ISO/OSI的七層網絡模型
ISO國際標准化組織
OSI開放系統互連

1.應用層
給用戶提供一個操作界面
2.表示層
表示數據(0101)
加密(MD5sum)
壓縮(tar、zip)
3.會話層
判斷數據是否進行網絡傳遞
4.傳輸層
對報文進行分組(發送時)、組裝(接收時)
選擇傳輸協議:
TCP(傳輸控制協議):可靠的,面向連接的傳輸協議(可靠准確,慢),相當於打電話
UDP(用戶數據包協議):不可靠的、面向無連接的傳輸協議(不可靠,快),相當於發短信
端口封裝(訪問server的哪個端口,TCP或者UDP)
差錯校驗(數據包的發送有可能會出錯)
5.網絡層
ip地址編址(查找)
路由選擇
靜態路由,不需要路由器做任何運算,指定路由路徑,但是配置復雜
動態路由,路由器自動選擇路由路徑(自動選擇路由節點最少的路徑),但是會消耗CPU
6.數據鏈路層
MAC地址編址
MAC地址尋址
差錯校驗
7.物理層
數據實際傳輸
硬件
#數據包
ipv4協議中,數據包的大小不能超過2*16字節,所以一條數據在傳輸層,對以上層的數據進行拆包,同理,server端接收的時候對數據包進行組裝
#ip是全球唯一的
#ip地址與MAC地址
ip地址是用來不用網段的數據傳輸
MAC地址是用來相同網段的數據傳輸
在同一個廣播域中,通過MAC地址通訊
不同網段的主機通訊,ip、MAC、端口號缺一不可(端口是用來區分不同的服務的)
#TCP與UDP
數據的傳輸基本使用的是TCP協議,一般考慮實時性的話才會選擇UDP
TCP/IP四層模型

TCP/IP協議族

TCP包頭內容
數據包的組成

1.斷開
源端口隨機生成
目的端口指定
2.要發送的序列號
3.要接收的確認號
4.標志信號
5.標志校驗
6.可選
TCP三次握手
2**16 = 65535
#序號
seq序號,占32位二進制數,用來表示從TCP端向目的端發送的字節流,發起方發送數據時對此進行標記
#確認號
ACK序號 ,占32位二進制數,只有ACK標記為1時,確認序號才有效(ACK=seq+1)
#標志位
一共6個,即URG、ACK、ACK、PSH、RST、SYN、FIN等
URD:緊急指針有效
ACK:確認序號有效 #
PSH:接收方應該盡快將這個報文交給應用層
RST:重置連接
SYN:發起一個新連接 #
FIN:釋放一個連接(斷開連接) #

最后,通訊雙方都進入established狀態
TCP四次揮手

#可以針對 TIME_WAIT進行洪水攻擊
網段、IP、廣播地址
1.ip
確定網絡位、主機位的ip才有意義
2.子網掩碼
標准的表達方式,8、16、24 (表示二進制中子網掩碼中1的個數)
網段表示,255.255.255.192
二進制表示方法,11111111.11111111.11111111.11000000
子網掩碼的作用
1.ip和子網掩碼同時表示才有意義,單獨的ip和子網掩碼沒有任何意義(標准的子網表達方式可以省略(8/16/24))
2.子網掩碼是用來給ip地址划分網絡地址與主機地址的
3.和子網掩碼1對應的ip地址,代表網絡位,和子網掩碼0對應的ip地址,代表主機位(二進制表示子網掩碼)
4.子網中只要1是連續的,就是合理子網掩碼
ABC三類ip地址的組成

#
10.0.0.0 - 10.0.0.255 一共256個ip地址,0代表網絡本身,不能使用,255是廣播地址,不能使用
根據子網掩碼判斷ip屬於哪一類地址

1.子網掩碼中,1必須是連續的,否則無意義

網絡地址
ip 172.22.141.231 10101100.00010110.10001101.11100111
子網掩碼 255.255.255.192 11111111.11111111.11111111.11000000
邏輯與運算 10101100.00010110.10001101.11000000
網絡地址 172.22.141.192
廣播地址
ip 172.22.141.231 10101100.00010110.10001101.11100111
子網掩碼 255.255.255.192 11111111.11111111.11111111.11000000
#有效子網掩碼,也就是0和1搶的那一段
公式運算 10101100.00010110.10001101.11111111
廣播地址 172.22.141.255
畫圖理解計算公式

子網個數 2**2
主機個數 2**6 -2=62
進制轉換



私有ip免費使用
linux權限划分
文件基本權限
-rw-r--r-- 1 root root 247 Jun 30 03:48 xiugaizhuji.sh
#文件身份,屬主屬組
#文件權限
#目錄權限
#權限分配
1.給文件或目錄分配權限,先考慮屬主和屬組
2.遵循最小權限規則
3.注意遞歸授權目錄,一般遞歸屬主和屬組
#特殊權限(SUID、SGID、SBIT)
1.特殊權限是為了讓特定命令可以擁有足夠的權限運行
2.SUID只針對可執行文件,SGID只針對可執行文件和目錄,SBIT只針對可執行目錄
作用在
判斷方法
作用
#ACL權限
作用於系統權限分配不足的時候
#sudo權限
#系統文件鎖
lsattr
chattr
#企業權限的使用
1.linux系統權限、數據庫權限不要掌握在同一個部門
2.滿足使用,權限最小
3.盡量不要使用root用戶,使用 普通用戶 + sodu提權
4.使用Chattr鎖定重要的系統權限
5.使用腳本檢測系統中新增的SUID、SGID、SBIT文件
6.使用秘鑰登錄,修改SSH服務端口
備份方案
---------------------------- 備份對象
1.備份系統重要文件
2.備份數據庫
全備+增備
3.備份Apache服務配置文件
4.備份其他服務
日志備份
使用日志切割工具logrotate
日志輪替(輪替刪除)
使用Apache服務配置文件自帶日志切割功能,但是需要使用腳本進行輪替
---------------------------- 備份方式
#全量備份
cp、tar、dump、xfsdump、Veeam、commvault
#增量備份,基於上一次備份,然后進行的備份
C6:dump工具
C7:xfsdump工具
#差異備份,基於上一次全備,然后進行的備份
C6:dump工具
C7:xfsdump工具
---------------------------- 備份頻率
1.實時備份
mysql的主從同步
sersync
2.定時備份
腳本 + 定時任務,如每天、每周備份
---------------------------- 備份的存儲位置
1.本地備份
2.異地備份
服務器配置
lb、web 8核,16G,3x1T raid5
mysql、elk、redis 16核,32G,6x1T raid5
磁盤陣列
raid 0
1.必須使用兩塊或兩塊以上的硬盤組成
2.每塊硬盤的大小必須一致
3.raid0 是所有動態磁盤中,數據讀寫最快的
4.損壞幾率相對最高
5.沒有磁盤容錯功能
#數據分開存儲,CPU對數據的讀取最快(同時讀取)
#磁盤的損壞率是單塊盤的多倍
#沒有磁盤的冗余功能(一塊磁盤壞了的話,那么數據就丟了)
raid 1
1.由2塊或2的倍數硬盤組成
2.每塊硬盤大小必須一致
3.磁盤利用率只有50%,寫入速度最慢
4.擁有磁盤容錯功能
#磁盤另外50%使用率做了備份,同一條數據寫2遍,所以速度慢
#優點是磁盤容錯
raid 5
1.由三塊或三塊以上的硬盤組成
2.每塊硬盤大小必須一致
3.磁盤利用率是n-1塊盤
4.利用奇偶校驗,擁有磁盤容錯功能
#磁盤個數越多,利用率越高
#注意只支持一塊硬盤同時損壞

raid 6
1.raid6是raid5的增強版
2.由4塊或以上硬盤組成
3.每塊硬盤大小必須一致
4.磁盤利用率是n-2塊盤
5.支持磁盤容錯,可以支持2塊硬盤損壞
#支持同時壞2塊盤損壞
raid 10
1.必須由4塊等大小的硬盤組成
2.兩兩硬盤先組成raid1,再組成raid0
3.兼顧raid0 和raid1 的特點,中和兩種raid的缺點
軟raid與硬raid的區別
#軟raid
是由操作系統模擬的raid,一旦硬盤損壞,操作系統就會損壞,raid就會喪失作用
#硬raid
是由獨立於硬盤之外的,硬件raid卡組成,就算硬盤損壞,也不會導致raid卡損壞,磁盤容錯才能起作用
1.軟raid的作用就是模擬read,用來學習
2.硬件read有獨立的操作系統,進而可以修復磁盤損壞
linux資源查看
CPU

網絡

磁盤

內存

綜合監控工具





啟動流程
C6
1.服務器加電自檢(滴滴滴),加載BIOS信息,BIOS進行系統檢測
2.加載grub菜單(進行多系統選擇)
3.系統內核
4.加載硬件驅動
5.由內核啟動系統第一個進程 /sbin/init
6.由/etc/init/rcS.conf調用 /etc/inittab,確定系統的默認運行級別
7.調用/etc/init/rc.conf配置文件
8.運行相應的運行級別目錄 /etc/rc[0-6].d/中的腳本
9.執行 /etc/rc.d/rc.local中的程序(進程串行啟動)
10.登錄界面

C7
1.服務器加電自檢(滴滴滴),加載BIOS信息,BIOS進行系統檢測
2.加載grub2菜單
3.grub2加載系統內核
4.grub2加載inintamfs虛擬文件系統
5.內核初始化,加載硬件的驅動
6.內核啟動系統的第一個進程systemd
7.進程並行啟動
8.systemd進程調用default.target


linux系統優化
1.禁用不需要的端口
linux使用ntsysv命令
禁用Samba服務的默認端口445
2.避免直接使用root用戶,普通用戶通過sudo授權操作
3.通過Chattr鎖定重要系統文件
/etc/passwd
4.配置國內yum源,加快下載速度
5.配置系統同時打開的最大文件數
ulimit -SHn 65535
6.服務器同步時間
ntpdate time1.aliyun.com
定時任務 + ntpdate
7.更改ssh服務的默認端口22,配置ssh密匙對登錄
8.配置合理的iptables/firewalld 規則
9.配置selinux
10.監控文件、帶寬、端口
11.定時備份系統重要的文件
本地 + 異地
文本截取、排序、過濾
1. cut -d '/' -f 3
2. sort -t '/' -k 3 -n -r
3. uniq -c 顯示重復次數
4. awk
5. sed
6.監控連接的狀態
netstat -an| grep ESTABLISHED| awk '{print $5}' |cut -d ':' -f 1 |sort -n |uniq -c |sort -nr
隨機字符串
面試題

工具

tr

[root@jenkins01 ~]# echo " aa...,+1 b2c /* $dd 3 ls 4" |tr -dc '0-9 \n'
1 2 3 4
#!/bin/bash
if [ ! -d /syy ];then
mkdir /syy
fi
cd /syy
for ((i=1;i<=10;i++));do
filename=$(tr -dc 'A-Za-z0-9' < /dev/urandom| head -c 6)
touch "$filename"_gg.txt
#rm -rf /syy/*
done
生成隨機數
# $RANDOM 這個系統變量可以默認隨機生成 0-32767的數字(包括0,不包括32767)
[root@jenkins01 syy]# echo $RANDOM
12844
[root@jenkins01 syy]# echo $(($RANDOM%1000)) #生成1000內的隨機數
890




網站監測

1.ping 監測目標主機是否宕機
2.curl 監測網站是否正常
#curl命令
開源的用於數據傳輸的命令行工具,可以用與http訪問,用於上傳和下載、用戶認證、代理訪問等
選項:
-o :將命令輸出保存在指定文件
-s :靜默輸出
-w :按指定格式輸出內容,例如:-w %{http_code} #輸出http狀態碼
--connect-timeout :指定超時時間

#!bin/bash
web = (
www.qq.com
10.0.0.90
10.0.0.91
)
for i in ${web[*]};do
code = $(curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' $i |grep -E '200|302')
if [ "$code" != "" ];then
echo "$i is ok" >> /root/ok.log
else
sleep 10
code = $(curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' $i |grep -E '200|302')
if [ "$code" != "" ];then
echo "$i is ok" >> /root/ok.log
else
echo "$i is error" >> /root/error.log
fi
fi
done
提升ssh服務遠程管理的安全等級
1.ssh服務的登錄驗證方式(口令、密鑰對)
2.ssh服務的登錄端口的監聽(端口)
3.ssh服務的登錄用戶個數限制
4.ssh服務的登錄超時設置
5.ssh服務的登錄失敗次數限制(防止損耗CPU)
密鑰對

端口設置

配置文件
[root@jenkins02 ~]# ll /etc/ssh/ssh*
-rw-r--r--. 1 root root 2276 Apr 11 2018 /etc/ssh/ssh_config #客戶端
-rw------- 1 root root 3905 Jun 30 03:30 /etc/ssh/sshd_config #服務端
FTP
FTP服務器主動模式

1.FTP服務端21號端口一致保持連接
2.FTP服務端22端口只有在數據傳輸的時候才會開啟
3.FTP服務器只會使用22號端口提供服務
FTP服務器被動模式

1.FTP服務器提供服務的端口是隨機的,所以此時不會因為端口問題導致FTP服務停止運行
時間同步
手動同步
ntpdate 實際服務器IP地址
自動同步
crontab -e
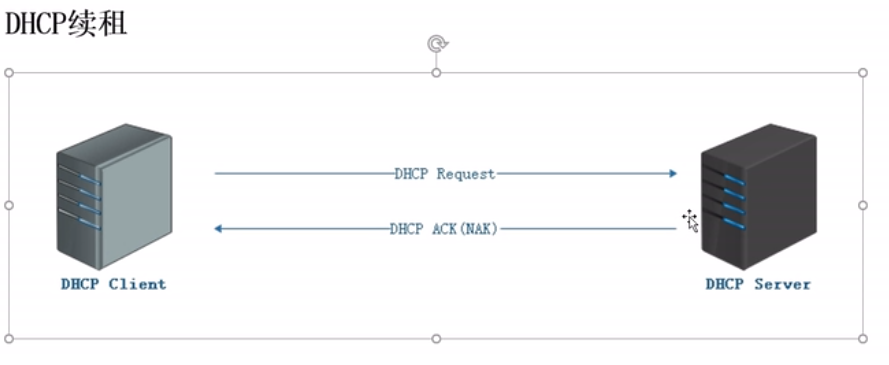
通過DHCP服務獲取IP地址的過程
DHCP協議又叫動態主機分配協議
作用是分配ip資源
類型:
DHCP租約
DHCP續租
資源池:
ip資源池


#租約
discover、offer、request、ACK數據的傳輸為廣播
ACK/NAK 是/否
#續租
數據的傳輸使用ip地址,直接傳輸數據包
#取消VMVARE網卡的DHCP功能
#下載
[root@jenkins01 syy]# yum install -y dhcp
#配置
[root@jenkins01 syy]# vim /etc/dhcp/dhcpd.conf
subnet 10.0.0.0 netmask 255.255.255.0 {
range 10.0.0.100 10.0.0.254;
option domain name-servers 114.114.114.114;
option routers 10.0.0.2;
default-lease-time 600;
max-lease-time 7200;
}
DNS (域名解析服務)

域名: 表示一個網站或一組服務器的專有的一個字符串,為了人去記憶ip地址
ip: 為每一個網絡設備來設置一個ip地址,為了資源定位
DNS服務器原理及解析流程

本地DNS
# local DNS
[root@hass-11 ku]# vim /etc/hosts
#IPV4本地回環地址 別名 別名
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#IPV6本地回環地址
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#缺點
維護壓力大
#local DNS 遞歸服務器
DNS服務器(遞歸查詢)

#GATEWAY
數據傳輸必須要有網關
#DNS1
首選DNS
#DNS2
備選DNS
#本地解析的優先級大於DNS服務器解析
迭代查詢

#ROOT DNS(根域服務器)
只負責接收local DNS的請求
#TLD DNS
只負責接收根域傳來的頂級域
#ROOOT DNS、TLD DNS、Domain Auth-DNS迭代服務器,根域、頂級域、二級域服務器
#二級DNS又叫權威DNS
#local DNS幫助PC第一次解析,還可以記錄迭代查詢的結果
文字解析

權威DNS 和遞歸DNS的定義

智能DNS

Apache虛擬主機
1.基於IP的虛擬主機
~]# ifconfig eth0:0 10.0.0.3/24 #設置網卡子接口,臨時生效
2.基於IP+端口的虛擬主機
3.基於域名的虛擬主機
基於域名的 多虛擬主機
#編輯多虛擬主機
~]# vim /etc/httpd/conf.d/test.conf
<VirtualHost 10.0.0.3:80>
DocumentRoot /var/www/html/a.com
ServerName www.a.com
#管理員信息
#ServerAdmin xinxi
#日志
#Errorlog log_dir
</VirtualHost>
<VirtualHost 10.0.0.4:80>
DocumentRoot /var/www/html/b.com
ServerName www.b.com
</VirtualHost>
#添加虛擬網卡
~]# ifconfig eth0:0 10.0.0.3/24
~]# ifconfig eth0:1 10.0.0.4/24
#本地解析
~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.3 www.a.com
10.0.0.4 www.b.com
~]# mkdir /var/www/html/{a,b}.com
~]# echo "www.a.com..." >> /var/www/html/a.com/index.html
~]# echo "www.b.com..." >> /var/www/html/b.com/index.html
#重啟httpd
~]# service httpd restart
基於ip和端口的 多虛擬主機
#配置域名解析
~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.3 www.a.com
10.0.0.3 www.b.com
#關閉多余的網卡
~]# ifconfig eth0:1 10.0.0.4 down
~]# ip a|grep 10.0.0.3
inet 10.0.0.3/24 brd 10.0.0.255 scope global secondary eth0:0
#配置httpd 多虛擬主機
~]# vim /etc/httpd/conf.d/test.conf
<VirtualHost 10.0.0.3:80>
DocumentRoot /var/www/html/a.com
ServerName www.a.com
</VirtualHost>
<VirtualHost 10.0.0.3:8080>
DocumentRoot /var/www/html/b.com
ServerName www.b.com
</VirtualHost>
#使httpd監聽多個端口
~]# vim /etc/httpd/conf/httpd.conf
Listen 80
Listen 8888
#curl
[root@jenkins01 ~]# curl www.a.com:80
www.a.com...
[root@jenkins01 ~]# curl www.b.com:80
www.a.com...
[root@jenkins01 ~]# curl www.a.com:8888
www.b.com...
[root@jenkins01 ~]# curl www.b.com:8888
www.b.com...
域名跳轉
#本地解析
~]# vim /etc/hosts
10.0.0.3 www.a.com
10.0.0.4 www.b.com
#配置子網卡
~]# ifconfig eth0:0 10.0.0.3/24
~]# ifconfig eth0:1 10.0.0.4/24
#
~]# vim /etc/httpd/conf.d/test.conf
<VirtualHost 10.0.0.3:80>
DocumentRoot /var/www/html/a.com
ServerName www.a.com
</VirtualHost>
<VirtualHost 10.0.0.4:80>
DocumentRoot /var/www/html/b.com
ServerName www.b.com
<IfModule mod_rewrite.c>
RewriteEngine on
#開啟rewrite功能
RewriteCond %{HTTP_HOST} ^www.b.com
#把以www.a.com開頭的內容復制給HTTP_HOST變量
RewriteRule ^(.*)$ http://www.a.com/$1 [R=301,L]
#^(.*)$指客戶端要訪問的資源
#$1 把 .* 所指的內容賦值給$1
#R=permanent 永久重定向 = 301
#L 指生效的最后一條規則,以后的不再生效
</IfModule>
</VirtualHost>
#curl
~]# curl www.a.com:80
www.a.com...
~]# !c
curl www.b.com:80
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>301 Moved Permanently</title>
</head><body>
<h1>Moved Permanently</h1>
<p>The document has moved <a href="http://www.a.com//">here</a>.</p>
</body></html>
Apache的三種工作模式
prefork模式

#該模式下,Apache會開啟多個子進程,在處理請求之前
#一個子進程下面有一個線程,一個線程只處理一個請求
#優點
對請求的處理穩定
#缺點
進程獨占資源,不適合高並發
worker模式

#一個子進程下面有多個線程,一個線程只處理一個請求
#優點
資源利用率高,適合高並發
#缺點
一個線程不能工作,會導致該子進程下的所有線程都不能工作(線程安全)
event模式

#同一個用戶在同一個網站進行多次訪問,為了防止系統重復的進行TCP/IP連接和斷開,存在一個連接超時時間T,在時間T范圍內,該用戶可以直接訪問該網站,不需要再進行TCP/IP連接
#event模式新增了'分配管理線程'
#該線程的作用就是查找所有進程中處於等待時間T的進程,停止該進程的等待,讓其處理別的請求
#優點
該模式下,要比worker模式更擅長處理高並發
#查看Apache的工作模式
~]# httpd -V |grep -i 'server mpm'
Server MPM: prefork
#指定Apache的工作模式
在編譯時,在選項中指定 --with-mpm=xxx
Apache優化
#apache服務器的安全
#apache服務器的效率
日志優化
#查看Apache日志路徑
~]# cat /etc/httpd/conf/httpd.conf |grep CustomLog
CustomLog "logs/access_log" combined
~]# ll /var/log/httpd/
total 12
-rw-r--r-- 1 root root 1021 Sep 23 20:18 access_log #其他日志
-rw-r--r-- 1 root root 7842 Sep 23 20:13 error_log #報錯日志
#查看日志切割工具
[root@jenkins01 ~]# rpm -q logrotate
logrotate-3.8.6-17.el7.x86_64
[root@jenkins01 ~]# rpm -ql logrotate |grep bin
/usr/sbin/logrotate
[root@jenkins01 ~]# rpm -ql logrotate |grep sbin #logrotate安裝包含的命令
/usr/sbin/logrotate
[root@jenkins01 ~]# which rotatelogs
/usr/sbin/rotatelogs
[root@jenkins01 ~]# rpm -qf /usr/sbin/rotatelogs #查看命令屬於哪個包
httpd-2.4.6-93.el7.centos.x86_64
[root@jenkins01 ~]# rpm -qf /usr/bin/cd
bash-4.2.46-31.el7.x86_64
#配置Apache日志(在配置文件使用httpd自帶的日志切割工具,指定日志切割)
~]# /etc/httpd/conf/httpd.conf
CustomLog "|/usr/sbin/rotatelogs -l /tmp/httpd_access_%Y%m%d.log 86400" combined
#檢測
~]# tailf /tmp/systemd-private-61d9106934ca4074a160dbe4ac63987a-httpd.service-5txtFo/tmp/httpd_access_20200923.log
10.0.0.91 - - [23/Sep/2020:21:19:51 +0800] "GET / HTTP/1.1" 200 13 "-" "curl/7.29.0"
錯誤頁面的美化
#可以將 404 500等錯誤信息頁面重定向到網站首頁或其他頁面,提升用戶體驗
#編輯虛擬主機
~]# vim /etc/httpd/conf.d/test.conf
<VirtualHost 10.0.0.3:80>
DocumentRoot /var/www/html/a.com
ServerName www.a.com
ErrorDocument 404 httpd://www.b.com
</VirtualHost>
<VirtualHost 10.0.0.4:80>
DocumentRoot /var/www/html/b.com
ServerName www.b.com
</VirtualHost>
#編輯美化頁面
~]# echo '我是美化頁面' > /var/www/html/b.com/index.html
屏蔽Apache版本等敏感信息
#子文件調用
~]# vim /etc/httpd/conf/httpd.conf
Include conf/extra/httpd-default.conf
#修改配置文件中默認顯示的信息
~]# vim /etc/httpd/conf.d/httpd-default.conf
ServerTokens Prod
ServerTokens Major
ServerTokens Minor
ServerTokens Min
ServerTokens OS
ServerTokens Full
配置Apache緩存

#緩存對象
.gif、jpeg、png、css等文件,不能緩存視頻等較大的文件
#該模塊一定要在網站的標簽里面聲明
<VirtualHost IdModule 10.0.0.x mod_expires.c>
<IdModule></IdModule>
禁止PHP解析代碼
~]# vim /etc/httpd/conf.d/httpd-default.conf
<Directory "/www.a.com/uploads">
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
php_flag engine off
</Directory>
優化總結

#對故障進行預測,解決對應問題的策略/方案都叫優化
提高網站的安全和效率
- 殺毒軟件可以提高網站的安全
- CDN

#CDN又叫內容分發網絡,可以加快用戶對靜態資源的訪問
#CDN的作用就是減輕網站服務器的壓力,還有保護服務器的真實身份
就是web通過CDN把變化頻率較低的文件(圖片文件、文本文件),分發到各個城市的CDN服務器上
這樣各個城市的用戶要訪問資源,通過智能DNS會直接把域名解析成'離當前位置最近'的DNS的ip
#這時的CDN相當於一個緩存服務器
3.常見的服務器攻擊
#DHCP安全威脅
1.餓死攻擊(DHCP服務器沒有ip分配)
黑客可以使用chadder來不斷的向DHCP服務器請求ip,chadder相當於MAC,不同的chadder代表不同的主機,從而別的服務器無法上網
2.仿冒服務器攻擊
私接路由器
安裝DHCP server
3.中間人攻擊
ARP中間人攻擊(雙向欺騙),使用非對稱加密可以避免
#使用snooping可以解決餓死攻擊、仿冒服務器攻擊、中間人攻擊
4.飽死攻擊
DDOS攻擊,黑客一直向服務器發送請求
Apache的優缺點
優點
1.Apache的rewrite功能比nginx的要強大 (域名、關鍵詞)
2.Apache模塊非常多,基本想要的功能都能找到模塊 (模塊化)
3.存在時間較長,相關文檔多,bug相對較少
4.靜態解析很穩定(html)
5.動態解析也很穩定(解析需要連接數據庫的文件,比如 .php文件)
缺點
1.由於工作模式是'同步阻塞型',導致資源的消耗較高,並發能力較差
nginx的優缺點
優點
1.輕量級服務,比Apache占用更少的內存及資源
2.並發能力強,nginx處理請求是異步非阻塞型的,而Apache則是同步阻塞型,在高並發下nginx能保持'低資源、低消耗、高性能'
3.高度模塊化的設計,編寫模塊相對簡單
4.社區活躍,各種高性能模塊產出迅速
缺點
1.動態處理上需要使用fastcgi連接PHP的fpm服務,相比apace不占優勢
nginx的動態解析解析

Apache和nginx的選擇
1.nginx 適合做靜態處理,簡單,效率高,並發高
2.Apache 適合做動態處理(連接PHP更方便),穩定,功能強
3.並發較高的情況下優先選擇nginx,並發要求不高的情況下,兩者都可以。
4.可以使用nginx作為反向代理,然后將動態請求負載均衡到后端Apache上
nginx反向代理、負載均衡、動靜分離

#企業常用
nginx處理請求的原理

同步
關鍵在於等,效率低,但是可以保持數據的一致性
異步
效率高,數據有偏差
#同步或者異步是相對於數據來說的

阻塞
線程的使用效率低
非阻塞
線程的使用效率高
#阻塞非阻塞是相對於進程來說的
nginx以異步非阻塞的方式進行工作的

nginx常用模塊
http_ssl_module模塊

1.http_ssl_module模塊在nginx編譯安裝的時候需要指定
2.http 使用80端口,HTTPS使用443端口
3.使用rewrite或return,可以實現nginx的請求轉發
http_image_filter_module模塊

1.直接在配置文件中圖片的寬和高
http_rewrite_module模塊

http_proxy_module模塊

http_upstream_module模塊

#負載均衡的算法
RR輪詢
lnmp、lamp、lnmTJ總結

靜態資源直接訪問靜態資源服務器,CDN
lnmp
nginx通過fast_cgi模塊,代理PHP-FPM,訪問數據庫,並發量高
lamp
Apache直接連接PHP,訪問數據庫
lnmTJ
nginx通過fast_cgi模塊,反向代理后端的Tomcat服務器,Tomcat服務器使用JDK,訪問數據庫
nginx調用PHP的過程

nginx調用Tomcat的過程

http狀態碼
1** :信息,服務器收到請求,需要請求者繼續執行操作(客戶端看不到)
2** :成功,操作被成功接收並處理(客戶端看不到)
3** :重定向,需要進一步的操作以完成請求(客戶端看不到)
4** :客戶端錯誤,請求包含語法錯誤或無法完成請求
5** :服務端錯誤,服務端在處理請求的過程中發生了錯誤
#五個類別的響應代碼的第一個數字是'唯一代表'
成功響應

重定向

客戶端錯誤

服務器錯誤(生成中應該避免)

SQL語句

select count(*) from student.report where Nmae like '李%';
select Result from student.report order by result desc limit 2;
#函數count(*),顯示匹配的數據的數量
#order by 升序排列
#order by desc 降序排列
#limit 步長
增
創建用戶
create user user_name@'%' identified by '123';
創建數據庫
create database db_name;
創建數據表
create table tb_name(id int,name char(30),age int);
插入數據
insert tb_name(id,name,age) values(1,'zhangsan',21);
#數據庫用戶登錄方式有2種
1.本地,使用localhost授權
2.遠程,使用 %授權
刪
刪除用戶
drop user user_name@'%';
刪除數據庫
drop database db_name;
刪除數據表
drop table tb_name;
刪除數據
delete from sj1 where id=5;
delete from sj1 where age between 23 and 25;
改
修改表中的數據
update tb_name set age=21 where id=30;
修改數據表的名稱
alter table tb_name1 rename tb_name2;
修改數據表的字段類型
describe tb_name;
alter table tb_name modify name char(50);
describe tb_name;
修改數據表的字段類型
alter table tb_name change name username char(50) not null default '';
添加刪除字段
alter table tb_name add time datetime;
alter table tb_name drop time;
#change 既可以修改表名(rename),又可以修改字段類型(modify)
查
查看所有數據庫
show databases;
查看指定庫內所有的數據表
show tables;
查看指定數據表的字段
desc tb_name;
查看所有mysql用戶密碼和登錄方式
select User,Password,Host from mysql.user;
數據數量
select count(*) from db_name.tb_name;
授權
授權用戶全部權限(除了grant)
grant all on *.* to username@'%';
創建用戶,並授權,或者給已存在的用戶授權
grant all on *.* to username@'%' identified by '123';
回收權限
revoke drop,delete on *.* from username@'%';
數據庫的啟動、關閉
啟動
service mysqld start
/etc/init.d/mysqld start
mysqld_safe &
關閉
service mysqld stop
/etc/init.d/mysqld stop
mysqladmin -uroot -p123 shutdown
心靈雞湯
數據庫這方面的知識對我們運維工程師來說是非常重要的技能
但是作為運維來說,我們學習數據庫主要學習數據庫架構的搭建,以及中間件的部署等
我們運維不用過多的去關注數據庫數據的結構、語法結構,因為,數據庫里面的所有的庫、表、數據結構都是需要開發工程師切合他們的開發項目的
我們運維要做的就是為他們提供一個安全穩定的運行環境、數據庫環境
數據庫集群
mysql主從復制,一主二從

#主庫
接收用戶的寫入
接收用戶的查詢
#從庫
從服務器的作用只是用來備份主服務器上的數據的
#主從復制原理
bin-log日志(二進制日志),要先開啟主服務器上的bin-log日志記錄功能,將主服務器的bin-log日志傳到從服務器,從服務器根據日志內容將數據換源到本地
#bin-log日志是一種特殊的日志,二進制日志,記錄用戶對數據庫的操作,但是bin-log日志只會記錄對數據進行修改的操作 (增刪改 授權)
#主從復制就是對master的一種備份,而且比普通的備份效率高得多,消耗的資源更少一些
#主從復制中,主庫宕機,從庫將會來不及同步主庫上的數據,少量的數據丟失是在所難免的
#mysql的master-slave讀寫分離,是為了分攤主庫的讀壓力
#mysql的master-master,是為了分攤主庫的寫壓力
#mysql的master-master-slave,即一台主機作為兩個master的從庫,原理是虛擬主機
MHA(自動故障恢復)
主從復制中,主庫宕機,然后登陸所有的從庫查看POST信息,使用最大POST的從庫作為新的主庫,然后將它提升為新的主庫,登陸從庫(新的主庫)執行 stop slave
新的主庫修改my.cnf配置文件,開啟bin-log並重新啟動數據庫服務,登陸數據庫執行reset master
登陸其它從庫,執行change master to操作
解決單台mysql的性能瓶頸
#縱向擴展
提升單台服務器的性能,增加CPU、內存、硬盤
小心短板效應
#橫向擴展(mysql集群)
數據庫代理工具:Amoeba
Amoeba是致力於mysql的分布式數據庫前端代理層(代理服務器),
它主要在應用層(web服務器)訪問mysql的時候充當'SQL路由功能',專注於分布式數據庫代理層開發,
具有負載均衡、高可用性、SQL過濾、讀寫分離、可路由相關的'請求'到'目標數據庫'、可並發請求多台數據庫、合並結果。通過Amoeba,
你能夠完成多數據源的高可用、負載均衡、數據切片的功能
#Amoeba 就是mysql集群中反向代理的中間件工具
#生產中,可以使用2台Amoeba做成高可用
atlas -- mycat -- amoeba

數據庫索引
#索引也算是對數據庫的一種優化
1.什么是索引
索引本質是一種排好序的可以快速查找的數據的結構,可以提高查找的效率
可以理解為數據的分身
數據庫這種滿足特定查找算法的數據結構,再次基礎上實現高級的查找算法
2.索引的分類
主鍵索引,創建主鍵的時候自動為該字段創建主鍵索引
單值索引(單列索引),如果某個字段經常用來檢索,就可以為該列創建單只索引
復合索引,一個索引包含多個列,如電話簿上 姓+名,注意復合索引最好不要超過5個字段
唯一鍵索引,注意該列所有的值必須唯一,允許有空值
輔助索引,普通索引和唯一鍵索引可以稱為輔助索引
3.優點
使數據的查詢效率更高
避免了查詢數據的時候對數據進行的排序操作
使隨機的IO查詢變成有順序的IO查詢
3.缺點
索引實際上也是一張表,該表保存了主鍵與索引字段,並指向實體表的數據,索引需要占用額外的磁盤空間
索引雖然大大的提高了數據的查詢速度,但是會降低更新表的速度(insert、update、delete)
因為mysql不僅要保存數據,還要保存索引文件
每次更新添加了索引列的字段,都會調整因為更新所帶來的鍵值對變化后的索引信息
4.什么時候需要創建索引
頻繁作為查詢條件的字段應該創建索引
查詢中與其它表關聯的字段,外鍵關系的列建立索引
數據本身就有順序,通過索引將大大提高排序速度
統計或分組字段
5.什么時候不需要創建索引
頻繁更新的字段不適合創建索引,因為沒猜錯更新不單單是更新了數據,還會更新索引
where里用不到的字段不創建索引
對單列數據,不要創建多種索引(減少資源消耗)
表數據太少不需要創建索引,一個表中的數據在三百萬左右才需要創建索引
性別,國籍字段
#創建索引的時候,系統自動創建了2個空間,索引空間,數據空間
數據庫備份

1.查看binlog日志,記錄drop之前的位置點m
2.查看全備,找到mysql數據庫的數據備份到了哪個位置點n
3.通過binlog日志,使用mysqldump命令,導出n到m的binlog信息,a.txt
4.拷貝全備文件和a.txt 到新庫所在主機
5.使用mysqldump命令導入binlog日志,數據恢復
6.根據數據庫數據量的大小,選擇
切換前端web對數據庫的指向
將新恢復的數據庫的數據導出、拷貝到舊庫所在主機、導入
#數據庫binlog需要手動開啟
#binlog記錄了用戶,對數據庫所有的增刪改操作
redis
#redis是一種非關系型數據庫
#redis中的數據是保存在內存中的,將redis中的數據實時保存到磁盤,叫做redis的持久化
#原子性,指的是一次完整的事務,與事務的commit、rollback有關
#redis中的交集,和mysql的連表查詢類似
redis是一個key-value的存儲系統,它支持value(數據)類型相對較多,包括string、list、set、zset,這些數據都支持push、pop、add、remove和交集、並集、補集等操作
redis致辭各種不同方式的排序
為了保證效率,redis中的數據是緩存在內存中的
redis會周期性的把數據從內存寫入磁盤,或者把修改等操作追加寫入記錄文件(持久化)
redis支持master-slave,即主從復制
redis持久化--RDB
在redis運行時,RDB程序將當前內存中的數據庫快照 保存到磁盤中,當redis需要重啟時,RDB程序會通過重載RDB文件來還原數據庫
#保存(RDBsave)
RDBsave負責將內存中的數據庫數據'以RDB格式'保存到磁盤中,如果RDB文件已經存在,將會替換已有的RDB文件,保存文件期間會阻塞主進程,這段時間期間將'不能處理新的客戶端請求',直到保存完成為止
#讀取(RDBload)
當redis啟動時,會根據配置的持久化模式,決定是否讀取RDB文件,並將其中的對象加載到內存中
redis持久化-AOF
以'協議文本'的方式,將所有對數據庫進行的寫入命令記錄到AOF文件,達到記錄數據庫狀態的目的
#redis的AOF持久化,相當於mysql數據庫的binlog日志
#保存
1,將客戶端請求的命令轉化為網絡協議格式
2.將協議內容字符串追加到變量server.aof 中
3.當AOF系統達到設定的條件時,會調用aof_fsync(文件描述符號)將數據寫入到磁盤
#讀取
1.AOF保存的是網絡協議格式的數據,所以只要將AOF中的數據轉換為命令,模擬客戶端重新執行一遍,就可以還原所有數據庫的狀態
2.讀取AOF保存的文本,還原數據為原命令和原參數,然后使用模擬的客戶端執行這個目錄請求
3.一條一條的執行第二步,直到,讀取完
#AOF重寫
1.把AOF文件從磁盤讀取到內存中
2.有條件的合並AOF中的redis語句(只保留最新的修改)
3.用新的AOF文件,覆蓋原有的AOF文件
使用redis對mysql進行性能優化

#用戶請求與集群的響應
1.web服務器先對redis服務器發出請求,查找數據,如果redis服務器中沒有對應的數據
2.web服務器再對amoeba服務器發出請求
3.amoeba對請求進行負載均衡、讀寫分離,將用戶的請求分配到mysql服務器上
4.mysql服務器進行請求反饋
5.linux系統以key-value的形式,將查詢結果保存到redis服務器
#注意要設置redis數據庫數據的生存時間TTL(緩存時間),使用redis數據庫中的數據與mysql數據庫中的數據一致
#redis sitinel模式來實現緩存
jenkins
#什么是持續集成
持續集成( Continuous integration , 簡稱 CI )指的是,頻繁地(一天多次)將代碼集成到主干。
持續集成的目的,就是讓產品可以快速迭代,同時還能保持高質量。
它的核心措施是,代碼集成到主干
之前,必須通過自動化測試。只要有一個測試用例失敗,就不能集成。
持續交付CD
1.gitlab
1.組的概念
創建組,創建用戶,將用戶添加到組里(5種權限),組中創建項目
2.IDE工具的使用
安裝Windows git
綁定IDE工具和git
git推送代碼到gitlab
2.jenkins,Role-based Authorization Strategy插件,用戶權限管理
#role-base插件有角色的概念
角色的使用
1.創建角色、創建用戶
2.用戶綁定角色、角色綁定項目,實現jenkins用戶權限的管理
#Credentials Binding插件,憑證管理
Username with password:用戶名和密碼
SSH Username with private key: 使用SSH用戶和密鑰
Secret file:需要保密的文本文件,使用時Jenkins會將文件復制到一個臨時目錄中,再將文件路徑
設置到一個變量中,等構建結束后,所復制的Secret file就會被刪除。
Secret text:需要保存的一個加密的文本串,如釘釘機器人或Github的api token
Certificate:通過上傳證書文件的方式
#git,jenkins從gitlab拉取代碼
添加憑證
jenkins進行項目構建,代碼目錄/var/lib/jenkins/workspace/
#Jenkins中自動構建項目的類型有很多,常用的有以下三種:
自由風格軟件項目(FreeStyle Project)
使用Executor Shell構建
Maven項目(Maven Project)
流水線項目(Pipeline Project)
#maven
安裝maven
jenkins關聯JDK和Maven
maven打包代碼
#Maven Integration插件,Maven項目構建
創建maven項目
使用pom.xml文件,進行構建
#Pipeline插件,Pipeline流水線項目構建
Pipeline 支持兩種語法:Declarative(聲明式)和 Scripted Pipeline(腳本式)語法
聲明式Pipeline
腳本式Pipeline
輪詢SCM,把Pipeline腳本放在項目中(一起進行版本控制)
是指定時掃描本地代碼倉庫的代碼是否有變更,如果代碼有變更就觸發項目構建
自動觸發構建,Git hook,需要安裝兩個插件,Gitlab Hook和GitLab
#Deploy to container,把項目部署到遠程的Tomcat里面
添加Tomcat憑證
添加項目構建后的操作
#Jenkins內置4種構建觸發器:
遠程觸發構建
其他工程構建后觸發(Build after other projects are build)
定時構建(Build periodically)
輪詢SCM(Poll SCM)
#參數化構建
#Email Extension插,配置郵箱服務器發送構建結果
對email.html進行版本控制
項目添加構建后發送郵件
#SonarQube是一個用於管理代碼質量的開放平台,可以快速的定位代碼中潛在的或者明顯的錯誤。
下載、配置SonarQube
安裝SonarQube Scanner插件,jenkins調用SonarQube
添加SonarQube憑證
在項目添加SonaQube代碼審查
SonarQube的UI界面查看審查結果
nexus
kafka
常用的消息隊列message queue
#RabbitMQ
開源免費
它非常重量級,更適合於企業級的開發。同時實現了Broker構架
#redis
基於redis的setinue模式
10K以下數據的入隊和出隊
#zeroMQ
ZeroMQ號稱最快的消息隊列系統,尤其針對大吞吐量的需求場景
#ActiveMQ
類似於ZeroMQ,它能夠以代理人和點對點的技術實現隊列。同時類似於RabbitMQ,它少量代碼就可以高效地實現高級應用場景。
#Kafka/Jafka
Kafka是Apache下的一個子項目,是一個高性能跨語言分布式發布/訂閱消息隊列系統,而Jafka是在Kafka之上孵化而來的,即Kafka的一個升級版。
#kafka注意應用場景是:日志收集系統和消息系統。
#Kafka主要設計目標如下:
以時間復雜度為O(1)的方式提供消息持久化能力,'即使對TB級以上數據也能保證常數時間的訪問性能'。
高吞吐率。即使在非常廉價的商用機器上也能做到單機支持每秒100K條消息的傳輸。
支持Kafka Server間的消息分區,及分布式消費,同時保證每個partition內的消息順序傳輸。
同時支持離線數據處理和實時數據處理。
Scale out:支持在線水平擴展
#消息傳遞模式
一個消息系統負責將數據從一個應用傳遞到另外一個應用,應用只需關注於數據,無需關注數據在兩個或多個應用間是如何傳遞的。
分布式消息傳遞基於可靠的消息隊列,在客戶端應用和消息系統之間異步傳遞消息。
有兩種主要的消息傳遞模式:點對點傳遞模式、發布-訂閱模式。大部分的消息系統選用發布-訂閱模式。
Kafka就是一種發布-訂閱模式
#每條發布到Kafka集群的消息都有一個類別,這個類別被稱為Topic
#Kafka 集群包含一個或多個服務器,服務器節點稱為broker。
點對點

發布訂閱

memchached
Memcached 官網:https://memcached.org/
Memcached是一個自由開源的,高性能,分布式內存對象緩存系統。memcached是一種高速運行的分布式緩存服務器
Memcached是一種基於內存的key-value存儲
解決了大數據量緩存的很多問題
#作用
通過緩存數據庫查詢結果,減少數據庫訪問次數,以提高動態Web應用的速度、提高可擴展性。
#優點
memcached是多線程工作,而redis是單線程工作。
服務器並不具有分布式功能,分布式部署取決於memcache客戶端
CPU使用率低
#缺點
內存使用率高
各個memcached服務器之間互不通信,各自獨立存取數據,不共享任何信息。
#集群和分布式有什么區別?
集群可以在單機或者多台機子上部署多個相同配置的服務
分布式在多台機子上部署多個不同服務。
memcached與普通緩存對比

由於Memcached緩存實例是獨立於各個應用服務器實例運行的,因此應用服務實例可以訪問任意的緩存實例。
而傳統的緩存則與特定的應用實例綁定,因此每個應用實例將只能訪問特定的緩存。這種綁定一方面會導致整個應用所能夠訪問的緩存容量變得很小,另一方面也可能導致不同的緩存實例中存在着冗余的數據,從而降低了緩存系統的整體效率。
memcached的集群方案有哪些?
答:因為memcached的服務器並不支持集群,所以有兩種方案支持,一種是客戶端支持集群,一種是代理端支持集群(性能會有所損耗,大概20%)。推薦使用客戶端。
客戶端

中間件

緩存架構的演化
-
並發量低的時候

-
並發量1000~1w的時候

-
並發量1w~5w的時候

openstack
OpenStack既是一個社區,也是一個項目和一個開源軟件,提供開放源碼軟件,建立公共和私有雲,
它提供了一個部署雲的操作平台或工具集,其宗旨在於:幫助組織運行為虛擬計算或存儲服務的雲,為公有雲、私有雲,也為大雲、小雲提供可擴展的、靈活的雲計算。
OpenStackd開源項目由社區維護,包括OpenStack計算(代號為Nova),OpenStack對象存儲(代號為Swift),並OpenStack鏡像服務(代號Glance)的集合。 OpenStack提供了一個操作平台,或工具包,用於編排雲。
下面列出Openstack的詳細構架圖

LVS負載均衡

LVS(Linux Virtual Server)即Linux虛擬服務器,是由章文嵩博士主導的開源負載均衡項目,目前LVS已經被集成到Linux內核模塊中。
用戶請求 -- LVS調度器 -- 根據自己預設的算法決定將該請求發送給后端的某台Web服務器
web服務器 -- 真實服務器會選擇不同的方式將用戶需要的數據發送到終端用戶
#LVS有工作模式,分為NAT模式、TUN模式、以及DR模式
#LVS負載均衡算法,輪詢調度(簡稱'RR'),加權輪詢(簡稱'WRR'),最小連接調度(簡稱'LC'),加權最少連接(簡稱'WLC'),最少隊列調度
#基於NAT的LVS負載均衡,動態網絡地址轉換模式
LVS負載調度器可以使用兩塊網卡配置不同的IP地址,eth0設置為私鑰IP與內部網絡通過交換設備相互連接,eth1設備為外網IP與外部網絡聯通。
調度器在得到響應的數據包后會將源地址和源端口修改為VIP及調度器相應的端口
由於LVS調度器有一個連接Hash表,該表中會記錄連接請求及轉發信息,當同一個連接的下一個數據包發送給調度器時,從該Hash表中可以直接找到之前的連接記錄,並根據記錄信息選出相同的真實服務器及端口信息。

#基於TUN的LVS負載均衡,ip隧道模式
如果后端服務器的數量大於10台,則調度器就會成為整個集群環境的瓶頸
LVS(TUN)的思路就是將請求與響應數據分離,讓調度器僅處理數據請求,而讓真實服務器響應數據包直接返回給客戶端
IP隧道(IP tunning)是一種數據包封裝技術,它可以將原始數據包封裝並添加新的包頭(內容包括新的源地址及端口、目標地址及端口),從而實現將一個目標為調度器的VIP地址的數據包封裝

#基於DR的LVS負載均衡,DR模式也叫直接路由模式
在LVS(TUN)模式下,由於需要在LVS調度器與真實服務器之間創建隧道連接,這會增加服務器的負擔
LVS依然僅承擔數據的入站請求以及根據算法選出合理的真實服務器,最終由后端真實服務器負責將響應數據包發送返回給客戶端
與隧道模式不同的是,直接路由模式(DR模式)要求'調度器與后端服務器'必須在'同一個局域網內',VIP地址需要在調度器與后端所有的服務器間'共享'
這樣客戶端訪問的是調度器的VIP地址,回應的源地址也依然是該VIP地址(真實服務器上的VIP),客戶端是感覺不到后端服務器存在的

大數據
大數據與雲計算的關系就像一枚硬幣的正反面一樣密不可分。
大數據必然無法用單台的計算機進行處理,必須采用分布式計算架構。
大數據常用組件
CDH
hive
hadoop
flick
spark
storm
hbase