什么是任務調度
大數據平台技術框架支持的開發語言多種多樣,開發人員的背景差異也很大,這就產生出很多不同類型的程序(任務)運行在大數據平台之上,如:MapReduce、Hive、Pig、Spark、Java、Shell、Python 等。
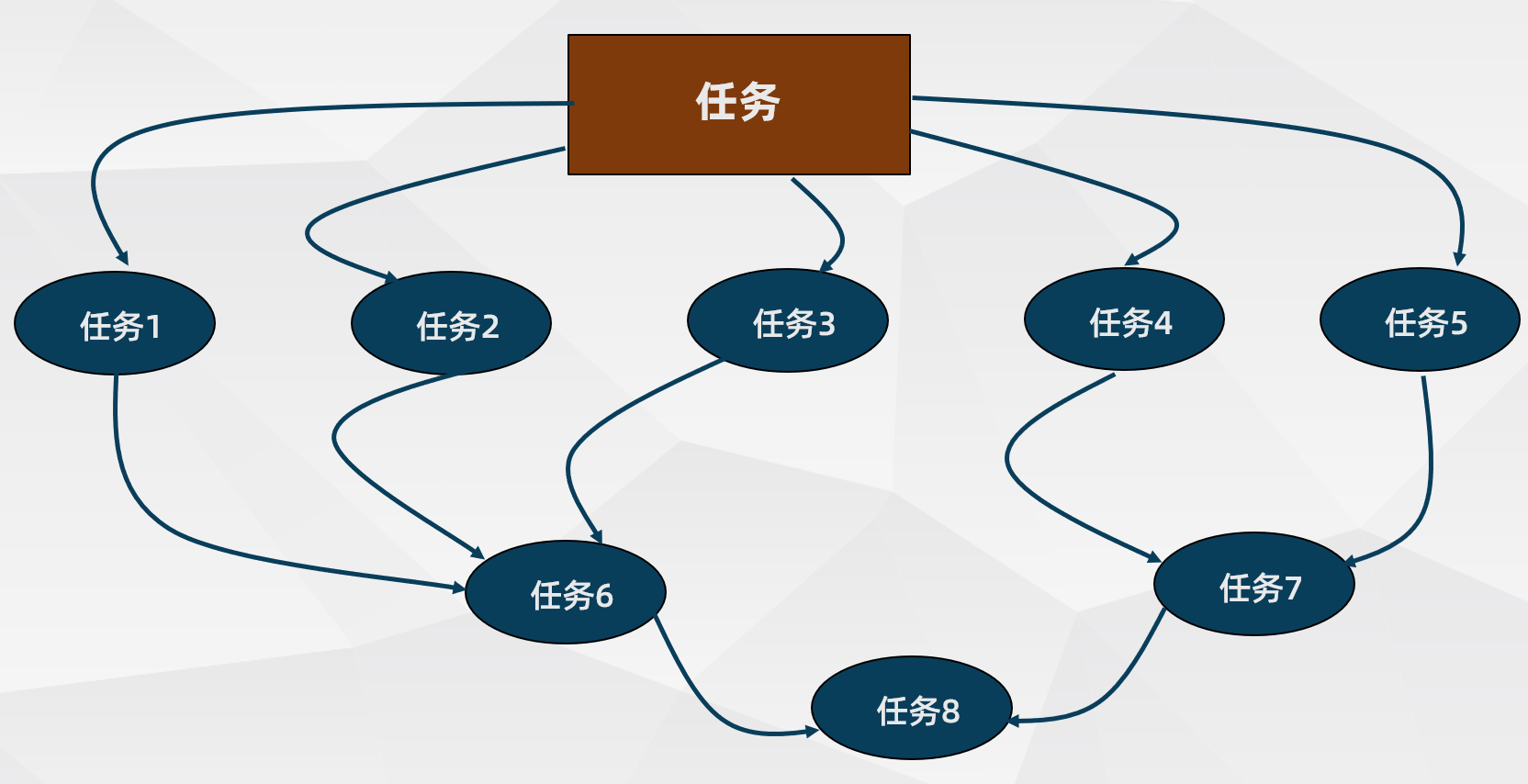
這些任務需要不同的運行環境,並且除了定時運行,各種類型之間的任務存在依賴關系,一張簡單的任務依賴圖如下:
常見任務調度工具
- crontab (Linux 自帶命令,使用方式簡單,適合不是非常復雜的場景,比如只按照時間來調度)
- oozie( Hadoop 自帶的開源調度系統,使用方式比較復雜,適合大型項目場景)
- azkaban(一個開源調度系統,使用方式比較簡單,適合中小型項目場景)
- 企業定制開發(企業自研的調度系統,不開源)
Azkaban 是什么
Azkaban 是由 Linkedin 公司推出的一個批量工作流任務調度器,Azkaban 使用 job 文件建立任務之間的依賴關系,並提供 Web 界面供用戶管理和調度工作流
Azkaban 特點
Azkaban 是由 Linkedin 開源的一個批量工作流任務調度器。用於在一個工作流內以一個特定的順序運行一組工作和流程。Azkaban 定義了一種 KV 文件格式來建立任務之間的依賴關系,並提供一個易於使用的 web 用戶界面維護和跟蹤你的工作流。
它有如下功能特點:
- Web 用戶界面
- 方便上傳工作流
- 方便設置任務之間的關系
- 調度工作流
- 認證/授權(權限的工作)
- 能夠殺死並重新啟動工作流
- 模塊化和可插拔的插件機制
- 項目工作區
- 工作流和任務的日志記錄和審計
Azkaban 與 Oozie 對比
Azkaban 和 Oozie 是市面上最流行的兩種調度器。總體來說,Ooize 相比 Azkaban 是一個重量級的任務調度系統,功能全面,但部署和使用也更復雜,比較適合作為大型項目的任務調度系統。而 Azkaban 相對而言,配置和使用更為簡單,能夠滿足常見的任務調度,比較適合作為中小型項目的任務調度系統。
Azkaban 和 Oozie 詳情對比如下:
-
功能
兩者均可以調度 mapreduce,pig,java,腳本工作流任務
兩者均可以定時執行工作流任務 -
工作流定義
Azkaban 使用 Properties 文件定義工作流
Oozie 使用 XML 文件定義工作流 -
工作流傳參
Azkaban 支持直接傳參
Oozie 支持參數和 EL 表達式
-
定時執行
Azkaban 的定時執行任務是基於時間的
Oozie 的定時執行任務基於時間和輸入數據 -
資源管理
Azkaban 有較嚴格的權限控制,如用戶對工作流進行讀/寫/執行等操作
Oozie 暫無嚴格的權限控制 -
工作流執行
Azkaban 有兩種運行模式,分別是單機模式和集群模式
Oozie 作為工作流服務器運行,支持多用戶和多工作流 -
工作流管理
Azkaban 支持瀏覽器以及 ajax 方式操作工作流
Oozie 支持命令行、HTTP REST、Java API、瀏覽器操作工作流
Azkaban 運行模式及架構
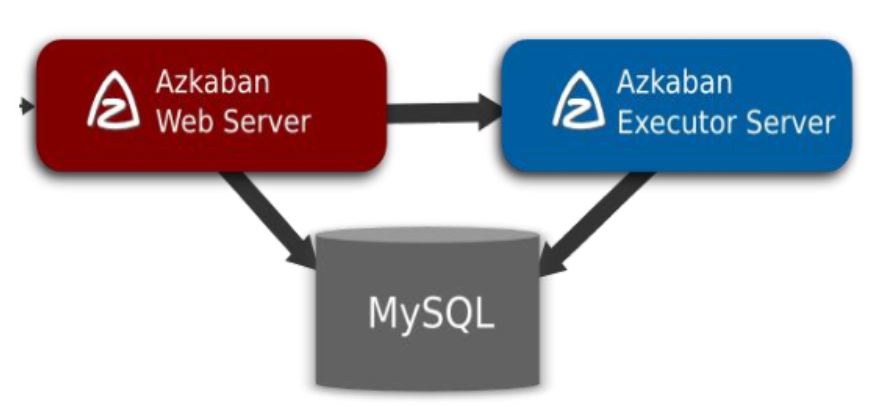
Azkaban 三大核心組件
- 關系型元數據庫(MySQL)
- Azkaban Web Server
- Azkaban Executor Server
Azkaban有兩種部署方式
-
solo server mode(單機模式)
WebServer 和 ExecutorServer 在同一個進程
-
cluster server mode(集群模式)
WebServe r和 ExecutorServer 運行在不同進程,並用數據庫保存定義及狀態
- 單個Executor
- 多個Executor
Azkaban Web Server
AzkabanWebServer 是 Azkaban 的主要管理者,負責項目管理、身份驗證、調度和監控執行,並且為用戶界面
Azkaban Executor
提交和執行工作流,記錄工作流日志,和 Azkaban WebServer 可以在同一台服務器,也可部署在獨立的機器。把 Executor 單獨分開有幾個好處:
- 在多 Executor 模式下可以方便擴展
- 工作流在某一個 Executor 掛掉,可以在另一個 Executor 上重試
- 可以滾動升級,從而不影響調度
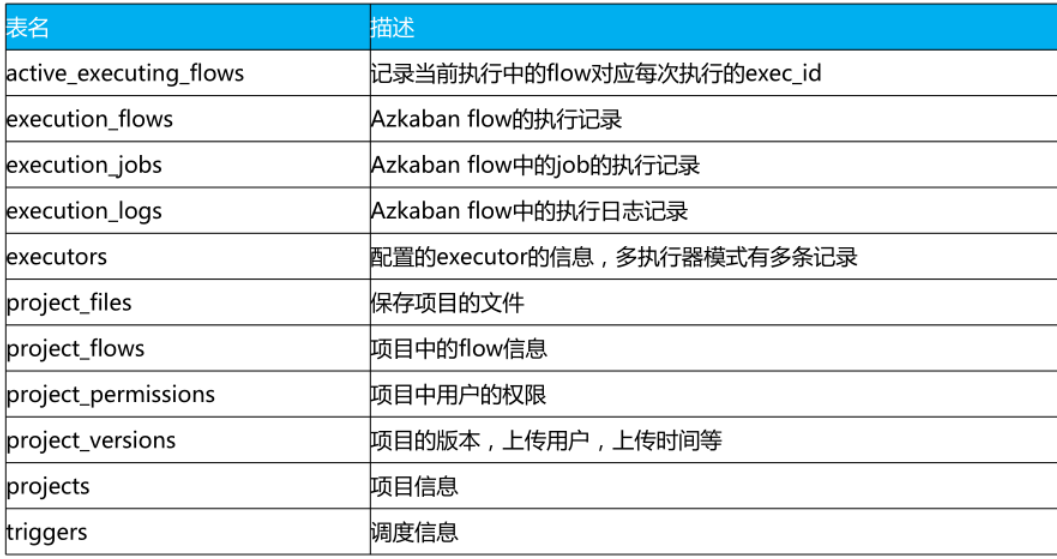
Azkaban 元數據庫
Azkaban 任務調度步驟
- Azkaban 新建項目
- 在 Azkaban Web 界面創建 Project
- 創建 job 文件
- 將文件壓縮為 zip 文件
- 上傳 zip 文件到 Web 界面
- 執行調度
Azkaban 常見任務類型
執行 shell 命令
type=command
command=echo 'hello'
執行 shell 腳本
type=command
command=sh hello.sh
執行 Spark 程序
type=command
command=/usr/install/spark/bin/spark-submit --class com.test.AzkabanTest test-1.0-SNAPSHOT.jar
hive 命令\腳本
type=command
command=beeline -u jdbc:hive2://localhost:10000 -n hive -p hive -f 'test.sql'
執行 MapReduce 程序
type=command
command=${HADOOP_HOME}bin/hadoop jar hadoop-mapreduce-examples-2.8.0.jar
wordcount ${input} ${output}