JAVA程序最爽的地方是它的GC機制,開發人員不需要關注內存申請和回收問題。同時,JAVA程序最頭疼的地方也是它的GC機制,因為掌握JVM和GC調優是一件非常困難的事情。在ParallelOldGC、CMS、G1之后,JDK11帶來的全新的「ZGC」為我們解決了什么問題?Oracle官方介紹它是一個Scalable、Low Latency的垃圾回收器。所以它的目的是「降低停頓時間」,由此會導致吞吐量會有所降低。吞吐量降低問題不大,橫向擴展幾台服務器就能解決問題了啦。
ZGC目標
如下圖所示,ZGC的目標主要有4個:
- 支持TB量級的堆。這你受得了嗎?我們生產環境的硬盤還沒有上TB呢,這應該可以滿足未來十年內,所有JAVA應用的需求了吧。
- 最大GC停頓時間不超10ms。這你受得了嗎?目前一般線上環境運行良好的JAVA應用Minor GC停頓時間在10ms左右,Major GC一般都需要100ms以上(G1可以調節停頓時間,但是如果調的過低的話,反而會適得其反),之所以能做到這一點是因為它的停頓時間主要跟Root掃描有關,而Root數量和堆大小是沒有任何關系的。
- 奠定未來GC特性的基礎。牛逼,牛逼!
- 最糟糕的情況下吞吐量會降低15%。這都不是事,停頓時間足夠優秀。至於吞吐量,通過擴容分分鍾解決。

另外,Oracle官方提到了它最大的優點是:它的停頓時間不會隨着堆的增大而增長!也就是說,幾十G堆的停頓時間是10ms以下,幾百G甚至上T堆的停頓時間也是10ms以下。
ZGC概述
接下來從幾個維度概述一下ZGC。
- New GC
- Single Generation
- Region Based
- Partial Compaction
- NUMA-aware
- Colored Pointers
- Load Barriers
- ZGC tuning
- Change Log
New GC
ZGC是一個全新的垃圾回收器,它完全不同以往HotSpot的任何垃圾回收器,比如:PS、CMS、G1等。如果真要說它最像誰的話,那應該是Azul公司的商業化垃圾回收器:「C4」,ZGC所采用的算法就是Azul Systems很多年前提出的Pauseless GC,而實現上它介於早期Azul VM的Pauseless GC與后來Zing VM的C4之間。不過需要說明的是,JDK11中ZGC只能運行在Linux64操作系統之上。JDK14新增支持了MacOS和Window平台:
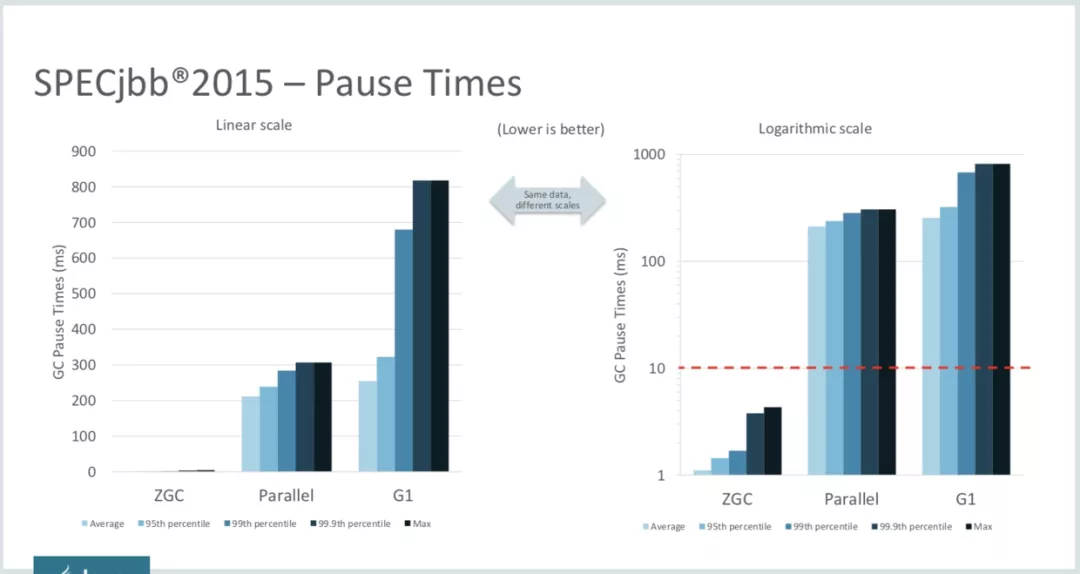
如下圖所示,是ZGC和Parallel以及G1的壓測對比結果(CMS在JDK9中已經被標記deprecated,更高版本中已經被徹底移除,所以不在對比范圍內)。我們可以明顯的看到,停頓時間方面,ZGC是100%不超過10ms的,簡直是秒天秒地般的存在:
接下來,再看一下ZGC的垃圾回收過程,如下圖所示。由圖我們可知,ZGC依然沒有做到整個GC過程完全並發執行,依然有3個STW階段,其他3個階段都是並發執行階段:
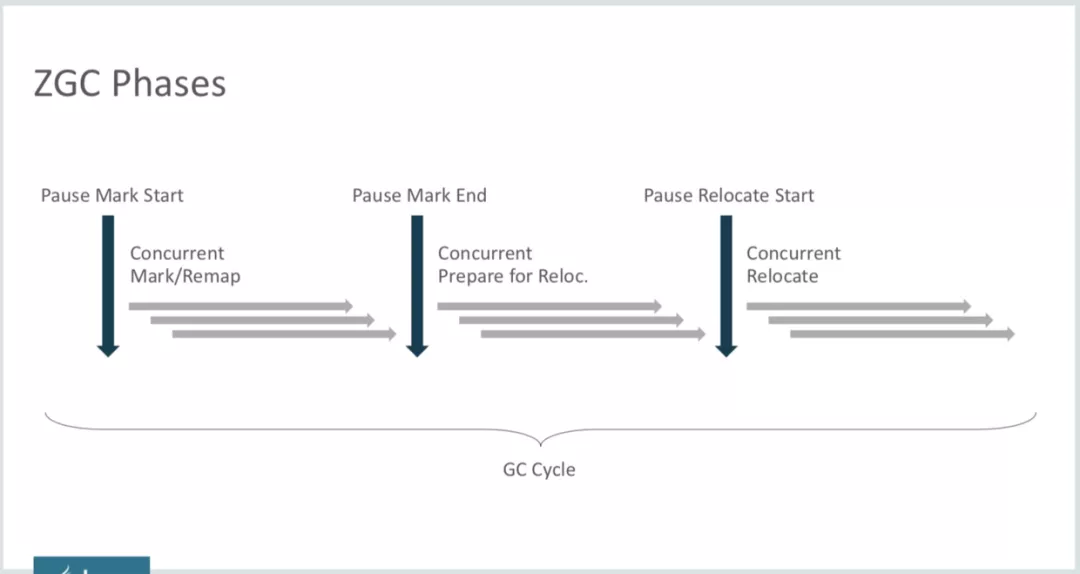
- Pause Mark Start
這一步就是初始化標記,和CMS以及G1一樣,主要做Root集合掃描,「GC Root是一組必須活躍的引用,而不是對象」。例如:活躍的棧幀里指向GC堆中的對象引用、Bootstrap/System類加載器加載的類、JNI Handles、引用類型的靜態變量、String常量池里面的引用、線程棧/本地(native)棧里面的對象指針等,但不包括GC堆里的對象指針。所以這一步驟的STW時間非常短暫,並且和堆大小沒有任何關系。不過會根據線程的多少、線程棧的大小之類的而變化。
- Concurrent Mark/Remap
第二步就是並發標記階段,這個階段在第一步的基礎上,繼續往下標記存活的對象。並發標記后,還會有一個短暫的暫停(Pause Mark End),確保所有對象都被標記。
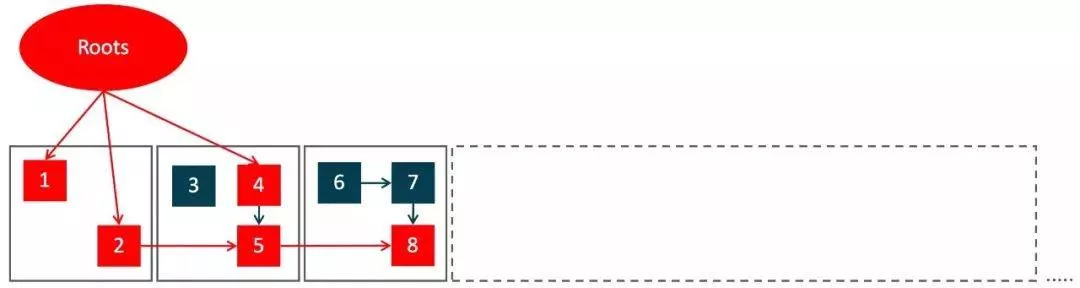
- Concurrent Prepare for Relocate
即為Relocation階段做准備,選取接下來需要標記整理的Region集合,這個階段也是並發執行的。接下來又會有一個Pause Relocate Start步驟,它的作用是只移動Root集合對象引用,所以這個STW階段也不會停頓太長時間。
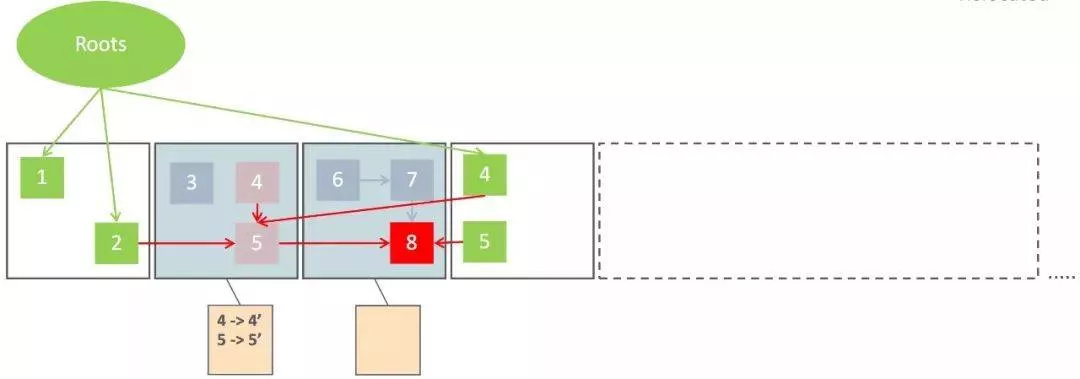
- Concurrent Relocate
最后,就是並發回收階段了,這個階段會把上一階段選中的需要整理的Region集合中存活的對象移到一個新的Region中(這個行為就叫做「Relocate」,即重新安置對象),如上圖所示。Relocate動作完成后,原來占用的Region就能馬上回收並被用於接下來的對象分配。細心的同學可能有疑問了,這就完了?Relocate后對象地址都發生變化了,應用程序還怎么正常操作這些對象呢?這就靠接下來會詳細說明的Load Barrier了。
Single Generation
單代,即ZGC「沒有分代」。我們知道以前的垃圾回收器之所以分代,是因為源於“「大部分對象朝生夕死」”的假設,事實上大部分系統的對象分配行為也確實符合這個假設。
那么為什么ZGC就不分代呢?因為分代實現起來麻煩,作者就先實現出一個比較簡單可用的單代版本。用符合我們國情的話來解釋,大概就是說:工作量太大了,人力又不夠,老板,先上個1.0版本吧!!!
Region Based
這一點和G1一樣,都是基於Region設計的垃圾回收器,ZGC中的Region也被稱為「ZPages」,ZPages被動態創建,動態銷毀。不過,和G1稍微有點不同的是,G1的每個Region大小是完全一樣的,而ZGC的Region大小分為3類:2MB,32MB,N×2MB,如此一來,靈活性就更好了:
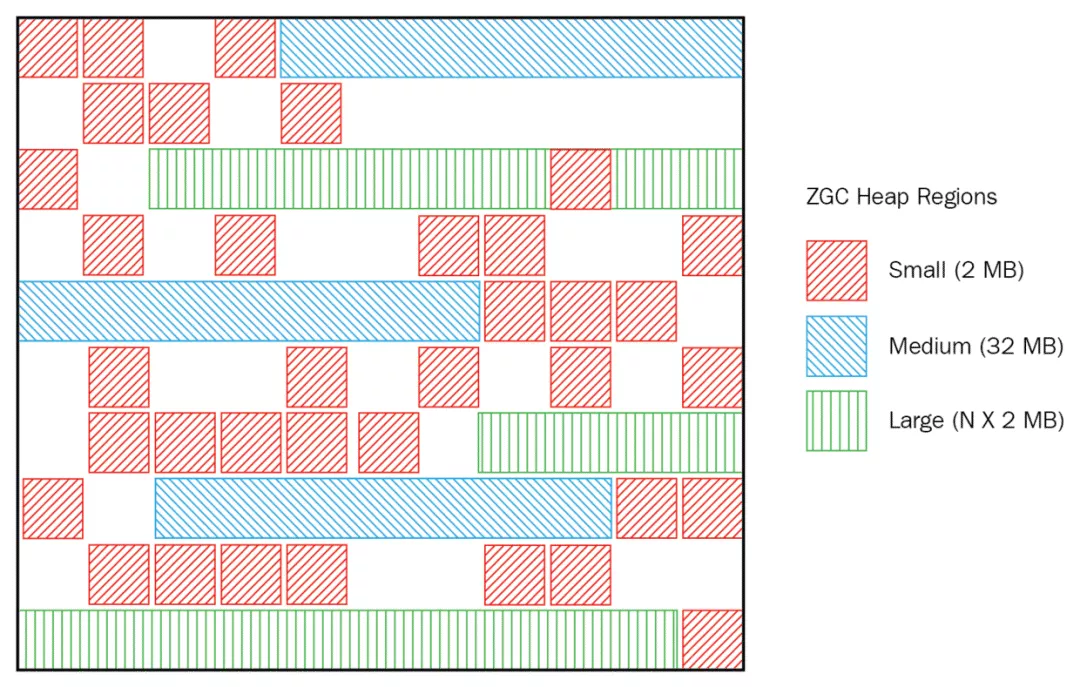
Partial Compaction
部分壓縮,這一點也很G1類似。以前的ParallelOldGC,以及CMS GC在壓縮Old區的時候,無論Old區有多大,必須整體進行壓縮(CMS GC默認情況下只是標記清除,只會發生FGC時才會采用Mark-Sweep-Compact對Old區進行壓縮),如此一來,Old區越大,壓縮需要的時間肯定就越長,從而導致停頓時間就越長。
而G1和ZGC都是基於Region設計的,在回收的時候,它們只會選擇一部分Region進行回收,這個回收過程采用的是Mark-Compact算法,即將待回收的Region中存活的對象拷貝到一個全新的Region中,這個新的Region對象分配就會非常緊湊,幾乎沒有碎片。垃圾回收算法這一點上,和G1是一樣的。
NUMA-aware
NUMA對應的有UMA,UMA即Uniform Memory Access Architecture,NUMA就是Non Uniform Memory Access Architecture。UMA表示內存只有一塊,所有CPU都去訪問這一塊內存,那么就會存在競爭問題(爭奪內存總線訪問權),有競爭就會有鎖,有鎖效率就會受到影響,而且CPU核心數越多,競爭就越激烈。NUMA的話每個CPU對應有一塊內存,且這塊內存在主板上離這個CPU是最近的,每個CPU優先訪問這塊內存,那效率自然就提高了:
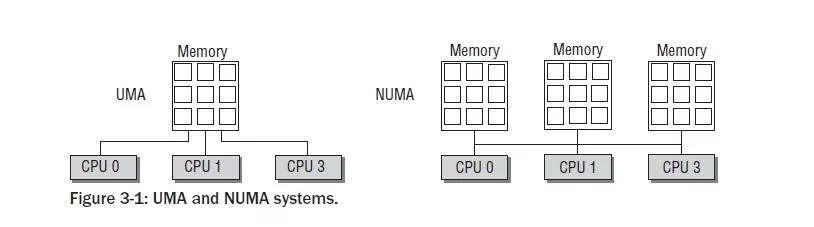
服務器的NUMA架構在中大型系統上一直非常盛行,也是高性能的解決方案,尤其在系統延遲方面表現都很優秀。ZGC是能自動感知NUMA架構並充分利用NUMA架構特性的。
Colored Pointers
Colored Pointers,即顏色指針是什么呢?如下圖所示,ZGC的核心設計之一。以前的垃圾回收器的GC信息都保存在對象頭中,而ZGC的GC信息保存在指針中。每個對象有一個64位指針,這64位被分為:
- 18位:預留給以后使用;
- 1位:Finalizable標識,次位與並發引用處理有關,它表示這個對象只能通過finalizer才能訪問;
- 1位:Remapped標識,設置此位的值后,對象未指向relocation set中(relocation set表示需要GC的Region集合);
- 1位:Marked1標識;
- 1位:Marked0標識,和上面的Marked1都是標記對象用於輔助GC;
- 42位:對象的地址(所以它可以支持2^42=4T內存):
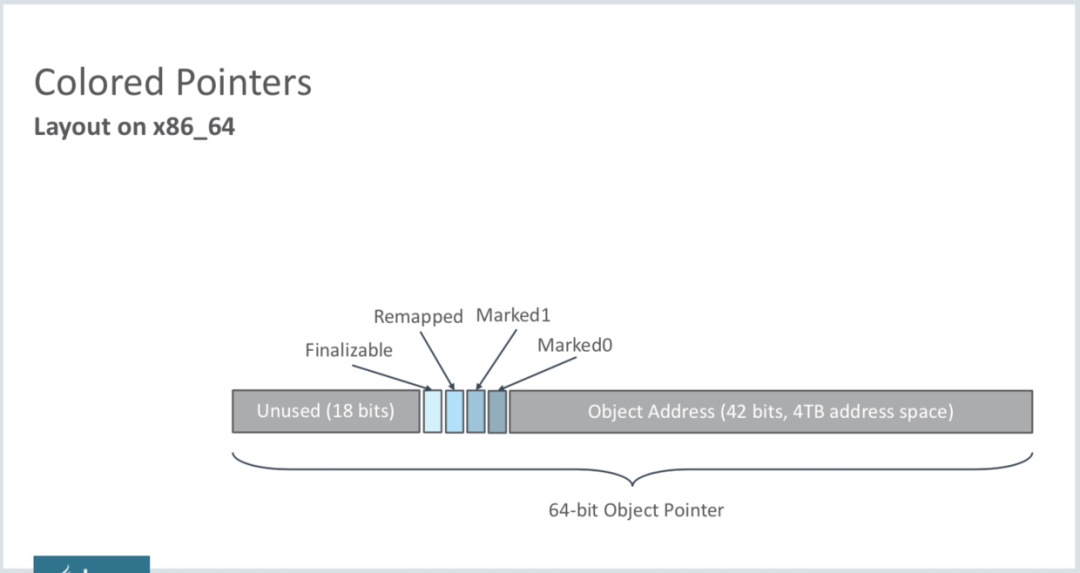
通過對配置ZGC后對象指針分析我們可知,對象指針必須是64位,那么ZGC就無法支持32位操作系統,同樣的也就無法支持壓縮指針了(CompressedOops,壓縮指針也是32位)。
Load Barriers
這個應該翻譯成讀屏障(與之對應的有寫屏障即Write Barrier,之前的GC都是采用Write Barrier,這次ZGC采用了完全不同的方案),這個是ZGC一個非常重要的特性。在標記和移動對象的階段,每次「從堆里對象的引用類型中讀取一個指針」的時候,都需要加上一個Load Barriers。那么我們該如何理解它呢?看下面的代碼,第一行代碼我們嘗試讀取堆中的一個對象引用obj.fieldA並賦給引用o(fieldA也是一個對象時才會加上讀屏障)。如果這時候對象在GC時被移動了,接下來JVM就會加上一個讀屏障,這個屏障會把讀出的指針更新到對象的新地址上,並且把堆里的這個指針“修正”到原本的字段里。這樣就算GC把對象移動了,讀屏障也會發現並修正指針,於是應用代碼就永遠都會持有更新后的有效指針,而且不需要STW。那么,JVM是如何判斷對象被移動過呢?就是利用上面提到的顏色指針,如果指針是Bad Color,那么程序還不能往下執行,需要「slow path」,修正指針;如果指針是Good Color,那么正常往下執行即可:

這個動作是不是非常像JDK並發中用到的CAS自旋?讀取的值發現已經失效了,需要重新讀取。而ZGC這里是之前持有的指針由於GC后失效了,需要通過讀屏障修正指針。
后面3行代碼都不需要加讀屏障:Object p = o這行代碼並沒有從堆中讀取數據;o.doSomething()也沒有從堆中讀取數據;obj.fieldB不是對象引用,而是原子類型。
正是因為Load Barriers的存在,所以會導致配置ZGC的應用的吞吐量會變低。官方的測試數據是需要多出額外4%的開銷:

那么,判斷對象是Bad Color還是Good Color的依據是什么呢?就是根據上一段提到的Colored Pointers的4個顏色位。當加上讀屏障時,根據對象指針中這4位的信息,就能知道當前對象是Bad/Good Color了。
「擴展閱讀」:既然低42位指針可以支持4T內存,那么能否通過預約更多位給對象地址來達到支持更大內存的目的呢?答案肯定是不可以。因為目前主板地址總線最寬只有48bit,4位是顏色位,就只剩44位了,所以受限於目前的硬件,ZGC最大只能支持16T的內存,JDK13就把最大支持堆內存從4T擴大到了16T。
ZGC tuning
啟用ZGC比較簡單,設置JVM參數即可:-XX:+UnlockExperimentalVMOptions 「-XX:+UseZGC」。調優也並不難,因為ZGC調優參數並不多,遠不像CMS那么復雜。它和G1一樣,可以調優的參數都比較少,大部分工作JVM能很好的自動完成。下圖所示是ZGC可以調優的參數:
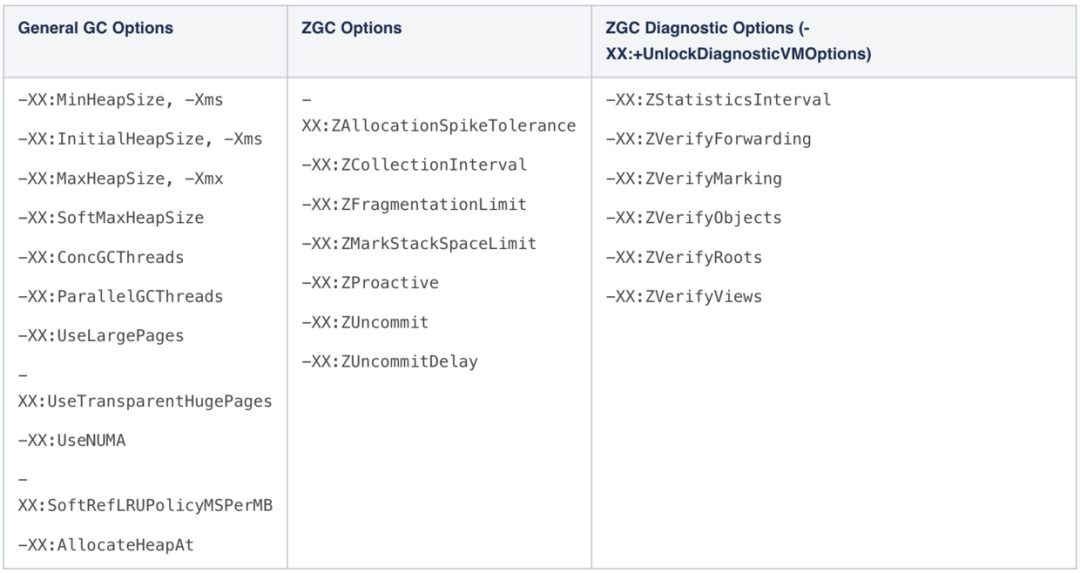
下面對部分參數進行更加詳細的說明。
UseNUMA
ZGC默認是開啟支持NUMA的,不過,如果JVM探測到系統綁定的是CPU子集,就會自動禁用NUMA。我們可以通過參數-XX:+UseNUMA顯示啟動,或者通過參數-XX:-UseNUMA顯示禁用。如果運行在NUMA服務器上,並且設置-XX:+UseNUMA,那對性能提升是顯而易見的。
UseLargePages
配置ZGC使用large page通常就會得到更好的性能,比如在吞吐量、延遲、啟動時間等方面。而且沒有明顯的缺點,除了配置過程復雜一點。因為它需要root權限,這也是默認並沒有開啟使用large page的原因。
ConcGCThreads
ZGC是一個並發垃圾收集器,那么並發GC線程數就非常重要了。如果設置並發GC線程數越多,意味着應用線程數就會越少,這肯定是非常不利於應用系統穩定運行的。這個參數ZGC能自動設置,如果沒有十足的把握。最好不要設置這個參數。
ParallelGCThreads
這是個並行線程數,與上一個參數ConcGCThreads有所不同,ConcGCThreads表示GC線程和應用線程「並發」執行時GC線程數量。而ParallelGCThreads表示GC時STW階段的「並行」GC線程數量(例如第一階段的Root掃描),這時候只有GC線程,沒有應用線程。筆者這里解釋了JVM中「並發和並行的區別」,也是JVM中比較容易理解錯誤的地方。
ZUncommit
掌握這個參數之前,我們先說一下JVM申請以及回收內存的行為。以前的垃圾回收器比如ParallelOldGC和CMS,只要JVM申請過的內存,即使發生了GC回收了很多內存空間,JVM也不會把這些內存歸還給操作系統。這就會導致top命令中看到的RSS只會越來越高,而且一般都會超過Xmx的值(參考文章:)。
不過,默認情況下,ZGC是會把不再使用的內存歸還給操作系統的。這對於那些比較注意內存占用情況的應用和服務器來說,是很有用的。這種行為可以通過JVM參數-XX:-ZUncommit關閉。不過,無論怎么歸還,JVM至少會保留Xms參數指定的內存大小,這就是說,當Xmx和Xms一樣大的時候,這個參數就不起作用了。
和這個參數一起起作用的還有另一個參數:-「XX:ZUncommitDelay=sec」,默認300秒。這個參數表示不再使用的內存最多延遲多長時間才會被歸還給操作系統。因為不再使用的內存不應該立即歸還給操作系統,這樣會造成頻繁的歸還和申請行為,所以通過這個參數來控制不再使用的內存需要經過多久的時間才歸還給操作系統。
Change Log
接下來,我們看一下從JDK11到JDK15這5個版本,ZGC都迭代了哪些特性:
JDK 15 (under development)
- Improved NUMA awareness
- Support for Class Data Sharing (CDS)
- Support for placing the heap on NVRAM
JDK 14
- macOS support (JEP 364)
- Windows support (JEP 365)
- Support for tiny/small heaps (down to 8M)
- Support for JFR leak profiler
- Support for limited and discontiguous address space
- Parallel pre-touch (when using -XX:+AlwaysPreTouch)
- Performance improvements (clone intrinsic, etc)
- Stability improvements
JDK 13
- Increased max heap size from 4TB to 16TB
- Support for uncommitting unused memory (JEP 351)
- Support for -XX:SoftMaxHeapSIze
- Support for the Linux/AArch64 platform
- Reduced Time-To-Safepoint
JDK 12
- Support for concurrent class unloading
- Further pause time reductions
JDK 11
- Initial version of ZGC
- Does not support class unloading (using -XX:+ClassUnloading has no effect)
看完三件事❤️
如果你覺得這篇內容對你還蠻有幫助,我想邀請你幫我三個小忙:
-
點贊,轉發,有你們的 『點贊和評論』,才是我創造的動力。
-
關注公眾號 『 java爛豬皮 』,不定期分享原創知識。
-
同時可以期待后續文章ing🚀
