基礎知識
Spring Data JPA 初識
JPA 是 JDK 5.0 新增的協議,通過相關持久層注解(@Entity 里面的各種注解)來描述對象和關系型數據里面的表映射關系,並將 Java 項目運行期的實體對象,通過一種Session持久化到數據庫中。
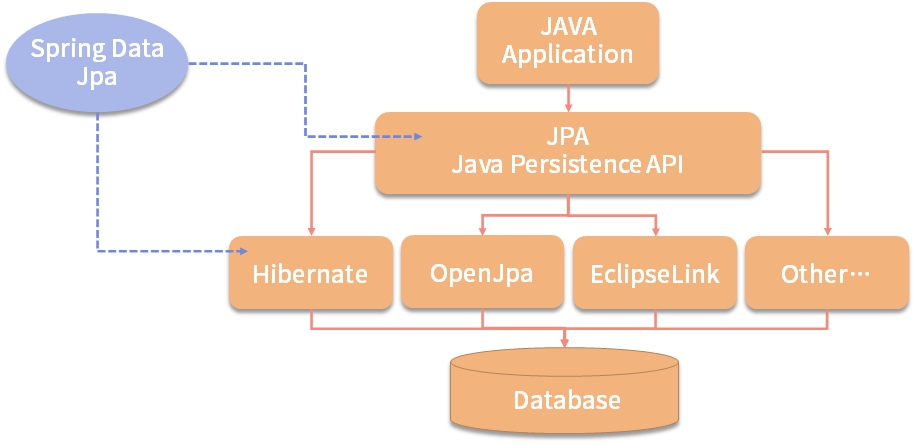
JPA 的宗旨是為 POJO 提供持久化標准規范,可以集成在 Spring 的全家桶使用,也可以直接寫獨立 application 使用,任何用到 DB 操作的場景,都可以使用,極大地方便開發和測試,所以 JPA 的理念已經深入人心了。Spring Data JPA、Hibernate 3.2+、TopLink 10.1.3 以及 OpenJPA、QueryDSL 都是實現 JPA 協議的框架,他們之間的關系結構如下圖所示:
Spring Data 項目是從 2010 年開發發展起來的,Spring Data 利用一個大家熟悉的、一致的、基於“注解”的數據訪問編程模型,做一些公共操作的封裝,它可以輕松地讓開發者使用數據庫訪問技術,包括關系數據庫、非關系數據庫(NoSQL)。同時又有不同的數據框架的實現,保留了每個底層數據存儲結構的特殊特性。
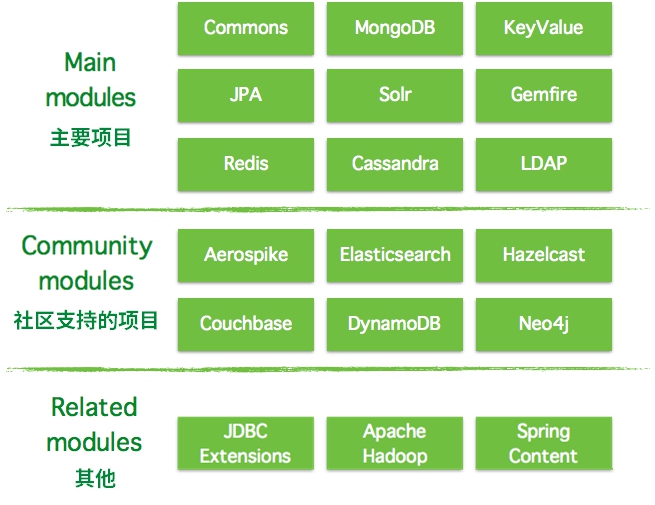
Spring Data Common 是 Spring Data 所有模塊的公共部分,該項目提供了基於 Spring 的共享基礎設施,它提供了基於 repository 接口以 DB 操作的一些封裝,以及一個堅持在 Java 實體類上標注元數據的模型。
Spring Data 不僅對傳統的數據庫訪問技術如 JDBC、Hibernate、JDO、TopLick、JPA、MyBatis 做了很好的支持和擴展、抽象、提供方便的操作方法,還對 MongoDB、KeyValue、Redis、LDAP、Cassandra 等非關系數據的 NoSQL 做了不同的實現版本,方便我們開發者觸類旁通。
下圖為目前 Spring Data 的框架分類結構圖,里面都有哪些模塊可以一目了然,也可以知道哪些是我們需要關心的項目。
Repository接口
Repository 是 Spring Data Common 里面的頂級父類接口,里面什么方法都沒有,但是如果任何接口繼承它,就能得到一個 Repository,還可以實現 JPA 的一些默認實現方法。Spring 利用 Repository 作為 DAO 操作的 Type,以及利用 Java 動態代理機制就可以實現很多功能。
package org.springframework.data.repository;
import org.springframework.stereotype.Indexed;
@Indexed
public interface Repository<T, ID> {
}
Spring 在做動態代理的時候,只要是它的子類或者實現類,再利用 T 類以及 T 類的 主鍵 ID 類型作為泛型的類型參數,就可以來標記出來、並捕獲到要使用的實體類型,就能幫助使用者進行數據庫操作。
Repository 分為以下 4 個大類:
ReactiveCrudRepository:響應式編程,主要支持當前 NoSQL 方面的操作,因為這方面大部分操作都是分布式的,所以由此我們可以看出 Spring Data 想統一數據操作的“野心”,即想提供關於所有 Data 方面的操作。目前 Reactive 主要有 Cassandra、MongoDB、Redis 的實現。RxJava2CrudRepository:為了支持 RxJava 2 做的標准響應式編程的接口。CoroutineCrudRepository:為了支持 Kotlin 語法而實現的。CrudRepository:JPA 相關的操作接口,也是我們主要用到的接口。
更詳細一點,我們需要掌握和使用到的7 大 Repository 接口如下所示:
Repository(org.springframework.data.repository),沒有暴露任何方法;CrudRepository(org.springframework.data.repository),簡單的 Curd 方法;PagingAndSortingRepository(org.springframework.data.repository),帶分頁和排序的方法;QueryByExampleExecutor(org.springframework.data.repository.query),簡單 Example 查詢;JpaRepository(org.springframework.data.jpa.repository),JPA 的擴展方法;JpaSpecificationExecutor(org.springframework.data.jpa.repository),JpaSpecification 擴展查詢;QueryDslPredicateExecutor(org.springframework.data.querydsl),QueryDsl 的封裝。
兩大 Repository 實現類:
SimpleJpaRepository(org.springframework.data.jpa.repository.support),JPA 所有接口的默認實現類;QueryDslJpaRepository(org.springframework.data.jpa.repository.support),QueryDsl 的實現類。
Defining Query Methods
Spring Data JPA 的最大特色是利用方法名定義查詢方法(Defining Query Methods)來做 CRUD 操作。
DQM 語法共有 2 種,具體如下:
- 一種是直接通過方法名就可以實現;
- 另一種是 @Query 手動在方法上定義。
定義查詢方法的配置和使用方法
若想要實現 CRUD 的操作,常規做法是寫一大堆 SQL 語句。但在 JPA 里面,只需要繼承 Spring Data Common 里面的任意 Repository 接口或者子接口,然后直接通過方法名就可以實現:
interface UserRepository extends CrudRepository<User, Long> {
User findByEmailAddress(String emailAddress);
}
方法的查詢策略設置
目前在實際生產中還沒有遇到要修改默認策略的情況,但我們必須要知道有這樣的配置方法,做到心中有數,這樣我們才能知道為什么方法名可以,@Query 也可以。通過 @EnableJpaRepositories 注解來配置方法的查詢策略,詳細配置方法如下:
@EnableJpaRepositories(queryLookupStrategy= QueryLookupStrategy.Key.CREATE_IF_NOT_FOUND)
其中,QueryLookupStrategy.Key 的值共 3 個,具體如下:
- Create:直接根據方法名進行創建,規則是根據方法名稱的構造進行嘗試,一般的方法是從方法名中刪除給定的一組已知前綴,並解析該方法的其余部分。如果方法名不符合規則,啟動的時候會報異常,這種情況可以理解為,即使配置了 @Query 也是沒有用的。
- USE_DECLARED_QUERY:聲明方式創建,啟動的時候會嘗試找到一個聲明的查詢,如果沒有找到將拋出一個異常,可以理解為必須配置 @Query。
- CREATE_IF_NOT_FOUND:這個是默認的,除非有特殊需求,可以理解為這是以上 2 種方式的兼容版。先用聲明方式(@Query)進行查找,如果沒有找到與方法相匹配的查詢,那用 Create 的方法名創建規則創建一個查詢;這兩者都不滿足的情況下,啟動就會報錯。
以 Spring Boot 項目為例,更改其配置方法如下:
@EnableJpaRepositories(queryLookupStrategy= QueryLookupStrategy.Key.CREATE_IF_NOT_FOUND)
public class Example1Application {
public static void main(String[] args) {
SpringApplication.run(Example1Application.class, args);
}
}
Defining Query Method(DQM)語法
該語法是:帶查詢功能的方法名由查詢策略(關鍵字)+ 查詢字段 + 一些限制性條件組成,具有語義清晰、功能完整的特性,我們實際工作中 80% 的 API 查詢都可以簡單實現。
下面表格是一個我們在上面 DQM 方法語法里常用的關鍵字列表:
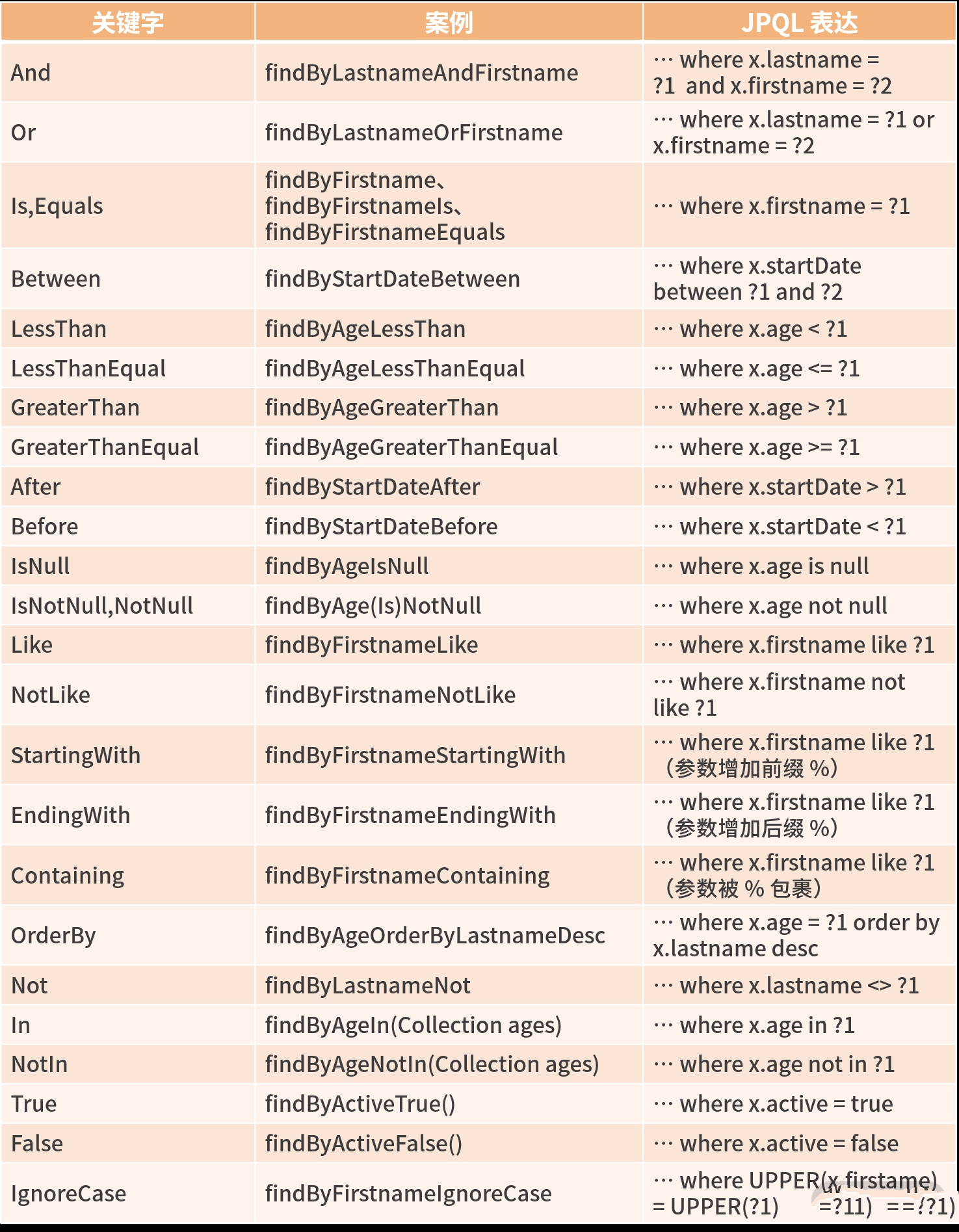
綜上,總結 3 點經驗:
- 方法名的表達式通常是實體屬性連接運算符的組合,如 And、or、Between、LessThan、GreaterThan、Like 等屬性連接運算表達式,不同的數據庫(NoSQL、MySQL)可能產生的效果不一樣,如果遇到問題,我們可以打開 SQL 日志觀察。
- IgnoreCase 可以針對單個屬性(如
findByLastnameIgnoreCase(…)),也可以針對查詢條件里面所有的實體屬性忽略大小寫(所有屬性必須在 String 情況下,如findByLastnameAndFirstnameAllIgnoreCase(…))。 - OrderBy 可以在某些屬性的排序上提供方向(Asc 或 Desc),稱為靜態排序,也可以通過一個方便的參數 Sort 實現指定字段的動態排序的查詢方法(如
repository.findAll(Sort.by(Sort.Direction.ASC, "myField")))。
我們看到上面的表格雖然大多是 find 開頭的方法,除此之外,JPA 還支持read、get、query、stream、count、exists、delete、remove等前綴,如字面意思一樣。實例代碼如下:
interface UserRepository extends CrudRepository<User, Long> {
long countByLastname(String lastname);//查詢總數
long deleteByLastname(String lastname);//根據一個字段進行刪除操作,並返回刪除行數
List<User> removeByLastname(String lastname);//根據Lastname刪除一堆User,並返回刪除的User
}
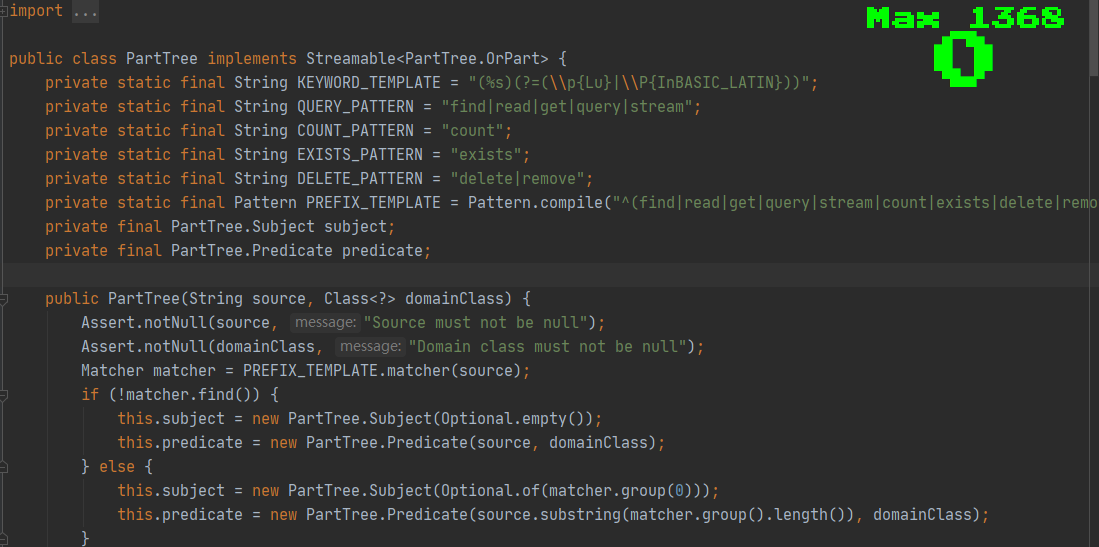
有的時候隨着版本的更新,也會有更多的語法支持,或者不同的版本語法可能也不一樣,我們通過源碼來看一下上面說的幾種語法。感興趣的同學可以到類 org.springframework.data.repository.query.parser.PartTree 查看相關源碼的邏輯和處理方法,關鍵源碼如下:
Sort 排序和 Pageable 分頁
Spring Data JPA 為了方便我們排序和分頁,支持了兩個特殊類型的參數:Sort 和 Pageable。
Pageable 是一個接口,里面有常見的分頁方法排序、當前頁、下一行、當前指針、一共多少頁、頁碼、pageSize 等。
在查詢方法中如何使用 Pageable 和 Sort 呢?下面代碼定義了根據 Lastname 查詢 User 的分頁和排序的實例,此段代碼是在 UserRepository 接口里面定義的方法:
Page<User> findByLastname(String lastname, Pageable pageable);//根據分頁參數查詢User,返回一個帶分頁結果的Page對象(方法一)
Slice<User> findByLastname(String lastname, Pageable pageable);//我們根據分頁參數返回一個Slice的user結果(方法二)
List<User> findByLastname(String lastname, Sort sort);//根據排序結果返回一個List(方法三)
List<User> findByLastname(String lastname, Pageable pageable);//根據分頁參數返回一個List對象(方法四)
我們可以通過 PageRequest 里面提供的幾個 of 靜態方法(多態),分別構建頁碼、頁面大小、排序等。
//查詢user里面的lastname=jk的第一頁,每頁大小是20條;並會返回一共有多少頁的信息
Page<User> users = userRepository.findByLastname("jk",PageRequest.of(1, 20));
//查詢user里面的lastname=jk的第一頁的20條數據,不知道一共多少條
Slice<User> users = userRepository.findByLastname("jk",PageRequest.of(1, 20));
//查詢出來所有的user里面的lastname=jk的User數據,並按照name正序返回List
List<User> users = userRepository.findByLastname("jk",new Sort(Sort.Direction.ASC, "name"))
//按照createdAt倒序,查詢前一百條User數據
List<User> users = userRepository.findByLastname("jk",PageRequest.of(0, 100, Sort.Direction.DESC, "createdAt"));
限制查詢結果 First 和 Top
有的時候我們想直接查詢前幾條數據,也不需要動態排序,那么就可以簡單地在方法名字中使用 First 和 Top 關鍵字,來限制返回條數。
我們來看看 userRepository 里面可以定義的一些限制返回結果的使用。在查詢方法上加限制查詢結果的關鍵字 First 和 Top。
User findFirstByOrderByLastnameAsc();
User findTopByOrderByAgeDesc();
List<User> findDistinctUserTop3ByLastname(String lastname, Pageable pageable);
List<User> findFirst10ByLastname(String lastname, Sort sort);
List<User> findTop10ByLastname(String lastname, Pageable pageable);
其中:
- 查詢方法在使用 First 或 Top 時,數值可以追加到 First 或 Top 后面,指定返回最大結果的大小;
- 如果數字被省略,則假設結果大小為 1;
- 限制表達式也支持 Distinct 關鍵字;
- 支持將結果包裝到 Optional 中(下一課時詳解)。
- 如果將 Pageable 作為參數,以 Top 和 First 后面的數字為准,即分頁將在限制結果中應用。
@NonNull、@NonNullApi、@Nullable
從 Spring Data 2.0 開始,JPA 新增了@NonNull @NonNullApi @Nullable,是對 null 的參數和返回結果做的支持。
- @NonNullApi:在包級別用於聲明參數,以及返回值的默認行為是不接受或產生空值的。
- @NonNull:用於不能為空的參數或返回值(在 @NonNullApi 適用的參數和返回值上不需要)。
- @Nullable:用於可以為空的參數或返回值。
Repository 中的方法返回值
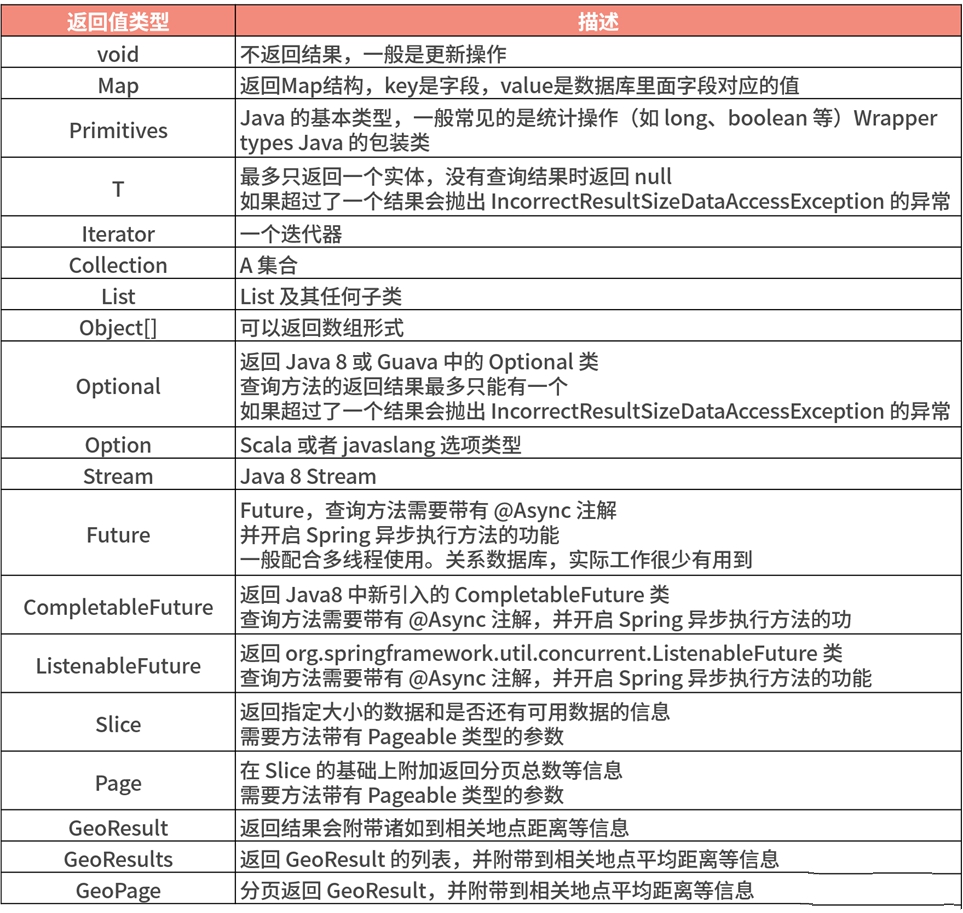
Repository 的返回類型包括:Optional、Iterable、List、Page、Long、Boolean、Entity 對象等,而實際上支持的返回類型還要多一些。
由於 Repository 里面支持 Iterable,所以其實 java 標准的 List、Set 都可以作為返回結果,並且也會支持其子類,Spring Data 里面定義了一個特殊的子類 Steamable,Streamable 可以替代 Iterable 或任何集合類型。它還提供了方便的方法來訪問 Stream,可以直接在元素上進行 ….filter(…) 和 ….map(…) 操作,並將 Streamable 連接到其他元素。
User user = userRepository.save(User.builder().name("jackxx").email("123456@126.com").sex("man").address("shanghai").build());
Assert.assertNotNull(user);
Streamable<User> userStreamable = userRepository.findAll(PageRequest.of(0,10)).and(User.builder().name("jack222").build());
userStreamable.forEach(System.out::println);
返回結果類型 List/Stream/Page/Slice
public interface UserRepository extends JpaRepository<User,Long> {
//自定義一個查詢方法,返回Stream對象,並且有分頁屬性
@Query("select u from User u")
Stream<User> findAllByCustomQueryAndStream(Pageable pageable);
//測試Slice的返回結果
@Query("select u from User u")
Slice<User> findAllByCustomQueryAndSlice(Pageable pageable);
}
異步返回結果Feature/CompletableFuture
我們可以使用 Spring 的異步方法執行Repository查詢,這意味着方法將在調用時立即返回,並且實際的查詢執行將發生在已提交給 Spring TaskExecutor 的任務中,比較適合定時任務的實際場景。異步使用起來比較簡單,直接加@Async 注解即可,如下所示:
@Async
Future<User> findByFirstname(String firstname); (1)
@Async
CompletableFuture<User> findOneByFirstname(String firstname); (2)
@Async
ListenableFuture<User> findOneByLastname(String lastname);(3)
關於實際使用需要注意以下三點內容:
- 在實際工作中,直接在 Repository 這一層使用異步方法的場景不多,一般都是把異步注解放在 Service 的方法上面,這樣的話,可以有一些額外邏輯,如發短信、發郵件、發消息等配合使用;
- 使用異步的時候一定要配置線程池,這點切記,否則“死”得會很難看;
- 萬一失敗我們會怎么處理?關於事務是怎么處理的呢?這種需要重點考慮的。
下表列出了 Spring Data JPA Query Method 機制支持的方法的返回值類型:
DTO映射 Projections
Spring JPA 對 Projections 擴展的支持,我個人覺得這是個非常好的東西,從字面意思上理解就是映射,指的是和 DB 的查詢結果的字段映射關系。一般情況下,返回的字段和 DB 的查詢結果的字段是一一對應的;但有的時候,需要返回一些指定的字段,或者返回一些復合型的字段,而不需要全部返回。
原來我們的做法是自己寫各種 entity 到 view 的各種 convert 的轉化邏輯,而 Spring Data 正是考慮到了這一點,允許對專用返回類型進行建模,有選擇地返回同一個實體的不同視圖對象。
下面還以我們的 User 查詢對象為例,看看怎么自定義返回 DTO:
@Entity
public class User {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
private String sex;
private String address;
}
看上面的原始 User 實體代碼,如果我們只想返回 User 對象里面的 name 和 email,應該怎么做?下面我們介紹三種方法。
第一種方法:新建一張表的不同 Entity
首先,我們新增一個Entity類:通過 @Table 指向同一張表,這張表和 User 實例里面的表一樣都是 user。
@Entity
@Table(name = "user")
public class UserOnlyNameEmailEntity {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
}
然后,新增一個 UserOnlyNameEmailEntityRepository,做單獨的查詢:
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserOnlyNameEmailEntityRepository extends JpaRepository<UserOnlyNameEmailEntity,Long> {
}
這種方式的好處是簡單、方便,很容易可以想到;缺點就是通過兩個實體都可以進行 update 操作,如果同一個項目里面這種實體比較多,到時候就容易不知道是誰更新的,從而導致出 bug 不好查詢,實體職責划分不明確。我們來看第二種返回 DTO 的做法。
第二種方法:直接定義一個 UserOnlyNameEmailDto
首先,我們新建一個 DTO 類來返回我們想要的字段,它是 UserOnlyNameEmailDto,用來接收 name、email 兩個字段的值,具體如下:
public class UserOnlyNameEmailDto {
private String name;
private String email;
}
其次,在 UserRepository 里面做如下用法:
public interface UserRepository extends JpaRepository<User,Long> {
//測試只返回name和email的DTO
UserOnlyNameEmailDto findByEmail(String email);
}
所以這種方式的優點就是返回的結果不需要實體對象,對 DB 不能進行除了查詢之外的任何操作;缺點就是有 set 方法還可以改變里面的值,構造方法不能更改,必須全參數,這樣如果是不熟悉 JPA 的新人操作的時候很容易引發 Bug。
第三種方法:返回結果是一個 POJO 的接口
我們再來學習一種返回不同字段的方式,這種方式與上面兩種的區別是只需要定義接口,它的好處是只讀,不需要添加構造方法,我們使用起來非常靈活,一般很難產生 Bug,那么它怎么實現呢?
首先,定義一個 UserOnlyName 的接口:
package com.example.jpa.example1;
public interface UserOnlyName {
String getName();
String getEmail();
}
其次,我們的 UserRepository 寫法如下:
package com.example.jpa.example1;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User,Long> {
/**
* 接口的方式返回DTO
* @param address
* @return
*/
UserOnlyName findByAddress(String address);
}
這個時候會發現我們的 userOnlyName 接口成了一個代理對象,里面通過 Map 的格式包含了我們的要返回字段的值(如:name、email),我們用的時候直接調用接口里面的方法即可,如 userOnlyName.getName() 即可;這種方式的優點是接口為只讀,並且語義更清晰,所以這種是我比較推薦的做法。
@Query的使用
@Query 的基本用法
public interface UserRepository extends JpaRepository<User, Long>{
/**
* JPL寫法
*/
@Query("select u from User u where u.emailAddress = ?1")
User findByEmailAddress1(String emailAddress);
/**
* Naive寫法
*/
@Query(value = "SELECT * FROM USERS WHERE EMAIL_ADDRESS = ?1", nativeQuery = true)
User findByEmailAddress2(String emailAddress);
/**
* Native排序寫法
*/
@Query(value = "select * from user_info where first_name=?1 order by ?2",nativeQuery = true)
List<UserInfoEntity> findByFirstName(String firstName,String sort);
}
@Query 的排序
@Query中在用JPQL的時候,想要實現排序,方法上直接用 PageRequest 或者 Sort 參數都可以做到。
在排序實例中,實際使用的屬性需要與實體模型里面的字段相匹配,這意味着它們需要解析為查詢中使用的屬性或別名。我們看一下例子,這是一個state_field_path_expression JPQL的定義,並且 Sort 的對象支持一些特定的函數。
public interface UserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.lastname like ?1%")
List<User> findByAndSort(String lastname, Sort sort);
@Query("select u.id, LENGTH(u.firstname) as fn_len from User u where u.lastname like ?1%")
List<Object[]> findByAsArrayAndSort(String lastname, Sort sort);
}
@Query 的分頁
@Query 的分頁分為兩種情況,分別為 JQPl 的排序和 nativeQuery 的排序。看下面的案例。
直接用 Page 對象接受接口,參數直接用 Pageable 的實現類即可。
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "select u from User u where u.lastname = ?1")
Page<User> findByLastname(String lastname, Pageable pageable);
}
//調用者的寫法
repository.findByFirstName("jackzhang",new PageRequest(1,10));
@Query 對原生 SQL 的分頁支持,並不是特別友好,因為這種寫法比較“駭客”,可能隨着版本的不同會有所變化。我們以 MySQL 為例。
public interface UserRepository extends JpaRepository<UserInfoEntity, Integer>, JpaSpecificationExecutor<UserInfoEntity> {
@Query(value = "select * from user_info where first_name=?1 /* #pageable# */",
countQuery = "select count(*) from user_info where first_name=?1",
nativeQuery = true)
Page<UserInfoEntity> findByFirstName(String firstName, Pageable pageable);
}
//調用者的寫法
return userRepository.findByFirstName("jackzhang",new PageRequest(1,10, Sort.Direction.DESC,"last_name"));
//打印出來的sql
select * from user_info where first_name=? /* #pageable# */ order by last_name desc limit ?, ?
這里需要注意:這個注釋 /* #pageable# */ 必須有。
另外,隨着版本的變化,這個方法有可能會進行優化。此外還有一種實現方法,就是自己寫兩個查詢方法,自己手動分頁。
@Param 用法
@Param 注解指定方法參數的具體名稱,通過綁定的參數名字指定查詢條件,這樣不需要關心參數的順序。我比較推薦這種做法,因為它比較利於代碼重構。如果不用 @Param 也是可以的,參數是有序的,這使得查詢方法對參數位置的重構容易出錯。我們看個案例。
根據 firstname 和 lastname 參數查詢 user 對象。
public interface UserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.firstname = :firstname or u.lastname = :lastname")
User findByLastnameOrFirstname(@Param("lastname") String lastname,
@Param("firstname") String firstname);
}
@Query整合DTO映射 Projections
首先,新增一個 UserSimpleDto 接口來得到我們想要的 name、email、idCard 信息。
package com.example.jpa.example1;
public interface UserSimpleDto {
String getName();
String getEmail();
String getIdCard();
}
其次,在 UserDtoRepository 里面新增一個方法,返回結果是 UserSimpleDto 接口。
public interface UserDtoRepository extends JpaRepository<User, Long> {
//利用接口DTO獲得返回結果,需要注意的是每個字段需要as和接口里面的get方法名字保持一樣
@Query("select CONCAT(u.name,'JK123') as name,UPPER(u.email) as email ,e.idCard as idCard from User u,UserExtend e where u.id= e.userId and u.id=:id")
UserSimpleDto findByUserSimpleDtoId(@Param("id") Long id);
}
比起 DTO 我們不需要 new 了,並且接口只能讀,那么我們返回的結果 DTO 的職責就更單一了,只用來查詢。
接口的方式是我比較推薦的做法,因為它是只讀的,對構造方法沒有要求,返回的實際是 HashMap。
@Query 動態查詢解決方法
我們看一個例子,來了解一下如何實現 @Query 的動態參數查詢。
首先,新增一個 UserOnlyName 接口,只查詢 User 里面的 name 和 email 字段。
package com.example.jpa.example1;
//獲得返回結果
public interface UserOnlyName {
String getName();
String getEmail();
}
其次,在我們的 UserDtoRepository 里面新增兩個方法:一個是利用 JPQL 實現動態查詢,一個是利用原始 SQL 實現動態查詢。
package com.example.jpa.example1;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface UserDtoRepository extends JpaRepository<User, Long> {
/**
* 利用JQPl動態查詢用戶信息
* @param name
* @param email
* @return UserSimpleDto接口
*/
@Query("select u.name as name,u.email as email from User u where (:name is null or u.name =:name) and (:email is null or u.email =:email)")
UserOnlyName findByUser(@Param("name") String name,@Param("email") String email);
/**
* 利用原始sql動態查詢用戶信息
* @param user
* @return
*/
@Query(value = "select u.name as name,u.email as email from user u where (:#{#user.name} is null or u.name =:#{#user.name}) and (:#{#user.email} is null or u.email =:#{#user.email})",nativeQuery = true)
UserOnlyName findByUser(@Param("user") User user);
}
我們知道定義方法名可以獲得想要的結果,@Query 注解亦可以獲得想要的結果,nativeQuery 也可以獲得想要的結果,那么我們該如何做選擇呢?下面我從個人經驗中總結了一些觀點。
- 能用方法名表示的,盡量用方法名表示,因為這樣語義清晰、簡單快速,基本上只要編譯通過,一定不會有問題;
- 能用 @Query 里面的 JPQL 表示的,就用 JPQL,這樣與 SQL 無關,萬一哪天換數據庫了,基本上代碼不用改變;
- 最后實在沒有辦法了,可以選擇 nativeQuery 寫原始 SQL,特別是一開始從 MyBatis 轉過來的同學,選擇寫 SQL 會更容易一些。
JPA的注解
JPA 協議里面關於實體有如下定義,(這里推薦一個查看 JPA 協議的官方地址:https://download.oracle.com/otn-pub/jcp/persistence-2_2-mrel-spec/JavaPersistence.pdf):
-
實體是直接進行數據庫持久化操作的領域對象(即一個簡單的 POJO,可以按照業務領域划分),必須通過 @Entity 注解進行標示。
-
實體必須有一個 public 或者 protected 的無參數構造方法。
-
Entity 里面的注解生效只有兩種方式:將注解寫在字段上或者將注解寫在方法上(JPA 里面稱 Property)。
需要注意的是,在同一個 Entity 里面只能有一種方式生效,也就是說,注解要么全部寫在 field 上面,要么就全部寫在 Property 上面。
JPA 里面支持的注解大概有一百多個,這里只提及一些最常見的,包括 @Entity、@Table、@Access、@Id、@GeneratedValue、@Enumerated、@Basic、@Column、@Transient、@Lob、@Temporal 等。
@Entity
用於定義對象將會成為被 JPA 管理的實體,必填,將字段映射到指定的數據庫表中,使用起來很簡單,直接用在實體類上面即可,通過源碼表達的語法如下:
@Target(TYPE) //表示此注解只能用在class上面
public @interface Entity {
//可選,默認是實體類的名字,整個應用里面全局唯一。
String name() default "";
}
@Table
用於指定數據庫的表名,表示此實體對應的數據庫里面的表名,非必填,默認表名和 entity 名字一樣。
@Target(TYPE) //一樣只能用在類上面
public @interface Table {
//表的名字,可選。如果不填寫,系統認為好實體的名字一樣為表名。
String name() default "";
//此表所在schema,可選
String schema() default "";
//唯一性約束,在創建表的時候有用,表創建之后后面就不需要了。
UniqueConstraint[] uniqueConstraints() default { };
//索引,在創建表的時候使用,表創建之后后面就不需要了。
Index[] indexes() default {};
}
@Access
用於指定 entity 里面的注解是寫在字段上面,還是 get/set 方法上面生效,非必填。在默認不填寫的情況下,當實體里面的第一個注解出現在字段上或者 get/set 方法上面,就以第一次出現的方式為准。
@Id
定義屬性為數據庫的主鍵,一個實體里面必須有一個主鍵,但不一定是這個注解,可以和 @GeneratedValue 配合使用或成對出現。
@GeneratedValue
主鍵生成策略。
@Enumerated
這個注解很好用,因為它對 enum 提供了下標和 name 兩種方式,用法直接映射在 enum 枚舉類型的字段上。
@Basic
表示屬性是到數據庫表的字段的映射。如果實體的字段上沒有任何注解,默認即為 @Basic。也就是說默認所有的字段肯定是和數據庫進行映射的,並且默認為 Eager 類型(EAGER(默認):立即加載;LAZY:延遲加載。(LAZY主要應用在大字段上面))。
@Transient
表示該屬性並非一個到數據庫表的字段的映射,表示非持久化屬性。JPA 映射數據庫的時候忽略它,與 @Basic 有相反的作用。也就是每個字段上面 @Transient 和 @Basic 必須二選一,而什么都不指定的話,默認是 @Basic。
@Column
定義該屬性對應數據庫中的列名。
@Temporal
用來設置 Date 類型的屬性映射到對應精度的字段,存在以下三種情況:
@Temporal(TemporalType.DATE) //映射為日期date (只有日期)
@Temporal(TemporalType.TIME) //映射為日期time (只有時間)
@Temporal(TemporalType.TIMESTAMP) //映射為日期date time (日期+時間)
IDEA生成實體
打開 Persistence 視圖,點擊 Generate Persistence Mapping>,接着點擊選中數據源,然后,選擇表和字段,並點擊 OK。
這樣就可以生成我們想要的實體了。如果是新庫、新表,我們也可以先定義好實體,通過實體配置JPA的 spring.jpa.generate-ddl=true,反向直接生成 DDL 操作數據庫生成表結構。
聯合主鍵
在實際的工作中,我們會經常遇到聯合主鍵的情況。可以通過 javax.persistence.EmbeddedId 和 javax.persistence.IdClass 兩個注解實現聯合主鍵的效果。
public class UserInfoID implements Serializable {
private String name,telephone;
}
@Entity
@IdClass(UserInfoID.class)
public class UserInfo {
private Integer ages;
@Id
private String name;
@Id
private String telephone;
}
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserInfoRepository extends JpaRepository<UserInfo,UserInfoID> {
}
@Embeddable 與 @EmbeddedId 注解同樣可以做到聯合主鍵的效果。
@Embeddable
public class UserInfoID implements Serializable {
private String name,telephone;
}
@Entity
public class UserInfo {
private Integer ages;
@EmbeddedId
private UserInfoID userInfoID;
@Column(unique = true)
private String uniqueNumber;
}
@IdClass 和 @EmbeddedId 的區別是什么?有以下兩個方面:
- 如上面測試用例,在使用的時候,Embedded 用的是對象,而 IdClass 用的是具體的某一個字段;
- 二者的JPQL 也會不一樣:
① 用 @IdClass JPQL 的寫法:SELECT u.name FROM UserInfo u
② 用 @EmbeddedId 的 JPQL 的寫法:select u.userInfoId.name FROM UserInfo u
聯合主鍵還有需要注意的就是,它與唯一性索引約束的區別是寫法不同,如上面所講,唯一性索引的寫法如下:
@Column(unique = true)
private String uniqueNumber;
實體之間的繼承關系
會使得表與實體之間的關系變得復雜不直觀,不建議使用。
在 Java 面向對象的語言環境中,@Entity 之間的關系多種多樣,而根據 JPA 的規范,我們大致可以將其分為以下幾種:
- 純粹的繼承,和表沒關系,對象之間的字段共享。利用注解 @MappedSuperclass,協議規定父類不能是 @Entity。
- 單表多態問題,同一張 Table,表示了不同的對象,通過一個字段來進行區分。利用
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)注解完成,只有父類有 @Table。 - 多表多態,每一個子類一張表,父類的表擁有所有公用字段。通過
@Inheritance(strategy = InheritanceType.JOINED)注解完成,父類和子類都是表,有公用的字段在父表里面。 - Object 的繼承,數據庫里面每一張表是分開的,相互獨立不受影響。通過
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)注解完成,父類(可以是一張表,也可以不是)和子類都是表,相互之間沒有關系。
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
父類實體對象與各個子實體對象共用一張表,通過一個字段的不同值代表不同的對象,我們看一個例子。
@Inheritance(strategy = InheritanceType.JOINED)
在這種映射策略里面,繼承結構中的每一個實體(entity)類都會映射到數據庫里一個單獨的表中。也就是說,每個實體(entity)都會被映射到數據庫中,一個實體(entity)類對應數據庫中的一個表。
其中根實體(root entity)對應的表中定義了主鍵(primary key),所有的子類對應的數據庫表都要共同使用 Book 里面的 @ID 這個主鍵。
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
我們在使用 @MappedSuperClass 主鍵的時候,如果不指定 @Inhertance,默認就是此種TABLE_PER_CLASS模式。當然了,我們也顯示指定,要求繼承基類的都是一張表,而父類不是表,是 java 對象的抽象類。
高級用法與實戰
JpaSpecificationExecutor
QueryByExampleExecutor用法
QueryByExampleExecutor(QBE)是一種用戶友好的查詢技術,具有簡單的接口,它允許動態查詢創建,並且不需要編寫包含字段名稱的查詢。
下面是一個 UML 圖,你可以看到 QueryByExampleExecutor 是 JpaRepository 的父接口,也就是 JpaRespository 里面繼承了 QueryByExampleExecutor 的所有方法。
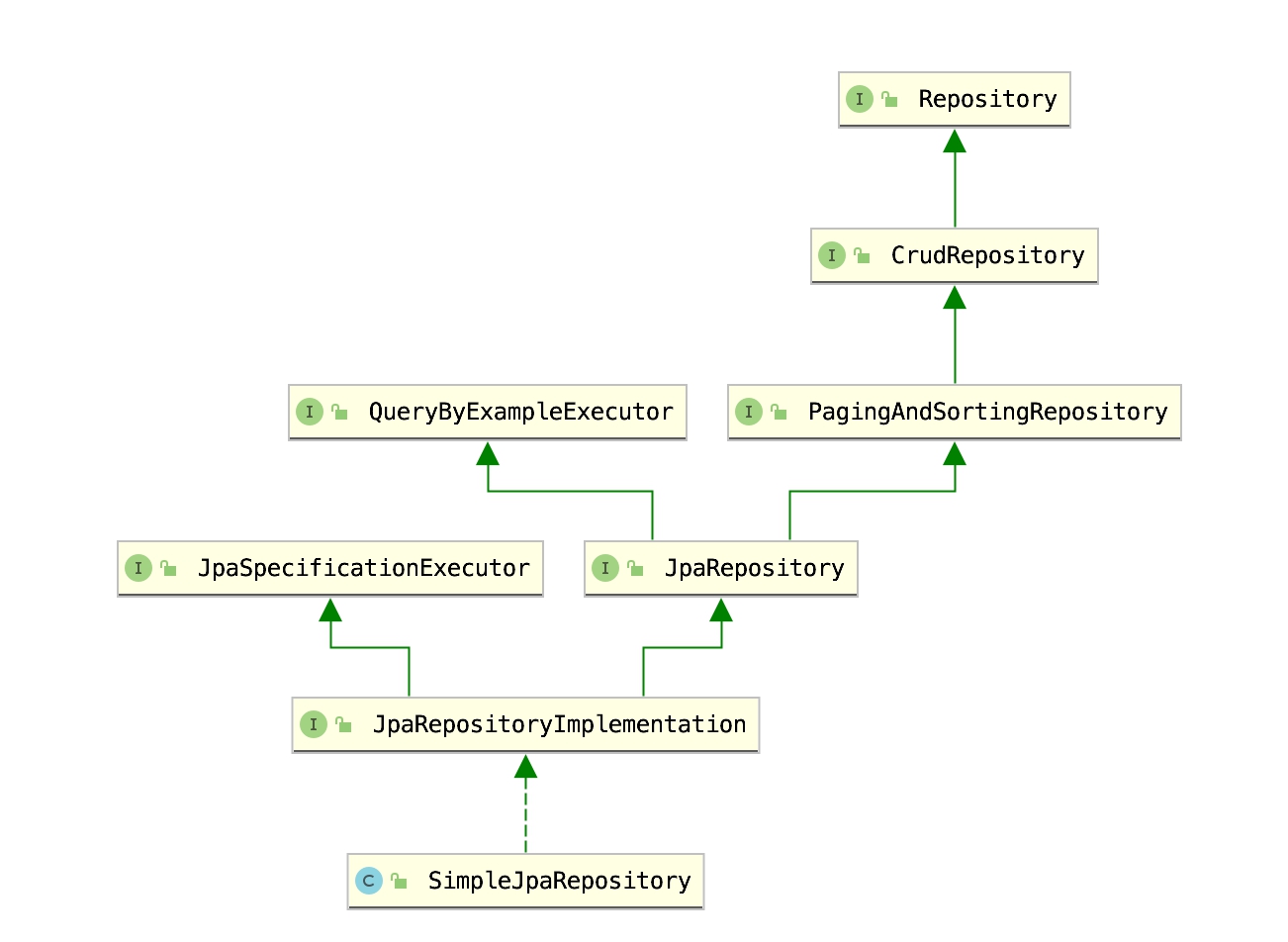
QBE 的基本語法可以分為下述幾種。
public interface QueryByExampleExecutor<T> {
//根據“實體”查詢條件,查找一個對象
<S extends T> S findOne(Example<S> example);
//根據“實體”查詢條件,查找一批對象
<S extends T> Iterable<S> findAll(Example<S> example);
//根據“實體”查詢條件,查找一批對象,可以指定排序參數
<S extends T> Iterable<S> findAll(Example<S> example, Sort sort);
//根據“實體”查詢條件,查找一批對象,可以指定排序和分頁參數
<S extends T> Page<S> findAll(Example<S> example, Pageable pageable);
//根據“實體”查詢條件,查找返回符合條件的對象個數
<S extends T> long count(Example<S> example);
//根據“實體”查詢條件,判斷是否有符合條件的對象
<S extends T> boolean exists(Example<S> example);
}
這里寫一個測試用例,來熟悉一下 QBE 的語法,看一下完整的測試用例的寫法:
@DataJpaTest
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class UserAddressRepositoryTest {
@Autowired
private UserAddressRepository userAddressRepository;
@Test
@Rollback(false)
public void testQBEFromUserAddress() throws JsonProcessingException {
User request = User.builder()
.name("jack").age(20).email("12345")
.build();
UserAddress address = UserAddress.builder().address("shang").user(request).build();
ObjectMapper objectMapper = new ObjectMapper();
// System.out.println(objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(address)); //可以打印出來看看參數是什么
//創建匹配器,即如何使用查詢條件
ExampleMatcher exampleMatcher = ExampleMatcher.matching()
.withMatcher("user.email", ExampleMatcher.GenericPropertyMatchers.startsWith())
.withMatcher("address", ExampleMatcher.GenericPropertyMatchers.startsWith());
Page<UserAddress> u = userAddressRepository.findAll(Example.of(address,exampleMatcher), PageRequest.of(0,2));
System.out.println(objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(u));
}
}
JpaSpecificationExecutor 使用案例
我們假設一個后台管理頁面根據 name 模糊查詢、sex 精准查詢、age 范圍查詢、時間區間查詢、address 的 in 查詢這樣一個場景,來查詢 user 信息,我們看看這個例子應該怎么寫。
@DataJpaTest
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class UserJpeTest {
@Autowired
private UserRepository userRepository;
@Autowired
private UserAddressRepository userAddressRepository;
private Date now = new Date();
@Test
public void testSPE() {
//模擬請求參數
User userQuery = User.builder()
.name("jack")
.email("123456@126.com")
.sex(SexEnum.BOY)
.age(20)
.addresses(Lists.newArrayList(UserAddress.builder().address("shanghai").build()))
.build();
//假設的時間范圍參數
Instant beginCreateDate = Instant.now().plus(-2, ChronoUnit.HOURS);
Instant endCreateDate = Instant.now().plus(1, ChronoUnit.HOURS);
//利用Specification進行查詢
Page<User> users = userRepository.findAll(new Specification<User>() {
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
List<Predicate> ps = new ArrayList<Predicate>();
if (StringUtils.isNotBlank(userQuery.getName())) {
//我們模仿一下like查詢,根據name模糊查詢
ps.add(cb.like(root.get("name"),"%" +userQuery.getName()+"%"));
}
if (userQuery.getSex()!=null){
//equal查詢條件,這里需要注意,直接傳遞的是枚舉
ps.add(cb.equal(root.get("sex"),userQuery.getSex()));
}
if (userQuery.getAge()!=null){
//greaterThan大於等於查詢條件
ps.add(cb.greaterThan(root.get("age"),userQuery.getAge()));
}
if (beginCreateDate!=null&&endCreateDate!=null){
//根據時間區間去查詢創建
ps.add(cb.between(root.get("createDate"),beginCreateDate,endCreateDate));
}
if (!ObjectUtils.isEmpty(userQuery.getAddresses())) {
//聯表查詢,利用root的join方法,根據關聯關系表里面的字段進行查詢。
ps.add(cb.in(root.join("addresses").get("address")).value(userQuery.getAddresses().stream().map(a->a.getAddress()).collect(Collectors.toList())));
}
return query.where(ps.toArray(new Predicate[ps.size()])).getRestriction();
}
}, PageRequest.of(0, 2));
System.out.println(users);
}
}
我們看一下生成的HQL:
select user0_.id as id1_1_, user0_.age as age2_1_, user0_.create_date as create_d3_1_, user0_.email as email4_1_, user0_.name as name5_1_, user0_.sex as sex6_1_, user0_.update_date as update_d7_1_ from user user0_ inner join user_address addresses1_ on user0_.id=addresses1_.user_id where (user0_.name like ?) and user0_.sex=? and user0_.age>20 and (user0_.create_date between ? and ?) and (addresses1_.address in (?)) limit ?
JpaSpecificationExecutor 實戰應用場景
其實JpaSpecificationExecutor 的目的不是讓我們做日常的業務查詢,而是給我們提供了一種自定義 Query for rest 的架構思路,如果做日常的增刪改查,肯定不如我們前面介紹的 Defining Query Methods 和 @Query 方便。
JpaSpecificationExecutor 解決了哪些問題
- 我們通過 QueryByExampleExecutor 的使用方法和原理分析,不難發現,JpaSpecificationExecutor 的查詢條件 Specification 十分靈活,可以幫我們解決動態查詢條件的問題,正如 QueryByExampleExecutor 的用法一樣;
- 它提供的 Criteria API 的使用封裝,可以用於動態生成 Query 來滿足我們業務中的各種復雜場景;
- 既然QueryByExampleExecutor 能利用 Specification 封裝成框架,我們是不是也可以利用 JpaSpecificationExecutor 封裝成框架呢?這樣就學會了舉一反三。
JPA 的審計功能
Auditing 是幫我們做審計用的,當我們操作一條記錄的時候,需要知道這是誰創建的、什么時間創建的、最后修改人是誰、最后修改時間是什么時候,甚至需要修改記錄……這些都是 Spring Data JPA 里面的 Auditing 支持的,它為我們提供了四個注解來完成上面說的一系列事情,如下:
- @CreatedBy 是哪個用戶創建的。
- @CreatedDate 創建的時間。
- @LastModifiedBy 最后修改實體的用戶。
- @LastModifiedDate 最后一次修改的時間。
利用上面的四個注解實現方法,一共有三種方式實現 Auditing,我們分別看看。
第一種方式:直接在實例里面添加上述四個注解
第一步:在 @Entity:User 里面添加四個注解,並且新增 @EntityListeners(AuditingEntityListener.class) 注解。
添加完之后,User 的實體代碼如下:
@Entity
@EntityListeners(AuditingEntityListener.class)
public class User implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
@CreatedBy
private Integer createUserId;
@CreatedDate
private Date createTime;
@LastModifiedBy
private Integer lastModifiedUserId;
@LastModifiedDate
private Date lastModifiedTime;
}
第二步:實現 AuditorAware 接口,告訴 JPA 當前的用戶是誰。
我們需要實現 AuditorAware 接口,以及 getCurrentAuditor 方法,並返回一個 Integer 的 user ID。
public class MyAuditorAware implements AuditorAware<Integer> {
//需要實現AuditorAware接口,返回當前的用戶ID
@Override
public Optional<Integer> getCurrentAuditor() {
ServletRequestAttributes servletRequestAttributes =
(ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
Integer userId = (Integer) servletRequestAttributes.getRequest().getSession().getAttribute("userId");
return Optional.ofNullable(userId);
}
}
這里關鍵的一步,是實現 AuditorAware 接口的方法,如下所示:
public interface AuditorAware<T> {
T getCurrentAuditor();
}
需要注意的是:這里獲得用戶 ID 的方法不止這一種,實際工作中,我們可能將當前的 user 信息放在 Session 中,可能把當前信息放在 Redis 中,也可能放在 Spring 的 security 里面管理。
第三步:通過 @EnableJpaAuditing 注解開啟 JPA 的 Auditing 功能。
第三步是最重要的一步,如果想使上面的配置生效,我們需要開啟 JPA 的 Auditing 功能(默認沒開啟)。這里需要用到的注解是 @EnableJpaAuditing。
@Inherited
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Import(JpaAuditingRegistrar.class)
public @interface EnableJpaAuditing {
//auditor用戶的獲取方法,默認是找AuditorAware的實現類;
String auditorAwareRef() default "";
//是否在創建修改的時候設置時間,默認是true
boolean setDates() default true;
//在創建的時候是否同時作為修改,默認是true
boolean modifyOnCreate() default true;
//時間的生成方法,默認是取當前時間(為什么提供這個功能呢?因為測試的時候有可能希望時間保持不變,它提供了一種自定義的方法);
String dateTimeProviderRef() default "";
}
@Configuration
@EnableJpaAuditing
public class JpaConfiguration {
@Bean
@ConditionalOnMissingBean(name = "myAuditorAware")
MyAuditorAware myAuditorAware() {
return new MyAuditorAware();
}
}
第二種方式:實體里面實現Auditable 接口
我們改一下上面的 User 實體對象,如下:
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "addresses")
@EntityListeners(AuditingEntityListener.class)
public class User implements Auditable<Integer,Long, Instant> {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
@Enumerated(EnumType.STRING)
private SexEnum sex;
private Integer age;
@OneToMany(mappedBy = "user")
@JsonIgnore
private List<UserAddress> addresses;
private Boolean deleted;
private Integer createUserId;
private Instant createTime;
private Integer lastModifiedUserId;
private Instant lastModifiedTime;
@Override
public Optional<Integer> getCreatedBy() {
return Optional.ofNullable(this.createUserId);
}
@Override
public void setCreatedBy(Integer createdBy) {
this.createUserId = createdBy;
}
@Override
public Optional<Instant> getCreatedDate() {
return Optional.ofNullable(this.createTime);
}
@Override
public void setCreatedDate(Instant creationDate) {
this.createTime = creationDate;
}
@Override
public Optional<Integer> getLastModifiedBy() {
return Optional.ofNullable(this.lastModifiedUserId);
}
@Override
public void setLastModifiedBy(Integer lastModifiedBy) {
this.lastModifiedUserId = lastModifiedBy;
}
@Override
public void setLastModifiedDate(Instant lastModifiedDate) {
this.lastModifiedTime = lastModifiedDate;
}
@Override
public Optional<Instant> getLastModifiedDate() {
return Optional.ofNullable(this.lastModifiedTime);
}
@Override
public boolean isNew() {
return id==null;
}
}
與第一種方式的差異是,這里我們要去掉上面說的四個注解,並且要實現接口 Auditable 的方法,代碼會變得很冗余和啰唆,從代碼的復雜程度來看,這種方式我不推薦使用。
第三種方式:利用 @MappedSuperclass 注解
第一步:創建一個 BaseEntity,里面放一些實體的公共字段和注解。
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
public class BaseEntity {
@CreatedBy
private Integer createUserId;
@CreatedDate
private Instant createTime;
@LastModifiedBy
private Integer lastModifiedUserId;
@LastModifiedDate
private Instant lastModifiedTime;
}
注意: BaseEntity里面需要用上面提到的四個注解,並且加上@EntityListeners(AuditingEntityListener.class),這樣所有的子類就不需要加了。
第二步:實體直接繼承 BaseEntity 即可。
我們修改一下上面的 User 實例繼承 BaseEntity,代碼如下:
@Entity
public class User extends BaseEntity {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private Boolean deleted;
}
這樣的話,User 實體就不需要關心太多,我們只關注自己需要的邏輯即可。這種方式,是我最推薦的,也是實際工作中使用最多的一種方式。它的好處顯而易見就是公用性強,代碼簡單,需要關心的少。
JPA 的審計功能解決了哪些問題?
-
可以很容易地讓我們寫自己的 BaseEntity,把一些公共的字段放在里面,不需要我們關心太多和業務無關的字段,更容易讓我們公司的表更加統一和規范。
實際工作中,BaseEntity 可能還更復雜一點,比如說把 ID 和 @Version 加進去,會變成如下形式:
@Data @MappedSuperclass @EntityListeners(AuditingEntityListener.class) public class BaseEntity { @Id @GeneratedValue(strategy= GenerationType.AUTO) private Long id; @CreatedBy private Integer createUserId; @CreatedDate private Instant createTime; @LastModifiedBy private Integer lastModifiedUserId; @LastModifiedDate private Instant lastModifiedTime; @Version private Integer version; } -
Auditing 在實戰應用場景中,比較適合做后台管理項目,對應純粹的 RestAPI 項目,提供給用戶直接查詢的 API 的話,可以考慮一個特殊的 UserID。
Auditing 的實現原理
JPA的審計功能利用了 Java Persistence API 里面的@PrePersist、@PreUpdate 回調函數,在更新和創建之前通過AuditingHandler 添加了用戶信息和時間信息。
@Entity 的回調方法
JPA 協議里面規定,可以通過一些注解,為其監聽回調事件、指定回調方法。下面我整理了一個回調事件注解表,分別列舉了 @PrePersist、@PostPersist、@PreRemove、@PostRemove、@PreUpdate、@PostUpdate、@PostLoad注解及其概念。
回調事件注解表
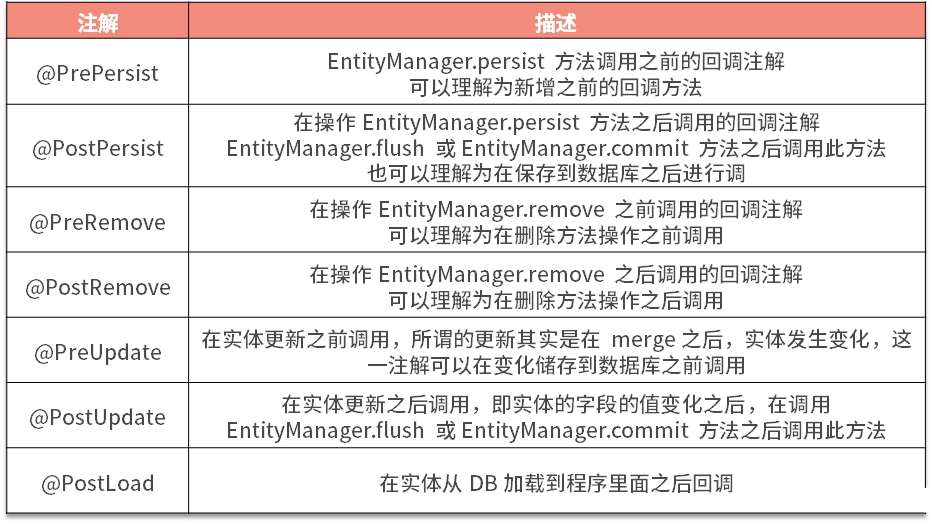
語法注意事項
關於上表所述的幾個方法有一些需要注意的地方,如下:
- 回調函數都是和 EntityManager.flush 或 EntityManager.commit 在同一個線程里面執行的,只不過調用方法有先后之分,都是同步調用,所以當任何一個回調方法里面發生異常,都會觸發事務進行回滾,而不會觸發事務提交。
- Callbacks 注解可以放在實體里面,可以放在 super-class 里面,也可以定義在 entity 的 listener 里面,但需要注意的是:放在實體(或者 super-class)里面的方法,簽名格式為“void ()”,即沒有參數,方法里面操作的是 this 對象自己;放在實體的 EntityListener 里面的方法簽名格式為“void (Object)”,也就是方法可以有參數,參數是代表用來接收回調方法的實體。
- 使上述注解生效的回調方法可以是 public、private、protected、friendly 類型的,但是不能是 static 和 final 類型的方法。
JPA 里面規定的回調方法還有一些,但不常用,就不過多介紹了。接下來,我們看一下回調注解在實體里面是如何使用的。
JPA Callbacks 的使用方法
第一種用法:在實體和 super-class 中使用
第一步:修改 BaseEntity,在里面新增回調函數和注解,代碼如下:
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
public class BaseEntity {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
// @CreatedBy 這個可能會被 AuditingEntityListener覆蓋,為了方便測試,我們先注釋掉
private Integer createUserId;
@CreatedDate
private Instant createTime;
@LastModifiedBy
private Integer lastModifiedUserId;
@LastModifiedDate
private Instant lastModifiedTime;
// @Version 由於本身有樂觀鎖機制,這個我們測試的時候先注釋掉,改用手動設置的值;
private Integer version;
@PreUpdate
public void preUpdate() {
System.out.println("preUpdate::"+this.toString());
this.setCreateUserId(200);
}
@PostUpdate
public void postUpdate() {
System.out.println("postUpdate::"+this.toString());
}
@PreRemove
public void preRemove() {
System.out.println("preRemove::"+this.toString());
}
@PostRemove
public void postRemove() {
System.out.println("postRemove::"+this.toString());
}
@PostLoad
public void postLoad() {
System.out.println("postLoad::"+this.toString());
}
}
上述代碼中,我在類里面使用了@PreUpdate、@PostUpdate、@PreRemove、@PostRemove、@PostLoad 幾個注解,並在相應的回調方法里面加了相應的日志。
第二步:修改一下 User 類,也新增兩個回調函數,並且和 BaseEntity 做法一樣,代碼如下:
@Entity
public class User extends BaseEntity {// implements Auditable<Integer,Long, Instant> {
private String name;
private String email;
@Enumerated(EnumType.STRING)
private SexEnum sex;
private Integer age;
@OneToMany(mappedBy = "user")
@JsonIgnore
private List<UserAddress> addresses;
private Boolean deleted;
@PrePersist
private void prePersist() {
System.out.println("prePersist::"+this.toString());
this.setVersion(1);
}
@PostPersist
public void postPersist() {
System.out.println("postPersist::"+this.toString());
}
}
我在其中使用了 @PrePersist、@PostPersist 回調事件。
然后通過JPA調用進行測試,可以發現響應的回調函數被觸發了。
第二種用法:自定義 EntityListener
第一步:自定義一個 EntityLoggingListener 用來記錄操作日志,通過 listener 的方式配置回調函數注解,代碼如下:
@Log4j2
public class EntityLoggingListener {
@PrePersist
private void prePersist(BaseEntity entity) {
//entity.setVersion(1); 如果注釋了,測試用例這個地方的驗證也需要去掉
log.info("prePersist::{}",entity.toString());
}
@PostPersist
public void postPersist(Object entity) {
log.info("postPersist::{}",entity.toString());
}
@PreUpdate
public void preUpdate(BaseEntity entity) {
//entity.setCreateUserId(200); 如果注釋了,測試用例這個地方的驗證也需要去掉
log.info("preUpdate::{}",entity.toString());
}
@PostUpdate
public void postUpdate(Object entity) {
log.info("postUpdate::{}",entity.toString());
}
@PreRemove
public void preRemove(Object entity) {
log.info("preRemove::{}",entity.toString());
}
@PostRemove
public void postRemove(Object entity) {
log.info("postRemove::{}",entity.toString());
}
@PostLoad
public void postLoad(Object entity) {
//查詢方法里面可以對一些敏感信息做一些日志
if (User.class.isInstance(entity)) {
log.info("postLoad::{}",entity.toString());
}
}
}
在這一步驟中需要注意的是:
- 我們上面注釋的代碼,也可以改變 entity 里面的值,但是在這個 Listener 的里面我們不做修改,所以把 setVersion 和 setCreateUserId 注釋掉了,要注意測試用例里面這兩處也需要修改。
- 如果在 @PostLoad 里面記錄日志,不一定每個實體、每次查詢都需要記錄日志,只需要對一些敏感的實體或者字段做日志記錄即可。
- 回調函數時我們可以加上參數,這個參數可以是父類 Object,可以是 BaseEntity,也可以是具體的某一個實體;我推薦用 BaseEntity,因為這樣的方法是類型安全的,它可以約定一些框架邏輯,比如 getCreateUserId、getLastModifiedUserId 等。
第二步:還是一樣的道理,寫一個測試用例跑一下。
JPA Callbacks 的最佳實踐
我以個人經驗總結了幾個最佳實踐。
-
回調函數里面應盡量避免直接操作業務代碼,最好用一些具有框架性的公用代碼,如上一課時我們講的 Auditing,以及本課時前面提到的實體操作日志等;
-
注意回調函數方法要在同一個事務中進行,異常要可預期,非可預期的異常要進行捕獲,以免出現意想不到的線上 Bug;
-
回調函數方法是同步的,如果一些計算量大的和一些耗時的操作,可以通過發消息等機制異步處理,以免阻塞主流程,影響接口的性能;
-
在回調函數里面,盡量不要直接在操作 EntityManager 后再做 session 的整個生命周期的其他持久化操作,以免破壞事務的處理流程;也不要進行其他額外的關聯關系更新動作,業務性的代碼一定要放在 service 層面,否則太過復雜,時間長了代碼很難維護;
-
回調函數里面比較適合用一些計算型的transient方法,如下面這個操作:
public class UserListener { @PrePersist public void prePersist(User user) { //通過一些邏輯計算年齡; user.calculationAge(); } } -
JPA 官方比較建議放一些默認值,但是我不是特別贊同,因為覺得那樣不夠直觀,我們直接用字段初始化就可以了,沒必要在回調函數里面放置默認值。
樂觀鎖和重試機制
樂觀鎖和重試其實不是Spring Data Jpa的功能,這里結合Spring Data Jpa說明使用方法。
Spring 全家桶里面提供了@Retryable 的注解,會幫我們進行重試。下面看一個 @Retryable 的例子。
第一步:利用 gradle 引入 spring-retry 的依賴 jar,如下所示:
implementation 'org.springframework.retry:spring-retry'
第二步:在 UserInfoserviceImpl 的方法中添加 @Retryable 注解,就可以實現重試的機制了
第三步:新增一個RetryConfiguration並添加@EnableRetry 注解,是為了開啟重試機制,使 @Retryable 生效。
@EnableRetry
@Configuration
public class RetryConfiguration {
}
通過案例你會發現 Retry 的邏輯其實很簡單,只需要利用 @Retryable 注解即可。
下面對常用的 @Retryable 注解中的參數做一下說明:
-
maxAttempts:最大重試次數,默認為 3,如果要設置的重試次數為 3,可以不寫;
-
value:拋出指定異常才會重試;
-
include:和 value 一樣,默認為空,當 exclude 也為空時,默認異常;
-
exclude:指定不處理的異常;
-
backoff:重試等待策略,默認使用 @Backoff的 value,默認為 1s。
其中:
-
value=delay:隔多少毫秒后重試,默認為 1000L,單位是毫秒;
-
multiplier(指定延遲倍數)默認為 0,表示固定暫停 1 秒后進行重試,如果把 multiplier 設置為 1.5,則第一次重試為 2 秒,第二次為 3 秒,第三次為 4.5 秒。
下面是一個關於 @Retryable 擴展的使用例子,具體看一下代碼:
@Service
public interface MyService {
@Retryable( value = SQLException.class, maxAttempts = 2, backoff = @Backoff(delay = 100))
void retryServiceWithCustomization(String sql) throws SQLException;
}
可以看到,這里明確指定 SQLException.class 異常的時候需要重試兩次,每次中間間隔 100 毫秒。
@Service
public interface MyService {
@Retryable( value = SQLException.class, maxAttemptsExpression = "${retry.maxAttempts}",
backoff = @Backoff(delayExpression = "${retry.maxDelay}"))
void retryServiceWithExternalizedConfiguration(String sql) throws SQLException;
}
此外,你也可以利用 SpEL 表達式讀取配置文件里面的值。
關於 Retryable 的語法就介紹到這里,常用的基本就這些,如果你遇到更復雜的場景,可以到 GitHub 中看一下官方的 Retryable 文檔:https://github.com/spring-projects/spring-retry。下面再給你分享一個我在使用樂觀鎖+重試機制中的最佳實踐。
樂觀鎖+重試機制的最佳實踐
我比較建議你使用如下配置:
@Retryable(value = ObjectOptimisticLockingFailureException.class,backoff = @Backoff(multiplier = 1.5,random = true))
這里明確指定 ObjectOptimisticLockingFailureException.class 等樂觀鎖異常要進行重試,如果引起其他異常的話,重試會失敗,沒有意義;而 backoff 采用隨機 +1.5 倍的系數,這樣基本很少會出現連續 3 次樂觀鎖異常的情況,並且也很難發生重試風暴而引起系統重試崩潰的問題。
到這里講的一直都是樂觀鎖相關內容,那么 JPA 也支持悲觀鎖嗎?
悲觀鎖
Java Persistence API 2.0 協議里面有一個 LockModeType 枚舉值,里面包含了所有它支持的樂觀鎖和悲觀鎖的值,我們看一下。
public enum LockModeType {
//等同於OPTIMISTIC,默認,用來兼容2.0之前的協議
READ,
//等同於OPTIMISTIC_FORCE_INCREMENT,用來兼容2.0之前的協議
WRITE,
//樂觀鎖,默認,2.0協議新增
OPTIMISTIC,
//樂觀寫鎖,強制version加1,2.0協議新增
OPTIMISTIC_FORCE_INCREMENT,
//悲觀讀鎖 2.0協議新增
PESSIMISTIC_READ,
//悲觀寫鎖,version不變,2.0協議新增
PESSIMISTIC_WRITE,
//悲觀寫鎖,version會新增,2.0協議新增
PESSIMISTIC_FORCE_INCREMENT,
//2.0協議新增無鎖狀態
NONE
}
悲觀鎖在 Spring Data JPA 里面是如何支持的呢?很簡單,只需要在自己的 Repository 里面覆蓋父類的 Repository 方法,然后添加 @Lock 注解並指定 LockModeType 即可,請看如下代碼:
public interface UserInfoRepository extends JpaRepository<UserInfo, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<UserInfo> findById(Long userId);
}
在生產環境中要慎用悲觀鎖,因為它是阻塞的,一旦發生服務異常,可能會造成死鎖的現象。
JPA 對 Web MVC的支持
我們使用 Spring Data JPA 的時候,一般都會用到 Spring MVC,Spring Data 對 Spring MVC 做了很好的支持,體現在以下幾個方面:
-
支持在 Controller 層直接返回實體,而不使用其顯式的調用方法;
-
對 MVC 層支持標准的分頁和排序功能;
-
擴展的插件支持 Querydsl,可以實現一些通用的查詢邏輯。
正常情況下,我們開啟 Spring Data 對 Spring Web MVC 支持的時候需要在 @Configuration 的配置文件里面添加 @EnableSpringDataWebSupport 這一注解,如下面這種形式:
@Configuration
@EnableWebMvc
//開啟支持Spring Data Web的支持
@EnableSpringDataWebSupport
public class WebConfiguration { }
由於我們用了 Spring Boot,其有自動加載機制,會自動加載 SpringDataWebAutoConfiguration 類,發生如下變化:
@EnableSpringDataWebSupport
@ConditionalOnWebApplication(type = Type.SERVLET)
@ConditionalOnClass({ PageableHandlerMethodArgumentResolver.class, WebMvcConfigurer.class })
@ConditionalOnMissingBean(PageableHandlerMethodArgumentResolver.class)
@EnableConfigurationProperties(SpringDataWebProperties.class)
@AutoConfigureAfter(RepositoryRestMvcAutoConfiguration.class)
public class SpringDataWebAutoConfiguration {}
從類上面可以看出來,@EnableSpringDataWebSupport 會自動開啟,所以當我們用 Spring Boot + JPA + MVC 的時候,什么都不需要做,因為 Spring Boot 利用 Spring Data 對 Spring MVC 做了很多 Web 開發的天然支持。支持的組件有 DomainConverter、Page、Sort、Databinding、Dynamic Param 等。
那么我們先來看一下它對 DomainClassConverter 組件的支持。
DomainClassConverter 組件
這個組件的主要作用是幫我們把 Path 中 ID 的變量,或 Request 參數中的變量 ID 的參數值,直接轉化成實體對象注冊到 Controller 方法的參數里面。怎么理解呢?我們看個例子,就很好懂了。
首先,寫一個 MVC 的 Controller,分別從 Path 和 Param 變量里面,根據 ID 轉化成實體,代碼如下:
@RestController
public class UserInfoController {
/**
* 從path變量里面獲得參數ID的值,然后直接轉化成UserInfo實體
* @param userInfo
* @return
*/
@GetMapping("/user/{id}")
public UserInfo getUserInfoFromPath(@PathVariable("id") UserInfo userInfo) {
return userInfo;
}
/**
* 將request的param中的ID變量值,轉化成UserInfo實體
* @param userInfo
* @return
*/
@GetMapping("/user")
public UserInfo getUserInfoFromRequestParam(@RequestParam("id") UserInfo userInfo) {
return userInfo;
}
}
Controller 里面的 getUserInfoFromRequestParam 方法會自動根據 ID 查詢實體對象 UserInfo,然后注入方法的參數里面。
Page 和 Sort 的參數支持
這是一個通過分頁和排序參數查詢 UserInfo 的實例。
首先,我們新建一個 UserInfoController,里面添加如下兩個方法,分別測試分頁和排序。
@GetMapping("/users")
public Page<UserInfo> queryByPage(Pageable pageable, UserInfo userInfo) {
return userInfoRepository.findAll(Example.of(userInfo),pageable);
}
@GetMapping("/users/sort")
public HttpEntity<List<UserInfo>> queryBySort(Sort sort) {
return new HttpEntity<>(userInfoRepository.findAll(sort));
}
其中,queryByPage 方法中,兩個參數可以分別接收分頁參數和查詢條件,我們請求一下,看看效果:
復制代碼
GET http://127.0.0.1:8089/users?size=2&page=0&ages=10&sort=id,desc
參數里面可以支持分頁大小為 2、頁碼 0、排序(按照 ID 倒序)、參數 ages=10 的所有結果,Pageable 既支持分頁參數,也支持排序參數。也可以單獨調用 Sort 參數。
Web Databinding Support
Spring Data JPA 里面,可以通過 @ProjectedPayload 和 @JsonPath 對接口進行注解支持,不過要注意這與前面所講的 Jackson 注解的區別在於,此時我們講的是接口。
這里我依然結合一個實例來對這個接口進行講解,請看下面的步驟。
第一步:如果要支持 Projection,必須要在 gradle 里面引入 jsonpath 依賴才可以:
implementation 'com.jayway.jsonpath:json-path'
第二步:新建一個 UserInfoInterface 接口類,用來接收接口傳遞的 json 對象。
package com.example.jpa.example1;
import org.springframework.data.web.JsonPath;
import org.springframework.data.web.ProjectedPayload;
@ProjectedPayload
public interface UserInfoInterface {
@JsonPath("$.ages") // 第一級參數/JSON里面找ages字段
// @JsonPath("$..ages") $..代表任意層級找ages字段
Integer getAges();
@JsonPath("$.telephone") //第一級找參數/JSON里面的telephone字段
// @JsonPath({ "$.telephone", "$.user.telephone" }) //第一級或者user下面的telephone都可以
String getTelephone();
}
第三步:在 Controller 里面新建一個 post 方法,通過接口獲得 RequestBody 參數對象里面的值。
@PostMapping("/users/projected")
public UserInfoInterface saveUserInfo(@RequestBody UserInfoInterface userInfoInterface) {
return userInfoInterface;
}
第四步:我們發送一個 get 請求,代碼如下:
POST /users HTTP/1.1
{"ages":10,"telephone":"123456789"}
此時可以正常得到如下結果:
{
"ages": 10,
"telephone": "123456789"
}
這個響應結果說明了接口可以正常映射。
QueryDSL Web Support
實際工作中,經常有人會用 Querydsl 做一些復雜查詢,方便生成 Rest 的 API 接口,那么這種方法有什么好處,又會暴露什么缺點呢?我們先看一個實例。
這是一個通過 QueryDSL 作為請求參數的使用案例,通過它你就可以體驗一下 QueryDSL 的用法和使用場景,我們一步一步來看一下。
第一步:需要 grandle 引入 querydsl 的依賴。
implementation 'com.querydsl:querydsl-apt'
implementation 'com.querydsl:querydsl-jpa'
annotationProcessor("com.querydsl:querydsl-apt:4.3.1:jpa",
"org.hibernate.javax.persistence:hibernate-jpa-2.1-api:1.0.2.Final",
"javax.annotation:javax.annotation-api:1.3.2",
"org.projectlombok:lombok")
annotationProcessor("org.springframework.boot:spring-boot-starter-data-jpa")
annotationProcessor 'org.projectlombok:lombok'
第二步:UserInfoRepository 繼承 QuerydslPredicateExecutor 接口,就可以實現 QueryDSL 的查詢方法了,代碼如下:
public interface UserInfoRepository extends JpaRepository<UserInfo, Long>, QuerydslPredicateExecutor<UserInfo> {}
第三步:Controller 里面直接利用 @QuerydslPredicate 注解接收 Predicate predicate 參數。
@GetMapping(value = "user/dsl")
Page<UserInfo> queryByDsl(@QuerydslPredicate(root = UserInfo.class) com.querydsl.core.types.Predicate predicate, Pageable pageable) {
//這里面我用的userInfoRepository里面的QuerydslPredicateExecutor里面的方法
return userInfoRepository.findAll(predicate, pageable);
}
第四步:直接請求我們的 user / dsl 即可,這里利用 queryDsl 的語法 ,使 &ages=10 作為我們的請求參數。
GET http://127.0.0.1:8089/user/dsl?size=2&page=0&ages=10&sort=id%2Cdesc&ages=10
Content-Type: application/json
{
"content": [
{
"id": 2,
"version": 0,
"ages": 10,
"telephone": "123456789"
},
{
"id": 1,
"version": 0,
"ages": 10,
"telephone": "123456789"
}
],
"pageable": {
"sort": {
"sorted": true,
"unsorted": false,
"empty": false
},
"offset": 0,
"pageNumber": 0,
"pageSize": 2,
"unpaged": false,
"paged": true
},
"totalPages": 1,
"totalElements": 2,
"last": true,
"size": 2,
"number": 0,
"sort": {
"sorted": true,
"unsorted": false,
"empty": false
},
"numberOfElements": 2,
"first": true,
"empty": false
}
Response code: 200; Time: 721ms; Content length: 425 bytes
現在我們可以得出結論:QuerysDSL 可以幫我們省去創建 Predicate 的過程,簡化了操作流程。但是它依然存在一些局限性,比如多了一些模糊查詢、范圍查詢、大小查詢,它對這些方面的支持不是特別友好。可能未來會更新、優化。
@DynamicUpdate & @DynamicInsert 詳解
@DynamicInsert:這個注解表示 insert 的時候,會動態生產 insert SQL 語句,其生成 SQL 的規則是:只有非空的字段才能生成 SQL。代碼如下:
@Target( TYPE )
@Retention( RUNTIME )
public @interface DynamicInsert {
//默認是true,如果設置成false,就表示空的字段也會生成sql語句;
boolean value() default true;
}
這個注解主要是用在 @Entity 的實體中,如果加上這個注解,就表示生成的 insert SQL 的 Columns 只包含非空的字段;如果實體中不加這個注解,默認的情況是空的,字段也會作為 insert 語句里面的 Columns。
@DynamicUpdate:和 insert 是一個意思,只不過這個注解指的是在 update 的時候,會動態產生 update SQL 語句,生成 SQL 的規則是:只有非空的字段才會生成到 update SQL 的 Columns 里面。請看代碼:
@Target( TYPE )
@Retention( RUNTIME )
public @interface DynamicUpdate {
//和insert里面一個意思,默認true;
boolean value() default true;
}
和上一個注解的原理類似,這個注解也是用在 @Entity 的實體中,如果加上這個注解,就表示生成的 update SQL 的 Columns 只包含非空的字段;如果不加這個注解,默認的情況是空的字段也會作為 update 語句里面的 Columns。
擴展使用
N+1 SQL 問題
想要解決一個問題,必須要知道它是什么、如何產生的,這樣才能有方法、有邏輯地去解決它。下面通過一個例子來看一下什么是 N+1 的 SQL 問題。
假設一個 UserInfo 實體對象和 Address 是一對多的關系,即一個用戶有多個地址,我們首先看一下一般實體里面的關聯關系會怎么寫。兩個實體對象如下述代碼所示。
// UserInfo實體對象如下:
@Entity
@Table
@ToString(exclude = "addressList")//exclued防止 toString打印日志的時候死循環
public class UserInfo extends BaseEntity {
private String name;
private String telephone;
// UserInfo實體對象的關聯關系由Address對象里面的userInfo字段維護,默認是lazy加載模式,為了方便演示fetch取EAGER模式。此處是一對多關聯關系
@OneToMany(mappedBy = "userInfo",fetch = FetchType.EAGER)
private List<Address> addressList;
}
// Address對象如下:
@Entity
@Table
@ToString(exclude = "userInfo")
public class Address extends BaseEntity {
private String city;
//維護UserInfo和Address的外鍵關系,方便演示也采用EAGER模式;
@ManyToOne(fetch = FetchType.EAGER)
@JsonBackReference //此注解防止JSON死循環
private UserInfo userInfo;
}
然后,我們請求通過 UserInfoRepository 查詢所有的 UserInfo 信息,方法如下面這行代碼所示。
userInfoRepository.findAll()
現在,我們的控制台將會得到四個 SQL,如下所示。
org.hibernate.SQL :
select userinfo0_.id as id1_1_,
userinfo0_.create_time as create_t2_1_,
userinfo0_.create_user_id as create_u3_1_,
userinfo0_.last_modified_time as last_mod4_1_,
userinfo0_.last_modified_user_id as last_mod5_1_,
userinfo0_.version as version6_1_,
userinfo0_.ages as ages7_1_,
userinfo0_.email_address as email_ad8_1_,
userinfo0_.last_name as last_nam9_1_,
userinfo0_.name as name10_1_,
userinfo0_.telephone as telepho11_1_
from user_info userinfo0_ org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_0_,
addresslis0_.id as id1_0_0_,
addresslis0_.id as id1_0_1_,
addresslis0_.create_time as create_t2_0_1_,
addresslis0_.create_user_id as create_u3_0_1_,
addresslis0_.last_modified_time as last_mod4_0_1_,
addresslis0_.last_modified_user_id as last_mod5_0_1_,
addresslis0_.version as version6_0_1_,
addresslis0_.city as city7_0_1_,
addresslis0_.user_info_id as user_inf8_0_1_
from address addresslis0_
where addresslis0_.user_info_id = ? org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_0_,
addresslis0_.id as id1_0_0_,
addresslis0_.id as id1_0_1_,
addresslis0_.create_time as create_t2_0_1_,
addresslis0_.create_user_id as create_u3_0_1_,
addresslis0_.last_modified_time as last_mod4_0_1_,
addresslis0_.last_modified_user_id as last_mod5_0_1_,
addresslis0_.version as version6_0_1_,
addresslis0_.city as city7_0_1_,
addresslis0_.user_info_id as user_inf8_0_1_
from address addresslis0_
where addresslis0_.user_info_id = ? org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_0_,
addresslis0_.id as id1_0_0_,
addresslis0_.id as id1_0_1_,
addresslis0_.create_time as create_t2_0_1_,
addresslis0_.create_user_id as create_u3_0_1_,
addresslis0_.last_modified_time as last_mod4_0_1_,
addresslis0_.last_modified_user_id as last_mod5_0_1_,
addresslis0_.version as version6_0_1_,
addresslis0_.city as city7_0_1_,
addresslis0_.user_info_id as user_inf8_0_1_
from address addresslis0_
where addresslis0_.user_info_id = ?
通過 SQL 我們可以看得出來,當取 UserInfo 的時候,有多少條 UserInfo 數據就會觸發多少條查詢 Address 的 SQL。
那么所謂的 N+1 的 SQL,此時 1 代表的是一條 SQL 查詢 UserInfo 信息;N 條 SQL 查詢 Address 的信息。你可以想象一下,如果有 100 條 UserInfo 信息,可能會觸發 100 條查詢 Address 的 SQL,性能很差。
很簡單,這就是我們常說的 N+1 SQL 問題。我們這里使用的是 EAGER 模式,當使用 LAZY 的時候也是一樣的道理,只是生成 N 條 SQL 的時機是不一樣的。
現在你認識了這個問題,下一步該思考,怎么解決才更合理呢?有沒有什么辦法可以減少 SQL 條數呢?
減少 N+1 SQL 的條數
最容易想到,就是有沒有什么機制可以減少 N 對應的 SQL 條數呢?從原理分析會知道,不管是 LAZY 還是 EAGER 都是沒有用的,因為這兩個只是決定了 N 條 SQL 的觸發時機,而不能減少 SQL 的條數。
不知道你是否還記得在第 20 講(Spring JPA 中的 Hibernate 加載過程與配置項是怎么回事)中,我們介紹過的 Hibernate 的配置項有哪些,如果你回過頭去看,會發現有個配置可以改變每次批量取數據的大小。
hibernate.default_batch_fetch_size 配置
hibernate.default_batch_fetch_size 配置在 AvailableSettings.class 里面,指的是批量獲取數據的大小,默認是 -1,表示默認沒有匹配取數據。那么我們把這個值改成 20 看一下效果,只需要在 application.properties 里面增加如下配置即可。
# 更改批量取數據的大小為20
spring.jpa.properties.hibernate.default_batch_fetch_size= 20
在實體類不發生任何改變的前提下,我們再執行如下兩個方法,分別看一下 SQL 的生成情況。
userInfoRepository.findAll();
還是先查詢所有的 UserInfo 信息,看一下 SQL 的執行情況,代碼如下所示。
org.hibernate.SQL :
select userinfo0_.id as id1_1_,
userinfo0_.create_time as create_t2_1_,
userinfo0_.create_user_id as create_u3_1_,
userinfo0_.last_modified_time as last_mod4_1_,
userinfo0_.last_modified_user_id as last_mod5_1_,
userinfo0_.version as version6_1_,
userinfo0_.ages as ages7_1_,
userinfo0_.email_address as email_ad8_1_,
userinfo0_.last_name as last_nam9_1_,
userinfo0_.name as name10_1_,
userinfo0_.telephone as telepho11_1_
from user_info userinfo0_ org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_1_,
addresslis0_.id as id1_0_1_,
addresslis0_.id as id1_0_0_,
addresslis0_.create_time as create_t2_0_0_,
addresslis0_.create_user_id as create_u3_0_0_,
addresslis0_.last_modified_time as last_mod4_0_0_,
addresslis0_.last_modified_user_id as last_mod5_0_0_,
addresslis0_.version as version6_0_0_,
addresslis0_.city as city7_0_0_,
addresslis0_.user_info_id as user_inf8_0_0_
from address addresslis0_
where addresslis0_.user_info_id in (?, ?, ?)
我們可以看到 SQL 直接減少到兩條了,其中查詢 Address 的地方查詢條件變成了 in(?,?,?)。
想象一下,如果我們有 20 條 UserInfo 信息,那么產生的 SQL 也是兩條,此時要比 20+1 條 SQL 性能高太多了。
而 hibernate.default_batch_fetch_size 的經驗參考值,可以設置成 20、30、50、100 等,太高了也沒有意義。一個請求執行一次,產生的 SQL 數量為 3-5 條基本上都算合理情況,這樣通過設置 default_batch_fetch_size 就可以很好地避免大部分業務場景下的 N+1 條 SQL 的性能問題了。
此時你還需要注意一點就是,在實際工作中,一定要知道我們一次操作會產生多少 SQL,有沒有預期之外的 SQL 參數,這是需要關注的重點,這種情況可以利用我們之前說過的如下配置來開啟打印 SQL,請看代碼。
## 顯示sql的執行日志,如果開了這個,show_sql就可以不用了,show_sql沒有上下文,多線程情況下,分不清楚是誰打印的,所有我推薦如下配置項:
logging.level.org.hibernate.SQL=debug
但是這種配置也有個缺陷,就是只能全局配置,沒辦法針對不通過的實體管理關系配置不同的 Fetch Size 的值。
而與之類似的 Hibernate 里面也提供了一個注解 @BatchSize 可以解決此問題。
@BatchSize 注解
@BatchSize 注解是 Hibernate 提供的用來解決查詢關聯關系的批量處理大小,默認無,可以配置在實體上,也可以配置在關聯關系上面。此注解里面只有一個屬性 size,用來指定關聯關系 LAZY 或者是 EAGER 一次性取數據的大小。
我們還是將上面的例子中的 UserInfo 實體做一下改造,在里面增加兩次 @BatchSize 注解,代碼如下所示。
@Entity
@Table
@ToString(exclude = "addressList")
@BatchSize(size = 2)//實體類上加@BatchSize注解,用來設置當被關聯關系的時候一次查詢的大小,我們設置成2,方便演示Address關聯UserInfo的時候的效果
public class UserInfo extends BaseEntity {
private String name;
private String telephone;
@OneToMany(mappedBy = "userInfo",cascade = CascadeType.PERSIST,fetch = FetchType.EAGER)
@BatchSize(size = 20)//關聯關系的屬性上加@BatchSize注解,用來設置當通過UserInfo加載Address的時候一次取數據的大小
private List<Address> addressList;
}
我們通過改造 UserInfo 實體,可以直接演示 @BatchSize 應用在實體類和屬性字段上的效果,所以 Address 實體可以不做任何改變,hibernate.default_batch_fetch_size 還改成默認值 -1,我們再分別執行一下兩個 findAll 方法,看一下效果。
第一種:查詢所有 UserInfo,代碼如下面這行所示。
userInfoRepository.findAll()
我們看一下 SQL 控制台。
org.hibernate.SQL :
select userinfo0_.id as id1_1_,
userinfo0_.create_time as create_t2_1_,
userinfo0_.create_user_id as create_u3_1_,
userinfo0_.last_modified_time as last_mod4_1_,
userinfo0_.last_modified_user_id as last_mod5_1_,
userinfo0_.version as version6_1_,
userinfo0_.ages as ages7_1_,
userinfo0_.email_address as email_ad8_1_,
userinfo0_.last_name as last_nam9_1_,
userinfo0_.name as name10_1_,
userinfo0_.telephone as telepho11_1_
from user_info userinfo0_ org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_1_,
addresslis0_.id as id1_0_1_,
addresslis0_.id as id1_0_0_,
addresslis0_.create_time as create_t2_0_0_,
addresslis0_.create_user_id as create_u3_0_0_,
addresslis0_.last_modified_time as last_mod4_0_0_,
addresslis0_.last_modified_user_id as last_mod5_0_0_,
addresslis0_.version as version6_0_0_,
addresslis0_.city as city7_0_0_,
addresslis0_.user_info_id as user_inf8_0_0_
from address addresslis0_
where addresslis0_.user_info_id in (?, ?, ?)
和剛才設置 hibernate.default_batch_fetch_size=20 的效果一模一樣,所以我們可以利用 @BatchSize 這個注解針對不同的關聯關系,配置不同的大小,從而提升 N+1 SQL 的性能。
注意事項:
@BatchSize 的使用具有局限性,不能作用於 @ManyToOne 和 @OneToOne 的關聯關系上,那樣代碼是不起作用的,如下所示。
public class Address extends BaseEntity {
private String city;
@ManyToOne(cascade = CascadeType.PERSIST,fetch = FetchType.EAGER)
@BatchSize(size = 30) //由於是@ManyToOne的關聯關系所有沒有作用
private UserInfo userInfo;
}
因此,要注意 @BatchSize 只能作用在 @ManyToMany、@OneToMany、實體類這三個地方。
Hibernate 中 @Fetch 數據的策略
Hibernate 提供了一個 @Fetch 注解,用來改變獲取數據的策略。我們來研究一下這一注解的語法,代碼如下所示。
// fetch注解只能用在方法和字段上面
@Target({ElementType.METHOD, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface Fetch {
//注解里面,只有一個屬性獲取數據的模式
FetchMode value();
}
//其中FetchMode的值有如下幾種:
public enum FetchMode {
//默認模式,就是會有N+1 sql的問題;
SELECT,
//通過join的模式,用一個sql把主體數據和關聯關系數據一口氣查出來
JOIN,
//通過子查詢的模式,查詢關聯關系的數據
SUBSELECT
}
需要注意的是,不要把這個注解和 JPA 協議里面的 FetchType.EAGER、FetchType.LAZY 搞混了,JPA 協議的關聯關系中的 FetchTyp 解決的是取關聯關系數據時機的問題,也就是說 EAGER 代表的是立即獲得關聯關系的數據,LAZY 是需要的時候再獲得關聯關系的數據。
這和 Hibernate 的 FetchMode 是兩回事,FetchMode 解決的是獲得數據策略的問題,也就是說,獲得關聯關系數據的策略有三種模式:SELECT(默認)、JOIN、SUBSELECT。下面我通過例子來分別介紹一下這三種模式有什么區別,分別起到什么作用。
FetchMode.SELECT
FetchMode.Select 是默認策略,加與不加是同樣的效果,代表獲取關系的時候新開一個 SQL 進行查詢,依然會產生 N+1 的 SQL 問題。
FetchMode.JOIN
FetchMode.JOIN 的意思是主表信息和關聯關系通過一個 SQL JOIN 的方式查出來,我們看一下例子。
首先,將 UserInfo 里面的 FetchMode 改成 JOIN 模式,關鍵代碼如下。
public class UserInfo extends BaseEntity {
private String name;
private String telephone;
@OneToMany(mappedBy = "userInfo",cascade = CascadeType.PERSIST,fetch = FetchType.EAGER)
@Fetch(value = FetchMode.JOIN) //唯一變化的地方采用JOIN模式
private List<Address> addressList;
}
然后,調用一下 userInfoRepository.findAll(); 這個方法,發現依然是這三條 SQL。
這是因為 FetchMode.JOIN 只支持通過 ID 或者聯合唯一鍵獲取數據才有效,這正是 JOIN 策略模式的局限性所在。
那么我們再調用一下 userInfoRepository.findById(id),看看控制台的 SQL 執行情況,代碼如下。
select userinfo0_.id as id1_1_0_,
userinfo0_.create_time as create_t2_1_0_,
userinfo0_.create_user_id as create_u3_1_0_,
userinfo0_.last_modified_time as last_mod4_1_0_,
userinfo0_.last_modified_user_id as last_mod5_1_0_,
userinfo0_.version as version6_1_0_,
userinfo0_.ages as ages7_1_0_,
userinfo0_.email_address as email_ad8_1_0_,
userinfo0_.last_name as last_nam9_1_0_,
userinfo0_.name as name10_1_0_,
userinfo0_.telephone as telepho11_1_0_,
addresslis1_.user_info_id as user_inf8_0_1_,
addresslis1_.id as id1_0_1_,
addresslis1_.id as id1_0_2_,
addresslis1_.create_time as create_t2_0_2_,
addresslis1_.create_user_id as create_u3_0_2_,
addresslis1_.last_modified_time as last_mod4_0_2_,
addresslis1_.last_modified_user_id as last_mod5_0_2_,
addresslis1_.version as version6_0_2_,
addresslis1_.city as city7_0_2_,
addresslis1_.user_info_id as user_inf8_0_2_
from user_info userinfo0_
left outer join address addresslis1_ on userinfo0_.id = addresslis1_.user_info_id
where userinfo0_.id = ?
這時我們會發現,當查詢 UserInfo 的時候,它會通過 left outer join 把 Address 的信息也查詢出來,雖然 SQL 上會有冗余信息,但是你會發現我們之前的 N+1 的 SQL 直接變成 1 條 SQL 了。
此時我們修改 UserInfo 里面的 @OneToMany,這個 @Fetch(value = FetchMode.JOIN) 同樣適用於 @ManyToOne;然后再改一下 Address 實例,用 @Fetch(value = FetchMode.JOIN) 把 Adress 里面的 UserInfo 關聯關系改成 JOIN 模式;接着我們用 LAZY 獲取數據的時機,會發現其對獲取數據的策略沒有任何影響。
這里我只是給你演示獲取數據時機的不同情況,關鍵代碼如下。
@Entity
@Table
@ToString(exclude = "userInfo")
public class Address extends BaseEntity {
private String city;
@ManyToOne(cascade = CascadeType.PERSIST,fetch = FetchType.LAZY)
@JsonBackReference
@Fetch(value = FetchMode.JOIN)
private UserInfo userInfo;
}
同樣的道理,JOIN 對列表性的查詢是沒有效果的,我們調用一下 addressRepository.findById(id),產生的 SQL 如下所示。
org.hibernate.SQL :
select address0_.id as id1_0_0_,
address0_.create_time as create_t2_0_0_,
address0_.create_user_id as create_u3_0_0_,
address0_.last_modified_time as last_mod4_0_0_,
address0_.last_modified_user_id as last_mod5_0_0_,
address0_.version as version6_0_0_,
address0_.city as city7_0_0_,
address0_.user_info_id as user_inf8_0_0_,
userinfo1_.id as id1_1_1_,
userinfo1_.create_time as create_t2_1_1_,
userinfo1_.create_user_id as create_u3_1_1_,
userinfo1_.last_modified_time as last_mod4_1_1_,
userinfo1_.last_modified_user_id as last_mod5_1_1_,
userinfo1_.version as version6_1_1_,
userinfo1_.ages as ages7_1_1_,
userinfo1_.email_address as email_ad8_1_1_,
userinfo1_.last_name as last_nam9_1_1_,
userinfo1_.name as name10_1_1_,
userinfo1_.telephone as telepho11_1_1_
from address address0_
left outer join user_info userinfo1_ on address0_.user_info_id = userinfo1_.id
where address0_.id = ?
我們發現此時只會產生一個 SQL,即通過 from address left outer join user_info 一次性把所有信息都查出來,然后 Hibernate 再根據查詢出來的結果組合到不同的實體里面。
也就是說 FetchMode.JOIN 對於關聯關系的查詢 LAZY 是不起作用的,因為 JOIN 的模式是通過一條 SQL 查出來所有信息,所以 FetchMode.JOIN 會忽略 FetchType。
FetchMode.SUBSELECT
這種模式很簡單,就是將關聯關系通過子查詢的形式查詢出來,我們還是結合例子來理解一下。
首先,將 UserInfo 里面的關聯關系改成 @Fetch(value = FetchMode.SUBSELECT),關鍵代碼如下。
public class UserInfo extends BaseEntity {
@OneToMany(mappedBy = "userInfo",cascade = CascadeType.PERSIST,fetch = FetchType.LAZY) //我們這里測試一下LAZY情況
@Fetch(value = FetchMode.SUBSELECT) //唯一變化之處
private List<Address> addressList;
}
接着,像上面的做法一樣,執行一下 userInfoRepository.findAll();方法,看一下控制台的 SQL 情況,如下所示。
org.hibernate.SQL :
select userinfo0_.id as id1_1_,
userinfo0_.create_time as create_t2_1_,
userinfo0_.create_user_id as create_u3_1_,
userinfo0_.last_modified_time as last_mod4_1_,
userinfo0_.last_modified_user_id as last_mod5_1_,
userinfo0_.version as version6_1_,
userinfo0_.ages as ages7_1_,
userinfo0_.email_address as email_ad8_1_,
userinfo0_.last_name as last_nam9_1_,
userinfo0_.name as name10_1_,
userinfo0_.telephone as telepho11_1_
from user_info userinfo0_
org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_1_,
addresslis0_.id as id1_0_1_,
addresslis0_.id as id1_0_0_,
addresslis0_.create_time as create_t2_0_0_,
addresslis0_.create_user_id as create_u3_0_0_,
addresslis0_.last_modified_time as last_mod4_0_0_,
addresslis0_.last_modified_user_id as last_mod5_0_0_,
addresslis0_.version as version6_0_0_,
addresslis0_.city as city7_0_0_,
addresslis0_.user_info_id as user_inf8_0_0_
from address addresslis0_
where addresslis0_.user_info_id in (select userinfo0_.id from user_info userinfo0_)
這個時候會發現,查詢 Address 信息是直接通過 addresslis0_.user_info_id in (select userinfo0_.id from user_info userinfo0_) 子查詢的方式進行的,也就是說 N+1 SQL 變成了 1+1 的 SQL,這有點類似我們配置 @BatchSize 的效果。
FetchMode.SUBSELECT 支持 ID 查詢和各種條件查詢,唯一的缺點是只能配置在 @OneToMany 和 @ManyToMany 的關聯關系上,不能配置在 @ManyToOne 和 @OneToOne 的關聯關系上,所以我們在 Address 里面關聯 UserInfo 的時候就沒有辦法做實驗了。
總之,@Fetch 的不同模型,都有各自的優缺點:FetchMode.SELECT 默認,和不配置的效果一樣;FetchMode.JOIN 只支持類似 findById(id) 的方法,只能根據 ID 查詢才有效果;FetchMode.SUBSELECT 雖然不限使用方式,但是只支持 OneToMany 的關聯關系。
所以你在使用 @Fetch 的時候需要注意一下它的局限性,我個人是比較推薦 @BatchSize 的方式。
SpEL 表達式
SpEL 在 @Value 里面的用法最常見,我們通過 @Value 來了解一下。
@Value 的應用場景
新建一個 DemoProperties 對象,用 Spring 裝載,測試一下兩個語法點:運算符和 Map、List。
第一個語法:通過 @Value 展示 SpEL 里面支持的各種運算符的寫法。如下面的表格所示。

第二個語法:@Value 展示了 SpEL 可以直接讀取 Map 和 List 里面的值,代碼如下所示。
//我們通過@Component加載一個類,並且給其中的List和Map附上值
@Component("workersHolder")
public class WorkersHolder {
private List<String> workers = new LinkedList<>();
private Map<String, Integer> salaryByWorkers = new HashMap<>();
public WorkersHolder() {
workers.add("John");
workers.add("Susie");
workers.add("Alex");
workers.add("George");
salaryByWorkers.put("John", 35000);
salaryByWorkers.put("Susie", 47000);
salaryByWorkers.put("Alex", 12000);
salaryByWorkers.put("George", 14000);
}
//Getters and setters ...
}
//SpEL直接讀取Map和List里面的值
@Value("#{workersHolder.salaryByWorkers['John']}") // 35000
private Integer johnSalary;
@Value("#{workersHolder.salaryByWorkers['George']}") // 14000
private Integer georgeSalary;
@Value("#{workersHolder.salaryByWorkers['Susie']}") // 47000
private Integer susieSalary;
@Value("#{workersHolder.workers[0]}") // John
private String firstWorker;
@Value("#{workersHolder.workers[3]}") // George
private String lastWorker;
@Value("#{workersHolder.workers.size()}") // 4
private Integer numberOfWorkers;
以上就是 SpEL 的運算符和對 Map、List、SpringBeanFactory 里面的 Bean 的調用情況。
@Value 使用的注意事項 # 與 $ 的區別
SpEL 表達式默認以 # 開始,以大括號進行包住,如 #{expression}。默認規則在 ParserContext 里面設置,我們也可以自定義,但是一般建議不要動。
這里注意要與 Spring 中的 Properties 進行區別,Properties 相關的表達式是以 $ 開始的大括號進行包住的,如 ${property.name}。
也就是說 @Value 的值有兩類:
${ property**:**default_value }
#{ obj.property**? :**default_value }
第一個注入的是外部參數對應的 Property,第二個則是 SpEL 表達式對應的內容。
而 Property placeholders 不能包含 SpEL 表達式,但是 SpEL 表達式可以包含 Property 的引用。如 #{${someProperty} + 2},如果 someProperty=1,那么效果將是 #{ 1 + 2},最終的結果將是 3。
JPA 中 @Query 的應用場景
SpEL 除了能在 @Value 里面使用外,也能在 @Query 里使用,而在 @Query 里還有一個特殊的地方,就是它可以用來取方法的參數。
通過 SpEL 取被 @Query 注解的方法參數
在 @Query 注解中使用 SpEL 的主要目的是取方法的參數,主要有三種用法,如下所示。
//用法一:根據下標取方法里面的參數
@Query("select u from User u where u.age = ?#{[0]}")
List<User> findUsersByAge(int age);
//用法二:#customer取@Param("customer")里面的參數
@Query("select u from User u where u.firstname = :#{#customer.firstname}")
List<User> findUsersByCustomersFirstname(@Param("customer") Customer customer);
//用法三:用JPA約定的變量entityName取得當前實體的實體名字
@Query("from #{#entityName}")
List<UserInfo> findAllByEntityName();
其中,
-
方法一可以通過 [0] 的方式,根據下標取到方法的參數;
-
方法二通過 #customer 可以根據 @Param 注解的參數的名字取到參數,必須通過 ?#{} 和 :#{} 來觸發 SpEL 的表達式語法;
-
方法三通過 #{#entityName} 取約定的實體的名字。
要注意區別@Param 的用法:lastname這種方式。
下面我們再來看一個更復雜一點的例子,代碼如下。
public interface UserInfoRepository extends JpaRepository<UserInfo, Long> {
// JPA約定的變量entityName取得當前實體的實體名字
@Query("from #{#entityName}")
List<UserInfo> findAllByEntityName();
//一個查詢中既可以支持SpEL也可以支持普通的:ParamName的方式
@Modifying
@Query("update #{#entityName} u set u.name = :name where u.id =:id")
void updateUserActiveState(@Param("name") String name, @Param("id") Long id);
//演示SpEL根據數組下標取參數,和根據普通的Parma的名字:name取參數
@Query("select u from UserInfo u where u.lastName like %:#{[0]} and u.name like %:name%")
List<UserInfo> findContainingEscaped(@Param("name") String name);
//SpEL取Parma的名字customer里面的屬性
@Query("select u from UserInfo u where u.name = :#{#customer.name}")
List<UserInfo> findUsersByCustomersFirstname(@Param("customer") UserInfo customer);
//利用SpEL根據一個寫死的'jack'字符串作為參數
@Query("select u from UserInfo u where u.name = ?#{'jack'}")
List<UserInfo> findOliverBySpELExpressionWithoutArgumentsWithQuestionmark();
//同時SpEL支持特殊函數escape和escapeCharacter
@Query("select u from UserInfo u where u.lastName like %?#{escape([0])}% escape ?#{escapeCharacter()}")
List<UserInfo> findByNameWithSpelExpression(String name);
// #entityName和#[]同時使用
@Query("select u from #{#entityName} u where u.name = ?#{[0]} and u.lastName = ?#{[1]}")
List<UserInfo> findUsersByFirstnameForSpELExpressionWithParameterIndexOnlyWithEntityExpression(String name, String lastName);
//對於 native SQL同樣適用,並且同樣支持取pageable分頁里面的屬性值
@Query(value = "select * from (" //
+ "select u.*, rownum() as RN from (" //
+ "select * from user_info ORDER BY ucase(firstname)" //
+ ") u" //
+ ") where RN between ?#{ #pageable.offset +1 } and ?#{#pageable.offset + #pageable.pageSize}", //
countQuery = "select count(u.id) from user_info u", //
nativeQuery = true)
Page<UserInfo> findUsersInNativeQueryWithPagination(Pageable pageable);
}
我個人比較推薦使用 @Param 的方式,這樣語義清晰,參數換位置了也不影響執行結果。
SpEL 在 @Cacheable 中的應用場景
我們在實際工作中還有一個經常用到 SpEL 的場景,就是在 Cache 的時候,也就是 Spring Cache 的相關注解里面,如 @Cacheable、@CachePut、@CacheEvict 等。我們還是通過例子來體會一下,代碼如下所示。
//緩存key取當前方法名,判斷一下只有返回結果不為null或者非empty才進行緩存
@Cacheable(value = "APP", key = "#root.methodName", cacheManager = "redis.cache", unless = "#result == null || #result.isEmpty()")
@Override
public Map<String, Map<String, String>> getAppGlobalSettings() {}
//evict策略的key是當前參數customer里面的name屬性
@Caching(evict = {
@CacheEvict(value="directory", key="#customer.name") })
public String getAddress(Customer customer) {...}
//在condition里面使用,當參數里面customer的name屬性的值等於字符串Tom才放到緩存里面
@CachePut(value="addresses", condition="#customer.name=='Tom'")
public String getAddress(Customer customer) {...}
//用在unless里面,利用SpEL的條件表達式判斷,排除返回的結果地址長度小於64的請求
@CachePut(value="addresses", unless="#result.length()<64")
public String getAddress(Customer customer) {...}
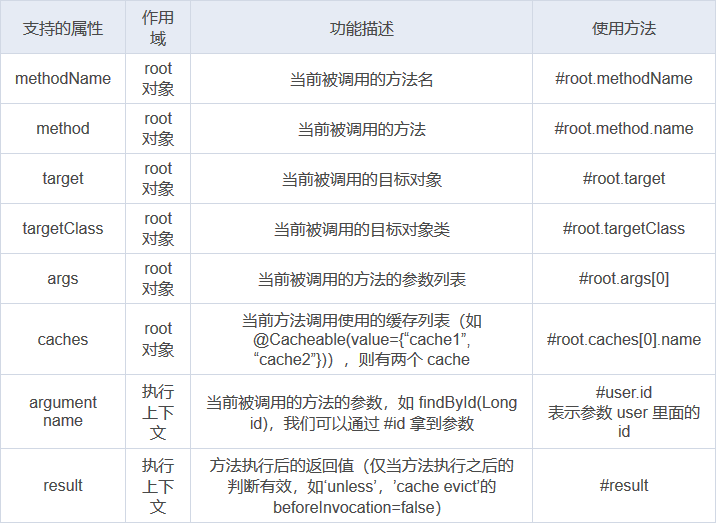
Spring Cache 中 SpEL 支持的上下文語法
Spring Cache 提供了一些供我們使用的 SpEL 上下文數據,如下表所示(摘自 Spring 官方文檔)。
Spring Data JPA 單元測試最佳實踐
測試用例寫法主要依賴@DataJpaTest注解:
@DataJpaTest
public class AddressRepositoryTest {
@Autowired
private AddressRepository addressRepository;
//測試一下保存和查詢
@Test
public void testSave() {
Address address = Address.builder().city("shanghai").build();
addressRepository.save(address);
List<Address> address1 = addressRepository.findAll();
address1.stream().forEach(address2 -> System.out.println(address2));
}
}
通過上面的測試用例可以看到,我們直接添加了 @DataJpaTest 注解,然后利用 Spring 的注解 @Autowired,引入了 spring context 里面管理的 AddressRepository 實例。換句話說,我們在這里面使用了集成測試,即直接連接的數據庫來完成操作。
@DataJpaTest 注解幫我們做了很多事情:
- 加載 Spring Data JPA 所需要的上下文,即數據庫,所有的 Repository;
- 啟用默認集成數據庫 h2,完成集成測試。
什么是單元測試
通俗來講,就是不依賴本類之外的任何方法完成本類里面的所有方法的測試,也就是我們常說的依賴本類之外的,都通過 Mock 的方式進行。那么在單元測試的模式下,我們一起看看 Service 層的單元測試應該怎么寫。
Service 層單元測試
單元測試寫法如下。
@ExtendWith(SpringExtension.class)//通過這個注解利用Spring的容器
@Import(UserInfoServiceImpl.class)//導入要測試的UserInfoServiceImpl
public class UserInfoServiceTest {
@Autowired //利用spring的容器,導入要測試的UserInfoService
private UserInfoService userInfoService;
@MockBean //里面@MockBean模擬我們service中用到的userInfoRepository,這樣避免真實請求數據庫
private UserInfoRepository userInfoRepository;
// 利用單元測試的思想,mock userInfoService里面的UserInfoRepository,這樣Service層就不用連接數據庫,就可以測試自己的業務邏輯了
@Test
public void testGetUserInfoDto() {
//利用Mockito模擬當調用findById(1)的時候,返回模擬數據
Mockito.when(userInfoRepository.findById(1L)).thenReturn(java.util.Optional.ofNullable(UserInfo.builder().name("jack").id(1L).build()));
UserInfoDto userInfoDto = userInfoService.findByUserId(1L);
//經過一些service里面的邏輯計算,我們驗證一下返回結果是否正確
Assertions.assertEquals("jack",userInfoDto.getName());
}
}
這樣就可以完成了我們的 Service 層的測試了。
其中 @ExtendWith(SpringExtension.class) 是 spring boot 與 Junit 5 結合使用的時候,當利用 Spring 的 TesatContext 進行 mock 測試時要使用的。有的時候如果們做一些簡單 Util 的測試,就不一定會用到 SpringExtension.class。
在 service 的單元測試中,主要用到的知識點有四個。
- 通過 @ExtendWith(SpringExtension.class) 加載 Spring 的測試框架及其 TestContext;
- 通過 @Import(UserInfoServiceImpl.class) 導入具體要測試的類,這樣 SpringTestContext 就不用加載項目里面的所有類,只需要加載 UserInfoServiceImpl.class 就可以了,這樣可以大大提高測試用例的執行速度;
- 通過 @MockBean 模擬 UserInfoSerceImpl 依賴的 userInfoRepository,並且自動注入 Spring test context 里面,這樣 Service 里面就自動有依賴了;
- 利用 Mockito.when().thenReturn() 的機制,模擬測試方法。
這樣我們就可以通過 Assertions 里面的斷言來測試 serice 方法里面的邏輯是否符合預期了。
Controller 層單元測試
完整的測試用例,代碼如下所示。
package com.example.jpa.demo;
@WebMvcTest(UserInfoController.class)
public class UserInfoControllerTest {
@Autowired
private MockMvc mvc;
@MockBean
private UserInfoService userInfoService;
//單元測試mvc的controller的方法
@Test
public void testGetUserDto() throws Exception {
//利用@MockBean,當調用 userInfoService的findByUserId(1)的時候返回一個模擬的UserInfoDto數據
Mockito.when(userInfoService.findByUserId(1L)).thenReturn(UserInfoDto.builder().name("jack").id(1L).build());
//利用mvc驗證一下Controller里面的解決是否OK
MockHttpServletResponse response = mvc
.perform(MockMvcRequestBuilders
.get("/user/1/")//請求的path
.accept(MediaType.APPLICATION_JSON)//請求的mediaType,這里面可以加上各種我們需要的Header
)
.andDo(print())//打印一下
.andExpect(status().isOk())
.andExpect(MockMvcResultMatchers.jsonPath("$.name").value("jack"))
.andReturn().getResponse();
System.out.println(response);
}
}
其中我們主要利用了 @WebMvcTest 注解,來引入我們要測試的 Controller。
當通過 @WebMvcTest(UserInfoController.class) 導入我們需要測試的 Controller 之后,就可以再通過 MockMvc 請求到我們加載的 Contoller 里面的 path 了,並且可以通過 MockMvc 提供的一些方法發送請求,驗證 Controller 的響應結果。
下面概括一下 Contoller 層單元測試主要用到的三個知識點。
- 利用 @WebMvcTest 注解,加載我們要測試的 Controller,同時生成 mvc 所需要的 Test Context;
- 利用 @MockBean 默認 Controller 里面的依賴,如 Service,並通過 Mockito.when().thenReturn();的語法 mock 依賴的測試數據;
- 利用 MockMvc 中提供的方法,發送 Controller 的 Rest 風格的請求,並驗證返回結果和狀態碼。
那么單元測試我們先介紹這么多,下面看一下什么是集成測試。
什么是集成測試
顧名思義,就是指多個模塊放在一起測試,和單元測試正好相反,並非采用 mock 的方式測試,而是通過直接調用的方式進行測試。也就是說我們依賴 spring 容器進行開發,所有的類之間直接調用,模擬應用真實啟動時候的狀態。
Service 層的集成測試用例寫法
我們還用剛才的例子,看一下 UserInfoService 里面的 findByUserId 通過集成測試如何進行。測試用例的寫法如下。
@DataJpaTest
@ComponentScan(basePackageClasses= UserInfoServiceImpl.class)
public class UserInfoServiceIntegrationTest {
@Autowired
private UserInfoService userInfoService;
@Autowired
private UserInfoRepository userInfoRepository;
@Test
@Rollback(false)//如果我們事務回滾設置成false的話,數據庫可以真實看到這條數據
public void testIntegtation() {
UserInfo u1 = UserInfo.builder().name("jack-db").ages(20).id(1L).telephone("1233456").build();
//數據庫真實加一條數據
userInfoRepository.save(u1);//數據庫里面真實保存一條數據
UserInfoDto userInfoDto = userInfoService.findByUserId(1L);
userInfoDto.getName();
Assertions.assertEquals(userInfoDto.getName(),u1.getName()+"_HELLO");
}
}
這時你會發現數據已經不再回滾,也會正常地執行 SQL,而不是通過 Mock 的方式測試。Service 的集成測試相對來說還比較簡單,那么我們看下 Controller 層的集成測試用例應該怎么寫。
Controller 層的集成測試用例的寫法
我們用集成測試把剛才 UserInfoCotroller 寫的 user/1/ 接口測試一下,將集成測試的代碼做如下改動。
@SpringBootTest(classes = DemoApplication.class,
webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT) //加載DemoApplication,指定一個隨機端口
public class UserInfoControllerIntegrationTest {
@LocalServerPort //獲得模擬的隨機端口
private int port;
@Autowired //我們利用RestTemplate,發送一個請求
private TestRestTemplate restTemplate;
@Test
public void testAllUserDtoIntegration() {
UserInfoDto userInfoDto = this.restTemplate
.getForObject("http://localhost:" + port + "/user/1", UserInfoDto.class);//真實請求有一個后台的API
Assertions.assertNotNull(userInfoDto);
}
}
我們再看日志的話,會發現此次的測試用例會在內部啟動一個 tomcat 容器,然后再利用 TestResTemplate 進行真實請求,返回測試結果進行測試。
而其中會涉及一個注解 @SpringBootTest,它用來指定 Spring 應用的類是哪個,也就是我們真實項目的 Application 啟動類;然后會指定一個端口,此處必須使用隨機端口,否則可能會有沖突(如果我們啟動的集成測試有點多的情況)。
Junit 4 和 Junit 5 在 Spring Boot 中的區別
第一,Spring Boot 2.2+ 以上的版本默認導入的是 Junit 5 的 jar 包依賴,以下的版本默認導入的是 Junit 4 的 jar 包依賴的版本,所以你在使用不同版本的 Spring Boot 的時候需要注意一下依賴的 jar 包是否齊全。
第二,org.junit.junit.Test 變成了 org.junit.jupiter.api.Test。
第三,一些注解發生了變化:
- @Before 變成了 @BeforeEach
- @After 變成了 @AfterEach
- @BeforeClass 變成了 @BeforeAll
- @AfterClass 變成了 @AfterAll
- @Ignore 變成了 @Disabled
- @Category 變成了 @Tag
- @Rule 和 @ClassRule 沒有了,用 @ExtendWith 和 @RegisterExtension 代替
第四,引用 Spring 的上下文 @RunWith(SpringRunner.class) 變成了 @ExtendWith(SpringExtension.class)。
第五,org.junit.Assert 下面的斷言都移到了org.junit.jupiter.api.Assertions 下面,所以一些斷言的寫法會發生如下變化:
//junit4斷言的寫法
Assert.assertEquals(200, result.getStatusCodeValue());
Assert.assertEquals(true, result.getBody().contains("employeeList"));
//junit5斷言的寫法
Assertions.assertEquals(400, ex.getRawStatusCode());
Assertions.assertEquals(true, ex.getResponseBodyAsString().contains("Missing request header"));
第六,Junit 5 提供 @DisplayName("Test MyClass") 用來標識此次單元測試的名字。
Spring Data ElasticSearch
Spring Data 和 Elasticsearch 結合的時候,唯一需要注意的是版本之間的兼容性問題,Elasticsearch 和 Spring Boot 是同時向前發展的,而 Elasticsearch 的大版本之間還存在一定的 API 兼容性問題,所以我們必須要知道這些版本之間的關系,我整理了一個表格,如下。
| Spring Data Release Train | Spring Data Elasticsearch | Elasticsearch | Spring Boot |
|---|---|---|---|
| 2020.0.0[1] | 4.1.x[1] | 7.9.3 | 2.4.x[1] |
| Neumann | 4.0.x | 7.6.2 | 2.3.x |
| Moore | 3.2.x | 6.8.12 | 2.2.x |
| Lovelace | 3.1.x | 6.2.2 | 2.1.x |
| Kay[2] | 3.0.x[2] | 5.5.0 | 2.0.x[2] |
| Ingalls[2] | 2.1.x[2] | 2.4.0 | 1.5.x[2] |
現在你對這些版本之間的關聯關系有了一定印象,由於版本越新越便利,所以一般情況下我們直接采用最新的版本。
首先參考官方文檔:https://github.com/elastic/helm-charts/tree/master/elasticsearch 安裝ES,完成安裝后就可以開始測試了。
第一步:引入 spring-boot-starter-data-elasticsearch 依賴。
第二步:在 application.properties 里面新增 es 的連接地址,連接本地的 Elasticsearch。
spring.data.elasticsearch.client.reactive.endpoints=127.0.0.1:9200
第三步:新增一個 ElasticSearchConfiguration 的配置文件,主要是為了開啟掃描的包。
package com.example.data.es.demo.es;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.repository.config.EnableElasticsearchRepositories;
//利用@EnableElasticsearchRepositories注解指定Elasticsearch相關的Repository的包路徑在哪里
@EnableElasticsearchRepositories(basePackages = "com.example.data.es.demo.es")
@Configuration
public class ElasticSearchConfiguration {
}
第四步:我們新增一個 Topic 的 Document,它類似 JPA 里面的實體,用來保存和讀取 Topic 的數據,代碼如下所示。
package com.example.data.es.demo.es;
@Document(indexName = "topic")
//論壇主題信息
public class Topic {
@Id
private Long id;
private String title;
@Field(type = FieldType.Nested, includeInParent = true)
private List<Author> authors;
}
package com.example.data.es.demo.es;
//作者信息
public class Author {
private String name;
}
第五步:新建一個 Elasticsearch 的 Repository,用來對 Elasticsearch 索引的增刪改查,代碼如下所示。
package com.example.data.es.demo.es;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
//類似JPA一樣直接操作Topic類型的索引
public interface TopicRepository extends ElasticsearchRepository<Topic,Long> {
List<Topic> findByTitle(String title);
}
第六步: 新建一個 Controller,對 Topic 索引進行查詢和添加。
@RestController
public class TopicController {
@Autowired
private TopicRepository topicRepository;
//查詢topic的所有索引
@GetMapping("topics")
public List<Topic> query(@Param("title") String title) {
return topicRepository.findByTitle(title);
}
//保存 topic索引
@PostMapping("topics")
public Topic create(@RequestBody Topic topic) {
return topicRepository.save(topic);
}
}
第七步:發送一個添加和查詢的請求測試一下。
我們發送三個 POST 請求,添加三條索引,代碼如下所示。
POST /topics HTTP/1.1
Host: 127.0.0.1:8080
Content-Type: application/json
Cache-Control: no-cache
Postman-Token: d9cc1f6c-24dd-17ff-f2e8-3063fa6b86fc
{
"title":"jack",
"id":2,
"authors":[{
"name":"jk1"
},{
"name":"jk2"
}]
}
然后發送一個 get 請求,獲得標題是 jack 的索引,如下面這行代碼所示。
GET http://127.0.0.1:8080/topics?title=jack
得到如下結果。
GET http://127.0.0.1:8080/topics?title=jack
HTTP/1.1 200
Content-Type: application/json
Transfer-Encoding: chunked
Date: Wed, 30 Dec 2020 15:12:16 GMT
Keep-Alive: timeout=60
Connection: keep-alive
{
"id": 1,
"title": "jack",
"authors": [
{
"name": "jk1"
},
{
"name": "jk2"
}
]
},
{
"id": 3,
"title": "jack",
"authors": [
{
"name": "jk1"
},
{
"name": "jk2"
}
]
},
{
"id": 2,
"title": "jack",
"authors": [
{
"name": "jk1"
},
{
"name": "jk2"
}
]
}
]
Response code: 200; Time: 348ms; Content length: 199 bytes
Cannot preserve cookies, cookie storage file is included in ignored list:
> /Users/jack/Company/git_hub/spring-data-jpa-guide/2.3/elasticsearch-data/.idea/httpRequests/http-client.cookies
這時,一個完整的 Spring Data Elasticsearch 的例子就演示完了。其實你會發現,我們使用 Spring Data Elasticsearch 來操作 ES 相關的 API 的話,比我們直接寫 Http 的 client 要簡單很多,因為這里面幫我們封裝了很多基礎邏輯,省去了很多重復造輪子的過程。