引言
提起成熟的消息隊列或消息引擎,毋庸置疑,大多數人的第一反應一定是 Kafka。
Kafka 能夠徹底滿足海量數據場景下高吞吐、高並發需求,在短短幾年內,已經被阿里、騰訊、百度、字節跳動、Netflix、Twitter 等超一線大廠視為技術核心——可以說,Kafka 是目前大數據 Spark 實時流處理的標配。
Kafka 的優勢
Kafka 具有高吞吐量、低延遲、容錯、持久性、可伸縮性,尤其是廣為人知的高吞吐量,Kafka 每秒大約可以生產約 25 萬消息(50 MB),每秒處理 55 萬消息(110 MB)!Kafka 還有一個巨大的優勢就是容錯,它具備一個固有功能,可以自行應對集群中的節點故障。
Kafka 的不足
在運維和實踐過程中,Kafka 卻也始終存在着一些棘手的問題。例如:
-
擴展性較差,剝離 Broker 意味着必須復制 topic 分區和副本,效率很低;
-
缺乏一致性,一旦 API 發生變化很有可能出現問題;
-
存儲成本非常高,幾乎沒有人用Kafka長時間存儲數據;
-
沒有與租戶完全隔離的本地多租戶,需要自行配置解決方案
Pulsar 背景介紹
俯瞰技術生態,有沒有一個平台,能夠既擁有 Kafka 的優勢,又規避它的缺陷,同時還融合了 MQ 的一系列特性呢?
有,那就是 Pulsar。
Apache Pulsar 是 Apache 軟件基金會頂級項目,是下一代雲原生分布式消息流平台,集消息、存儲、輕量化函數式計算為一體。該系統源於 Yahoo,最初在 Yahoo 內部開發和部署,支持 Yahoo 應用服務平台 140 萬個主題,日處理超過 1000 億條消息。
Pulsar 於 2016 年由 Yahoo 開源並捐贈給 Apache 軟件基金會進行孵化,2018 年成為 Apache 軟件基金會頂級項目。
Pulsar 作為下一代雲原生分布式消息流平台,支持多租戶、持久化存儲、多機房跨區域數據復制,具有強一致性、高吞吐以及低延時的高可擴展流數據存儲特性,內置諸多其他系統商業版本才有的特性,是雲原生時代解決實時消息流數據傳輸、存儲和計算的最佳解決方案。
目前,Apache Pulsar 已經應用部署在國內外眾多大型互聯網公司和傳統行業公司,案例分布在人工智能、金融、電信運營商、直播與短視頻、物聯網、零售與電子商務、在線教育等多個行業,如美國有線電視網絡巨頭 Comcast、Yahoo!、騰訊、中國電信、中國移動、BIGO、VIPKID 等。
目前 Apache Pulsar 項目原生核心貢獻者已組成創業公司 StreamNative,進一步為 Apache Pulsar 提供更好的企業級服務支持與生態建設。
Plusar 是什么
"Pulsar is a distributed pub-sub messaging platform with a very flexible messaging model and an intuitive client API."
Pulsar 是 pub-sub(發布者/訂閱者)模式的分布式消息平台,擁有靈活的消息模型和直觀的客戶端 API。
核心概念
Topic(主題)
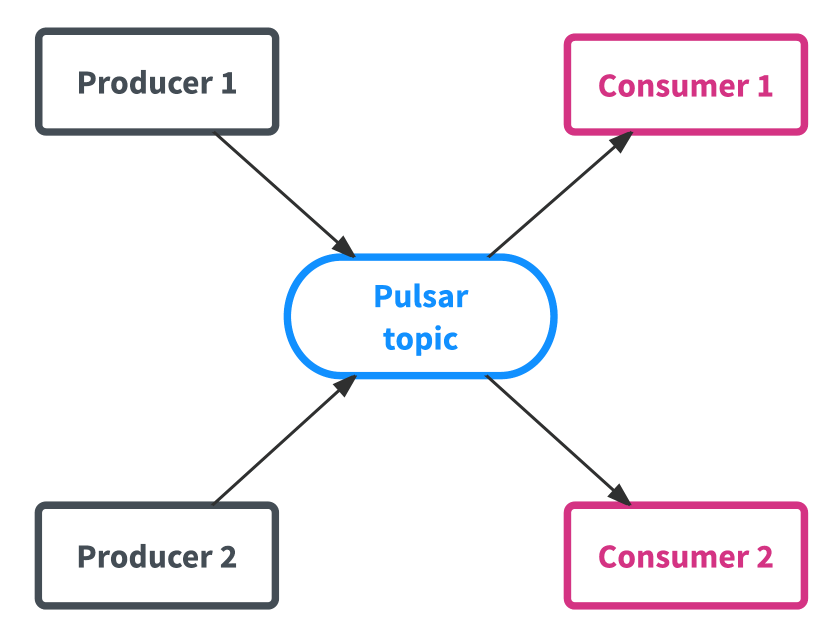
Topic 是Pulsar的核心概念,表示一個“channel”,Producer 可以寫入數據,Consumer 從中消費數據(與 Kafka 類似)。
Topic 名稱的 URL 類似如下的結構:
{persistent|non-persistent}://tenant/namespace/topic
- persistent|non-persistent:表示數據是否持久化(Pulsar支持消息持久化和非持久化兩種模式)
- Tenant:表示為租戶
- Namespace:一般聚合一系列相關的Topic,一個租戶下可以有多個Namespace
Tenant(租戶)和Namespace(名稱空間)關系
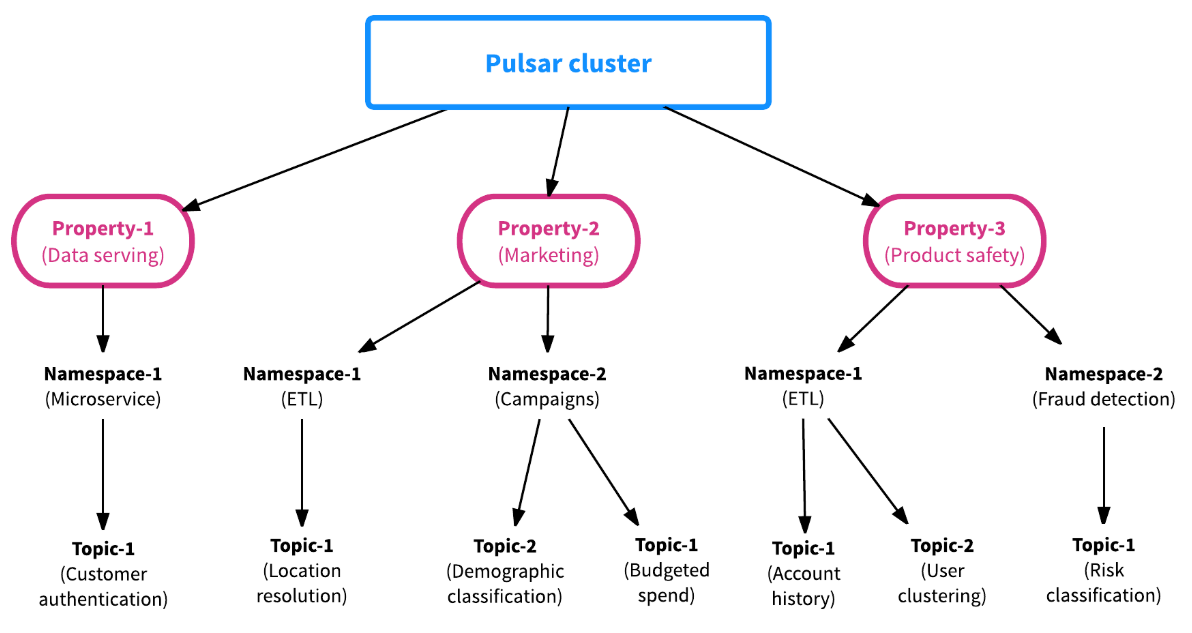
上圖中 Property 即為租戶,每個租戶下可以有多個 Namespace,每個 Namespace 下有多個 Topic。
Namespace 是 Pulsar 中的操作單元,包括Topic是配置在Namespace級別的,包括多地域復制,消息過期策略等都是配置在Namespace上的。
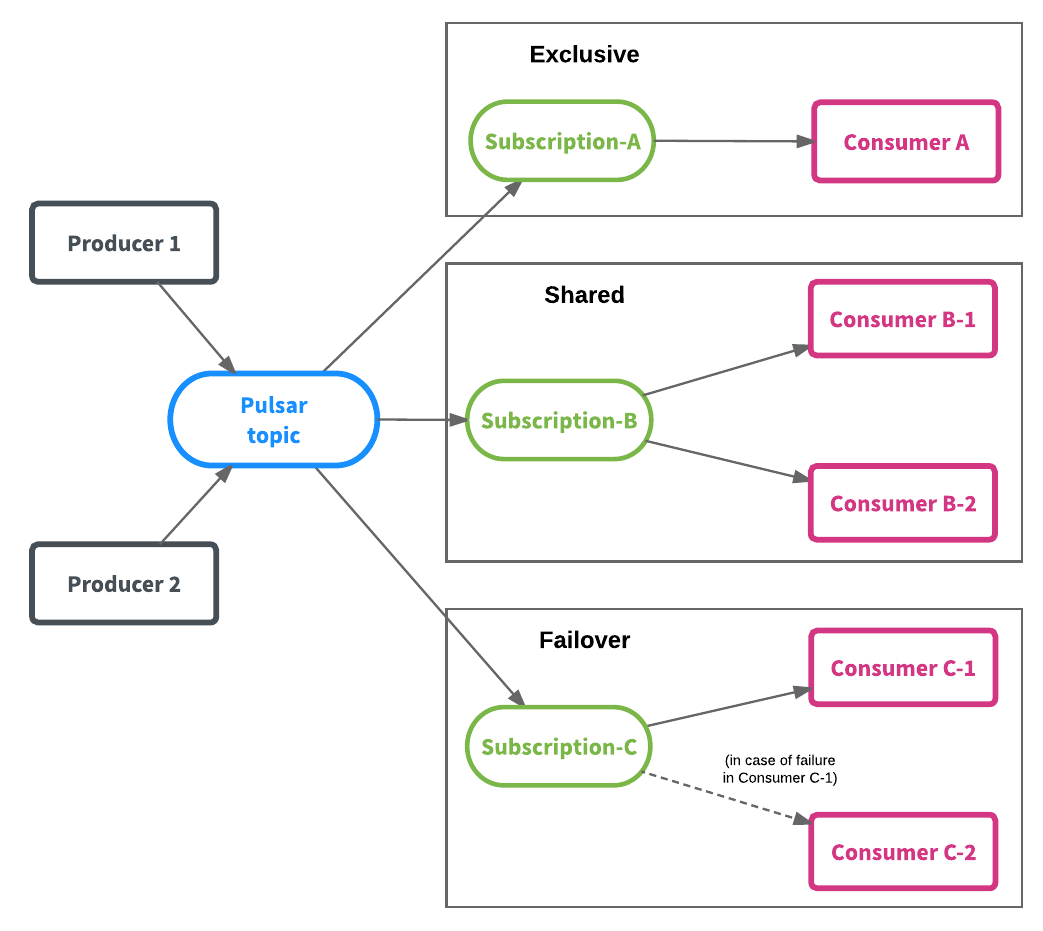
訂閱模型
Pulsar 提供了靈活的消息模型,支持三種訂閱類型:
-
Exclusive subscription:排他的,只能有一個Consumer,接收一個Topic所有的消息
-
Shared subscription:共享的,可以同時存在多個Consumer,每個Consumer處理Topic中一部消息(Shared模型是不保證消息順序的,Consumer數量可以超過分區的數量)
-
Failover subscription:Failover模式,同一時刻只有一個有效的Consumer,其余的Consumer作為備用節點,在Master Consumer不可用后進行替代(看起來適用於數據量小,且解決單點故障的場景)
分區(Partition)
為了解決吞吐等問題,Pulsar和Kafka一樣,采用了分區(Partition)的機制。
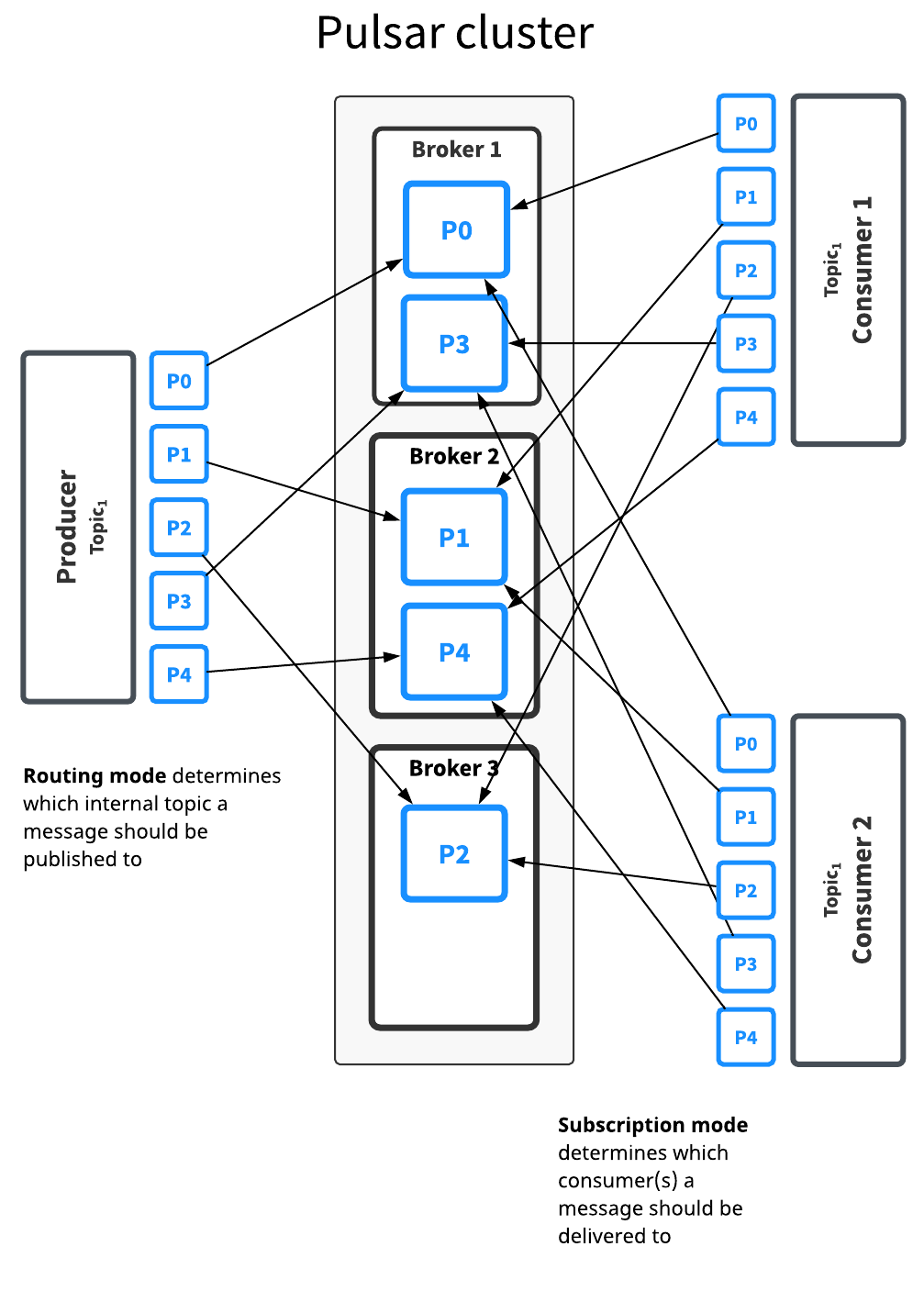
Pulsar提供了一些策略來處理消息到Partition的路由(MessageRouter):
- Single partitioning:Producer隨機選擇一個Partition並將所有消息寫入到這個分區
- Round robin partitioning :采用Round robin的方式,輪訓所有分區進行消息寫入
- Hash partitioning:這種模式每條消息有一個Key,Producer根據消息的Key的哈希值進行分區的選擇(Key相同的消息可以保證順序)。
- Custom partitioning:用戶自定義路由策略
不同於別的MQ系統,Pulsar允許Consumer的數量超過分區的數量(對於RocketMQ,超過分區數的Consumer會分配不到分區而“空跑”)。
在Shared subscription的訂閱模式下,Consumer數量可以大於分區的數量,每個Consumer處理每個Partition中的一部分消息,不保證消息的順序。
持久化
Pulsar通過 BookKeeper 來存儲消息,保證消息不會丟失(BookKeeper:A scalable, fault-tolerant, and low-latency storage service optimized for real-time workloads)。
架構
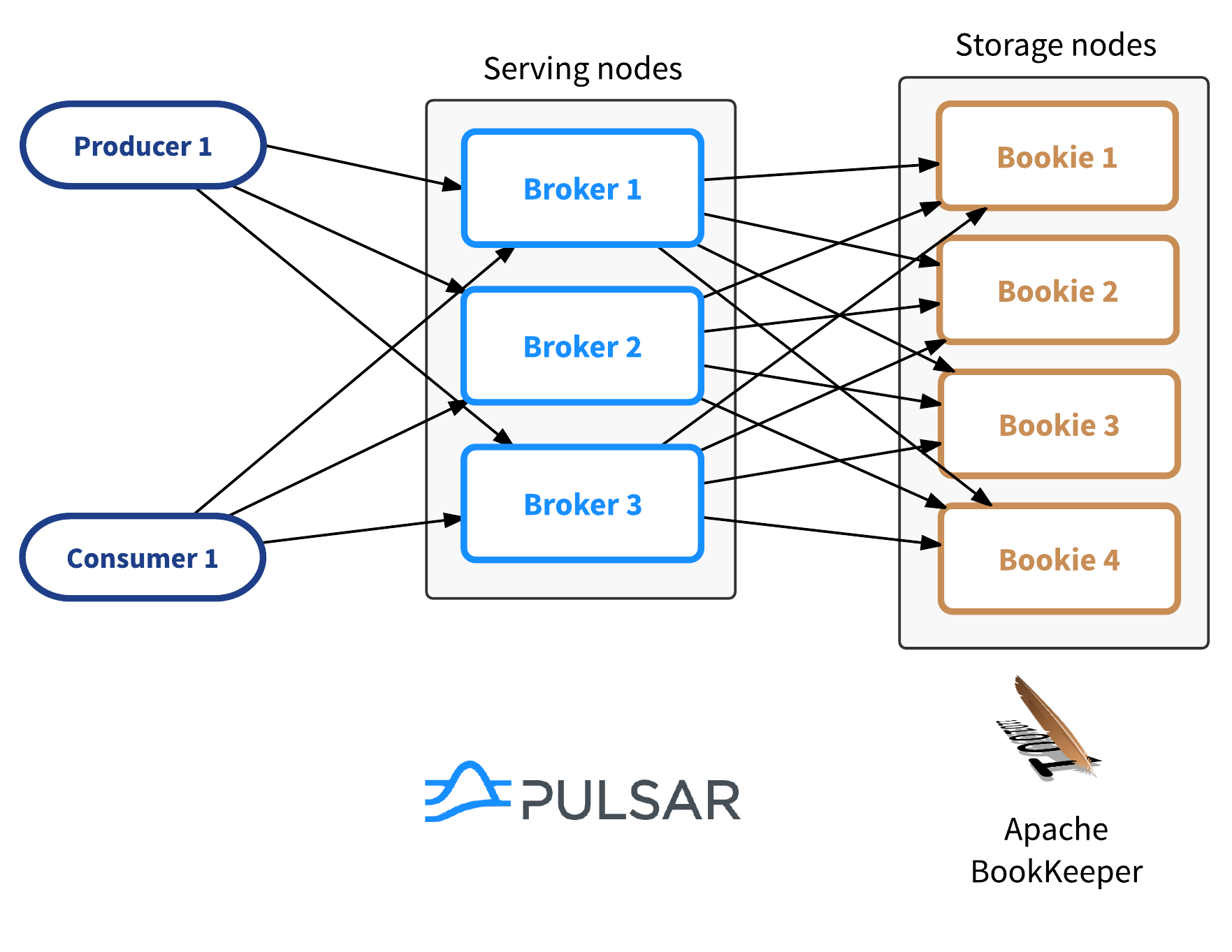
Pulsar采用“存儲和服務分離”的兩層架構(這是Pulsar區別於其他MQ系統最重要的一點,也是所謂的“下一代消息系統”的核心):
-
Broker:提供發布和訂閱的服務(Pulsar的組件)
-
Bookie:提供存儲能力(BookKeeper的存儲組件)
優勢是Broker成為了stateless的組件,可以水平擴容(RocketMQ的Broker是包含存儲的,是有狀態的,Broker的擴容更像是“拆分”)。高可靠,一致性等通過BookKeeper去保證。
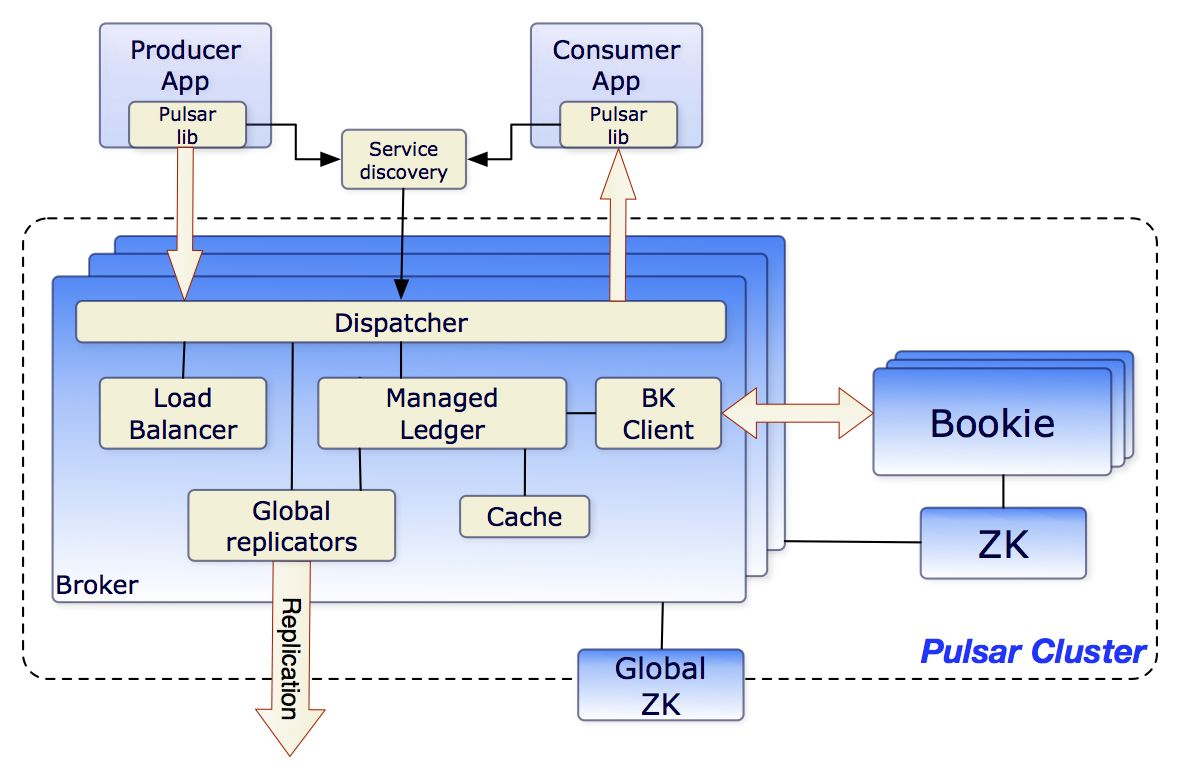
上圖是Pulsar Cluster的架構:
采用 ZooKeeper 存儲元數據,集群配置,作為coordination
-
local zk負責Pulsar Cluster內部的配置等
-
global zk則用於Pulsar Cluster之間的數據復制等
采用Bookie作為存儲設備(大多數MQ系統都采用本地磁盤或者DB作為存儲設備)
-
Broker負責負載均衡和消息的讀取、寫入等
-
Global replicators負責集群間的數據復制
GEO-REPLICATOIN
多個Broker節點組成一個Pulsar Cluster;多個Pulsar Cluster組成一個Pulsar Instance。
Pulsar通過GEO-REPLICATION支持一個Instance內在不同的地域發送和消費消息。
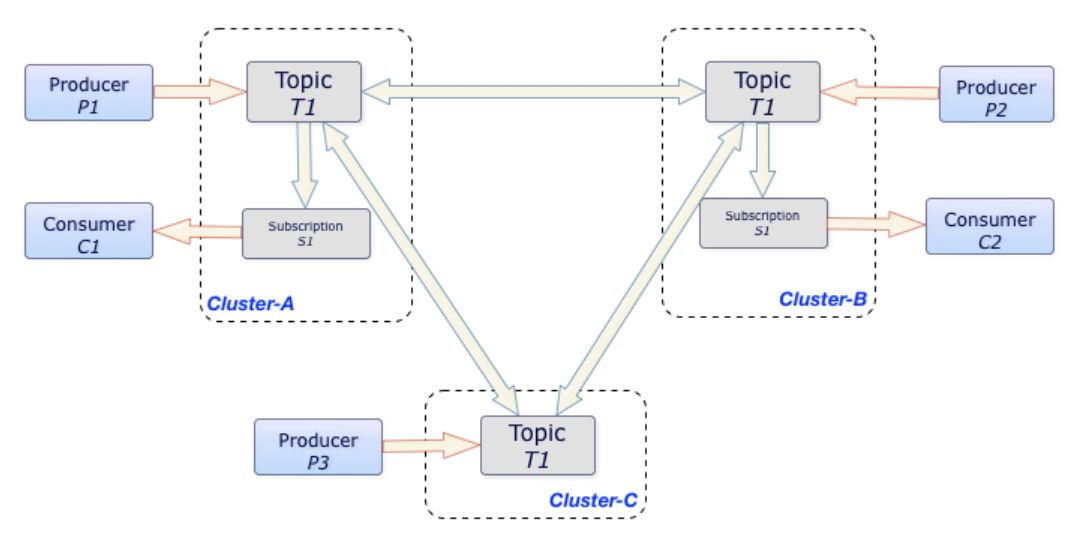
上圖中,Producer P1、P2、P3在不同的Cluster發送給Topic T1的消息,會在Cluster之間進行復制,Consumer C1、C2可以在自己所在的Cluster消費到所有的消息。
當消息被寫入Pulsar時,首先消息被持久化在local cluster,之后異步的發送到其他cluster。在沒有鏈接問題的情況下,通常復制的latency相近於網絡的RTT。
Pulsar的應用
- 作為普通的Pub-Sub模型的消息隊列使用,類似於RocketMQ
- 支持Function(Stream),整合到 Stream 平台(如 Spark)
總結
Apache Pulsar 提供了統一的消費模型,支持 Stream(如 Kafka)和 Queue(如 RabbitMQ)兩種消費模型, 支持 exclusive、failover 和 shared 三種消費模式。
同時,Pulsar 提供和 Kafka 兼容的 API,以及 Kafka-On-Pulsar(KoP) 組件來兼容 Kafka 的應用程序,KoP 在 Pulsar Broker 中解析 Kafka 協議,用戶不用改動客戶端的任何 Kafka 代碼就能直接使用 Pulsar。
一句話,Plusar 是對 Kafka 的增強或升級。