通常,Kafka中的每個Partiotion中有多個副本(Replica)用於實現高可用,使用相關命令可以查看某一Topic中的Partition數量、Leader、Follower以及ISR的情況:
[root@test-ece-kafka2 kafka]# ./bin/kafka-topics.sh --describe --zookeeper test-ece-zk1:2181 --topic uat-log
Topic:uat-log PartitionCount:5 ReplicationFactor:2 Configs:
Topic: uat-log Partition: 0 Leader: 1 Replicas: 1,3 Isr: 3,1
Topic: uat-log Partition: 1 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: uat-log Partition: 2 Leader: 3 Replicas: 3,2 Isr: 2,3
Topic: uat-log Partition: 3 Leader: 1 Replicas: 1,2 Isr: 2,1
Topic: uat-log Partition: 4 Leader: 2 Replicas: 2,3 Isr: 2,3
想象一個場景,Consumer正在消費Leader中Offset=10的數據,而此時Follower中只同步到Offset=8。那么當Leader所在的Broker宕機后,當前Follower經選舉成為新的Leader,Consumer再次消費時便會報錯。因此,Kafka引入了High Watermark(高水位)來保證副本數據的可靠性和一致性。
High Watermark(HW)
HW定義了消息的可見性,即標識Partition中的哪些消息是可以被Consumer消費的,只有小於HW值的消息才被認為是已備份或已提交的(committed)。而LEO(Log End Offset)則表示副本寫入下一條消息的Offset,因此同一副本的HW值永遠不會大於其LEO值。
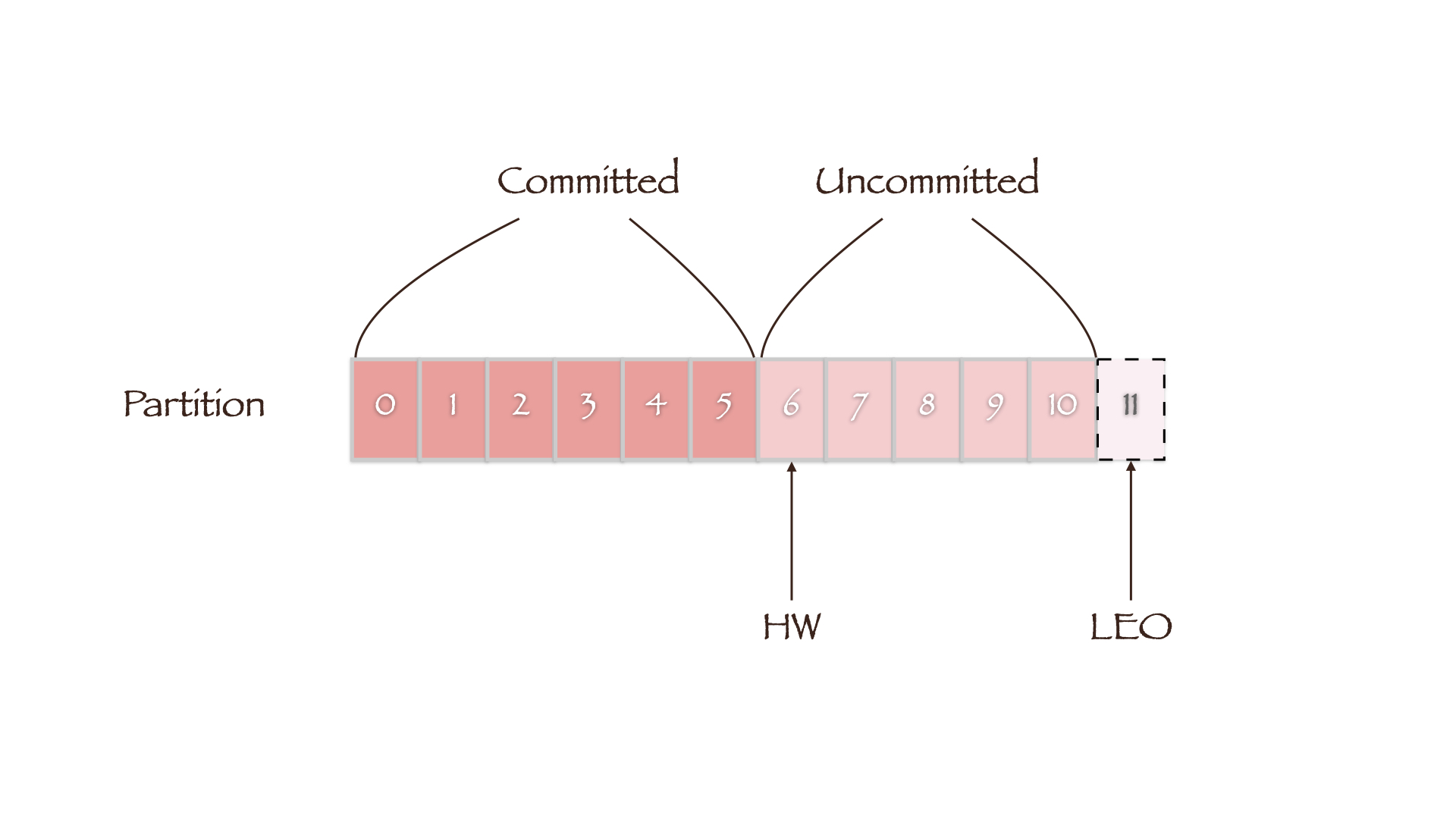
當集群中副本所在的Broker發生故障而后恢復時,副本先將數據截斷(Truncation)到其HW處(LEO等於HW),然后再開始向Leader同步數據。
HW的更新機制
每一個副本都保存了其HW值和LEO值,即Leader HW(實際上也是Partition HW)、Leader LEO和Follower HW、Follower LEO。而Leader所在的Broker上還保存了其他Follower的LEO值,稱為Remote LEO。上述幾個值的更新流程如下:
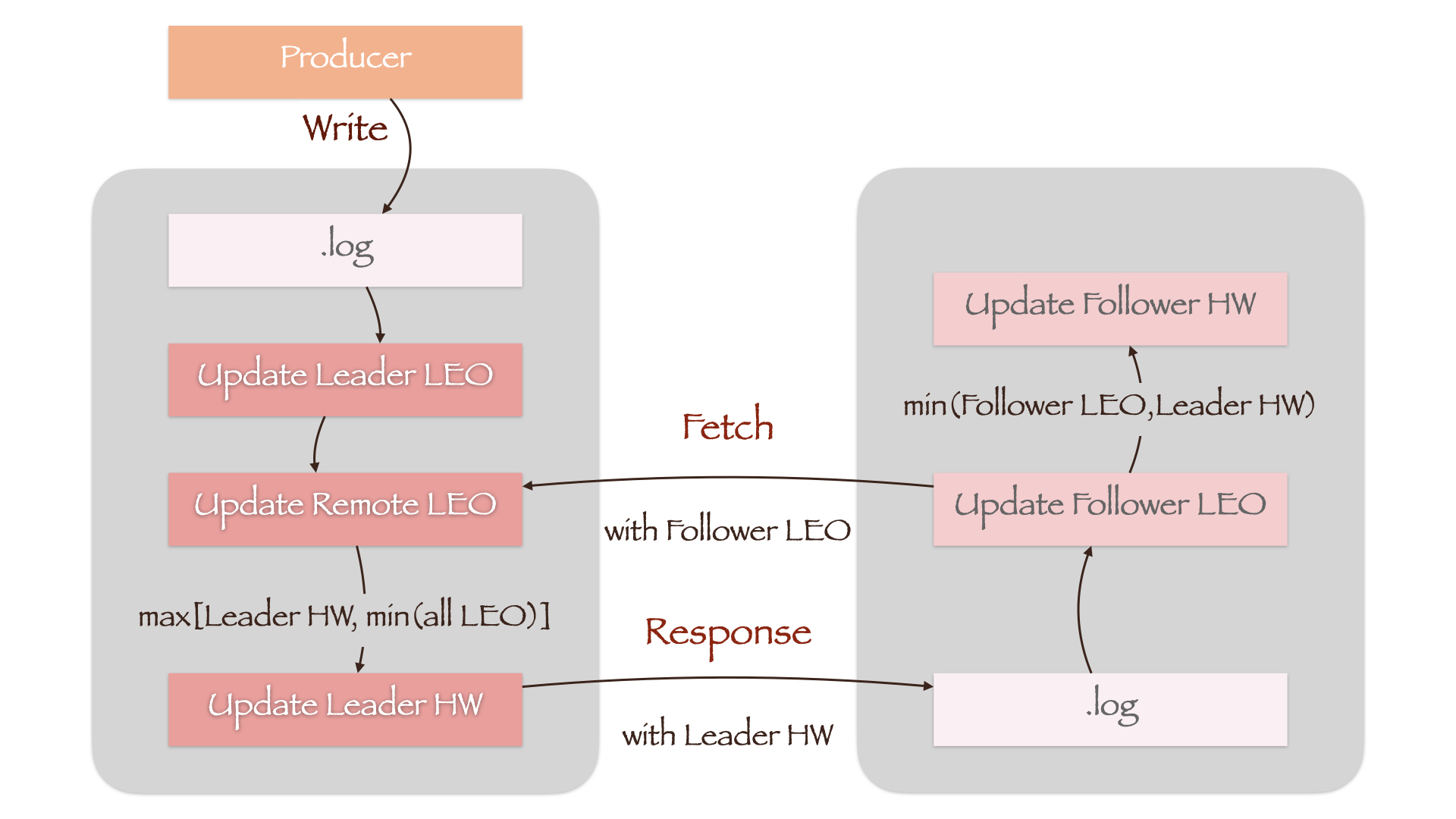
如圖所示,當Producer向.log文件寫入數據時,Leader LEO首先被更新。而Remote LEO要等到Follower向Leader發送同步請求(Fetch)時,才會根據請求攜帶的當前Follower LEO值更新。隨后,Leader計算所有副本LEO的最小值,將其作為新的Leader HW。考慮到Leader HW只能單調遞增,因此還增加了一個LEO最小值與當前Leader HW的比較,防止Leader HW值降低(max[Leader HW, min(All LEO)])。
Follower在接收到Leader的響應(Response)后,首先將消息寫入.log文件中,隨后更新Follower LEO。由於Response中攜帶了新的Leader HW,Follower將其與剛剛更新過的Follower LEO相比較,取最小值作為Follower HW(min(Follower LEO, Leader HW))。
舉例來說,如果一開始Leader和Follower中沒有任何數據,即所有值均為0。那么當Prouder向Leader寫入第一條消息,上述幾個值的變化順序如下:
| Leader LEO | Remote LEO | Leader HW | Follower LEO | Follower HW | |
|---|---|---|---|---|---|
| Producer Write | 1 | 0 | 0 | 0 | 0 |
| Follower Fetch | 1 | 0 | 0 | 0 | 0 |
| Leader Update HW | 1 | 0 | 0 | 0 | 0 |
| Leader Response | 1 | 0 | 0 | 1 | 0 |
| Follower Update HW | 1 | 0 | 0 | 1 | 0 |
| Follower Fetch | 1 | 1 | 0 | 1 | 0 |
| Leader Update HW | 1 | 1 | 1 | 1 | 0 |
| Leader Response | 1 | 1 | 1 | 1 | 0 |
| Follower Update HW | 1 | 1 | 1 | 1 | 1 |
HW的隱患
通過上面的表格我們發現,Follower往往需要進行兩次Fetch請求才能成功更新HW。Follower HW在某一階段內總是落后於Leader HW,因此副本在根據HW值截取數據時將有可能發生數據的丟失或不一致。
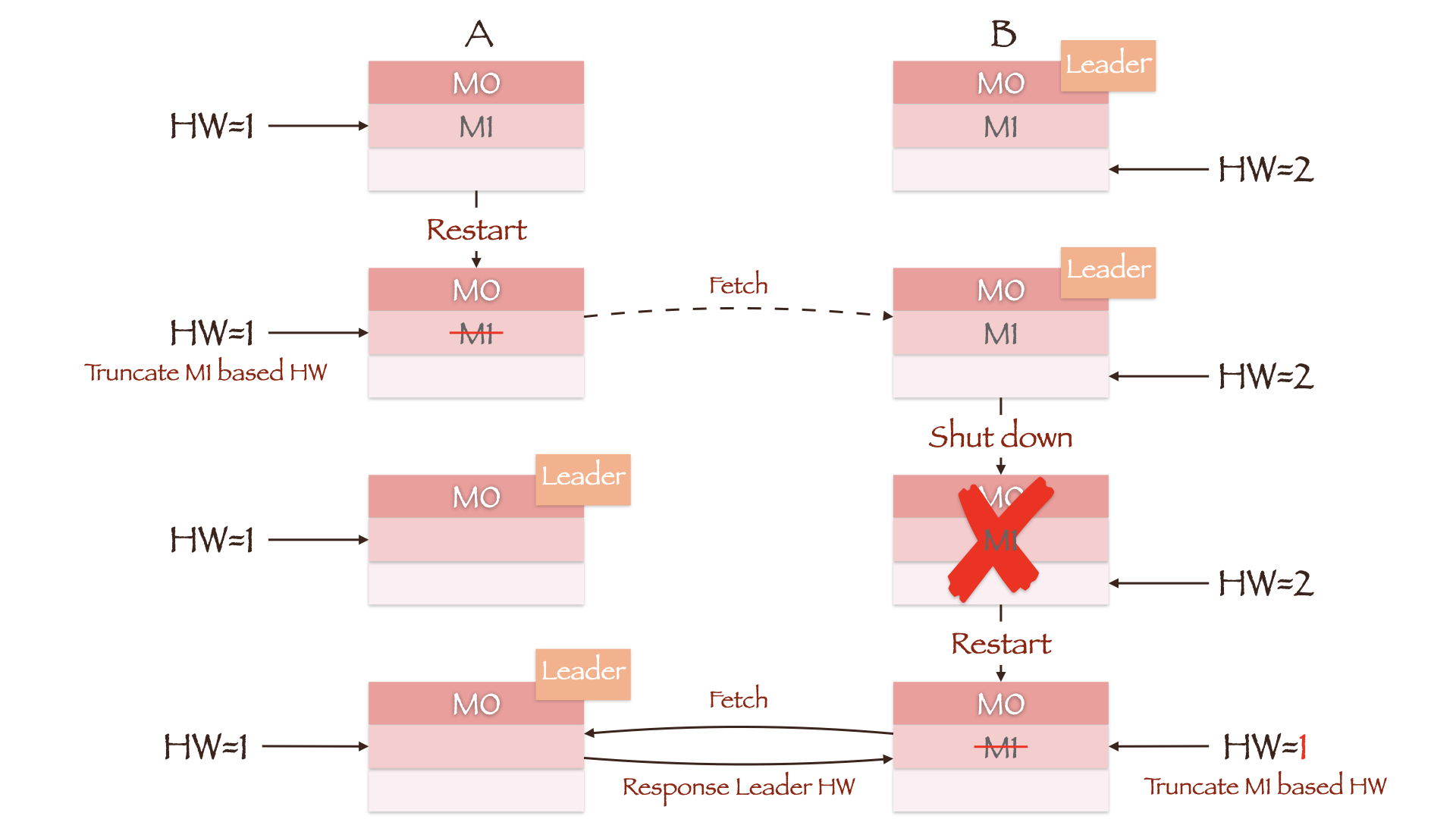
圖中兩副本的LEO均為2,但Leader副本B上的HW為2,Follower副本A上的HW為1。正常情況下,副本A將在接收Leader Response后根據Leader HW更新其Follower HW為2。但假如此時副本A所在的Broker重啟,它會把Follower LEO修改為重啟前自身的HW值1,因此數據M1(Offset=1)被截斷。當副本A重新向副本B發送同步請求時,如果副本B所在的Broker發生宕機,副本A將被選舉成為新的Leader。即使副本B所在的Broker能夠成功重啟且其LEO值依然為2,但只要它向當前Leader(副本A)發起同步請求后就會更新其HW為1(計算min(Follower LEO, Leader HW)),數據M1(Offset=1)隨即被截斷。如果min.insync.replicas參數為1,那么Producer不會因副本A沒有同步成功而重新發送消息,M1也就永遠丟失了。
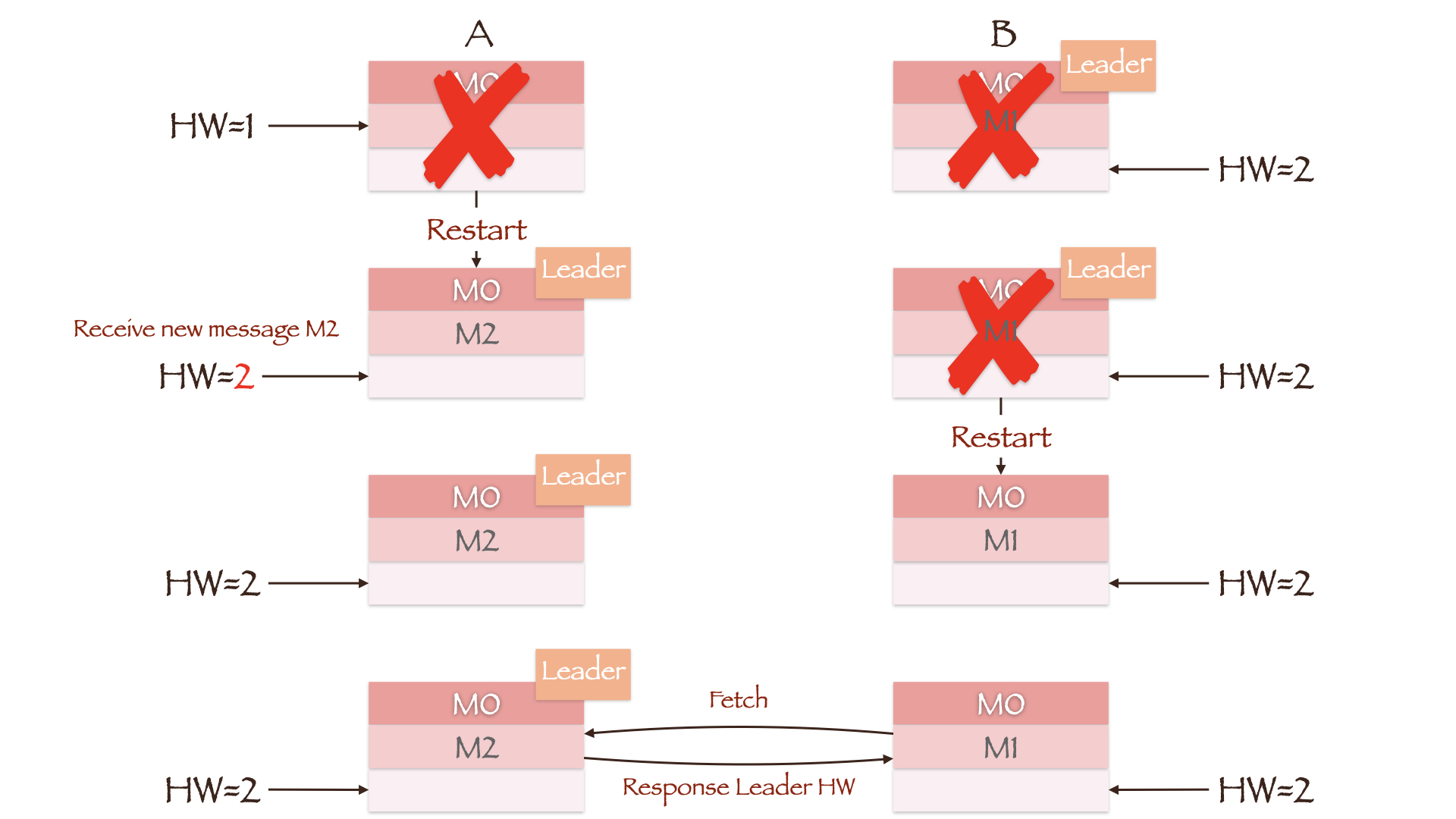
圖中Leader副本B寫入了兩條數據M0和M1,Follower副本A只寫入了一條數據M0。此時Leader HW為2,Follower HW為1。如果在Follower同步第二條數據前,兩副本所在的Broker均發生重啟且副本B所在的Broker先重啟成功,那么副本A將成為新的Leader。這時Producer向其寫入數據M2,副本A作為集群中的唯一副本,更新其HW為2。當副本B所在的Broker重啟后,它將向當前的Leader副本A同步數據。由於兩者的HW均為2,因此副本B不需要進行任何截斷操作。在這種情況下,副本B中的數據為重啟前的M0和M1,副本A中的數據卻是M0和M2,副本間的數據出現了不一致。
Leader Epoch
Kakfa引入Leader Epoch后,Follower就不再參考HW,而是根據Leader Epoch信息來截斷Leader中不存在的消息。這種機制可以彌補基於HW的副本同步機制的不足,Leader Epoch由兩部分組成:
- Epoch:一個單調增加的版本號。每當Leader副本發生變更時,都會增加該版本號。Epoch值較小的Leader被認為是過期Leader,不能再行使Leader的權力;
- 起始位移(Start Offset):Leader副本在該Epoch值上寫入首條消息的Offset。
舉例來說,某個Partition有兩個Leader Epoch,分別為(0, 0)和(1, 100)。這意味該Partion歷經一次Leader副本變更,版本號為0的Leader從Offset=0處開始寫入消息,共寫入了100條。而版本號為1的Leader則從Offset=100處開始寫入消息。
每個副本的Leader Epoch信息既緩存在內存中,也會定期寫入消息目錄下的leaderer-epoch-checkpoint文件中。當一個Follower副本從故障中恢復重新加入ISR中,它將:
- 向Leader發送LeaderEpochRequest,請求中包含了Follower的Epoch信息;
- Leader將返回其Follower所在Epoch的Last Offset;
- 如果Leader與Follower處於同一Epoch,那么Last Offset顯然等於Leader LEO;
- 如果Follower的Epoch落后於Leader,則Last Offset等於Follower Epoch + 1所對應的Start Offset。這可能有點難以理解,我們還是以(0, 0)和(1, 100)為例進行說明:Offset=100的消息既是Epoch=1的Start Offset,也是Epoch=0的Last Offset;
- Follower接收響應后根據返回的Last Offset截斷數據;
- 在數據同步期間,只要Follower發現Leader返回的Epoch信息與自身不一致,便會隨之更新Leader Epoch並寫入磁盤。

在剛剛介紹的數據丟失場景中,副本A所在的Broker重啟后根據自身的HW將數據M1截斷。而現在,副本A重啟后會先向副本B發送一個請求(LeaderEpochRequest)。由於兩副本的Epoch均為0,副本B返回的Last Offset為Leader LEO值2。而副本A上並沒有Offset大於等2的消息,因此無需進行數據截斷,同時其HW也會更新為2。之后副本B所在的Broker宕機,副本A成為新的Leader,Leader Epoch隨即更新為(1, 2)。當副本B重啟回來並向當前Leader副本A發送LeaderEpochRequest,得到的Last Offset為Epoch=1對應的Start Offset值2。同樣,副本B中消息的最大Offset值只有1,因此也無需進行數據截斷,消息M1成功保留了下來。
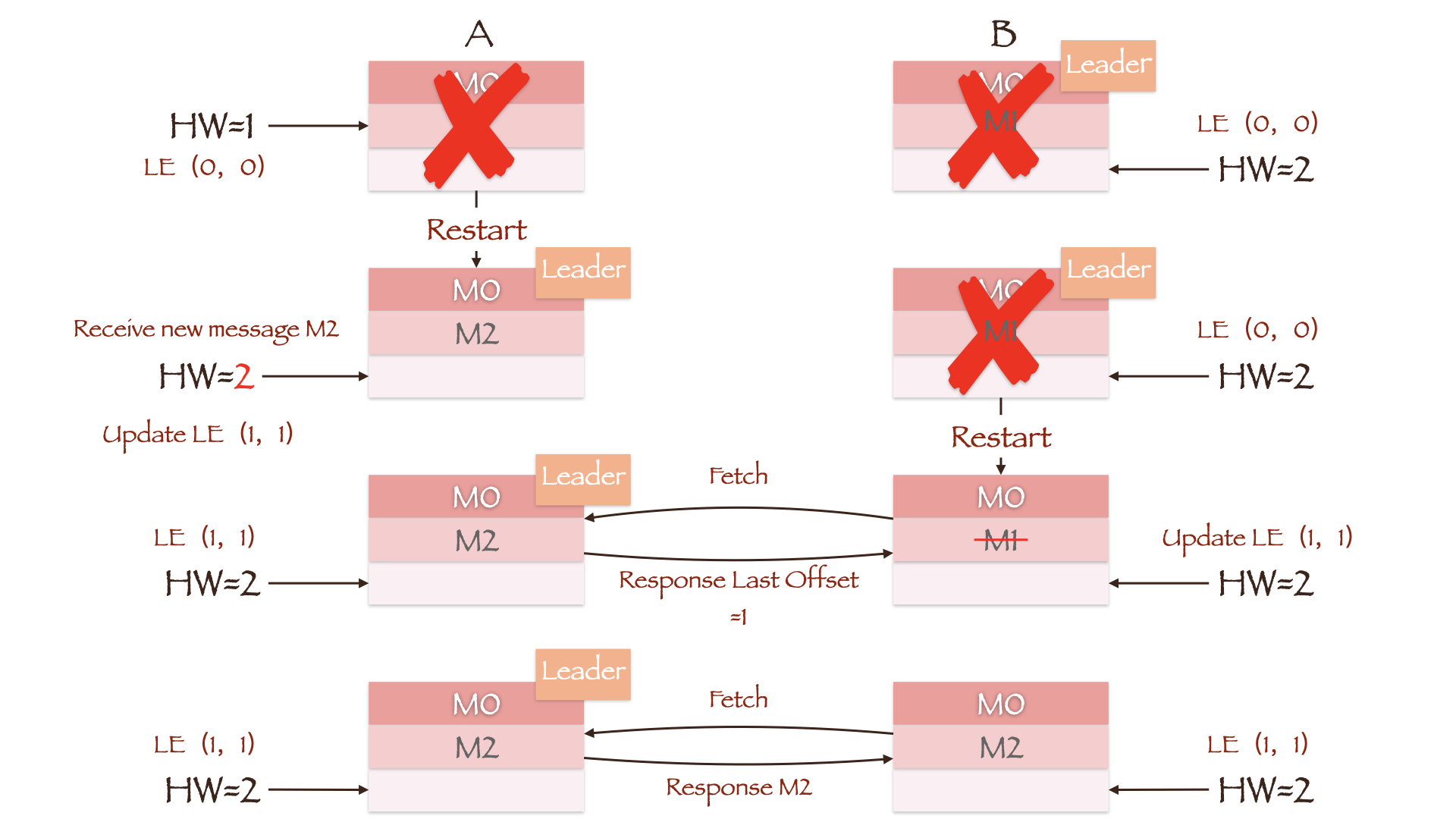
在剛剛介紹的數據不一致場景中,由於最后兩副本HW值相等,因此沒有將不一致的數據截斷。而現在,副本A重啟后並便會更新Leader Epoch為(1, 1),同時也會更新其HW值為2。副本B重啟后向當前Leader副本A發送LeaderEpochRequest,得到的Last Offset為Epoch=1對應的Start Offset值1,因此截斷Offset=1的消息M1。這樣只要副本B再次發起請求同步消息M2,兩副本的數據便可以保持一致。
值得一提的是,Leader Epoch機制在min.insync.replicas參數為1且unclean.leader.election.enabled參數為true時依然無法保證數據的可靠性。這里不再贅述,可參考KIP-101 - Alter Replication Protocol to use Leader Epoch rather than High Watermark for Truncation文中的附錄部分。