背景介紹
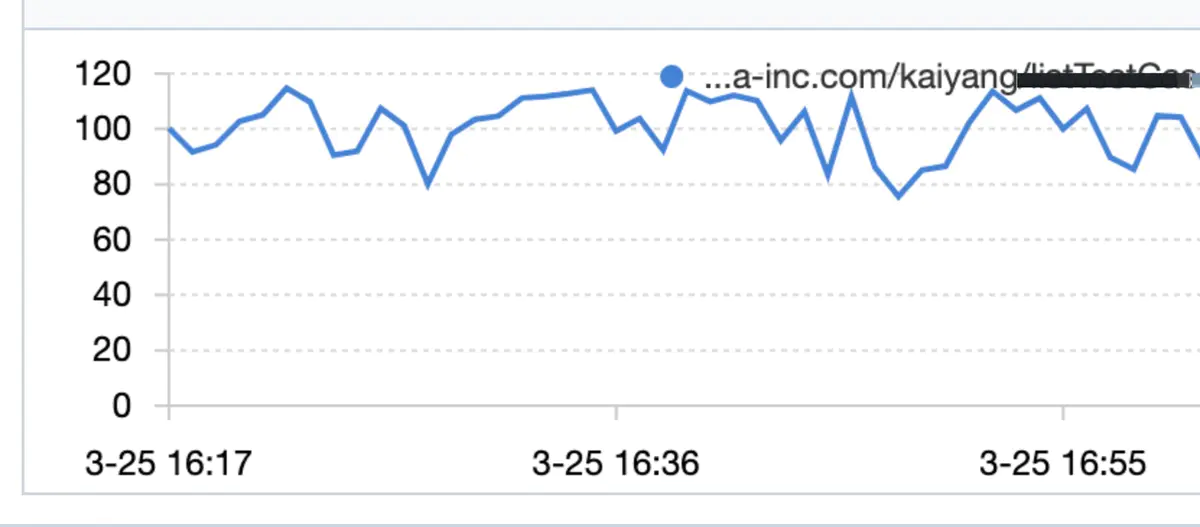
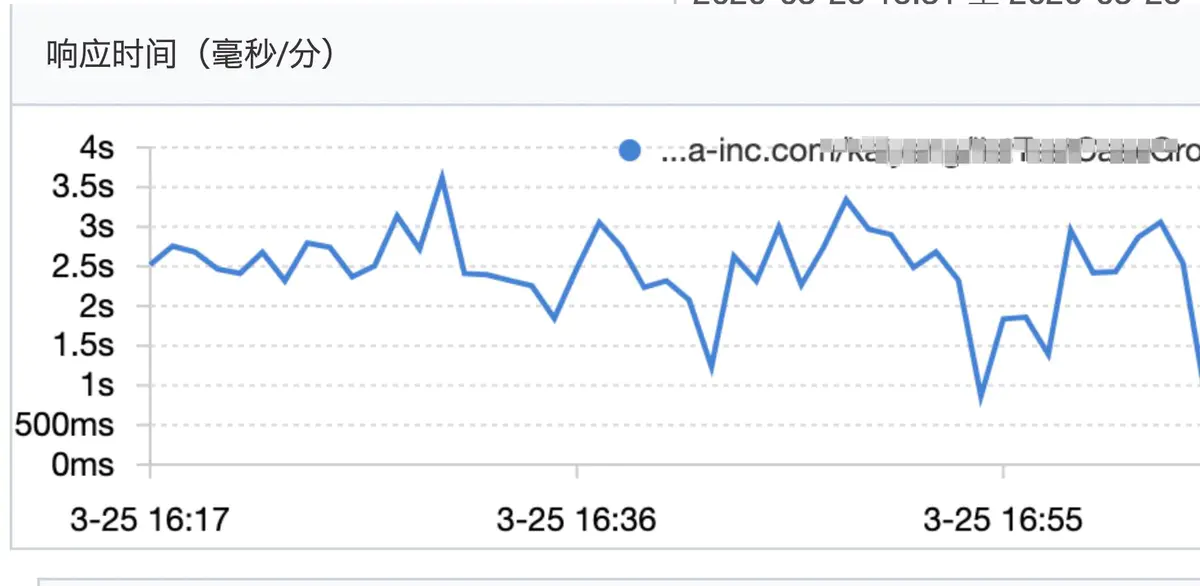
某日下午大約四點多,接到合作方消息,線上環境,我這邊維護的某http服務突然大量超時(對方超時時間設置為300ms),我迅速到鷹眼平台開啟采樣,發現該服務平均QPS到了120左右,平均RT在2秒多到3秒,部分毛刺高達5到6秒(正常時候在60ms左右)。
qps情況:
rt情況
問題解決
該服務是一個對內的運營平台服務(只部署了兩台docker)預期qps個位數,近期沒做過任何的線上發布,核心操作是整合查詢數據庫,一次請求最多涉及40次左右的DB查詢,最終查詢結果為一個多層樹形結構,一個響應體大約50K。之前口頭跟調用方約定要做緩存,現在看到QPS在120左右,(QPS證明沒有做緩存),遂要求對方做緩存,降低QPS。后QPS降到80以內,rt恢復正常(平均60ms),最終QPS一直降到40(后續需要推動調用方上緩存,保證QPS在個位數)。
問題定位
由於該服務核心操作是查詢數據庫,且一次請求有40次DB query,遂首先排查是否慢sql導致,查看db性能監控,發現db 平均rt在0.3ms以內,可以算出來DB整體耗時在12ms左右,排除慢sql導致RT變高。
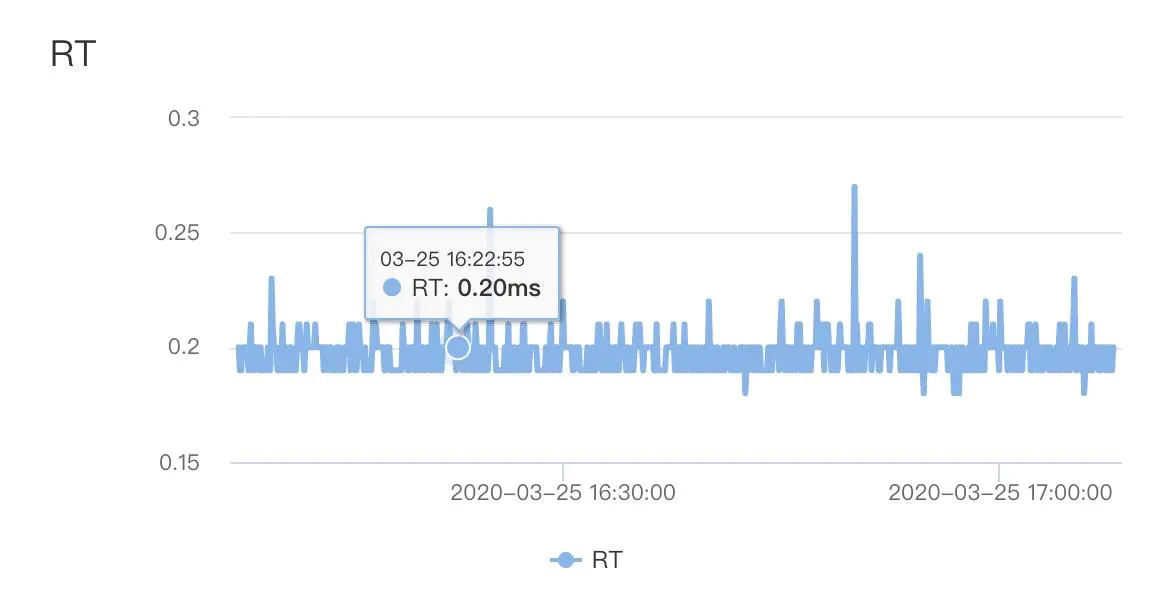
開始懷疑,是否DB連接池在高並發下出現排隊,tddl默認的連接池大小是10.一查監控,整個占用的連接數從來沒有超過7個,排除連接池不足的問題。
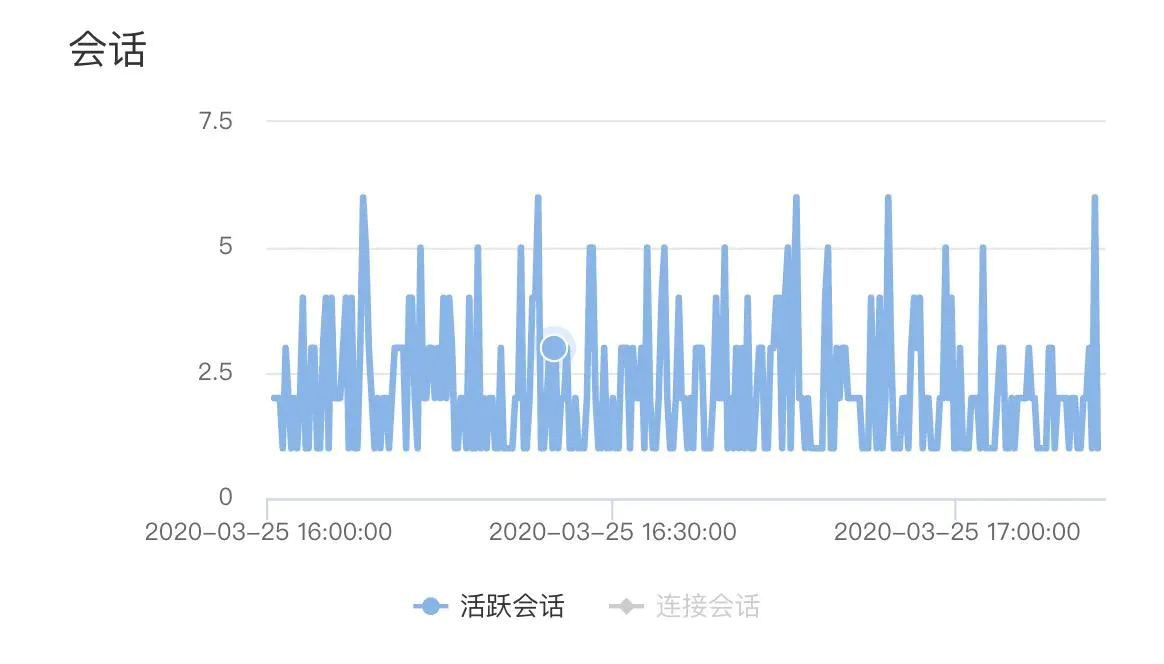
至此,造成RT高的原因,在數據庫層面被排除。
接着開始查采樣到的服務調用鏈上的每一個執行點,看看到底是調用鏈上的那部分耗時最多。發現里面很多執行點都有一個特點,就是本地調用耗時特別長(幾百毫秒),但是真正的服務調用(比如db查詢動作)時間卻很短,(0ms代表執行時間小於1ms,也間接印證之前db的平均RT在0.3ms以內)
本地調用耗時: 267ms
客戶端發送請求: 0ms
服務端處理請求: 0ms
客戶端收到響應: 1ms
總耗時: 1ms
這時候問題逐漸清晰,問題出現在本地方法執行的耗時過長,可是再次檢查該服務所有代碼,並沒有需要長耗時的本地執行邏輯,那么繼續看CPU的load情況。
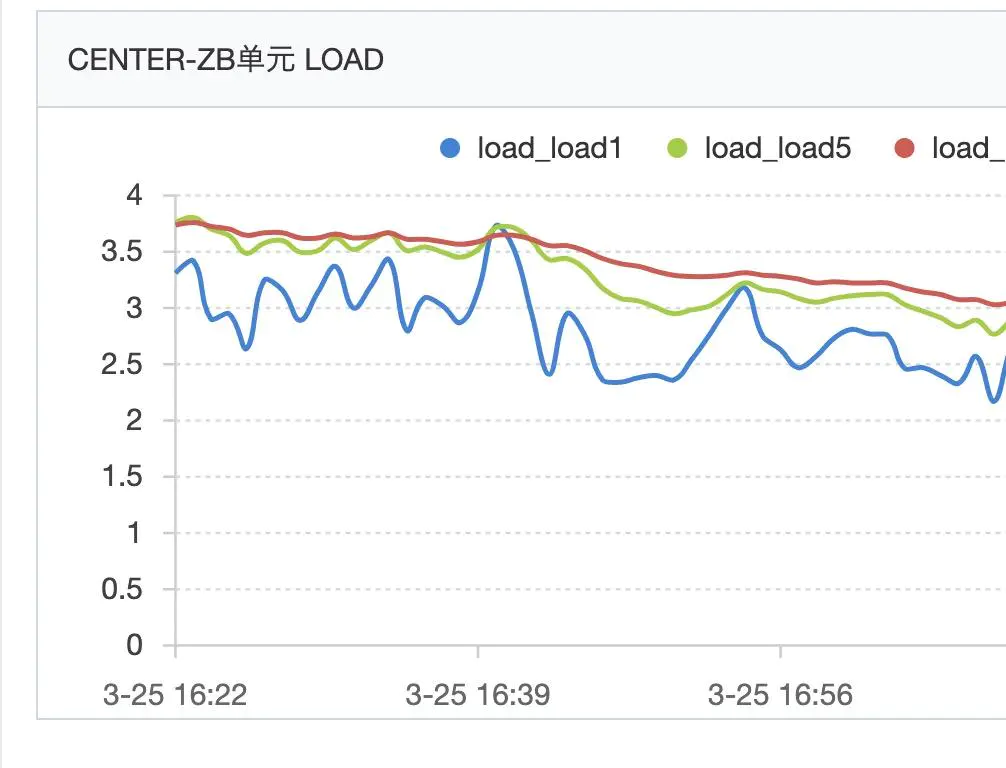
load長時間在4左右徘徊,我們的docker部署在4c8G的宿主機上,但是我們不能獨占這個4C的,持續這么高的load已經不正常了。
繼續追查cpu load飆高的原因,接着去看GC日志,發現大量的Allocation Failure,然后ParNew次數在每分鍾100次以上,明顯異常,見下GC日志例子
2020-03-25T16:16:18.390+0800: 1294233.934: [GC (Allocation Failure) 2020-03-25T16:16:18.391+0800: 1294233.935: [ParNew: 1770060K->25950K(1922432K), 0.0317141 secs] 2105763K->361653K(4019584K), 0.0323010 secs] [Times: user=0.12 sys=0.00, real=0.04 secs]
復制代碼每次占用cpu的時間在0.04s左右,但是由於ParNew GC太過頻繁,每分鍾最高100次以上,整體占用cpu時間還是很可觀。
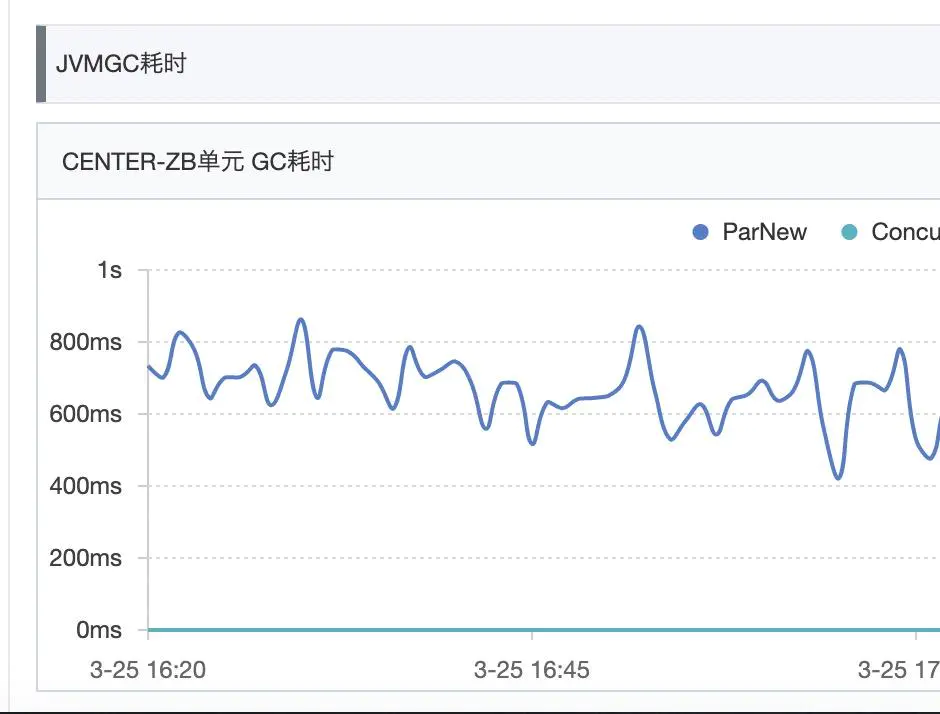
看了下jvm內存參數
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 2147483648 (2048.0MB)
MaxNewSize = 2147483648 (2048.0MB)
OldSize = 2147483648 (2048.0MB)
NewRatio = 2
SurvivorRatio = 10
MetaspaceSize = 268435456 (256.0MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 536870912 (512.0MB)
G1HeapRegionSize = 0 (0.0MB)
復制代碼年輕代分配了2G內存,其中eden區約1.7G
使用jmap查看年輕代對象占用空間情況,排名靠前的有多個org.apache.tomcat.util.buf包下的對象,比如ByteChunk、CharChunk、MessageBytes等,以及響應涉及的一些臨時對象列表。其中ByteChunk等即tomcat響應輸出相關類
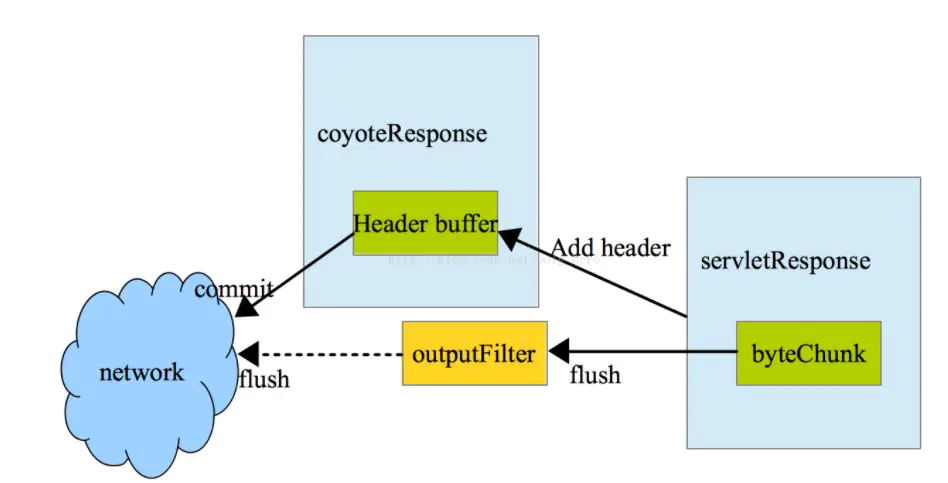
至此問題明確,超大響應包(50K)在發送到網卡的過程中,需要經過從用戶態user space拷貝到內核態 kernel space,然后在拷貝到網卡進行發送(像netty等的零拷貝針對的就是這種拷貝),加上響應體查詢過程中,涉及的大量臨時對象list,在高並發場景下,就導致年輕代內存占滿,然后頻繁gc(后續在合適的時間會壓測該接口),這里還有一個點,很多人以為ParNewGC不會stop the world,其實是會的。頻繁ParNewGC造成用戶線程進入阻塞狀態,讓出CPU時間片,最終導致連接處理等待,接口的RT變高。整個排查過程,鷹眼,idb性能監控等可視化監控平台幫助真的很大,否則到處去查日志得查的暈頭轉向了。
經驗總結
- 接口設計,需要避免超大響應體出現,分而治之,將一個大接口拆分為多個小接口。
- 緩存設計,像這個服務一樣,一個請求帶來將近40次DB查詢的,需要考慮在服務端進行緩存(當時偷懶了,要求調用方去做緩存)。
- 性能設計,要對自己負責系統的性能了如指掌,可以通過壓測等手段得到自己系統的天花板,否則,某一個接口hang住,會導致整個應用的可用性出現問題。
- 流量隔離,內部應用和外部流量之間,需要進行流量隔離,即使通過緩存,也有緩存擊穿的問題。
- 口頭說的東西都不靠譜,要落在文檔上,還需要檢查執行情況。
看完三件事❤️
如果你覺得這篇內容對你還蠻有幫助,我想邀請你幫我三個小忙:
-
點贊,轉發,有你們的 『點贊和評論』,才是我創造的動力。
-
關注公眾號 『 java爛豬皮 』,不定期分享原創知識。
-
同時可以期待后續文章ing🚀

作者:edenbaby