建議閱讀
重要性由高到低
本文簡要的這些文章做了一些總結
基本概念
IO,即in和out,也就是輸入和輸出,指應用程序和外部設備之間的數據傳遞,常見的外部設備包括文件(file)、管道 (pipe)、網絡連接 (network)。
流(Stream),是一個抽象的概念,是指一連串的數據(字符或字節),是以先進先出的方式發送信息的通道。
流的特性:
- 先進先出:最先寫入輸出流的數據最先被輸入流讀取到。
- 順序存取:可以一個接一個地往流中寫入一串字節,讀出時也將按寫入順序讀取一串字節,不能隨機訪問中間的數據。(RandomAccessFile除外)
- 只讀或只寫:每個流只能是輸入流或輸出流的一種,不能同時具備兩個功能,輸入流只能進行讀操作,對輸出流只能進行寫操作。在一個數據傳輸通道中,如果既要寫入數據,又要讀取數據,則要分別提供兩個流。
IO流主要的分類方式有以下3種:
- 按數據流的方向:輸入流、輸出流
- 按處理數據單位:字節流、字符流
- 按功能:節點流、處理流

輸入流和輸出流
輸入與輸出是相對於應用程序而言的,比如文件讀寫,讀取文件是輸入流,寫文件是輸出流,這點很容易搞反。

字節流和字符流
字節流和字符流的用法幾乎完成全一樣,區別在於字節流和字符流所操作的數據單元不同,字節流操作的單元是數據單元是8位的字節,字符流操作的是數據單元為16位的字符。
為什么要有字符流?
Java中字符是采用Unicode標准,Unicode 編碼中,一個英文為一個字節,一個中文為兩個字節。

而在UTF-8編碼中,一個中文字符是3個字節。例如下面圖中,“雲深不知處”5個中文對應的是15個字節:-28-70-111-26-73-79-28-72-115-25-97-91-27-92-124

那么問題來了,如果使用字節流處理中文,如果一次讀寫一個字符對應的字節數就不會有問題,一旦將一個字符對應的字節分裂開來,就會出現亂碼了。為了更方便地處理中文這些字符,Java就推出了字符流。
字節流和字符流的其他區別:
- 字節流一般用來處理圖像、視頻、音頻、PPT、Word等類型的文件。字符流一般用於處理純文本類型的文件,如TXT文件等,但不能處理圖像視頻等非文本文件。用一句話說就是:字節流可以處理一切文件,而字符流只能處理純文本文件。
- 字節流本身沒有緩沖區,緩沖字節流相對於字節流,效率提升非常高。而字符流本身就帶有緩沖區,緩沖字符流相對於字符流效率提升就不是那么大了。詳見文末效率對比。
節點流和處理流
節點流:直接操作數據讀寫的流類,比如FileInputStream
處理流:對一個已存在的流的鏈接和封裝,通過對數據進行處理為程序提供功能強大、靈活的讀寫功能,例如BufferedInputStream(緩沖字節流)
處理流和節點流應用了Java的裝飾者設計模式。
下圖就很形象地描繪了節點流和處理流,處理流是對節點流的封裝,最終的數據處理還是由節點流完成的。

緩沖流 是一個非常重要的處理流。
我們知道,程序與磁盤的交互相對於內存運算是很慢的,容易成為程序的性能瓶頸。減少程序與磁盤的交互,是提升程序效率一種有效手段。緩沖流,就應用這種思路:普通流每次讀寫一個字節,而緩沖流在內存中設置一個緩存區,緩沖區先存儲足夠的待操作數據后,再與內存或磁盤進行交互。這樣,在總數據量不變的情況下,通過提高每次交互的數據量,減少了交互次數。

然而緩沖流的效率卻不一定高,在某些情形下,緩沖流的效率反而更低

IO流常用對象
File 對象
在計算機系統中,文件是非常重要的存儲方式。Java的標准庫java.io提供了File對象來操作文件和目錄。
構造File對象時,既可以傳入絕對路徑,也可以傳入相對路徑。絕對路徑是以根目錄開頭的完整路徑,例如:
File f = new File("C:\\Windows\\notepad.exe");
注意Windows平台使用\作為路徑分隔符,在Java字符串中需要用\\表示一個\。Linux平台使用/作為路徑分隔符:
File f = new File("/usr/bin/javac");
傳入相對路徑時,相對路徑前面加上當前目錄就是絕對路徑:
// 假設當前目錄是C:\Docs
File f1 = new File("sub\\javac"); // 絕對路徑是C:\Docs\sub\javac
File f3 = new File(".\\sub\\javac"); // 絕對路徑是C:\Docs\sub\javac
File f3 = new File("..\\sub\\javac"); // 絕對路徑是C:\sub\javac
可以用.表示當前目錄,..表示上級目錄。
File對象有3種形式表示的路徑,一種是getPath(),返回構造方法傳入的路徑,一種是getAbsolutePath(),返回絕對路徑,一種是getCanonicalPath,它和絕對路徑類似,但是返回的是規范路徑。
public class Main {
public static void main(String[] args) throws IOException {
File f = new File("..");
System.out.println(f.getPath());
System.out.println(f.getAbsolutePath());
System.out.println(f.getCanonicalPath());
}
}
..
/app/..
/
絕對路徑可以表示成C:\Windows\System32\..\notepad.exe,而規范路徑就是把.和..轉換成標准的絕對路徑后的路徑:C:\Windows\notepad.exe。
文件和目錄
File對象既可以表示文件,也可以表示目錄。特別要注意的是,構造一個File對象,即使傳入的文件或目錄不存在,代碼也不會出錯,因為構造一個File對象,並不會導致任何磁盤操作。只有當我們調用File對象的某些方法的時候,才真正進行磁盤操作。
例,調用isFile(),判斷該File對象是否是一個已存在的文件,調用isDirectory(),判斷該File對象是否是一個已存在的目錄。
用File對象獲取到一個文件時,還可以進一步判斷文件的權限和大小:
boolean canRead():是否可讀;boolean canWrite():是否可寫;boolean canExecute():是否可執行;long length():文件字節大小。
創建和刪除文件
當File對象表示一個文件時,可以通過createNewFile()創建一個新文件,用delete()刪除該文件:
File file = new File("/path/to/file");
if (file.createNewFile()) {
// 文件創建成功:
// TODO:
if (file.delete()) {
// 刪除文件成功:
}
}
有些時候,程序需要讀寫一些臨時文件,File對象提供了createTempFile()來創建一個臨時文件,以及deleteOnExit()在JVM退出時自動刪除該文件。
public class Main {
public static void main(String[] args) throws IOException {
File f = File.createTempFile("tmp-", ".txt"); // 提供臨時文件的前綴和后綴
f.deleteOnExit(); // JVM退出時自動刪除
System.out.println(f.isFile());
System.out.println(f.getAbsolutePath());
}
}
遍歷文件和目錄
當File對象表示一個目錄時,可以使用list()和listFiles()列出目錄下的文件和子目錄名。listFiles()提供了一系列重載方法,可以過濾不想要的文件和目錄:
public class Main {
public static void main(String[] args) throws IOException {
File f = new File("C:\\Windows");
File[] fs1 = f.listFiles(); // 列出所有文件和子目錄
printFiles(fs1);
File[] fs2 = f.listFiles(new FilenameFilter() { // 僅列出.exe文件
public boolean accept(File dir, String name) {
return name.endsWith(".exe"); // 返回true表示接受該文件
}
});
printFiles(fs2);
}
static void printFiles(File[] files) {
System.out.println("==========");
if (files != null) {
for (File f : files) {
System.out.println(f);
}
}
System.out.println("==========");
}
}
和文件操作類似,File對象如果表示一個目錄,可以通過以下方法創建和刪除目錄:
boolean mkdir():創建當前File對象表示的目錄;boolean mkdirs():創建當前File對象表示的目錄,並在必要時將不存在的父目錄也創建出來;boolean delete():刪除當前File對象表示的目錄,當前目錄必須為空才能刪除成功。
Path 對象
Java標准庫還提供了一個Path對象,它位於java.nio.file包。Path對象和File對象類似,但操作更加簡單:
public class Main {
public static void main(String[] args) throws IOException {
Path p1 = Paths.get(".", "project", "study"); // 構造一個Path對象
System.out.println(p1);
Path p2 = p1.toAbsolutePath(); // 轉換為絕對路徑
System.out.println(p2);
Path p3 = p2.normalize(); // 轉換為規范路徑
System.out.println(p3);
File f = p3.toFile(); // 轉換為File對象
System.out.println(f);
for (Path p : Paths.get("..").toAbsolutePath()) { // 可以直接遍歷Path
System.out.println(" " + p);
}
}
}
./project/study
/app/./project/study
/app/project/study
/app/project/study
app
..
練習
請利用File對象列出指定目錄下的所有子目錄和文件,並按層次打印。
例如,輸出:
Documents/
word/
1.docx
2.docx
work/
abc.doc
ppt/
other/
import java.io.*;
import java.nio.file.*;
public class fasta {
public static void main(String[] args) throws IOException {
File pwd = new File("./src");
System.out.println(pwd);
printFiles(pwd, 1);
}
public static void printFiles(File pwd, int depth) throws IOException {
String[] fs = pwd.list();
if (fs != null) {
for (String f : fs) {
for (int i = 0; i < depth; i++) {
System.out.print(" ");
}
System.out.println(f+'/');
Path temp = Paths.get(pwd.toString(), f);
printFiles(temp.toFile(), depth + 1);
}
}
}
}
InputStream
InputStream就是Java標准庫提供的最基本的輸入流。它位於java.io這個包里。java.io包提供了所有同步IO的功能。
要特別注意的一點是,InputStream並不是一個接口,而是一個抽象類,它是所有輸入流的超類。這個抽象類定義的一個最重要的方法就是int read(),簽名如下:
public abstract int read() throws IOException;
這個方法會讀取輸入流的下一個字節,並返回字節表示的int值(0~255)。如果已讀到末尾,返回-1表示不能繼續讀取了。
FileInputStream
FileInputStream是InputStream的一個子類。顧名思義,FileInputStream就是從文件流中讀取數據。下面的代碼演示了如何完整地讀取一個FileInputStream的所有字節:
public void readFile() throws IOException {
// 創建一個FileInputStream對象:
InputStream input = new FileInputStream("src/readme.txt");
for (;;) {
int n = input.read(); // 反復調用read()方法,直到返回-1
if (n == -1) {
break;
}
System.out.println(n); // 打印byte的值
}
input.close(); // 關閉流
}
InputStream和OutputStream都是通過close()方法來關閉流。關閉流就會釋放對應的底層資源。
我們還要注意到在讀取或寫入IO流的過程中,可能會發生錯誤,例如,文件不存在導致無法讀取,沒有寫權限導致寫入失敗,等等,這些底層錯誤由Java虛擬機自動封裝成IOException異常並拋出。因此,所有與IO操作相關的代碼都必須正確處理IOException。
仔細觀察上面的代碼,會發現一個潛在的問題:如果讀取過程中發生了IO錯誤,InputStream就沒法正確地關閉,資源也就沒法及時釋放。
因此,我們需要用try ... finally來保證InputStream在無論是否發生IO錯誤的時候都能夠正確地關閉:
public void readFile() throws IOException {
InputStream input = null;
try {
input = new FileInputStream("src/readme.txt");
int n;
while ((n = input.read()) != -1) { // 利用while同時讀取並判斷
System.out.println(n);
}
} finally {
if (input != null) { input.close(); }
}
}
用try ... finally來編寫上述代碼會感覺比較復雜,更好的寫法是利用Java 7引入的新的try(resource)的語法,只需要編寫try語句,讓編譯器自動為我們關閉資源。推薦的寫法如下:
public void readFile() throws IOException {
try (InputStream input = new FileInputStream("src/readme.txt")) {
int n;
while ((n = input.read()) != -1) {
System.out.println(n);
}
} // 編譯器在此自動為我們寫入finally並調用close()
}
實際上,編譯器並不會特別地為InputStream加上自動關閉。編譯器只看try(resource = ...)中的對象是否實現了java.lang.AutoCloseable接口,如果實現了,就自動加上finally語句並調用close()方法。InputStream和OutputStream都實現了這個接口,因此,都可以用在try(resource)中。
緩沖
在讀取流的時候,一次讀取一個字節並不是最高效的方法。很多流支持一次性讀取多個字節到緩沖區,對於文件和網絡流來說,利用緩沖區一次性讀取多個字節效率往往要高很多。InputStream提供了兩個重載方法來支持讀取多個字節:
int read(byte[] b):讀取若干字節並填充到byte[]數組,返回讀取的字節數int read(byte[] b, int off, int len):指定byte[]數組的偏移量和最大填充數
利用上述方法一次讀取多個字節時,需要先定義一個byte[]數組作為緩沖區,read()方法會盡可能多地讀取字節到緩沖區, 但不會超過緩沖區的大小。read()方法的返回值不再是字節的int值,而是返回實際讀取了多少個字節。如果返回-1,表示沒有更多的數據了。
利用緩沖區一次讀取多個字節的代碼如下:
public void readFile() throws IOException {
try (InputStream input = new FileInputStream("src/readme.txt")) {
// 定義1000個字節大小的緩沖區:
byte[] buffer = new byte[1000];
int n;
while ((n = input.read(buffer)) != -1) { // 讀取到緩沖區
System.out.println("read " + n + " bytes.");
}
}
}
阻塞
在調用InputStream的read()方法讀取數據時,我們說read()方法是阻塞(Blocking)的。它的意思是,對於下面的代碼:
int n;
n = input.read(); // 必須等待read()方法返回才能執行下一行代碼
int m = n;
執行到第二行代碼時,必須等read()方法返回后才能繼續。因為讀取IO流相比執行普通代碼,速度會慢很多,因此,無法確定read()方法調用到底要花費多長時間。
OutputStream
和InputStream相反,OutputStream是Java標准庫提供的最基本的輸出流。
和InputStream類似,OutputStream也是抽象類,它是所有輸出流的超類。這個抽象類定義的一個最重要的方法就是void write(int b),簽名如下:
public abstract void write(int b) throws IOException;
這個方法會寫入一個字節到輸出流。要注意的是,雖然傳入的是int參數,但只會寫入一個字節,即只寫入int最低8位表示字節的部分(相當於b & 0xff)。
Flush
和InputStream類似,OutputStream也提供了close()方法關閉輸出流,以便釋放系統資源。要特別注意:OutputStream還提供了一個flush()方法,它的目的是將緩沖區的內容真正輸出到目的地。
為什么要有
flush()?因為向磁盤、網絡寫入數據的時候,出於效率的考慮,操作系統並不是輸出一個字節就立刻寫入到文件或者發送到網絡,而是把輸出的字節先放到內存的一個緩沖區里(本質上就是一個byte[]數組),等到緩沖區寫滿了,再一次性寫入文件或者網絡。對於很多IO設備來說,一次寫一個字節和一次寫1000個字節,花費的時間幾乎是完全一樣的,所以OutputStream有個flush()方法,能強制把緩沖區內容輸出。
通常情況下,我們不需要調用這個flush()方法,因為緩沖區寫滿了OutputStream會自動調用它,並且,在調用close()方法關閉OutputStream之前,也會自動調用flush()方法。
但是,在某些情況下,我們必須手動調用flush()方法。舉個栗子:
小明正在開發一款在線聊天軟件,當用戶輸入一句話后,就通過OutputStream的write()方法寫入網絡流。小明測試的時候發現,發送方輸入后,接收方根本收不到任何信息,怎么肥四?
原因就在於寫入網絡流是先寫入內存緩沖區,等緩沖區滿了才會一次性發送到網絡。如果緩沖區大小是4K,則發送方要敲幾千個字符后,操作系統才會把緩沖區的內容發送出去,這個時候,接收方會一次性收到大量消息。
解決辦法就是每輸入一句話后,立刻調用flush(),不管當前緩沖區是否已滿,強迫操作系統把緩沖區的內容立刻發送出去。
實際上,InputStream也有緩沖區。例如,從FileInputStream讀取一個字節時,操作系統往往會一次性讀取若干字節到緩沖區,並維護一個指針指向未讀的緩沖區。然后,每次我們調用int read()讀取下一個字節時,可以直接返回緩沖區的下一個字節,避免每次讀一個字節都導致IO操作。當緩沖區全部讀完后繼續調用read(),則會觸發操作系統的下一次讀取並再次填滿緩沖區。
FileOutputStream
我們以FileOutputStream為例,演示如何將若干個字節寫入文件流:
public void writeFile() throws IOException {
OutputStream output = new FileOutputStream("out/readme.txt");
output.write(72); // H
output.write(101); // e
output.write(108); // l
output.write(108); // l
output.write(111); // o
output.close();
}
每次寫入一個字節非常麻煩,更常見的方法是一次性寫入若干字節。這時,可以用OutputStream提供的重載方法void write(byte[])來實現:
public void writeFile() throws IOException {
OutputStream output = new FileOutputStream("out/readme.txt");
output.write("Hello".getBytes("UTF-8")); // Hello
output.close();
}
和InputStream一樣,上述代碼沒有考慮到在發生異常的情況下如何正確地關閉資源。寫入過程也會經常發生IO錯誤,例如,磁盤已滿,無權限寫入等等。我們需要用try(resource)來保證OutputStream在無論是否發生IO錯誤的時候都能夠正確地關閉:
public void writeFile() throws IOException {
try (OutputStream output = new FileOutputStream("out/readme.txt")) {
output.write("Hello".getBytes("UTF-8")); // Hello
} // 編譯器在此自動為我們寫入finally並調用close()
}
阻塞
和InputStream一樣,OutputStream的write()方法也是阻塞的。
同時操作多個AutoCloseable資源時,在try(resource) { ... }語句中可以同時寫出多個資源,用;隔開。例如,同時讀寫兩個文件:
// 讀取input.txt,寫入output.txt:
try (InputStream input = new FileInputStream("input.txt");
OutputStream output = new FileOutputStream("output.txt"))
{
input.transferTo(output); // transferTo的作用是?
}
Reader
Reader是Java的IO庫提供的另一個輸入流接口。和InputStream的區別是,InputStream是一個字節流,即以byte為單位讀取,而Reader是一個字符流,即以char為單位讀取:
| InputStream | Reader |
|---|---|
字節流,以byte為單位 |
字符流,以char為單位 |
讀取字節(-1,0~255):int read() |
讀取字符(-1,0~65535):int read() |
讀到字節數組:int read(byte[] b) |
讀到字符數組:int read(char[] c) |
java.io.Reader是所有字符輸入流的超類,它最主要的方法是:
public int read() throws IOException;
FileReader
FileReader是Reader的一個子類,它可以打開文件並獲取Reader。下面的代碼演示了如何完整地讀取一個FileReader的所有字符:
public void readFile() throws IOException {
// 創建一個FileReader對象:
Reader reader = new FileReader("src/readme.txt"); // 字符編碼是???
for (;;) {
int n = reader.read(); // 反復調用read()方法,直到返回-1
if (n == -1) {
break;
}
System.out.println((char)n); // 打印char
}
reader.close(); // 關閉流
}
如果我們讀取一個純ASCII編碼的文本文件,上述代碼工作是沒有問題的。但如果文件中包含中文,就會出現亂碼,因為FileReader默認的編碼與系統相關,例如,Windows系統的默認編碼可能是GBK,打開一個UTF-8編碼的文本文件就會出現亂碼。
要避免亂碼問題,我們需要在創建FileReader時指定編碼:
Reader reader = new FileReader("src/readme.txt", StandardCharsets.UTF_8);
和InputStream類似,Reader也是一種資源,需要保證出錯的時候也能正確關閉,所以我們需要用try (resource)來保證Reader在無論有沒有IO錯誤的時候都能夠正確地關閉:
try (Reader reader = new FileReader("src/readme.txt", StandardCharsets.UTF_8) {
// TODO
}
Reader還提供了一次性讀取若干字符並填充到char[]數組的方法:
public int read(char[] c) throws IOException
它返回實際讀入的字符個數,最大不超過char[]數組的長度。返回-1表示流結束。
利用這個方法,我們可以先設置一個緩沖區,然后,每次盡可能地填充緩沖區:
public void readFile() throws IOException {
try (Reader reader = new FileReader("src/readme.txt", StandardCharsets.UTF_8)) {
char[] buffer = new char[1000];
int n;
while ((n = reader.read(buffer)) != -1) {
System.out.println("read " + n + " chars.");
}
}
}
小結
Reader定義了所有字符輸入流的超類:
FileReader實現了文件字符流輸入,使用時需要指定編碼;CharArrayReader和StringReader可以在內存中模擬一個字符流輸入。
Reader是基於InputStream構造的:可以通過InputStreamReader在指定編碼的同時將任何InputStream轉換為Reader。
總是使用try (resource)保證Reader正確關閉。
Writer
Reader是帶編碼轉換器的InputStream,它把byte轉換為char,而Writer就是帶編碼轉換器的OutputStream,它把char轉換為byte並輸出。
Writer和OutputStream的區別如下:
| OutputStream | Writer |
|---|---|
字節流,以byte為單位 |
字符流,以char為單位 |
寫入字節(0~255):void write(int b) |
寫入字符(0~65535):void write(int c) |
寫入字節數組:void write(byte[] b) |
寫入字符數組:void write(char[] c) |
| 無對應方法 | 寫入String:void write(String s) |
Writer是所有字符輸出流的超類,它提供的方法主要有:
- 寫入一個字符(0~65535):
void write(int c); - 寫入字符數組的所有字符:
void write(char[] c); - 寫入String表示的所有字符:
void write(String s)。
FileWriter
FileWriter就是向文件中寫入字符流的Writer。它的使用方法和FileReader類似:
try (Writer writer = new FileWriter("readme.txt", StandardCharsets.UTF_8)) {
writer.write('H'); // 寫入單個字符
writer.write("Hello".toCharArray()); // 寫入char[]
writer.write("Hello"); // 寫入String
}
小結
Writer定義了所有字符輸出流的超類:
FileWriter實現了文件字符流輸出;CharArrayWriter和StringWriter在內存中模擬一個字符流輸出。
使用try (resource)保證Writer正確關閉。
Writer是基於OutputStream構造的,可以通過OutputStreamWriter將OutputStream轉換為Writer,轉換時需要指定編碼。
Filter 模式
又稱裝飾者模式
定義:動態給一個對象添加一些額外的職責,就象在牆上刷油漆.使用Decorator模式相比用生成子類方式達到功能的擴充顯得更為靈活。
設計初衷: 通常可以使用繼承來實現功能的拓展,如果這些需要拓展的功能的種類很繁多,那么勢必生成很多子類,增加系統的復雜性,同時,使用繼承實現功能拓展,我們必須可預見這些拓展功能,這些功能是編譯時就確定了,是靜態的。
要點: 裝飾者與被裝飾者擁有共同的超類,繼承的目的是繼承類型,而不是行為
Java的IO標准庫提供的InputStream根據來源可以包括:
FileInputStream:從文件讀取數據,是最終數據源;ServletInputStream:從HTTP請求讀取數據,是最終數據源;Socket.getInputStream():從TCP連接讀取數據,是最終數據源;
如果我們要給FileInputStream添加緩沖功能,則可以從FileInputStream派生一個類:
BufferedFileInputStream extends FileInputStream
如果要給FileInputStream添加計算簽名的功能,類似的,也可以從FileInputStream派生一個類:
DigestFileInputStream extends FileInputStream
如果要給FileInputStream添加加密/解密功能,還是可以從FileInputStream派生一個類:
CipherFileInputStream extends FileInputStream
這還只是針對FileInputStream設計,如果針對另一種InputStream設計,很快會出現子類爆炸的情況。
因此,直接使用繼承,為各種InputStream附加更多的功能,根本無法控制代碼的復雜度,很快就會失控。
為了解決這個問題,JDK首先將InputStream分為兩大類:
一類是直接提供數據的基礎InputStream,例如:
- FileInputStream
- ByteArrayInputStream
- ServletInputStream
- ...
一類是提供額外附加功能的InputStream,例如:
- BufferedInputStream
- DigestInputStream
- CipherInputStream
- ...
上述這種通過一個“基礎”組件再疊加各種“附加”功能組件的模式,稱之為Filter模式(或者裝飾器模式:Decorator)。它可以讓我們通過少量的類來實現各種功能的組合:
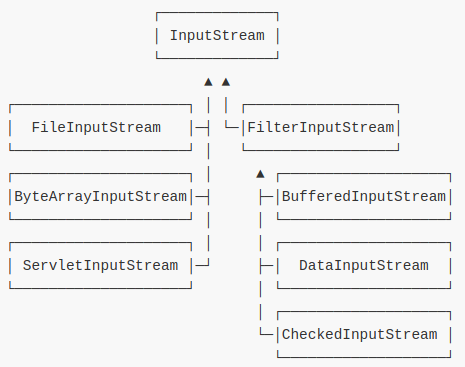
簡單來說,裝飾模式在基類上增加的每一個功能(簡單稱做功能類)都能夠互相調用,每一個功能類之間都是平行層級的,與直接使用extend不同,直接繼承的類之間是樹狀結構而不是平行的。這樣就避免功能之間的嵌套。
假如,我們基於A類,又實現了三個不同的功能類(A1,A2,A3),但是此時我們需要同時用到A1和A2的功能,按照直接繼承的思路而言,就要繼承A1或者A2實現A12的一個新類。但是對裝飾模式而言,我們不需要新建一個類,直接A1(A2),相當於A1去調用A2,這樣就可以同時實現A1A2的功能。
例子
下面舉個例子:
假如我們要去買一個漢堡,漢堡有多種類,還可以選擇是否添加生菜、辣椒等配料。這樣給漢堡定價格,就可以使用裝飾者模式。
這里如果我們直接使用繼承來做的話,假如有n種配料,我們就需要將n種配料之間的不同組合的類全部實現出來,直接爆炸。
如果使用裝飾者模式來做,我們只需要定義n個類就可以完成漢堡定價的功能,因為n個類之間可以相互調用,我們可以很方便的類的組合。
下面是代碼:
首先是漢堡的基類,這里定義了一個抽象類,返回了漢堡的名字和價格。
package decorator;
public abstract class Humburger {
protected String name;
public String getName(){ return name; }
public abstract double getPrice();
}
然后是漢堡的種類,這里用的雞腿堡
package decorator;
public class ChickenBurger extends Humburger {
public ChickenBurger(){ name = "雞腿堡"; }
@Override
public double getPrice() { return 10; }
}
配料的基類,返回配料的名稱
package decorator;
public abstract class Condiment extends Humburger {
public abstract String getName();
}
生菜(裝飾的第一層)
package decorator;
public class Lettuce extends Condiment {
Humburger hburger;
public Lettuce(Humburger burger){
this.hburger = burger;
}
@Override
public String getName() {
return hburger.getName()+" 加生菜";
}
@Override
public double getPrice() {
return hburger.getPrice()+1.5;
}
}
辣椒(裝飾者的第二層)
package decorator;
public class Chilli extends Condiment {
Humburger hburger;
public Chilli(Humburger burger){
this.hburger = burger;
}
@Override
public String getName() {
return hburger.getName()+" 加辣椒";
}
@Override
public double getPrice() {
return hburger.getPrice(); //辣椒是免費的哦
}
}
測試類
package decorator;
public class Test {
public static void main(String[] args) {
// 只要一個雞肉堡
Humburger humburger = new ChickenBurger();
System.out.println(humburger.getName()+" 價錢:"+humburger.getPrice());
// 雞肉堡加生菜,調用雞肉堡
Lettuce lettuce = new Lettuce(humburger);
System.out.println(lettuce.getName()+" 價錢:"+lettuce.getPrice());
// 雞肉堡加辣椒,調用雞肉堡
Chilli chilli = new Chilli(humburger);
System.out.println(chilli.getName()+" 價錢:"+chilli.getPrice());
// 雞肉堡加生菜加辣椒,調用雞肉生菜堡
Chilli chilli2 = new Chilli(lettuce);
System.out.println(chilli2.getName()+" 價錢:"+chilli2.getPrice());
}
}
雞腿堡 價錢:10.0
雞腿堡 加生菜 價錢:11.5
雞腿堡 加辣椒 價錢:10.0
雞腿堡 加生菜 加辣椒 價錢:11.5