文章首發於公眾號“蘑菇睡不着”,歡迎來訪~
前言
大家都知道 Redis 是一個內存數據庫,數據都存儲在內存中,這也是 Redis 非常快的原因之一。雖然速度提上來了,但是如果數據一直放在內存中,是非常容易丟失的。比如 服務器關閉或宕機了,內存中的數據就木有了。為了解決這一問題,Redis 提供了 持久化 機制。分別是 RDB 以及 AOF 持久化。
RDB
什么是 RDB 持久化?
RDB 持久化可以在指定的時間間隔內生成數據集的時間點快照(point-in-time snapshot)。
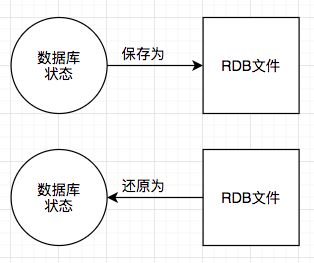
RDB 的優點?
- RDB 是一種表示某個即時點的 Redis 數據的緊湊文件。RDB 文件適用於備份。例如,你可能想要每小時歸檔最近24小時的 RDB 文件,每天保存近30天的 RDB 快照。這允許你很容易的恢復不同版本的數據集以容災。
- RDB 非常適合於災難恢復,作為一個緊湊的單一文件,可以被傳輸到遠程的數據中心。
- RDB 最大化了 Redis 的性能。因為 Redis 父進程持久化時唯一需要做的是啟動(fork)一個子進程,由子進程完成所有剩余的工作。父進程實例不需要執行像磁盤IO這樣的操作。
- RDB 在重啟保存了大數據集的實例比 AOF 快。
RDB 的缺點?
- 當你需要在Redis停止工作(例如停電)時最小化數據丟失,RDB可能不太好。你可以配置不同的保存點(save point)來保存RDB文件(例如,至少5分鍾和對數據集100次寫之后,但是你可以有多個保存點)。然而,你通常每隔5分鍾或更久創建一個RDB快照,所以一旦Redis因為任何原因沒有正確關閉而停止工作,你就得做好最近幾分鍾數據丟失的准備了。
- RDB需要經常調用fork()子進程來持久化到磁盤。如果數據集很大的話,fork()比較耗時,結果就是,當數據集非常大並且CPU性能不夠強大的話,Redis會停止服務客戶端幾毫秒甚至一秒。AOF也需要fork(),但是你可以調整多久頻率重寫日志而不會有損(trade-off)持久性(durability)。
RDB 文件的創建與載入
有個兩個 Redis 命令可以用於生成 RDB 文件,一個是 SAVE,另一個是 BGSAVE。
SAVE 命令會阻塞 Redis 服務器進程,直到 RDB 文件創建完畢為止,在服務器進程阻塞期間,服務器不能處理任何命令請求。
> SAVE // 一直等到 RDB 文件創建完畢
OK
和 SAVE 命令直接阻塞服務器進程不同的是,BGSAVE 命令會派生出一個子進程,然后由子進程負責創建 RDB 文件,服務器進程(父進程)繼續處理命令進程。
執行fork的時候操作系統(類Unix操作系統)會使用寫時復制(copy-on-write)策略,即fork函數發生的一刻父子進程共享同一內存數據,當父進程要更改其中某片數據時(如執行一個寫命令 ),操作系統會將該片數據復制一份以保證子進程的數據不受影響,所以新的RDB文件存儲的是執行fork一刻的內存數據。
> BGSAVE // 派生子進程,並由子進程創建 RDB 文件
Background saving started
生成 RDB 文件由兩種方式:一種是手動,就是上邊介紹的用命令的方式;另一種是自動的方式。
接下來詳細介紹一下自動生成 RDB 文件的流程。
Redis 允許用戶通過設置服務器配置的 save 選項,讓服務器每隔一段時間自動執行一次 BGSAVE 命令。
用戶可以通過在 redis.conf 配置文件中的 SNAPSHOTTING 下 save 選項設置多個保存條件,但只要其中任意一個條件被滿足,服務器就會執行 BGSAEVE 命令。
如,以下配置:
save 900 1
save 300 10
save 60 10000
上邊三個配置的含義是:
- 服務器在 900 秒內,對數據庫進行了至少 1 次修改。
- 服務器在 300 秒內,對數據庫進行了至少 10 次修改。
- 服務器在 60 秒內,對數據庫進行了至少 10000 次修改。
如果沒有手動去配置 save 選項,那么服務器會為 save 選項配置默認參數:
save 900 1
save 300 10
save 60 10000
接着,服務器就會根據 save 選項的配置,去設置服務器狀態 redisServer 結構的 saveparams 屬性:
struct redisServer{
// ...
// 記錄了保存條件的數組
struct saveparams *saveparams;
// ...
};
saveparams 屬性是一個數組,數組中的每一個元素都是一個 saveparam 結構,每個 saveparam 結構都保存了一個 save 選項設置的保存條件:
struct saveparam {
// 秒數
time_t seconds;
// 修改數
int changes;
};
除了 saveparams 數組之外,服務器狀態還維持着一個 dirty 計數器,以及一個 lastsave 屬性;
struct redisServer {
// ...
// 修改計數器
long long dirty;
// 上一次執行保存時間
time_t lastsave;
// ...
}
- dirty 計數器記錄距離上一次成功執行 SAVE 或 BGSAVE 命令之后,服務器對數據庫狀態(服務器中的所有數據庫)進行了多少次修改(包括寫入、刪除、更新等操作)。
- lastsave 屬性是一個 UNIX 時間戳,記錄了服務器上一次執行 SAVE 或 BGSAVE 命令的時間。
檢查條件是否滿足觸發 RDB
Redis 的服務器周期性操作函數 serverCron 默認每隔 100 毫秒執行一次,該函數用於對正在運行的服務器進行維護,它的其中一項工作就是檢查 save 選項所設置的保存條件是否已經滿足,如果滿足的話就執行 BGSAVE 命令。
Redis serverCron 源碼解析如下:

程序會遍歷並檢查 saveparams 數組中的所有保存條件,只要有任意一個條件被滿足,服務器就會執行 BGSAVE 命令。
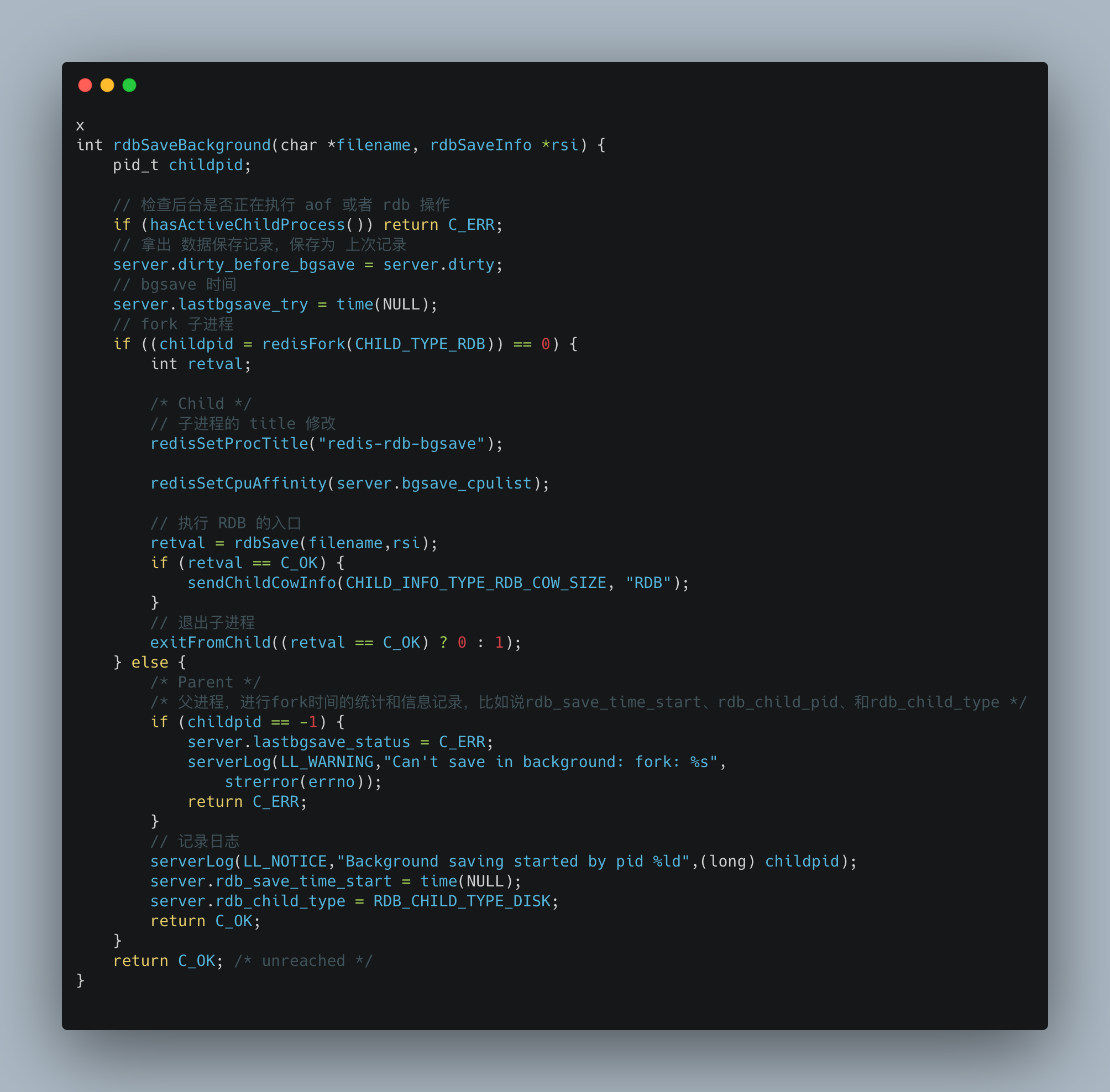
下面是 rdbSaveBackground 的源碼流程:
RDB 文件結構
下圖展示了一個完整 RDB 文件所包含的各個部分。

redis 文件的最開頭是 REDIS 部分,這個部分的長度是 5 字節,保存着 “REDIS” 五個字符。通過這五個字符,程序可以在載入文件時,快速檢查所載入的文件是否時 RDB 文件。
db_version 長度為 4 字節,他的值時一個字符串表示的整數,這個整數記錄了 RDB 文件的版本號,比如 “0006” 就代表 RDB 文件的版本為第六版。
database 部分包含着零個或任意多個數據庫,以及各個數據庫中的鍵值對數據:
- 如果服務器的數據庫狀態為空(所有數據庫都是空的),那么這個部分也為空,長度為 0 字節。
- 如果服務器的數據庫狀態為非空(有至少一個數據庫非空),那么這個部分也為非空,根據數據庫所保存鍵值對的數量、類型和內容不同,這個部分的長度也會有所不同。
EOF 常量的長度為 1 字節,這個常量標志着 RDB 文件正文內容的結束,當讀入程序遇到這個值后,他知道所有數據庫的所有鍵值對已經載入完畢了。
check_sum 是一個 8 字節長的無符號整數,保存着一個校驗和,這個校驗和時程序通過對 REDIS、db_version、database、EOF 四個部分的內容進行計算得出的。服務器在載入 RDB 文件時,會將載入數據所計算出的校驗和與 check_sum 所記錄的校驗和進行對比,以此來檢查 RDB 是否有出錯或者損壞的情況。
舉個例子:下圖是一個 0 號數據庫和 3 號數據庫的 RDB 文件。第一個就是 “REDIS” 表示是一個 RDB 文件,之后的 “0006” 表示這是第六版的 REDIS 文件,然后是兩個數據庫,之后就是 EOF 結束標識符,最后就是 check_sum。

AOF 持久化
什么是 AOF 持久化
AOF持久化方式記錄每次對服務器寫的操作,當服務器重啟的時候會重新執行這些命令來恢復原始的數據,AOF命令以redis協議追加保存每次寫的操作到文件末尾.Redis還能對AOF文件進行后台重寫,使得AOF文件的體積不至於過大.
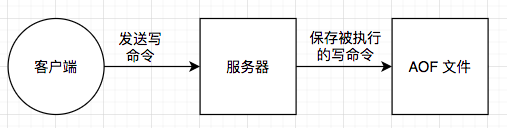
AOF 的優點?
- 使用AOF 會讓你的Redis更加耐久: 你可以使用不同的fsync策略:無fsync,每秒fsync,每次寫的時候fsync.使用默認的每秒fsync策略,Redis的性能依然很好(fsync是由后台線程進行處理的,主線程會盡力處理客戶端請求),一旦出現故障,你最多丟失1秒的數據.
- AOF文件是一個只進行追加的日志文件,所以不需要寫入seek,即使由於某些原因(磁盤空間已滿,寫的過程中宕機等等)未執行完整的寫入命令,你也也可使用redis-check-aof工具修復這些問題.
- Redis 可以在 AOF 文件體積變得過大時,自動地在后台對 AOF 進行重寫: 重寫后的新 AOF 文件包含了恢復當前數據集所需的最小命令集合。 整個重寫操作是絕對安全的,因為 Redis 在創建新 AOF 文件的過程中,會繼續將命令追加到現有的 AOF 文件里面,即使重寫過程中發生停機,現有的 AOF 文件也不會丟失。 而一旦新 AOF 文件創建完畢,Redis 就會從舊 AOF 文件切換到新 AOF 文件,並開始對新 AOF 文件進行追加操作。
- AOF 文件有序地保存了對數據庫執行的所有寫入操作, 這些寫入操作以 Redis 協議的格式保存, 因此 AOF 文件的內容非常容易被人讀懂, 對文件進行分析(parse)也很輕松。 導出(export) AOF 文件也非常簡單: 舉個例子, 如果你不小心執行了 FLUSHALL 命令, 但只要 AOF 文件未被重寫, 那么只要停止服務器, 移除 AOF 文件末尾的 FLUSHALL 命令, 並重啟 Redis , 就可以將數據集恢復到 FLUSHALL 執行之前的狀態。
AOF 的缺點?
- 對於相同的數據集來說,AOF 文件的體積通常要大於 RDB 文件的體積。
- 根據所使用的 fsync 策略,AOF 的速度可能會慢於 RDB 。 在一般情況下, 每秒 fsync 的性能依然非常高, 而關閉 fsync 可以讓 AOF 的速度和 RDB 一樣快, 即使在高負荷之下也是如此。 不過在處理巨大的寫入載入時,RDB 可以提供更有保證的最大延遲時間(latency)。
AOF持久化的實現
AOF持久化功能的實現可以分為命令追加(append)、文件寫入、文件同步(sync)三個步驟。
命令追加
當 AOF 持久化功能處於打開狀態時,服務器在執行完一個寫命令之后,會以協議格式將被執行的寫命令追加到服務器狀態的 aof_buf 緩沖區的末尾。
struct redisServer {
// ...
// AOF 緩沖區
sds aof_buf;
// ..
};
如果客戶端向服務器發送以下命令:
> set KEY VALUE
OK
那么服務器在執行這個 set 命令之后,會將以下協議內容追加到 aof_buf 緩沖區的末尾;
*3\r\n$3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVALUE\r\n
AOF 文件的寫入與同步
Redis的服務器進程就是一個事件循環(loop),這個循環中的文件事件負責接收客戶端
的命令請求,以及向客戶端發送命令回復,而時間事件則負責執行像 serverCron 函數這樣需
要定時運行的函數。
因為服務器在處理文件事件時可能會執行寫命令,使得一些內容被追加到aof_buf緩沖區
里面,所以在服務器每次結束一個事件循環之前,它都會調用 flushAppendOnlyFile 函數,考
慮是否需要將aof_buf緩沖區中的內容寫入和保存到AOF文件里面,這個過程可以用以下偽代
碼表示:
def eventLoop():
while True:
#處理文件事件,接收命令請求以及發送命令回復
#處理命令請求時可能會有新內容被追加到 aof_buf緩沖區中
processFileEvents()
#處理時間事件
processTimeEvents()
#考慮是否要將 aof_buf中的內容寫入和保存到 AOF文件里面
flushAppendOnlyFile()
flushAppendOnlyFile函數的行為由服務器配置的 appendfsync 選項的值來決定,各個不同
值產生的行為如下表所示。
| appendfsync 選項的值 | flushAppendOnlyFile 函數的行為 |
|---|---|
| always | 將 aof_buf 緩沖區中的所有內容寫入並同步到 AOF 文件 |
| everysec | 將 aof_buf 緩沖區中的所有內容寫入到 AOF 文件,如果上次同步 AOF 文件的時間距離現在超過一秒鍾,那么再次對 AOF 文件進行同步,並且這個同步操作是由一個線程專門負責執行的 |
| no | 將 aof_buf 緩沖區中的所有內容寫入到 AOF 文件,但並不對 AOF 文件進行同步,何時同步由操作系統來決定 |
如果用戶沒有主動為appendfsync選項設置值,那么appendfsync選項的默認值為everysec。
寫到這里有的小伙伴可能會對上面說的寫入和同步含義弄混,這里說一下:
寫入:將 aof_buf 中的數據寫入到 AOF 文件中。
同步:調用 fsync 以及 fdatasync 函數,將 AOF 文件中的數據保存到磁盤中。
通俗地講就是,你要往一個文件寫東西,寫的過程就是寫入,而同步則是將文件保存,數據落到磁盤上。
大家之前看文章的時候是不是大多都說 AOF 最多丟失一秒鍾的數據,那是因為 redis AOF 默認是 everysec 策略,這個策略每秒執行一次,所以 AOF 持久化最多丟失一秒鍾的數據。
AOF 文件的載入與數據還原
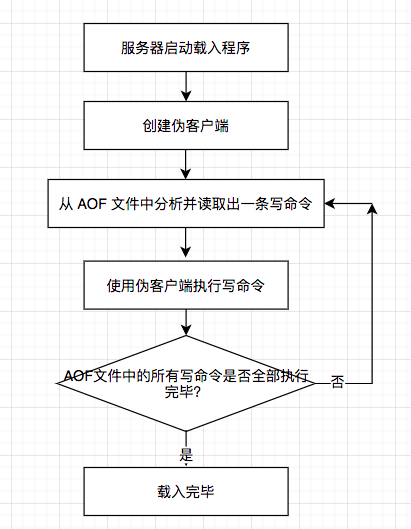
因為AOF文件里面包含了重建數據庫狀態所需的所有寫命令,所以服務器只要讀入並重新執行一遍AOF文件里面保存的寫命令,就可以還原服務器關閉之前的數據庫狀態。 Redis讀取AOF文件並還原數據庫狀態的詳細步驟如下:
- 創建一個不帶網絡連接的偽客戶端(fake client):因為Redis的命令只能在客戶端上 下文中執行,而載入AOF文件時所使用的命令直接來源於AOF文件而不是網絡連接,所以服 務器使用了一個沒有網絡連接的偽客戶端來執行AOF文件保存的寫命令,偽客戶端執行命令 的效果和帶網絡連接的客戶端執行命令的效果完全一樣。
- 從AOF文件中分析並讀取出一條寫命令。
- 使用偽客戶端執行被讀出的寫命令。
- 一直執行步驟2和步驟3,直到AOF文件中的所有寫命令都被處理完畢為止。
當完成以上步驟之后,AOF文件所保存的數據庫狀態就會被完整地還原出來,整個過程 如下圖所示。
AOF 重寫
因為AOF持久化是通過保存被執行的寫命令來記錄數據庫狀態的,所以隨着服務器運行 時間的流逝,AOF文件中的內容會越來越多,文件的體積也會越來越大,如果不加以控制的 話,體積過大的AOF文件很可能對Redis服務器、甚至整個宿主計算機造成影響,並且AOF文 件的體積越大,使用AOF文件來進行數據還原所需的時間就越多。
如 客戶端執行了以下命令是:
> rpush list "A" "B"
OK
> rpush list "C"
OK
> rpush list "D"
OK
> rpush list "E" "F"
OK
那么光是為了記錄這個list鍵的狀態,AOF文件就需要保存四條命令。
對於實際的應用程度來說,寫命令執行的次數和頻率會比上面的簡單示例要高得多,所 以造成的問題也會嚴重得多。 為了解決AOF文件體積膨脹的問題,Redis提供了AOF文件重寫(rewrite)功能。通過該 功能,Redis服務器可以創建一個新的AOF文件來替代現有的AOF文件,新舊兩個AOF文件所 保存的數據庫狀態相同,但新AOF文件不會包含任何浪費空間的冗余命令,所以新AOF文件 的體積通常會比舊AOF文件的體積要小得多。 在接下來的內容中,我們將介紹AOF文件重寫的實現原理,以及BGREWEITEAOF命令 的實現原理。
雖然Redis將生成新AOF文件替換舊AOF文件的功能命名為“AOF文件重寫”,但實際上, AOF文件重寫並不需要對現有的AOF文件進行任何讀取、分析或者寫入操作,這個功能是通 過讀取服務器當前的數據庫狀態來實現的。
就像上面的情況,服務器完全可以將這六條命令合並成一條。
> rpush list "A" "B" "C" "D" "E" "F"
除了上面列舉的列表鍵之外,其他所有類型的鍵都可以用同樣的方法去減少 AOF文件中的命令數量。首先從數據庫中讀取鍵現在的值,然后用一條命令去記錄鍵值對,代替之前記錄這個鍵值對的多條命令,這就是AOF重寫功能的實現原理。
在實際中,為了避免在執行命令時造成客戶端輸入緩沖區溢出,重寫程序在處理列表、 哈希表、集合、有序集合這四種可能會帶有多個元素的鍵時,會先檢查鍵所包含的元素數 量,如果元素的數量超過了redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD常量的值,那 么重寫程序將使用多條命令來記錄鍵的值,而不單單使用一條命令。 在目前版本中,REDIS_AOF_REWRITE_ITEMS_PER_CMD常量的值為64,這也就是 說,如果一個集合鍵包含了超過64個元素,那么重寫程序會用多條SADD命令來記錄這個集 合,並且每條命令設置的元素數量也為64個。
AOF 后台重寫
AOF 重寫會執行大量的寫操作,這樣會影響主線程,所以redis AOF 重寫放到了子進程去執行。這樣可以達到兩個目的:
- 子進程進行AOF重寫期間,服務器進程(父進程)可以繼續處理命令請求。
- 子進程帶有服務器進程的數據副本,使用子進程而不是線程,可以在避免使用鎖的情況 下,保證數據的安全性。
但是有一個問題,當子進程重寫數據時,主進程依然在處理新的數據,這也就會造成數據不一致情況。
為了解決這種數據不一致問題,Redis服務器設置了一個AOF重寫緩沖區,這個緩沖區在 服務器創建子進程之后開始使用,當Redis服務器執行完一個寫命令之后,它會同時將這個寫 命令發送給AOF緩沖區和AOF重寫緩沖區,如下圖:
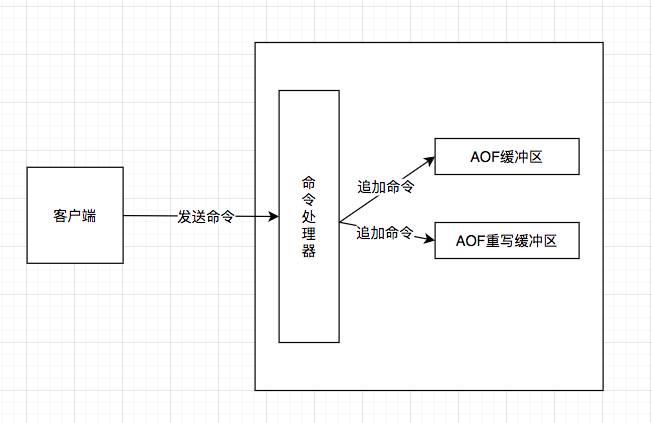
這也就是說,在子進程執行AOF重寫期間,服務器進程需要執行以下三個工作:
- 執行客戶端發來的命令。
- 將執行后的寫命令追加到AOF緩沖區。
- 將執行后的寫命令追加到AOF重寫緩沖區。
這樣一來可以保證:
- AOF緩沖區的內容會定期被寫入和同步到AOF文件,對現有AOF文件的處理工作會如常 進行。
- 從創建子進程開始,服務器執行的所有寫命令都會被記錄到AOF重寫緩沖區里面。
當子進程完成AOF重寫工作之后,它會向父進程發送一個信號,父進程在接到該信號之 后,會調用一個信號處理函數,並執行以下工作:
- 將AOF重寫緩沖區中的所有內容寫入到新AOF文件中,這時新AOF文件所保存的數 據庫狀態將和服務器當前的數據庫狀態一致。
- 對新的AOF文件進行改名,原子地(atomic)覆蓋現有的AOF文件,完成新舊兩個 AOF文件的替換。
這個信號處理函數執行完畢之后,父進程就可以繼續像往常一樣接受命令請求了。
在整個AOF后台重寫過程中,只有信號處理函數執行時會對服務器進程(父進程)造成 阻塞,在其他時候,AOF后台重寫都不會阻塞父進程,這將AOF重寫對服務器性能造成的影 響降到了最低。
Redis 混合持久化
Redis 還可以同時使用 AOF 持久化和 RDB 持久化。 在這種情況下, 當 Redis 重啟時, 它會優先使用 AOF 文件來還原數據集, 因為 AOF 文件保存的數據集通常比 RDB 文件所保存的數據集更完整。但是 AOF 恢復比較慢,Redis 4.0 推出了混合持久化。
混合持久化: 將 rdb 文件的內容和增量的 AOF 日志文件存在一起。這里的 AOF 日志不再是全量的日志,而是 自持久化開始到持久化結束 的這段時間發生的增量 AOF 日志,通常這部分 AOF 日志很小。
於是在 Redis 重啟的時候,可以先加載 RDB 的內容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重啟效率因此大幅得到提升。
覺得文章不錯的話,小伙伴們麻煩點個贊、關個注、轉個發一下唄~你的支持就是我寫文章的動力。
更多精彩的文章請關注公眾號“蘑菇睡不着”。
你越主動就會越主動,我們下期見~