矩陣
a = np.bmat("arr1 arr2; arr1 arr2") # 使用bmat函數合成矩陣
print(a)
2.矩陣的運算:
矩陣與數相乘:matr1 _3
矩陣相加減:matr1±matr2
矩陣相乘:matr1 _ matr2
矩陣對應元素相乘:np.multiply(matr1,matr2)
矩陣特有屬性:

- 通用函數 (universal function),是一種能夠對數組中所有元素進行操作的函數。
四則運算:加(+)、減(-)、乘(*)、除(/)、冪(**)。數組間的四則運算表示對每個數組中的元素分別進行四則運算,所以形狀必須相同。
比較運算:>、<、==、>=、<=、!=。比較運算返回的結果是一個布爾數組,每個元素為每個數組對應元素的比較結果。
邏輯運算:np.any函數表示邏輯“or”,np.all函數表示邏輯“and”。運算結果返回布爾值。
通用函數的廣播機制
廣播 (broadcasting)是指 不同形狀的數組之間執行算術運算的方式 。需要遵循4個原則。
讓所有輸入數組都向其中shape最長的數組看齊,shape中不足的部分都通過在前面加1補齊。
輸出數組的shape是輸入數組shape的各個軸上的最大值。
如果輸入數組的某個軸和輸出數組的對應軸的長度相同或者其長度為1時,這個數組能夠用來計算,否則出錯。
當輸入數組的某個軸的長度為1時,沿着此軸運算時都用此軸上的第一組值。
一維數組的廣播機制:

二維數組的廣播機制:

3. 利用numpy 進行統計分析
- 文件讀寫方式
numpy文件讀寫主要有 二進制的文件讀寫 和 文件列表形式的數據讀寫 兩種形式。
備注:存儲時可以省略擴展名,但讀取時不能省略擴展名。
import numpy as np
np.save("../systemcode/save_array",array) # save函數是以二進制的格式保存數據
np.load("../systemcode/save_array.npy") # load函數是從二進制的文件中讀取數據
np.savez('../systemcode/savez_array',array1,array2) # savez函數可以將多個數組保存到一個文件中
np.savetxt("../code/array.txt", array, fmt="%d", delimiter=",") # savetxt函數是將數組寫到某種分隔符隔開的文本文件中
np.loadtxt("../code/array.txt", delimiter=",") # loadtxt函數執行的是把文件加載到一個二維數組中
np.genfromtxt("../code/array.txt", delimiter=",") # genfromtxt函數面向的是結構化數組和缺失數據
- 排序 :
- 直接排序
最常用的排序方法–sort函數
sort函數也可以指定一個axis參數,使得sort函數可以沿着指定軸對數據集進行排序。axis=1為沿橫軸排序; axis=0為沿縱軸排序。 - 間接排序
- argsort函數返回值為重新排序值的下標。 arr.argsort()
- lexsort函數返回值是按照最后一個傳入數據排序的。 np.lexsort((a,b,c))
CODE:
import numpy as np # 導入類庫 numpy
b =np.array([[0.86705753, 0.47270344, 0.46960053], [0.24891569, 0.52897057, 0.98737962],
[0.51857887, 0.58543909, 0.61704753]])
b.sort(axis=1)
print(b)
a = np.array([6, 2, 3])
c = np.array([9, 1, 3])
c.sort() # 直接排序
print('直接排序:', c)
d = c.argsort() # argsort函數返回值為重新排序值的下標
print('argsort函數排序:', d)
f = np.lexsort((c, a)) # lexsort函數返回值是按照最后一個傳入數據排序的
print('lexsort函數排序:', f)
- 去除重復數據(去重)
unique函數 :可以找出數組中的唯一值並返回已排序的結果。
tile函數 :主要有兩個參數,參數“A”指定重復的數組,參數“reps”指定重復的次數。
np.tile(A,reps)
repeat函數
:主要有三個參數,參數“a”是需要重復的數組元素,參數“repeats”是重復次數,參數“axis”指定沿着哪個軸進行重復,axis = 0表示 按行
進行元素重復;axis = 1表示 按列 進行元素重復。
numpy.repeat(a, repeats, axis=None)
兩個函數的 主要區別 :tile函數是對 數組 進行重復操作,repeat函數是對 數組中的每個元素 進行重復操作。
CODE:
import numpy as np # 導入類庫 numpy
a = np.array([11, 22, 54, 3, 6, 9, 8, 15])
b = np.repeat(a, 3) # repeat函數:重復數組中元素3次
print('repeat()函數:', b)
c = np.tile(a, 3) # tile函數:重復數組3次
print('tile()函數:', c)
d = np.unique(c) # 去重函數
print('unique()函數:', c)
'''運行結果'''
# D:\Anaconda3\python.exe E:/Python數據分析/code/test.py
# repeat()函數: [11 11 11 22 22 22 54 54 54 3 3 3 6 6 6 9 9 9 8 8 8 15 15 15]
# tile()函數: [11 22 54 3 6 9 8 15 11 22 54 3 6 9 8 15 11 22 54 3 6 9 8 15]
# unique()函數: [11 22 54 3 6 9 8 15 11 22 54 3 6 9 8 15 11 22 54 3 6 9 8 15]
- 常用統計函數
當axis=0時,表示沿着縱軸(行)計算。當axis=1時,表示沿着橫軸(列)計算。 默認時計算一個總值 。
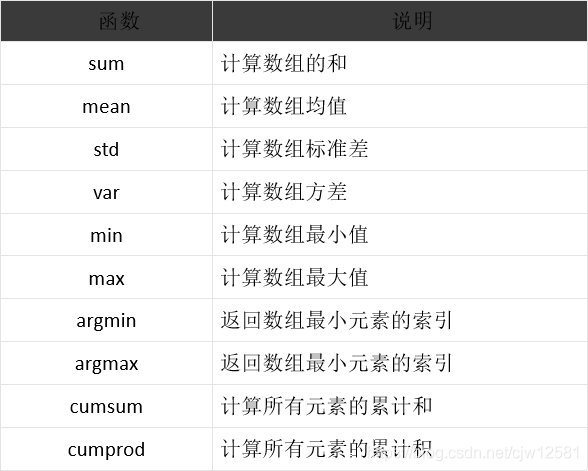
4. 案列:
讀取iris數據集中的花萼長度數據(已保存為csv格式),並對其進行排序、去重,並求出和、累積和、均值、標准差、方差、最小值、最大值。

'''案列:讀取iris數據集中的花萼長度數據(已保存為csv格式),並對其進行排序、去重,並求出和、累積和、均值、標准差、方差、最小值、最大值。'''
import numpy as np # 導入類庫 numpy
data = np.loadtxt('../data/iris_sepal_length.csv') # 讀取數據文件
data.sort() # 簡單排序
print('簡單排序后:', data)
data = np.unique(data) # 去除重復數據
print('數據去重后:', data)
print('數據求和:', np.sum(data)) # 數組求和
print('元素求和', np.cumsum(data)) # 元素求和
print('數據的均值:', np.mean(data)) # 均值
print('數據的標准差:', np.std(data)) # 標准差
print('數據的方差:', np.var(data)) # 方差
print('數據的最小值:', np.min(data)) # 最小值
print('數據的最大值:', np.max(data)) # 最大值
'''運行結果'''
# D:\Anaconda3\python.exe E:/Python數據分析/code/test.py
# 簡單排序后: [4.3 4.4 4.4 4.4 4.5 4.6 4.6 4.6 4.6 4.7 4.7 4.8 4.8 4.8 4.8 4.8 4.9 4.9
# 4.9 4.9 4.9 4.9 5. 5. 5. 5. 5. 5. 5. 5. 5. 5. 5.1 5.1 5.1 5.1
# 5.1 5.1 5.1 5.1 5.1 5.2 5.2 5.2 5.2 5.3 5.4 5.4 5.4 5.4 5.4 5.4 5.5 5.5
# 5.5 5.5 5.5 5.5 5.5 5.6 5.6 5.6 5.6 5.6 5.6 5.7 5.7 5.7 5.7 5.7 5.7 5.7
# 5.7 5.8 5.8 5.8 5.8 5.8 5.8 5.8 5.9 5.9 5.9 6. 6. 6. 6. 6. 6. 6.1
# 6.1 6.1 6.1 6.1 6.1 6.2 6.2 6.2 6.2 6.3 6.3 6.3 6.3 6.3 6.3 6.3 6.3 6.3
# 6.4 6.4 6.4 6.4 6.4 6.4 6.4 6.5 6.5 6.5 6.5 6.5 6.6 6.6 6.7 6.7 6.7 6.7
# 6.7 6.7 6.7 6.7 6.8 6.8 6.8 6.9 6.9 6.9 6.9 7. 7.1 7.2 7.2 7.2 7.3 7.4
# 7.6 7.7 7.7 7.7 7.7 7.9]
# 數據去重后: [4.3 4.4 4.5 4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6.
# 6.1 6.2 6.3 6.4 6.5 6.6 6.7 6.8 6.9 7. 7.1 7.2 7.3 7.4 7.6 7.7 7.9]
# 數據求和: 210.39999999999998
# 元素求和 [ 4.3 8.7 13.2 17.8 22.5 27.3 32.2 37.2 42.3 47.5 52.8 58.2
# 63.7 69.3 75. 80.8 86.7 92.7 98.8 105. 111.3 117.7 124.2 130.8
# 137.5 144.3 151.2 158.2 165.3 172.5 179.8 187.2 194.8 202.5 210.4]
# 數據的均值: 6.011428571428571
# 數據的標准差: 1.0289443768310533
# 數據的方差: 1.0587265306122449
# 數據的最小值: 4.3
# 數據的最大值: 7.9
#
# Process finished with exit code 0
_END _
