文章首發於公眾號 “蘑菇睡不着”
前言
Redis 的主從復制和 MySQL 差不多,主要起着 數據備份,讀寫分離等作用。所以說主從復制對 Redis 來說非常重要,而無論是面試還是工作總,了解 Redis主從復制 底層實現有非常有必要,那么接下來就和大家來看看 Redis 主從復制是怎么實現的吧。
什么是 Redis 主從復制?
在 Redis 中,我們可以通過 SLAVEOF 命令或者 slaveof 選項,讓一個服務器去復制另一個服務器,被復制的服務器稱為“主服務器”,發起復制的服務器稱為“從服務器”,由兩種服務器組成的模式稱為“主從復制”。
Redis 主從復制有以下特點:
- Redis 使用異步復制,slave 和 master 之間異步地確認處理的數據量。
- 一個 master 可以擁有多個 slave。
- slave 可以接受其他 slave 的連接。除了多個 slave 可以連接到同一個 master 之外, slave 之間也可以像層疊狀的結構(cascading-like structure)連接到其他 slave 。自 Redis 4.0 起,所有的 sub-slave 將會從 master 收到完全一樣的復制流。
- Redis 復制在 master 側是非阻塞的。這意味着 master 在一個或多個 slave 進行初次同步或者是部分重同步時,可以繼續處理查詢請求。
- 復制在 slave 側大部分也是非阻塞的。當然這個是可配的,如果在 redis.conf配置是非阻塞的,可以使用舊數據集處理查詢請求;如果配置的是阻塞的,slave 會返回一個 error 給客戶端。
怎么實現主從復制?
假設現在有兩個 Redis 服務器,地址分別為 127.0.0.1:6379 和 127.0.0.1:12345,如果在服務器 127.0.0.1:12345 執行以下命令:
127.0.0.1:12345> SLAVEOF 127.0.0.1 6379
OK
那么服務器127.0.0.1:12345就是127.0.0.1:6379 的從服務器。主從服務器的數據會保持一致
比如主服務器存儲數據:
127.0.0.1:6379> set msg "hello world"
OK
然后從服務器就能直接獲取數據:
127.0.0.1:12345>get msg
"hello world"
刪除數據也是一樣,主從會保持一致。
主從復制原理
首先,Redis 的復制分為同步(sync)和命令傳播(command propagate)兩個操作:
- 同步操作用於將從服務器數據庫的狀態更新為主服務器所處的狀態。
- 命令傳播則相反,它主要作用在主服務器的數據庫狀態更改時,導致主從服務器的數據庫狀態出現不一致時,讓主從回到一致的的過程。
接下來詳細說說這兩種復制。
同步
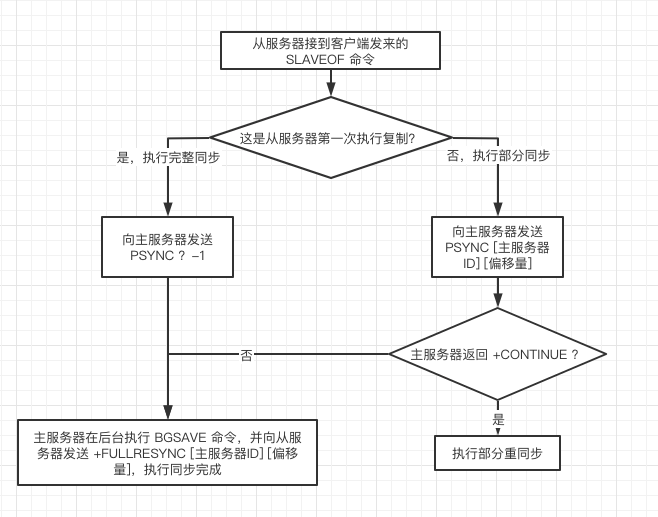
文字解說:
- 客戶端向從服務器發送 SLAVEOF 命令,先是判斷是否是第一次復制,第一次是復制一般是剛開始組建主從關系。
- 是第一次復制:從服務器會向主服務器發送 PSYNC ? -1 命令,請求主服務器執行完整重同步操作。
- 主服務器接到完整重同步請求之后,將在后台執行 BGSAVE 命令,在后台生成一個 RDB 文件,並使用一個復制積壓緩沖區記錄從現在開始執行的所有寫命令。
- BGSAVE 命令執行完畢之后,主服務器會將 RDB 文件以及 緩沖區中記錄的寫命令發送給從服務器,還會向從服務器返回 +FULLRESYNC [主服務器ID] [復制偏移量](和圖中的 偏移量 是一個)。
- 從服務器接收到后,會載入 RDB 文件,並執行 主服務器給的 寫命令,以此來達到和主服務器一致的數據狀態。
- 如果不是第一次復制,那么說明從服務器可能是斷線,導致和主服務器數據狀態不一致,需要同步主服務器的數據。那么從服務器會按照下面的步驟來請求部分同步。
- 向主服務器發送 PSYNC [主服務器ID] [復制偏移量](這個是第一次復制時主服務器傳過來的),主服務器ID 時斷線前的主服務器,用於定位去同步那個主服務器的;復制偏移量是上一次同步的位置,用於定位具體的同步位置的。
- 主服務器接收到從服務器的命令后,並找到相應同步的位置后,會給從服務器發送 +CONTINUE 命令,表示將於從服務器執行部分同步操作,之后主服務器會將保存在復制積壓緩沖區對應 復制偏移量之后的所有數據發送給從服務器,但是如果找不到偏移量之后的數據,就會進行完整同步,這樣就可以讓從服務器達到和主服務器一致的狀態。
命令傳播
主從服務器同步成功后,並不會一致保持這個狀態,主服務器可能會執行寫命令,這也主從數據就不知一致了。
為了處理這種問題,主服務器會把自己執行的寫命令發送給從服務器,當從服務器執行完這些命令之后,主從服務器的數據就一致了。
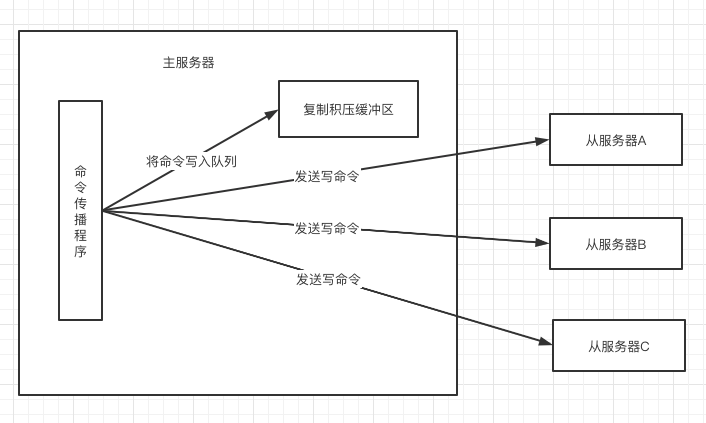
在命令傳播階段,從服務器默認會以每秒一次的頻率,向主服務器發送命令:
REPLCONF ACK <replication_offset>
<replication_offset> 是從服務器當前的復制偏移量。
發送 REPLCONF ACK 命令對於主從服務器有三個作用:
- 檢測主從服務器的網絡狀態。
- 輔助實現 min-slaves 選項。
- 檢測命令丟失。
關鍵詞講解
- 主服務器ID:用於標識一個服務器。
- 每個服務器,無論是主服務器還是從服務器都有屬於自己獨一無二的 服務器ID。
- ID 在服務器啟動時生成,由 40 個隨機的十六進制字符組成。
- 復制積壓緩沖區:復制積壓緩沖區是由主服務器維護的一個固定長度、先進先出(FIFO)隊列,默認大小為 1MB。如下:
| 偏移量 | ... | 10086 | 10087 | 10088 | 10089 | ... |
|---|---|---|---|---|---|---|
| 字節值 | ... | 3 | '\r' | '\n' | '$' | ... |
總結
Redis 主從復制主要是通過 PSYNC 命令實現。
復制分為 部分復制 以及 完整復制。
部分復制通過 復制偏移量、復制積壓緩沖區、服務器ID來實現。
完整復制通過 RDB 以及 復制積壓緩沖區來實現。
主從復制主要解決的是 數據備份、讀寫分離的問題。
最后
如果覺得文章對你有幫助,點贊、關注、轉發 統統走起來~
可以去公眾號 蘑菇睡不着 看看,更多精彩內容等你。