(十三)數據庫查詢處理之QueryExecution(2)
實驗室這一周真的忙爆(雖然都是各種打雜的活)所以拖了很久終於在周末(摸魚)把實驗3做完了。同時准備把和查詢這一塊有關的博客補一下。然后就進入最后一個project並行和鎖那里。不過下周華為的比賽就開了。爭取四月份之前把這些東西全都搞定。等到四月份的時候開一個新坑(leveldb源碼閱讀筆記📒)
1. 並行和分布式的區別
如今數據庫分布在多種資源中,以提高DBMS的不同方面
並行DBMS
- 資源在物理上靠近
- 資源之間可以高速互通
- 資源交互是非常廉價和可靠的
分布式DBMS
- 各種資源之間可以離得很遠
- 資源之間較慢速的互連進行通信
- 通信成本和問題不容忽視。(也就是很大)
2. 進程模型
1. PROCESS PER WORKER
每一個worker就是一個獨立的進程。worker可以理解為打工人。執行任務
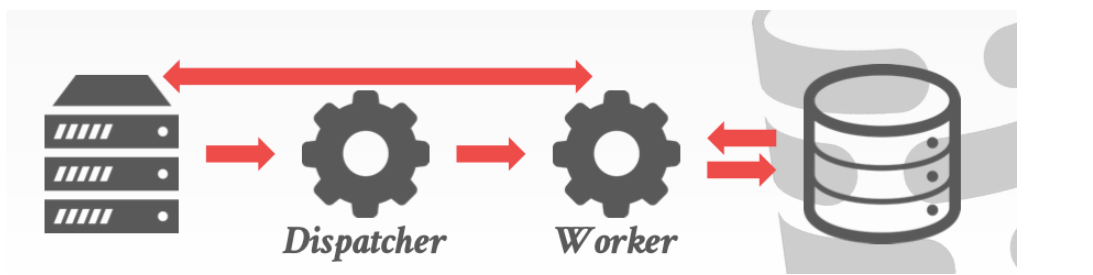
整個流程大致如下
- 你的應用程序想要和數據庫進行交互
- 通知調度器。調度器會
fork一個子進程(也就是產生一個worker)來執行這個任務 - 調度器會告訴應用程序你直接和worker進行交互就可
- 隨后worker訪問數據庫
- worker將得到的結果傳回應用程序
這個模型的好處是。如果一個進程出現了bug整個系統不會出現問題。只需要通知調度器在fork一個進程就好了
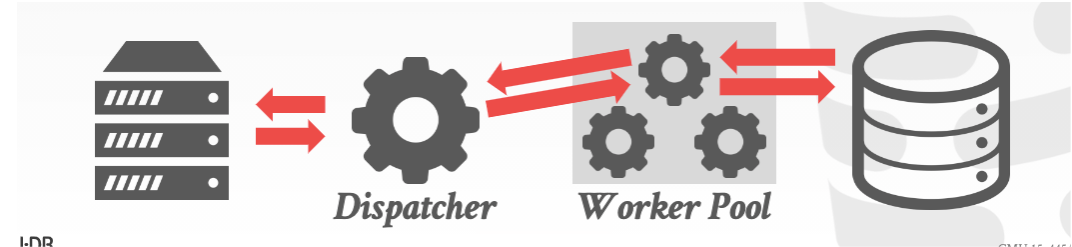
2. PROCESS POLL
進程之間仍然共享內存。並且依賴於操作系統的調度。每個worker可以使用在進程池中任意的一個進程
3. THREAD PER WORKER
一個進程可以有許多worker線程

整個流程大致如下
應用程序直接和worker的線程進行交互
優點
- 線程間的切換比進程間的切換要輕量級的多
- 這樣就不需要管理共享內存了(因為一個進程的多個線程就會共享這個進程的內存。這樣我們無需管理多個進程之間的內存共享)
注意這並不意味着dbms里的所有任務一定要多線程來執行
DBMS永遠知道的比操作系統更多

3. INTER-VS INTRA-QUERY PARALLELISM
1. I N T E R-Q U E R Y P A R A L L E L I S M
通過允許多條查詢同時進行來提高整體的性能。
如果多條查詢語句只是讀數據庫的話,那我們在不同的查詢之間幾乎不需要加任何限制條件
但是如果寫操作比較多的話就很麻煩了
2. I N T R A-Q U E R Y P A R A L L E L I S M
這個就是流水線操作。csapp第四章講的非常清楚
通過並行執行單條查詢語句來提高單個查詢的性能。可以從生產者消費者的角度來理解
下面來看一個例子 -> PARALLEL GRACE HASH JOIN
這個非常簡單我們讓一個worker去執行一行的join操作然后輸出結果就好
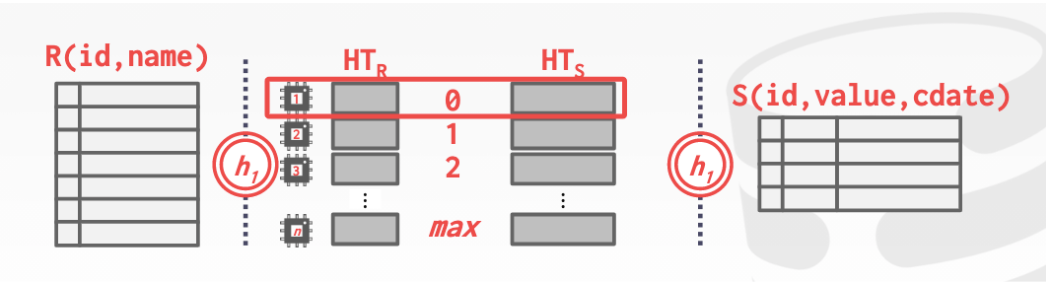
4. INTRA-QUERY PARALLELISM 的方法
1. 方法1 Intra-Operator(水平方法的並行)
將整個查詢操作分解為幾個獨立的片段,這些片段對不同的數據集執行相同的功能
例如下面的例子(截圖警告)
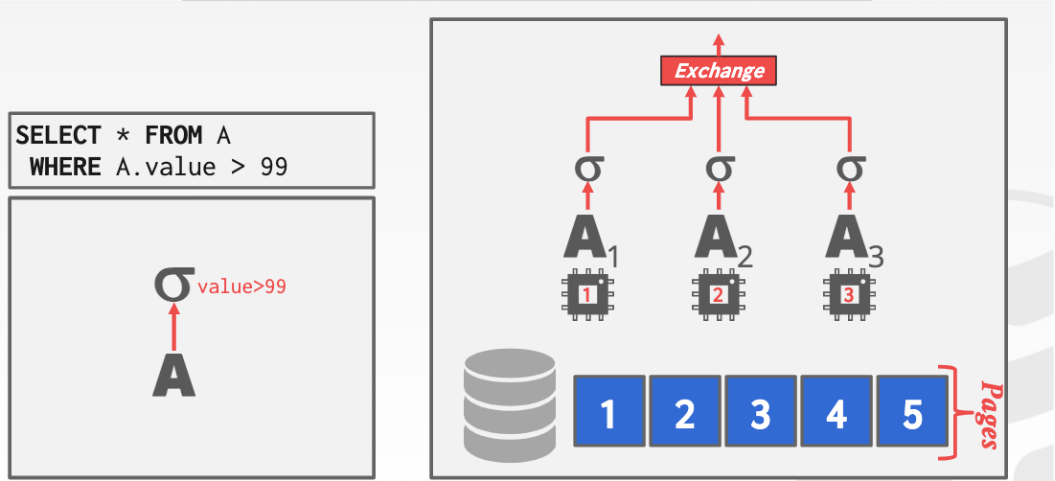
其中A1承擔一小部分任務
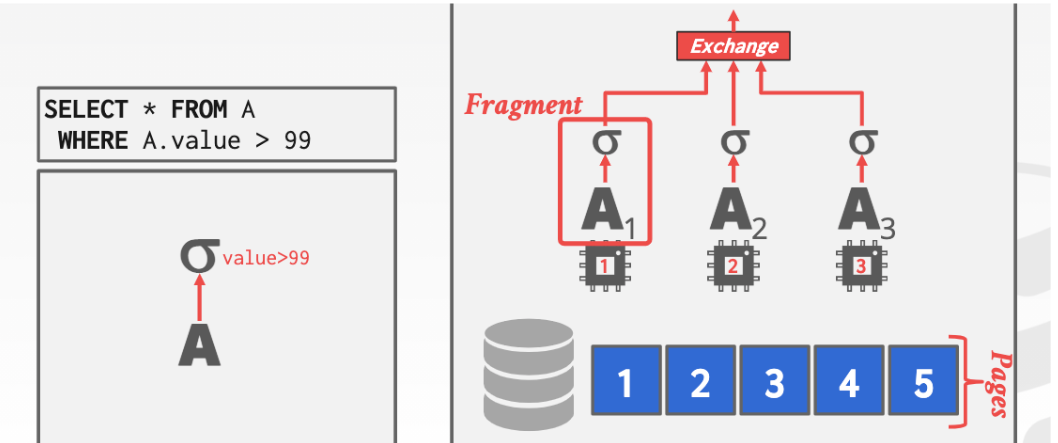
每個不同的worker承擔不同的任務
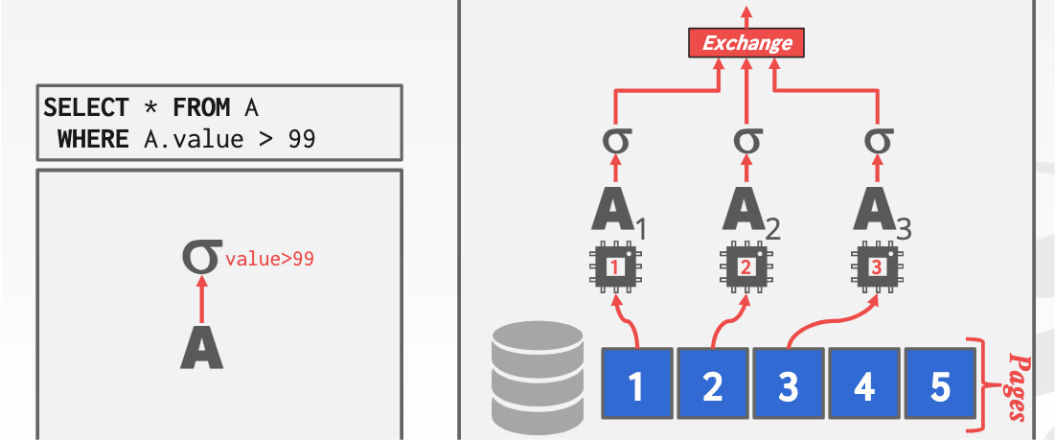
最上面的Exchange操作基本可以分為三個類型
-
case1 Gather
將來自多個worker的結果合並到一個輸出流中。最上層的Exchange操作必須始終是Gather
-
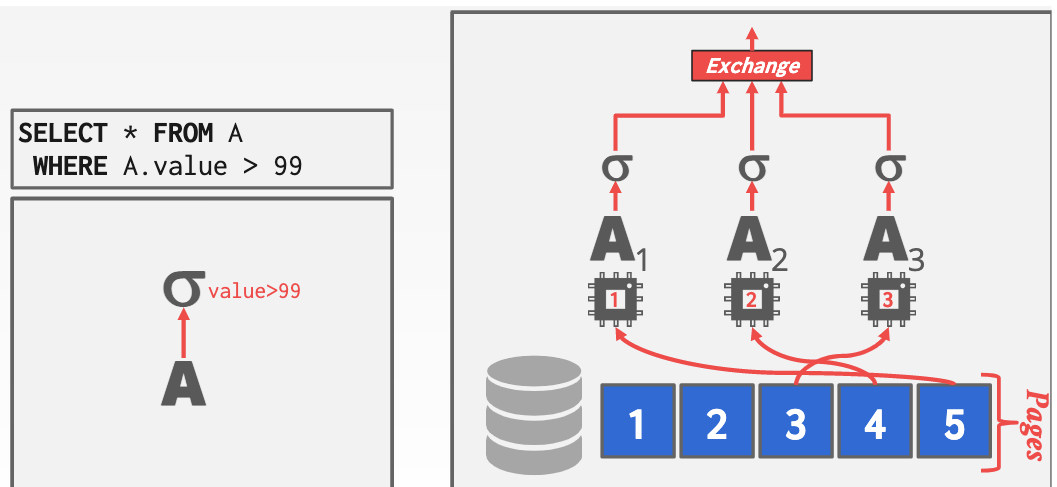
case2 Repartion
將多個輸入流重新打亂成多個輸出流
-
case3 Distribute
將單個輸入流拆分為多個輸出流
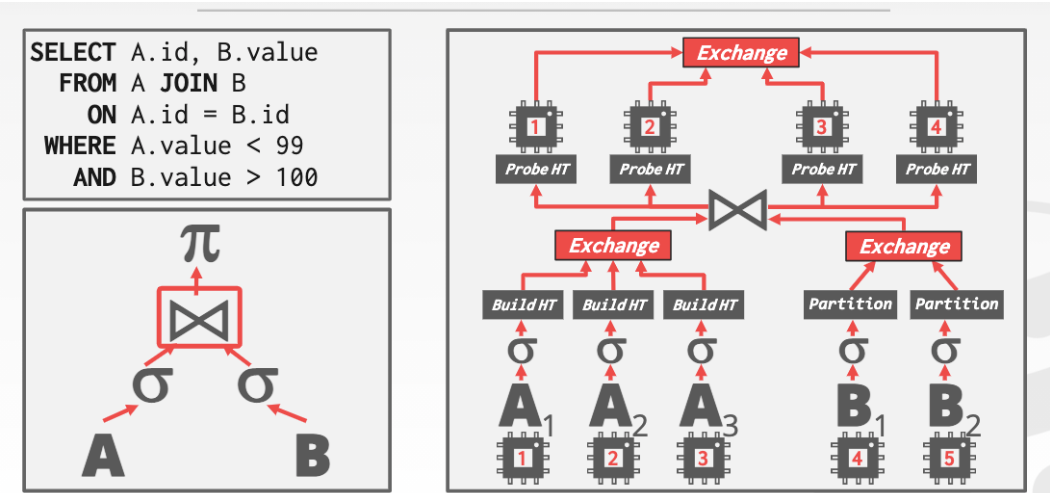
對於上面這個比較復雜的例子
- 首先A的所有worker和B的所有worker完成Hash join的基本操作
- 然后新的4個worker進行探測操作把結果匯入 根節點的Exchange得到結果
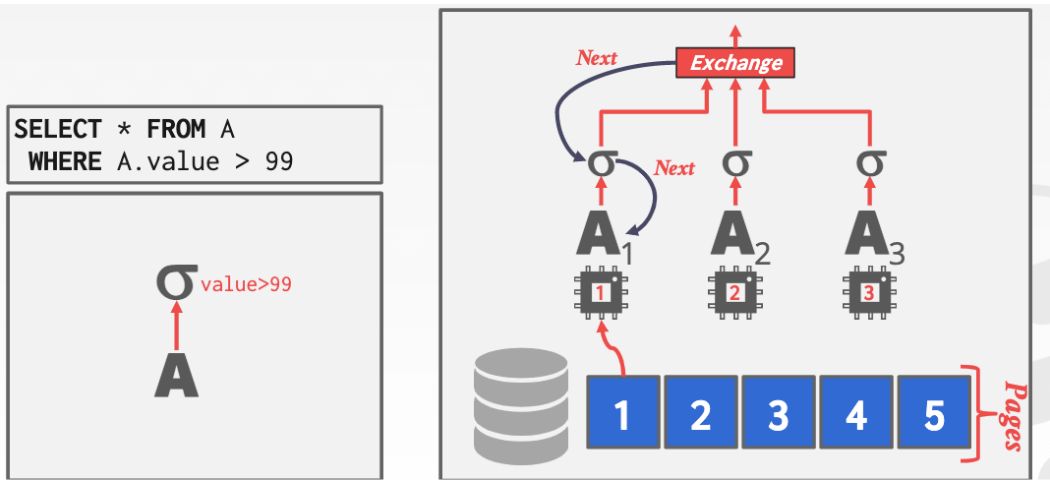
2. 方法2 INTER-OPERATOR PARALLELISM(垂直方向)
這也叫做pipelined parallelism.

這種方法非常好理解就是位於下層的worker把得到的結果向上傳遞給上層的worker
3. 方法3 Bushy Parallelism
方法1和2的結合版本
SELECT*FROM A JOIN B JOIN C JOIN D

在這個方法里一個woker1和worker同時執行整條語句的兩個部分。並且會將執行之后得到的結果往上傳遞給worker3和worker4
因為磁盤的限制。所以使用額外的進程/線程可能並不會產生很好的效果。接下來介紹I/O的並行
5. I / O PARALLELISM
1. MULTI-DISK PARALLELISM
拓展閱讀RAID
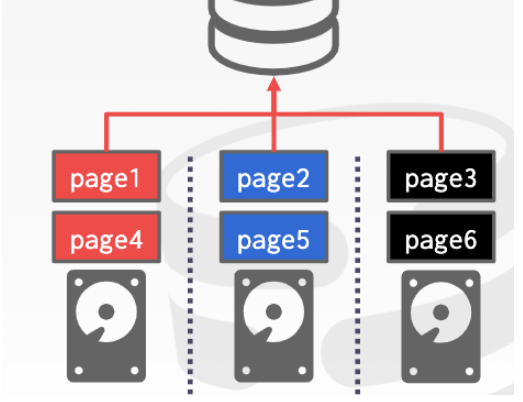
RAID0形式
不同的page存儲在不同的存儲設備中
RAID1形式
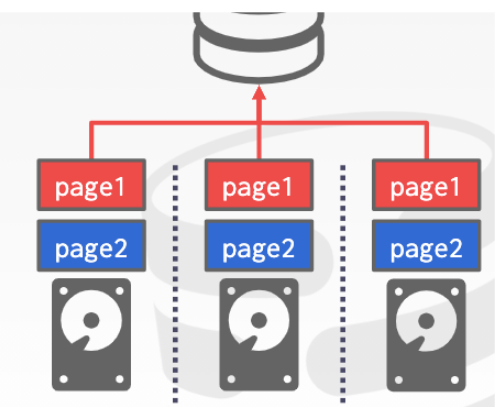
不同的存儲設備中存儲着相同的數據。
6. PARTITIONING
邏輯上的一張表。我們可以把它分成幾個獨立的部分放在不同的物理資源中。並且理想情況下分區程序應該對用戶是透明的
下面來看兩種不同的划分方法
1. 垂直划分
顧名思義就是按照列來划分。我們可以把不同的列放在不同的物理資源中

2. 水平划分
水平划分就是把不同的tuple(元組)放在不同的物理資源中
