1. hive內部表和外部表的區別
未被external修飾的是內部表,被external修飾的為外部表。
本文首發於公眾號【五分鍾學大數據】,關注公眾號,獲取最新大數據技術文章
區別:
-
內部表數據由Hive自身管理,外部表數據由HDFS管理;
-
內部表數據存儲的位置是
hive.metastore.warehouse.dir(默認:/user/hive/warehouse),外部表數據的存儲位置由自己制定(如果沒有LOCATION,Hive將在HDFS上的/user/hive/warehouse文件夾下以外部表的表名創建一個文件夾,並將屬於這個表的數據存放在這里); -
刪除內部表會直接刪除元數據(metadata)及存儲數據;刪除外部表僅僅會刪除元數據,HDFS上的文件並不會被刪除。
本文首發於公眾號【五分鍾學大數據】
2. Hive有索引嗎
Hive支持索引(3.0版本之前),但是Hive的索引與關系型數據庫中的索引並不相同,比如,Hive不支持主鍵或者外鍵。並且Hive索引提供的功能很有限,效率也並不高,因此Hive索引很少使用。
- 索引適用的場景:
適用於不更新的靜態字段。以免總是重建索引數據。每次建立、更新數據后,都要重建索引以構建索引表。
- Hive索引的機制如下:
hive在指定列上建立索引,會產生一張索引表(Hive的一張物理表),里面的字段包括:索引列的值、該值對應的HDFS文件路徑、該值在文件中的偏移量。
Hive 0.8版本后引入bitmap索引處理器,這個處理器適用於去重后,值較少的列(例如,某字段的取值只可能是幾個枚舉值)
因為索引是用空間換時間,索引列的取值過多會導致建立bitmap索引表過大。
注意:Hive中每次有數據時需要及時更新索引,相當於重建一個新表,否則會影響數據查詢的效率和准確性,Hive官方文檔已經明確表示Hive的索引不推薦被使用,在新版本的Hive中已經被廢棄了。
擴展:Hive是在0.7版本之后支持索引的,在0.8版本后引入bitmap索引處理器,在3.0版本開始移除索引的功能,取而代之的是2.3版本開始的物化視圖,自動重寫的物化視圖替代了索引的功能。
3. 運維如何對hive進行調度
-
將hive的sql定義在腳本當中;
-
使用azkaban或者oozie進行任務的調度;
-
監控任務調度頁面。
4. ORC、Parquet等列式存儲的優點
ORC和Parquet都是高性能的存儲方式,這兩種存儲格式總會帶來存儲和性能上的提升。
Parquet:
-
Parquet支持嵌套的數據模型,類似於Protocol Buffers,每一個數據模型的schema包含多個字段,每一個字段有三個屬性:重復次數、數據類型和字段名。
重復次數可以是以下三種:required(只出現1次),repeated(出現0次或多次),optional(出現0次或1次)。每一個字段的數據類型可以分成兩種:
group(復雜類型)和primitive(基本類型)。 -
Parquet中沒有Map、Array這樣的復雜數據結構,但是可以通過repeated和group組合來實現的。
-
由於Parquet支持的數據模型比較松散,可能一條記錄中存在比較深的嵌套關系,如果為每一條記錄都維護一個類似的樹狀結可能會占用較大的存儲空間,因此Dremel論文中提出了一種高效的對於嵌套數據格式的壓縮算法:Striping/Assembly算法。通過Striping/Assembly算法,parquet可以使用較少的存儲空間表示復雜的嵌套格式,並且通常Repetition level和Definition level都是較小的整數值,可以通過RLE算法對其進行壓縮,進一步降低存儲空間。
-
Parquet文件是以二進制方式存儲的,是不可以直接讀取和修改的,Parquet文件是自解析的,文件中包括該文件的數據和元數據。
ORC:
-
ORC文件是自描述的,它的元數據使用Protocol Buffers序列化,並且文件中的數據盡可能的壓縮以降低存儲空間的消耗。
-
和Parquet類似,ORC文件也是以二進制方式存儲的,所以是不可以直接讀取,ORC文件也是自解析的,它包含許多的元數據,這些元數據都是同構ProtoBuffer進行序列化的。
-
ORC會盡可能合並多個離散的區間盡可能的減少I/O次數。
-
ORC中使用了更加精確的索引信息,使得在讀取數據時可以指定從任意一行開始讀取,更細粒度的統計信息使得讀取ORC文件跳過整個row group,ORC默認會對任何一塊數據和索引信息使用ZLIB壓縮,因此ORC文件占用的存儲空間也更小。
-
在新版本的ORC中也加入了對Bloom Filter的支持,它可以進一
步提升謂詞下推的效率,在Hive 1.2.0版本以后也加入了對此的支
持。
5. 數據建模用的哪些模型?
1. 星型模型

星形模式(Star Schema)是最常用的維度建模方式。星型模式是以事實表為中心,所有的維度表直接連接在事實表上,像星星一樣。
星形模式的維度建模由一個事實表和一組維表成,且具有以下特點:
a. 維表只和事實表關聯,維表之間沒有關聯;
b. 每個維表主鍵為單列,且該主鍵放置在事實表中,作為兩邊連接的外鍵;
c. 以事實表為核心,維表圍繞核心呈星形分布。
2. 雪花模型
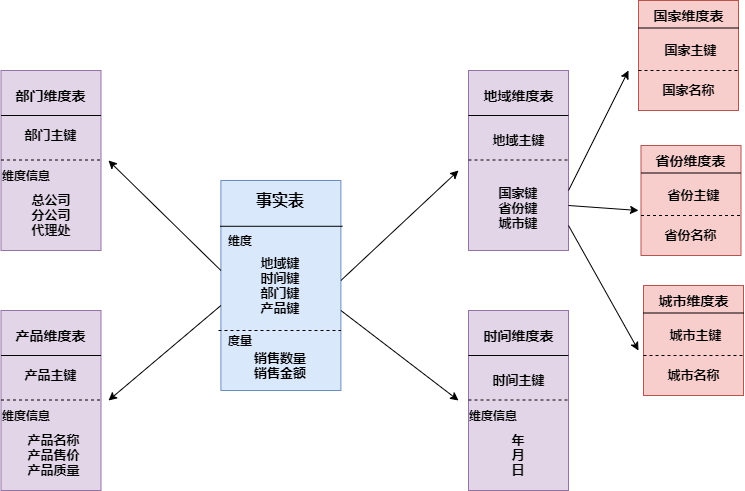
雪花模式(Snowflake Schema)是對星形模式的擴展。雪花模式的維度表可以擁有其他維度表的,雖然這種模型相比星型更規范一些,但是由於這種模型不太容易理解,維護成本比較高,而且性能方面需要關聯多層維表,性能比星型模型要低。
3. 星座模型
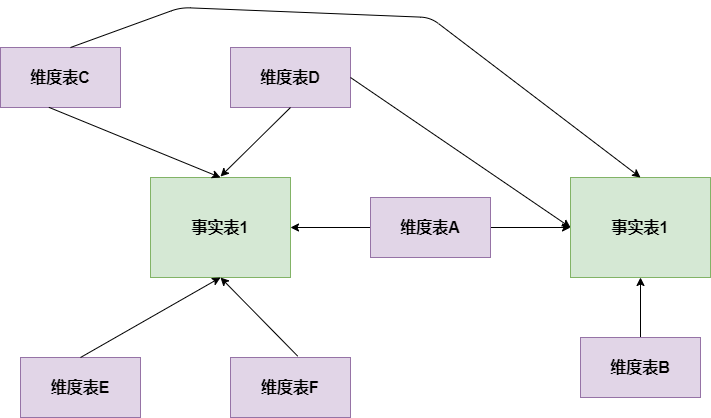
星座模式是星型模式延伸而來,星型模式是基於一張事實表的,而星座模式是基於多張事實表的,而且共享維度信息。前面介紹的兩種維度建模方法都是多維表對應單事實表,但在很多時候維度空間內的事實表不止一個,而一個維表也可能被多個事實表用到。在業務發展后期,絕大部分維度建模都采用的是星座模式。
數倉建模詳細介紹可查看:通俗易懂數倉建模
6. 為什么要對數據倉庫分層?
-
用空間換時間,通過大量的預處理來提升應用系統的用戶體驗(效率),因此數據倉庫會存在大量冗余的數據。
-
如果不分層的話,如果源業務系統的業務規則發生變化將會影響整個數據清洗過程,工作量巨大。
-
通過數據分層管理可以簡化數據清洗的過程,因為把原來一步的工作分到了多個步驟去完成,相當於把一個復雜的工作拆成了多個簡單的工作,把一個大的黑盒變成了一個白盒,每一層的處理邏輯都相對簡單和容易理解,這樣我們比較容易保證每一個步驟的正確性,當數據發生錯誤的時候,往往我們只需要局部調整某個步驟即可。
數據倉庫詳細介紹可查看:萬字詳解整個數據倉庫建設體系
7. 使用過Hive解析JSON串嗎
Hive處理json數據總體來說有兩個方向的路走:
-
將json以字符串的方式整個入Hive表,然后通過使用UDF函數解析已經導入到hive中的數據,比如使用
LATERAL VIEW json_tuple的方法,獲取所需要的列名。 -
在導入之前將json拆成各個字段,導入Hive表的數據是已經解析過的。這將需要使用第三方的
SerDe。
詳細介紹可查看:Hive解析Json數組超全講解
8. sort by 和 order by 的區別
order by 會對輸入做全局排序,因此只有一個reducer(多個reducer無法保證全局有序)只有一個reducer,會導致當輸入規模較大時,需要較長的計算時間。
sort by不是全局排序,其在數據進入reducer前完成排序.
因此,如果用sort by進行排序,並且設置mapred.reduce.tasks>1, 則sort by只保證每個reducer的輸出有序,不保證全局有序。
9. 數據傾斜怎么解決
數據傾斜問題主要有以下幾種:
-
空值引發的數據傾斜
-
不同數據類型引發的數據傾斜
-
不可拆分大文件引發的數據傾斜
-
數據膨脹引發的數據傾斜
-
表連接時引發的數據傾斜
-
確實無法減少數據量引發的數據傾斜
以上傾斜問題的具體解決方案可查看:Hive千億級數據傾斜解決方案
注意:對於 left join 或者 right join 來說,不會對關聯的字段自動去除null值,對於 inner join 來說,會對關聯的字段自動去除null值。
小伙伴們在閱讀時注意下,在上面的文章(Hive千億級數據傾斜解決方案)中,有一處sql出現了上述問題(舉例的時候原本是想使用left join的,結果手誤寫成了join)。此問題由公眾號讀者發現,感謝這位讀者指正。
10. Hive 小文件過多怎么解決
1. 使用 hive 自帶的 concatenate 命令,自動合並小文件
使用方法:
#對於非分區表
alter table A concatenate;
#對於分區表
alter table B partition(day=20201224) concatenate;
注意:
1、concatenate 命令只支持 RCFILE 和 ORC 文件類型。
2、使用concatenate命令合並小文件時不能指定合並后的文件數量,但可以多次執行該命令。
3、當多次使用concatenate后文件數量不在變化,這個跟參數 mapreduce.input.fileinputformat.split.minsize=256mb 的設置有關,可設定每個文件的最小size。
2. 調整參數減少Map數量
設置map輸入合並小文件的相關參數(執行Map前進行小文件合並):
在mapper中將多個文件合成一個split作為輸入(CombineHiveInputFormat底層是Hadoop的CombineFileInputFormat方法):
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 默認
每個Map最大輸入大小(這個值決定了合並后文件的數量):
set mapred.max.split.size=256000000; -- 256M
一個節點上split的至少大小(這個值決定了多個DataNode上的文件是否需要合並):
set mapred.min.split.size.per.node=100000000; -- 100M
一個交換機下split的至少大小(這個值決定了多個交換機上的文件是否需要合並):
set mapred.min.split.size.per.rack=100000000; -- 100M
3. 減少Reduce的數量
reduce 的個數決定了輸出的文件的個數,所以可以調整reduce的個數控制hive表的文件數量。
hive中的分區函數 distribute by 正好是控制MR中partition分區的,可以通過設置reduce的數量,結合分區函數讓數據均衡的進入每個reduce即可:
#設置reduce的數量有兩種方式,第一種是直接設置reduce個數
set mapreduce.job.reduces=10;
#第二種是設置每個reduce的大小,Hive會根據數據總大小猜測確定一個reduce個數
set hive.exec.reducers.bytes.per.reducer=5120000000; -- 默認是1G,設置為5G
#執行以下語句,將數據均衡的分配到reduce中
set mapreduce.job.reduces=10;
insert overwrite table A partition(dt)
select * from B
distribute by rand();
對於上述語句解釋:如設置reduce數量為10,使用 rand(), 隨機生成一個數 x % 10 ,
這樣數據就會隨機進入 reduce 中,防止出現有的文件過大或過小。
4. 使用hadoop的archive將小文件歸檔
Hadoop Archive簡稱HAR,是一個高效地將小文件放入HDFS塊中的文件存檔工具,它能夠將多個小文件打包成一個HAR文件,這樣在減少namenode內存使用的同時,仍然允許對文件進行透明的訪問。
#用來控制歸檔是否可用
set hive.archive.enabled=true;
#通知Hive在創建歸檔時是否可以設置父目錄
set hive.archive.har.parentdir.settable=true;
#控制需要歸檔文件的大小
set har.partfile.size=1099511627776;
使用以下命令進行歸檔:
ALTER TABLE A ARCHIVE PARTITION(dt='2021-05-07', hr='12');
對已歸檔的分區恢復為原文件:
ALTER TABLE A UNARCHIVE PARTITION(dt='2021-05-07', hr='12');
注意:
歸檔的分區可以查看不能 insert overwrite,必須先 unarchive
Hive 小文件問題具體可查看:解決hive小文件過多問題
11. Hive優化有哪些
1. 數據存儲及壓縮:
針對hive中表的存儲格式通常有orc和parquet,壓縮格式一般使用snappy。相比與textfile格式表,orc占有更少的存儲。因為hive底層使用MR計算架構,數據流是hdfs到磁盤再到hdfs,而且會有很多次,所以使用orc數據格式和snappy壓縮策略可以降低IO讀寫,還能降低網絡傳輸量,這樣在一定程度上可以節省存儲,還能提升hql任務執行效率;
2. 通過調參優化:
並行執行,調節parallel參數;
調節jvm參數,重用jvm;
設置map、reduce的參數;開啟strict mode模式;
關閉推測執行設置。
3. 有效地減小數據集將大表拆分成子表;結合使用外部表和分區表。
4. SQL優化
-
大表對大表:盡量減少數據集,可以通過分區表,避免掃描全表或者全字段;
-
大表對小表:設置自動識別小表,將小表放入內存中去執行。
Hive優化詳細剖析可查看:Hive企業級性能優化
微信搜索公眾號【五分鍾學大數據】,獲取最新的大數據技術文章