什么是維度
維度是維度建模的基礎和靈魂。在維度建模中,將度量稱為“事實” ,將環境描述為“維度”,維度是用於分析事實所需要的多樣環境。
例如,在分析交易過程時,可以通過買家、賣家、商品和時間等維度描述交易發生的環境。
什么是維度屬性
維度所包含的表示維度的列,稱為維度屬性。維度屬性是查詢約束條件、分組和報表標簽生成的基本來源,是數據易用性的關鍵。
例如,在查詢請求中,獲取某類目的商品、正常狀態的商品等,是通過約束商品類目屬性和商品狀態屬性來實現的;統計淘寶不同商品類目的每日成交金額,是通過商品維度的類目屬性進行分組的;我們在報表中看到的類目、BC 類型( B 指天貓, C 指集市)等,都是維度屬性。
維度屬性的作用一般是查詢約束、分類匯總以及排序等。
維度的基本設計方法
維度的設計過程就是確定維度屬性的過程,如何生成維度屬性,以及所生成的維度屬性的優劣,決定了維度使用的方便性,成為數據倉庫
易用性的關鍵。
以淘寶的商品維度為例對維度設計方法進行詳細說明
第一步:選擇維度或新建維度
作為維度建模的核心,在企業級數據倉庫中必須保證維度的唯一性。
以淘寶商品維度為例,有且只允許有一個維度定義。
第二步:確定主維表
此處的主維表一般是 ODS 表,直接與業務系統同步。
以淘寶商品維度為例, s_a uction_ auctions 是與前台商品中心系統同步的商品表,此表即是主維表。
第三步:確定相關維表
數據倉庫是業務源系統的數據整合,不同業務系統或者同一業務系統中的表之間存在關聯性。根據對業務的梳理,確定哪些表和主維表存在關聯關系,並選擇其中的某些表用於生成維度屬性。
以淘寶商品維度為例,根據對業務邏輯的梳理,可以得到商品與類目、SPU 、賣家、店鋪等維度存在關聯關系。
第四步:確定維度屬性
確定維度屬性主要包括兩個階段:
-
第一個階段:是從主維表中選擇維度屬性或生成新的維度屬性
-
第二個階段是從相關維表中選擇維度屬性或生成新的維度屬性
以淘寶商品維度為例,從主維表( s_auction_auctions )和類目、SPU 、賣家、店鋪等相關維表中選擇維度屬性或生成新的維度屬性。
確定維度屬性的幾點提示:
-
盡可能生成豐富的維度屬性
比如淘寶商品維度有近百個維度屬性,為下游的數據統計、分析、探查提供了良好的基礎。
-
盡可能多地給出包括一些富有意義的文字性描述
屬性不應該是編碼,而應該是真正的文字。
在淘寶維度建模中,一般是編碼和文字同時存在,比如商品維度中的商品ID 和商品標題、類目ID 和類目名稱等。ID 一般用於不同表之間的關聯,而名稱一般用於報表標簽。
-
區分數值型屬性和事實
數值型宇段是作為事實還是維度屬性,可以參考字段的一般用途。如果通常用於查詢約束條件或分組統計,則是作為維度屬性;如果通常用於參與度量的計算, 則是作為事實。
比如商品價格,可以用於查詢約束條件或統計價格區間的商品數量,此時是作為維度屬性使用的;也可以用於統計某類目下商品的平均價格,此時是作為事實使用的。
另外,如果數值型字段是離散值,則作為維度屬性存在的可能性較大;如果數值型宇段是連續值,則作為度量存在的可能性較大,但並不絕對,需要同時參考宇段的具體用途。
-
盡量沉淀出通用的維度屬性
有些維度屬性獲取需要進行比較復雜的邏輯處理,有些需要通過多表關聯得到,或者通過單表的不同字段混合處理得到,或者通過對單表的某個字段進行解析得到。
此時,需要將盡可能多的通用的維度屬性進行沉淀。一方面,可以提高下游使用的方便性,減少復雜度;另一方面,可以避免下游使用解析時由於各自邏輯不同而導致口徑不一致。
例如,淘寶商品的 property 字段,使用 key:value 方式存儲多個商品屬性。商品品牌就存存儲在此字段中,而商品品牌是重要的分組統計和查詢約束的條件,所以需要將品牌解析出來,作為品牌屬性存在。例如,商品是否在線,即在淘寶網站是否可以查看到此商品,是重要的查詢約束的條件,但是無法直接獲取,需要進行加工,加工邏輯是:商品狀態為 0 和 l 且商品上架時間小於或等於當前時間,則是在線商品g 否則是非在線商品。
所以需要封裝商品是否在線的邏輯作為一個單獨的屬性字段
維度的層次結構
維度中的一些描述屬性以層次方式或一對多的方式相互關聯,可以被理解為包含連續主從關系的屬性層次。
層次的最底層代表維度中描述最低級別的詳細信息,最高層代表最高級別的概要信息。維度常常有多個這樣的嵌入式層次結構。
比如淘寶商品維度,有賣家、類目、品牌等。商品屬於類目,類目屬於行業,其中類目的最低級別是葉子類目,葉子類目屬於二級類目,二級類目屬於一級類目。
在屬性的層次結構中進行鑽取是數據鑽取的方法之一,下面通過具體的例子,看看如何在層次結構中進行鑽取。
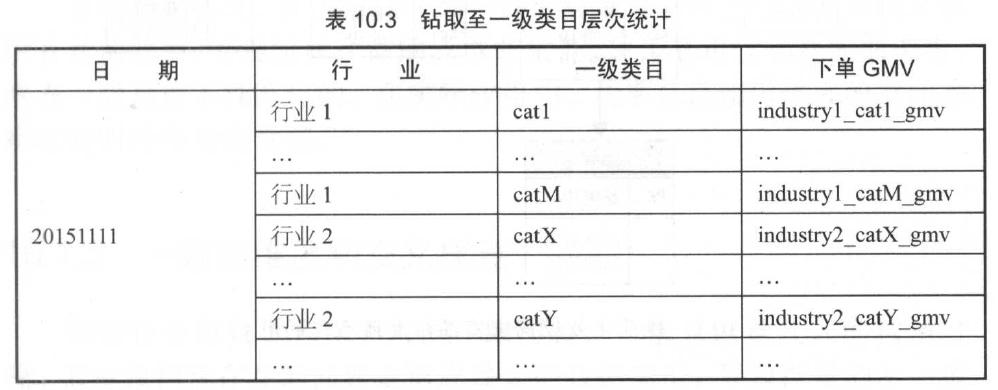
假設己有一個淘寶交易訂單,創建事實表。現在統計2015 年“雙 11 ”的下單 GMV , 得到一行記錄;沿着層次向下鑽取,添加行業,得
到行業實例個數的記錄數;繼續沿着層次向下鑽取,添加一級類目,得到一級類目實例個數的記錄數。可以看到,通過向報表中添加連續的維度細節級別,實現在層次結構中進行鑽取。
-
最高層次的統計

-
鑽取至行業層次

-
鑽取至一級類目層次
雪花模型(規范化)
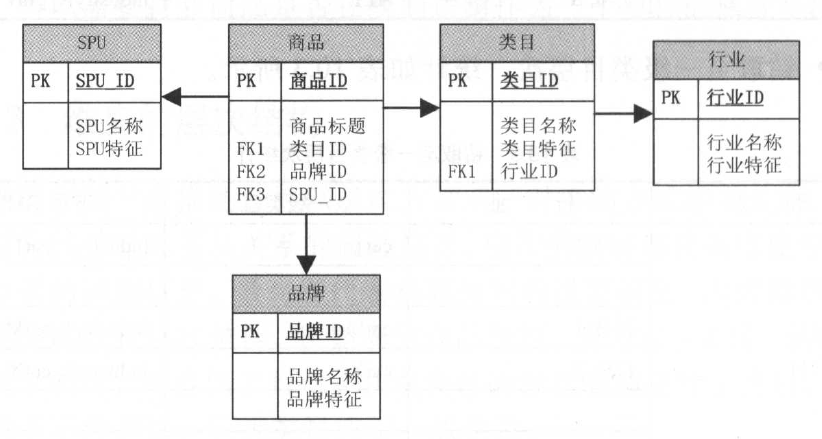
當屬性層次被實例化為一系列維度,而不是單一的維度時,被稱為雪花模式。
大多數聯機事務處理系統( OLTP )的底層數據結構在設計時采用此種規范化技術,通過規范化處理將重復屬性移至其自身所屬的
表中,刪除冗余數據。這種方法用在 OLTP 系統中可以有效避免數據冗余導致的不一致性。
比如在 OLTP 系統中,存在商品表和類目表,且商品表中有冗余的類目表的屬性字段,假設對某類目進行更新,則必須更新商品表和類目
表,且由於商品和類目是一對多的關系,商品表可能每次需要更新幾十萬甚至上百萬條記錄,這是不合理的。而對於聯機分析處理系統( OLAP)來說,數據是穩定的,不存在OLTP 系統中所存在的問題。
對於淘系商品維度,如果采用雪花模式進行規范化處理,將表現為如下形式:
星型模型(反規范化)
將維度的屬性層次合並到單個維度中的操作稱為反規范化。
分析系統的主要目的是用於數據分析和統計,如何更方便用戶進行統計分析決定了分析系統的優劣。采用雪花模式,用戶在統計分析的過程中需要大量的關聯操作,使用復雜度高,同時查詢性能很差;而采用反規范化處理,則方便、易用且性能好。
對於淘寶商品維度,如果采用反規范化處理,將表現為如下形式:

從用戶角度來看簡化了模型,並且使數據庫查詢優化器的連接路徑比完全規范化的模型簡化許多。反規范化的維度仍包含與規
范化模型同樣的信息和關系,從分析角度來看,沒有丟失任何信息,但復雜性降低了。
采用雪花模式,除了可以節約一部分存儲外,對於OLAP 系統來說沒有其他效用。而現階段存儲的成本非常低。出於易用性和性能的考慮,維表一般是很不規范化的。在實際應用中,幾乎總是使用維表的空間來換取簡明性和查詢性能。