Protobuf 協議淺析
導語:本文首先介紹了 protobuf 的基本概念和語法,然后重點介紹了 protobuf 編解碼的原理,最后結合前面的知識給出了 protobuf 的一些使用建議並利用思維導圖對這篇文章的內容做了總結。
1. Protobuf 介紹
1.1 Protobuf 基本概念
Protobuf 是由 Google 開發的一種語言無關,平台無關,可擴展的序列化結構數據的方法,可用於通信和數據存儲。
提到 Protobuf 就不得不提到序列化和反序列化的概念。
序列化和反序列化屬於通信協議的一部分,它們位於 TCP/IP 四層模型中的應用層和 OSI 七層模型中的表示層。
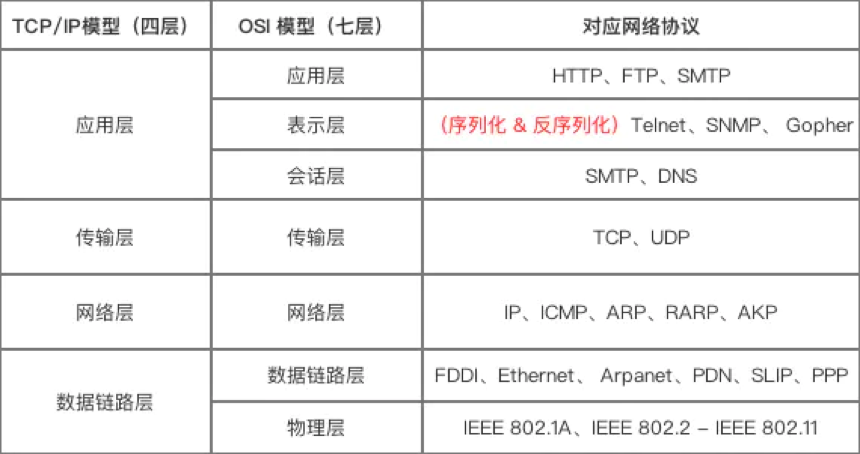
序列化是把應用層的對象轉換為二進制串,反序列化是把二進制串轉化成應用層的對象。
1.2 Protobuf 的優點
1)跨語言,跨平台
Protobuf 和語言,平台無關,定義好 pb 文件之后,對於不同的語言使用不同的語言的編譯器對 pb 文件進行編譯即可,編譯完成之后就會提供對應語言能夠使用的接口,通過這些接口就可以訪問在 pb 文件中定義好的內容了。
2)性能優越
Protobuf 十分高效,無論是在數據存儲還是通信性能都非常好,序列化的體積很小,序列化的速度也很快,關於這一點會在后面第 3 節序列化原理章節中做詳細的介紹。
3)兼容性好
Protobuf 的兼容性特別好,當我們更新數據的時候不會影響原有的程序,例如 int32 和 int64 是兩種不同的類型,存儲的數據占用的字節數也不同,但是如果現在需要存儲一個負數,采用 Varints 編碼時,它們都會占用固定的十個字節,這是為了防止用戶在將 int64 改為 int32 時會影響原有的程序。關於這方面的內容,在第3節也會做詳細的介紹。
1.3 Protobuf, JSON, XML 的區別
Protobuf 和 JSON,XML 既有相似點又有不同點,從數據結構化和數據序列化兩個維度去進行比較可能會更直觀一些。
數據結構化主要面向開發和業務層面,數據序列化主要面向通信和存儲層面。當然數據序列化也需要結構和格式,所以這兩者的區別主要在於應用領域和場景不同,因此要求和側重點也會有所不同。
數據結構化更加側重於人類的可讀性,強調語義表達能力,而數據序列化側重效率和壓縮。
接下來從這兩個維度出發,我們進行一些簡單的分析。
XML 作為一種可擴展標記語言,JSON 作為源於 JS 的數據格式,都具有數據結構化的能力。
例如 XML 可以衍生出 HTML(雖然 HTNL 早於 XML,但從概念上講,HTML 只是預定義標簽的 XML),HTML 的作用是標記和表達萬維網中資源的結構,以便瀏覽器更好地展示萬維網資源,同時也要盡可能保證其人類可讀以便開發人員進行開發,這是面向業務或開發層面的數據結構化。
再如 XML 還可衍生出 RDF/RDFS,進一步表達語義網中資源的關系和語義,同樣它強調數據結構化的能力和人類可讀。
JSON 也是同理,在很多場景下更多的是體現了數據結構化的能力,例如作為交互接口的數據結構的表達。
當然,JSON 和 XML 同樣也可以直接被用來數據序列化,實際上很多時候它們也是被這么使用的,例如直接采用 JSON,XML 進行網絡通信傳輸,此時 XML 和 JSON 就成了一種序列化格式,發揮了數據序列化的能力。
但是我們平時開發的時候經常會這么用並不代表就是合理的,或者說是最好的。實際上,將 JSON 和 XML 直接數據序列化進行網絡傳輸通常並不是最優的選擇。因為它們在速度、效率,占用空間上都並不是最優的。換句話說它們更適合數據結構化而不是數據序列化。但是如果從這兩方面綜合考慮或許我們平時的選擇又是合理的。
Protobuf 在數據結構化方面可能沒有那么突出,但是在數據序列化方面,你會發現 Protobuf 具有明顯的優勢,效率,速度,空間幾乎全面占優,這一部分將會在第 3 節編解碼部分做出詳細的闡述。
稍微做一個小的總結:
1)XML、JSON、Protobuf 都具有數據結構化和序列化的能力;
2)XML、JSON 更注重數據結構化,關注人類可讀性和語義表達能力,Protobuf 更注重數據序列化,關注效率,空間,速度。
3)Protobuf 的應用場景更為明確,一般是在傳輸數據量較大,RPC 服務數據數據傳輸,XML、JSON 的應用場景更為豐富,傳輸數據量較小,在 MongoDB 中采用 JSON 作為查詢語句,也是在發揮其數據結構化的能力。
2. Protobuf 基本語法
2.1 pb 文件的構成
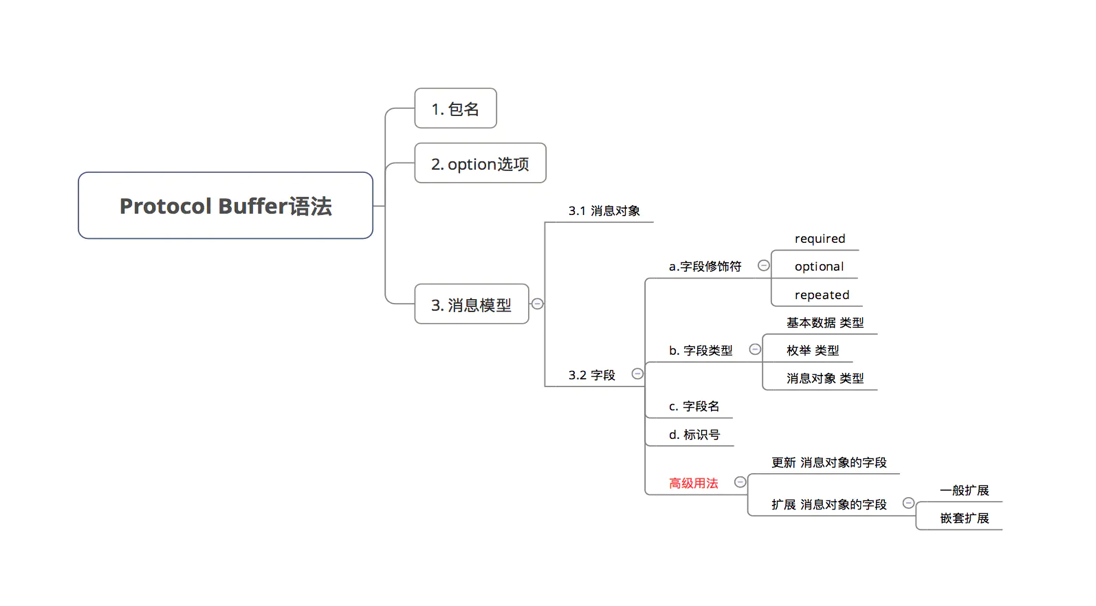
1)包名
作用:防止不同的 .proto 項目間命名發生沖突。
Protobuf 包的解析過程如下:
- protobuf 的類型名稱解析與 C++ 一致:從最內部開始查找,依次向外進行,每個包會被看作是父類包的內部類
- Protobuf 編譯器會解析
.proto文件中定義的所有類型名 - 生成器會根據不同語言生成對應語言的代碼文件
2)option 選項
作用:影響特定環境下的處理方式
常用的 option 選項如下:
// 定義: Java 包名
// 作用: 指定生成的類應該放在什么 Java 包名下
// 注意: 如果不顯示指定,默認包名為: 按照應用名稱倒序方式進行排序
option java_package="com.tencent.trpcprotocol.tde.provider.provider";
option java_outer_classname = "Demo";
// 定義:類名
// 作用:生成對應.java 文件的類名(不能跟下面message的類名相同)
// 注:如不顯式指定,則默認為把.proto文件名轉換為首字母大寫來生成
// 如.proto文件名="my_proto.proto",默認情況下,將使用 "MyProto" 做為類名
option optimize_for = ***;
// 作用:影響 C++ & java 代碼的生成
// ***參數如下:
// 1. SPEED (默認)::protocol buffer編譯器將通過在消息類型上執行序列化、語法分析及其他通用的操作。(最優方式)
// 2. CODE_SIZE::編譯器將會產生最少量的類,通過共享或基於反射的代碼來實現序列化、語法分析及各種其它操作。
// 特點:采用該方式產生的代碼將比SPEED要少很多, 但是效率較低;
// 使用場景:常用在 包含大量.proto文件 但 不追求效率 的應用中。
//3. LITE_RUNTIME::編譯器依賴於運行時 核心類庫 來生成代碼(即采用libprotobuf-lite 替代libprotobuf)。
// 特點:這種核心類庫要比全類庫小得多(忽略了 一些描述符及反射 );編譯器采用該模式產生的方法實現與SPEED模式不相上下,產生的類通過實現 MessageLite接口,但它僅僅是Messager接口的一個子集。
// 應用場景:移動手機平台應用
option cc_generic_services = false;
option java_generic_services = false;
option py_generic_services = false;
// 作用:定義在C++、java、python中,protocol buffer編譯器是否應該 基於服務定義 產生 抽象服務代碼(2.3.0版本前該值默認 = true)
// 自2.3.0版本以來,官方認為通過提供 代碼生成器插件 來對 RPC實現 更可取,而不是依賴於“抽象”服務
optional repeated int32 samples = 4 [packed=true];
// 如果該選項在一個整型基本類型上被設置為真,則采用更緊湊的編碼方式(不會對數值造成損失)
// 在2.3.0版本前,解析器將會忽略 非期望的包裝值。因此,它不可能在 不破壞現有框架的兼容性上 而 改變壓縮格式。
// 在2.3.0之后,這種改變將是安全的,解析器能夠接受上述兩種格式。
optional int32 old_field = 6 [deprecated=true];
// 作用:判斷該字段是否已經被棄用
// 作用同 在java中的注解@Deprecated
3)消息對象
作用:用於描述數據結構
一個消息對象(Message)可以看作一個結構化數據,消息對象(Message)里的字段可以看作結構化數據里的成員變量。
消息對象GetProxyEnvReq:
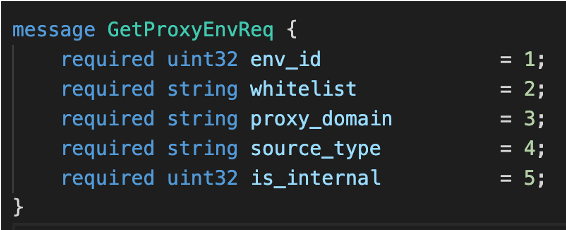
對應 JS 中的一個對象 getProxyEnvReq:
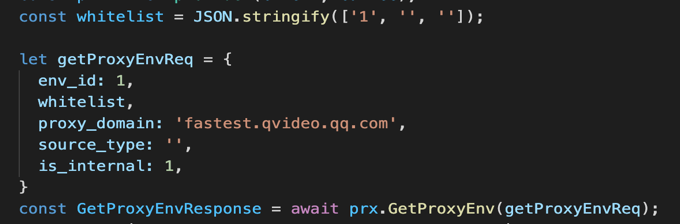
下面將詳細介紹一下消息對象。
2.2 消息對象
在 Protobuf 中,消息對象用 message 修飾,一個消息對象由多個字段構成。
消息對象中字段的構成格式:
字段修飾符 字段類型 字段名 = 字段標識號;
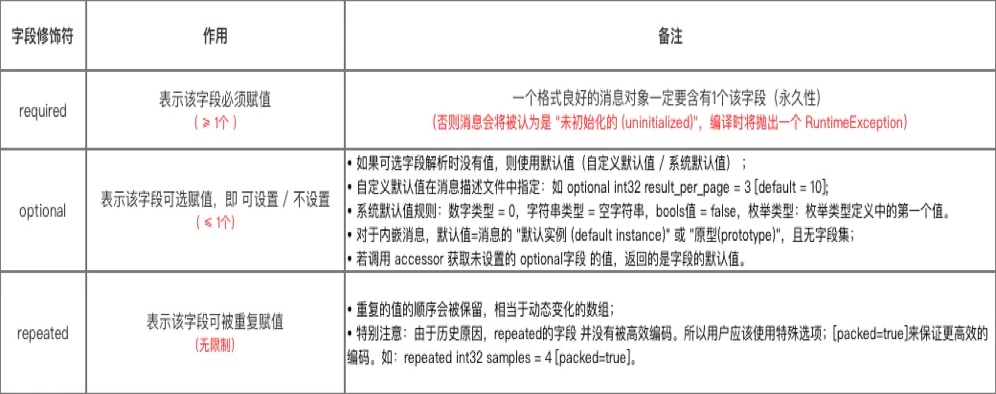
2.2.1 字段修飾符
作用:設置該字段解析時的規則。
注:Protobuf 現在主要有兩個版本,proto2 和 proto3。在 proto3 中如果不寫字段修飾符默認就是 optional。
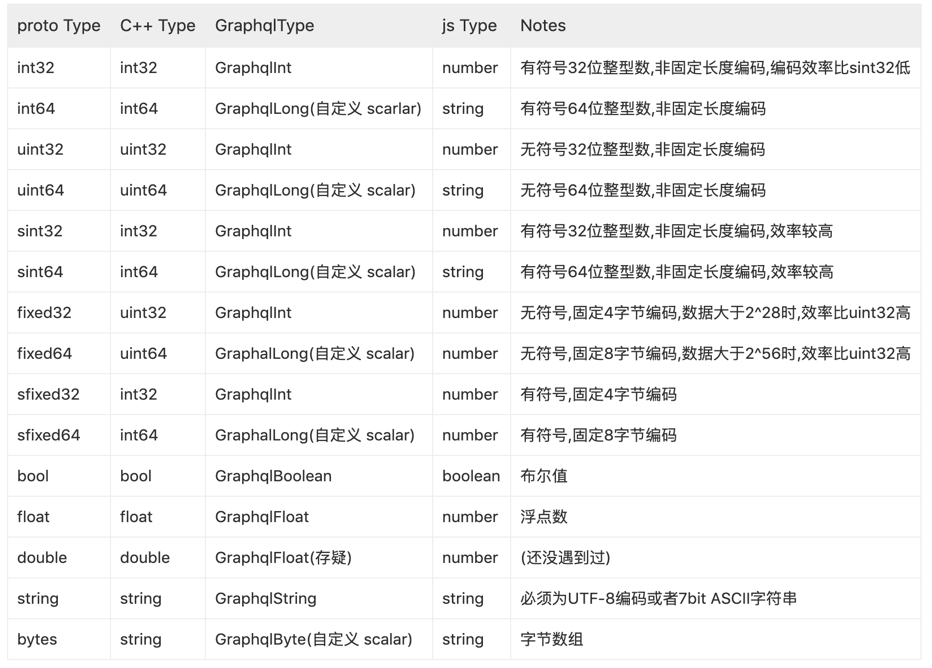
2.2.2 字段類型
1)基本數據類型
Protobuf 中的基本數據類型可以轉換為其它編程語言中對應的數據類型。
下圖來自 bff-service 項目
2)枚舉類型
作用:為字段指定一個可能取值的字段集合。
注意 Protobuf 中默認值的設置方式。
枚舉類型的定義可在一個消息對象的內部或外部,當枚舉類型是在一消息內部定義,希望在另一個消息中使用時,需要采用 MessageType.EnumType 的格式。
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
// 使用枚舉類型
message PhoneNumber {
PhoneType type = 1 [default = HOME] // 設置PhoneType的默認值為HOME
}
當對一個使用了枚舉類型的 .proto 文件使用 Protobuf 編譯器編譯時,生成的代碼文件中,對於 Java 或 C++ 來說,將有一個對應的 enum 文件,對於 Python 來說,會有一個特殊的 EnumDescriptor 類。
3)消息對象類型
一個消息對象可以作為其它消息對象模型中的字段的類型來使用的,一個消息消息對象本身也是一種類型。
消息對象類型的使用非常靈活
- 使用內部的消息對象
message Person {
string name = 1;
int32 id = 2;
string email = 3;
message PhoneNumber {
required string number = 1;
}
repeated PhoneNumber phone = 4;
}
- 使用外部的消息對象
message People {
string name = 1;
uint32 id = 2;
string email = 3;
}
message AddressBook {
repeated Person person = 1;
}
- 使用外部消息對象的內部消息對象類型
message Person {
string name = 1;
uint32 id = 2;
string email = 3;
message PhoneNumber {
string number = 1;
PhoneType type = 2 [default = HOME];
}
}
message OtherMessage {
Person.PhoneNumber phonenumber = 1;
}
- 使用不同 pb 文件里的消息類型
目的:需要在 A.proto 中使用 B.proto 文件里的消息類型。
解決方案:在 A.proto 文件中通過導入 B.proto 文件來使用 B.proto 文件里的消息類型。
import 'myproject/other_protos_proto';
// 在A.proto 文件中添加 B.proto文件路徑的導入聲明
// ProtocolBuffer編譯器 會在 該目錄中 查找需要被導入的 .proto文件
// 如果不提供參數,編譯器就在 其調用的目錄下 查找
2.2.3 標識號
作用:通過數字唯一標識一個字段
標識號的作用范圍是 [1, 2^29 - 1],不可以使用 [19000 - 19999] 的標識號,因為 Protobuf 協議實現中對這些標識號進行了預留。
每個字段在進行編碼時都會占用內存,而占用內存大小取決於標識號:
范圍 [1,15] 標識號的字段在編碼時占用1個字節,范圍在 [16, 2047] 標識號的字段在編碼時占用 2 個字節。
使用建議:
-
為頻繁出現的消息字段使用[1, 15]標識號
-
為將來可能添加、頻繁出現的消息字段預留[1, 15]標識號
2.3 使用 protobuf 編譯器編譯 pb 文件
根據上面介紹的語法,pb 文件我們已經寫好了,現在假設想要進行編程就需要通過 protobuf 編譯器將 .proto 文件編譯成對應平台的代碼文件。
如果現在是在用 trpc-node 進行開發,可以使用 trpc-tools-codec 這個編譯工具進行編譯,生成的代碼文件如下:
.
├── proto
│ ├── helloworld-dispatcher.ts ---- 協議文件生成的 server 端橋接代碼
│ ├── helloworld-imp.ts ---- 協議文件生成的 server 端腳手架代碼
│ ├── helloworld-proxy.ts ---- 協議文件生成的 client 端代理代碼
│ ├── helloworld.d.ts ---- 協議文件生成的 codec 代碼 for ts
│ ├── helloworld.js ---- 協議文件生成的 codec 代碼
│ └── helloworld.proto ---- 協議文件
利用這些生成的代碼文件我們就可以進行編寫 trpc 服務了。
3. Protobuf 序列化原理
3.1 Protobuf 編碼結構
protobuf 數據存儲采用 Tag-Length-Value 即標識 - 長度 - 字段值存儲方式,以標識 - 長度 - 字段值表示單個字段,最終將數據拼接成一個字節流,從而實現數據存儲的功能。
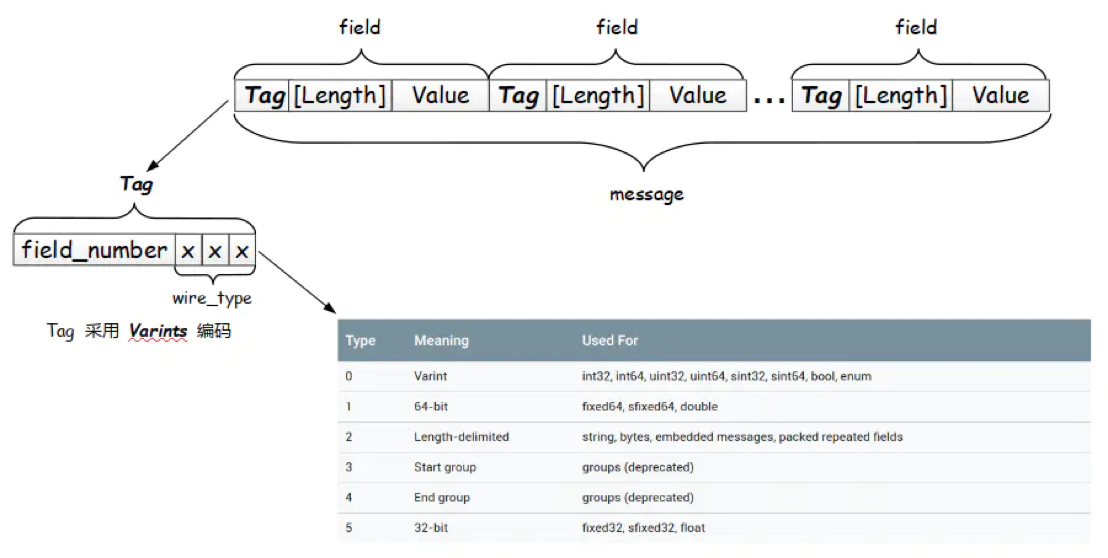
可以看到當采用 T - L - V 的存儲結構時不需要分隔符就能分隔開字段,各字段存儲地非常緊湊,存儲空間利用率非常高。
此外如果某字段沒有被設置字段值,那么該字段在序列化時是完全不存在的,即不需要編碼,這個字段在解碼時才會被設置默認值。
接下來重點介紹一下每個字段中都存在的 Tag。
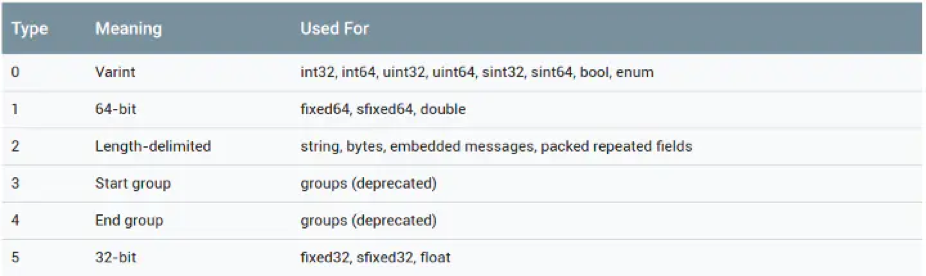
Tag 由 field_number 和 wire_type 兩部分組成,其中 field_number 是字段的標識號,wire_type 是一個數值,根據它的數值可以確定該字段的字段值需要采用的編碼類型。
// Tag 的具體表達式如下
Tag = (field_number << 3) | wire_type;
// 參數說明:
// field_number:對應於 .proto文件中消息字段的標識號,表示這是消息里的第幾個字段
// 原來的field_number需要左移三位再拼接上wire_type就會得出Tag,所以真正的field_number是將Tag右移三位后的值
// field_number << 3:表示 field_number = 將 Tag的二進制表示右移三位后的值
// field_num左移3位不會導致數據丟失,因為表示范圍還是足夠大地去表示消息里的字段數目
// wire_type:表示 字段 的數據類型
// wire_type = Tag的二進制表示 的最低三位值
// wire_type 的取值
enum WireType {
WIRETYPE_Varint = 0,
WIRETYPE_FIXED64 = 1,
WIRETYPE_LENGTH_DELIMITED = 2,
WIRETYPE_START_GROUP = 3,
WIRETYPE_END_GROUP = 4,
WIRETYPE_FIXED32 = 5
};
// 從上面可以看出,`wire_type` 最多占用 3 位的內存空間(因為3位足以表示 0-5 的二進制)
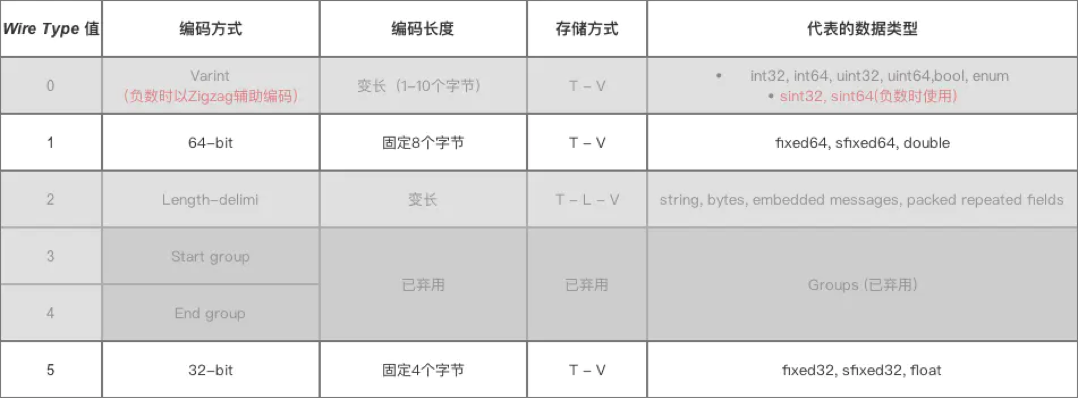
wire_type 占 3 bit,最多可以表達 8 種編碼類型,目前 Protobuf 已經定義了 6 種(Start group 和 End group 已經被廢棄掉了),如下圖所示。
每個字段根據不同的編碼類型會有下面兩種編碼格式:
- Tag - Length - Value: 編碼類型表中 Type = 2,即 Length - delimited 編碼類型將使用這種結構
- Tag - Value: 編碼類型表中 Varint,64-bit,32-bit 將使用這種結構
接下來就來詳細地介紹一下各種編碼類型。
3.2 Varint 編碼
Varint 編碼是一種變長的編碼方式,用字節表示數字,值越小的數字,使用越少的字節數表示。它通過減少表示數字的字節數從而進行數據壓縮。
3.2.1 Varint 編碼規則
部分源碼:
private void writeVarint32(int n) {
int idx = 0;
while (true) {
if ((n & ~0x7F) == 0) {
i32buf[idx++] = (byte)n;
break;
} else {
i32buf[idx++] = (byte)((n & 0x7F) | 0x80);
// 步驟1:取出字節串末7位
// 對於上述取出的7位:在最高位添加1構成一個字節
// 如果是最后一次取出,則在最高位添加0構成1個字節
n >>>= 7;
// 步驟2:通過將字節串整體往右移7位,繼續從字節串的末尾選取7位,直到取完為止。
}
}
trans_.write(i32buf, 0, idx);
// 步驟3: 將上述形成的每個字節 按序拼接 成一個字節串
// 即該字節串就是經過Varint編碼后的字節
}
從步驟 1 中可以看出,Varint 編碼中每個字節的最高位都有特殊的含義:
- 如果是 1,表示后續的字節也是該數字的一部分,需要繼續讀取
- 如果是 0,表示這是最后一個字節,且剩余 7 位都用來表示數字
所以,當使用 Varint 編碼時,只要讀取到最高位為 0 的字節時,就表示已經是 Varint 的最后一個字節了。
可以簡單地將 Varint 的編碼規則歸結為以下三點:
1)在每個字節開頭的 bit 設置了 msb(most significant bit),標識是否需要繼續讀取下一個字節
2)存儲數字對應的二進制補碼
3)補碼的低位排在前面
補碼的計算方法:
對於正數,原碼和補碼相同
對於負數,最高位符號位不變,其它位按位取反然后加 1
3.2.2 Varint 編碼示例
接下來通過一個示例來說明一下 Varint 編碼的過程
示例 1
int32 a = 8;
- 原碼:0000 ... 0000 1000
- 補碼:0000 ... 0000 1000
- 根據 Varint 編碼規則,從低位開始取 7 bit,000 1000
- 當取出前 7 bit 后,前面所有的位就都是 0 了,不需要繼續讀取了,因此設置 msb 位為 0 即可
- 所以最終 Varint 編碼為 0000 1000
可以看到在使用 Varint 編碼后只使用一個字節就可以了,而正常的 int32 編碼一般需要 4 個字節。
仔細體會上述的 Varint 編碼,我們可以發現 Varint 編碼本質實際上是每個字節都犧牲了一個 bit 位,來表示是否已經結束(是否需要繼續讀取下一個字節),msb 實際上就起到了 length 的作用,正因為有了這個 msb 位,所以我們可以擺脫原來那種無論數字大小都必須分配四個字節的窘境。
通過 Varint 編碼對於比較小的數字可以用很少的字節進行表示,從而減小了序列化后的體積。
但是由於 Varint 編碼每個字節都要拿出一位作為 msb 位,因此每個字節就少了一位來表示字段值。那這就意味着四個字節能表達的最大數字是為 2^28 而不是 2^32 了。
所以如果當數字大於 2^28 時,采用 Varint 編碼將導致分配 5 個字節,原先明明只需要 4 個字節。此時 Varint 編碼的效率不僅沒有提高反而是下降了。
但是這並不影響 Varint 編碼在實際應用時的高效,因為事實證明,在大多數情況下,數字在 2^28 ~ 2^32 出現的概率要遠遠小於 0 ~ 2^28 出現的概率。
示例 2
這樣看來 Varint 編碼似乎很完美,但是有一種情況下,Varint 編碼的效率很低。上面的例子中只給出了正數的情況,思考如果是負數的情況呢。
我們知道負數的二進制表示中最高位是符號位 1,這一點意味着負數都必須占用所有字節。
我們還是通過一個示例來體會一下。
int32 a = -1
- 原碼:1000 ... 0000 0001
- 補碼:1111 ... 1111 1111
- 根據 Varints 編碼規則,從低位開始取 7 bit,111 1111,由於前面還有 1 需要讀取,因此需要設置 msb 位為 1,然后將這個字節放在 Varint 編碼的高位。
- 依次類推,有 9 組(字節)都是 1,這 9 組的 msb 均為 1,最后一組只有 1 位是 1,由於已經是最后一組了不需要再繼續讀取了,因此這組的 msb 位應該是 0.
- 因此最終的 Varint 編碼是 1111 1111 ... 0000 0001(FF FF FF FF FF FF FF FF FF 01 )
可能大家會有疑問為什么會占用 10 個字節呢?
這是 Protobuf 基於兼容性考慮,例如當開發者將 int64 改為 int32 后應該不影響舊程序,所以將 int32 擴展為 int64 的八個字節。
可能大家還會有疑問為什么對於正數的時候不需要進行類似的兼容處理呢?
實際上當要編碼的是正數時,int32 和 int64 是天然兼容的,他們兩個的編碼過程是完全一樣的,利用 msb 位去控制最終的 Varint 編碼長度即可。
所以目前的情況是我們定義了一個 int32 類型的變量,如果將變量的值設置為 負數,如果直接采用 Varint 編碼的話,其編碼結果將總是占用十個字節,這顯然不是我們希望得到的結果。那么我們應該如何去解決呢?
答案就是下面的 Zigzag 編碼。
3.3 Zigzag 編碼
在 Protobuf 中 Zigzag 編碼的出現主要是為了解決 Varint 編碼負數效率低的問題。
基本原理就是將有符號正數映射成無符號整數,然后再使用 Varint 編碼,這里所說的映射是通過移位的方式實現的並不是通過存儲映射表。
3.3.1 Zigzag 編碼規則
部分源碼:
public int int_to_Zigzag(int n) {
// 傳入的參數n = 傳入字段值的二進制表示(此處以負數為例)
// 負數的二進制 = 符號位為1,剩余的位數為該數絕對值的原碼按位取反;然后整個二進制數+1
return (n <<1) ^ (n >>31);
}
// 解碼
public int Zigzag_to_int(int n) {
return (n >>> 1) ^ -(n & 1);
}
根據上面的源碼我們可以得出 Zigzag 的編碼過程如下:
- 將補碼左移 1 位,低位補 0,得到 result1
- 將補碼右移 31 位,得到 result2
- 首位是 1 的補碼(有符號數)是算數右移,即右移后左邊補 1
- 首位是 0 的補碼(無符號數)是邏輯右移,即右移后左邊補 0
- 將 result1 和 result2 異或
3.3.2 Zigzag 編碼示例
下面通過一個示例來演示一個 Zigzag 的編碼過程
sint32 a = -2
- 原碼:1000 ... 0010
- 補碼:1111 ... 1110
- 左移一位(算數右移)result1:1111 ... 1100
- 右移31位result2:1111 ... 1111
- 異或: 0000 ... 0011(3)
編碼過程示意圖如下:
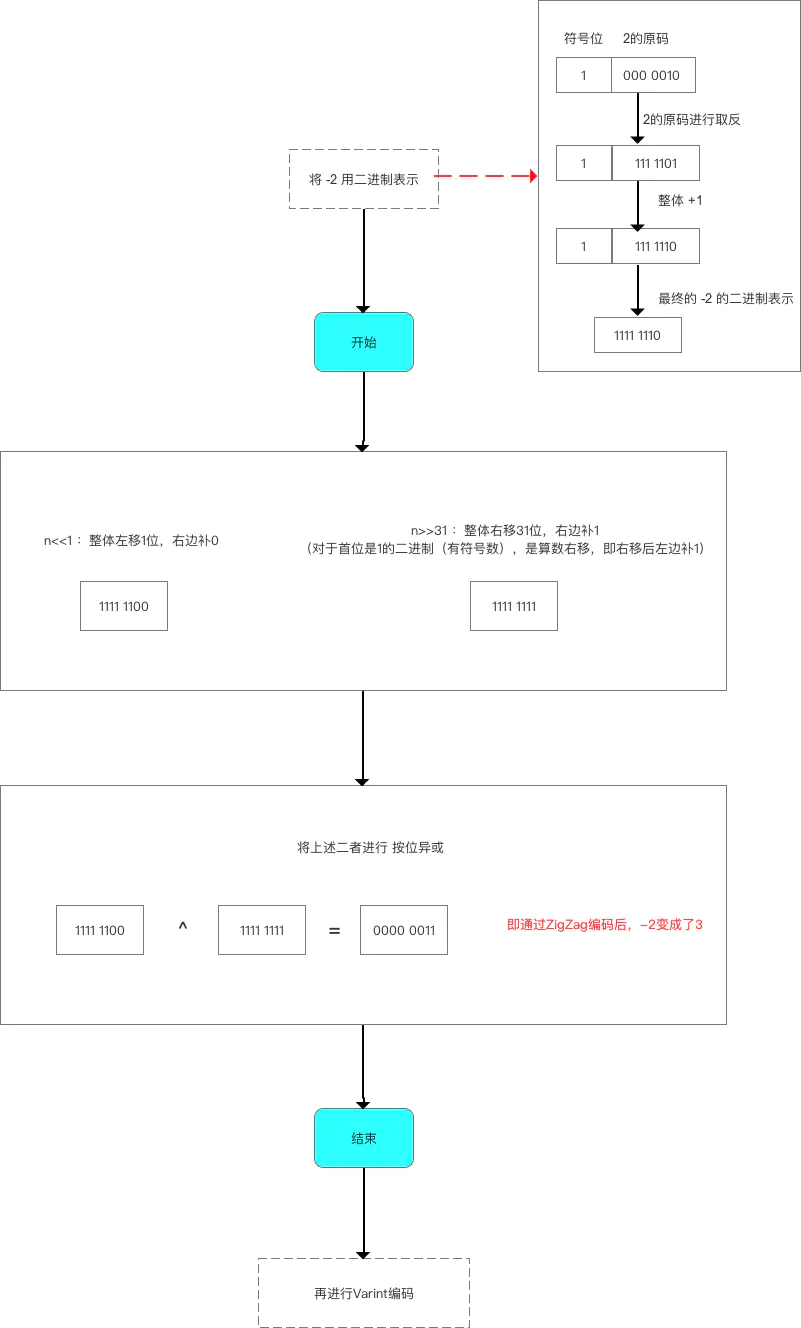
可以看到 -2 經過 Zigzag 編碼之后變成了正數 3,這時再通過 Varint 編碼就很高效了,在接收端先通過 Varint 解碼得到數字 3,然后再通過 Zigzag 解碼就可以得到原始發送的數據 -2 了。
因此在定義字段時如果知道該字段的值有可能是負數的話,那么建議使用 sint32/sint64 這兩種數據類型。
3.4 64-bit(32-bit)編碼
64-bit 和 32-bit 的編碼方式比較簡單,64-bit 編碼后是固定的 8 個字節,32 bit 編碼后是固定的 4 個字節。當數據類型是 fixed64,sfixed64,double 時將采用 64-bit 編碼方式,當數據類型是 fixd32,sfixed64,float 時將采用 32-bit 編碼方式。
注意這兩種編碼方式都是補碼的高位放到編碼后的低位。
它們都采用的是 T - V 的存儲方式。
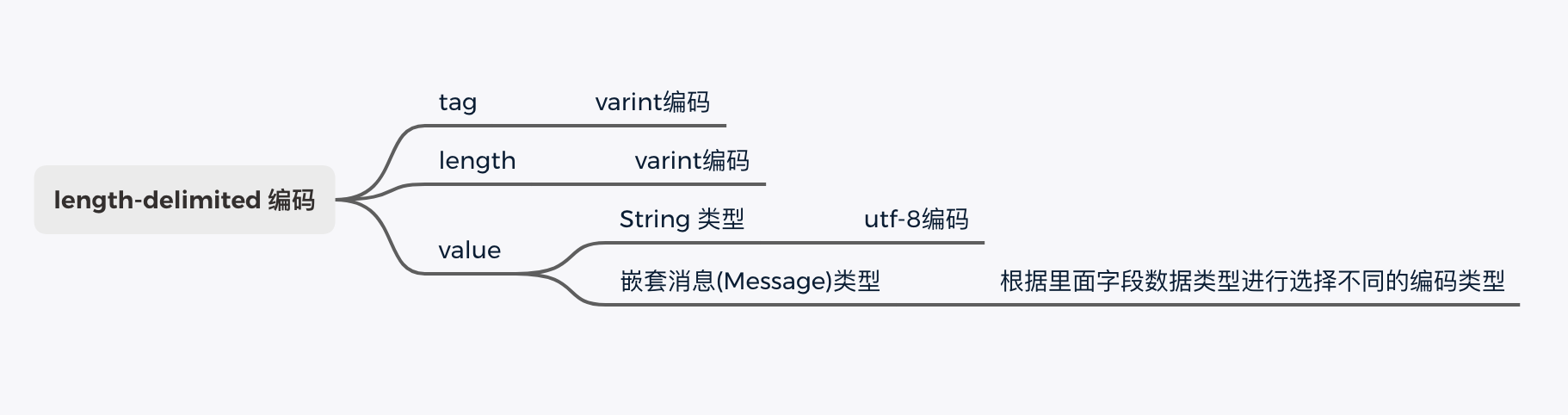
3.5 length-delimited
這是 Protobuf 中唯一一個采用 T - L - V 的存儲方式。如下圖所示,Tag 和 Length 仍然采用 Varint 編碼,對於字段值根據不同的數據類型采用不同的編碼方式。
例如,對於 string 類型字段值采用的是 utf-8 編碼,而對於嵌套消息數據類型會根據里面字段的類型選擇不同的編碼方式。
接下來重點說一下嵌套消息數據類型是如何進行編碼的。
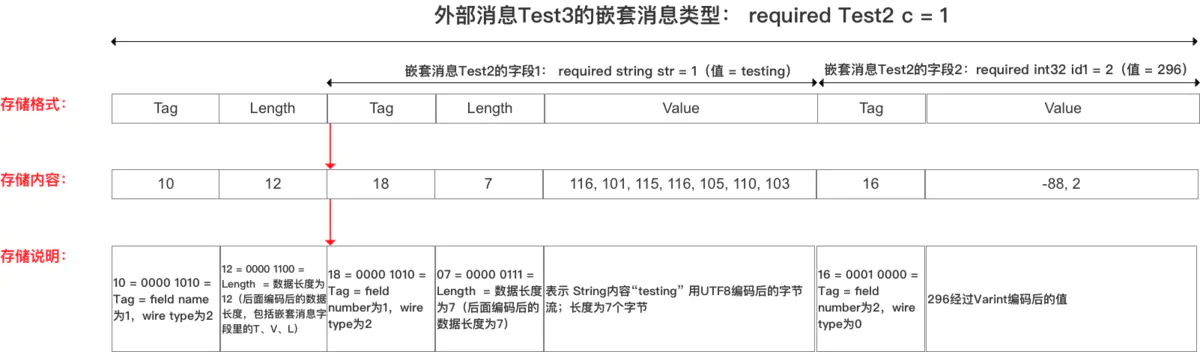
通過下面的示例來說明,在 Test3 這個 Message 對象中的 c 字段的類型是一個消息對象 Test2,並且將 Test2 中字段 str 的值設置為 testing,將字段 id1 的值設置為 296.
message Test2 {
required string str = 1;
required int32 id1 = 2;
}
message Test3 {
required Test2 c = 1
}
// 將Test2中的字段str設置為:testing
// 將Test2中的字段id1設置為:296
// 編碼后的字節為:10 ,12 ,18,7,116, 101, 115, 116, 105, 110, 103,16,-88,2
那么編碼后的存儲方式如下:
3.6 序列化過程
Protobuf 的性能非常優越主要體現在兩點,其中一點就是序列化后的體積非常小,這一點在前面編解碼的介紹中已經體現出來了。還有另外一點就是序列化速度非常快,接下來就簡單地介紹一下為什么序列化的速度非常快。
Protobuf 序列化的過程簡單來說主要有下面兩步
- 判斷每個字段是否有設置值,有值才進行編碼,
- 根據 tag 中的 wire_type 確定該字段采用什么類型的編碼方案進行編碼即可。
Protobuf 反序列化過程簡單來說也主要有下面兩步:
- 調用消息類的 parseFrom(input) 解析從輸入流讀入的二進制字節數據流
- 將解析出來的數據按照指定的格式讀取到相應語言的結構類型中
Protobuf 的序列化過程中由於編碼方式簡單,只需要簡單的數學運算位移即可,而且采用的是 Protobuf 框架代碼和編譯器共同完成,因此序列化的速度非常快。
可能這樣並不能很直觀地展現出 Protobuf 序列化過程非常快,接下來我們簡單介紹一下 XML 的反序列化過程,通過對比我們就能清晰地認識到 Protobuf 序列化的速度是非常快的。
XML 反序列化的過程大致如下:
- 從文件中讀取出字符串
- 從字符串轉換為 XML 文檔對象模型
- 從 XML 文檔對象結構模型中讀取指定節點的字符串
- 將該字符串轉換成指定類型的變量
從上述過程中,我們可以看到 XML 反序列化的過程比較繁瑣,而且在第二步,將 XML 文件轉換為文檔對象模型的過程是需要詞法分析的,這個過程是比較耗費時間的,因此通過對比我們就可以感受到 Protobuf 的序列化的速度是非常快的。
4. 使用建議
接下來結合上面所提到的一些知識,簡單給出一些在使用 Protobuf 時的一些小建議。
1)如果有負數,那么盡量使用 sint32/sint64 ,不要使用 int32/int64,因為采用 sin32/sin64 數據類型表示負數時,根據前面的介紹可以知道會先采用 Zigzag 將負數通過移位的方式映射為正數, 然后再使用 Varint 編碼,這樣就可以有效減少存儲的字節數。
2)字段標識號的時候盡量只使用 1~15,並且不要跳動使用。因為如果超過 15,那么 Tag 在編碼時就會占用更多的字節。如果將字段標識號定義為連續遞增的數值,將會獲得更好的編碼性能和解碼性能。
3)盡量多地使用 optional 或 repeated 修飾符(在 proto3 版本中默認是 optional),因為使用這兩個修飾符后如果不設置值,在序列化時是不進行編碼的,默認值會在反序列化時自動添加。
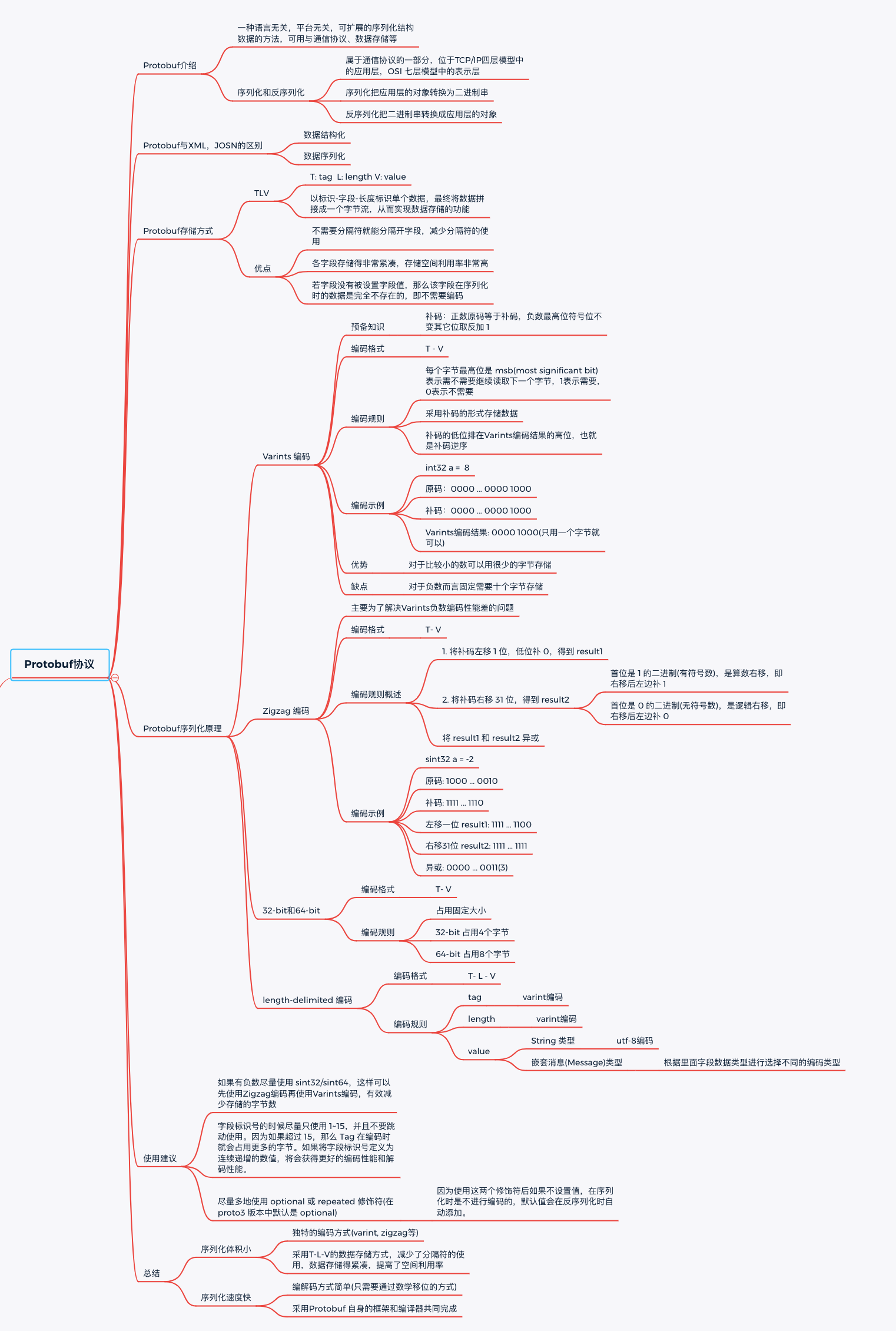
5. 總結