原文鏈接:https://fuckcloudnative.io/posts/ipvs-how-kubernetes-services-direct-traffic-to-pods/
Kubernetes 中的 Service 就是一組同 label 類型 Pod 的服務抽象,為服務提供了負載均衡和反向代理能力,在集群中表示一個微服務的概念。kube-proxy 組件則是 Service 的具體實現,了解了 kube-proxy 的工作原理,才能洞悉服務之間的通信流程,再遇到網絡不通時也不會一臉懵逼。
kube-proxy 有三種模式:userspace、iptables 和 IPVS,其中 userspace 模式不太常用。iptables 模式最主要的問題是在服務多的時候產生太多的 iptables 規則,非增量式更新會引入一定的時延,大規模情況下有明顯的性能問題。為解決 iptables 模式的性能問題,v1.11 新增了 IPVS 模式(v1.8 開始支持測試版,並在 v1.11 GA),采用增量式更新,並可以保證 service 更新期間連接保持不斷開。
目前網絡上關於 kube-proxy 工作原理的文檔幾乎都是以 iptables 模式為例,很少提及 IPVS,本文就來破例解讀 kube-proxy IPVS 模式的工作原理。為了理解地更加徹底,本文不會使用 Docker 和 Kubernetes,而是使用更加底層的工具來演示。
我們都知道,Kubernetes 會為每個 Pod 創建一個單獨的網絡命名空間 (Network Namespace) ,本文將會通過手動創建網絡命名空間並啟動 HTTP 服務來模擬 Kubernetes 中的 Pod。
本文的目標是通過模擬以下的 Service 來探究 kube-proxy 的 IPVS 和 ipset 的工作原理:
apiVersion: v1
kind: Service
metadata:
name: app-service
spec:
clusterIP: 10.100.100.100
selector:
component: app
ports:
- protocol: TCP
port: 8080
targetPort: 8080
跟着我的步驟,最后你就可以通過命令 curl 10.100.100.100:8080 來訪問某個網絡命名空間的 HTTP 服務。為了更好地理解本文的內容,推薦提前閱讀以下的文章:
- How do Kubernetes and Docker create IP Addresses?!
- iptables: How Docker Publishes Ports
- iptables: How Kubernetes Services Direct Traffic to Pods
注意:本文所有步驟皆是在 Ubuntu 20.04 中測試的,其他 Linux 發行版請自行測試。
准備實驗環境
首先需要開啟 Linux 的路由轉發功能:
$ sysctl --write net.ipv4.ip_forward=1
接下來的命令主要做了這么幾件事:
- 創建一個虛擬網橋
bridge_home - 創建兩個網絡命名空間
netns_dustin和netns_leah - 為每個網絡命名空間配置 DNS
- 創建兩個 veth pair 並連接到
bridge_home - 給
netns_dustin網絡命名空間中的 veth 設備分配一個 IP 地址為10.0.0.11 - 給
netns_leah網絡命名空間中的 veth 設備分配一個 IP 地址為10.0.021 - 為每個網絡命名空間設定默認路由
- 添加 iptables 規則,允許流量進出
bridge_home接口 - 添加 iptables 規則,針對
10.0.0.0/24網段進行流量偽裝
$ ip link add dev bridge_home type bridge
$ ip address add 10.0.0.1/24 dev bridge_home
$ ip netns add netns_dustin
$ mkdir -p /etc/netns/netns_dustin
echo "nameserver 114.114.114.114" | tee -a /etc/netns/netns_dustin/resolv.conf
$ ip netns exec netns_dustin ip link set dev lo up
$ ip link add dev veth_dustin type veth peer name veth_ns_dustin
$ ip link set dev veth_dustin master bridge_home
$ ip link set dev veth_dustin up
$ ip link set dev veth_ns_dustin netns netns_dustin
$ ip netns exec netns_dustin ip link set dev veth_ns_dustin up
$ ip netns exec netns_dustin ip address add 10.0.0.11/24 dev veth_ns_dustin
$ ip netns add netns_leah
$ mkdir -p /etc/netns/netns_leah
echo "nameserver 114.114.114.114" | tee -a /etc/netns/netns_leah/resolv.conf
$ ip netns exec netns_leah ip link set dev lo up
$ ip link add dev veth_leah type veth peer name veth_ns_leah
$ ip link set dev veth_leah master bridge_home
$ ip link set dev veth_leah up
$ ip link set dev veth_ns_leah netns netns_leah
$ ip netns exec netns_leah ip link set dev veth_ns_leah up
$ ip netns exec netns_leah ip address add 10.0.0.21/24 dev veth_ns_leah
$ ip link set bridge_home up
$ ip netns exec netns_dustin ip route add default via 10.0.0.1
$ ip netns exec netns_leah ip route add default via 10.0.0.1
$ iptables --table filter --append FORWARD --in-interface bridge_home --jump ACCEPT
$ iptables --table filter --append FORWARD --out-interface bridge_home --jump ACCEPT
$ iptables --table nat --append POSTROUTING --source 10.0.0.0/24 --jump MASQUERADE
在網絡命名空間 netns_dustin 中啟動 HTTP 服務:
$ ip netns exec netns_dustin python3 -m http.server 8080
打開另一個終端窗口,在網絡命名空間 netns_leah 中啟動 HTTP 服務:
$ ip netns exec netns_leah python3 -m http.server 8080
測試各個網絡命名空間之間是否能正常通信:
$ curl 10.0.0.11:8080
$ curl 10.0.0.21:8080
$ ip netns exec netns_dustin curl 10.0.0.21:8080
$ ip netns exec netns_leah curl 10.0.0.11:8080
整個實驗環境的網絡拓撲結構如圖:

安裝必要工具
為了便於調試 IPVS 和 ipset,需要安裝兩個 CLI 工具:
$ apt install ipset ipvsadm --yes
本文使用的 ipset 和 ipvsadm 版本分別為
7.5-1~exp1和1:1.31-1。
通過 IPVS 來模擬 Service
下面我們使用 IPVS 創建一個虛擬服務 (Virtual Service) 來模擬 Kubernetes 中的 Service :
$ ipvsadm \
--add-service \
--tcp-service 10.100.100.100:8080 \
--scheduler rr
- 這里使用參數
--tcp-service來指定 TCP 協議,因為我們需要模擬的 Service 就是 TCP 協議。 - IPVS 相比 iptables 的優勢之一就是可以輕松選擇調度算法,這里選擇使用輪詢調度算法。
目前 kube-proxy 只允許為所有 Service 指定同一個調度算法,未來將會支持為每一個 Service 選擇不同的調度算法,詳情可參考文章 IPVS-Based In-Cluster Load Balancing Deep Dive。
創建了虛擬服務之后,還得給它指定一個后端的 Real Server,也就是后端的真實服務,即網絡命名空間 netns_dustin 中的 HTTP 服務:
$ ipvsadm \
--add-server \
--tcp-service 10.100.100.100:8080 \
--real-server 10.0.0.11:8080 \
--masquerading
該命令會將訪問 10.100.100.100:8080 的 TCP 請求轉發到 10.0.0.11:8080。這里的 --masquerading 參數和 iptables 中的 MASQUERADE 類似,如果不指定,IPVS 就會嘗試使用路由表來轉發流量,這樣肯定是無法正常工作的。
譯者注:由於 IPVS 未實現
POST_ROUTINGHook 點,所以它需要 iptables 配合完成 IP 偽裝等功能。
測試是否正常工作:
$ curl 10.100.100.100:8080
實驗成功,請求被成功轉發到了后端的 HTTP 服務!
在網絡命名空間中訪問虛擬服務
上面只是在 Host 的網絡命名空間中進行測試,現在我們進入網絡命名空間 netns_leah 中進行測試:
$ ip netns exec netns_leah curl 10.100.100.100:8080
哦豁,訪問失敗!
要想順利通過測試,只需將 10.100.100.100 這個 IP 分配給一個虛擬網絡接口。至於為什么要這么做,目前我還不清楚,我猜測可能是因為網橋 bridge_home 不會調用 IPVS,而將虛擬服務的 IP 地址分配給一個網絡接口則可以繞過這個問題。
譯者注
Netfilter 是一個基於用戶自定義的 Hook 實現多種網絡操作的 Linux 內核框架。Netfilter 支持多種網絡操作,比如包過濾、網絡地址轉換、端口轉換等,以此實現包轉發或禁止包轉發至敏感網絡。
針對 Linux 內核 2.6 及以上版本,Netfilter 框架實現了 5 個攔截和處理數據的系統調用接口,它允許內核模塊注冊內核網絡協議棧的回調功能,這些功能調用的具體規則通常由 Netfilter 插件定義,常用的插件包括 iptables、IPVS 等,不同插件實現的 Hook 點(攔截點)可能不同。另外,不同插件注冊進內核時需要設置不同的優先級,例如默認配置下,當某個 Hook 點同時存在 iptables 和 IPVS 規則時,iptables 會被優先處理。
Netfilter 提供了 5 個 Hook 點,系統內核協議棧在處理數據包時,每到達一個 Hook 點,都會調用內核模塊中定義的處理函數。調用哪個處理函數取決於數據包的轉發方向,進站流量和出站流量觸發的 Hook 點是不一樣的。
內核協議棧中預定義的回調函數有如下五個:
- NF_IP_PRE_ROUTING: 接收的數據包進入協議棧后立即觸發此回調函數,該動作發生在對數據包進行路由判斷(將包發往哪里)之前。
- NF_IP_LOCAL_IN: 接收的數據包經過路由判斷后,如果目標地址在本機上,則將觸發此回調函數。
- NF_IP_FORWARD: 接收的數據包經過路由判斷后,如果目標地址在其他機器上,則將觸發此回調函數。
- NF_IP_LOCAL_OUT: 本機產生的准備發送的數據包,在進入協議棧后立即觸發此回調函數。
- NF_IP_POST_ROUTING: 本機產生的准備發送的數據包或者經由本機轉發的數據包,在經過路由判斷之后,將觸發此回調函數。
iptables 實現了所有的 Hook 點,而 IPVS 只實現了 LOCAL_IN、LOCAL_OUT、FORWARD 這三個 Hook 點。既然沒有實現 PRE_ROUTING,就不會在進入 LOCAL_IN 之前進行地址轉換,那么數據包經過路由判斷后,會進入 LOCAL_IN Hook 點,IPVS 回調函數如果發現目標 IP 地址不屬於該節點,就會將數據包丟棄。
如果將目標 IP 分配給了虛擬網絡接口,內核在處理數據包時,會發現該目標 IP 地址屬於該節點,於是可以繼續處理數據包。
dummy 接口
當然,我們不需要將 IP 地址分配給任何已經被使用的網絡接口,我們的目標是模擬 Kubernetes 的行為。Kubernetes 在這里創建了一個 dummy 接口,它和 loopback 接口類似,但是你可以創建任意多的 dummy 接口。它提供路由數據包的功能,但實際上又不進行轉發。dummy 接口主要有兩個用途:
- 用於主機內的程序通信
- 由於 dummy 接口總是 up(除非顯式將管理狀態設置為 down),在擁有多個物理接口的網絡上,可以將 service 地址設置為 loopback 接口或 dummy 接口的地址,這樣 service 地址不會因為物理接口的狀態而受影響。
看來 dummy 接口完美符合實驗需求,那就創建一個 dummy 接口吧:
$ ip link add dev dustin-ipvs0 type dummy
將虛擬 IP 分配給 dummy 接口 dustin-ipvs0 :
$ ip addr add 10.100.100.100/32 dev dustin-ipvs0
到了這一步,仍然訪問不了 HTTP 服務,還需要另外一個黑科技:bridge-nf-call-iptables。在解釋 bridge-nf-call-iptables 之前,我們先來回顧下容器網絡通信的基礎知識。
基於網橋的容器網絡
Kubernetes 集群網絡有很多種實現,有很大一部分都用到了 Linux 網橋:

- 每個 Pod 的網卡都是 veth 設備,veth pair 的另一端連上宿主機上的網橋。
- 由於網橋是虛擬的二層設備,同節點的 Pod 之間通信直接走二層轉發,跨節點通信才會經過宿主機 eth0。
Service 同節點通信問題
不管是 iptables 還是 ipvs 轉發模式,Kubernetes 中訪問 Service 都會進行 DNAT,將原本訪問 ClusterIP:Port 的數據包 DNAT 成 Service 的某個 Endpoint (PodIP:Port),然后內核將連接信息插入 conntrack 表以記錄連接,目的端回包的時候內核從 conntrack 表匹配連接並反向 NAT,這樣原路返回形成一個完整的連接鏈路:
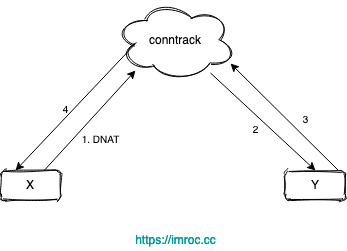
但是 Linux 網橋是一個虛擬的二層轉發設備,而 iptables conntrack 是在三層上,所以如果直接訪問同一網橋內的地址,就會直接走二層轉發,不經過 conntrack:
-
Pod 訪問 Service,目的 IP 是 Cluster IP,不是網橋內的地址,走三層轉發,會被 DNAT 成 PodIP:Port。
-
如果 DNAT 后是轉發到了同節點上的 Pod,目的 Pod 回包時發現目的 IP 在同一網橋上,就直接走二層轉發了,沒有調用 conntrack,導致回包時沒有原路返回 (見下圖)。
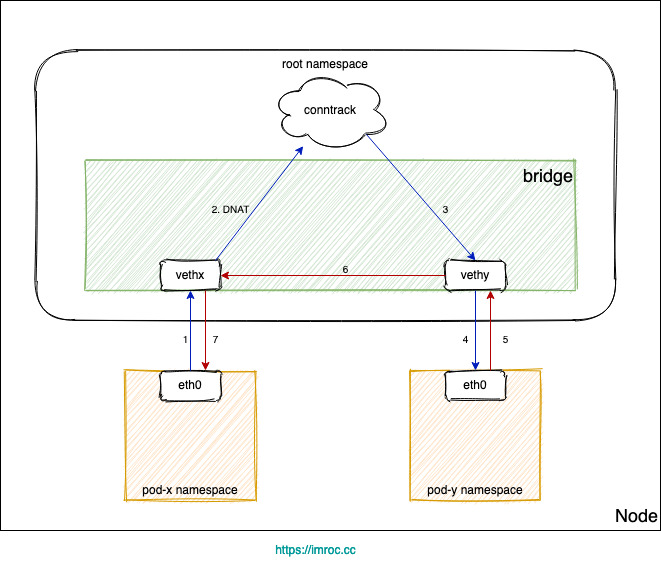
由於沒有原路返回,客戶端與服務端的通信就不在一個 “頻道” 上,不認為處在同一個連接,也就無法正常通信。
開啟 bridge-nf-call-iptables
啟用 bridge-nf-call-iptables 這個內核參數 (置為 1),表示 bridge 設備在二層轉發時也去調用 iptables 配置的三層規則 (包含 conntrack),所以開啟這個參數就能夠解決上述 Service 同節點通信問題。
所以這里需要啟用 bridge-nf-call-iptables :
$ modprobe br_netfilter
$ sysctl --write net.bridge.bridge-nf-call-iptables=1
現在再來測試一下連通性:
$ ip netns exec netns_leah curl 10.100.100.100:8080
終於成功了!
開啟 Hairpin(發夾彎)模式
雖然我們可以從網絡命名空間 netns_leah 中通過虛擬服務成功訪問另一個網絡命名空間 netns_dustin 中的 HTTP 服務,但還沒有測試過從 HTTP 服務所在的網絡命名空間 netns_dustin 中直接通過虛擬服務訪問自己,話不多說,直接測一把:
$ ip netns exec netns_dustin curl 10.100.100.100:8080
啊哈?竟然失敗了,這又是哪里的問題呢?不要慌,開啟 hairpin 模式就好了。那么什么是 hairpin 模式呢? 這是一個網絡虛擬化技術中常提到的概念,也即交換機端口的VEPA模式。這種技術借助物理交換機解決了虛擬機間流量轉發問題。很顯然,這種情況下,源和目標都在一個方向,所以就是從哪里進從哪里出的模式。
怎么配置呢?非常簡單,只需一條命令:
$ brctl hairpin bridge_home veth_dustin on
再次進行測試:
$ ip netns exec netns_dustin curl 10.100.100.100:8080
還是失敗了。。。
然后我花了一個下午的時間,終於搞清楚了啟用混雜模式后為什么還是不能解決這個問題,因為混雜模式和下面的選項要一起啟用才能對 IPVS 生效:
$ sysctl --write net.ipv4.vs.conntrack=1
最后再測試一次:
$ ip netns exec netns_dustin curl 10.100.100.100:8080
這次終於成功了,但我還是不太明白為什么啟用 conntrack 能解決這個問題,有知道的大神歡迎留言告訴我!
譯者注:IPVS 及其負載均衡算法只針對首個數據包,后繼的包必須被
conntrack表優先反轉,如果沒有conntrack,IPVS 對於回來的包是沒有任何辦法的。可以通過conntrack -L查看。
開啟混雜模式
如果想讓所有的網絡命名空間都能通過虛擬服務訪問自己,就需要在連接到網橋的所有 veth 接口上開啟 hairpin 模式,這也太麻煩了吧。有一個辦法可以不用配置每個 veth 接口,那就是開啟網橋的混雜模式。
什么是混雜模式呢?普通模式下網卡只接收發給本機的包(包括廣播包)傳遞給上層程序,其它的包一律丟棄。混雜模式就是接收所有經過網卡的數據包,包括不是發給本機的包,即不驗證MAC地址。
如果一個網橋開啟了混雜模式,就等同於將所有連接到網橋上的端口(本文指的是 veth 接口)都啟用了 hairpin 模式。可以通過以下命令來啟用 bridge_home 的混雜模式:
$ ip link set bridge_home promisc on
現在即使你把 veth 接口的 hairpin 模式關閉:
$ brctl hairpin bridge_home veth_dustin off
仍然可以通過連通性測試:
$ ip netns exec netns_dustin curl 10.100.100.100:8080
優化 MASQUERADE
在文章開頭准備實驗環境的章節,執行了這么一條命令:
$ iptables \
--table nat \
--append POSTROUTING \
--source 10.0.0.0/24 \
--jump MASQUERADE
這條 iptables 規則會對所有來自 10.0.0.0/24 的流量進行偽裝。然而 Kubernetes 並不是這么做的,它為了提高性能,只對來自某些具體的 IP 的流量進行偽裝。
為了更加完美地模擬 Kubernetes,我們繼續改造規則,先把之前的規則刪除:
$ iptables \
--table nat \
--delete POSTROUTING \
--source 10.0.0.0/24 \
--jump MASQUERADE
然后添加針對具體 IP 的規則:
$ iptables \
--table nat \
--append POSTROUTING \
--source 10.0.0.11/32 \
--jump MASQUERADE
果然,上面的所有測試都能通過。先別急着高興,又有新問題了,現在只有兩個網絡命名空間,如果有很多個怎么辦,每個網絡命名空間都創建這樣一條 iptables 規則?我用 IPVS 是為了啥?就是為了防止有大量的 iptables 規則拖垮性能啊,現在豈不是又繞回去了。
不慌,繼續從 Kubernetes 身上學習,使用 ipset 來解決這個問題。先把之前的 iptables 規則刪除:
$ iptables \
--table nat \
--delete POSTROUTING \
--source 10.0.0.11/32 \
--jump MASQUERADE
然后使用 ipset 創建一個集合 (set) :
$ ipset create DUSTIN-LOOP-BACK hash:ip,port,ip
這條命令創建了一個名為 DUSTIN-LOOP-BACK 的集合,它是一個 hashmap,里面存儲了目標 IP、目標端口和源 IP。
接着向集合中添加條目:
$ ipset add DUSTIN-LOOP-BACK 10.0.0.11,tcp:8080,10.0.0.11
現在不管有多少網絡命名空間,都只需要添加一條 iptables 規則:
$ iptables \
--table nat \
--append POSTROUTING \
--match set \
--match-set DUSTIN-LOOP-BACK dst,dst,src \
--jump MASQUERADE
網絡連通性測試也沒有問題:
$ curl 10.100.100.100:8080
$ ip netns exec netns_leah curl 10.100.100.100:8080
$ ip netns exec netns_dustin curl 10.100.100.100:8080
新增虛擬服務的后端
最后,我們把網絡命名空間 netns_leah 中的 HTTP 服務也添加到虛擬服務的后端:
$ ipvsadm \
--add-server \
--tcp-service 10.100.100.100:8080 \
--real-server 10.0.0.21:8080 \
--masquerading
再向 ipset 的集合 DUSTIN-LOOP-BACK 中添加一個條目:
$ ipset add DUSTIN-LOOP-BACK 10.0.0.21,tcp:8080,10.0.0.21
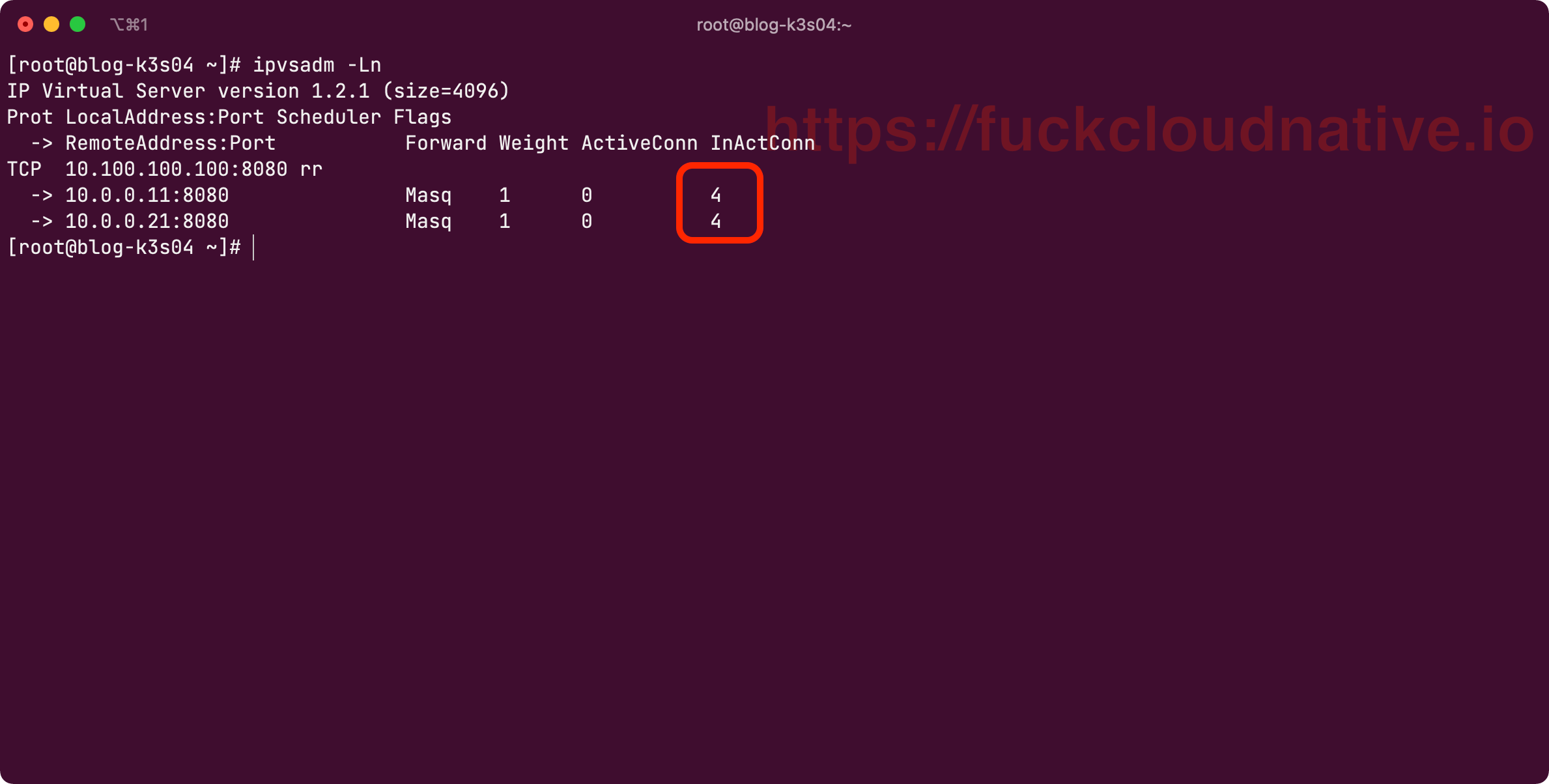
終極測試來了,試着多運行幾次以下的測試命令:
$ curl 10.100.100.100:8080
你會發現輪詢算法起作用了:
總結
相信通過本文的實驗和講解,大家應該理解了 kube-proxy IPVS 模式的工作原理。在實驗過程中,我們還用到了 ipset,它有助於解決在大規模集群中出現的 kube-proxy 性能問題。如果你對這篇文章有任何疑問,歡迎和我進行交流。